Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
レガシーなGoogle App Engine + Python2環境のAWS Fargate ...
Search
gree_tech
PRO
October 13, 2023
Technology
0
780
レガシーなGoogle App Engine + Python2環境のAWS Fargate + Ruby on Railsへの移行
GREE Tech Conference 2023で発表された資料です。
https://techcon.gree.jp/2023/session/TrackA-1
gree_tech
PRO
October 13, 2023
Tweet
Share
More Decks by gree_tech
See All by gree_tech
kustomizeをいい感じに使う方法
gree_tech
PRO
5
3.1k
スケーラビリティとコスト管理 Google Cloud Spanner 費用最適化の取り組み
gree_tech
PRO
0
900
「アナザーエデン 時空を超える猫」の5年前のログを引っ越してデータドリブンで事業運用プロセスを改善した話
gree_tech
PRO
0
640
Unity,PHP+Jenkins+GAS 多言語対応を意識させない開発を目指したシステム構築
gree_tech
PRO
0
1.1k
全社総会における「REALITY Spaces」の活用と、Addressableを用いたコンテンツ配信技術について
gree_tech
PRO
0
750
AWSのEKS環境でログ機能を構築/リリースしたお話
gree_tech
PRO
0
580
「ヘブンバーンズレッド」の大規模アップデートにおける国内及び翻訳QAの取り組み
gree_tech
PRO
0
690
アプリ「REALITY」の12言語対応プロセスの仕組みと品質向上の取り組み
gree_tech
PRO
0
1k
REALITYアプリのメンテナンスなしでの機能リリースを実現する、Istio導入とB/Gデプロイ実現の取り組み
gree_tech
PRO
1
810
Other Decks in Technology
See All in Technology
o1のAPIで実験してみたが 制限きつすぎて辛かった話
pharma_x_tech
0
120
AI でアップデートする既存テクノロジーと、クラウドエンジニアの生きる道
soracom
PRO
2
550
AIで変わるテスト自動化:最新ツールの多様なアプローチ/ 20240910 Takahiro Kaneyama
shift_evolve
0
210
OSTという文化を組織に根付かせてみた
sansantech
PRO
2
290
ついに出た!OpenAIの最新モデル「o1」って何がすごいの?
minorun365
PRO
3
730
なにもしてないのにNew Relicのデータ転送量が増えていたときに確認したこと
tk3fftk
2
220
PDF Viewer作成の今までとこれから
hunachi
0
400
忙しい人のためのLangGraph概要まとめ
__ymgc__
1
170
事前準備が肝!AI活用のための業務改革
layerx
PRO
1
370
Next.js のページ遷移を全力で止める
