Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
今からでも間に合う! 生成AI「RAG」再入門 / Re-introduction to RA...
Search
Hideaki Aoyagi
June 16, 2025
Technology
980
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
今からでも間に合う! 生成AI「RAG」再入門 / Re-introduction to RAG in Generative AI
2025/06/14「JAWS-UG熊本」で発表したLT資料です
Hideaki Aoyagi
June 16, 2025
More Decks by Hideaki Aoyagi
See All by Hideaki Aoyagi
初めてのAzure FunctionsをClaude Codeで作ってみた / My first Azure Functions using Claude Code
hideakiaoyagi
1
1.1k
10分で紹介するAmazon Bedrock利用時のセキュリティ対策 / 10-minutes introduction to security measures when using Amazon Bedrock
hideakiaoyagi
1
2.6k
5分で紹介する生成AIエージェントとAmazon Bedrock Agents / 5-minutes introduction to generative AI agents and Amazon Bedrock Agents
hideakiaoyagi
0
1.1k
「AI-Starter」と「らくらくRAG導入パック」で始める生成AI利活用 / Introducing Generative AI Solutions
hideakiaoyagi
0
1.7k
生成AIシステムのセキュリティ対策 〜 ベストプラクティスと実践 〜 / Security measures for generative AI systems
hideakiaoyagi
0
1.5k
コールセンターだけじゃない!Amazon Connectを使ってできる課題解決いろいろ / Automation Solutions using Amazon Connect
hideakiaoyagi
0
2.5k
Other Decks in Technology
See All in Technology
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
160
AI工学特論: MLOps・継続的評価
asei
4
150
現場との対話から始める “作る前に問い直す”業務改善
mochico50
1
190
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
130
Kaggleで成長するために意識したこと
prgckwb
2
440
複数プロダクト組織のAIネイティブ化における戦略 / AICon2026_kude
rakus_dev
0
300
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
380
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
