Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Cassandra for Data Analytics Backends
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
αλεx π
September 24, 2015
Research
460
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Cassandra for Data Analytics Backends
αλεx π
September 24, 2015
More Decks by αλεx π
See All by αλεx π
Scalable Time Series With Cassandra
ifesdjeen
1
420
Bayesian Inference is known to make machines biased
ifesdjeen
2
400
Stream Processing and Functional Programming
ifesdjeen
1
790
PolyConf 2015 - Rocking the Time Series boat with C, Haskell and ClojureScript
ifesdjeen
0
530
Clojure - A Sweetspot for Analytics
ifesdjeen
8
2.1k
Going Off Heap
ifesdjeen
3
1.9k
Always be learning
ifesdjeen
1
190
Learn Yourself Emacs For Great Good workshop slides
ifesdjeen
3
350
What Reading 5 Papers can yield for your Business
ifesdjeen
0
390
Other Decks in Research
See All in Research
Cross-Media Human-Information Interaction
signer
PRO
0
120
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
230
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
450
COMETAを用いたデータ民主化運動の歴史
sazimai
0
110
議論 学術ムーブメントを成功させるために何が必要なのだろうか
rmaruy
0
100
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
640
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
Featured
See All Featured
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
The Limits of Empathy - UXLibs8
cassininazir
1
510
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Navigating Team Friction
lara
192
16k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
350
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
The Curse of the Amulet
leimatthew05
2
13k
Transcript
@ifesdjeen
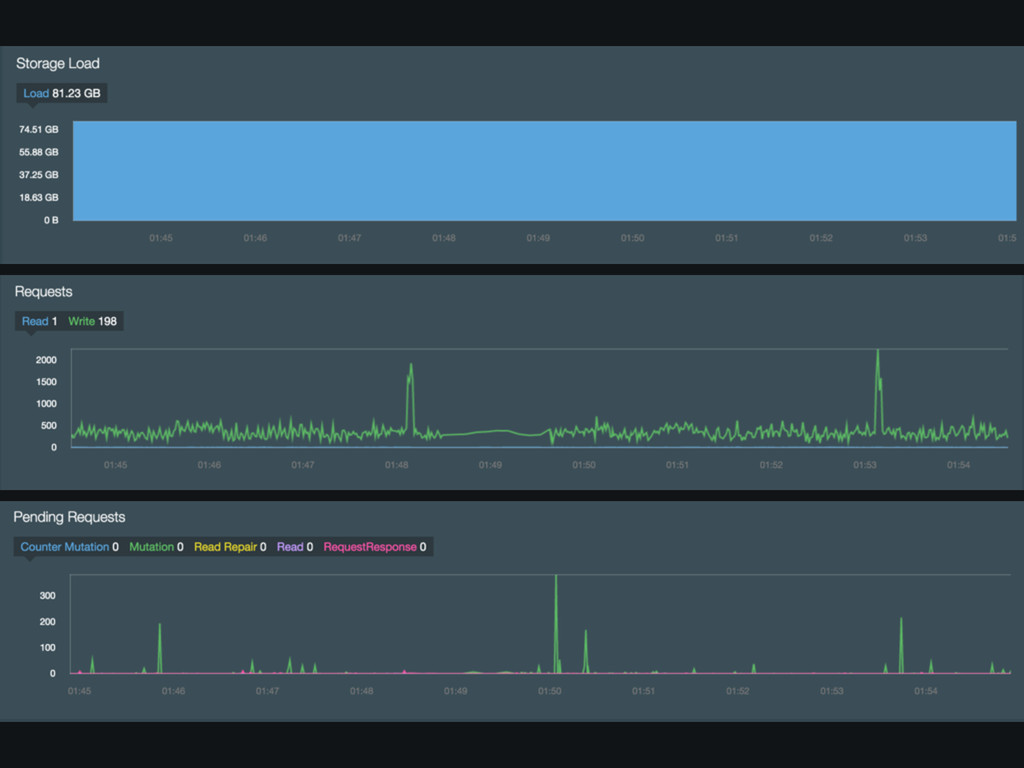
Cassandra Monitoring
None
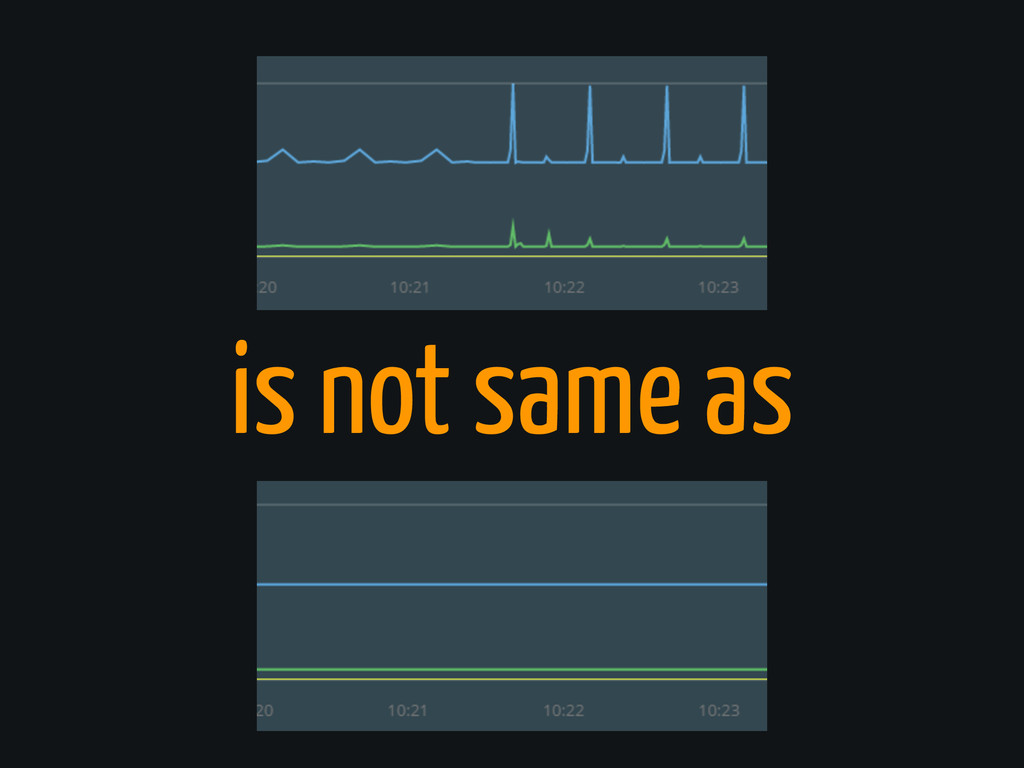
Precision
is not same as
Semantics
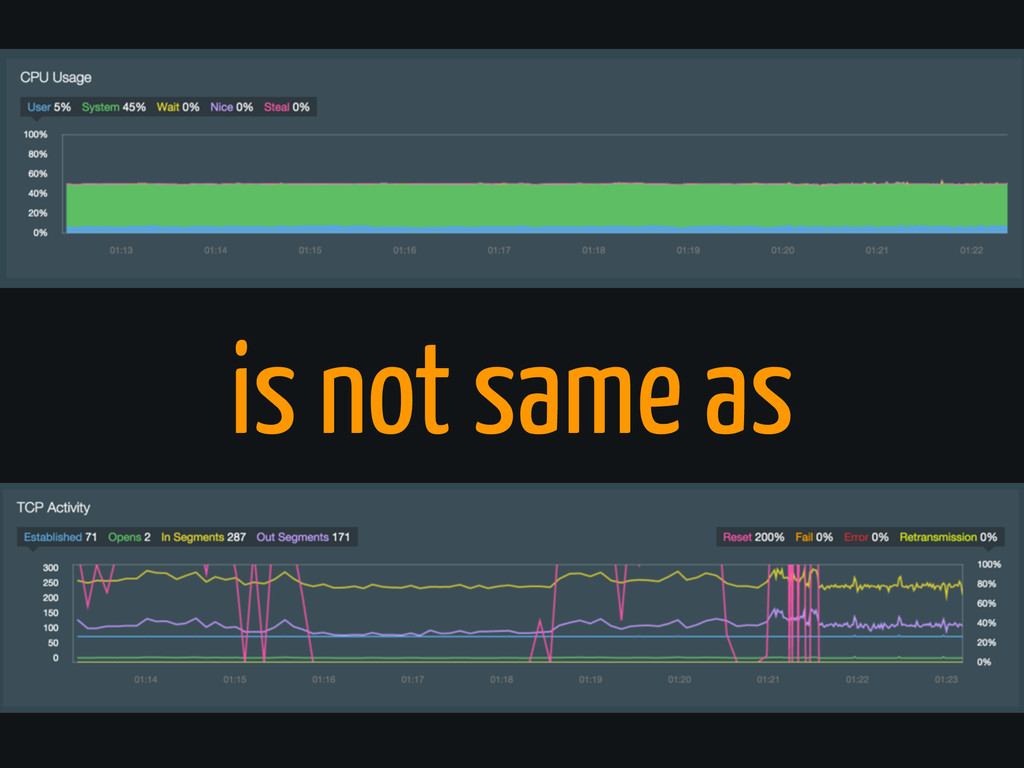
is not same as
Anomaly detection
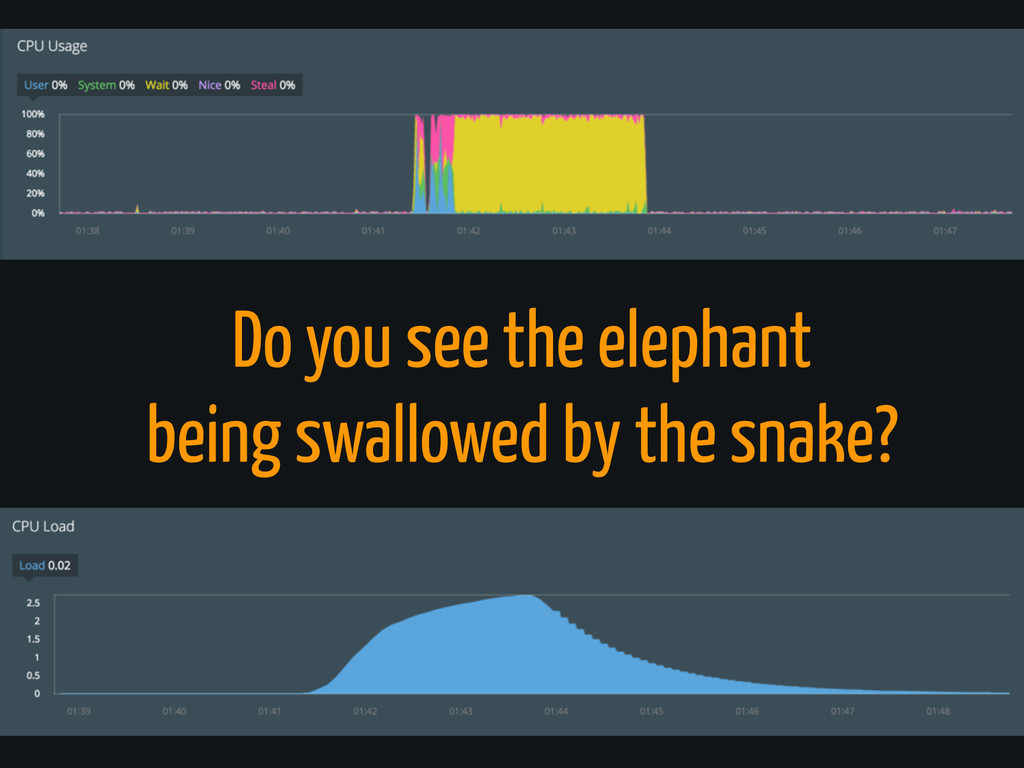
Do you see the elephant being swallowed by the snake?
