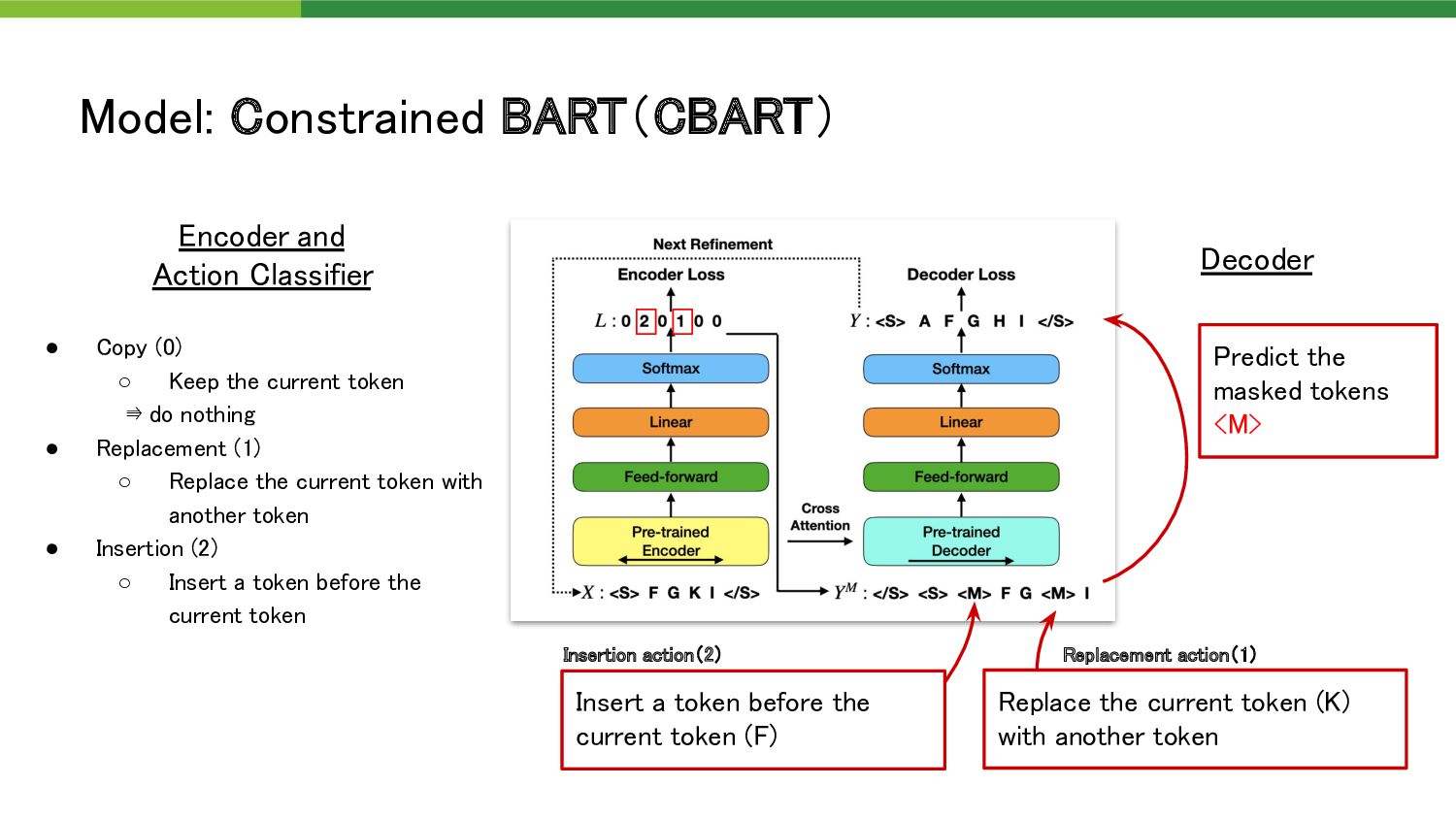
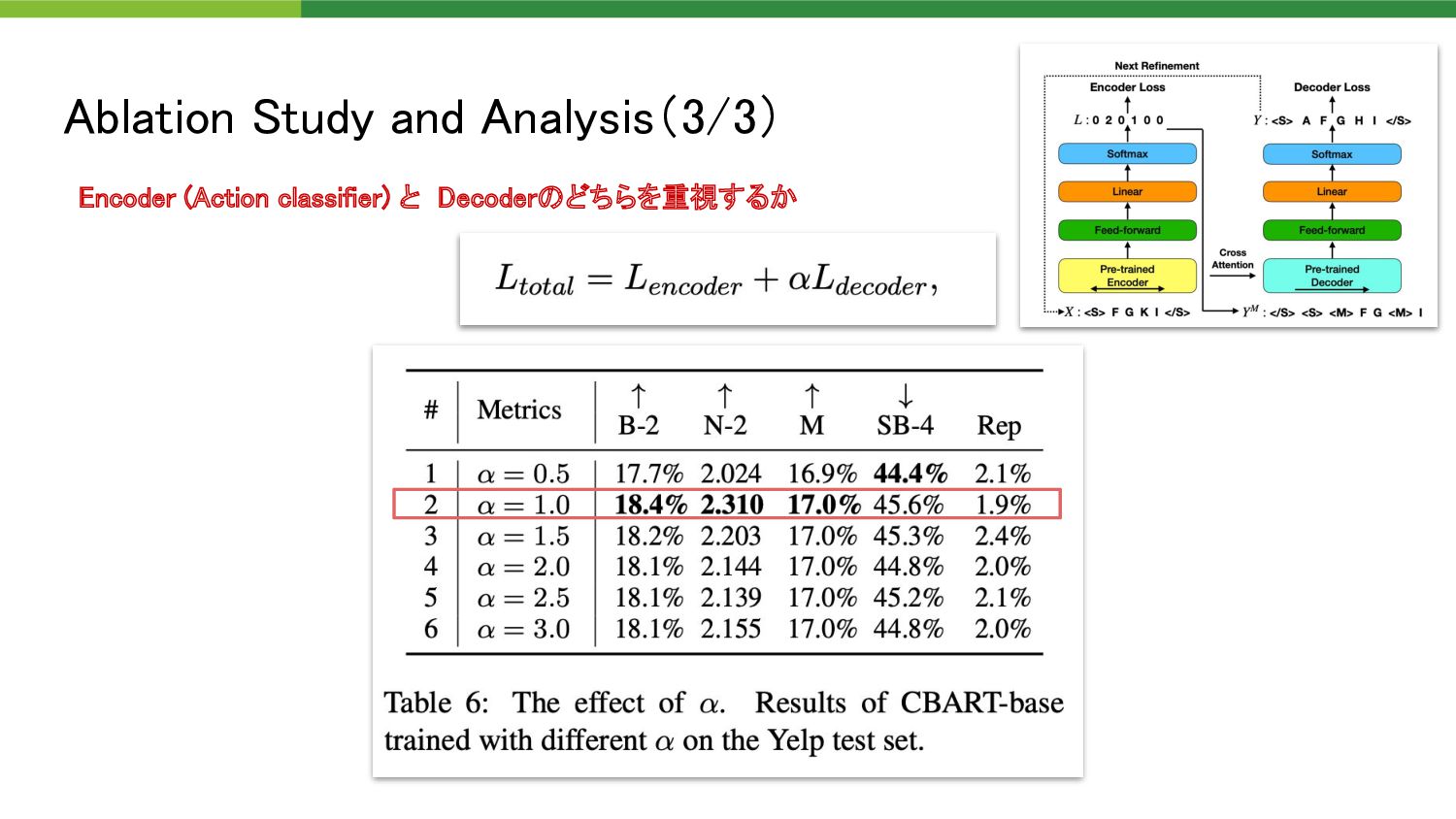
the masked tokens <M> • Copy (0) ◦ Keep the current token ⇛ do nothing • Replacement (1) ◦ Replace the current token with another token • Insertion (2) ◦ Insert a token before the current token Insert a token before the current token (F) Replace the current token (K) with another token Insertion action(2) Replacement action(1)