3
900
発表と総括 / Presentations and Summary
ks91
PRO
0
180
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
230
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
270
Featured
See All Featured
Writing Fast Ruby
sferik
630
63k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Balancing Empowerment & Direction
lara
6
1.2k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
WCS-LA-2024
lcolladotor
0
740
The agentic SEO stack - context over prompts
schlessera
0
850
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
180
Faster Mobile Websites
deanohume
310
32k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Transcript
今からでも間に合う! 生成 AI「RAG」再入門 青柳 英明 2025/06/14 JAWS-UGくまもと#16 AWSで生成AIにふれてみよう! くまもと
自己紹介 氏名: 青柳 英明 所属: クラスメソッド 福岡オフィス 職種: AWS ソリューションアーキテクト/
コアメンバーやってます くまモンファン歴: 15年 生成 AI エンジニア
生成 AI の基礎知識
「生成 AI」とは 従来からある「機械学習」の応用の一つ (Machine Learning: ML) 従来の機械学習: 画像認識や、分析・予測などに使われることが多かった 生成 AI:
文章や画像などを作り出すことができる
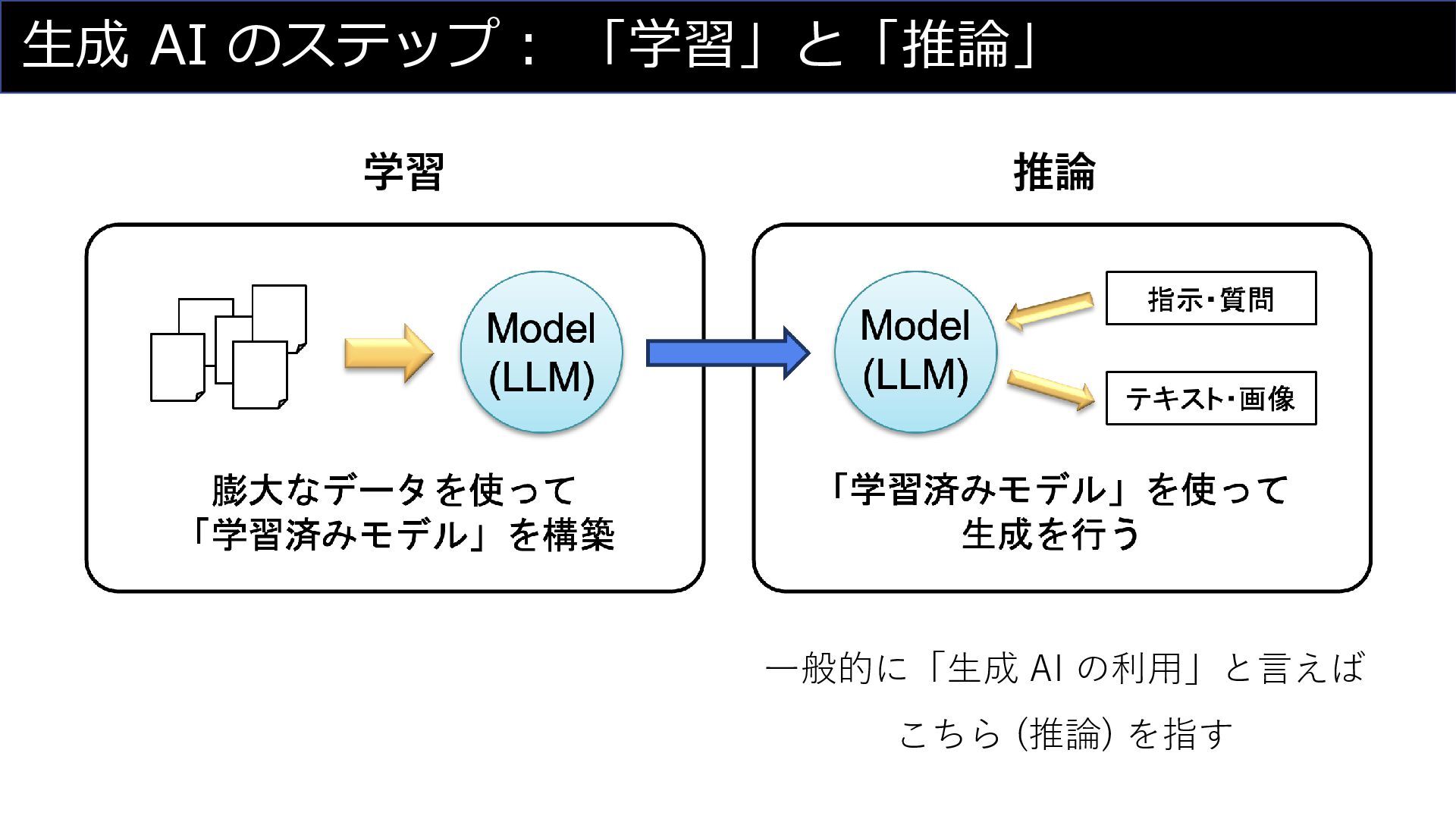
生成 AI のステップ: 「学習」と「推論」 学習 推論 一般的に「生成 AI の利用」と言えば こちら
(推論) を指す
参考: 大規模言語モデル (LLM) / 基盤モデル (FM) 大規模言語モデル (Large Language Model;
LLM) ・膨大な量のテキスト情報を学習させたモデル 基盤モデル (Foundation Model; FM) ・テキストのみでなく「画像」「動画」「音声」にも対応したモデル つまり →「FM (基盤モデル)」は「LLM」を含む概念 (基盤モデルの一種が「LLM」) (AWS の Bedrock でも原則として「基盤モデル」という表現が使われています)
「RAG」が生まれた経緯
基盤モデルが対応できない質問 (その1) 基盤モデルは、一般的に モデルがリリースされる少し前の時点の最新情報を使って学習される 例:「Claude Sonnet 4」の学習に使用されたデータ →「2024年11月」時点のインターネット上の情報 質問「2025年の九州地方の梅雨入りはいつでしたか?」 回答「申し訳ありませんが、私の知識は2024年までの情報に基づいており、
