values • Weights: ~a factor that influences transforming a value between layers • Training: fiddle with the weights until output approximates known input • Result of training → collection of weights (numbers)
on previous words • Context window • Training: show text, mask next word, calculate accuracy of prediction ♻ • Inference: start with input sentence, predict word, add to input sentence ♻
token based on previous tokens • Context window • Training: show tokens, mask next token, calculate accuracy of prediction ♻ • Inference: start with input tokens, predict next token, add to input tokens ♻
Can predict next token, not an assistant ◦ 💸💸💸💸 (1000’s of GPUs, $5-100 million) • Fine tuning: continue training to create assistant model ◦ Training text is structured conversation ideal examples (~10k - 100k+ examples) • Human preference tuning ◦ Further fine tuning by generating responses and selecting the best ones ◦ “Alignment”, “Safety” etc Type of models
◦ Reduces accuracy, but is generally OK ◦ Other optimisations possible • Train smaller models (less parameters) • Both • Or: train specialized ultra small model (llama2.c) (megabytes vs gigabytes) Shrinking LLMs
source research model • 2.7b parameters w/ performance of 13b parameters model • Quantized model can run on a phone • https://huggingface.co/microsoft/phi-2 Small LLM: Phi-2
used for training ◦ Except for enterprise editions • OpenAI API → data not used for training • Google Gemini…it depends ◦ TL;DR Gemini API (not available in the EU) may train on your users data ◦ The Google Cloud Platform Vertex API has different terms and does not
& GPU ◦ Supports many model architectures, like Phi-2 and Gemma ◦ Moves very fast (multiple releases a day) • Candle → ML framework from 🤗 written in Rust 😅 • Gemma.cpp • Mediapipe (crashes on a real device ) • Gemini nano → Only on select high end devices, currently EAP
of source ◦ (Sometimes) Easier for simple cases ◦ Can be convenient for testing, e.g. run cmd line tools on device, import .so w/ cmake ◦ Hard to maintain https://developer.android.com/ndk/guides/cmake#command-line
