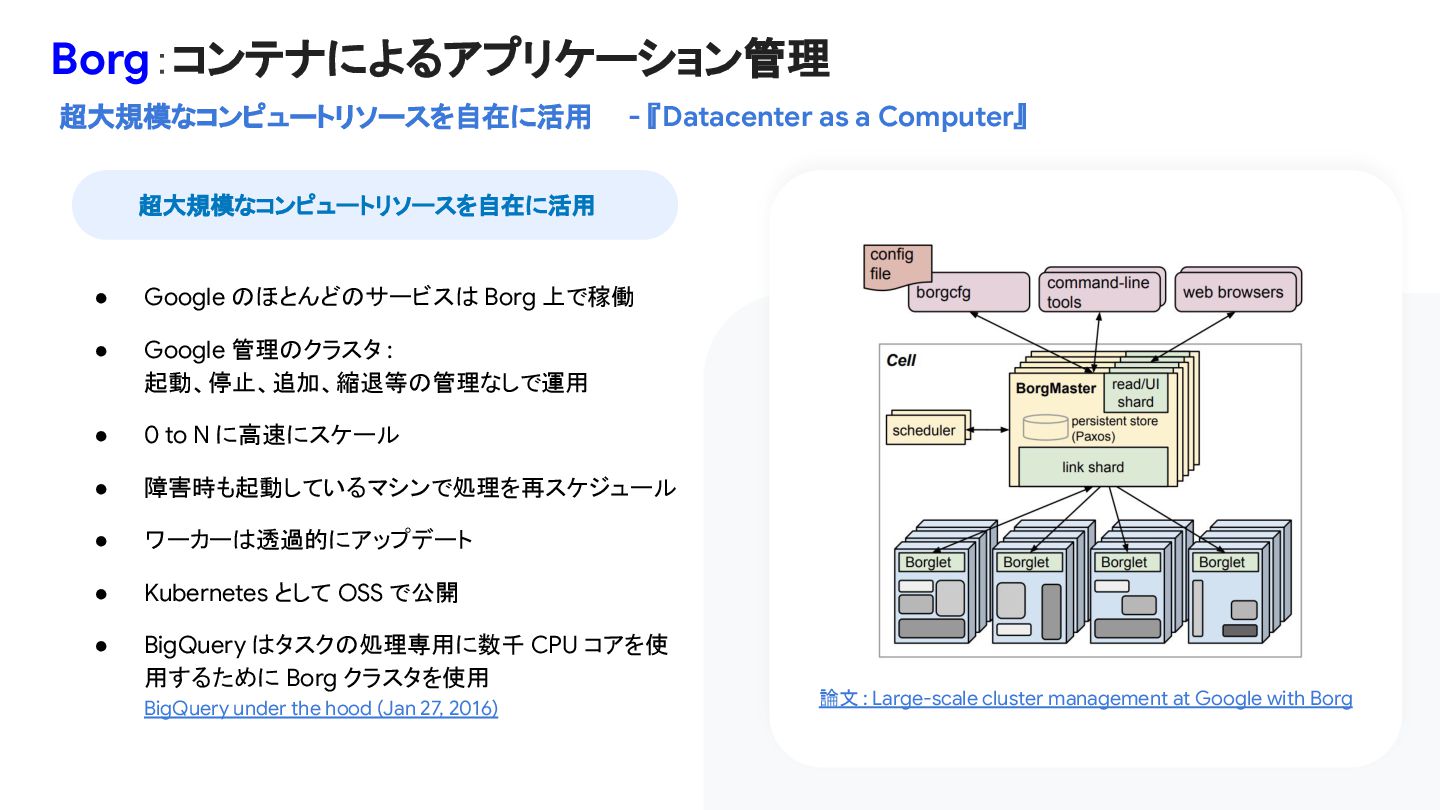
• 0 to N に高速にスケール • 障害時も起動しているマシンで処理を再スケジュール • ワーカーは透過的にアップデート • Kubernetes として OSS で公開 • BigQuery はタスクの処理専用に数千 CPU コアを使 用するために Borg クラスタを使用 BigQuery under the hood (Jan 27, 2016) 論文 : Large-scale cluster management at