Share
最適決定木を用いた処方的価格最適化 株式会社リクルート 株式会社リクルート 法政大学 筑波大学 第0回 MOAI 研究部会(zoom) 2023年8月3(木) 14:00-15:00 池田 春之介 西村 直樹 鮏川 矩義 高野 祐一
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
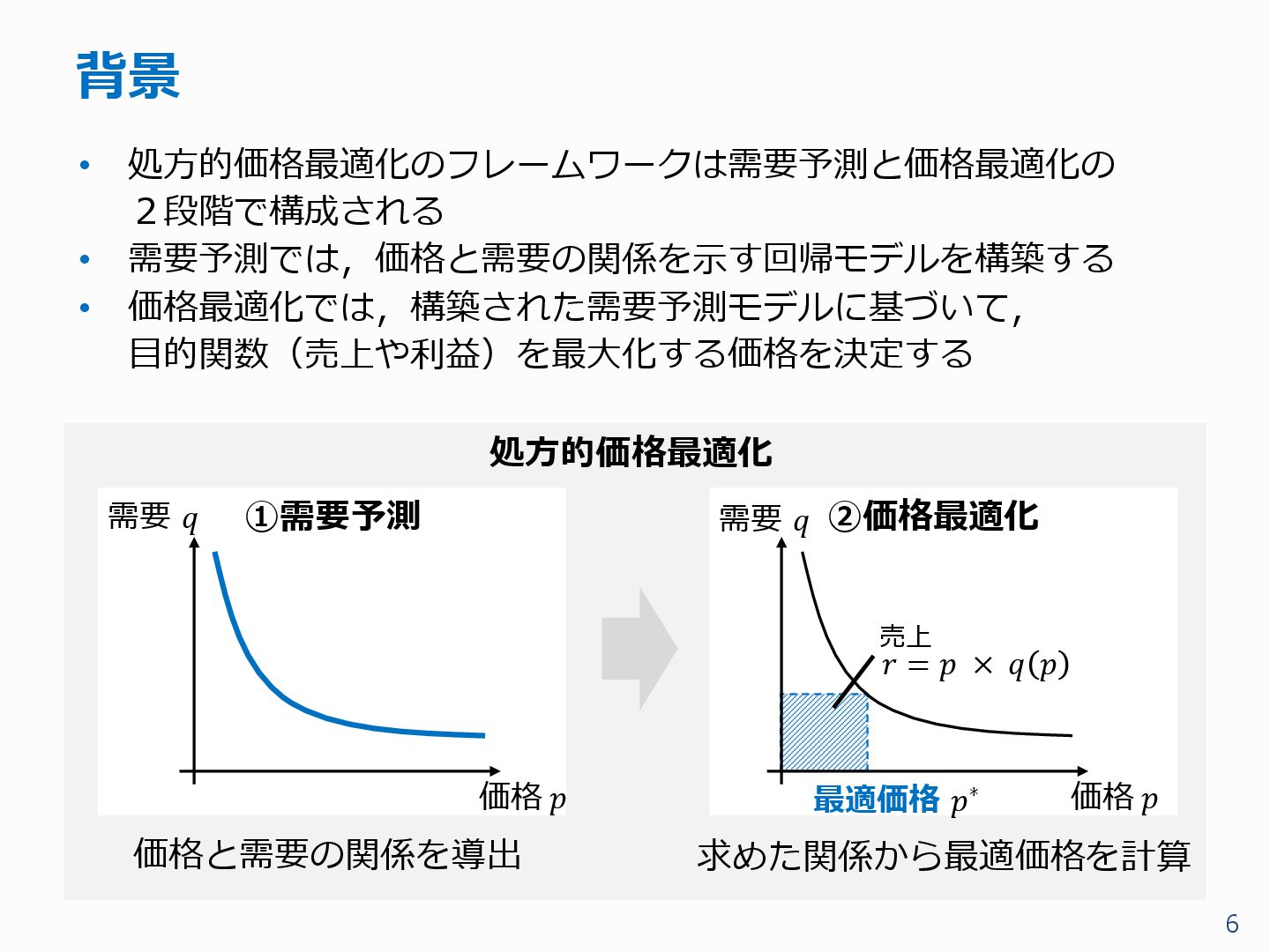{kind=link}
{kind=link}