ypresto
3
1.6k
AWS SAW を広めたい @四国クラウドお遍路
kazzpapa3
0
230
「認証認可」という体験をデザインする ~Nekko Cloud認証認可基盤計画
logica0419
2
430
Featured
See All Featured
Into the Great Unknown - MozCon
thekraken
29
1.4k
Debugging Ruby Performance
tmm1
72
12k
A better future with KSS
kneath
235
17k
Java REST API Framework Comparison - PWX 2021
mraible
PRO
27
7.4k
A Philosophy of Restraint
colly
202
16k
Put a Button on it: Removing Barriers to Going Fast.
kastner
58
3.4k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
123
18k
[RailsConf 2023] Rails as a piece of cake
palkan
48
4.6k
Designing Experiences People Love
moore
138
23k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
PRO
5
480
Designing with Data
zakiwarfel
98
5k
Facilitating Awesome Meetings
lara
49
5.9k
Transcript
レガシーなGoogle App Engine + Python2環境の AWS Fargate + Ruby on
Railsへの移行 Glossom株式会社 ソフトウェアエンジニア 木村洋太
自己紹介 木村洋太 Glossom株式会社 / プロダクト開発本部 / 開発部 / 開発グループ /
開発5チーム 略歴 2020/04 グリー株式会社入社 2020/04〜2022/07 メディア事業部にて住まい・暮らしの情報メディア「LIMIA」の開発 2022/07〜 DX事業部にてSNSマーケティング業務を一元管理して効率化する運用・分析ツール 「Social Pitt」のサービス全般の開発 2
はじめに • 今日お話しすること ◦ Google App Engine第一世代のバンドルサービスのそれぞれの移行方法 ◦ Google App
Engineに限らない移行・より大きなアプリケーションでも役に立 つ(であろう)移行方法 ◦ 移行当日の手順や失敗 3
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 4
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 5
SNSアカウント運用、インフルエンサーPR、UGCクリエィティブ活用など 様々なSNSマーケティング業務を効率化・効果最大化するサービス SNSマーケティングツール「Social Pitt」 6 1. Social Pittの紹介
