Abstract
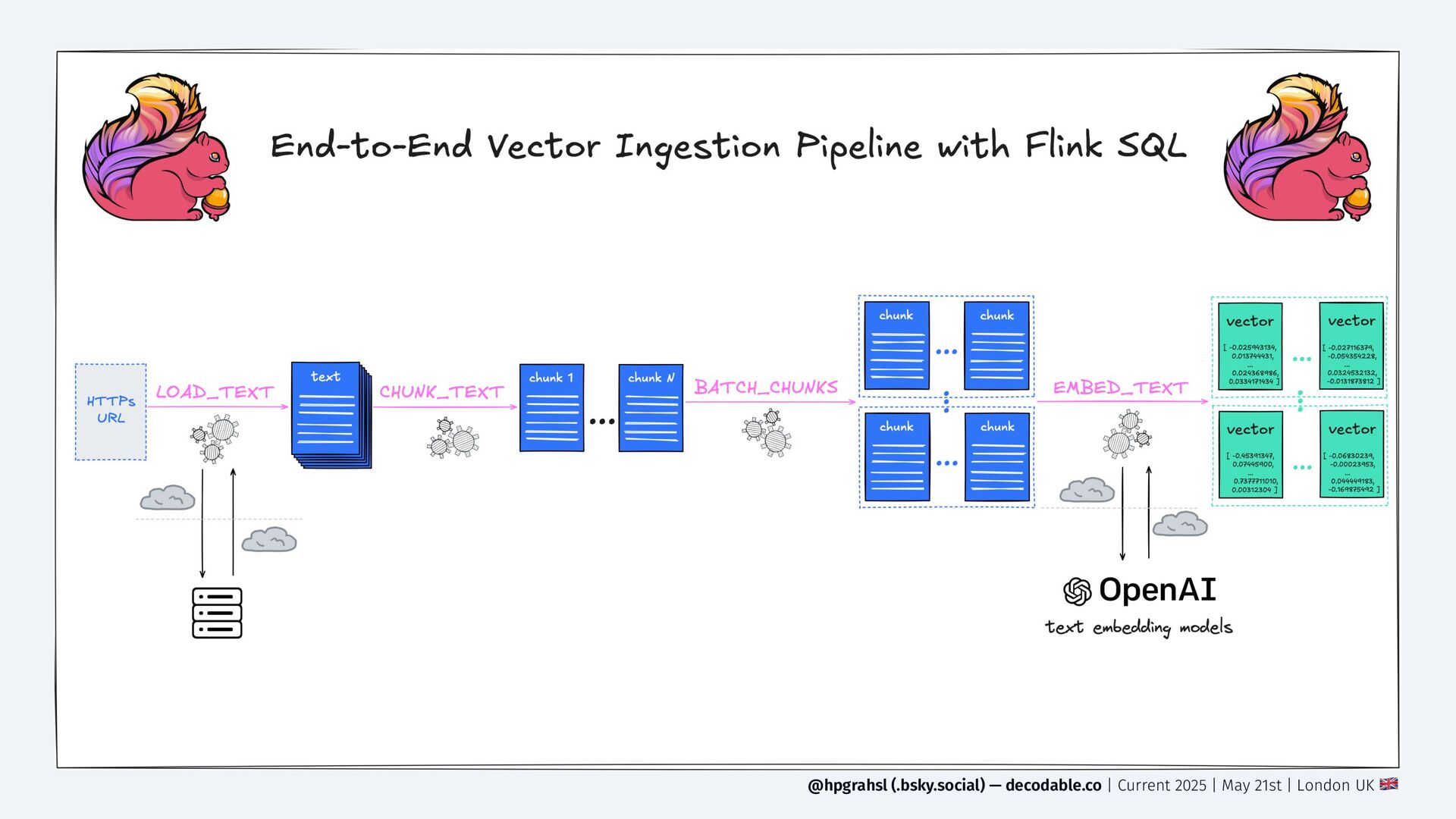
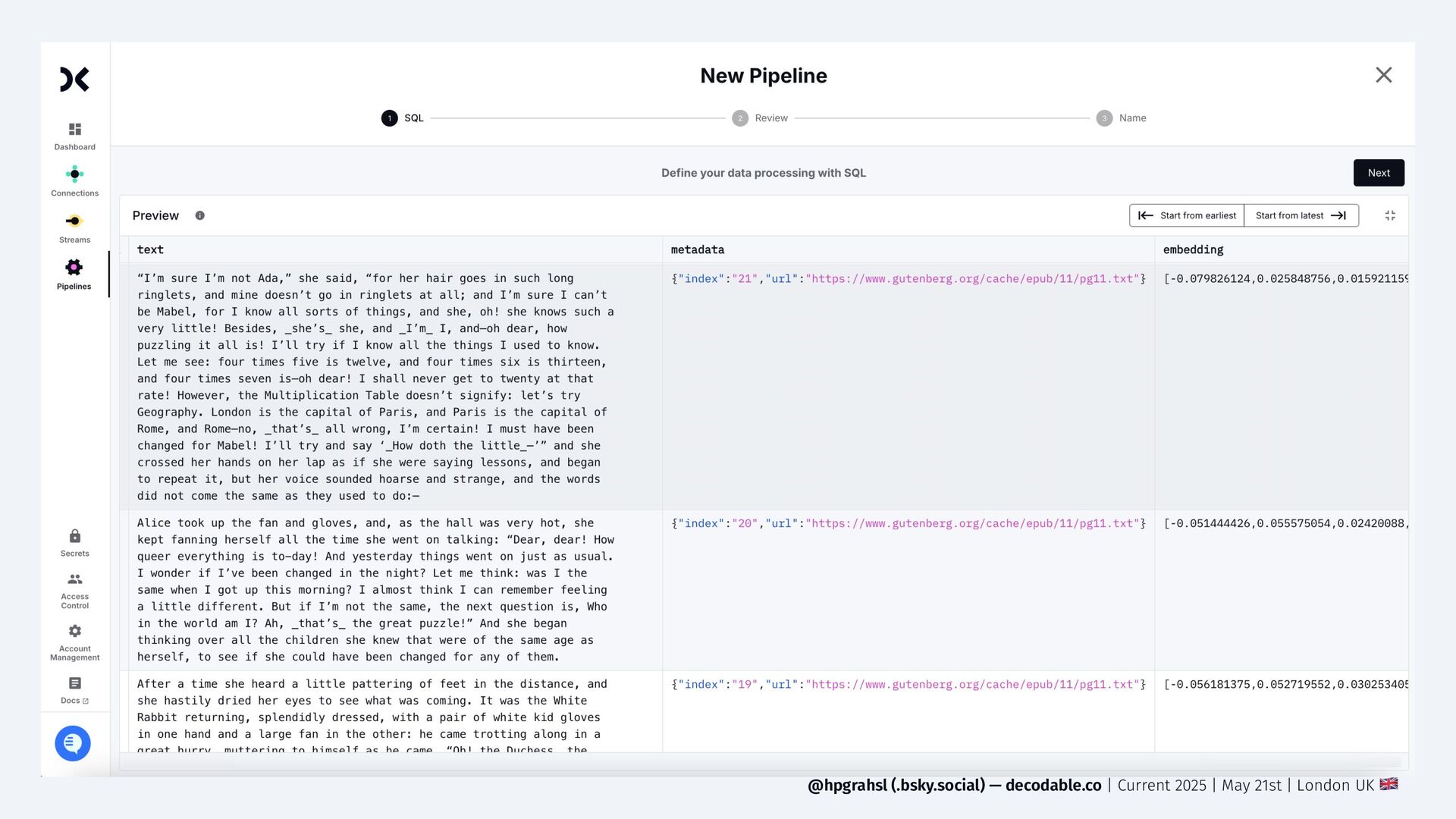
Retrieval-Augmented Generation (RAG) has become a foundational paradigm that augments the capabilities of language models—small or large—by attaching information stored in vector databases to provide grounding data. While the concept is straightforward, maintaining up-to-date embeddings as data constantly evolves across various source systems remains a persistent challenge. This lighting talk explores how to build a real-time vector ingestion pipeline on top of Apache Flink and its extensive connector ecosystem to keep vector stores fresh at all times seamlessly. To eliminate the need for custom code while still preserving a reasonable level of configurability, a handful of composable user-defined functions (UDFs) are discussed to address loading, parsing, chunking, and embedding of data directly from within Flink's Table API or Flink SQL jobs. Easy-to-follow examples demonstrate how the discussed approach helps to significantly lower the entry barrier for RAG adoption, ensuring that retrieval remains consistent with your latest knowledge.
