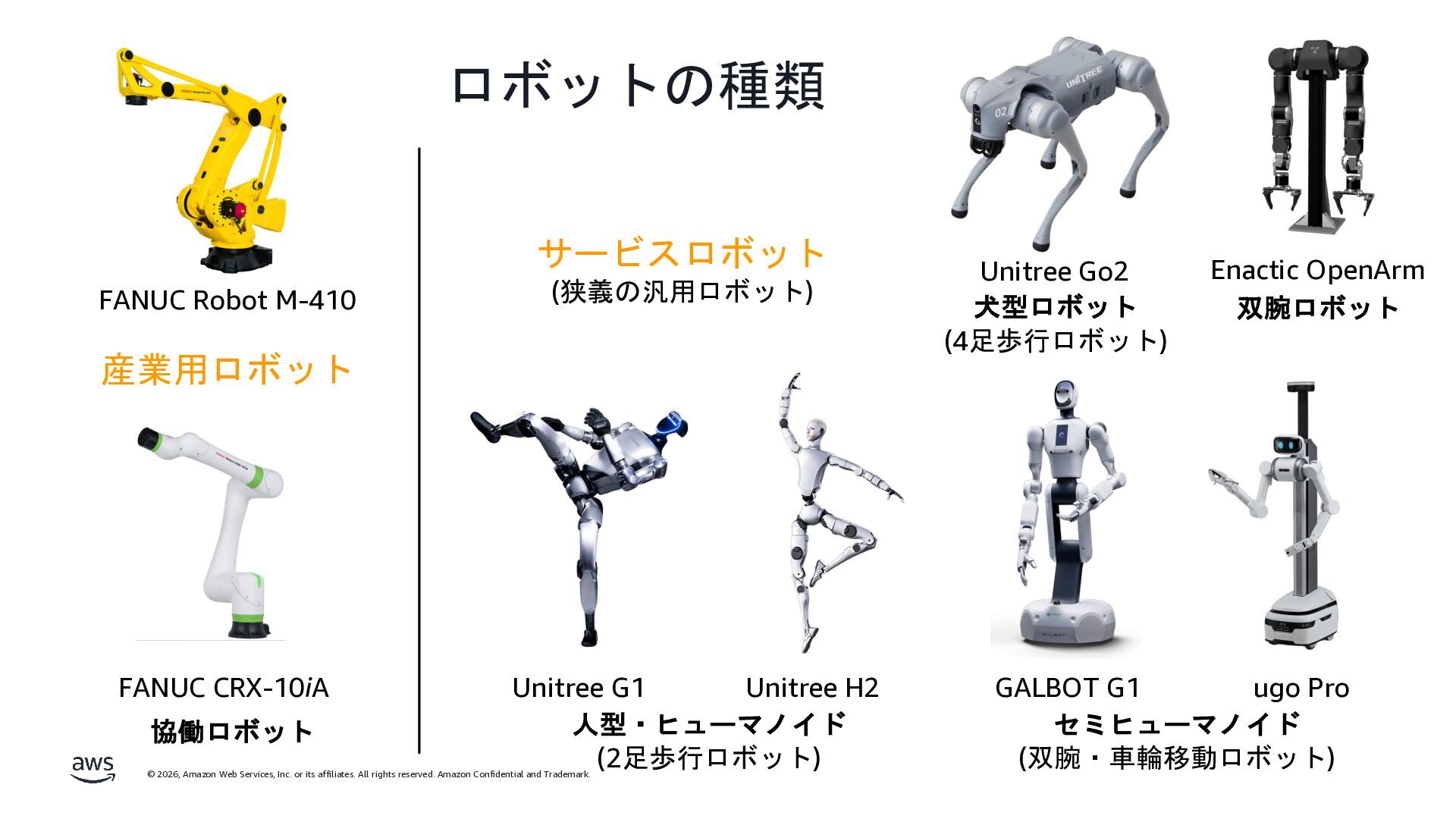
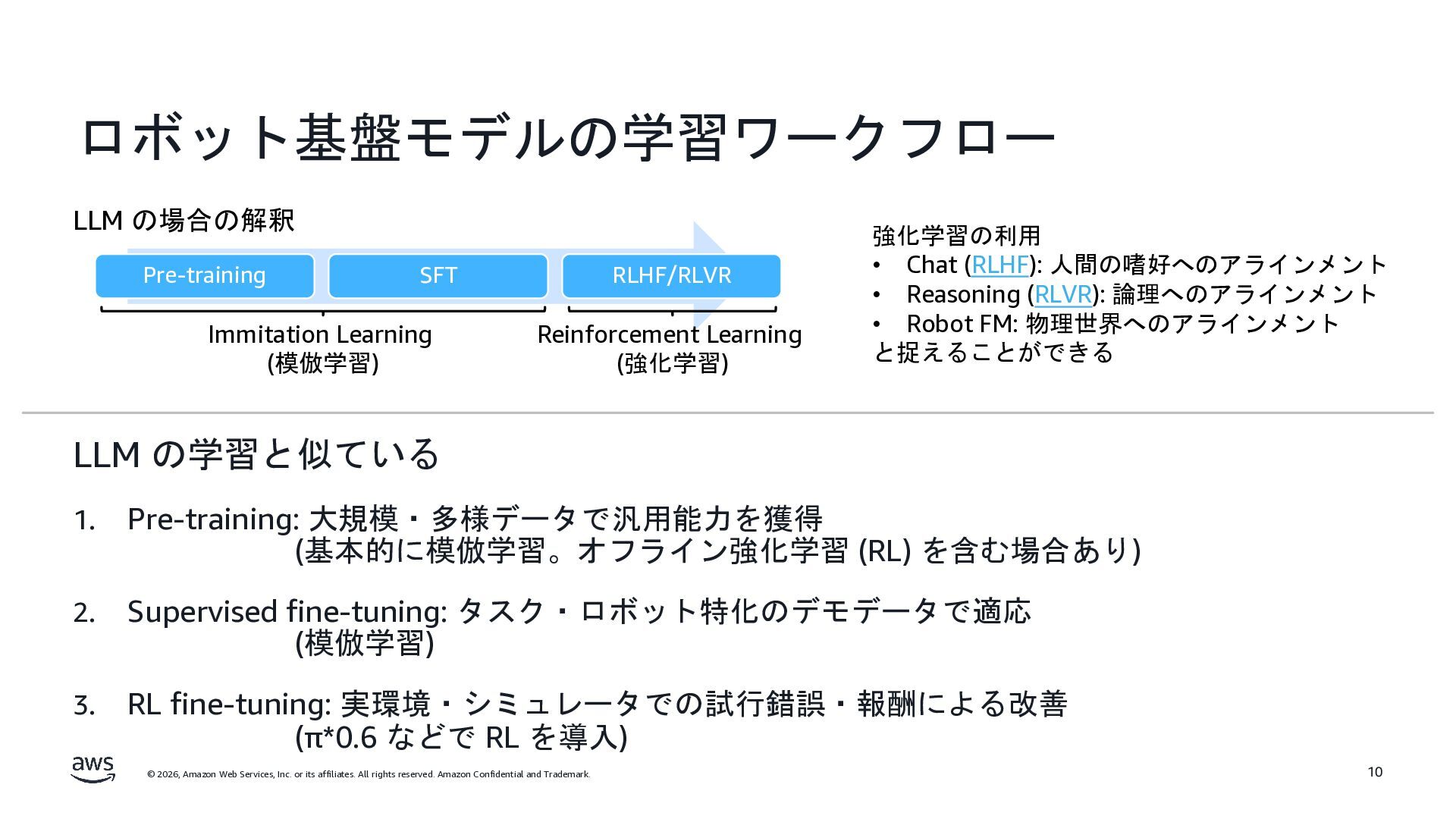
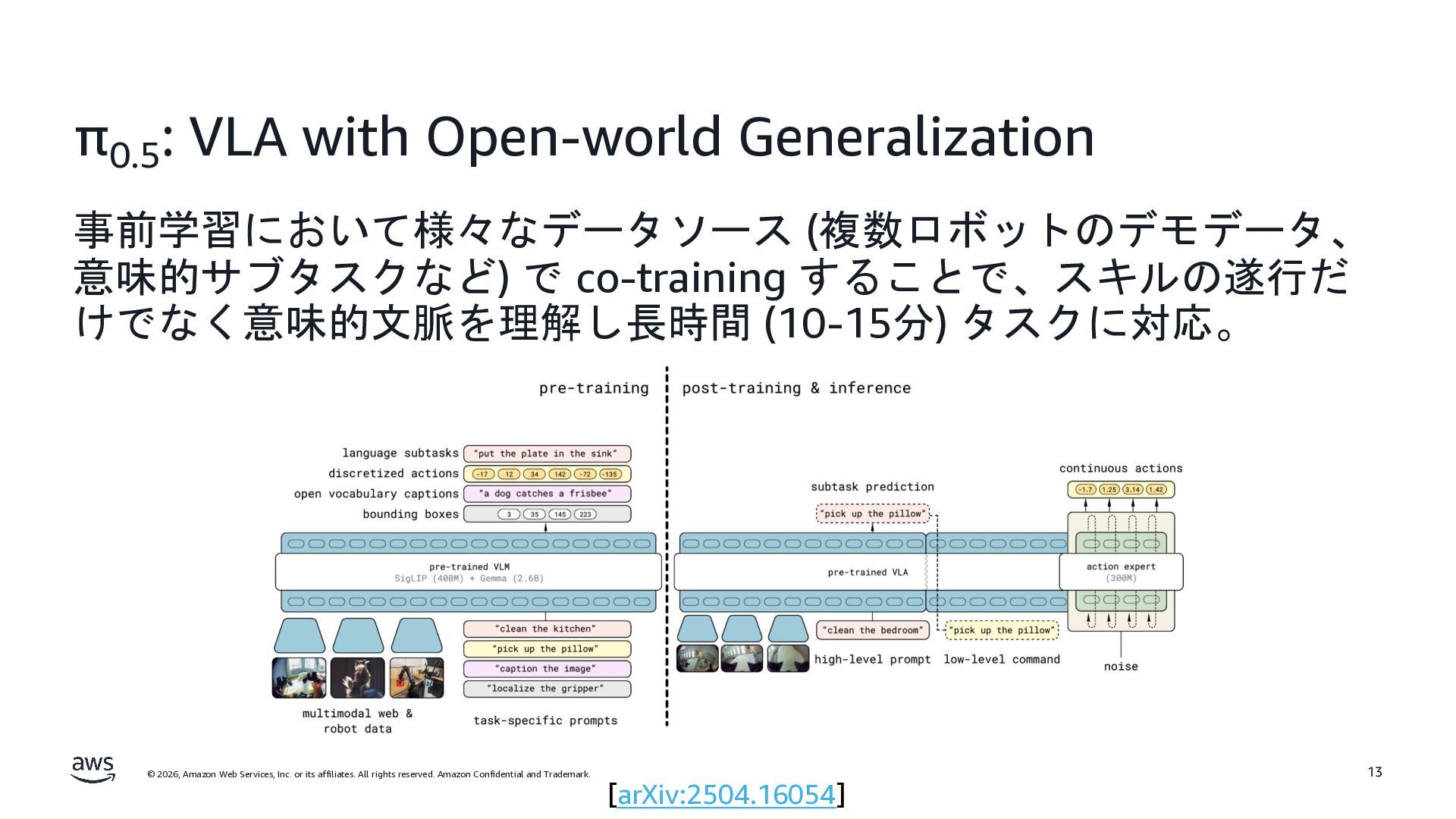
rights reserved. Amazon Confidential and Trademark. LLM から VLA へ Action Expert LLM LLM Large Language Model (LLM) Text Text Action 🦾 Vision Encoder LLM Text Image/Video Text Vision-Language Model (VLM) Vision-Language-Action Model (VLA) Vision Encoder Text Image/Video π0 [arXiv:2410.24164] Note: バックボーンに VLM ではなく、 動画基盤モデルや世界モデルを使う流れもある。 Backbone
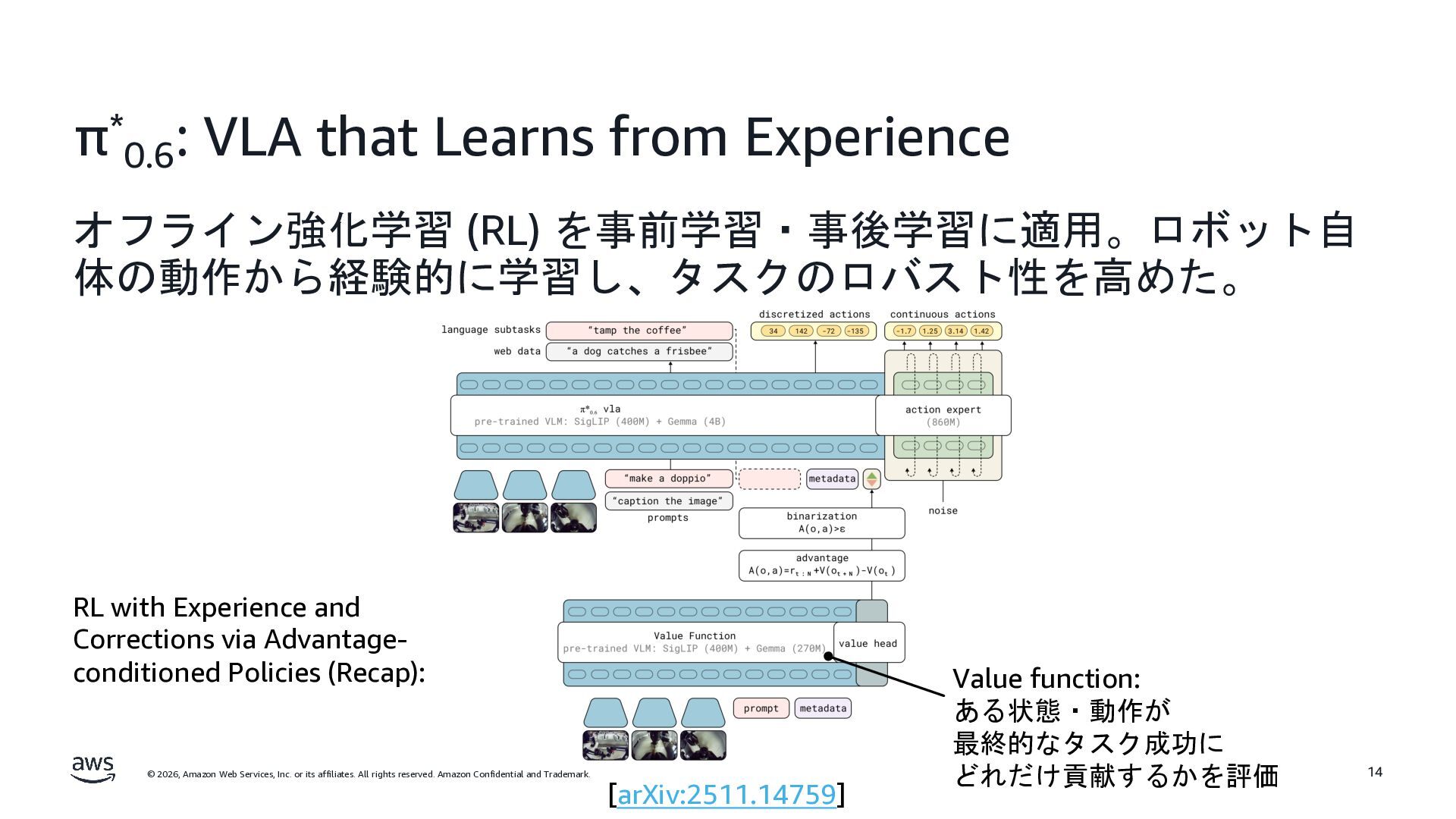
rights reserved. Amazon Confidential and Trademark. π* 0.6 : VLA that Learns from Experience オフライン強化学習 (RL) を事前学習・事後学習に適用。ロボット自 体の動作から経験的に学習し、タスクのロバスト性を高めた。 