SNSアカウント運用、インフルエンサーPR、UGCクリエィティブ活用など 様々なSNSマーケティング業務を効率化・効果最大化するサービス SNSマーケティングツール「Social Pitt」 7 1. Social Pittの紹介
Social Pittアカウント運用 8 1. Social Pittの紹介
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 9
移行の背景と目的 10 • 「Social Pittアカウント運用」の移行 ◦ 背景 ▪ 2018年ごろに内製ツールの外販に向けて開発 ▪
社内のアカウント運用業務では現在も広く利用 ▪ 2020年以降開発が停滞 ◦ 目的 ▪ Python2はとっくにdeprecatedなので脱却 ▪ サービス拡大に向けて、開発しやすい環境を整備 ▪ 予約投稿を強化し社内の運用効率を向上 2. 移行の概要
SNSアカウント運用、インフルエンサーPR、UGCクリエィティブ活用など 様々なSNSマーケティング業務を効率化・効果最大化するサービス SNSマーケティングツール「Social Pitt」 11 1. Social Pittの紹介
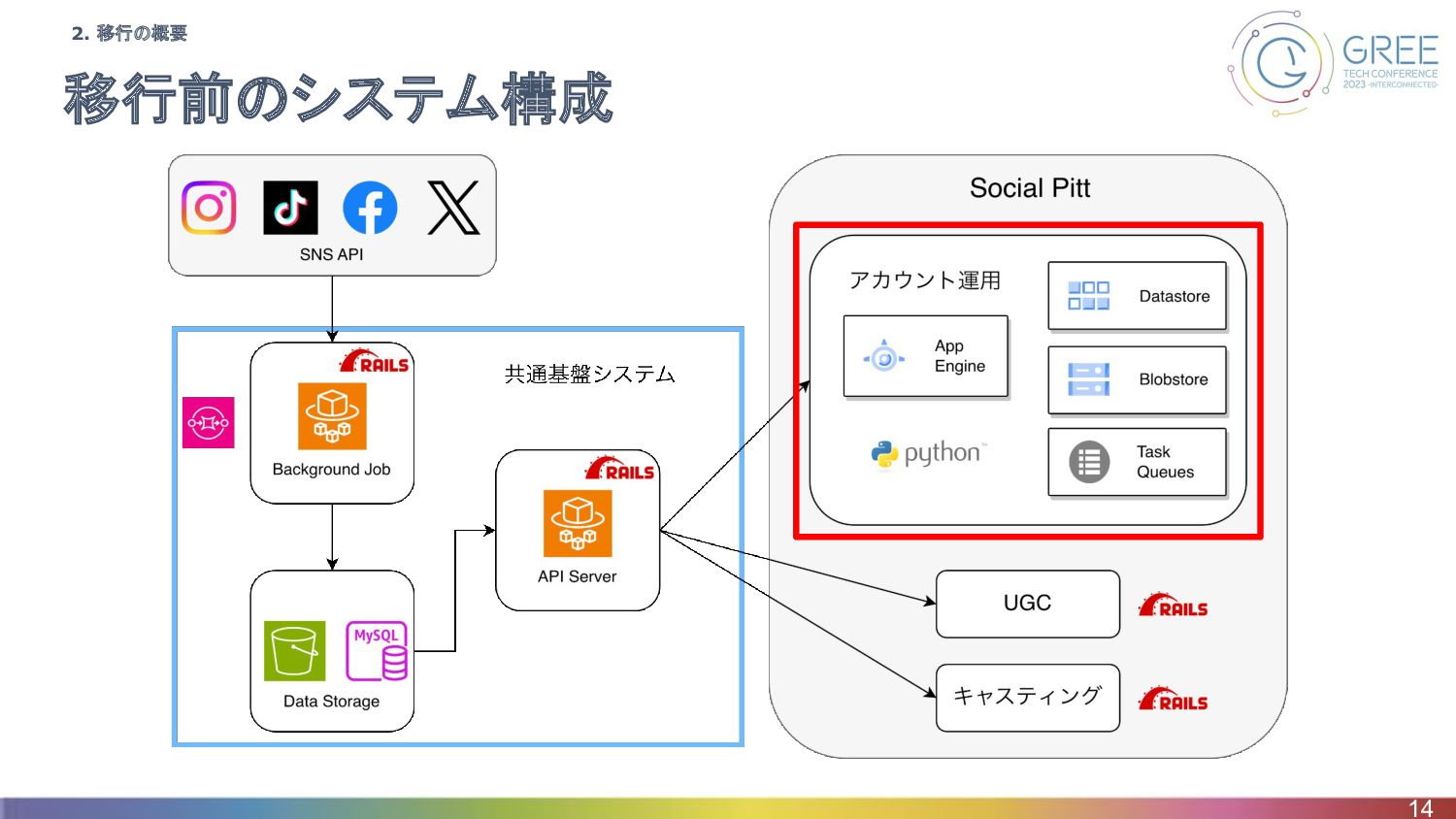
移行前のシステム構成 12 2. 移行の概要
(補足)Google App Engine 第一世代 13 • 様々なバンドルサービス ◦ Datastore ▪
NoSQLデータベース ◦ Blobstore ▪ Blob(Binary Large OBject)のデータストア ◦ Task Queue ▪ 非同期タスクを実行できるキューワーカーサービス ◦ MailやMemcacheなど ▪ アプリケーションの移行に含まれており個別には話さない 2. 移行の概要
移行前のシステム構成 14 2. 移行の概要
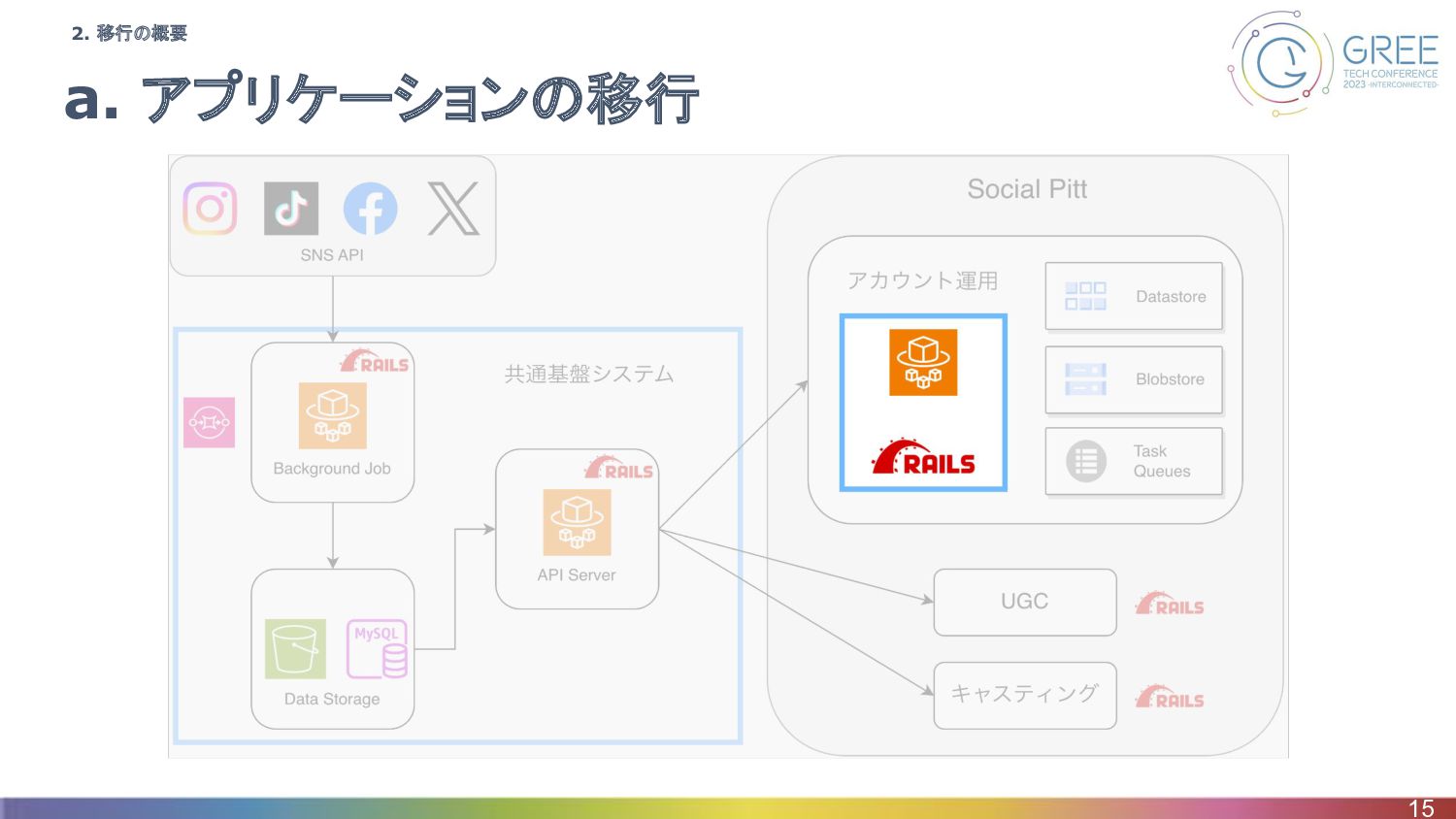
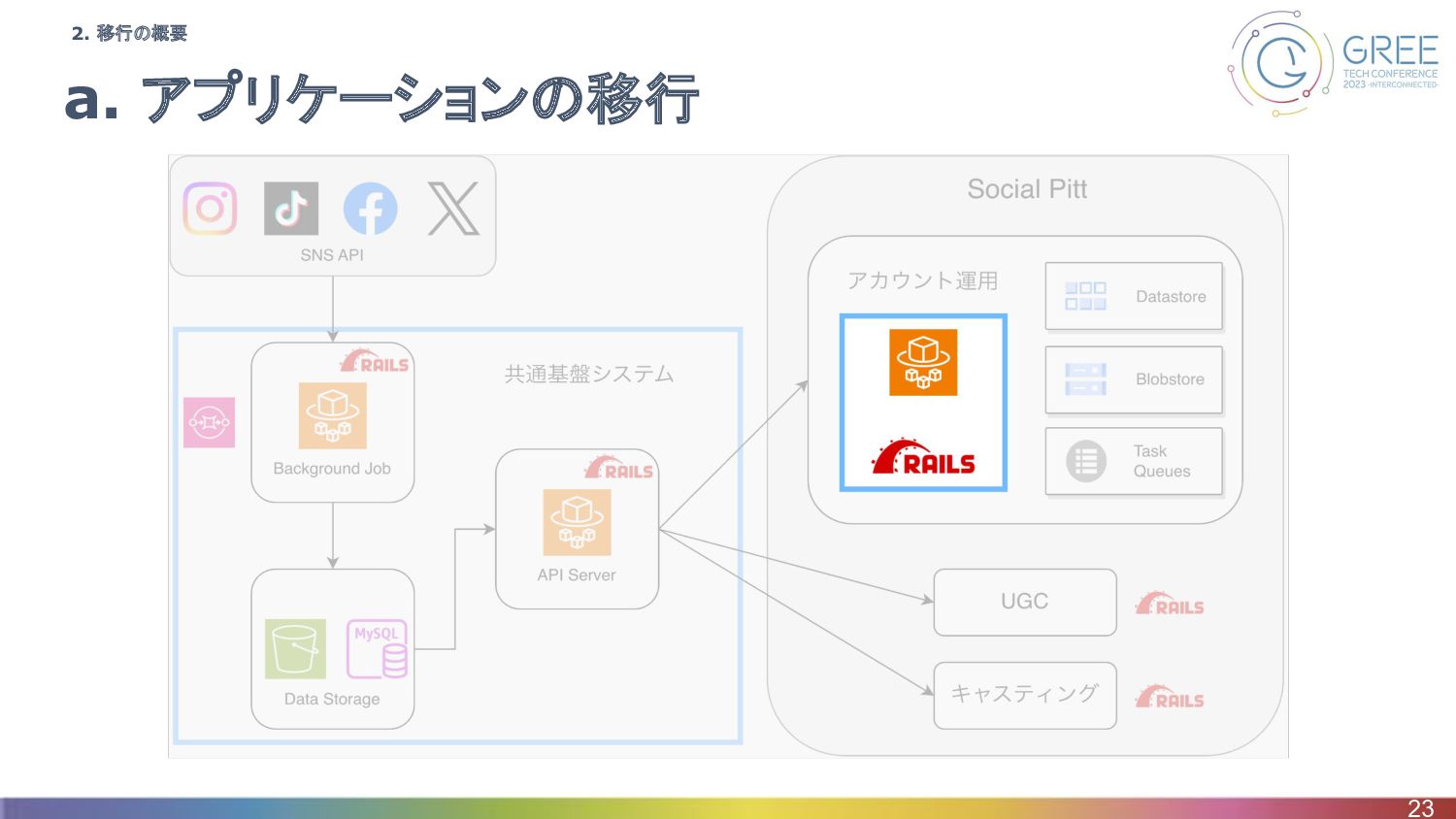
a. アプリケーションの移行 15 2. 移行の概要
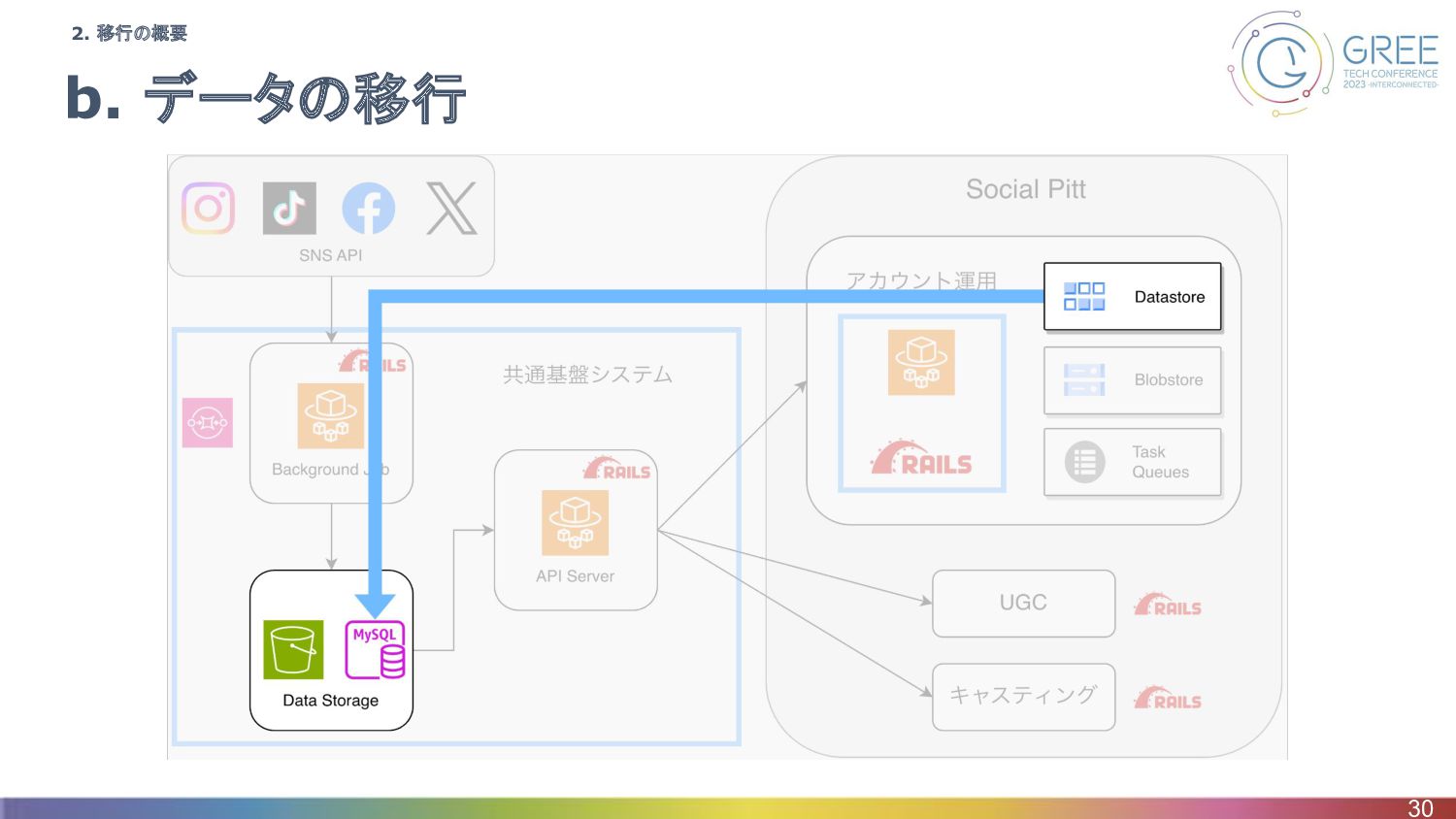
b. データの移行 16 2. 移行の概要
c. 画像・動画データの移行 17 2. 移行の概要
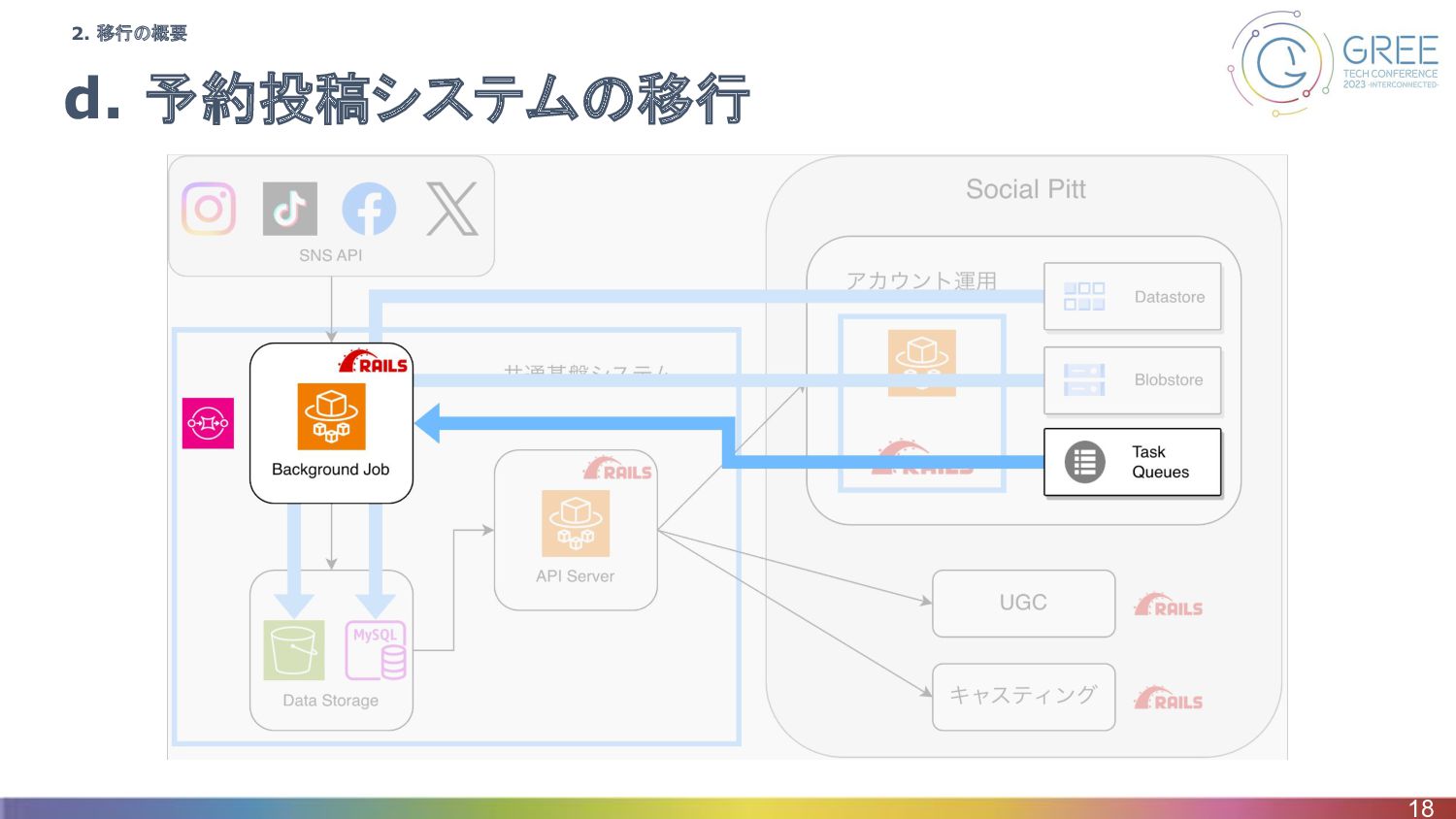
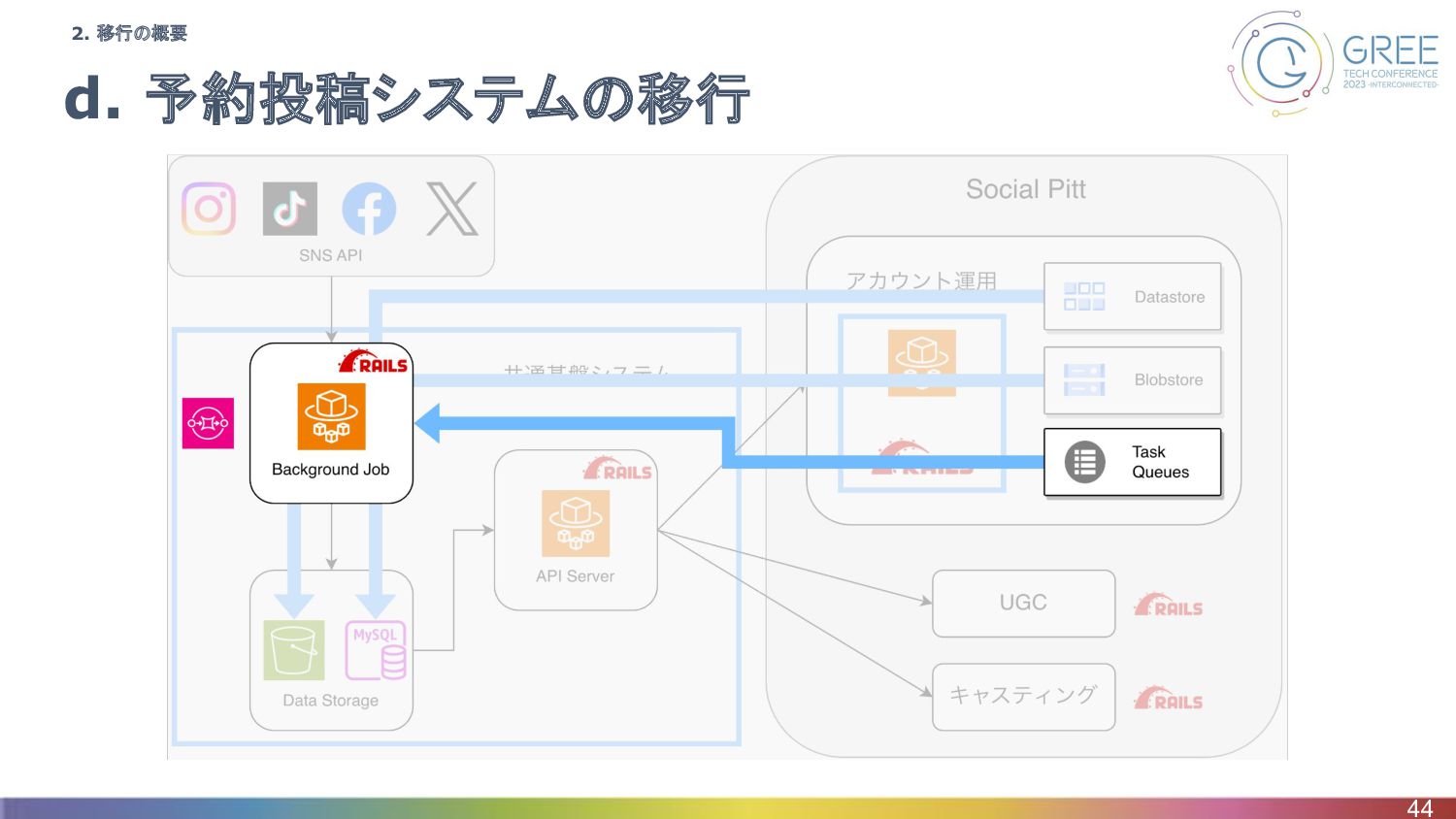
d. 予約投稿システムの移行 18 2. 移行の概要
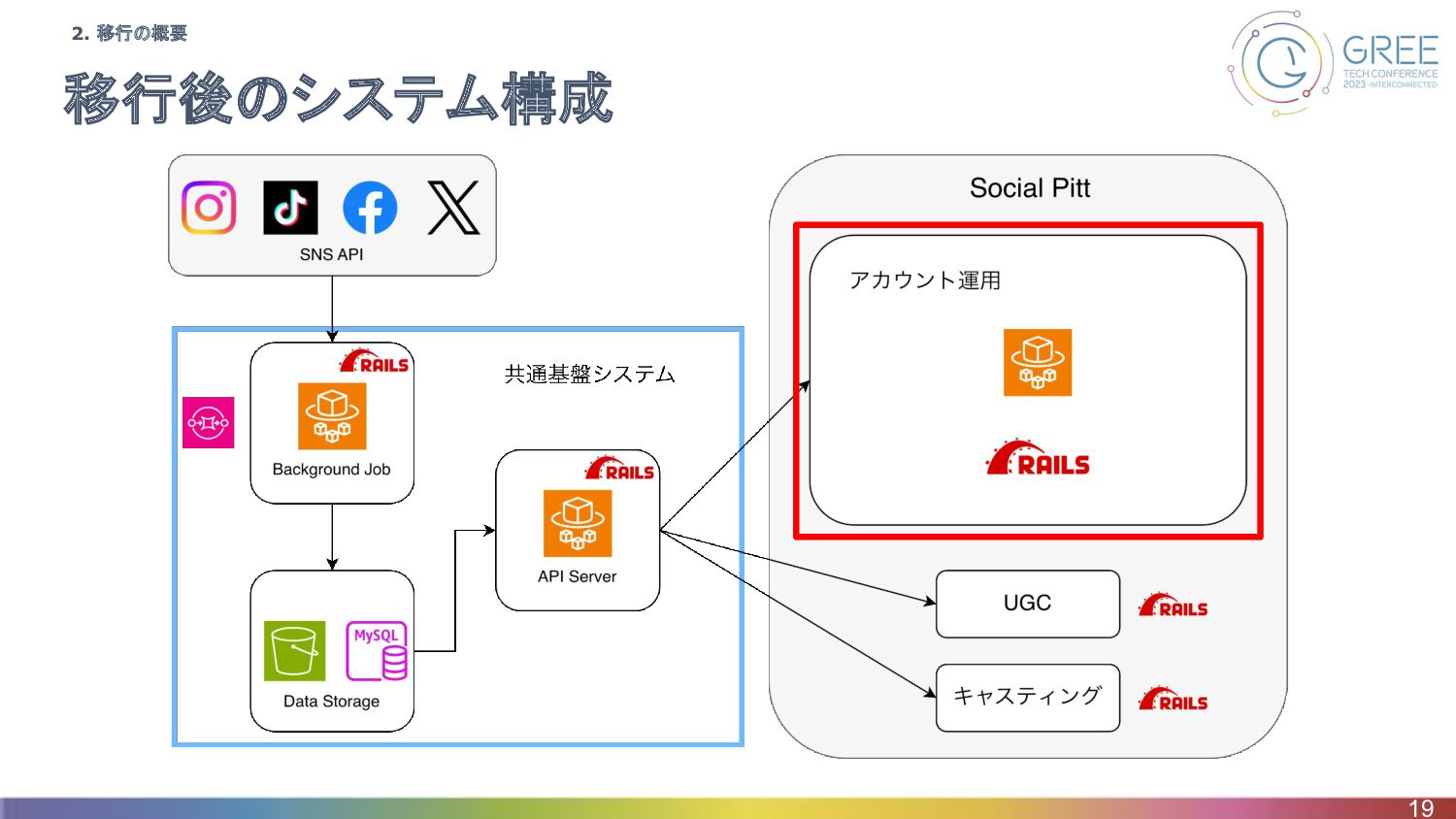
移行後のシステム構成 19 2. 移行の概要
どのような移行か 20 • 小規模プロダクトの短期移行 ◦ 期間 ▪ 2022/07〜2022/10の3ヶ月 ◦ 規模
▪ テーブル数は10個程度でデータ量も大きくない ▪ 画像・動画データは少し大きめ(数 TB程度) ◦ 移行方法 ▪ 一回の夜間メンテナンスで完全切替 • 夜中はユーザーアクセスがほぼないサービス • DBを載せ替えるため、部分的な移行や同時稼働での移行は困難 • データ量を計算し短時間で終わるような移行手順が必要 2. 移行の概要
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 21
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 22