Google with Borg 超大規模なコンピュートリソースを自在に活用 Borg:コンテナによるアプリケーション管理 超大規模なコンピュートリソースを自在に活用 - 『Datacenter as a Computer』
Silicon) Built for AI from ground up Google Cloud はエンドツーエンドのデータと AI を垂直統合 した唯一のクラウド Google は、組織全体でデータと AI のワークフローを最適化するためにゼロから構築 BigQuery Data Vertex AI AI Looker Insights Gemini on Google Cloud
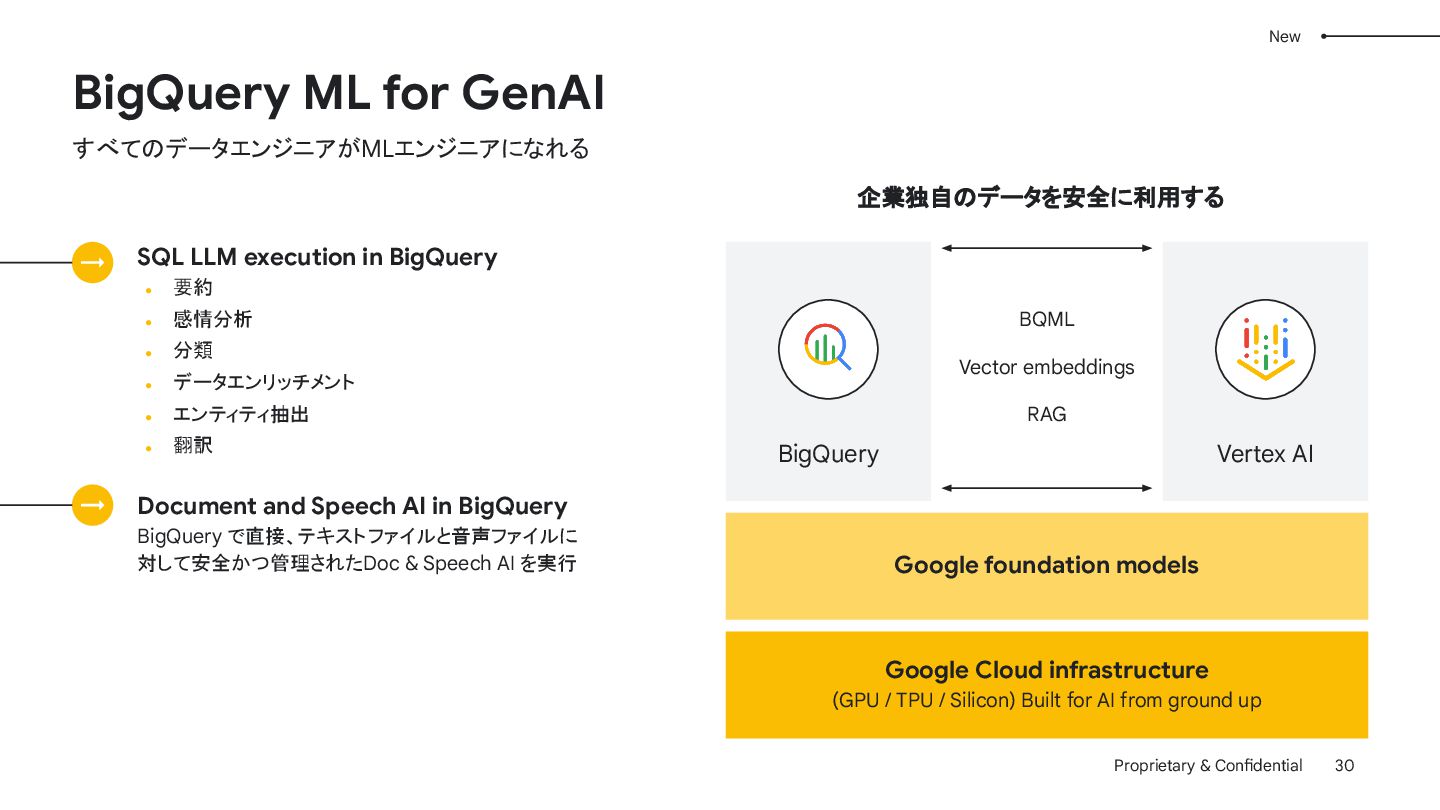
Vertex AI BQML Vector embeddings RAG Google foundation models Google Cloud infrastructure (GPU / TPU / Silicon) Built for AI from ground up SQL LLM execution in BigQuery • 要約 • 感情分析 • 分類 • データエンリッチメント • エンティティ抽出 • 翻訳 Document and Speech AI in BigQuery BigQuery で直接、テキスト ファイルと音声ファイルに 対して安全かつ管理された Doc & Speech AI を実行 企業独自のデータを安全に利用する New
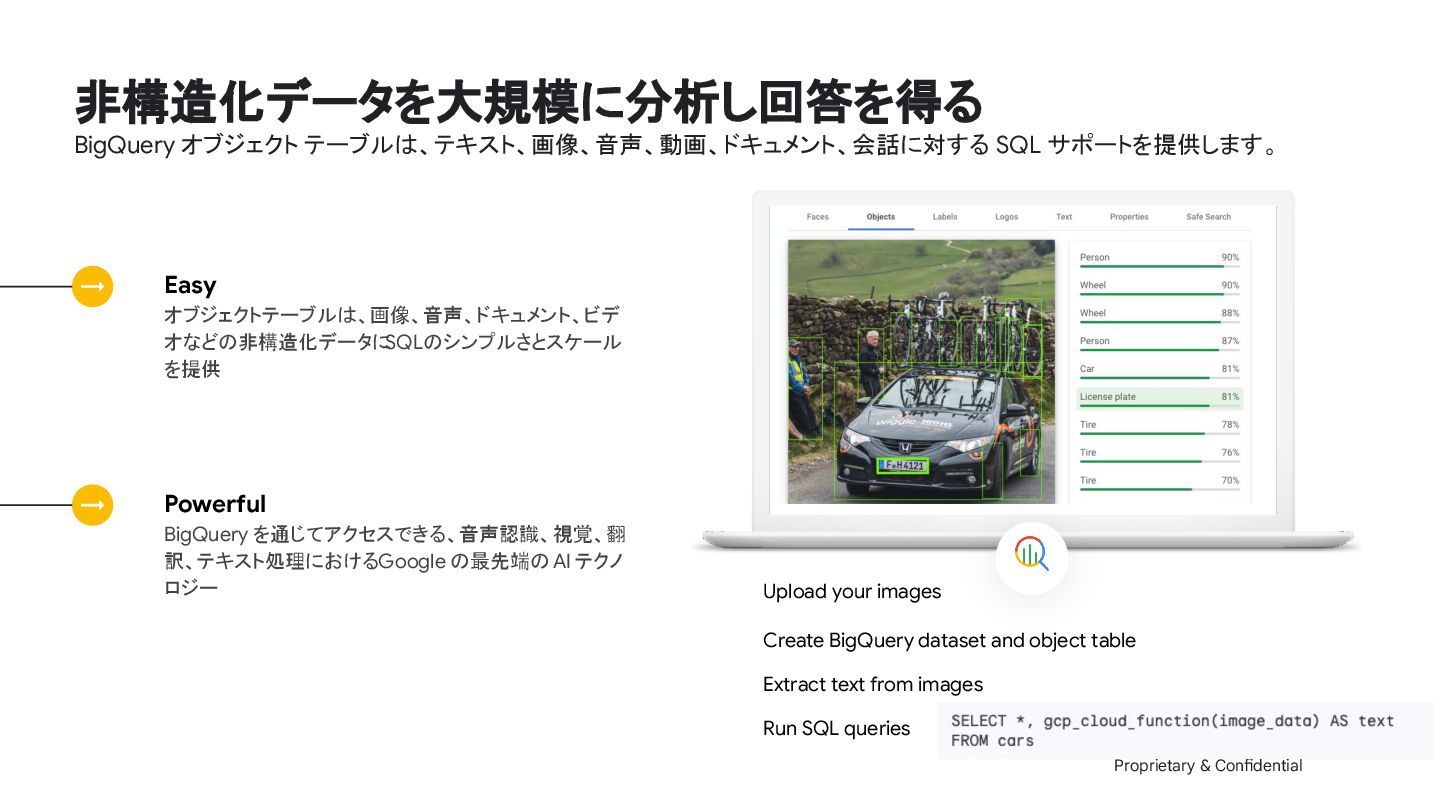
your images Create BigQuery dataset and object