14 Value function: ある状態・動作が 最終的なタスク成功に どれだけ貢献するかを評価 [arXiv:2511.14759] RL with Experience and Corrections via Advantage- conditioned Policies (Recap):
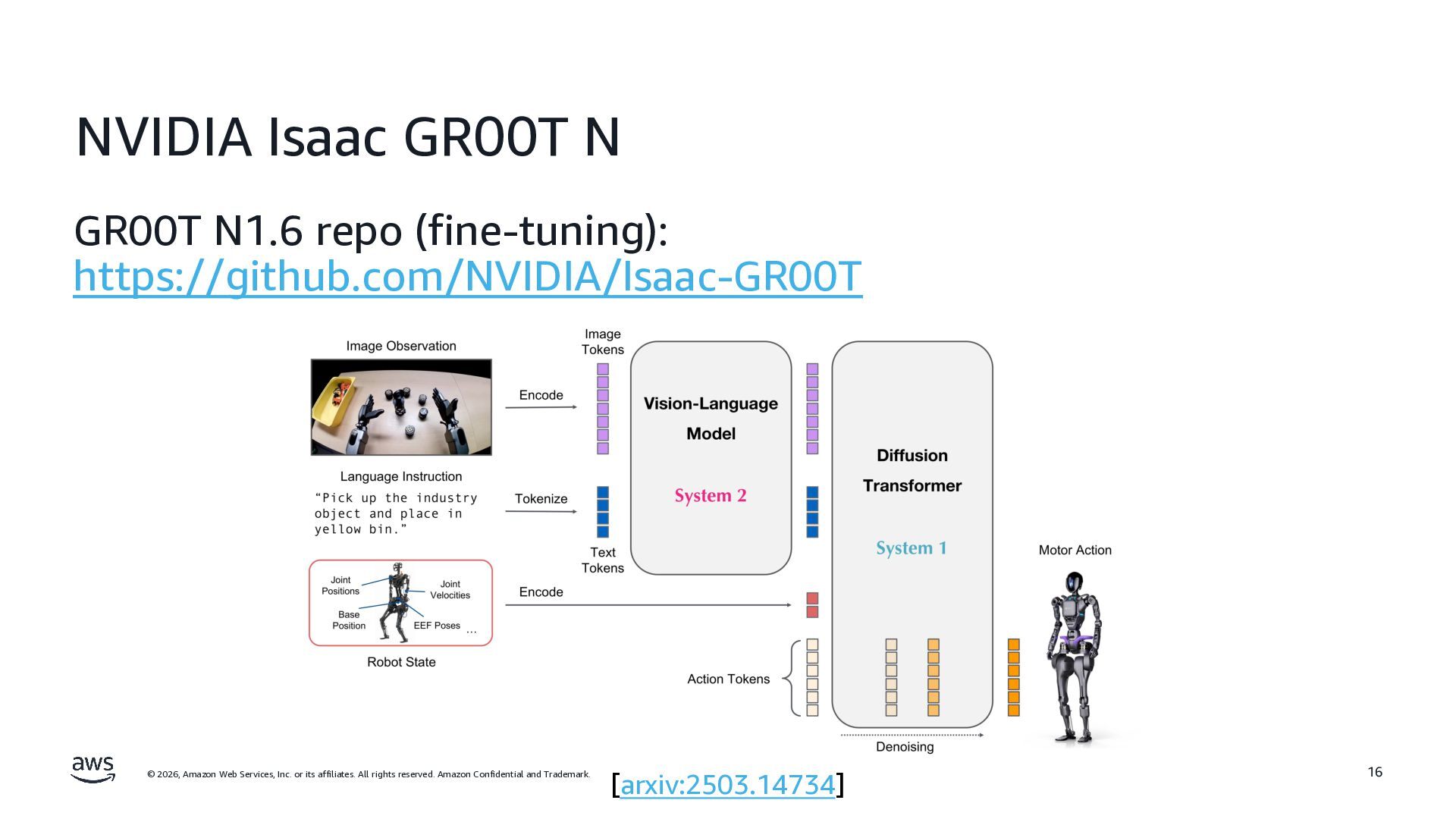
rights reserved. Amazon Confidential and Trademark. NVIDIA