a. アプリケーションの移行 23 2. 移行の概要
移行の方針 • Python2からRubyへコードをスクラッチから書き直し ◦ なぜ? ▪ 移行するPython2のコード部分が少なめ ▪ Python3化の話もあったが、Python2からPython3への移行とバンドルサービス からの移行で結局コードの変更量が大きい
▪ Social Pittの他のサービスではRuby on Railsを利用 • フロントエンドのコードは手を加えず移行 24 3-a. アプリケーションの移行
実際の移行と検証 • 仕様をよく知るエンジニアが大まかな移行のコードを作成 ◦ モデルはRailsで書きやすい形にして移行 ▪ 変わるところはデータ移行でなんとかする ◦ テンプレートも移行(Jinja2 →
Slim) ◦ 細かい部分は複数人で検証しつつ移行 • 新旧の環境を同時稼働し検証・修正 ◦ データを入れ両環境を並べて比較 ◦ データも分離されているので更新系も検証可能 ◦ 検証と修正はかなり泥臭い手作業 25 3-a. アプリケーションの移行
(補足)モデルの移行例 26 3-a. アプリケーションの移行 Post(id: 1, body: "body", status: "posted",
account_id: 1) PostAttachment(id: 1, order: 1, post_id: 1) PostAttachment(id: 2, order: 2, post_id: 1) Account(id: 1, name: "name", network: "instagram") (Key(Post, "uid"), "name", "instagram", ["blobkey1", "blobkey2"], "body", "posted")
実際の移行と検証 • 仕様をよく知るエンジニアが大まかな移行のコードを作成 ◦ モデルはRailsで書きやすい形にして移行 ▪ 変わるところはデータ移行側でなんとかする ◦ テンプレートも移行(Jinja2 →
Slim) ◦ 細かい部分は複数人で検証しつつ移行 • 新旧の環境を同時稼働し検証・修正 ◦ データを入れ両環境を並べて比較 ◦ データも分離されているので更新系も検証可能 ◦ 検証と修正はかなり泥臭い手作業 27 3-a. アプリケーションの移行
まとめ • 良かった点 ◦ 少人数でスピーディーに移行を進めることができた ◦ 同時稼働でデータも分離されており、検証しながら移行できた • 難しかった点・改善点 ◦
仕様を深く知る人がいなかったらスクラッチからの開発は難しかった ◦ 自動テストをあまり充実させられなかった 28 3-a. アプリケーションの移行
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 29
b. データの移行 30 2. 移行の概要
移行の方針 • DatastoreからMySQLへの移行 ◦ なぜ? ▪ parentを多用した実質リレーショナルなモデル構造 ▪ Social Pittの他サービスではMySQLを利用
• Embulkを用いてデータを抽出・変換・出力 31 3-b. データの移行
Embulkとは? • Embulk is an Open-source Pluggable Bulk Data Loader