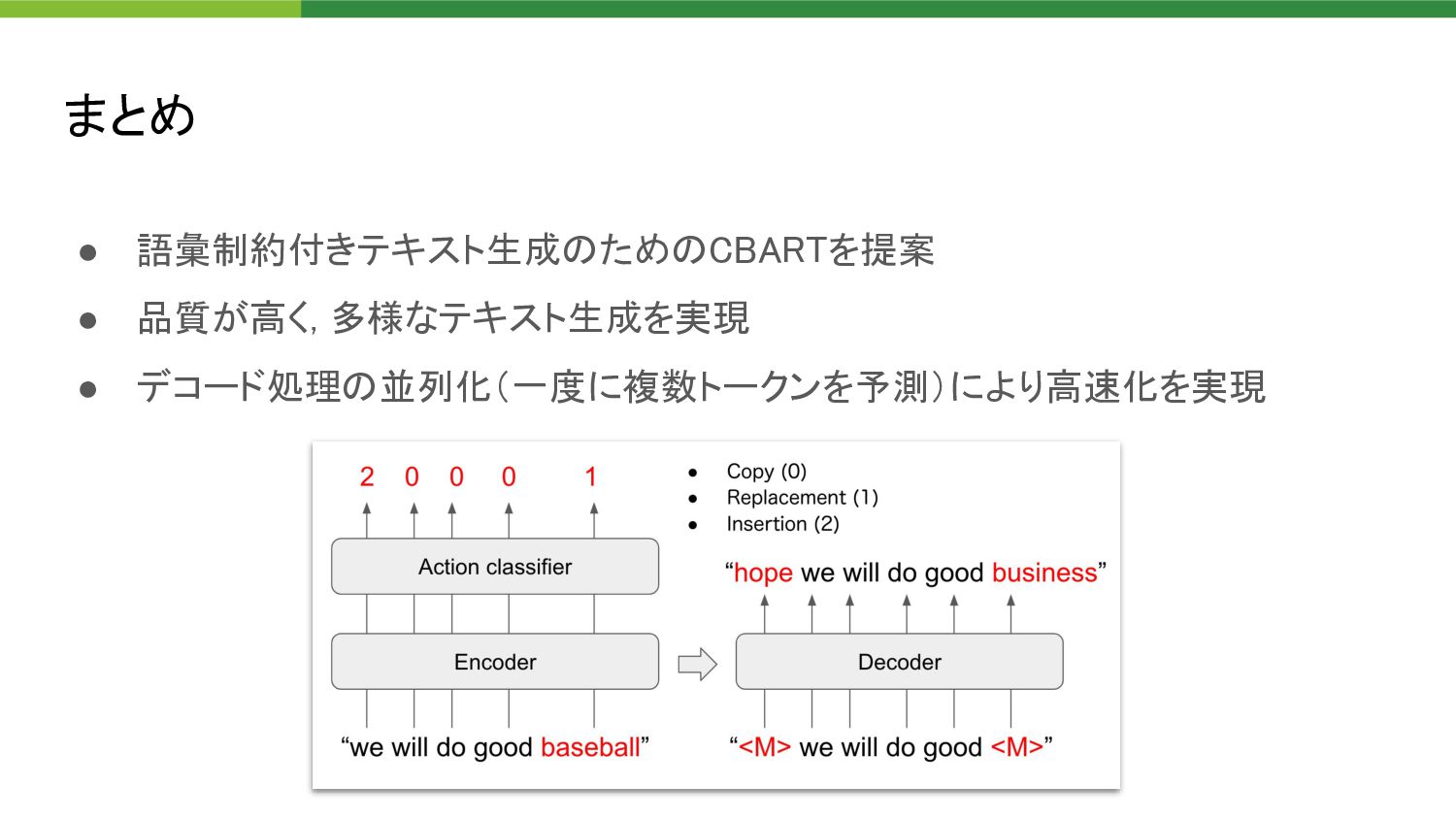
business together . ” “we will do good business” 【Example】 “we will do good baseball” 原文 原文から任意のトー クン列を抽出 15%をランダムなトー クンに置換 “<M> we will do good <M>” 2 0 0 0 1 Action classifierのラベル作成 • Copy (0) • Replacement (1) • Insertion (2)
baseball” Encoder Action classifier Decoder 2 0 0 0 1 “<M> we will do good <M>” “hope we will do good business” • Copy (0) • Replacement (1) • Insertion (2)