Agenda
Ad-hoc queries
Aggregations Fast
Machine Learning
parallel queries Step 1
+---------------+---------------+ | timestamp | sequenceId | +---------------+---------------+
Used to avoid timestamp resolution collisions To ensure sub-resolution order
Snapshot the data on overflow or timeout Ensures idempotence Sequence ID
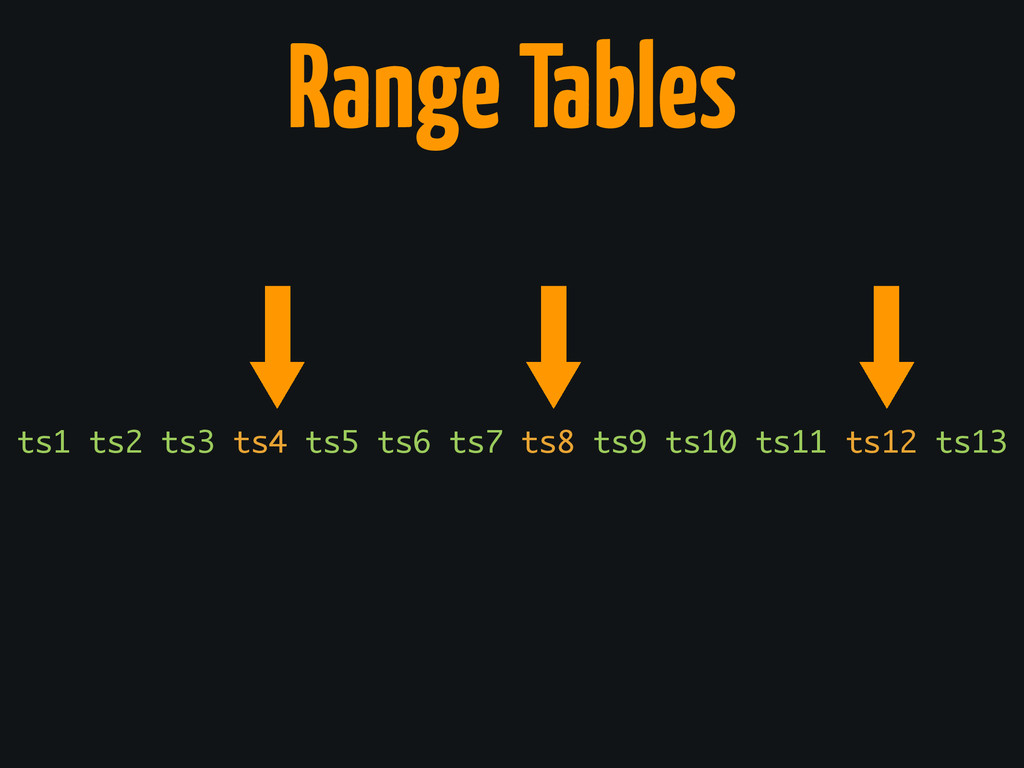
Fighting Dispersion
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13 Range Tables
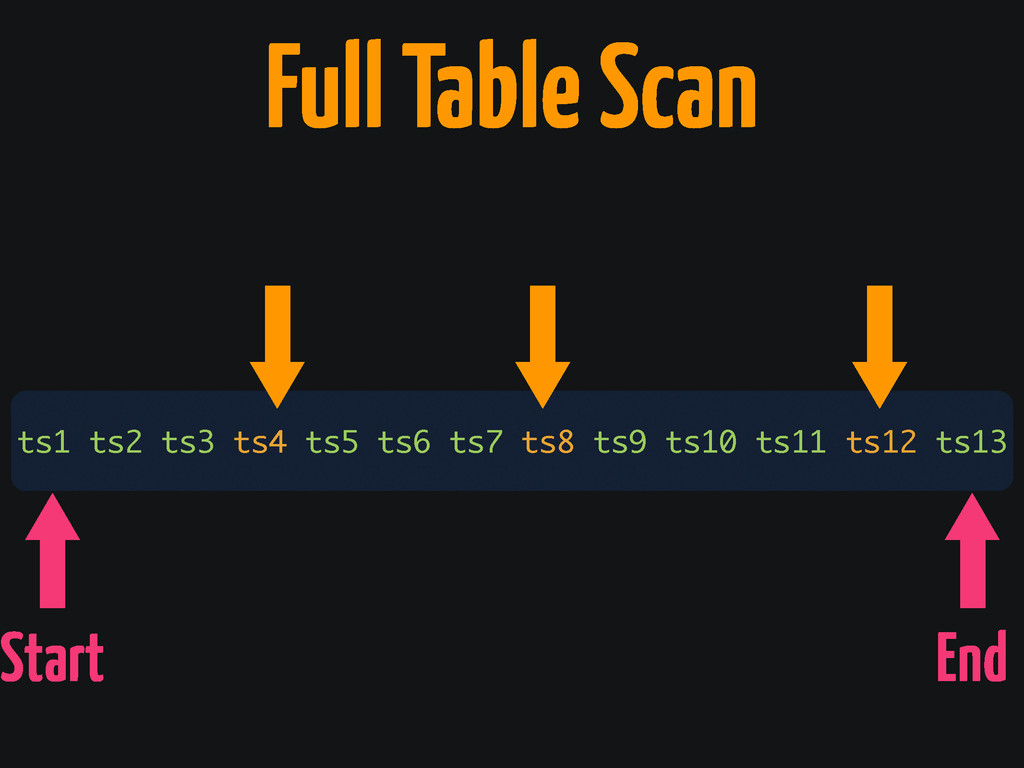
Full Table Scan ts1 ts2 ts3 ts4 ts5 ts6 ts7
ts8 ts9 ts10 ts11 ts12 ts13 Start End
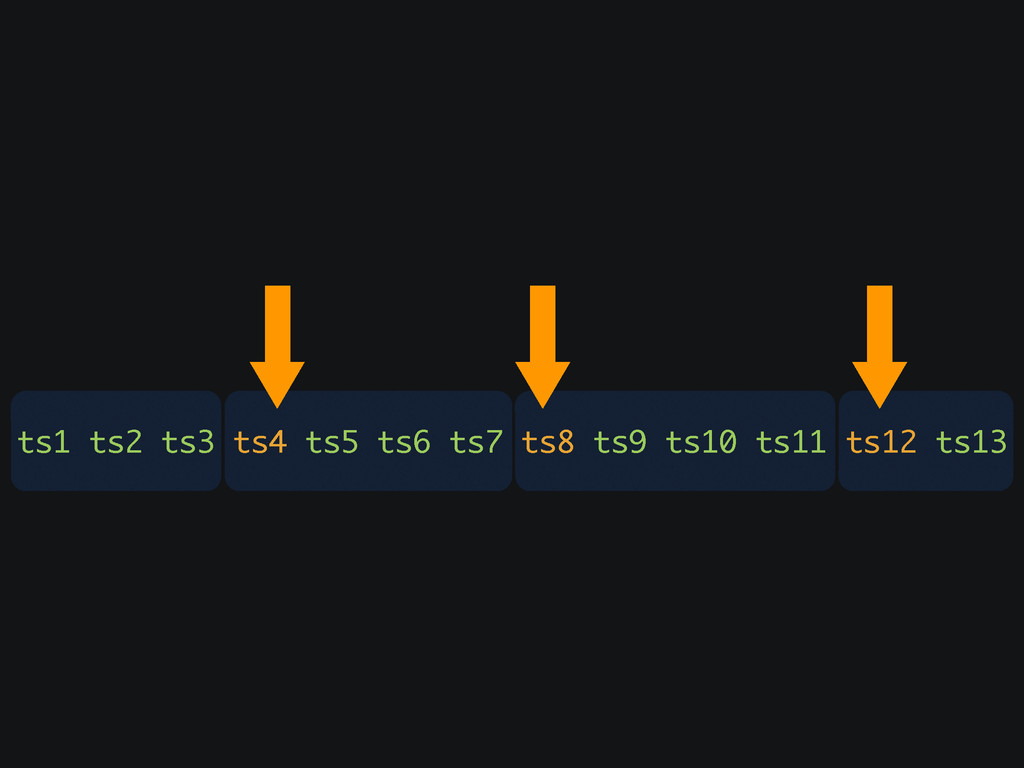
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13
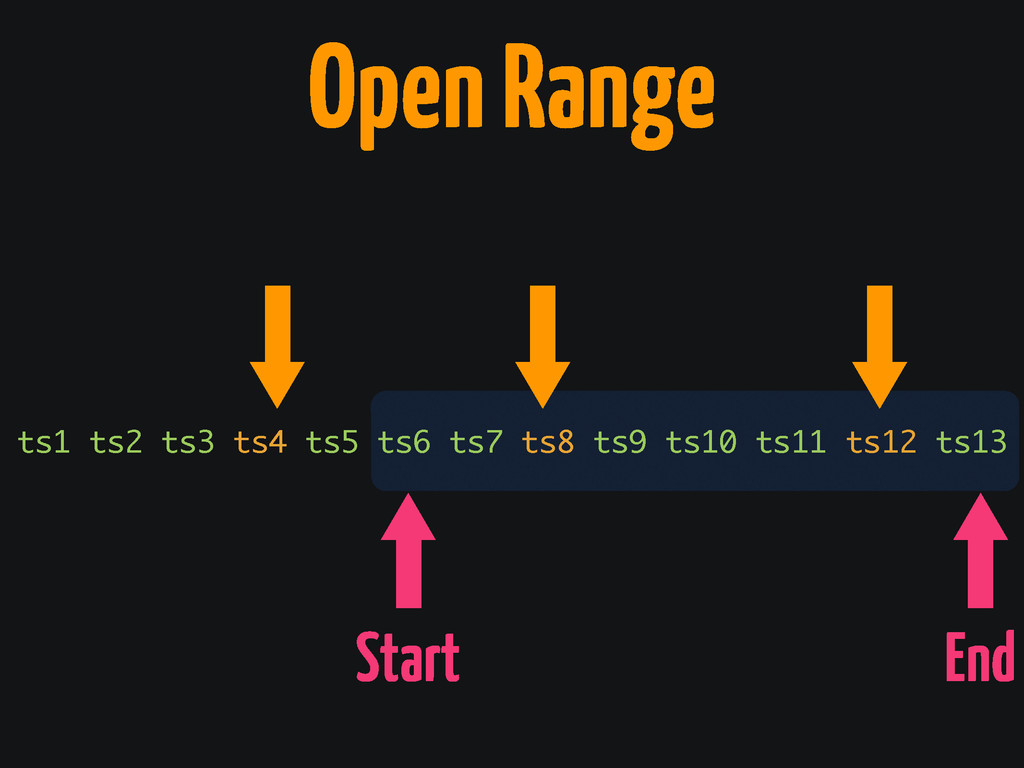
Open Range Start End ts1 ts2 ts3 ts4 ts5 ts6
ts7 ts8 ts9 ts10 ts11 ts12 ts13
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13
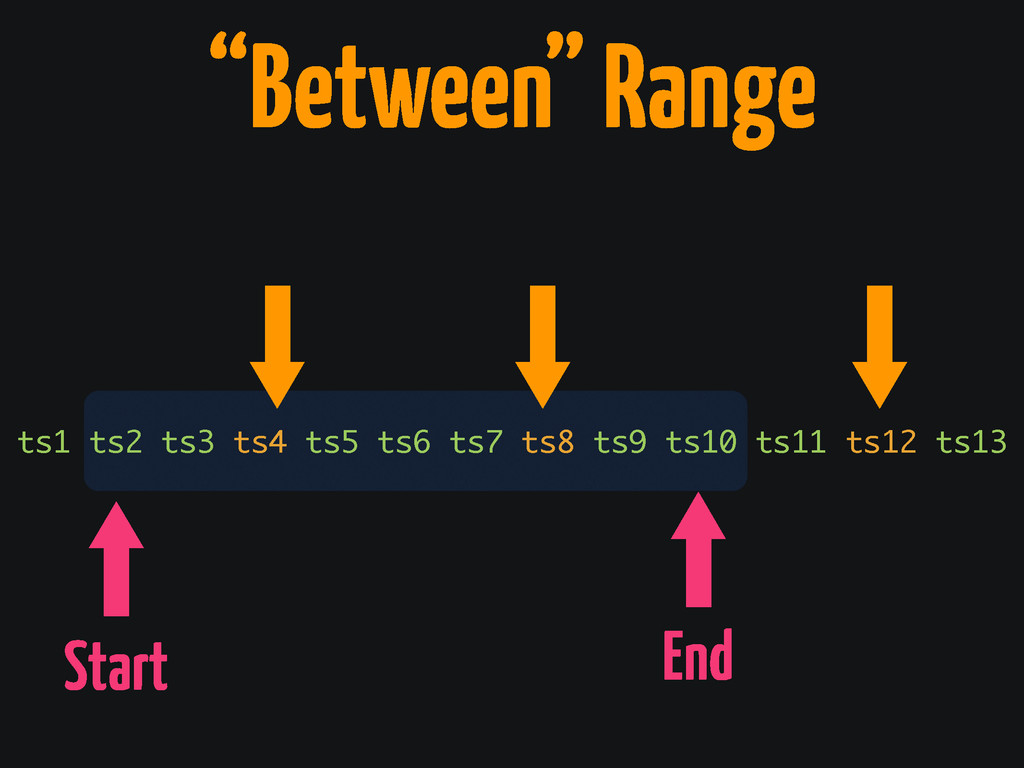