table Run SQL queries Extract text from images Powerful BigQuery を通じてアクセスできる、音声認識、視覚、翻 訳、テキスト処理における Google の最先端の AI テクノ ロジー Easy オブジェクトテーブルは、画像、音声、ドキュメント、ビデ オなどの非構造化データに SQLのシンプルさとスケール を提供
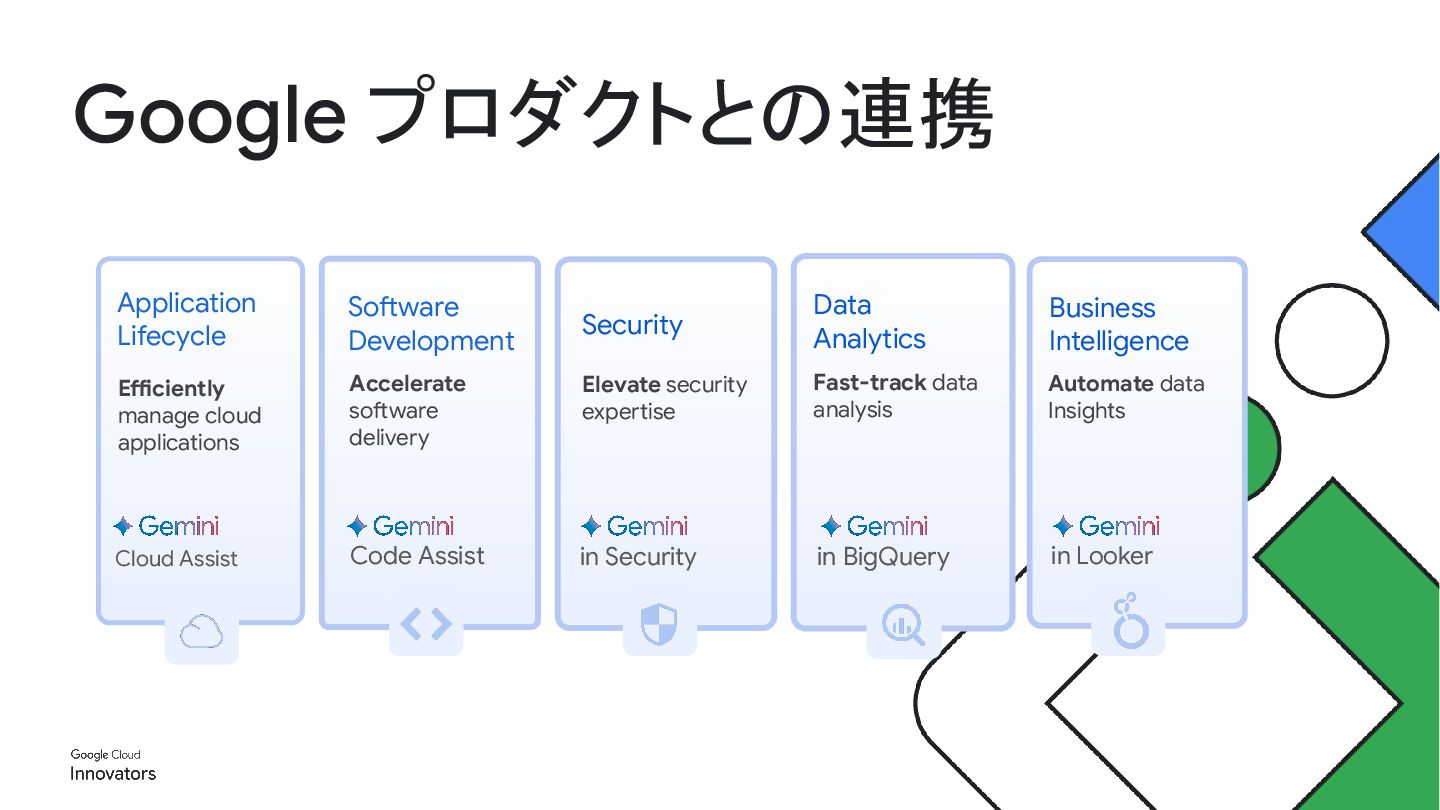
