t-SNE とは?
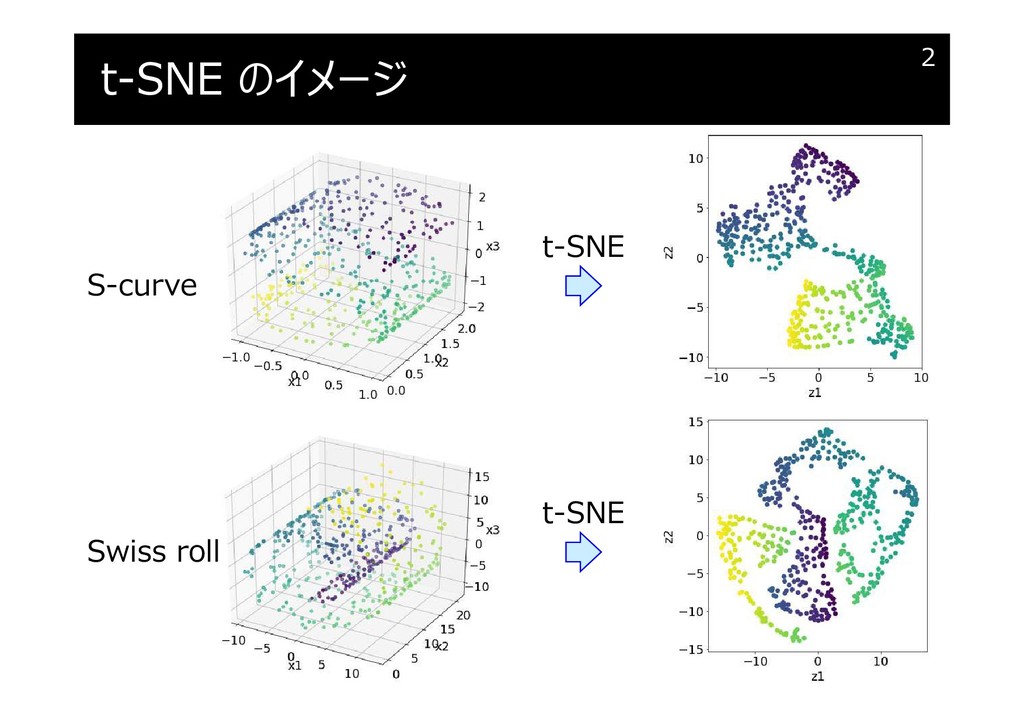
t-SNE のイメージ
文字の定義
前処理
t-SNEでは何をしているか?
p(x(i), x(j)) って何?
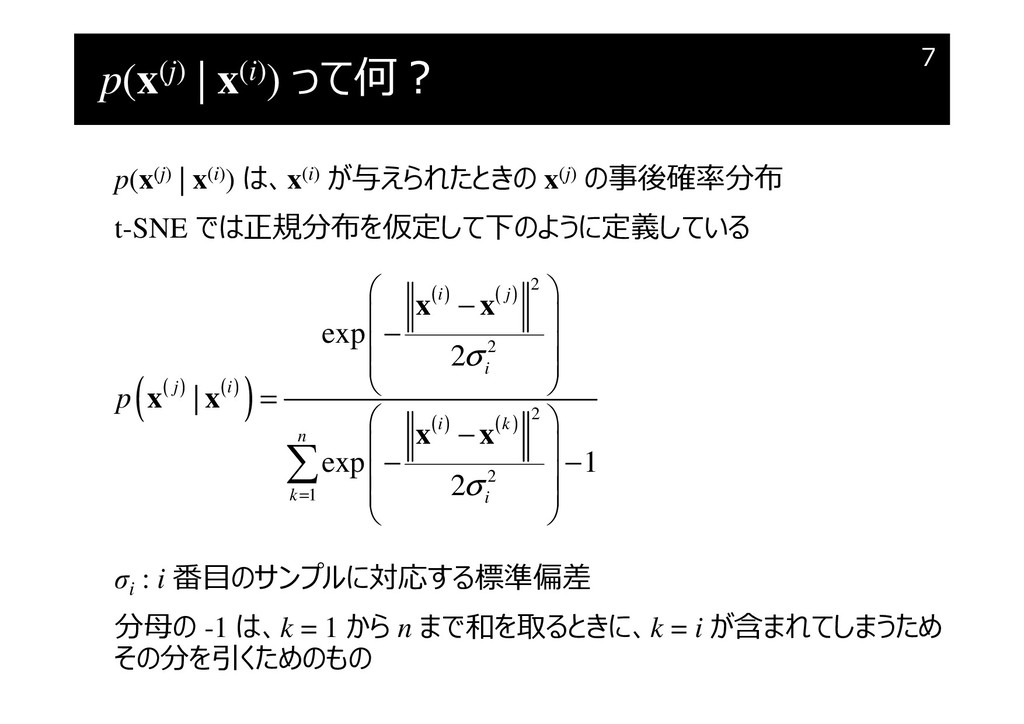
p(x(j) | x(i)) って何?
x(i) と x(j) の距離と p(x(i), x(j)) の関係
p(x(i) | x(j)) の σi はどうする?
p(z(i), z(j)) って何?
p(z(i), z(j)) の式
目的関数 C の最小化
z(i) の初期値
t-SNE をやってみる
perplexity をどう決めるか?
参考文献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![p(z(i), z(j)) の式 11 t-SNE では⾃由度1の (スチューデントの) t 分布 [1]](https://files.speakerdeck.com/presentations/4c641e97b21c4189aa54e33e1d1b17da/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}