“Between” Range ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8
ts9 ts10 ts11 ts12 ts13 Start End
ts1 ts2 ts3 ts4 ts5 ts6 ts7 ts8 ts9 ts10
ts11 ts12 ts13
(rich query API) Step 2 add some algebra
None
Stream Fusion for rich ad-hoc queries
What is even Stream Fusion
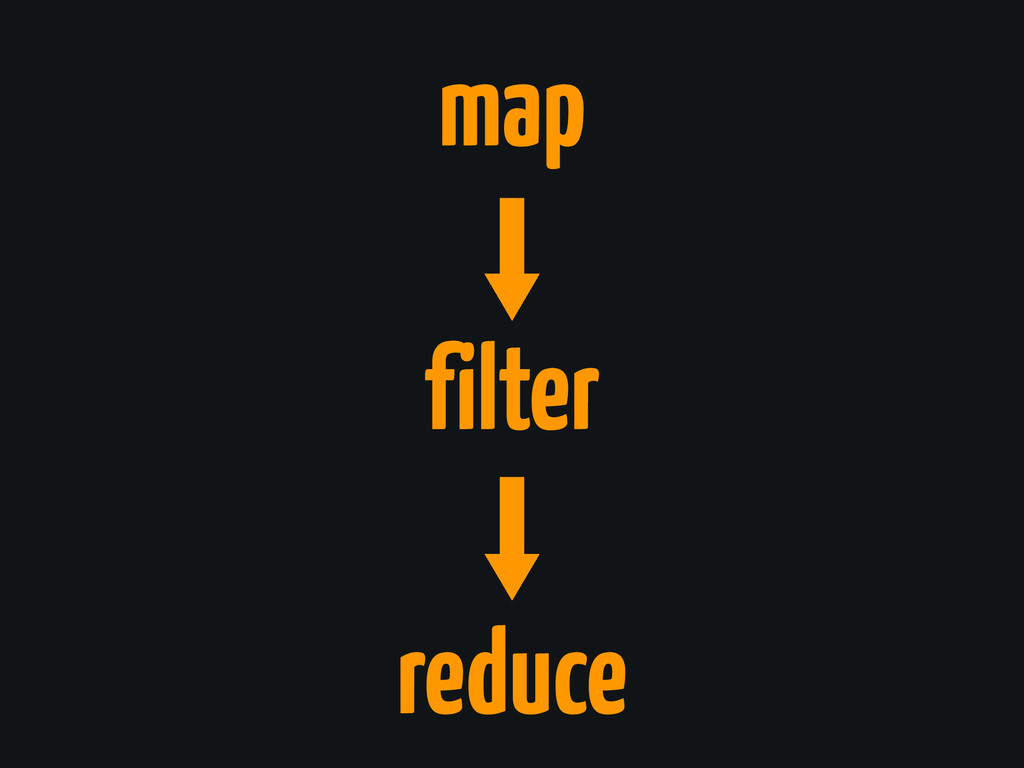
map filter reduce
single step mapFilterReduce
data Step data cursor = Yield data !cursor | Skip
!cursor | Done data Stream data = ∃s. Stream (cursor → Step data cursor) cursor
Stream Beginning: reading from the DB
map Yield data cursor → Yield (f cursor) cursor Skip
cursor → Skip cursor Done → Done maps :: (a → b) → Stream a → Stream b
filter Yield data cursor | p data → Yield data
cursor | otherwise → Skip cursor Skip cursor → Skip cursor Done → Done filters :: (a → Bool) → Stream a → Stream a
reduce/fold Yield x cursor → loop (f data x) cursor