![先行研究[1, 2]: • 処方的価格最適化問題の一般的なフレームワークを確立 • 需要を線形回帰で表現し,0-1整数二次最適化問題(BQO)に定式化 • BQOを高速で解くためのアルゴリズムを提案 課題: •](https://files.speakerdeck.com/presentations/71f879ed190241c6b0e161619d1fd78a/slide_7.jpg){kind=link}
![先行研究[3]: • 需要予測モデルにバギングを用いた回帰木を適用し, 0-1整数最適化問題として定式化 • 線形緩和を用いた高速アルゴリズムを提案 課題: • 需要予測の精度と引き換えに,交差価格弾力性(商品価格の変化が 他の商品の需要へ与える影響)を無視する強い仮定に依存](https://files.speakerdeck.com/presentations/71f879ed190241c6b0e161619d1fd78a/slide_8.jpg){kind=link}
![高精度の回帰モデルを用いつつ,現実的な時間で最適解が求められる 処方的価格最適化モデルを提案 1. 回帰モデルに解釈性を失わずに高い汎化性能が期待できる 最適決定木[4]を適用 (①需要予測) 2. 最適決定木を用いた価格最適化問題を混合整数線形最適化問題 (MILO)として定式化 (②価格最適化)](https://files.speakerdeck.com/presentations/71f879ed190241c6b0e161619d1fd78a/slide_9.jpg){kind=link}
{kind=link}
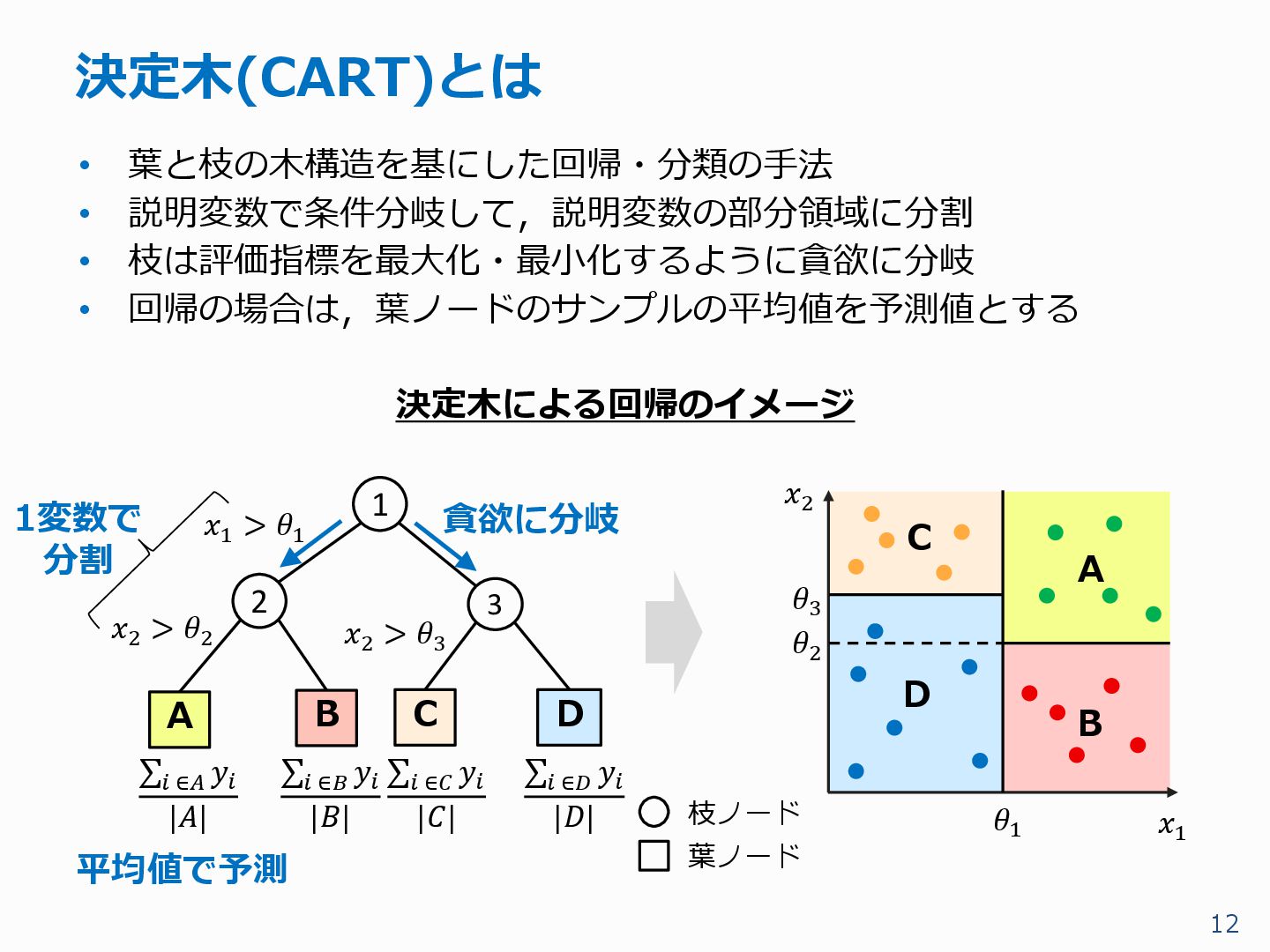{kind=link}
