it became clear that there was huge demand for a lightweight parallelism solution for Pandas DataFrames and machine learning tools, such as Scikit-Learn. Dask then evolved quickly to support these other projects where appropriate.” Matthew Rocklin Dask Creator Source https://coiled.io/blog/history-dask/ Image from Jake VanderPlas’ keynote, PyCon 2017
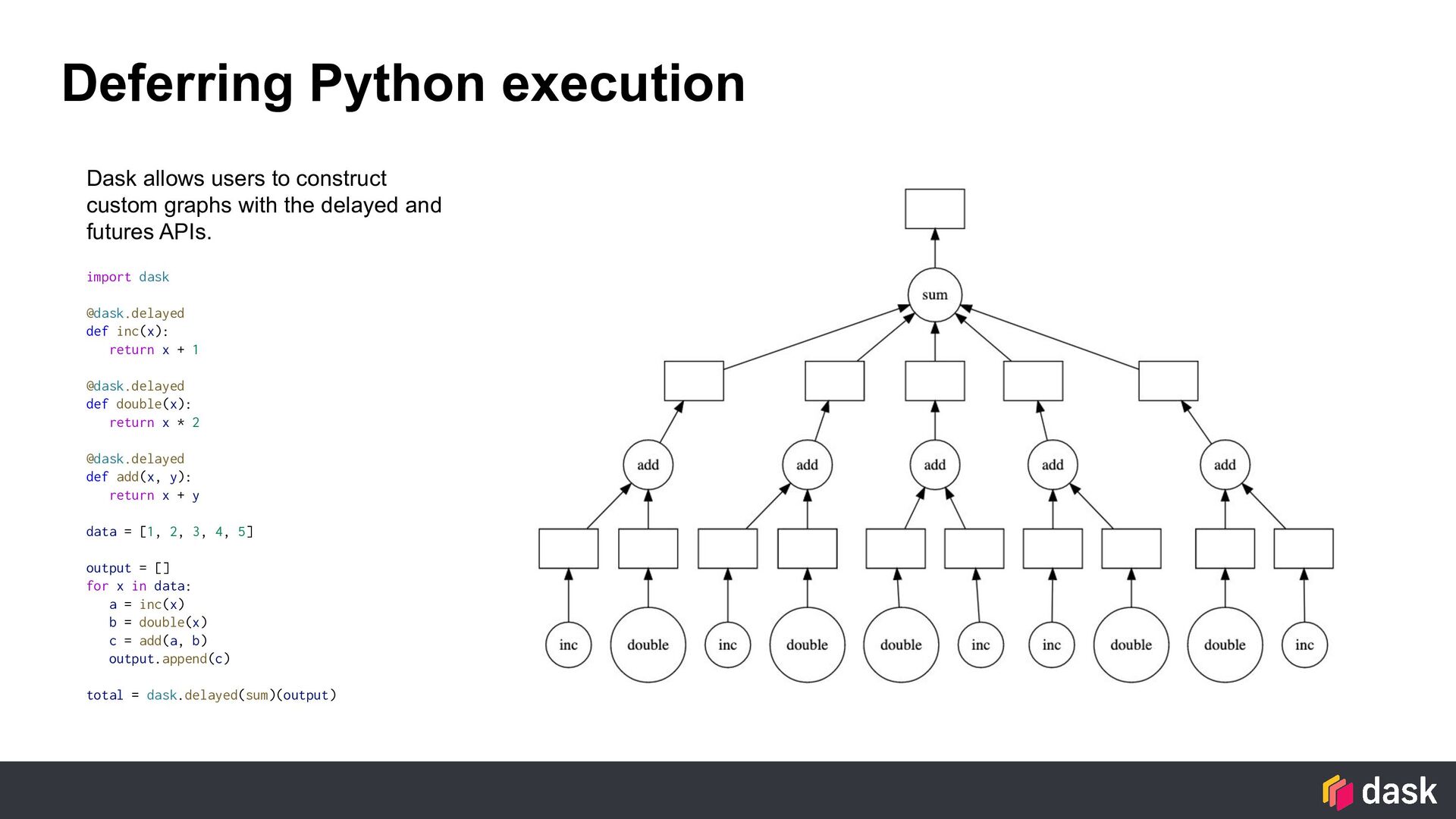
+ 1 @dask.delayed def double(x): return x * 2 @dask.delayed def add(x, y): return x + y data = [1, 2, 3, 4, 5] output = [] for x in data: a = inc(x) b = double(x) c = add(a, b) output.append(c) total = dask.delayed(sum)(output) Dask allows users to construct custom graphs with the delayed and futures APIs.