Skip cursor → loop data cursor Done → z foldls :: (Monoid acc) => (acc → a → acc) → acc → Stream a → acc
Append class Monoid a where mempty :: a mappend ::
a -> a -> a -- ^ Identity of 'mappend' -- ^ An associative operation
class (Monoid intermediate) => Aggregate intermediate end where combine ::
intermediate -> end Combine
data Count = Count Int instance Monoid Count where mempty
= Count 0 mappend (Count a) (Count b) = Count $ a + b instance Aggregate Count Int where combine (Count a) = a Count Example
add some ML Step 3
Storing Models
Support Vector Machines
Hyperplane α·x - φ = 1
[ α1 α1 α1 ...αn ] ρ
Option 1: list<double>
CREATE TABLE support_vectors( path varchar, alpha list<double>, phi int, PRIMARY
KEY(path))
Problems High deserialisation overhead Need to add PK specifiers for
multiple SVs
Alternative: blob & byte buffers
Vector Representation
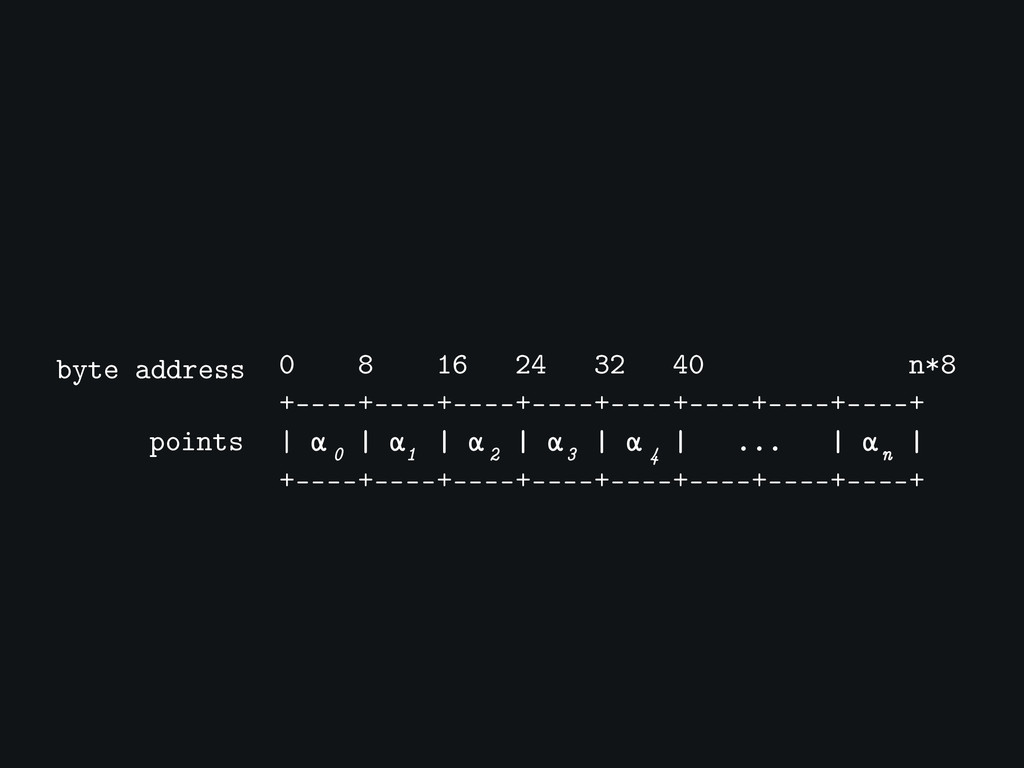