2025年の気象情報については把握しておりません」 (「知らない」と言われたり、場合によってはウソの回答=ハルシネーションをする)
基盤モデルが対応できない質問 (その2) 基盤モデルはインターネットに公開されている膨大な情報を使って学習される ↓ モデル開発ベンダーがアクセス可能な情報に限定される 企業内で使われる非公開の社内情報は、当然、学習には使われない 質問「出張時にモバイルルーターを借りる時、どこに申請すればよいですか?」 回答「出張時のモバイルルーター申請先はお勤めの会社によって異なりますが、 一般的には総務部や情報システム部に申請することが多いです」 (一般的な情報に基づいた回答しかしてくれない)
「最新の」「非公開の」情報に対応させる手法 手法 1: 独自データを使って独自のモデルを作成 (学習) する 基盤モデル開発ベンダー (OpenAI や Anthropic
など) と同様の手法により、 自分で用意した最新の/非公開のデータを使って独自モデルを作成する → 膨大な時間とお金がかかる 手法 2:「Fine Tuning」手法を使って既存の基盤モデルを追加学習する 既存の基盤モデルに対して、用意したデータを使って「追加学習」を行う → 手法 1 よりは簡易に可能だが、 それでも、追加学習のたびに時間や手間がかかってしまう
第3の手法「RAG」 そこで考案された画期的な手法「RAG」 RAG = Retrieval-Augmented Generation (検索拡張生成) 基盤モデル自体には手を加えず、 「検索」と基盤モデルを組み合わせることで 最新の/非公開の情報を使って質問に回答できるようにする手法
検索拡張生成 → 検索によって拡張された回答生成
RAG の仕組み
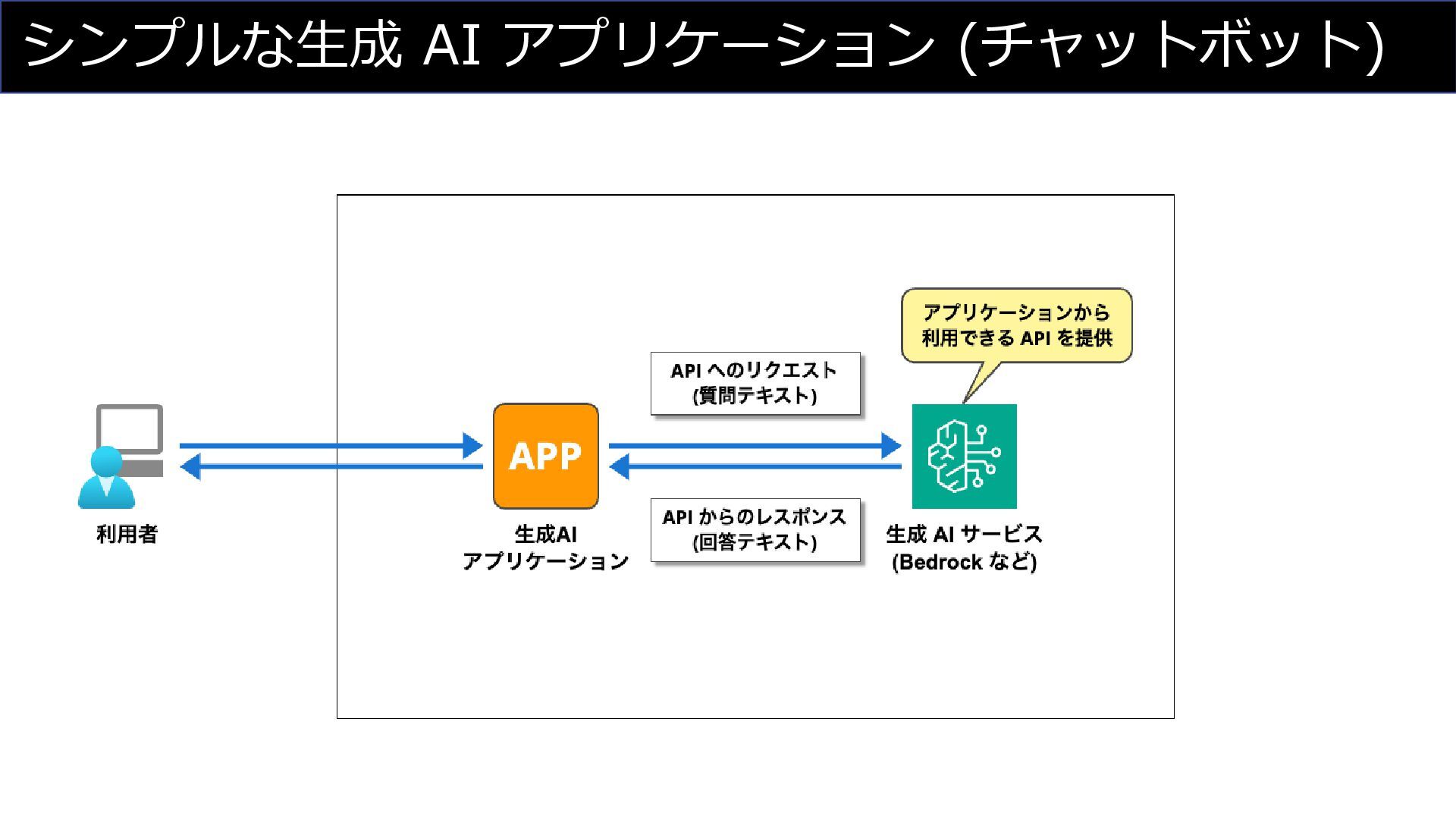