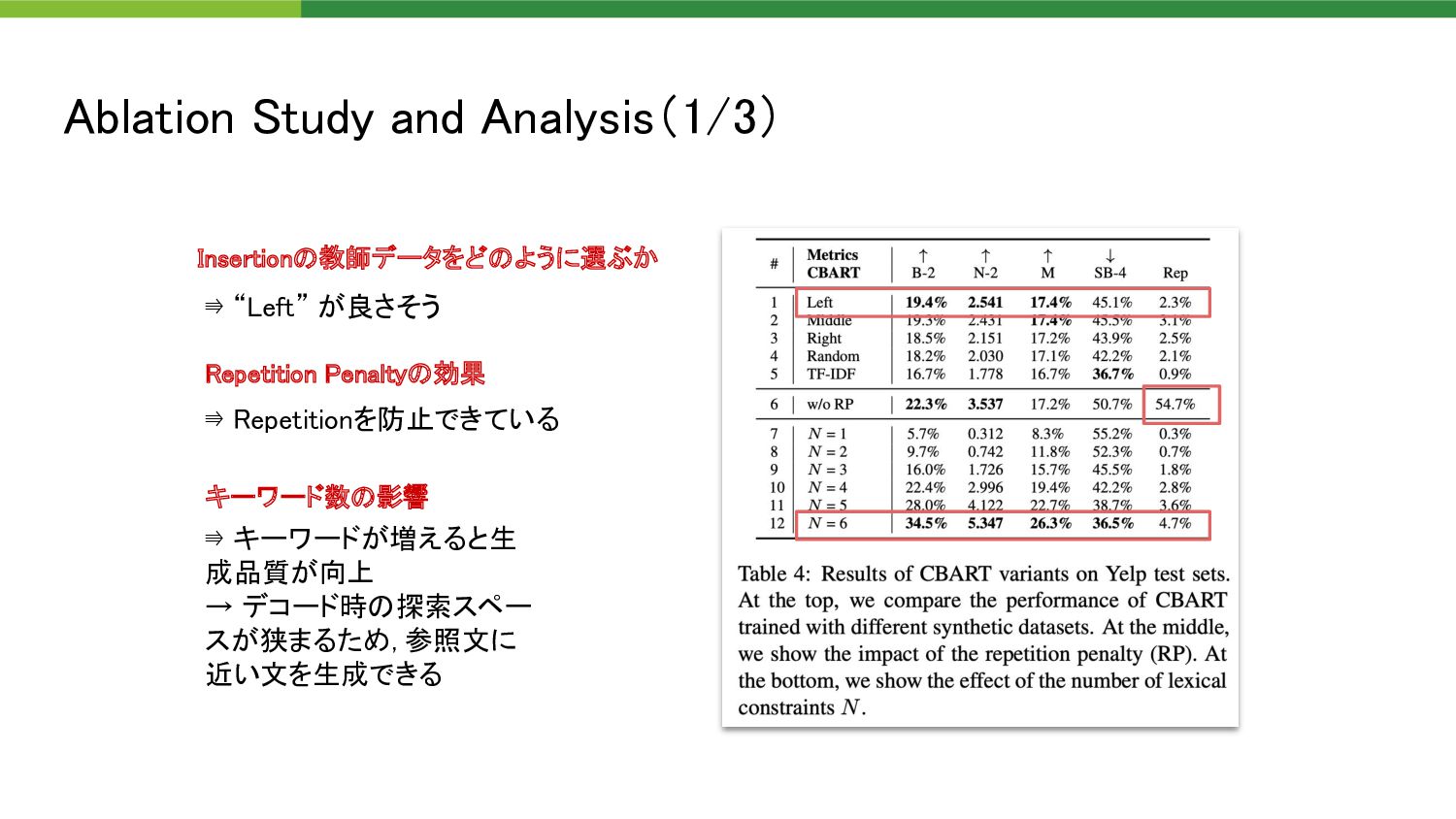
do good business together . ” “we will do good business” 【Example】 “we will do good baseball” 原文 原文から任意のトー クン列を抽出 15%をランダムなトー クンに置換 “<M> we will do good <M>” 2 0 0 0 1 Action classifierのラベル作成 • Copy (0) • Replacement (1) • Insertion (2) Insertionの教師データをどのように選ぶか ⇛ {Right, Left, Middle, Rand, TF-IDF}
{kind=link}
{kind=link}
![Background: BART [Lewis+2019] • BART: Denoising Sequence-to-Sequence Pre-training for](https://files.speakerdeck.com/presentations/bd586c6c6c2c4bcfa91bcb9a9c5c87f5/slide_2.jpg){kind=link}
![Background: Non-Autoregressive Decoding BART [Lewis+2019] Autoregressive Decoding Levenshtein](https://files.speakerdeck.com/presentations/bd586c6c6c2c4bcfa91bcb9a9c5c87f5/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}