0 8 16 24 32 40 n*8 +----+----+----+----+----+----+----+----+ | α
| α | α | α | α | ... | α | +----+----+----+----+----+----+----+----+ byte address points 1 2 3 4 0 n
Matrix Representation
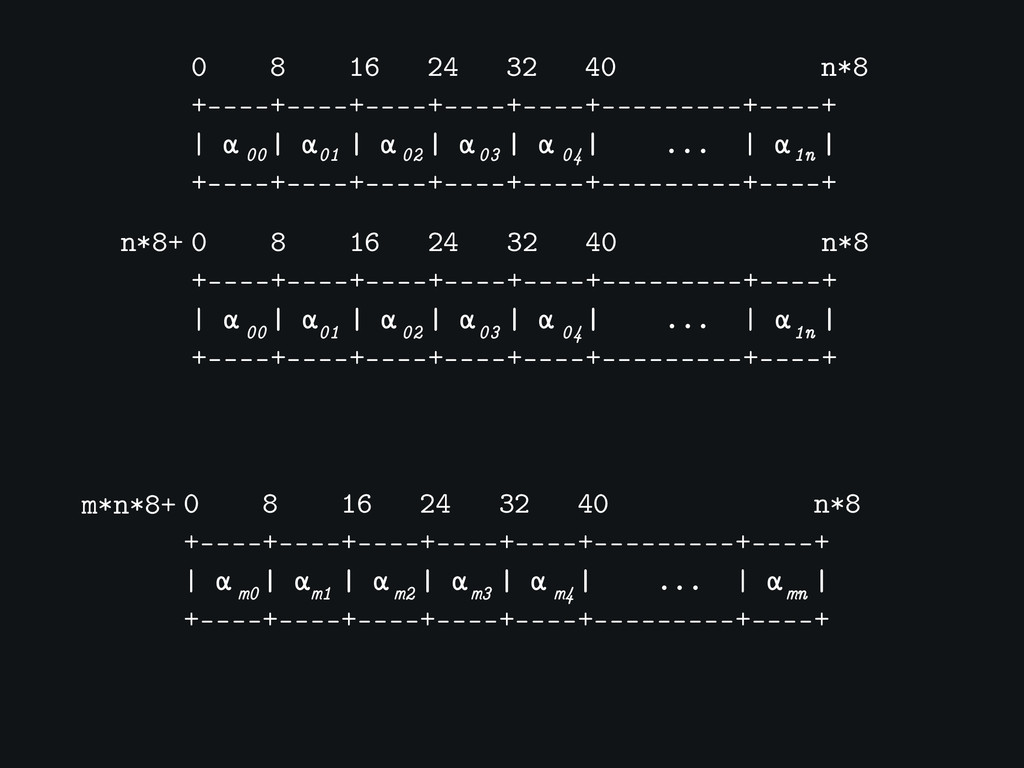
0 8 16 24 32 40 n*8 +----+----+----+----+----+---------+----+ | α
| α | α | α | α | ... | α | +----+----+----+----+----+---------+----+ 01 02 03 04 00 1n n*8+ 0 8 16 24 32 40 n*8 +----+----+----+----+----+---------+----+ | α | α | α | α | α | ... | α | +----+----+----+----+----+---------+----+ 01 02 03 04 00 1n m*n*8+ 0 8 16 24 32 40 n*8 +----+----+----+----+----+---------+----+ | α | α | α | α | α | ... | α | +----+----+----+----+----+---------+----+ m1 m2 m3 m4 m0 mn
Advantages No serialisation overhead Fast relative access Easy to go
multi-dimensional Easy to implement atomic in-memory operations
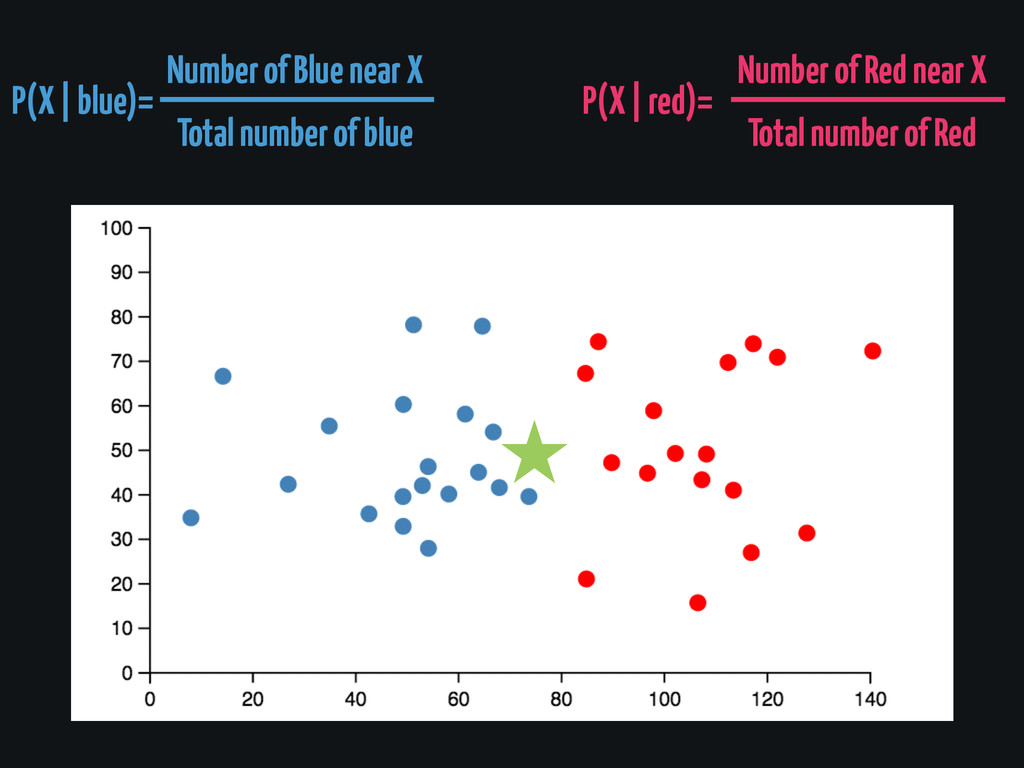