◦ 公式・有志のものを含めた豊富なプラグイン ▪ ストレージやデータベースに合わせてデータを加工できる ◦ 大量のデータを並列に処理できる ▪ Local Executor Plugin ◦ 型の推論と型の変換 ◦ yaml形式でデータ移行をシンプルに記述可能 32 3-b. データの移行
利用したEmbulkのプラグイン例 • input(抽出) ◦ Datastoreがレガシーなため、ちょうど良いプラグインがなかった ◦ embulk-input-datastoreを参考にしつつプラグインを作成 • filter(加工) ◦
embulk-mysql-plugin ▪ parentのキーを用いて親テーブルから idを取得 ▪ テーブルの作成順序を気をつける必要がある ◦ timestamp_format ▪ 様々な形式で保存されており ……それを統一 ◦ ruby_proc ▪ その他細かい変換 ▪ Rubyのprocで書けるならなんでもできる • output(出力) ◦ embulk-output-mysql 33 3-b. データの移行
34 in: type: datastore project_id: {{ env.GCP_PROJECT_ID }} json_keyfile: /key.json
gql: "select * from Account" 利用したEmbulkのプラグイン例 3-b. データの移行 • input(抽出) ◦ Datastoreがレガシーなため、ちょうど良いプラグインがなかった ◦ embulk-input-datastoreを参考にしつつプラグインを作成 • filter(加工) ◦ embulk-mysql-plugin ▪ parentのキーを用いて親テーブルから idを取得 ▪ テーブルの作成順序を気をつける必要がある ◦ timestamp_format ▪ 様々な形式で保存されており ……それを統一 ◦ ruby_proc ▪ その他細かい変換 ▪ Rubyのprocで書けるならなんでもできる • output(出力) ◦ embulk-output-mysql
35 filter: - type: mysql user: {{ env.DB_USERNAME }} host:
{{ env.DB_HOST }} password: {{ env.DB_PASSWORD }} database: {{ env.DB_NAME }} keep_input: true query: | select id as customer_id from customers where uid = ? params: - customer.id - type: timestamp_format default_from_timestamp_format: - "%Y-%m-%dT%H:%M:%S.%N%z" - "%Y-%m-%dT%H:%M:%S%z" - "%Y-%m-%d %H:%M:%S" columns: - name: created_at - name: updated_at - type: ruby_proc columns: - name: status proc: | ->(data) do status = { foo: 1, bar: 2, baz: 3 } status[data.to_sym] || 0 end 利用したEmbulkのプラグイン例 