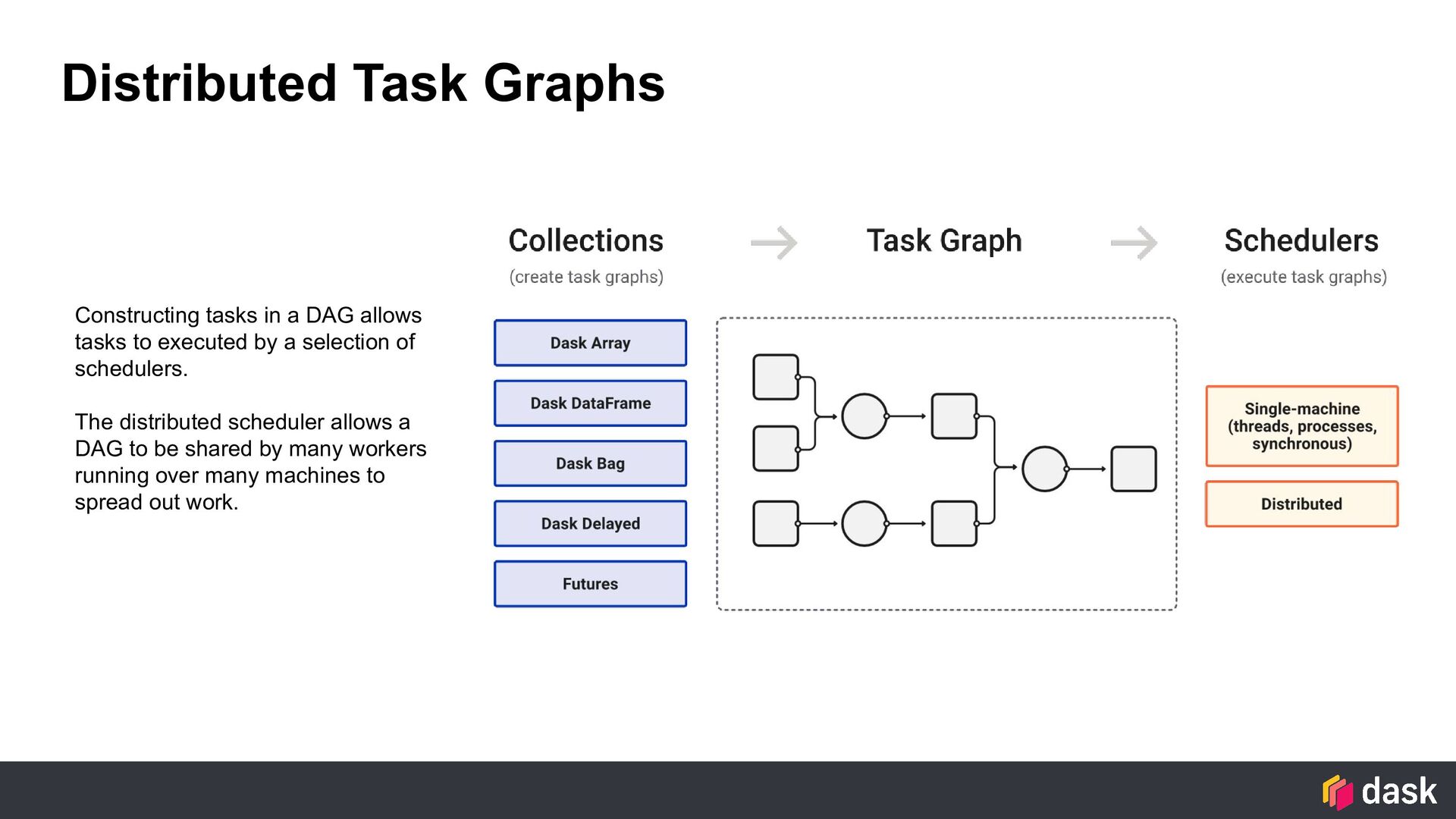
to executed by a selection of schedulers. The distributed scheduler allows a DAG to be shared by many workers running over many machines to spread out work.