Assist Google プロダクトとの連携 in Security Security Elevate security expertise in BigQuery Data Analytics Fast-track data analysis in Looker Business Intelligence Automate data Insights Code Assist Software Development Accelerate software delivery
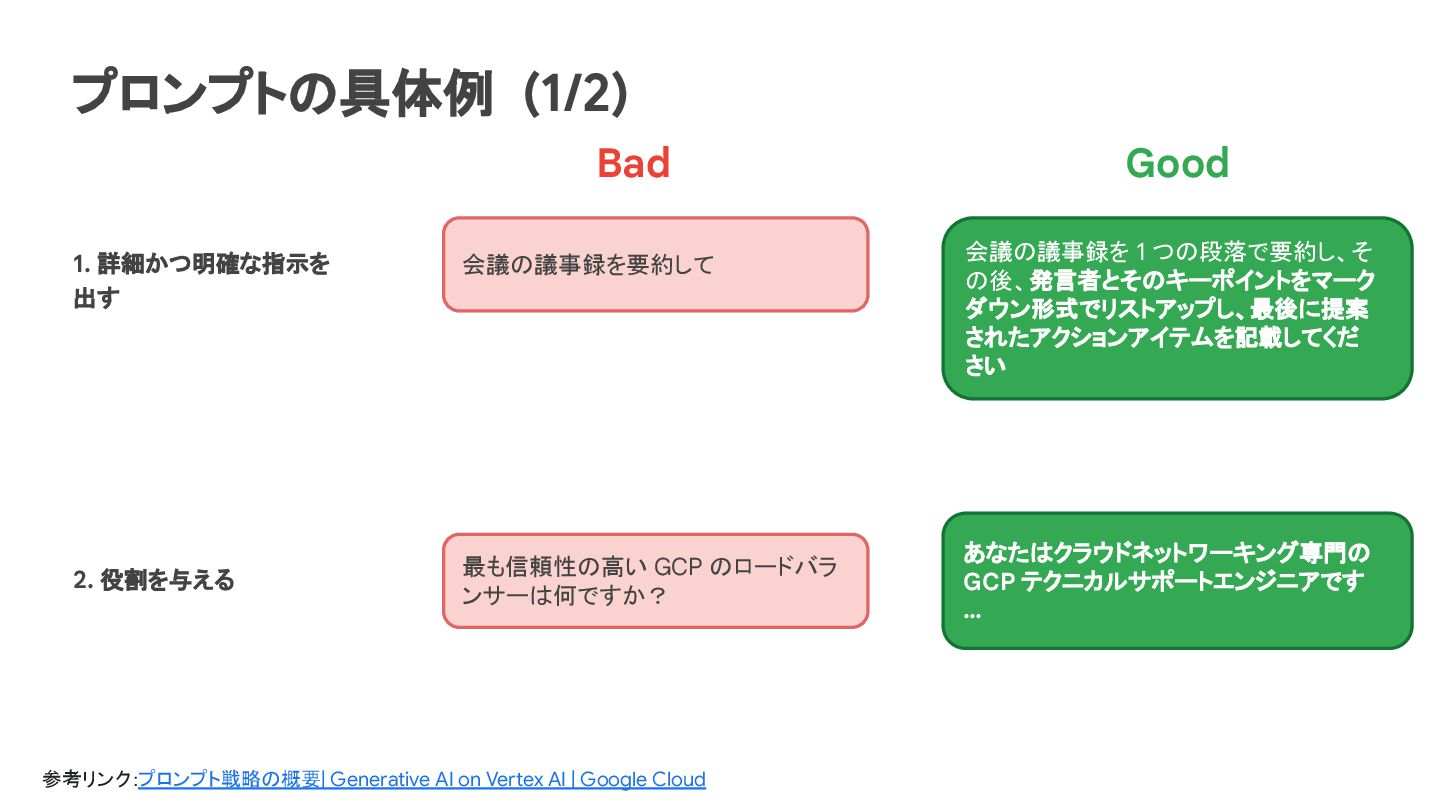