3-b. データの移行 • input(抽出) ◦ Datastoreがレガシーなため、ちょうど良いプラグインがなかった ◦ embulk-input-datastoreを参考にしつつプラグインを作成 • filter(加工) ◦ embulk-mysql-plugin ▪ parentのキーを用いて親テーブルから idを取得 ▪ テーブルの作成順序を気をつける必要がある ◦ timestamp_format ▪ 様々な形式で保存されており ……それを統一 ◦ ruby_proc ▪ その他細かい変換 ▪ Rubyのprocで書けるならなんでもできる • output(出力) ◦ embulk-output-mysql
36 output: type: mysql user: {{ env.DB_USERNAME }} host: {{
env.DB_HOST }} password: { { env.DB_PASSWORD }} database: {{ env.DB_NAME }} table: accounts driver_path: /mysql-connector-java-5.1.49/mysql-connector-java-5.1.49.jar mode: truncate_insert options: { tinyInt1isBit: false, useUnicode: true, characterEncoding: UTF-8 } create_table_option: DEFAULT CHARSET=utf8mb4 利用したEmbulkのプラグイン例 3-b. データの移行 • input(抽出) ◦ Datastoreがレガシーなため、ちょうど良いプラグインがなかった ◦ embulk-input-datastoreを参考にしつつプラグインを作成 • filter(加工) ◦ embulk-mysql-plugin ▪ parentのキーを用いて親テーブルから idを取得 ▪ テーブルの作成順序を気をつける必要がある ◦ timestamp_format ▪ 様々な形式で保存されており ……それを統一 ◦ ruby_proc ▪ その他細かい変換 ▪ Rubyのprocで書けるならなんでもできる • output(出力) ◦ embulk-output-mysql
• 良かった点 ◦ DatastoreからMySQLへのデータの抽出・加工・出力の流れが可視化される ◦ 並列化を勝手にやってくれる • 難しかった点・改善点 ◦ Datastoreのinputプラグインを自前で書くことになった
◦ Embulk (その頃のstable v0.9.24) のConnector/Jのバージョンが古かった ▪ utf-8のオプションを指定するとutf8mb3になっていた ▪ https://github.com/embulk/embulk-output-jdbc/issues/306 ◦ ruby_procを利用した処理が多いならRuby側でワーカー作っても良かった ▪ モデルのバリデーションをそのタイミングで確認できる 37 まとめ 3-b. データの移行
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 38
c. 画像・動画データの移行 39 2. 移行の概要
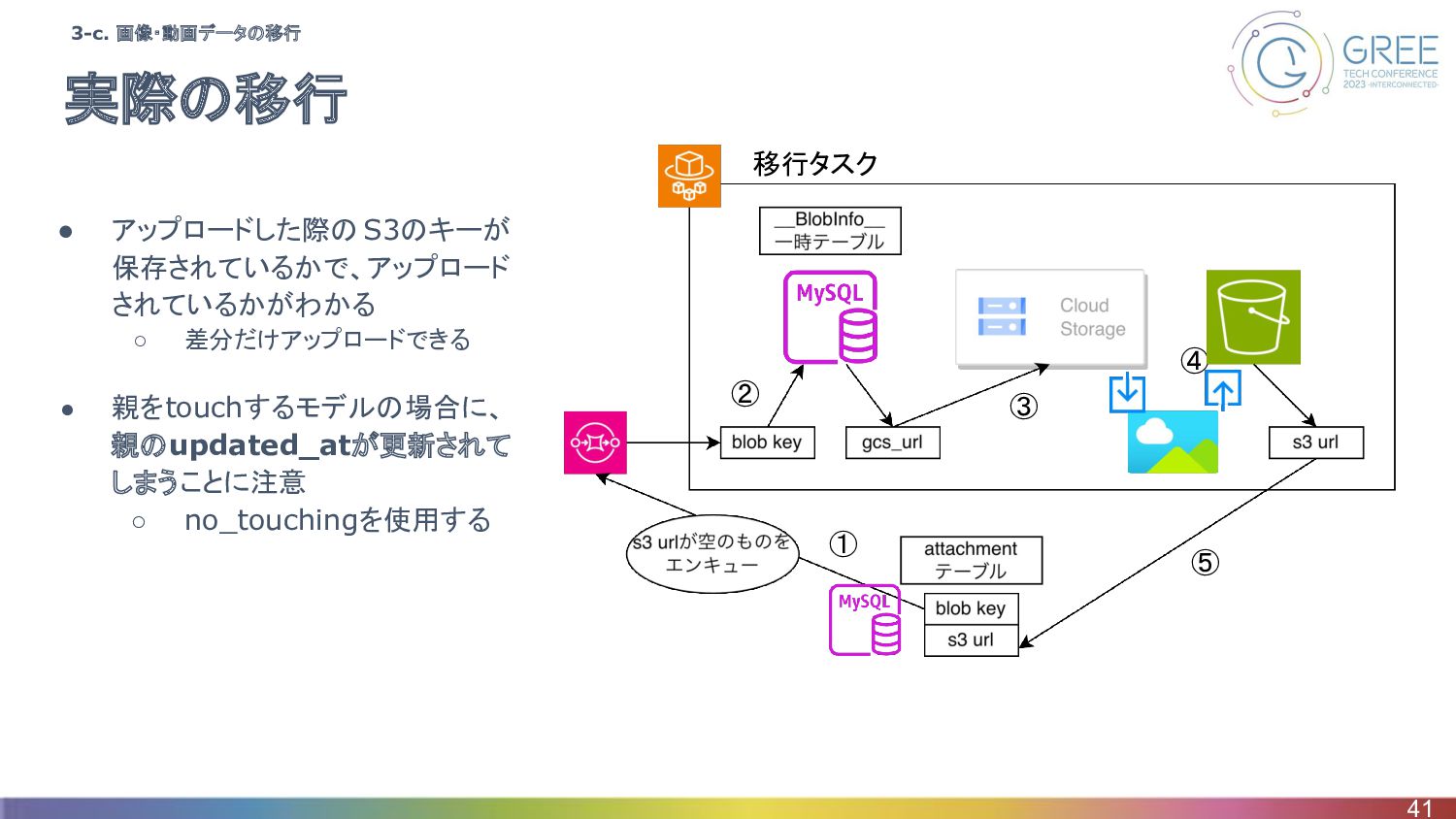
