Li. “Learning from Logged Implicit Exploration Data.” NeurIPS, 2010. https://arxiv.org/abs/1003.0120 [Swamminathan+,17] Adith Swaminathan, Akshay Krishnamurthy, Alekh Agarwal, Miroslav Dudík, John Langford, Damien Jose, Imed Zitouni. “Off-policy evaluation for slate recommendation.” NeurIPS, 2017. https://arxiv.org/abs/1605.04812 [Beygelzimer&Langford,09] Alina Beygelzimer, John Langford. “The Offset Tree for Learning with Partial Labels.” KDD, 2009. https://arxiv.org/abs/0812.4044 [Saito&Joachims,22] Yuta Saito, Thorsten Joachims. “Off-Policy Evaluation for Large Action Spaces via Embeddings.” ICML, 2022. https://arxiv.org/abs/2202.06317 [Dudík+,14] Miroslav Dudík, Dumitru Erhan, John Langford, and Lihong Li. “Doubly Robust Policy Evaluation and Optimization.” ICML, 2011. https://arxiv.org/abs/1503.02834 April 2024 OPE for slate bandits with abstraction @ WWW2024 37
{kind=link}
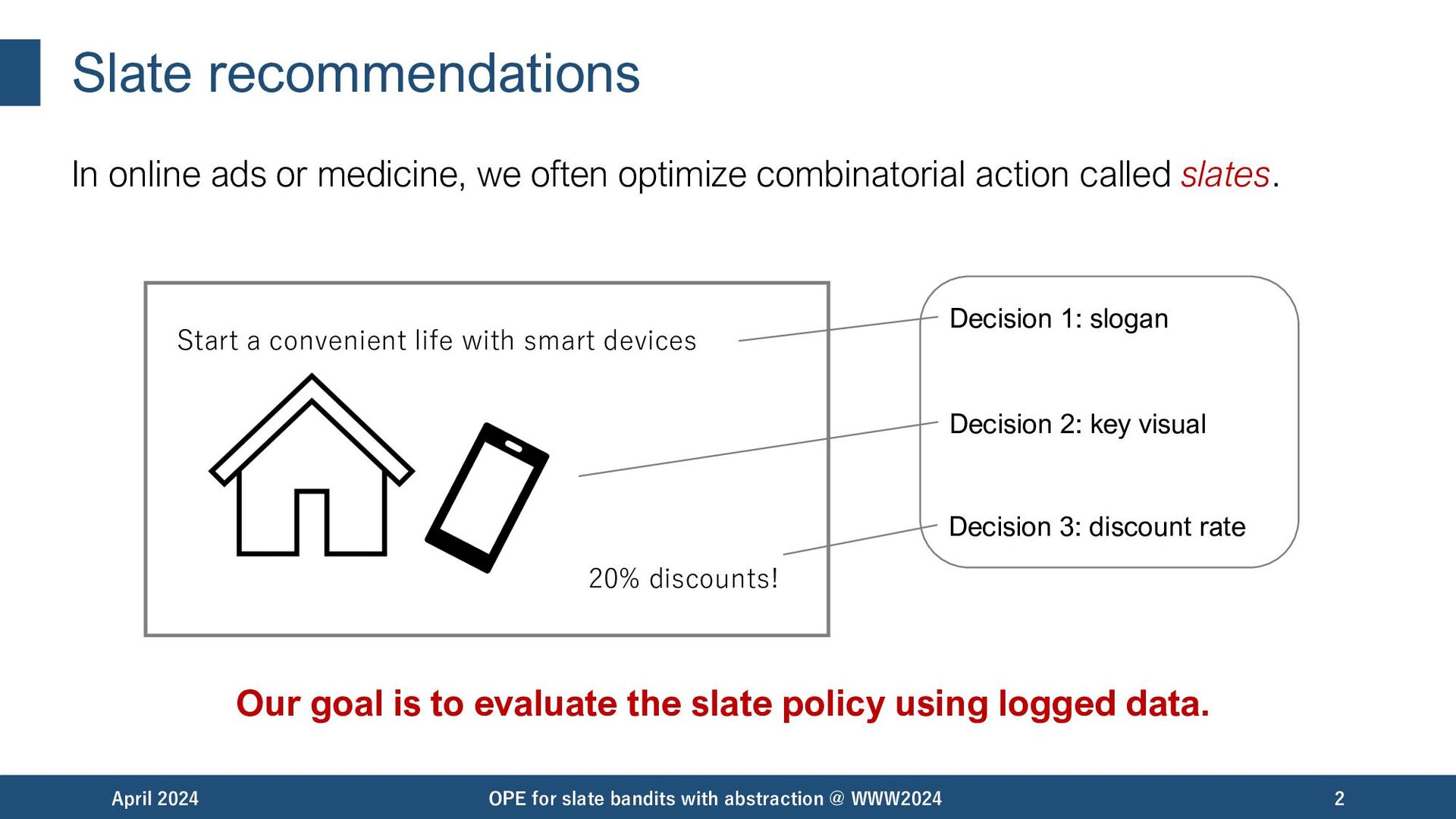{kind=link}
{kind=link}
{kind=link}
![Distribution shift and importance sampling [Strehl+,10] Because 𝜋0 and 𝜋](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_4.jpg){kind=link}