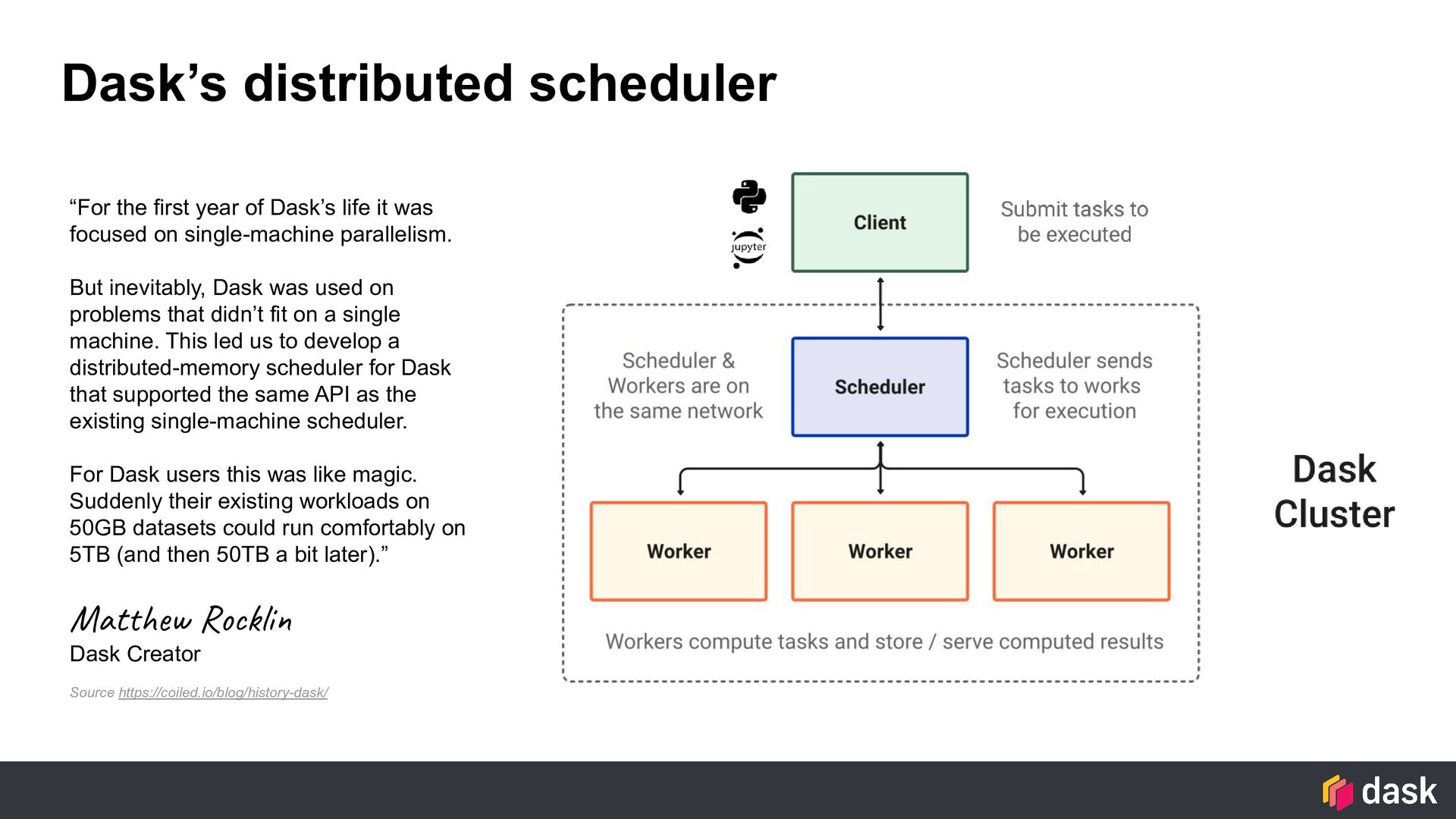
it was focused on single-machine parallelism. But inevitably, Dask was used on problems that didn’t fit on a single machine. This led us to develop a distributed-memory scheduler for Dask that supported the same API as the existing single-machine scheduler. For Dask users this was like magic. Suddenly their existing workloads on 50GB datasets