移行の方針 • BlobstoreからS3への移行 ◦ Blobstore APIを通してGCSにデータをアップロードしていた ▪ Datastoreの__BlobInfo__というテーブルにgcs_urlが保存されている ▪ 実質はGoogle
Cloud StorageからS3へのデータ移行 ◦ __BlobInfo__を一時的に保存し、アプリケーション側で GCSダウンロード、S3アップロードするワーカータスクを作成 40 Blobstore • GCSよりも古くから存在していて、現在は deprecated • Blobkeyと呼ばれるキーでblobを保存 • blobの保存先としてBlobstoreかGCSが選べる 3-c. 画像・動画データの移行
実際の移行 • アップロードした際の S3のキーが 保存されているかで、アップロード されているかがわかる ◦ 差分だけアップロードできる • 親をtouchするモデルの場合に、
親のupdated_atが更新されて しまうことに注意 ◦ no_touchingを使用する 41 3-c. 画像・動画データの移行 移行タスク ① ② ③ ④ ⑤
まとめ • 良かった点 ◦ 並列で実行できるようにしたことで移行時間を短縮 ◦ アプリケーション側でのアップロード処理 ▪ 画像のリサイズや変換などのロジックを通すことができた ▪
移行タスクのテストが書きやすかった ◦ 既存のワーカーシステムで稼働させることで、意識せずともリトライされる • 難しかった点 ◦ BlobstoreがGCSへのキーをどのように保存をしているかの理解 ▪ Blobstoreの情報も少なく難しかった ▪ Blobstoreのclient libraryのコードを見ることで理解が深まった ◦ carrierwaveで使われているssrf_filterのバグ ▪ net-httpのバージョンが新しく、ssrf_filter側のパッチが壊れたことが原因 ▪ https://github.com/arkadiyt/ssrf_filter/issues/53 42 3-c. 画像・動画データの移行
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 43
d. 予約投稿システムの移行 44 2. 移行の概要
まとめ • 移行後のシステムはDXブログ参照 ◦ https://tech.ddm.biz/entry/2023/01/12/172249 • 概要 ◦ DBに投稿予約の情報は入っており、移行自体は簡単 ◦
新しいシステムを稼働し、古いシステムはそのタイミングで停止 ▪ 夜間メンテナンス中の投稿予約はない ▪ 古い方を止めれば二重投稿は起きない 45 3-d. 予約投稿システムの移行
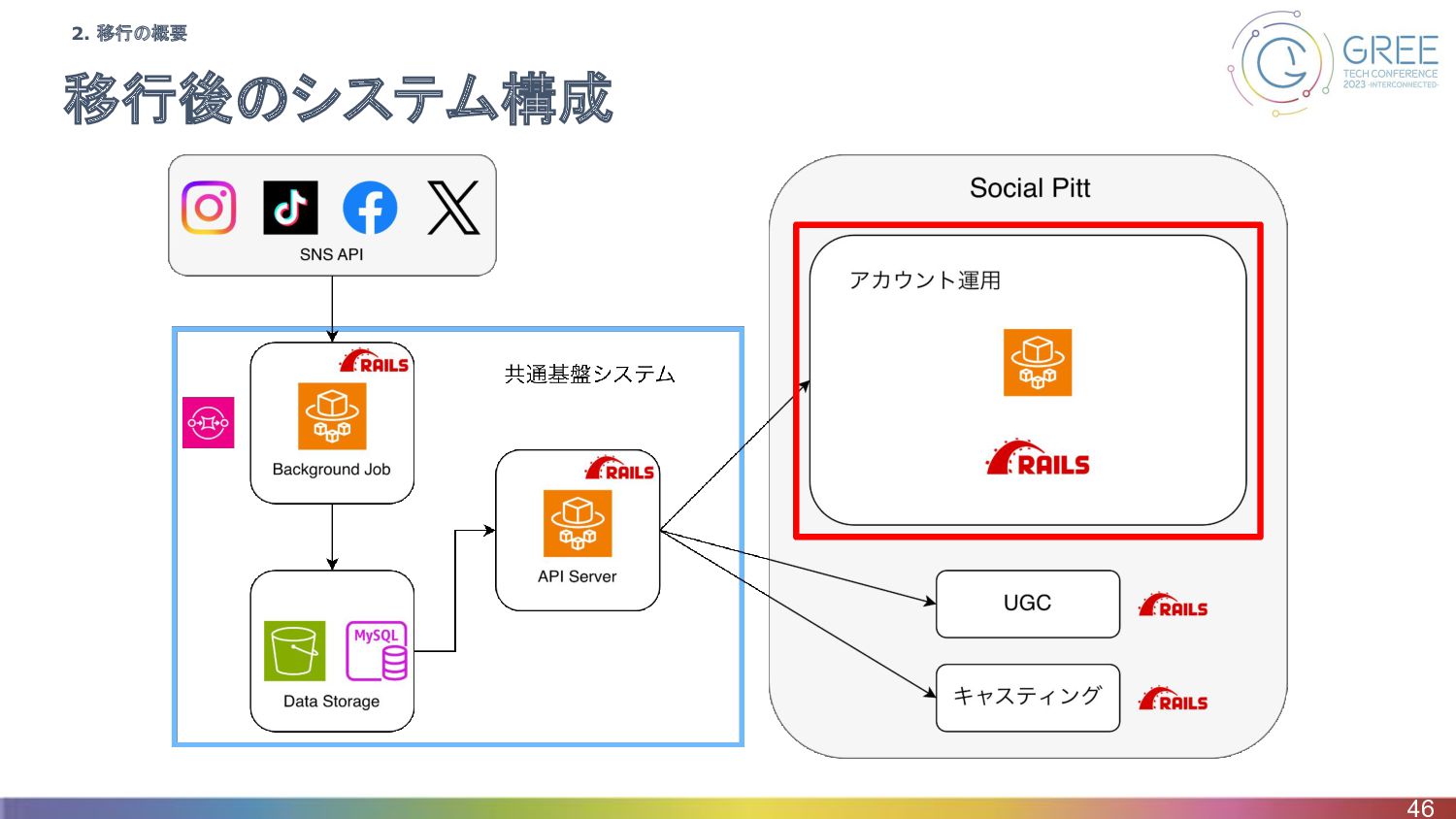
移行後のシステム構成 46 2. 移行の概要
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 47
移行作業手順(予定) • 予定では…… ◦ 事前作業 ▪ DNSのTTLを短くしておく ▪ DBのデータ、画像・動画データを前日分まで移行 ◦