![Distribution shift and importance sampling [Strehl+,10] Because 𝜋0 and 𝜋](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_5.jpg){kind=link}
![Distribution shift and importance sampling [Strehl+,10] Because 𝜋0 and 𝜋](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_6.jpg){kind=link}
![Linearity assum. and PseudoInverse (PI) [Swamminathan+,17] To deal with the](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_7.jpg){kind=link}
![Linearity assum. and PseudoInverse (PI) [Swamminathan+,17] To deal with the](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
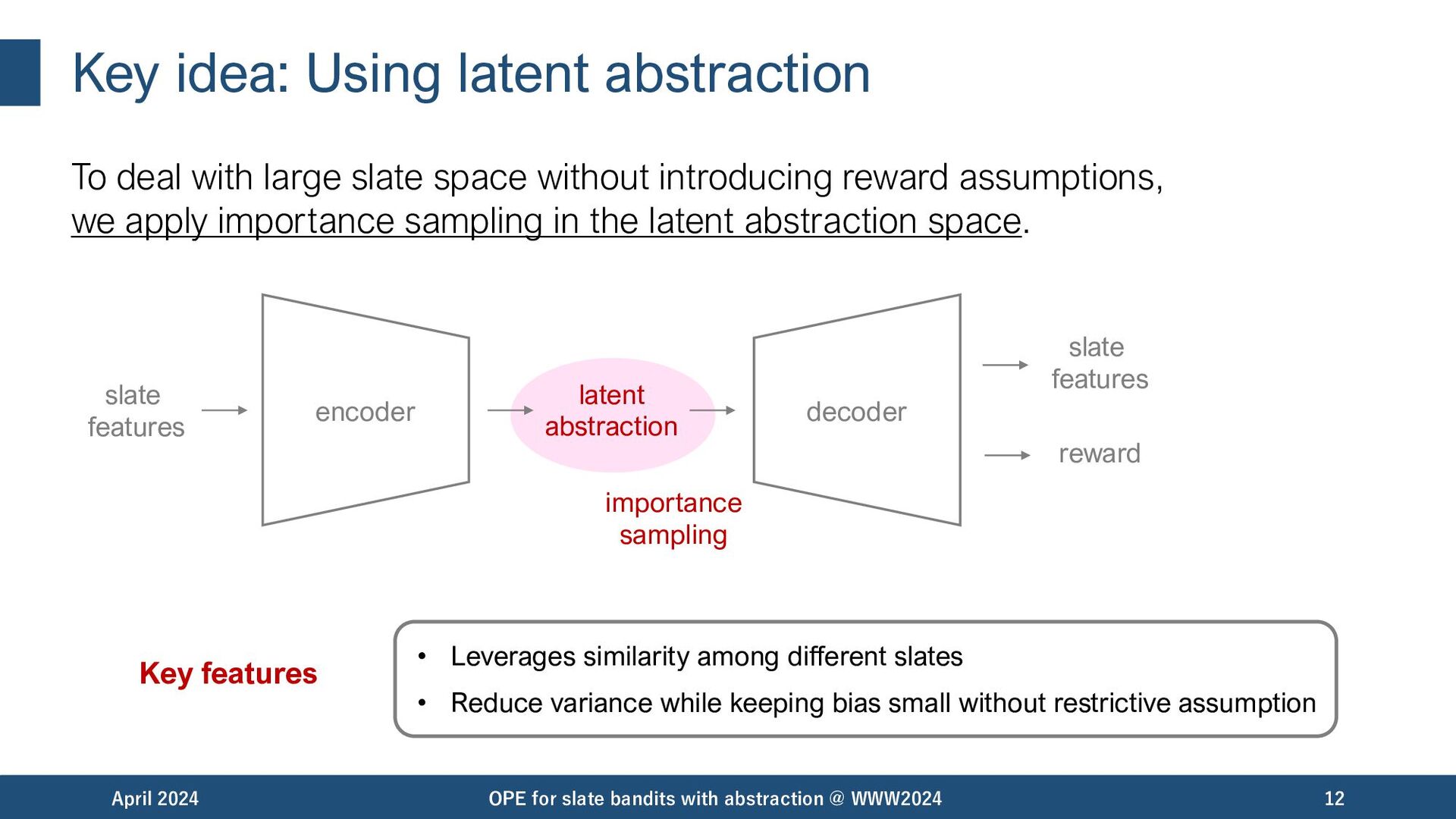{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
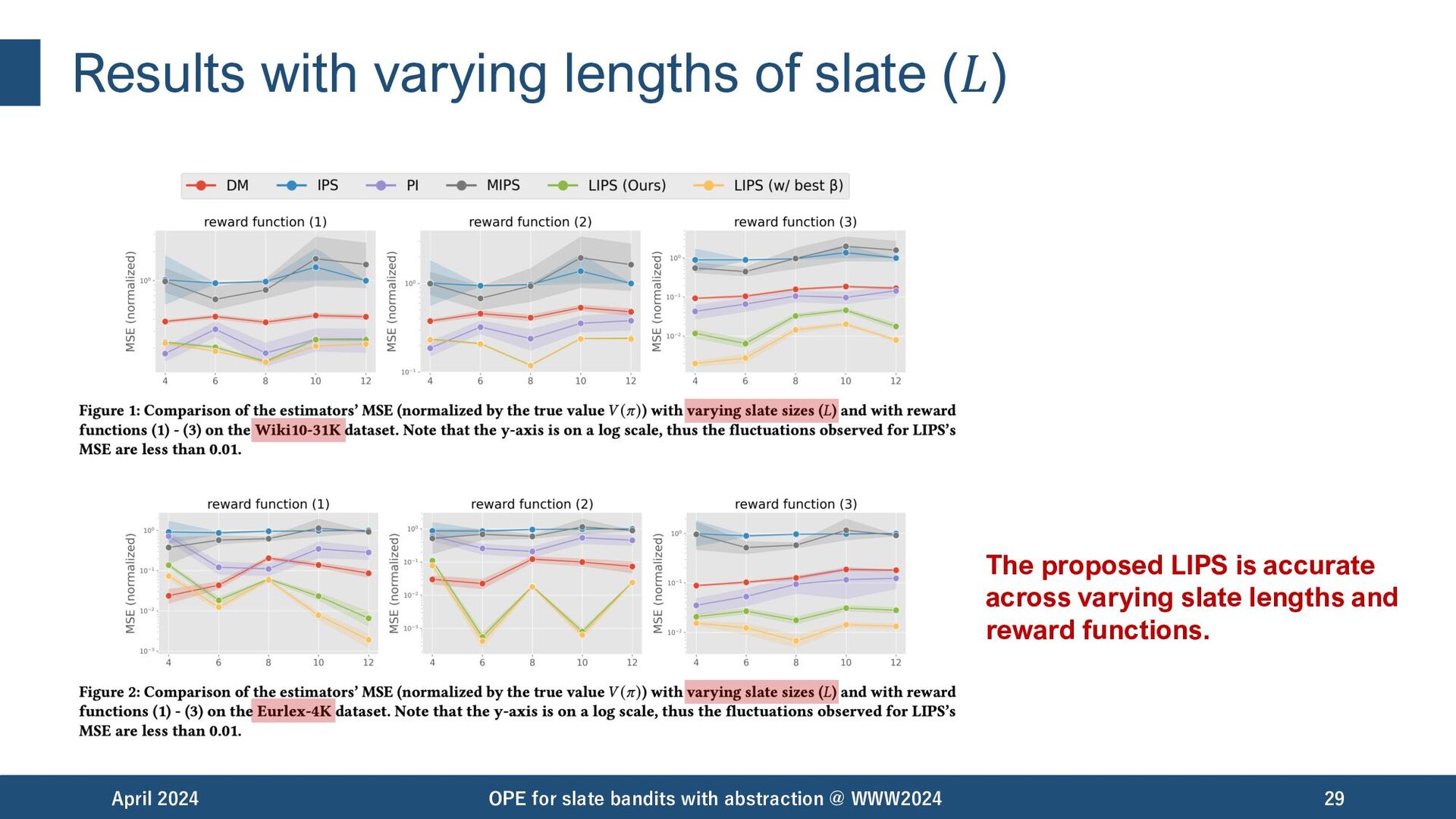{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
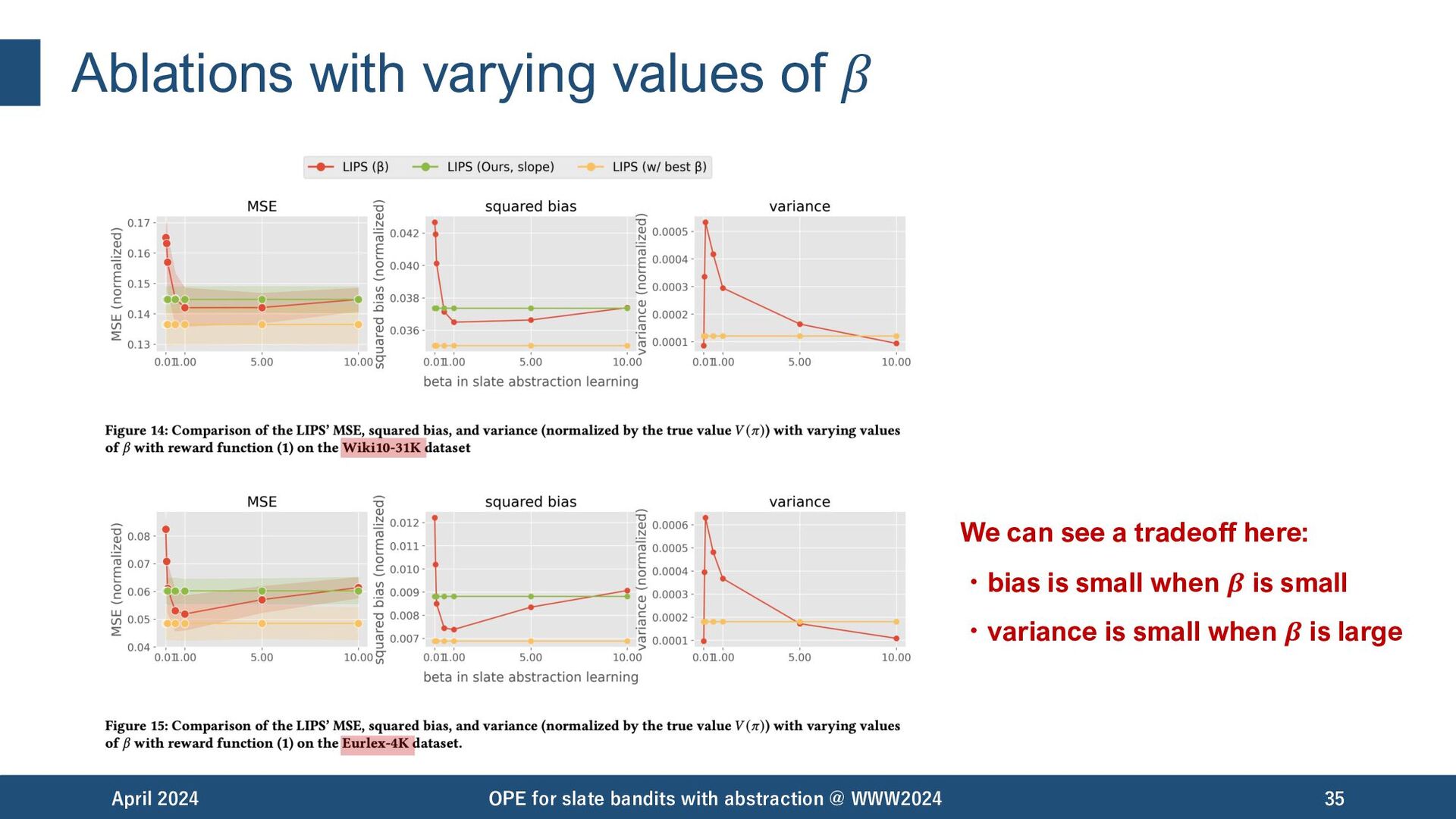{kind=link}
{kind=link}
![References (1/2) [Strehl+,10] Alex Strehl, John Langford, Sham Kakade, Lihong](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_36.jpg){kind=link}
![References (2/2) [Vlassis+,21] Nikos Vlassis, Ashok Chandrashekar, Fernando Amat Gil,](https://files.speakerdeck.com/presentations/2bd9f325853142469955792c3aceee13/slide_37.jpg){kind=link}