さい Bad Good 2. 役割を与える あなたはクラウドネットワーキング専門の GCP テクニカルサポートエンジニアです … 最も信頼性の高い GCP のロードバラ ンサーは何ですか? プロンプトの具体例 (1/2) 参考リンク:プロンプト戦略の概要 | Generative AI on Vertex AI | Google Cloud
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
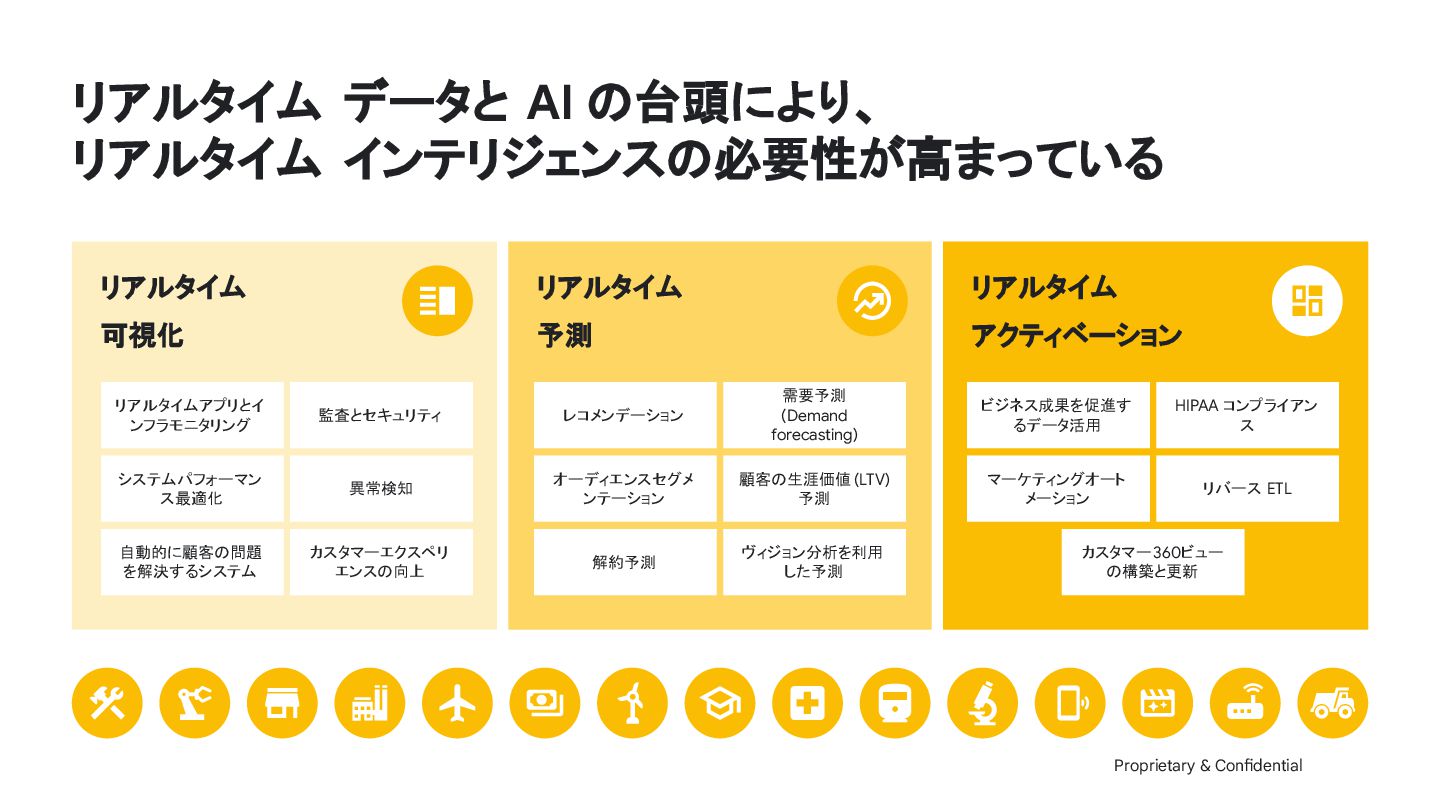{kind=link}