シンプルな生成 AI アプリケーション (チャットボット)
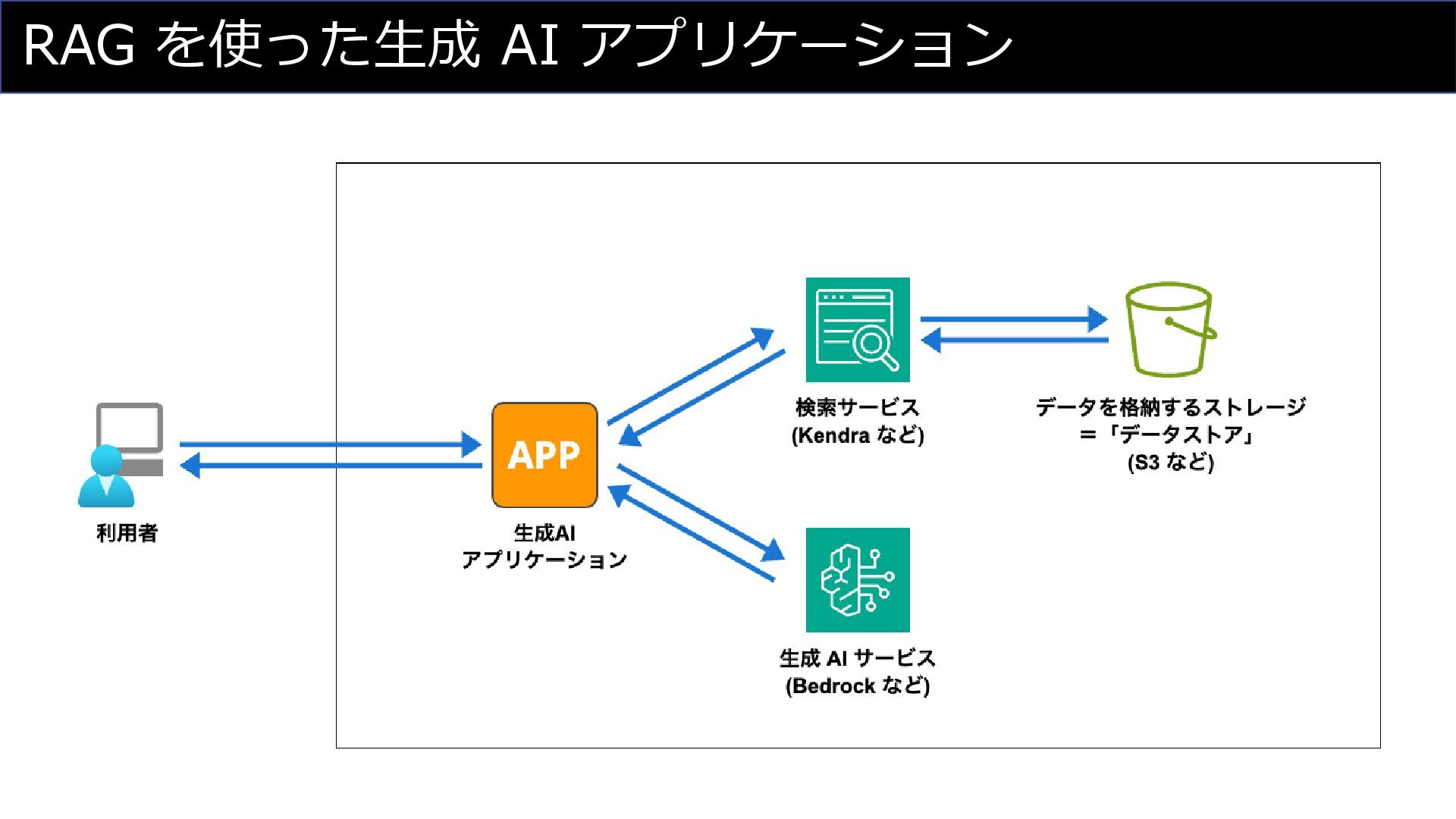
RAG を使った生成 AI アプリケーション
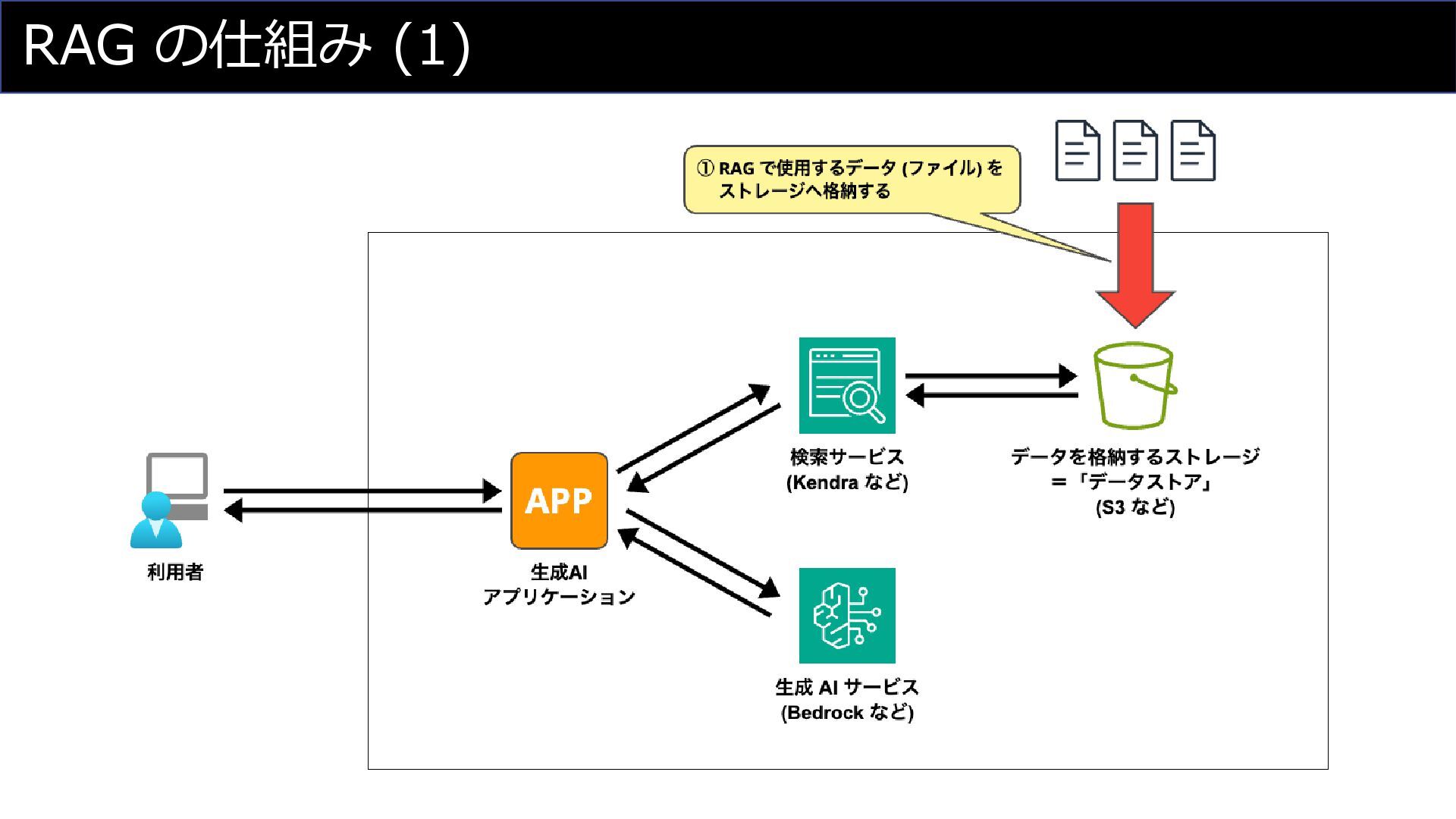
RAG の仕組み (1)
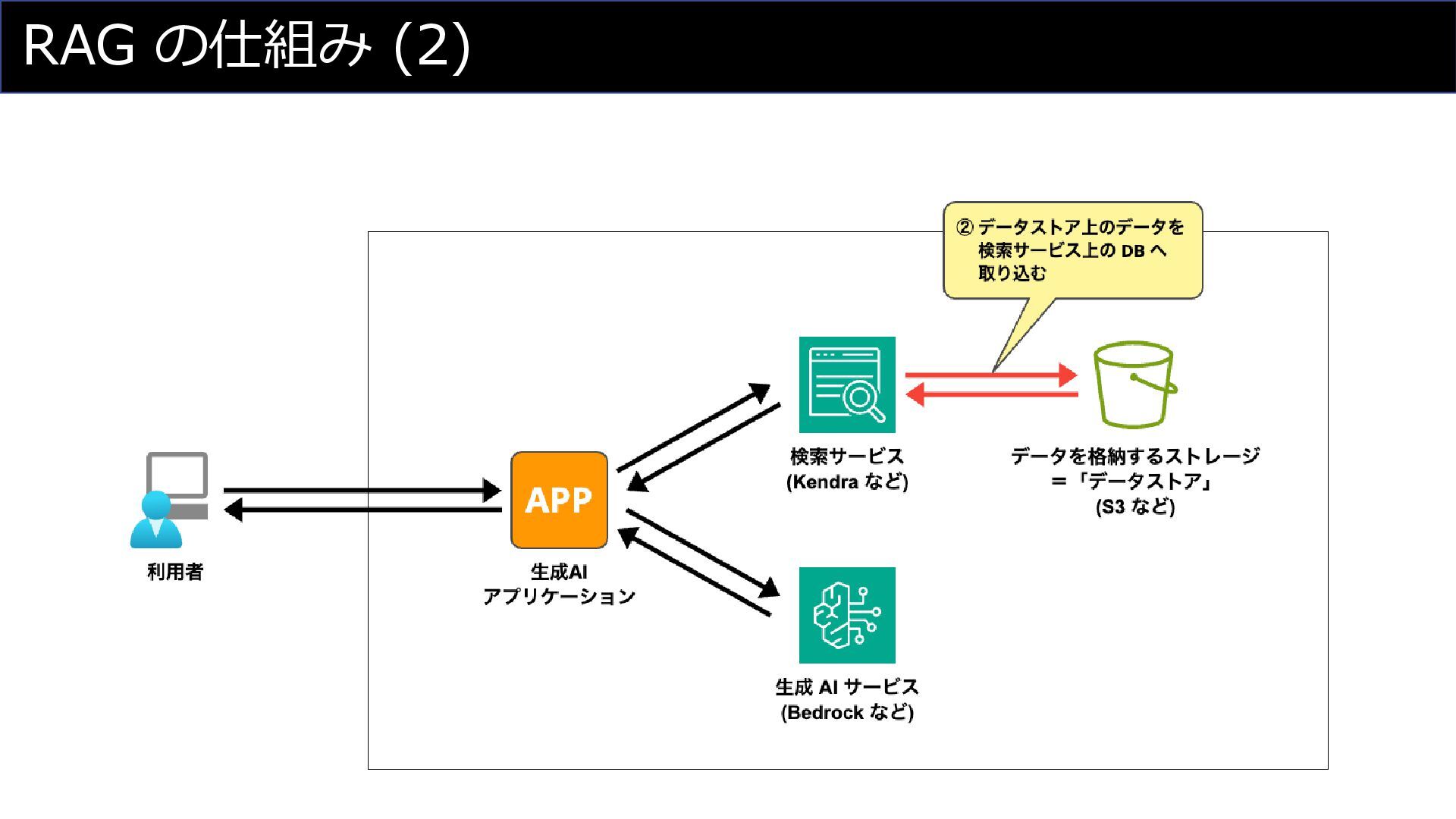
RAG の仕組み (2)
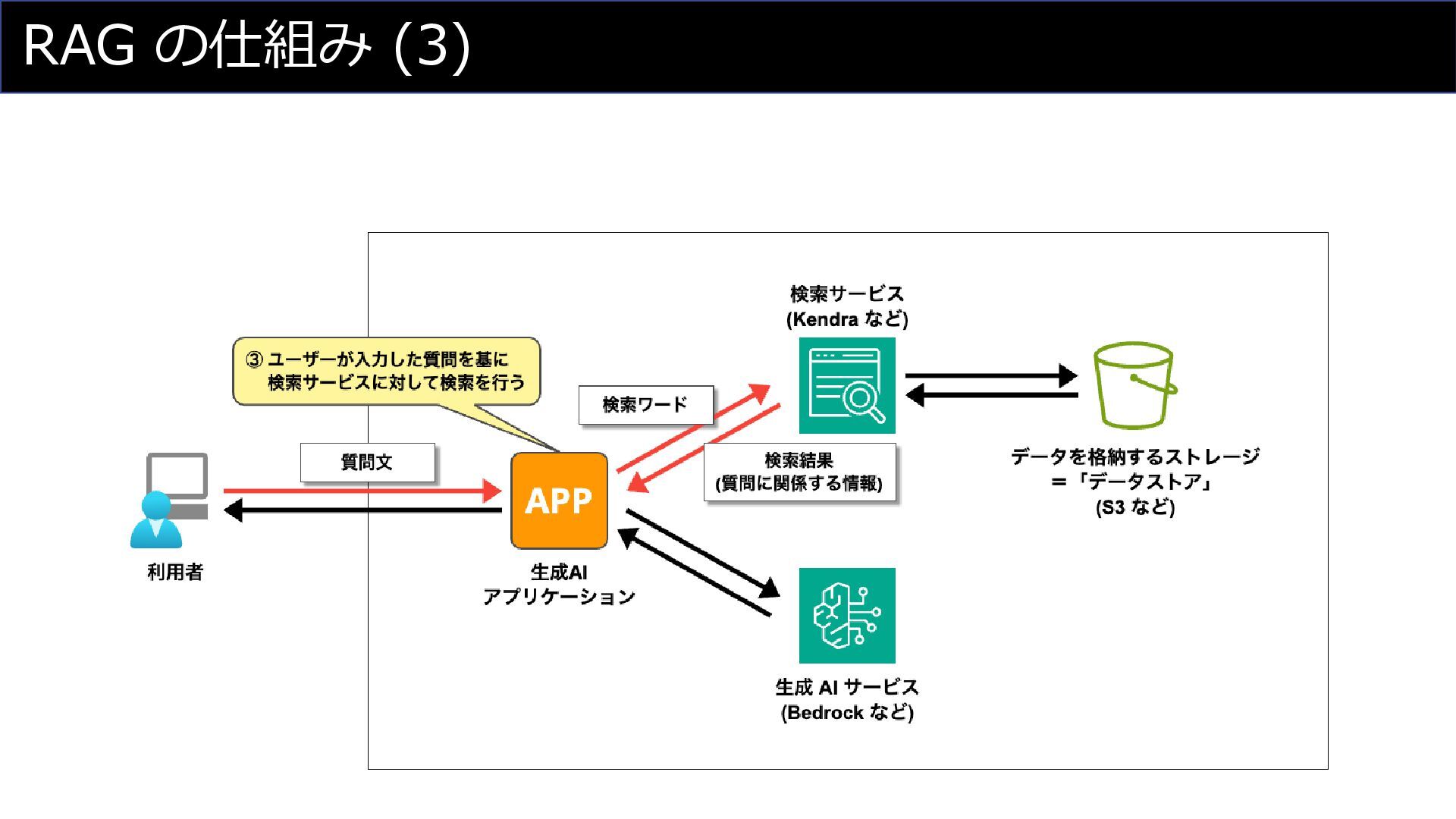
RAG の仕組み (3)
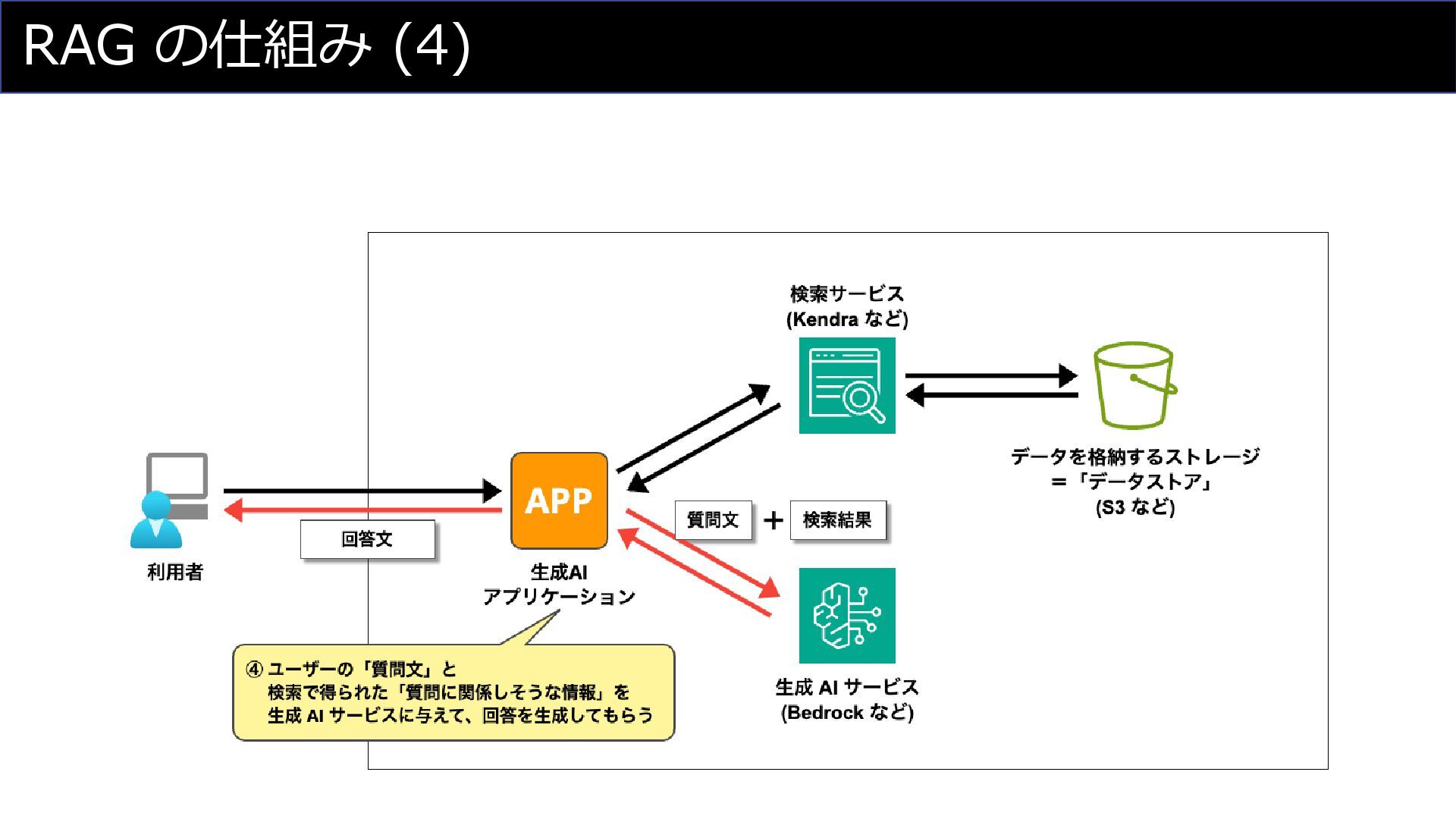
RAG の仕組み (4)
RAG で使われる検索技術: ベクトル検索 一般的に使われる「検索」方式:「キーワード検索」 →「検索対象テキスト」の中から「検索キーワード」に一致する部分を探す (文字列同士の比較) デメリット ・同義語や類似表現を検索できない (「パソコン」と「PC」) ・表記揺れに弱い
(「休暇取得を申請」「休暇の取得申請」) ・文脈や意味を理解しない
RAG で使われる検索技術: ベクトル検索 「ベクトル検索」 → 文章や単語を数値に変換して比較することで検索する その際、単一の数値では文章の多様な意味を表現できないため、 「多次元の数値データ」(=ベクトル) に変換したものを使う ・検索対象テキスト
(候補) → ベクトルデータに変換 ・検索キーワード → ベクトルデータに変換 ・ベクトルデータ同士を比較して、より距離が近いものを検索結果とする 「りんご」と「パソコン」: あまり関係ない → 距離が遠い 「りんご」と「みかん」 : かなり似ている → 距離が近い