当日作業 ▪ 00:05〜00:15:データの差分移行・確認 ▪ 00:15〜00:30:画像・動画の差分移行・確認 ▪ 00:30〜00:40:DNSの切り替え ▪ 00:40〜00:50:新予約投稿システムの起動・確認 ▪ 00:50〜01:00:Task Queueの停止・全体確認 48 4. 移行当日の手順
• 実際には…… ◦ 事前作業 ▪ DNSのTTLを短くしておく ▪ DBのデータ、画像・動画データを前日分まで移行 ◦ 当日作業
▪ 00:05〜00:15:データの差分移行・確認 ▪ 00:15〜03:45:画像・動画の差分移行 全体移行・確認 ▪ 03:45〜04:00:DNSの切り替え ▪ 04:00〜04:10:新予約投稿システムの起動・確認 ▪ 04:10〜04:20:Task Queueの停止・全体確認 49 移行作業手順(実際) 4. 移行当日の手順
• 画像・動画の移行タスクにおいて一部不具合があった ◦ 本番にしかない不整合なデータが保存されていた • 画像・動画のアップロードを全てやり直した ◦ メンテナンス時間中に間に合うなら移行を続行するという決定 ▪ 不具合を修正して再実行
◦ 画像移行タスクを100タスク並列で動かし、10倍くらいの速度で再実行 ▪ 4時間くらいかかるところを20分くらいで終わらせられた 50 移行中に生じた問題 4. 移行当日の手順
まとめ • 良かった点 ◦ 予定していた夜間メンテナンス時間中に移行完了できた ◦ 画像・動画移行タスクを並列化できるようにしておいたことで、生じた問題に対 してもなんとかリカバリできた • 反省点
◦ 本番データにしかない不整合データの検証ができていなかった 51 4. 移行当日の手順
目次 1. Social Pittの紹介 2. 移行の概要 3. 移行の内容 a. アプリケーションの移行
b. データの移行 c. 画像・動画データの移行 d. 予約投稿システムの移行 4. 移行当日の手順 5. 移行してみて 52
目的と結果 53 • 移行の目的 ◦ Python2はとっくにdeprecatedで脱却したい ◦ サービス拡大に向けて、開発しやすい環境を整える ◦ 予約投稿システムを強化し、社内の運用効率も向上させる
5. 移行してみて
目的と結果 54 • 移行の目的 ◦ Python2はとっくにdeprecatedで脱却したい → Ruby3系、Rails7系に ◦ サービス拡大に向けて、開発しやすい環境を整える
→ 移行によってSocial Pittチームの他のエンジニアもレビューや開発がで きるようになり、移行からの一年で様々な機能開発や改善 ◦ 予約投稿システムを強化し、社内の運用効率も向上させる → SNS運用チームの業務時間を60時間/月削減 5. 移行してみて
まとめと感想 55 • まとめ ◦ アプリケーション移行はスクラッチからRubyで書き直し ▪ インフラやデータごと別に環境を作ることで検証がしやすい ◦ データ移行はEmbulkを利用
▪ Embulkを用いたデータ移行はベストな選択だったかはわからない ◦ 画像・動画データ移行はワーカータスクを作成 ▪ 並列化できたことで移行時間を短縮できた • 感想 ◦ 社内のSNS運用の業務効率化に貢献できて良かった ◦ サービスのパフォーマンスも大幅に向上して良かった ◦ Railsで統一されたことはチーム開発の上で大きかった 5. 移行してみて
56
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}