Isaac GR00T N GR00T N1.6 repo (fine-tuning): https://github.com/NVIDIA/Isaac-GR00T 16 [arxiv:2503.14734]
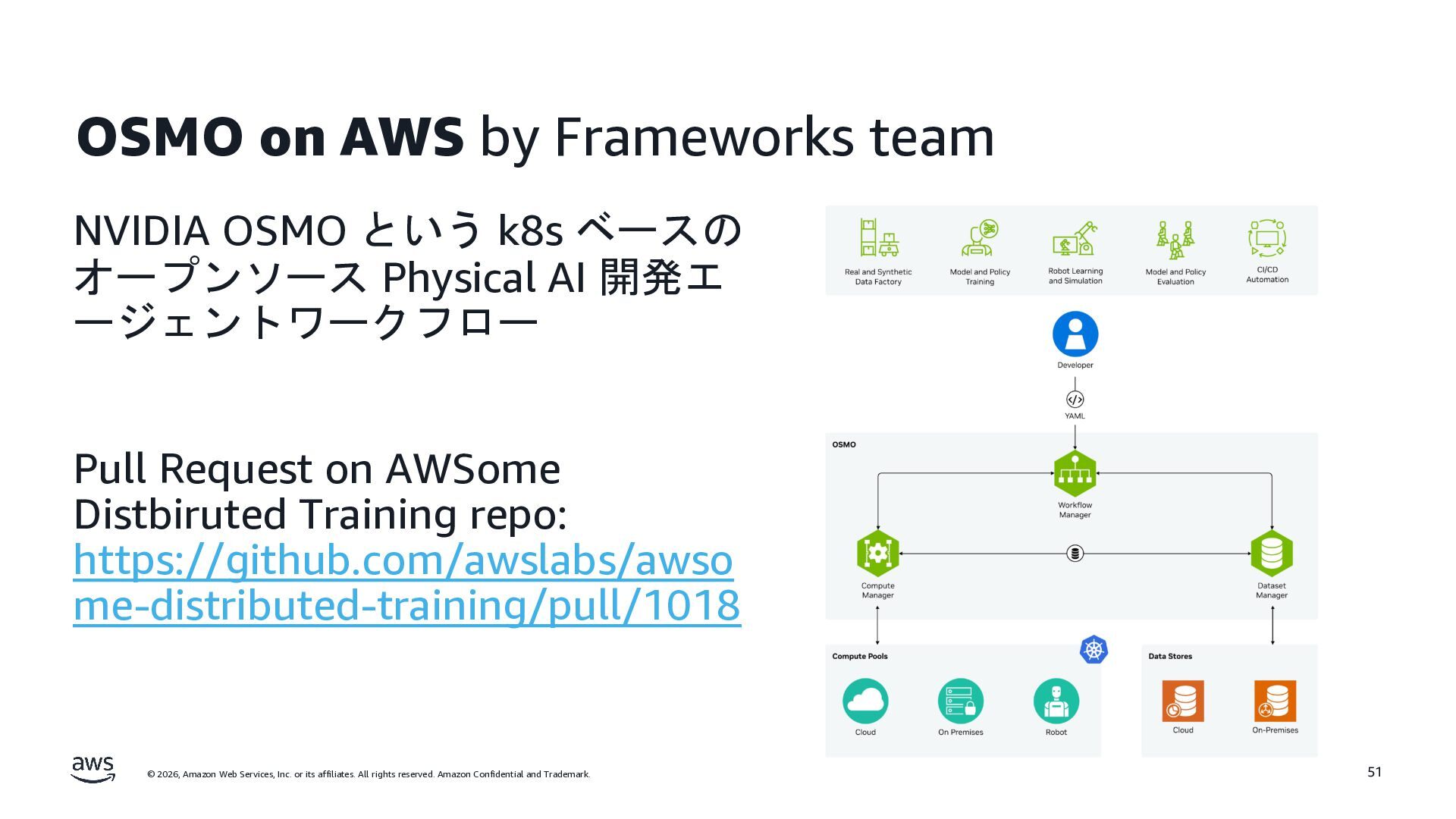
rights reserved. Amazon Confidential and Trademark. OSMO on AWS by Frameworks team NVIDIA OSMO という k8s ベースの オープンソース Physical AI 開発エ ージェントワークフロー Pull Request on AWSome Distbiruted Training repo: https://github.com/awslabs/awso me-distributed-training/pull/1018 51
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}