本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
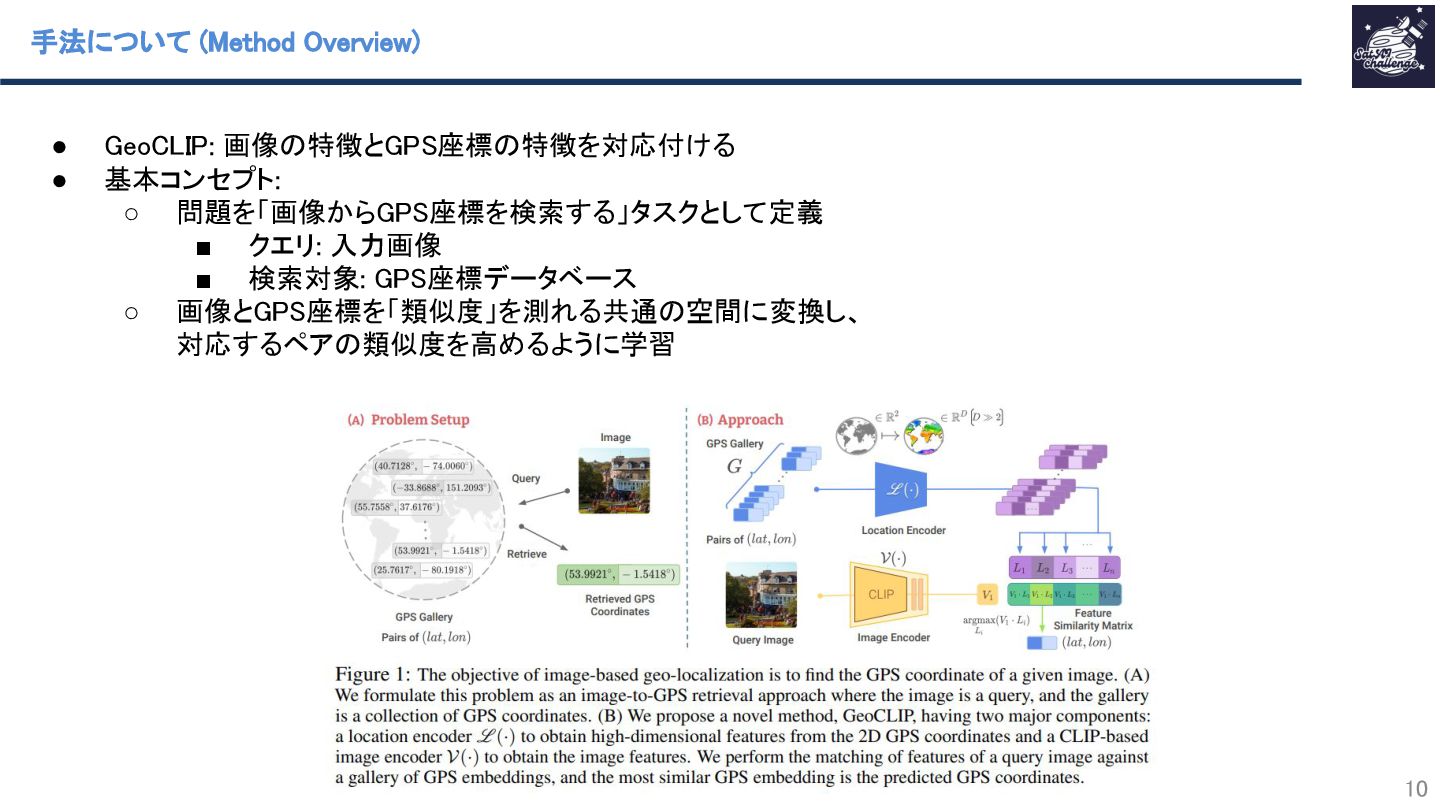
紹介する論文は、「GeoCLIP: Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization」です。 本研究では、全世界のどこで撮影された画像からでもそのGPS座標を特定するタスクにおいて、画像の特徴とGPS座標の特徴を直接結びつけるCLIPに着想を得た検索ベースの手法(GeoCLIP)を提案しています。GeoCLIPによって、少ない訓練データ(全体の20%)でも競争力のある高い精度が得られ、さらに画像だけでなくテキスト情報を用いた地理位置情報の特定も可能になります。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Image Encoder (V(·)): ◦ CLIP ViT[15] (凍結) +](https://files.speakerdeck.com/presentations/2191f66d83d04b4ba7fc6883d7ee81c9/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Table 1 (a) Results on the Im2GPS3k [7] dataset](https://files.speakerdeck.com/presentations/2191f66d83d04b4ba7fc6883d7ee81c9/slide_19.jpg){kind=link}
{kind=link}
{kind=link}