Recording:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
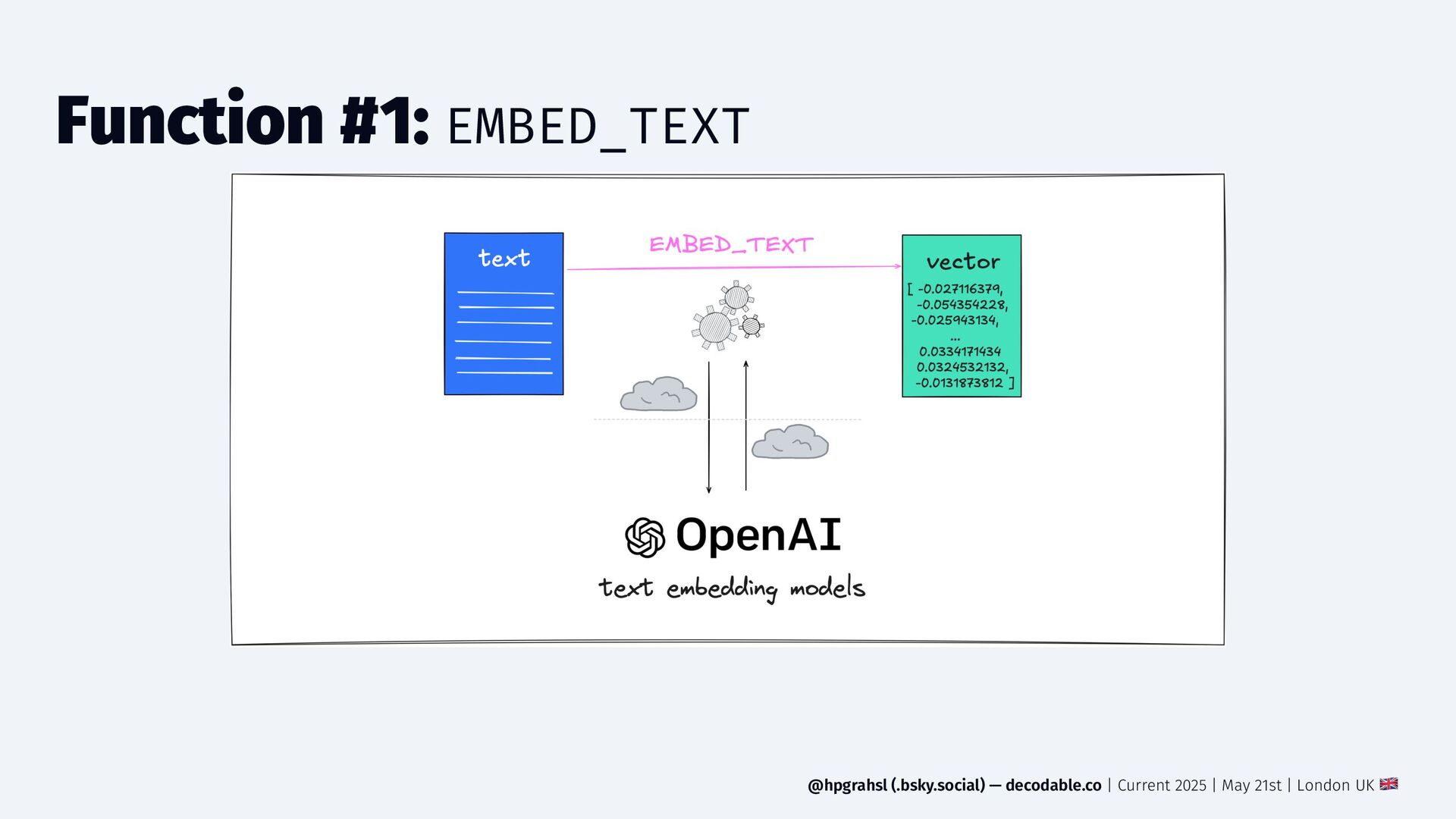{kind=link}
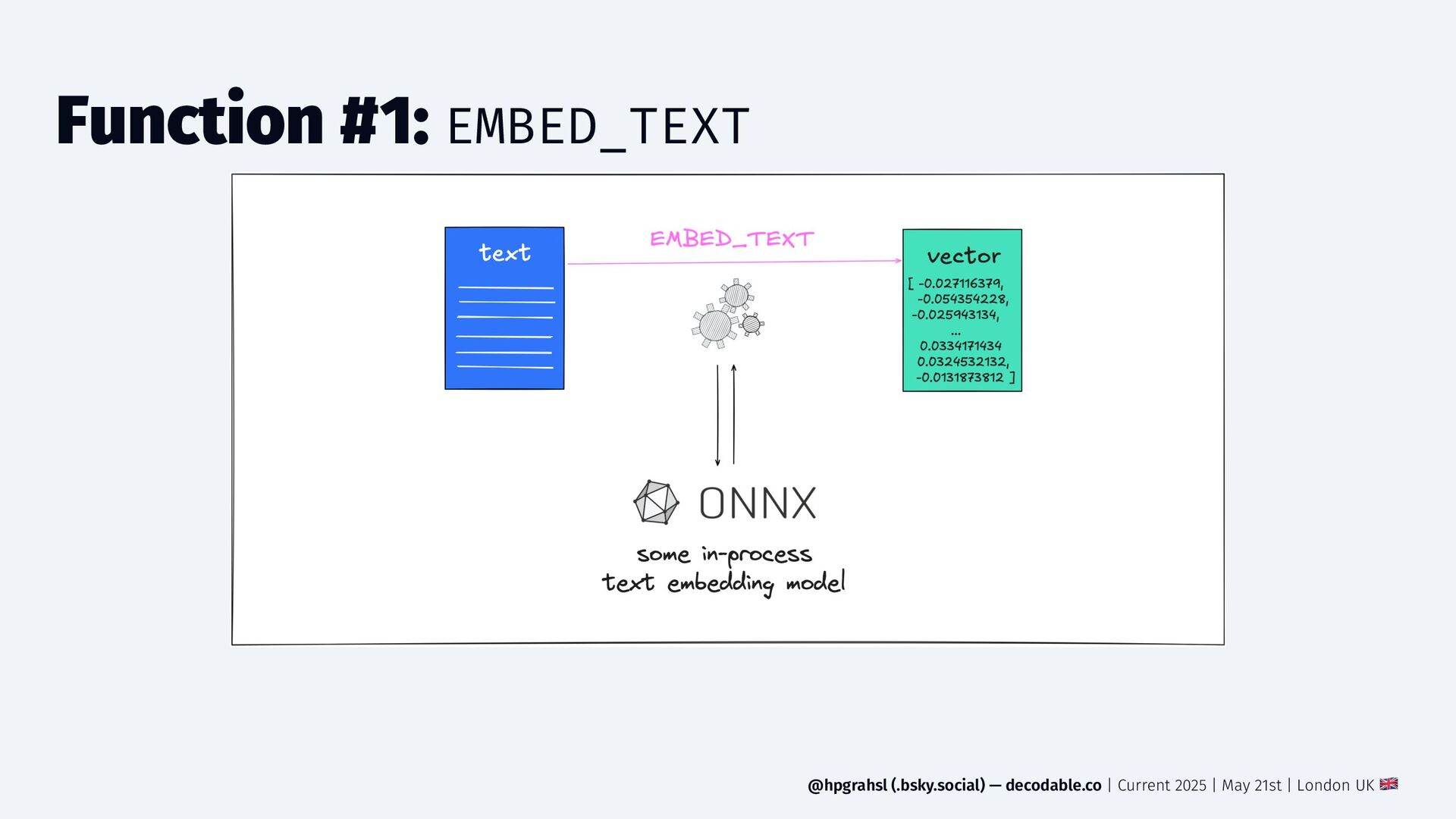