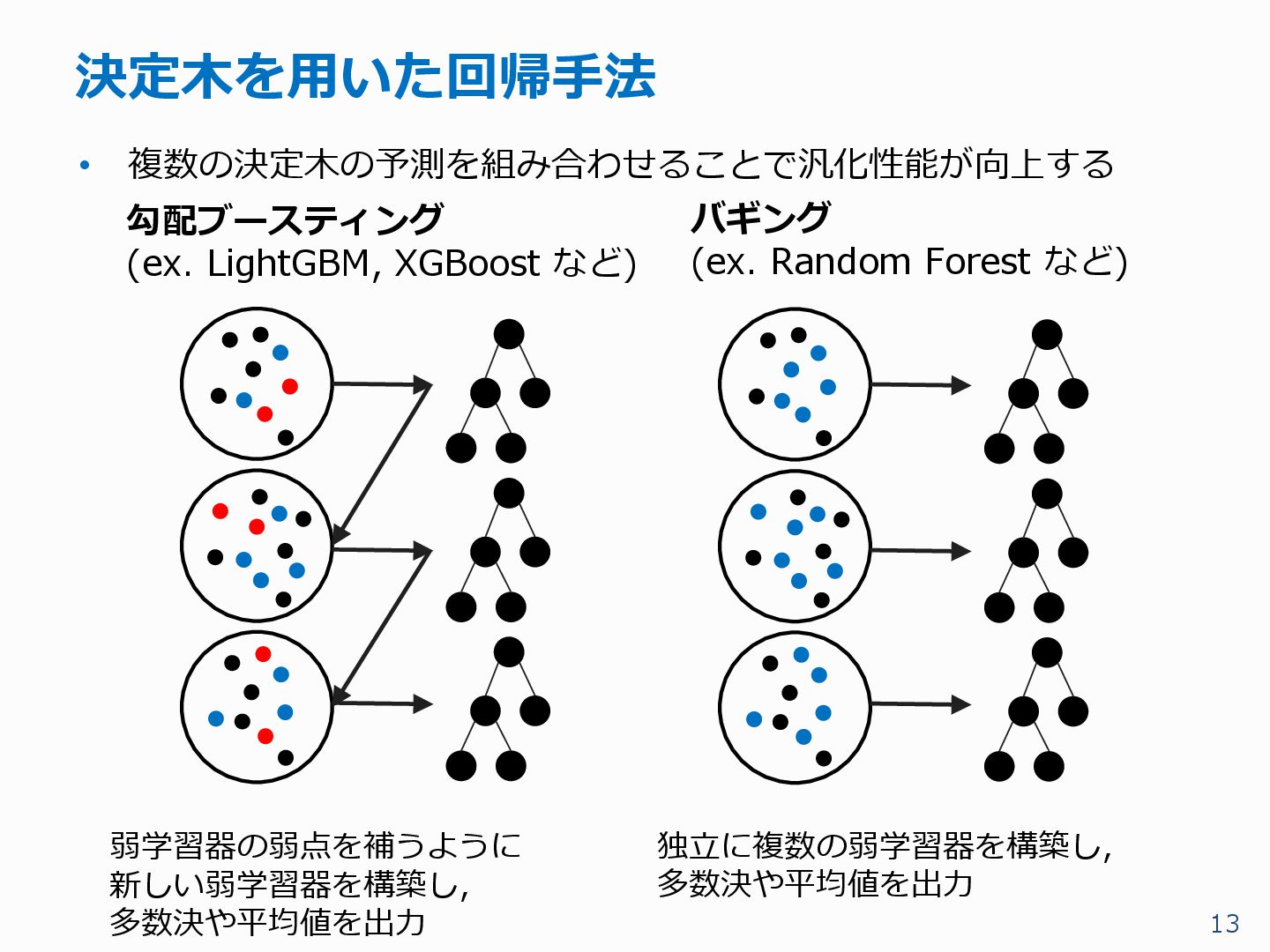{kind=link}
![• CARTでは貪欲に分岐していくのに対し,数理最適化を用いることで 木の深さを指定し評価指標に基づいてすべての分岐を同時に最適化 • 1つの決定木によって,回帰モデルが表現されるため解釈性が高い • 実験的には勾配ブースティング決定木と同等の性能が示されている 14 最適決定木[4]とは 最適決定木のイメージ(回帰)](https://files.speakerdeck.com/presentations/71f879ed190241c6b0e161619d1fd78a/slide_13.jpg){kind=link}
![• 各商品の需要𝑞𝑚 を予測するモデルを最適決定木により構築 15 最適決定木[4]による需要予測 最適決定木の定式化 各商品の最適決定木を構築すれば 価格最適化問題に組み込み可能 価格最適化問題の定式化 [4]](https://files.speakerdeck.com/presentations/71f879ed190241c6b0e161619d1fd78a/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
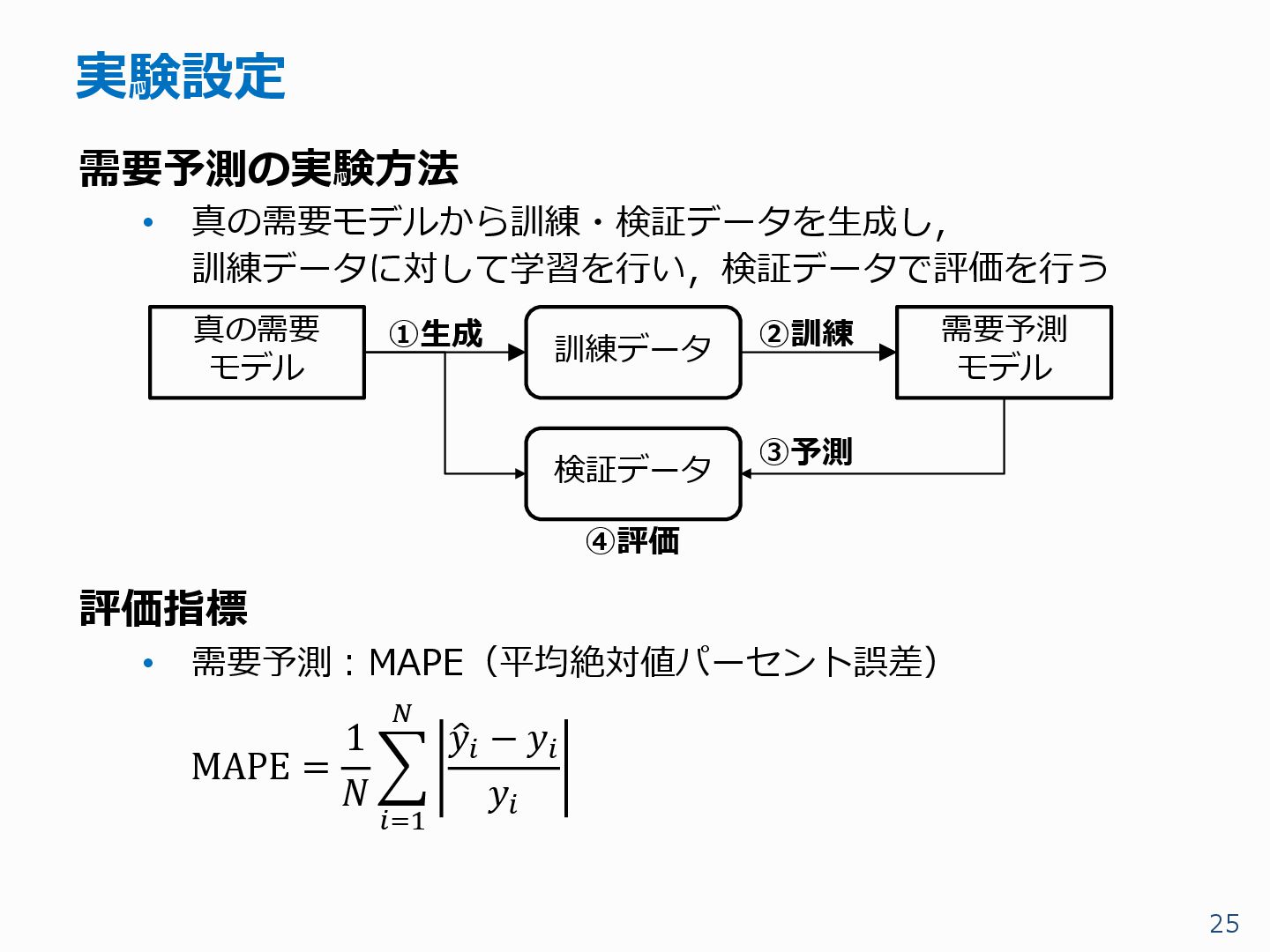{kind=link}
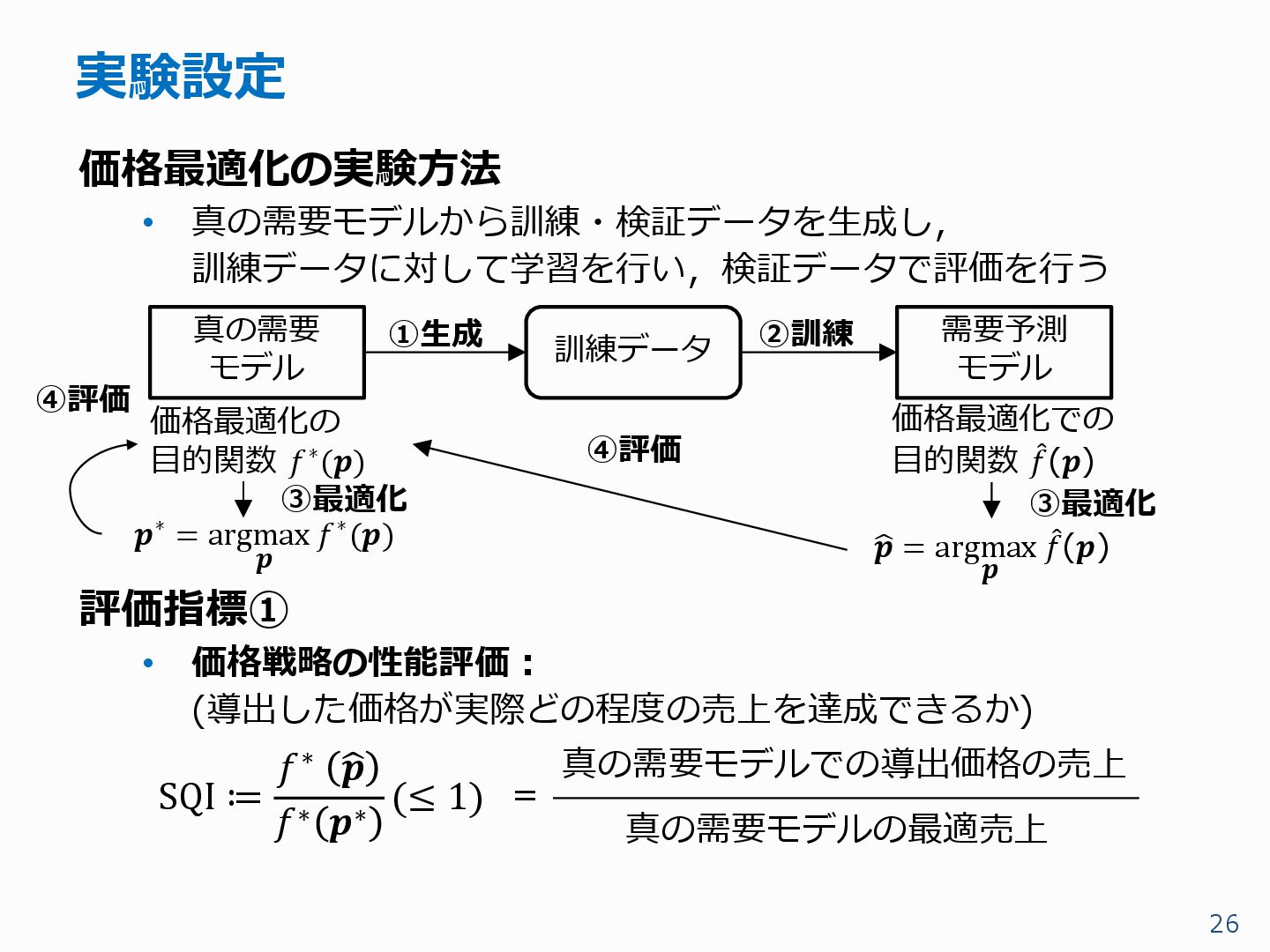{kind=link}
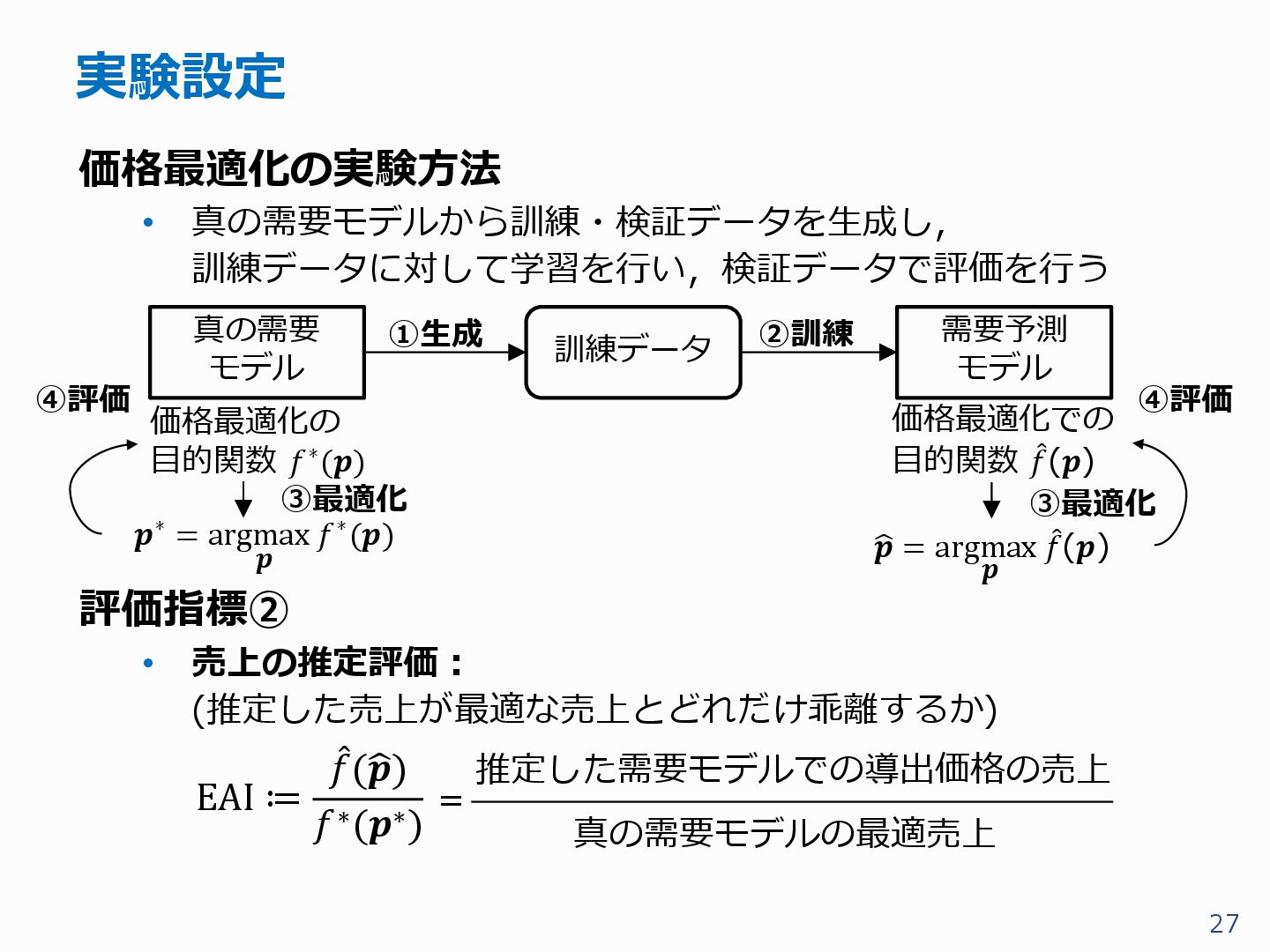{kind=link}
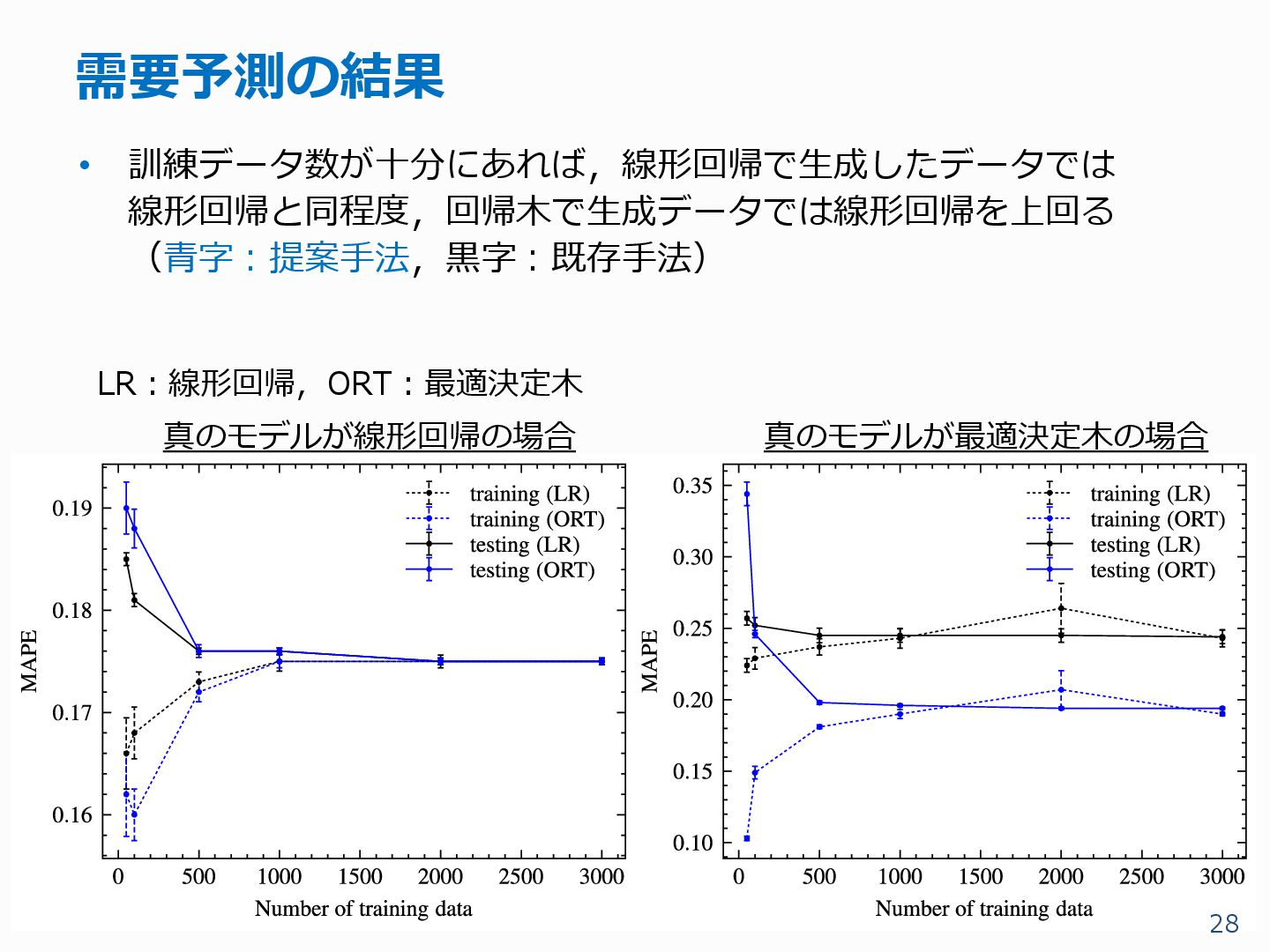{kind=link}
