Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015. [2] T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie. Feature pyramid networks for object detection. In CVPR, 2017. [3] Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo and Ross Girshick, Detectron2. https://github.com/facebookresearch/detectron2, 2019. [4] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Girshick. Mask R-CNN. In ICCV, 2017. [5] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollar. Focal loss for dense object detection. In ICCV, 2017. [6] Mingxing Tan, Ruoming Pang, and Quoc V Le. EfficientDet: Scalable and efficient object detection. In CVPR , 2020. [7] Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 779– 788, 2016. [8] Joseph Redmon and Ali Farhadi. YOLO9000: better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 7263– 7271, 2017. [9] Joseph Redmon and Ali Farhadi. YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018. [10] Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020. [11] YOLOv5, https://github.com/ultralytics/yolov5 , as of version 3.0 [12] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C 12 Berg. SSD: Single shot multibox detector. In ECCV, 2016. [13] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS: Fully convolutional one-stage object detection. In ICCV, 2019. [14] Xingyi Zhou, Dequan Wang, and Philipp Krahenbuhl. Objects as points. arXiv preprint arXiv:1904.07850, 2019. [15] Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and Stan Z Li. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In CVPR, 2020. References
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Example of 2-stage Detector [H1][3] : Faster R-CNN [1] +](https://files.speakerdeck.com/presentations/a8ca5e8787024a3995f28fe07eae2224/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![How are Feature Maps and Ground Truth Associated? from: [H1]](https://files.speakerdeck.com/presentations/a8ca5e8787024a3995f28fe07eae2224/slide_9.jpg){kind=link}
{kind=link}
![Region Proposal Network (RPN) INPUT OUTPUT from: [H1]](https://files.speakerdeck.com/presentations/a8ca5e8787024a3995f28fe07eae2224/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