{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
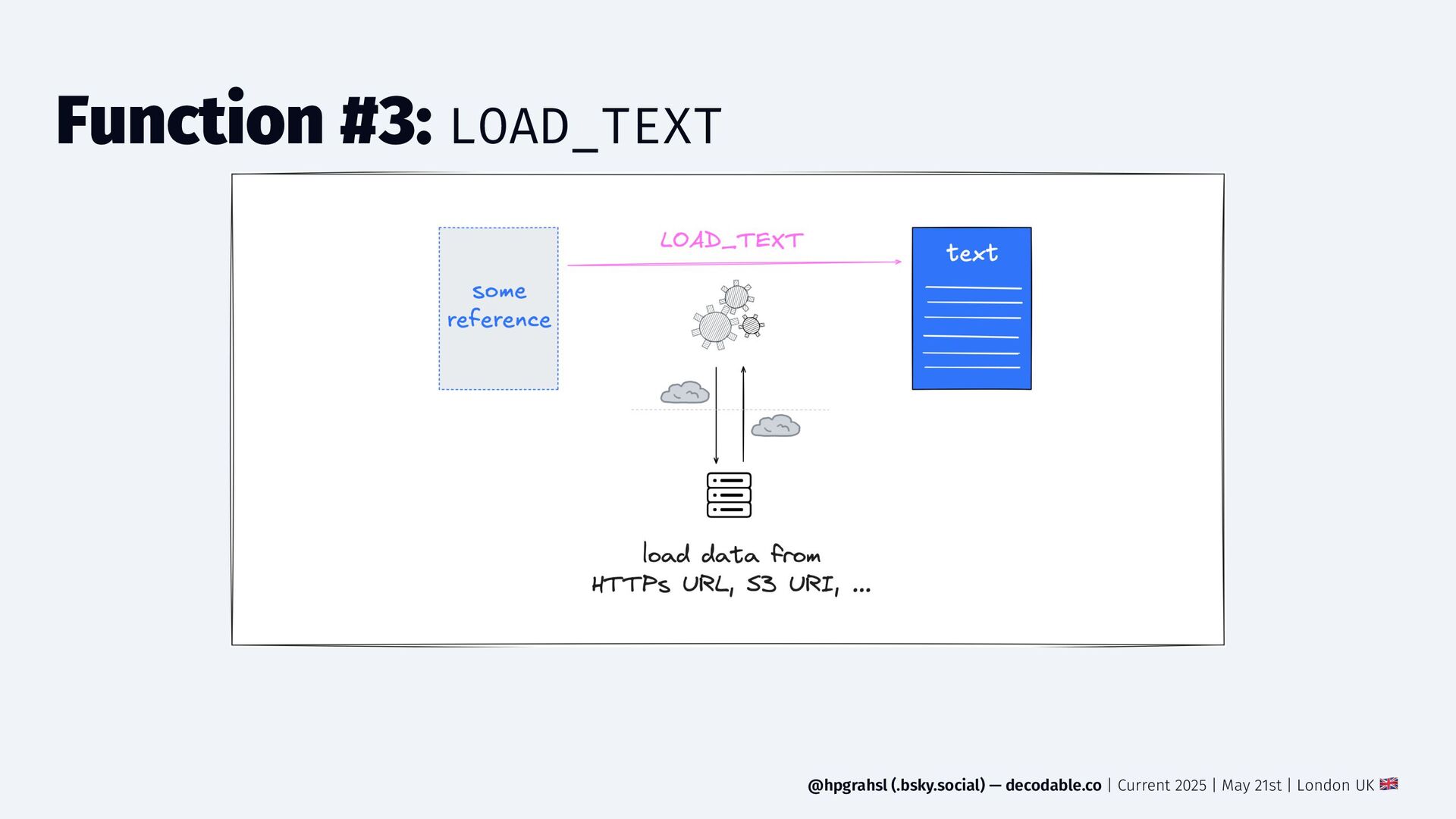{kind=link}
{kind=link}
{kind=link}