RAG で使われる検索技術: チャンキング 検索対象データ (データソース) には、大小さまざまな規模のデータがある ・周知文書: 1枚のテキストで、一つの内容のみが書かれている ・取扱説明書: 何ページもある文書で、複数の章・節で構成されている
(各部の説明、◯◯機能の操作方法、故障時の対応、etc.) サイズが大きく、複数の内容が含まれるデータの場合 → 文書全体をベクトルデータに変換しようとすると、 データに含まれるすべての要素が一つのベクトルデータになってしまう → 検索時に、探したい事項にピンポイントで情報をヒットさせることができない (知りたいのは「◯◯機能の操作方法」だけなのに、いらん情報までヒットする・・・)
RAG で使われる検索技術: チャンキング 検索対象データをベクトルデータ化する前に、 検索に適した単位の情報 (=「チャンク」) に分割する 取扱説明書 → チャンクに分割
・各部の説明 ・◯◯機能の操作方法 → チャンク単位でベクトルデータ化 ・△△機能の操作方法 検索時にピンポイントで必要な情報にヒット ・故障時の対応 etc.
応用編
RAG の回答がイマイチな場合、どうすればよい? 例: 社内の「FAQ」(質問 & 回答) を集めた Excel ファイルを使って 「質問に答えてくれる
RAG チャットボット」を作る
精度評価: 想定される質問を行い、回答の精度を評価 作成した RAG 環境を使って、実際に質問してみる 質問「出張費を精算する時、どこに申請すればよいですか?」 回答「情報システム部に申請してください」 → 出張費申請は「経理部」のはずだけど・・・ 回答が間違っている!