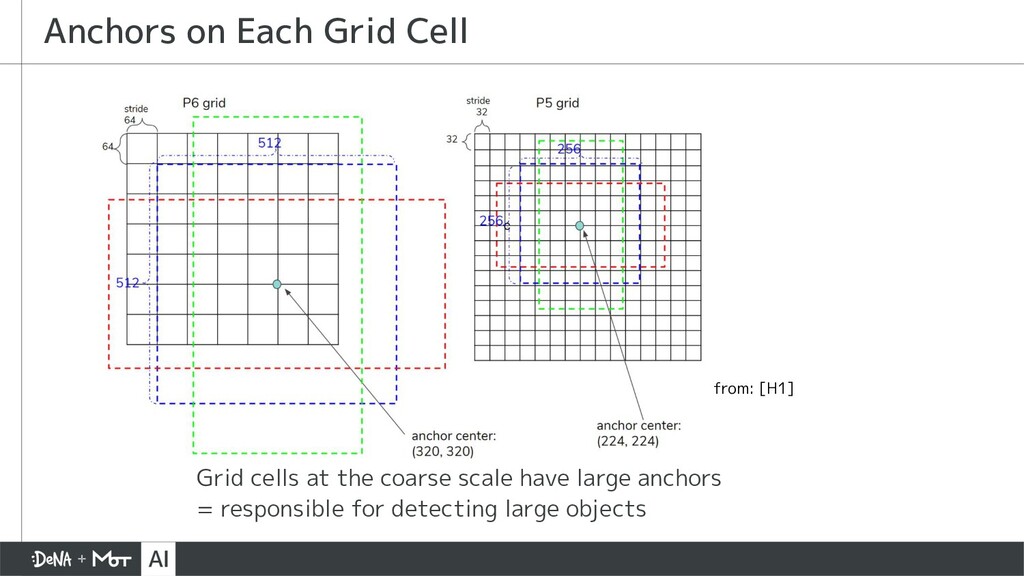{kind=link}
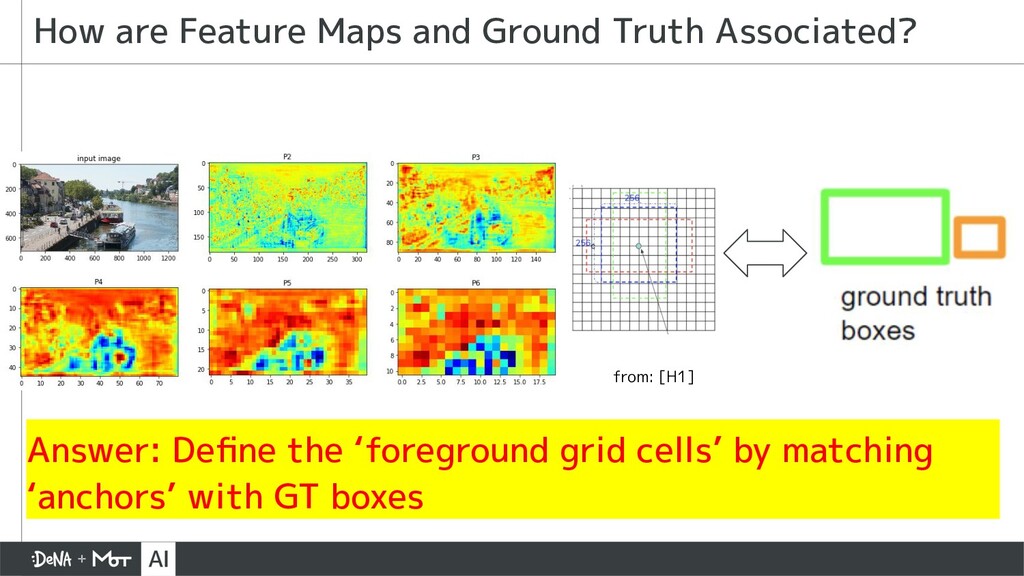{kind=link}
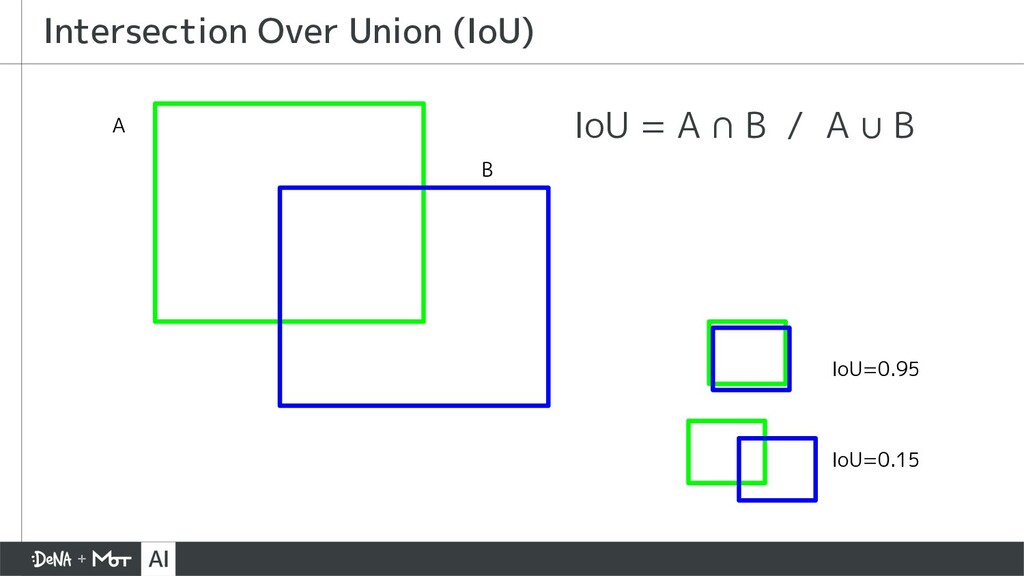{kind=link}
{kind=link}
{kind=link}
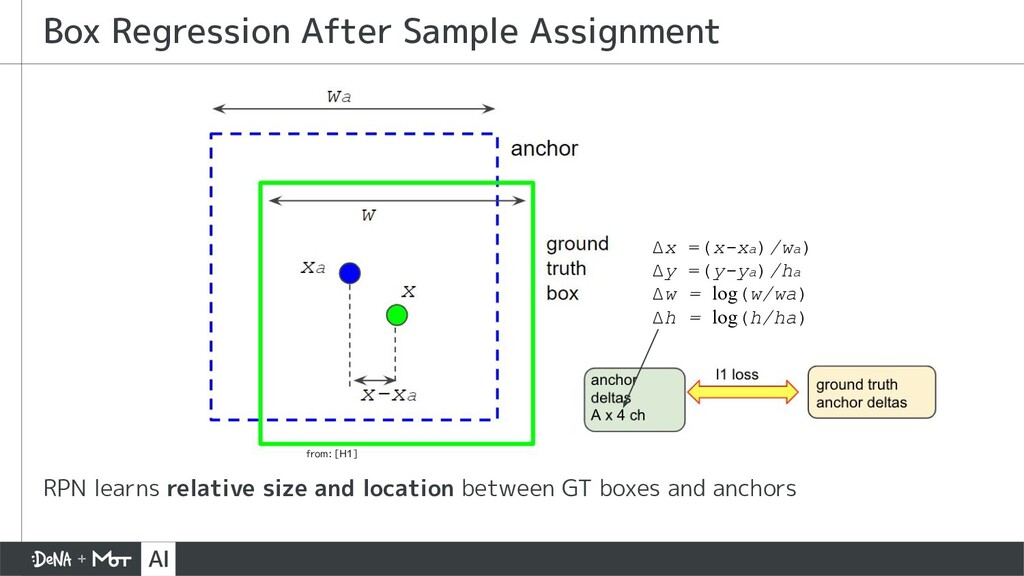{kind=link}
{kind=link}
{kind=link}
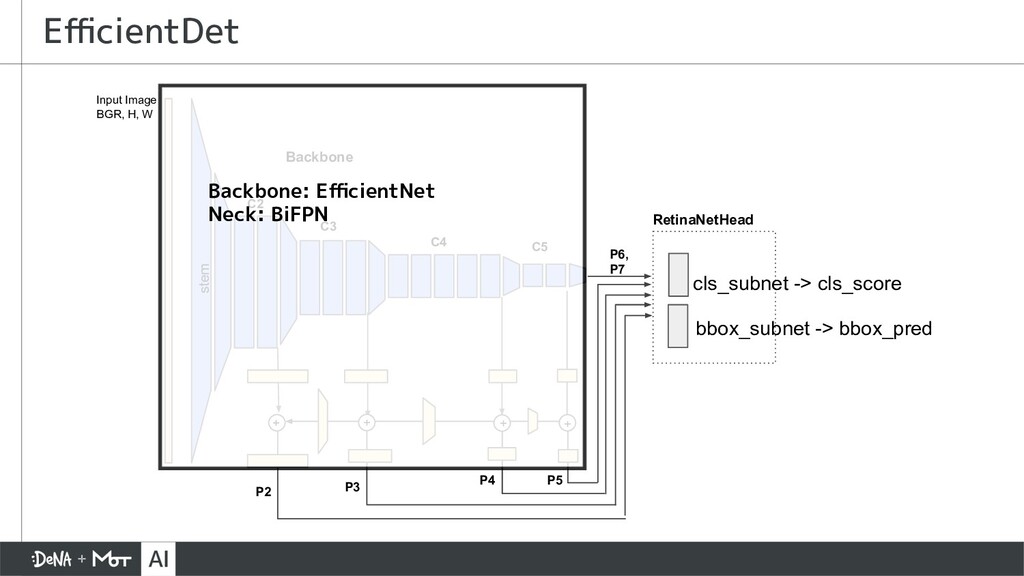{kind=link}
{kind=link}
{kind=link}
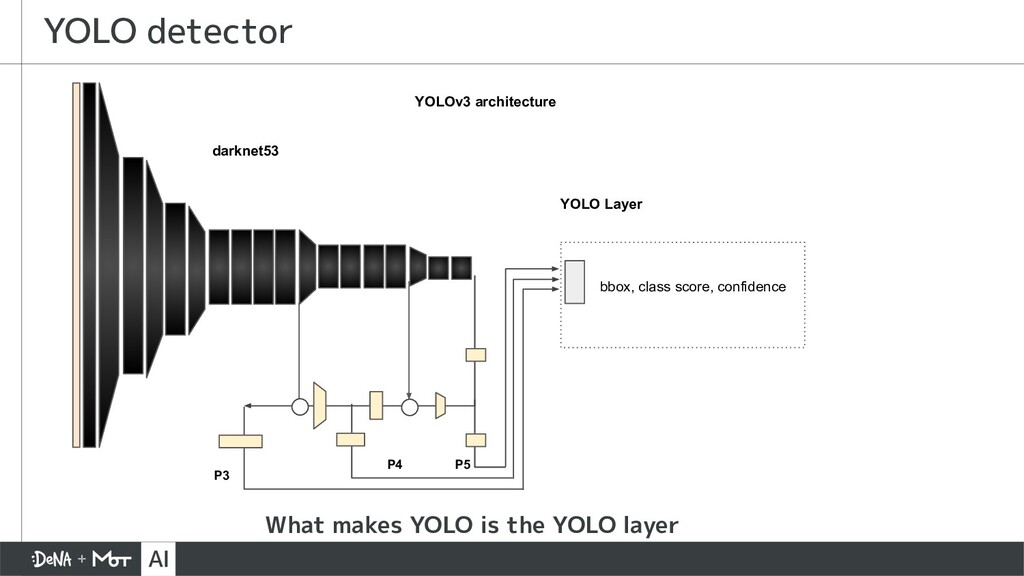{kind=link}
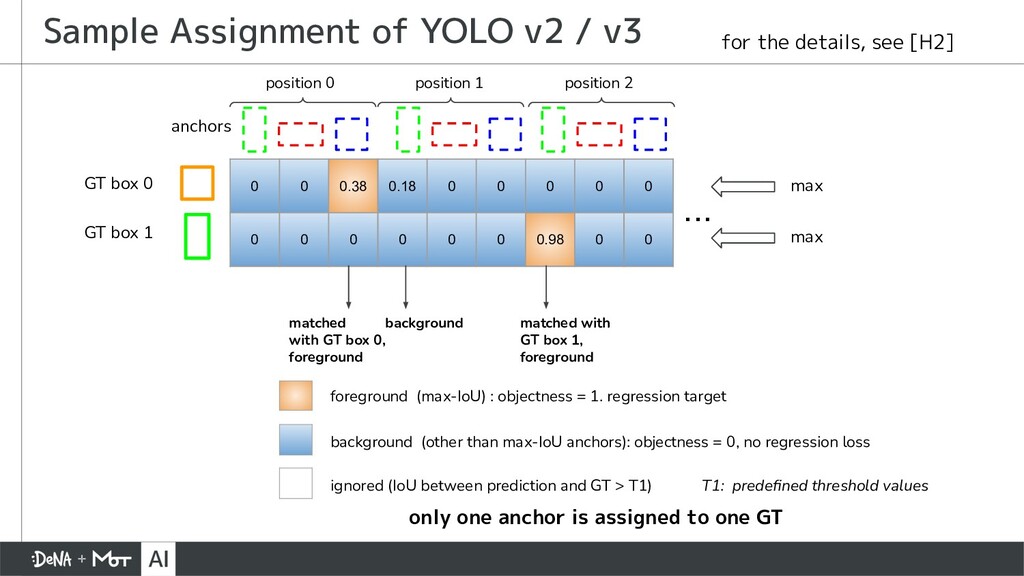{kind=link}
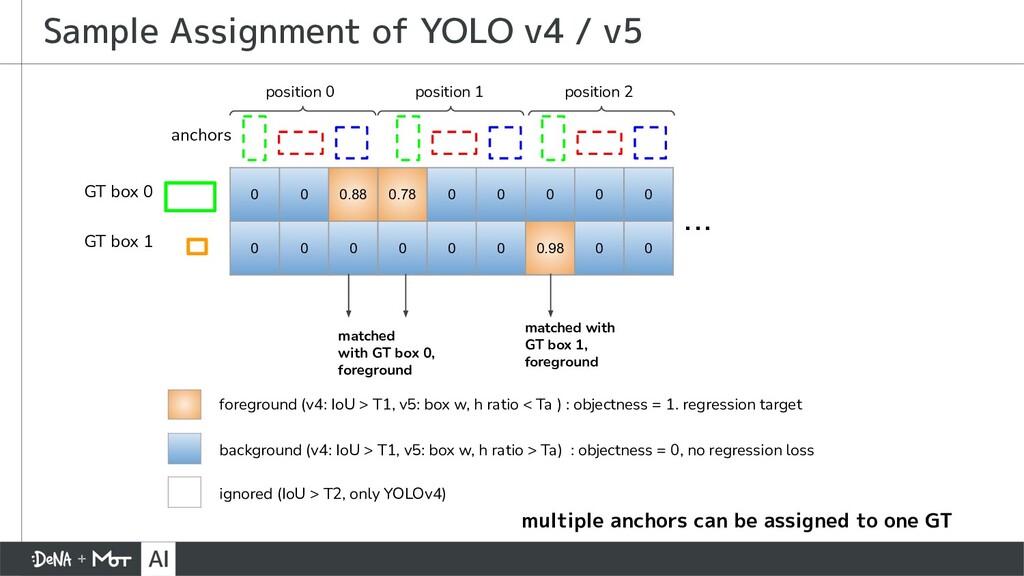{kind=link}
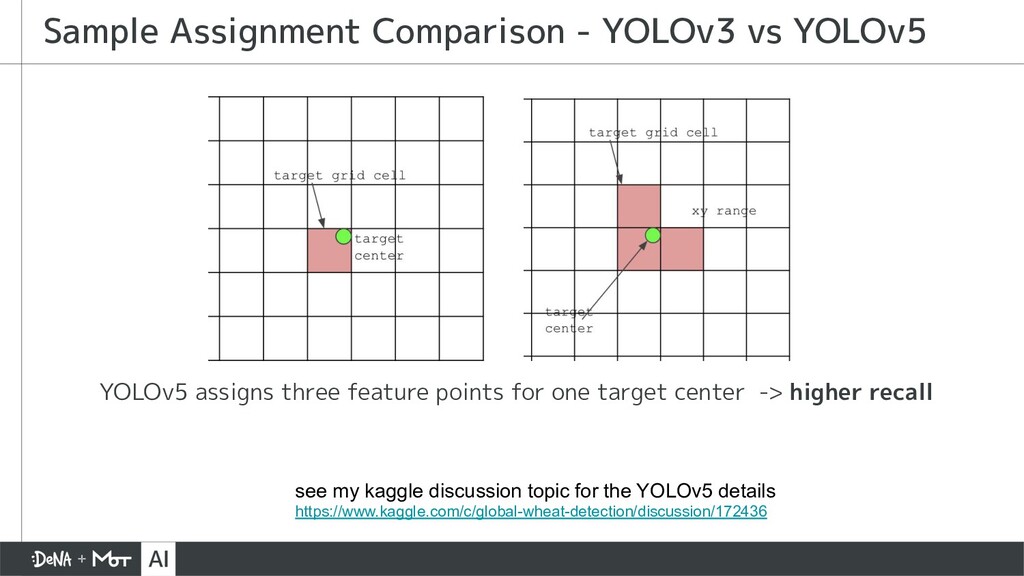{kind=link}
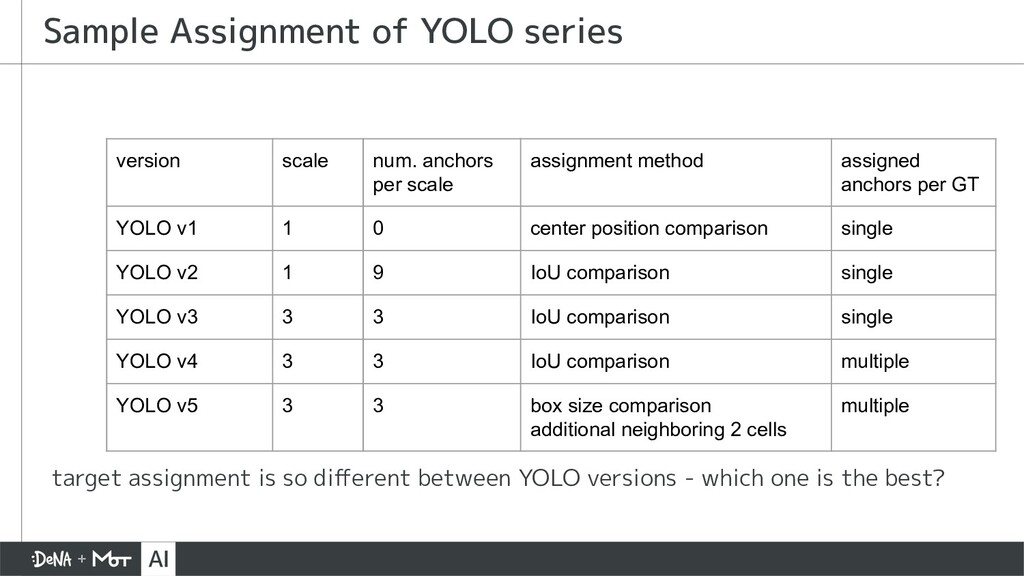{kind=link}
{kind=link}
{kind=link}
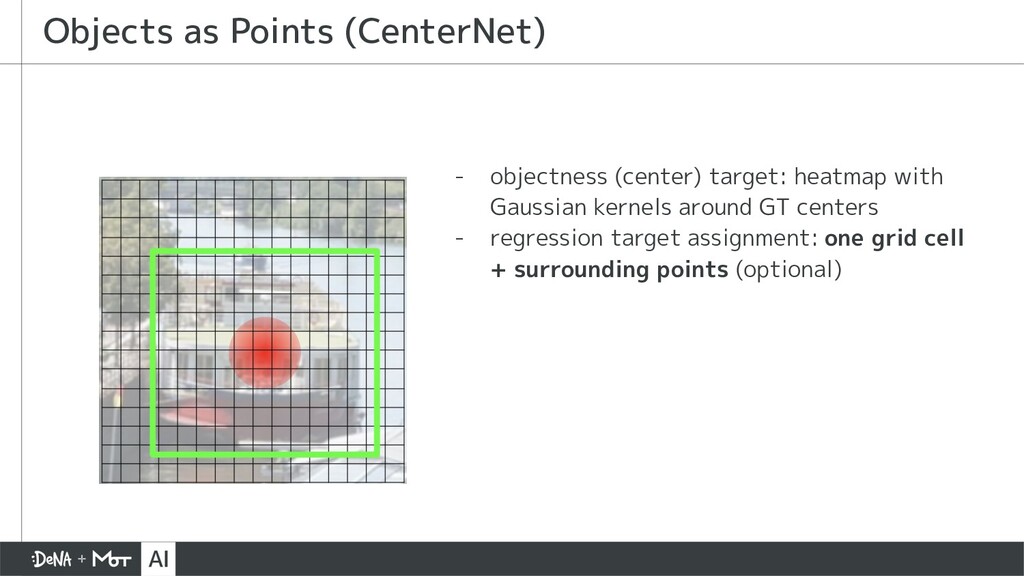{kind=link}
{kind=link}
{kind=link}
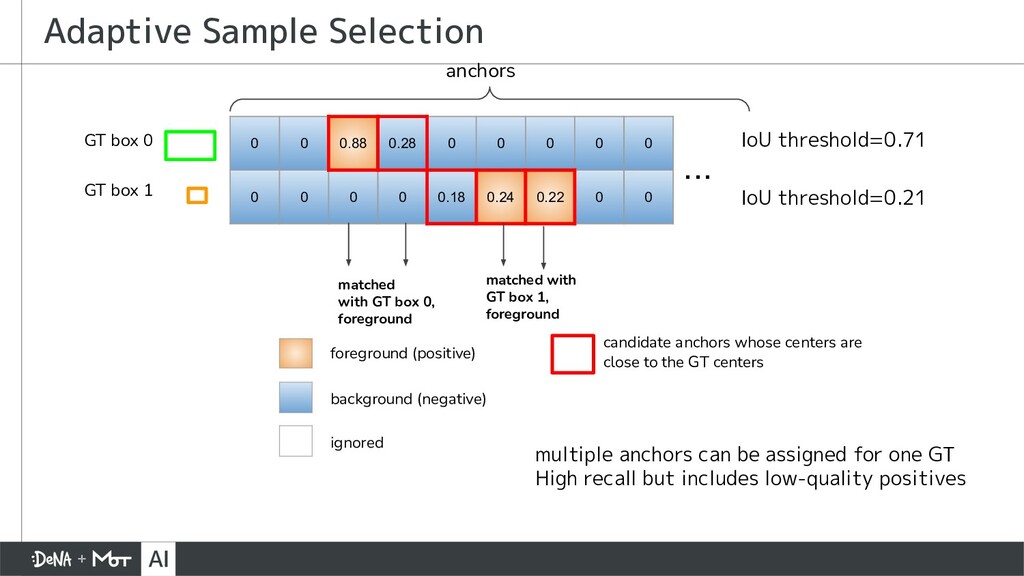{kind=link}
{kind=link}
![[1] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.](https://files.speakerdeck.com/presentations/a8ca5e8787024a3995f28fe07eae2224/slide_37.jpg){kind=link}
![Hiroto Honda’s medium blogs [H1] Digging Into Detectron 2 [part](https://files.speakerdeck.com/presentations/a8ca5e8787024a3995f28fe07eae2224/slide_38.jpg){kind=link}
{kind=link}