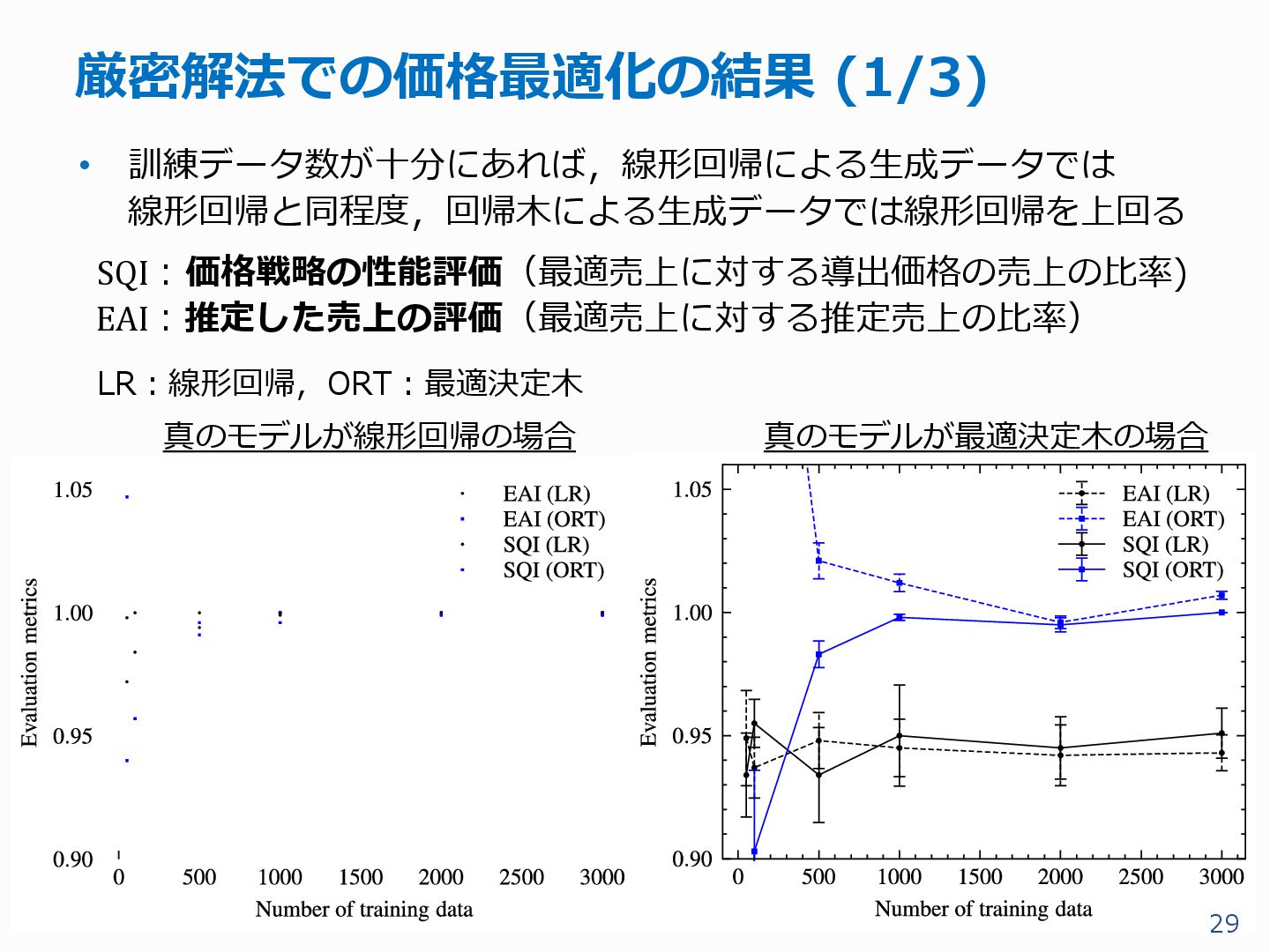{kind=link}
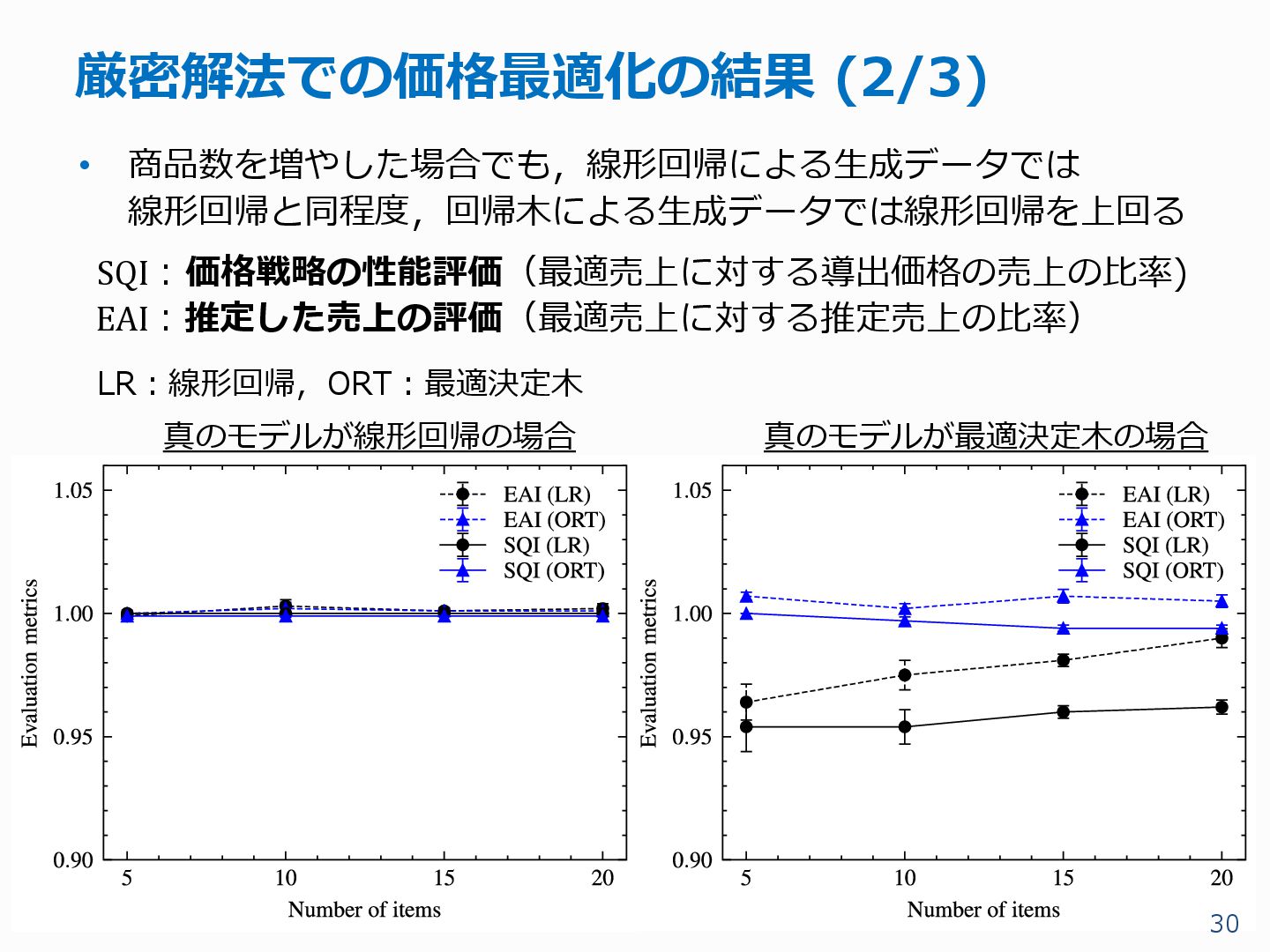{kind=link}
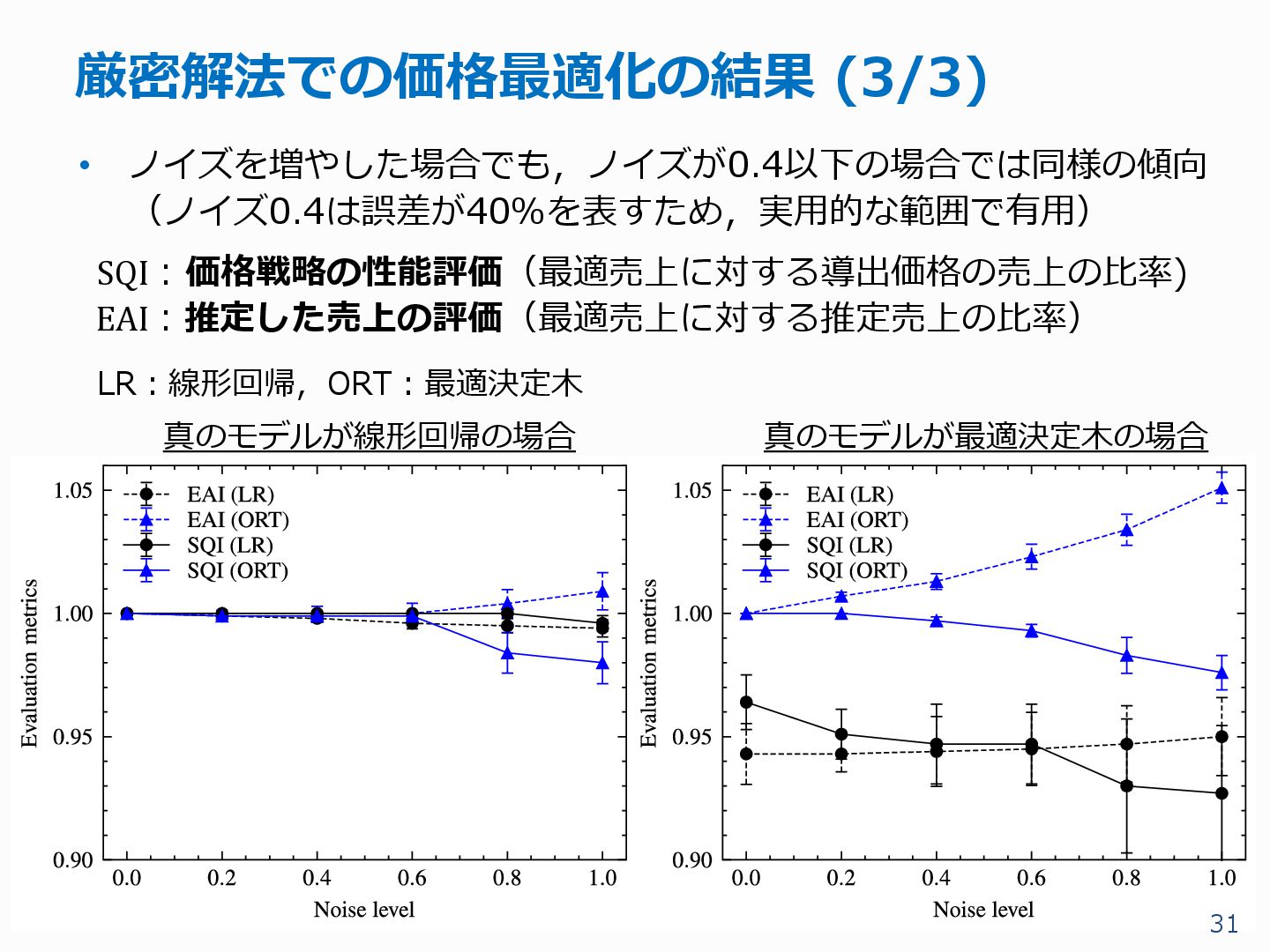{kind=link}
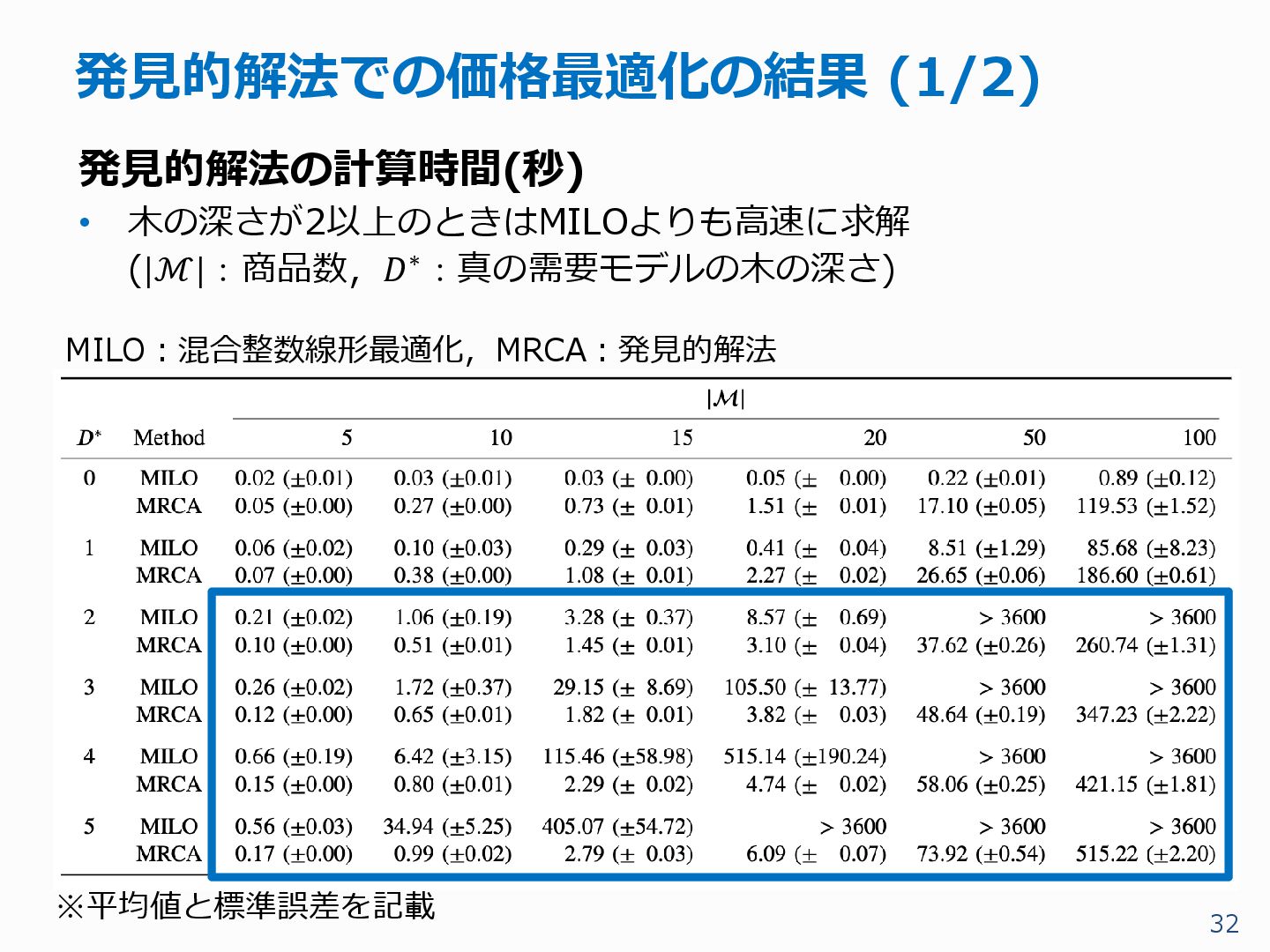{kind=link}
{kind=link}
{kind=link}
{kind=link}