could run comfortably on 5TB (and then 50TB a bit later).” Matthew Rocklin Dask Creator Source https://coiled.io/blog/history-dask/
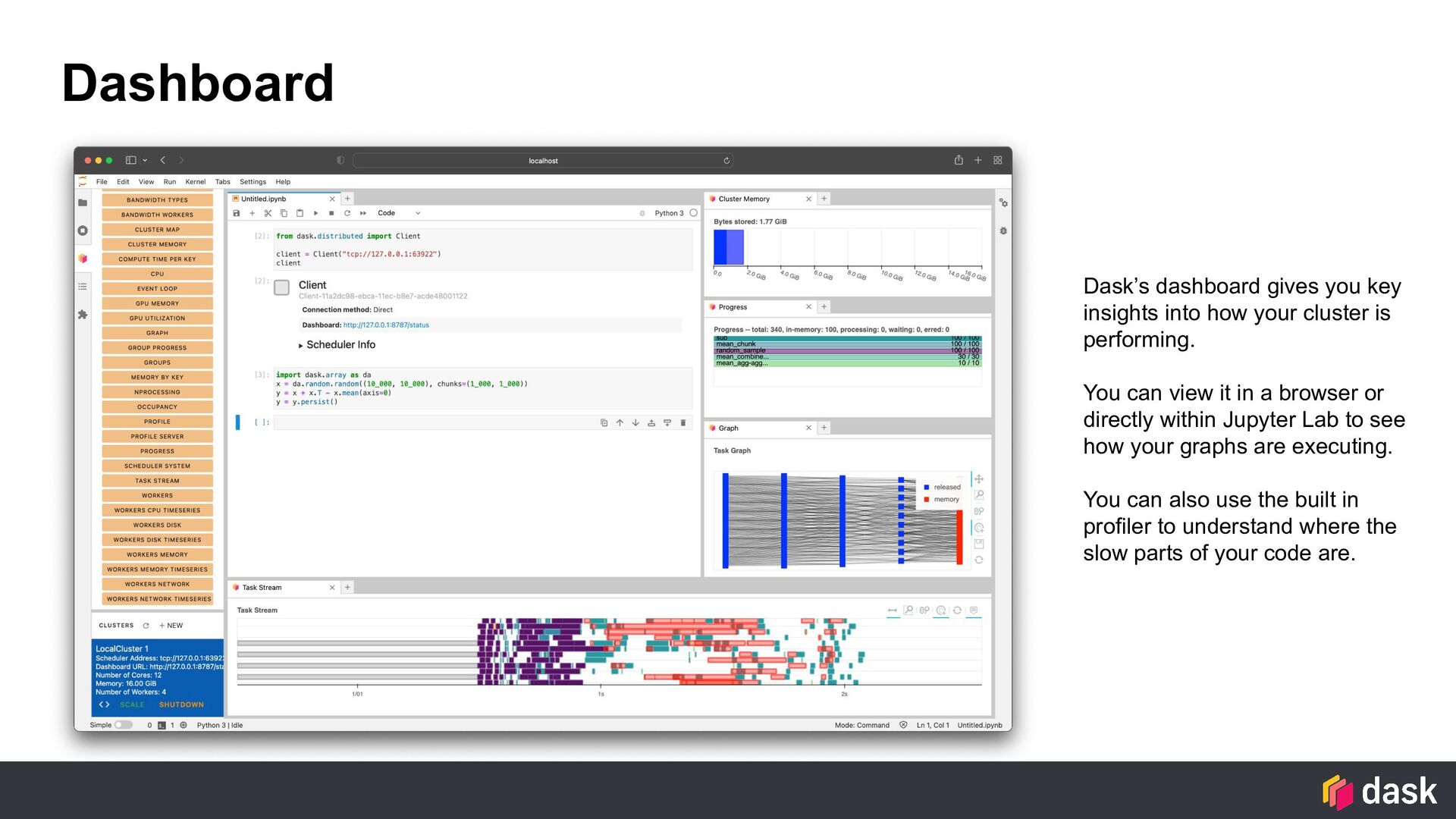
cluster is performing. You can view it in a browser or directly within Jupyter Lab to see how your graphs are executing. You can also use the built in profiler to understand where the slow parts of your code are.
