タイトル: Amazon SageMaker と NVIDIA で効率の良い生成 AI 開発
概要:
AWS 上で NVIDIA NeMo や NIM を使った効率の良いモデル学習・推論を行うために関連する Amazon SageMaker AI などのサービスを紹介します。
====
イベントタイトル: NVIDIA × AWS Presents: AI モデル開発最前線 ─ 「NVIDIA NeMo」「NVIDIA NIM」やAWSを活用してAI学習効率を最大化!
イベント概要:
本イベントは、最新の AI モデル開発環境と学習効率の最適化をテーマにしたイベントです。
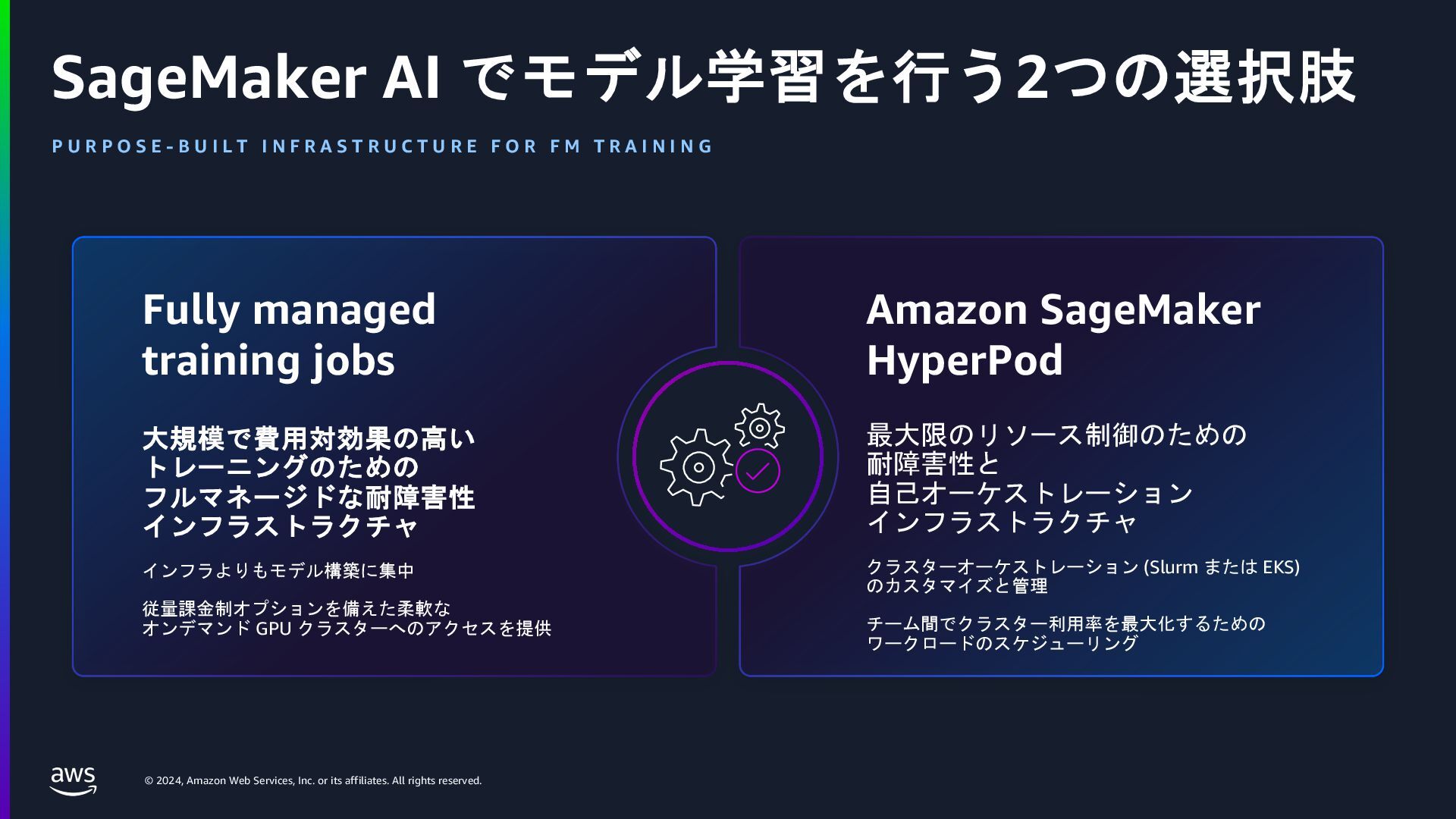
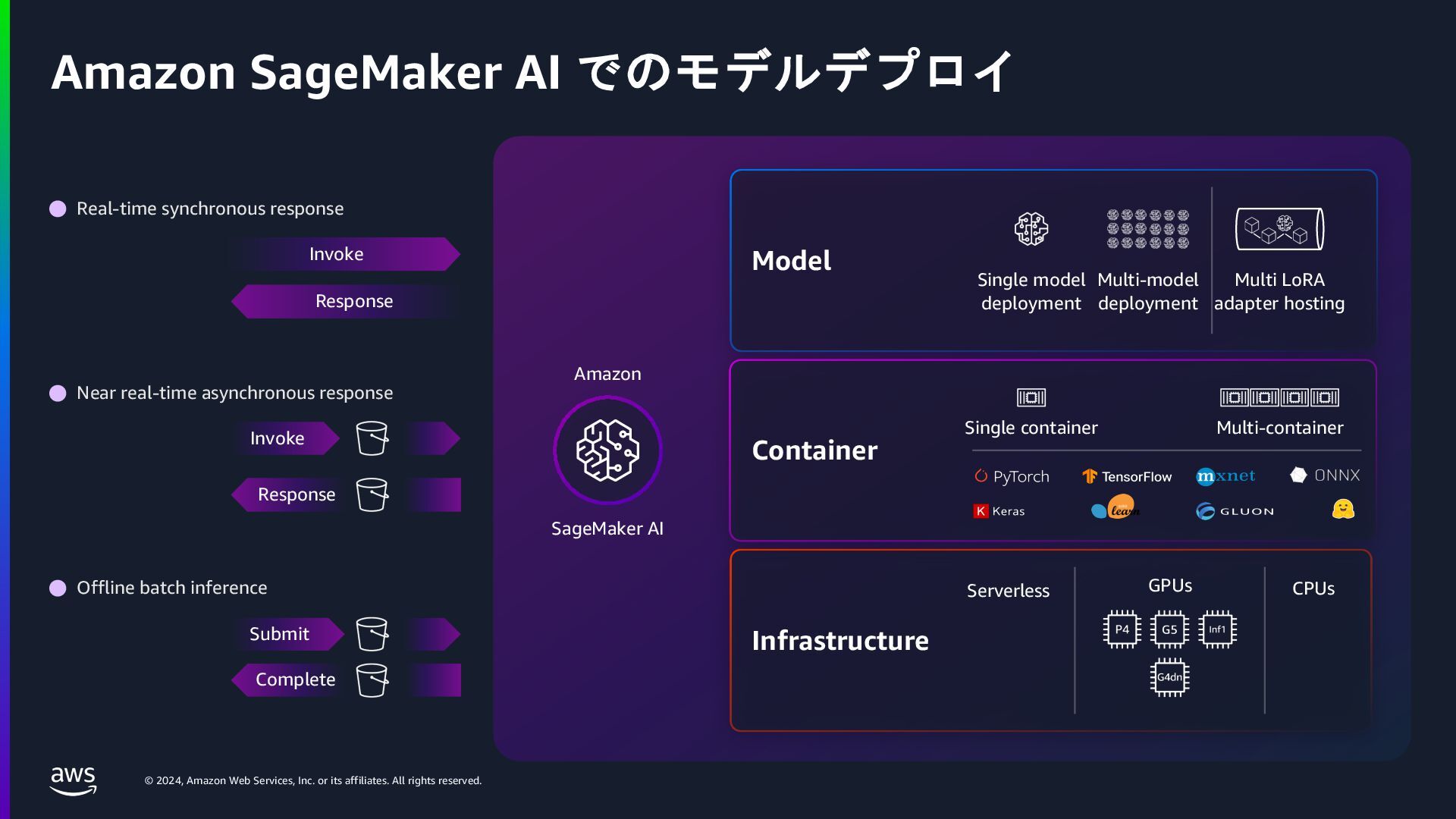
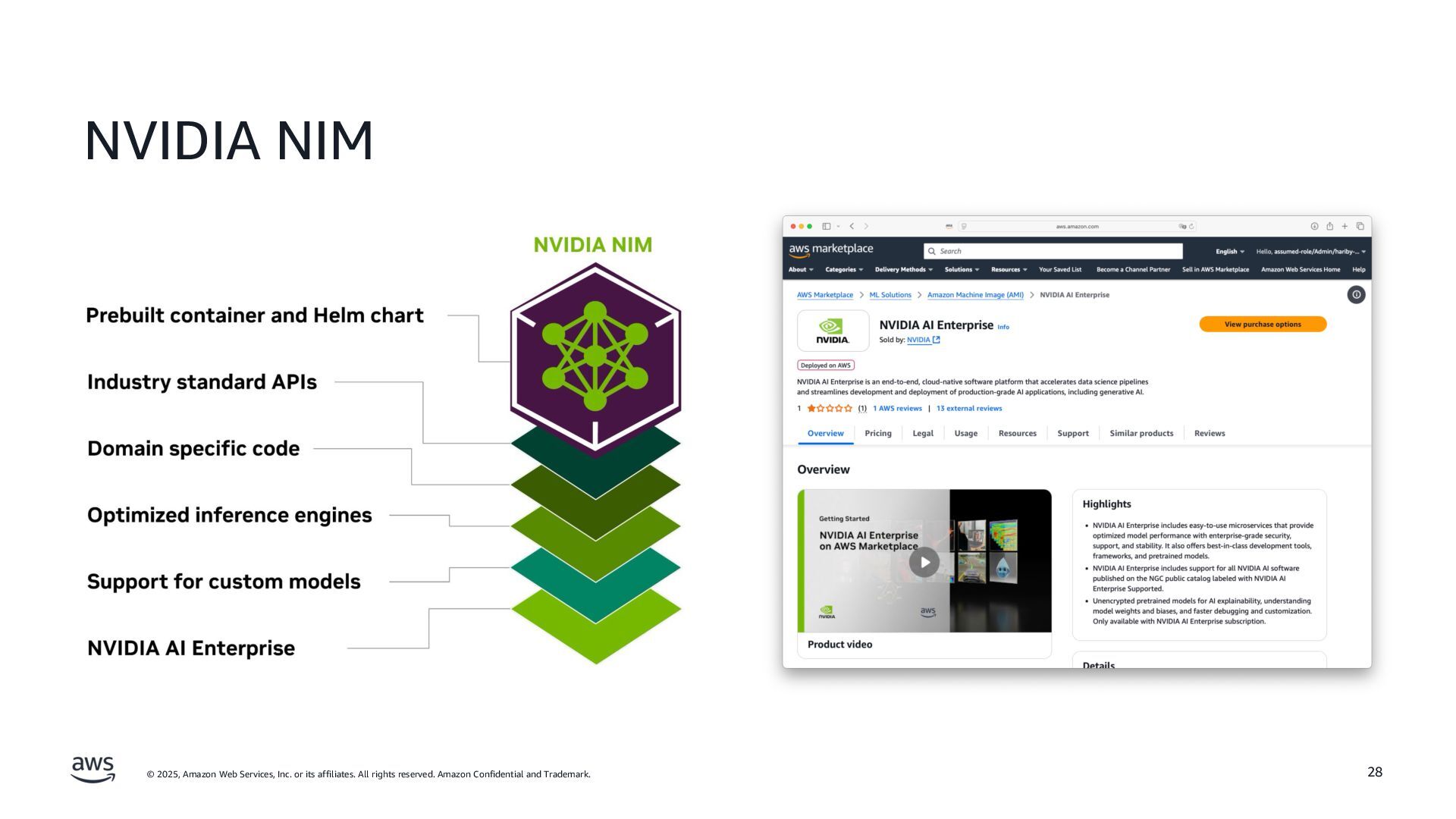
AWS からは Amazon SageMaker AI などのサービスを活用した効率的な生成AI開発について、NVIDIAからは最新の AI