Bayesian Classifiers
P(X | blue)= Number of Blue near X Total number
of blue P(X | red)= Number of Red near X Total number of Red
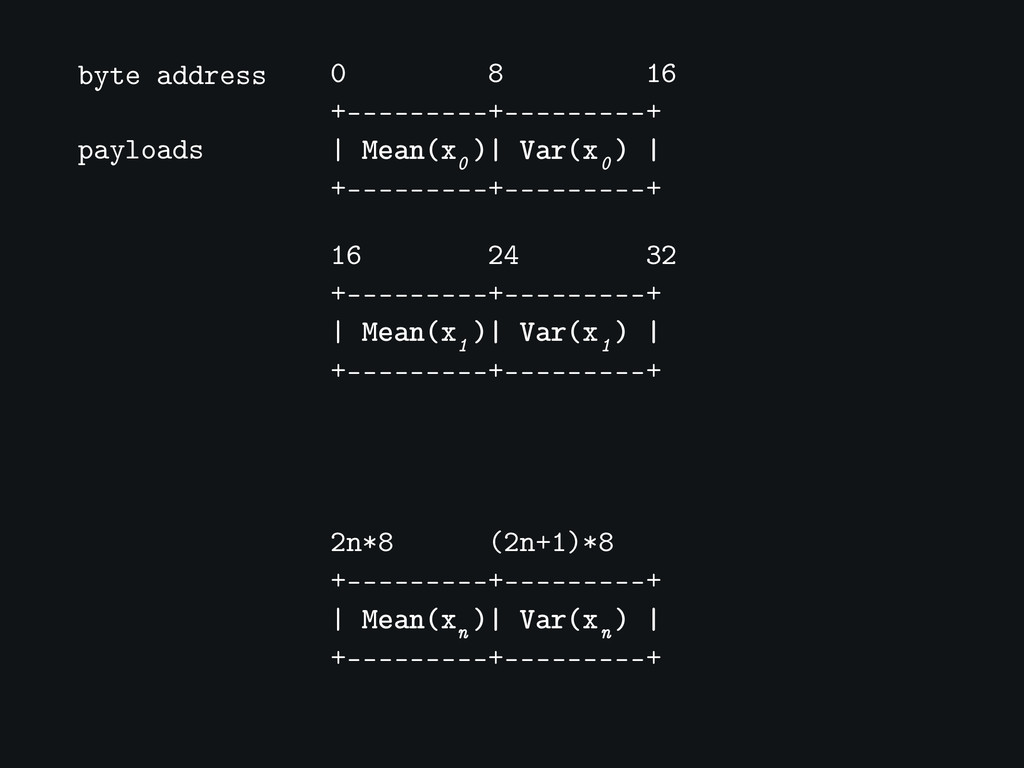
[[Mean(x1), Var(x1)] [Mean(x2), Var(x3)] ... [Mean(xn), Var(xn)]]
0 8 16 +---------+---------+ | Mean(x )| Var(x ) |
+---------+---------+ 0 0 16 24 32 +---------+---------+ | Mean(x )| Var(x ) | +---------+---------+ 1 1 2n*8 (2n+1)*8 +---------+---------+ | Mean(x )| Var(x ) | +---------+---------+ n n byte address payloads
make it rocket-fast Step 4
Approximate Data Structures
Bloom Filters are basically long arrays / vectors
BitSet
0 8 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 |
0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ 8 16 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ 16 24 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ 24 32 +---+---+---+---+---+---+---+---+ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | +---+---+---+---+---+---+---+---+ bit address
Advantages 64 bits per 8-byte Long Easy to represent by
the long-array using offsets, bit shifts and masks Easy to implement atomic in-memory operations
Count-min sketches are basically int matrices
Histograms are basically long vectors
Conclusions Ad-hoc queries Parallelism Lightweight DSs representation Optimisations and good
API fits
@ifesdjeen
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[ α1 α1 α1 ...αn ] ρ](https://files.speakerdeck.com/presentations/48f0d2a8595d49a78d29eb8e2b49165e/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[[Mean(x1), Var(x1)] [Mean(x2), Var(x3)] ... [Mean(xn), Var(xn)]]](https://files.speakerdeck.com/presentations/48f0d2a8595d49a78d29eb8e2b49165e/slide_54.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}