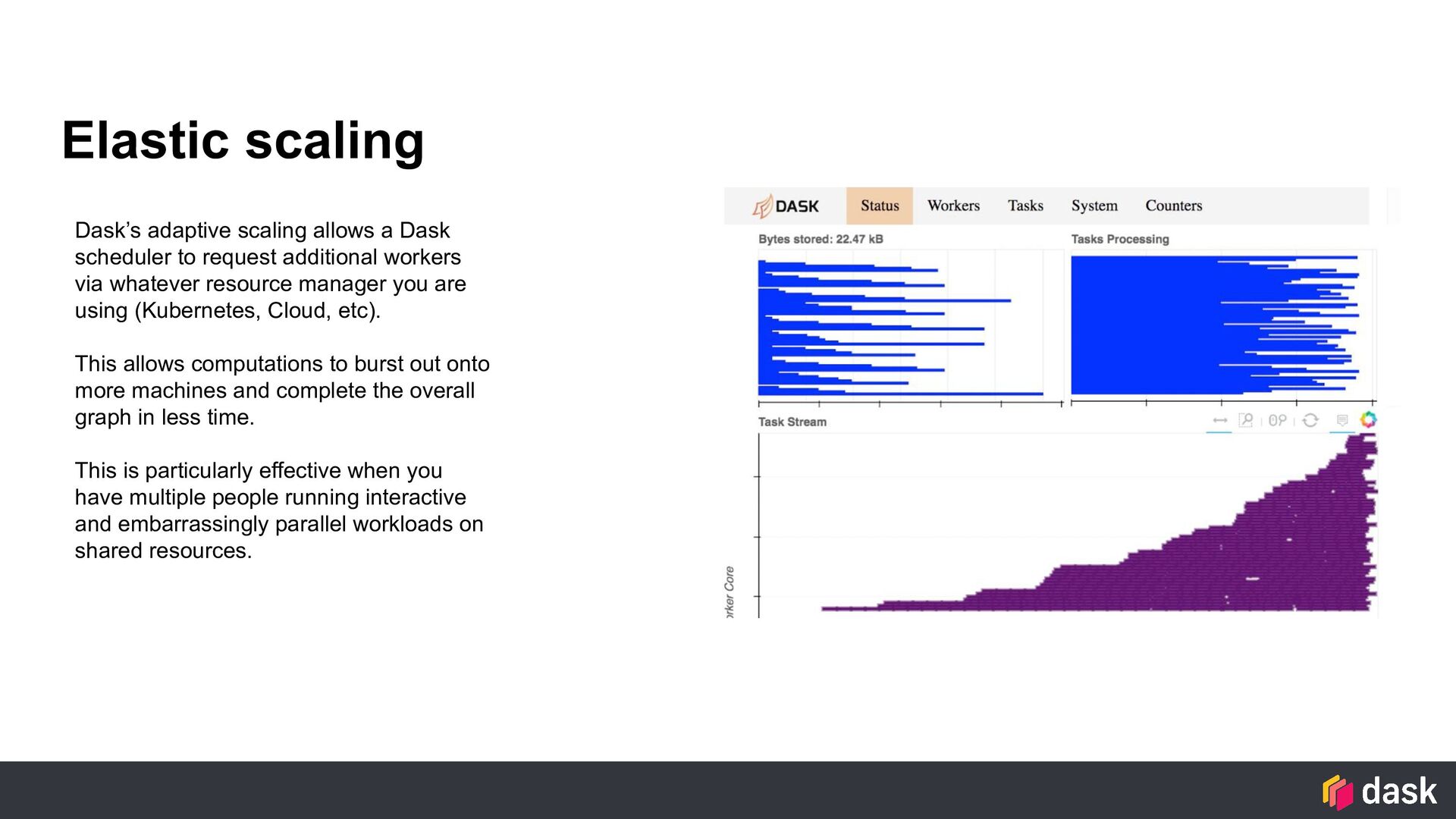
request additional workers via whatever resource manager you are using (Kubernetes, Cloud, etc). This allows computations to burst out onto more machines and complete the overall graph in less time. This is particularly effective when you have multiple people running interactive and embarrassingly parallel workloads on shared resources.