use cmake ◦ Even if they do…😬 • Options: precompile dependencies or include all source • NDK prefab packages ◦ AAR containing libs + headers ◦ Mixed results producing and consuming with cmake
file size • Acceptable performance with room for improvement • llama.cpp runs open source, fine tuned (by you) models, no restrictions • For real apps maybe prefer a JNI layer with only what you use Conclusions
![LLMs on small devices Hugo Visser @botteaap [email protected]](https://files.speakerdeck.com/presentations/c5d4b49bea114429adfaac31f10907bb/slide_0.jpg){kind=link}
{kind=link}
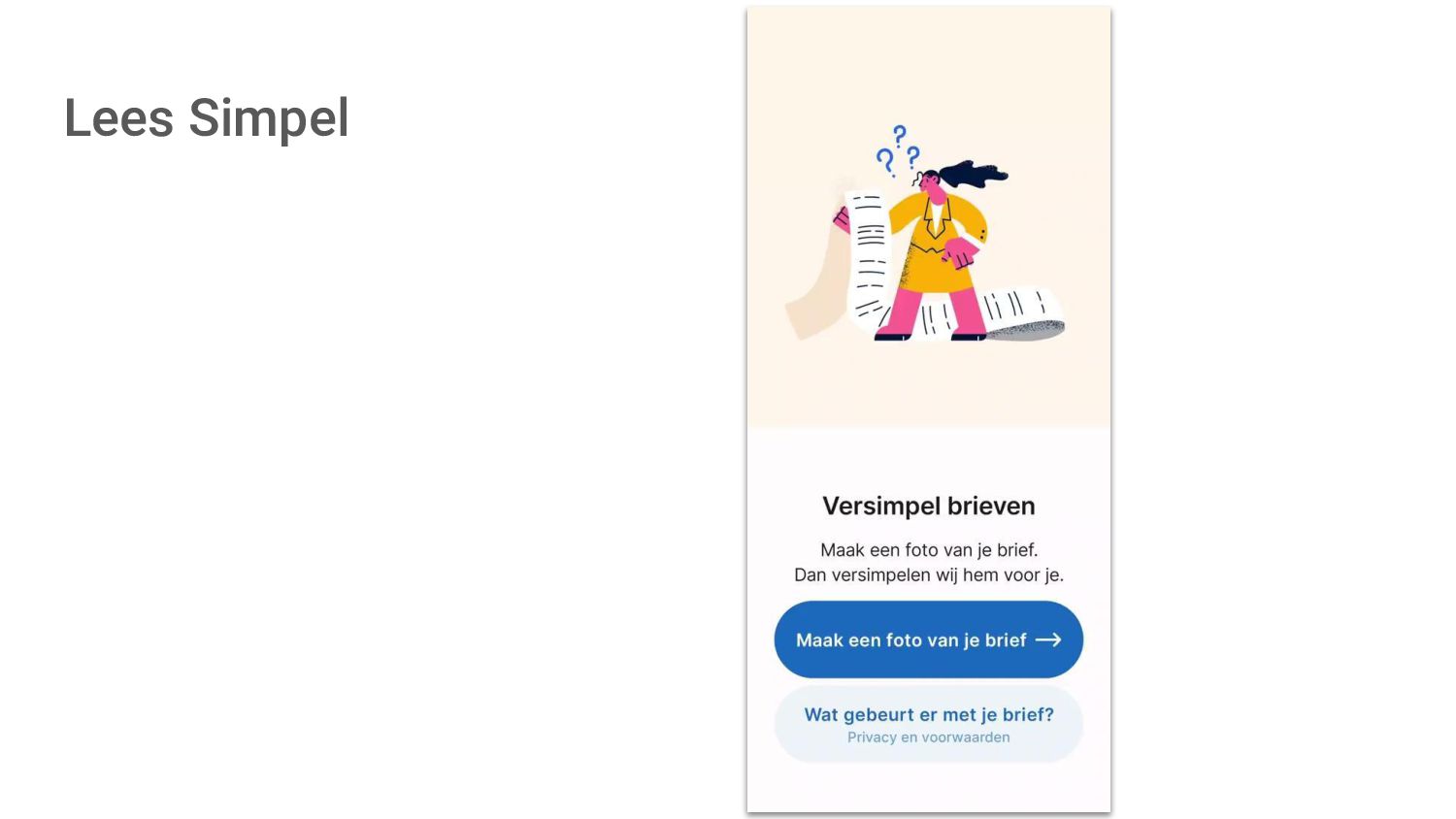{kind=link}
{kind=link}
{kind=link}
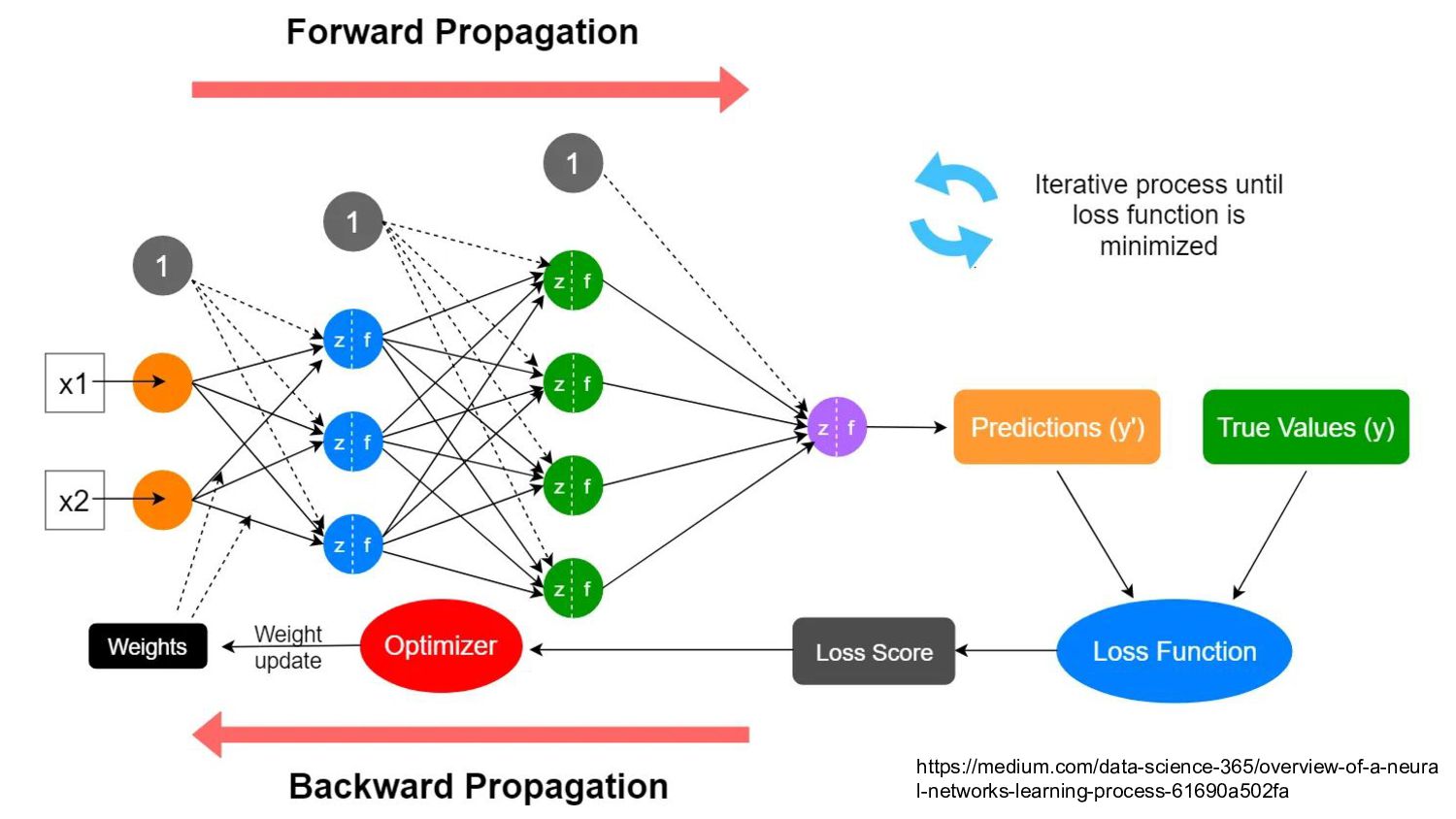{kind=link}
{kind=link}
{kind=link}
{kind=link}
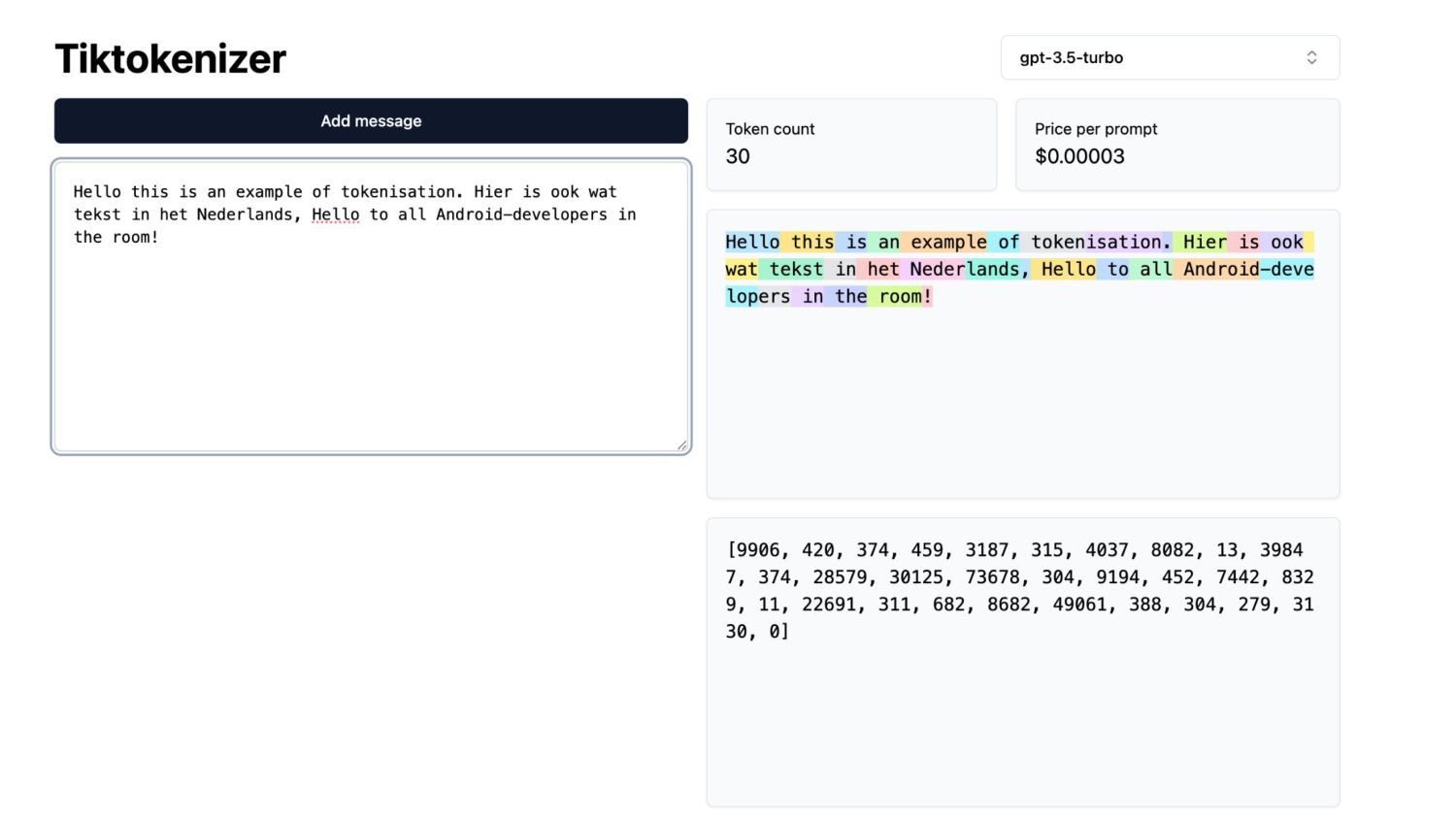{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LLMs on small devices Hugo Visser @botteaap [email protected]](https://files.speakerdeck.com/presentations/c5d4b49bea114429adfaac31f10907bb/slide_31.jpg){kind=link}