モデルやアプリケーションの構築を加速する「NVIDIA NeMo」と「NVIDIA NIM」の機能や利点について解説が行われます。
実践的な事例として、Stockmark 社より、AWS 上の開発環境でも活用できる NVIDIA NeMo を用いたモデル開発と精度改善について、NeMo Aligner や Reranker などのツールの具体的な活用方法が紹介されます。
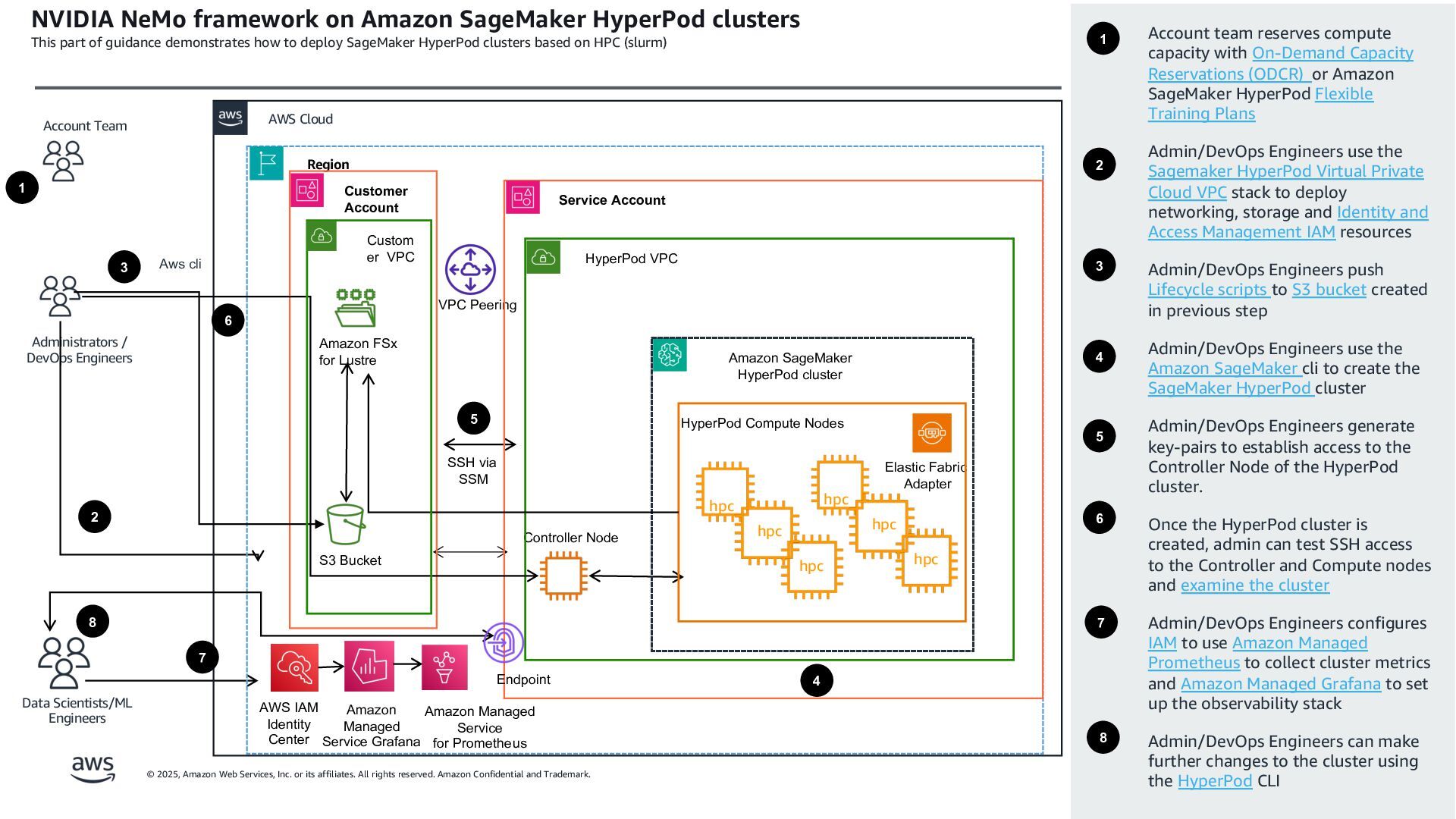
さらに、Turing からは自動運転AI開発における実践的な取り組みとして、GPU リソースの最適化やハイブリッド環境の設計、特にマルチモーダル基盤モデル開発のための GPU 計算環境構築について、オンプレとクラウドの比較を交えた紹介が予定されています。
セッション後には懇親会も設けられ、参加者間での情報交換の機会も提供されます。AI 開発者にとって、最新技術動向と実践的なノウハウを学べる貴重な機会となっています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}