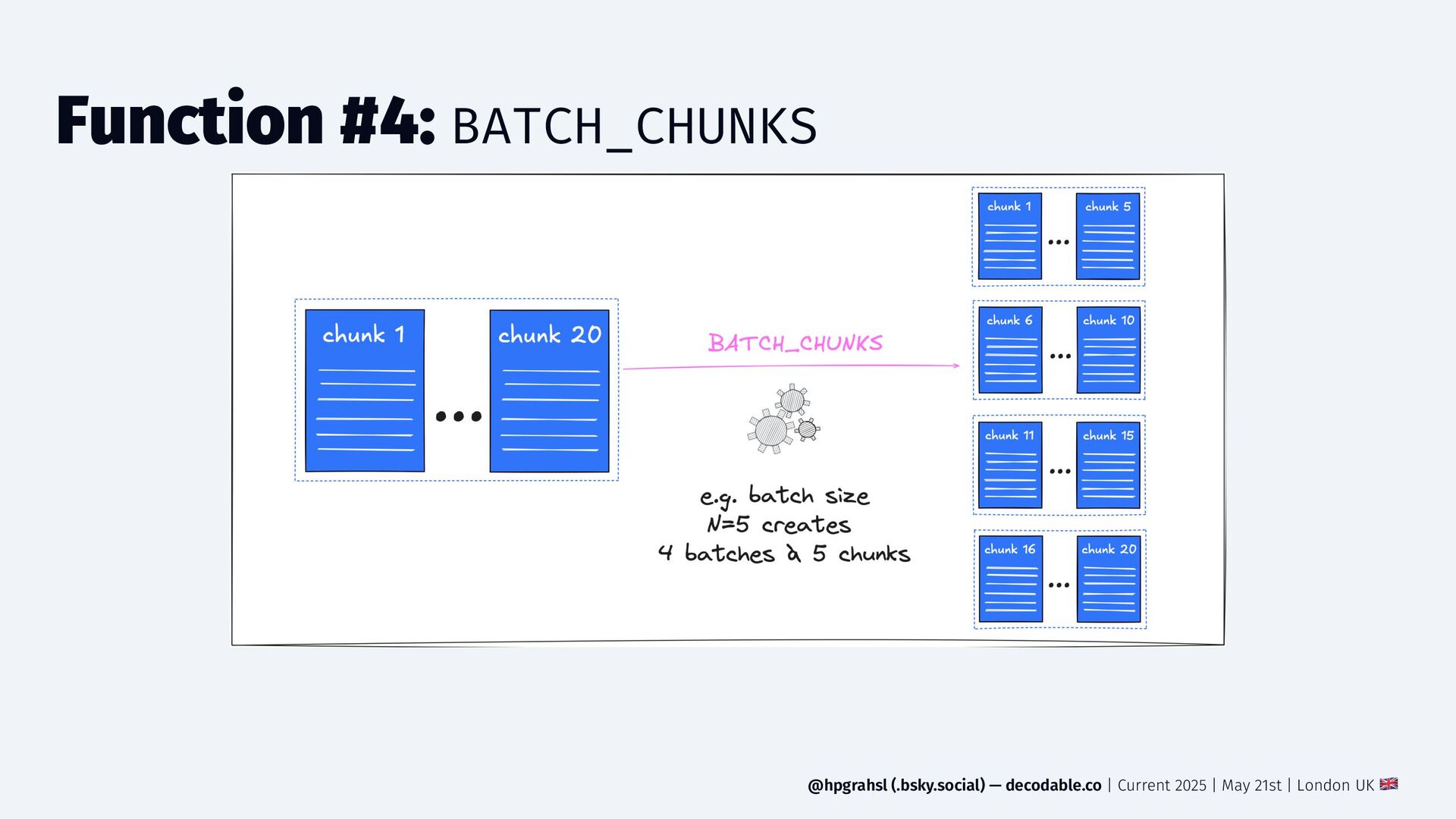{kind=link}
![Function #4: BATCH_CHUNKS (sync) public class BatchChunksUdtf extends TableFunction<String[]> {](https://files.speakerdeck.com/presentations/2abee217c04c40bba358cf107f470002/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}