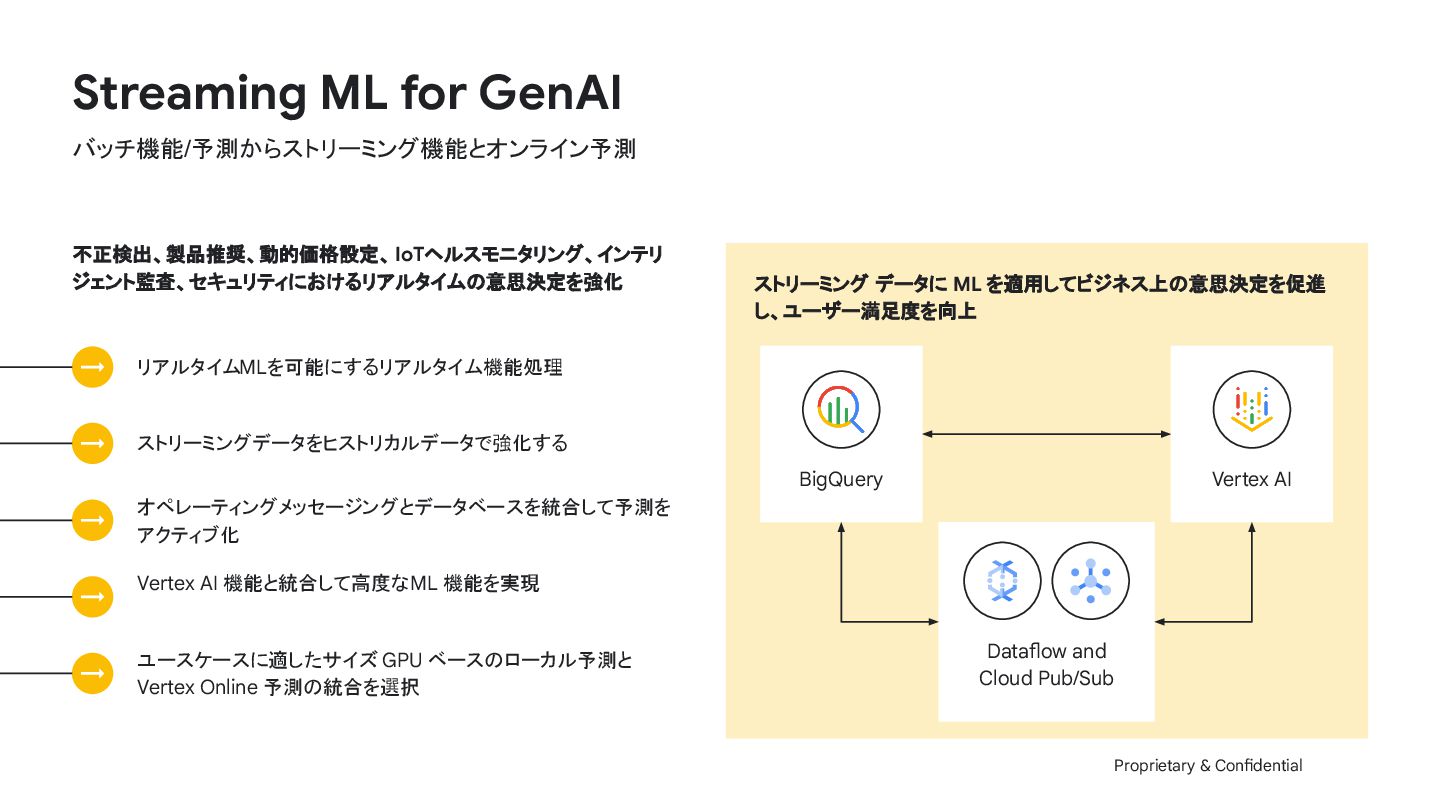{kind=link}
{kind=link}
{kind=link}
{kind=link}
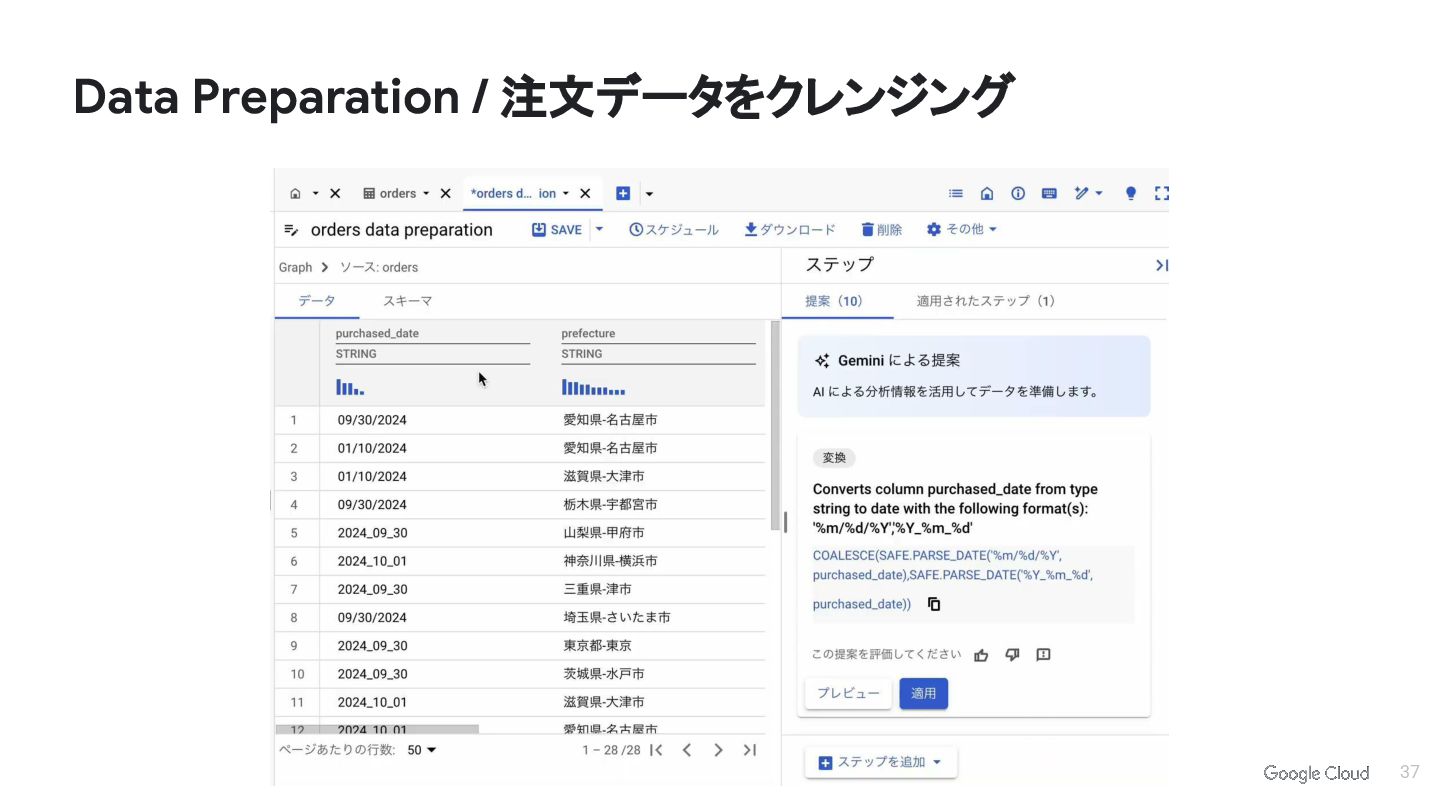{kind=link}
{kind=link}
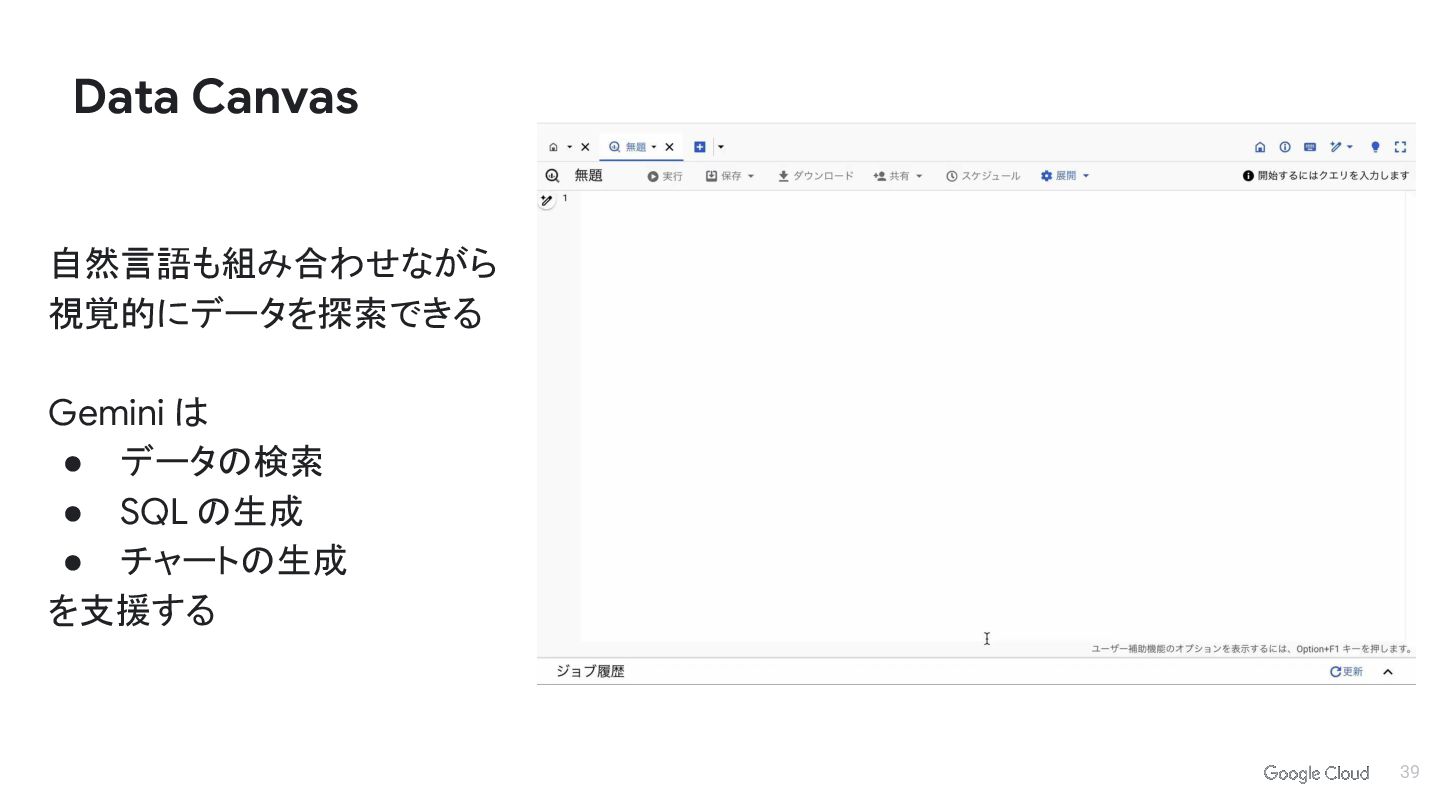{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}