原因分析: どうして間違った回答をしてしまうのか データソース (Excel ファイル) を RAG に取り込む際の 「チャンキング」(チャンク分割) が上手くいっていない
質問と回答のペアが 異なるチャンクに 別れてしまっている チャンキングは検索サービスが自動で行ってくれるが、 人間が認識する「情報の切れ目」の通りにチャンク分割してくれるとは限らない
精度改善: 考えられる原因に応じた対応を行う 改善策: 質問と回答のペアを 1 組ずつ、別々のファイルに分割してしまう → 確実に、ペアとなる質問と回答が 1 つのチャンクに収めることができる
(実は) RAG が向いていないこと 例: データソースに格納したデータ全体を、横串で分析したい → RAG は次のように処理を行う ・データソースに対して検索を行い、関係のある情報を抽出する ・検索された情報を使って回答を生成する
つまり、データ全体を使った回答生成は行えない データ全体の分析を行いたい場合は・・・ ・基盤モデルにファイルを直接添付して「分析して」と指示する ・外部ファイルを参照できる「生成 AI エージェント」を使う など
まとめ
まとめ ・基盤モデル自体は「最新の情報」や「非公開の情報」に関する質問に 回答することができない ・「RAG」は、基盤モデルに「検索システム」を組み合わせることによって 「最新の情報」や「非公開の情報」にも回答できるようにする仕組み ・RAG の回答がイマイチな時には「回答精度改善」の手法を試みる → 「精度の評価」〜「原因の分析」〜「精度改善の適用」 ・RAG
にも「向き」「不向き」がある → 「外部データを扱う = RAG」と思わずに、適切な手法を選ぶ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}