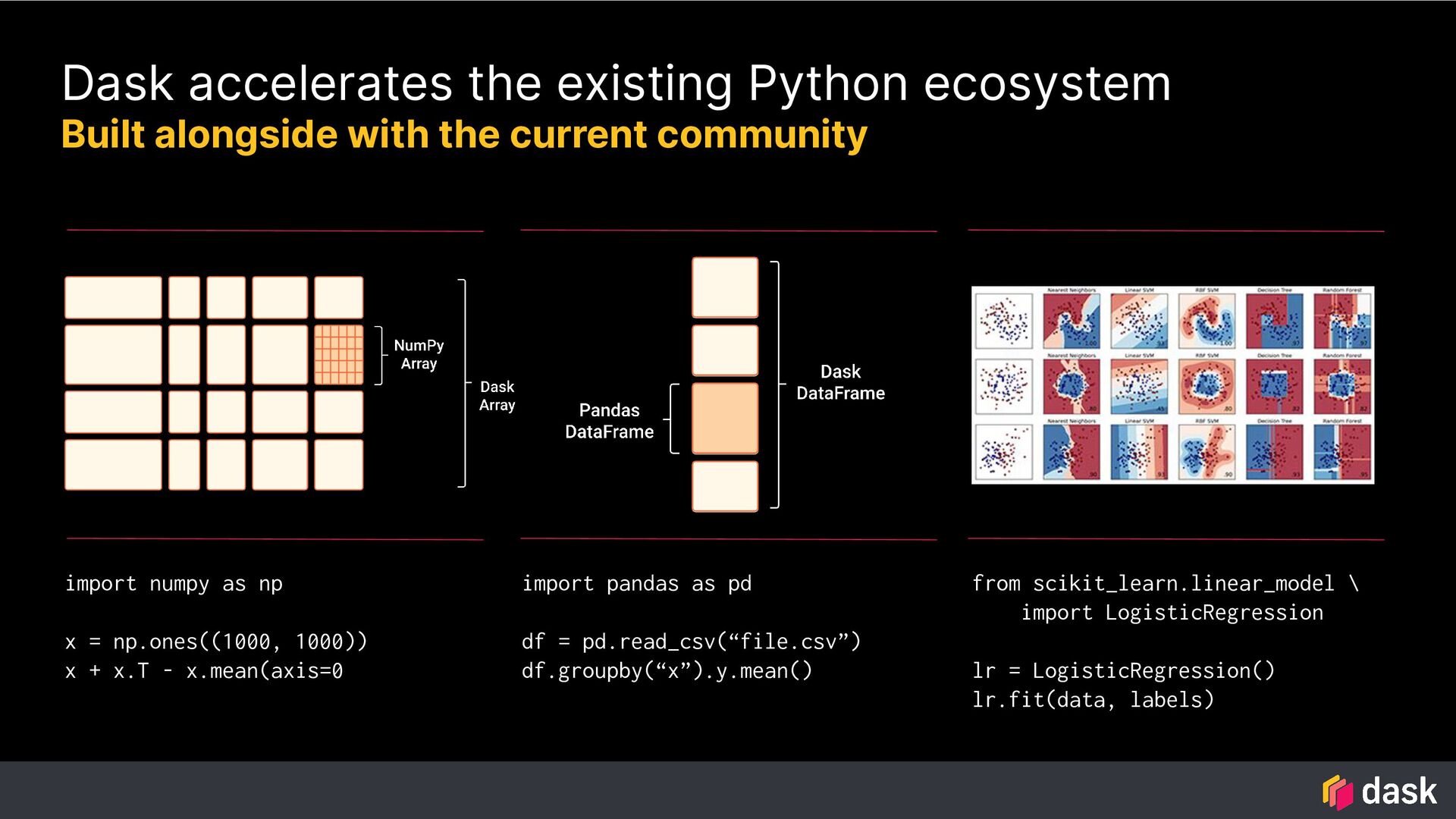
current community import numpy as np x = np.ones((1000, 1000)) x + x.T - x.mean(axis=0 import pandas as pd df = pd.read_csv(“file.csv”) df.groupby(“x”).y.mean() from scikit_learn.linear_model \ import LogisticRegression lr = LogisticRegression() lr.fit(data, labels) Numpy Pandas Scikit-Learn
through Familiar Interfaces In [1]: import pandas as pd In [2]: df = pd.read_csv(‘filepath’) In [1]: from sklearn.ensemble import RandomForestClassifier In [2]: clf = RandomForestClassifier(n_estimators=10 0,max_depth=8, random_state=0) In [3]: clf.fit(x, y) In [1]: import networkx as nx In [2]: page_rank=nx.pagerank(graph) In [1]: import cudf In [2]: df = cudf.read_csv(‘filepath’) In [1]: from cuml.ensemble import RandomForestClassifier In [2]: cuclf = RandomForestClassifier(n_estimators=10 0,max_depth=8, random_state=0) In [3]: cuclf.fit(x, y) In [1]: import cugraph In [2]: page_rank=cugraph.pagerank(graph) GPU CPU pandas scikit-learn NetworkX cuDF cuML cuGraph Average Speed-Ups: 150x Average Speed-Ups: 250x Average Speed-Ups: 50x
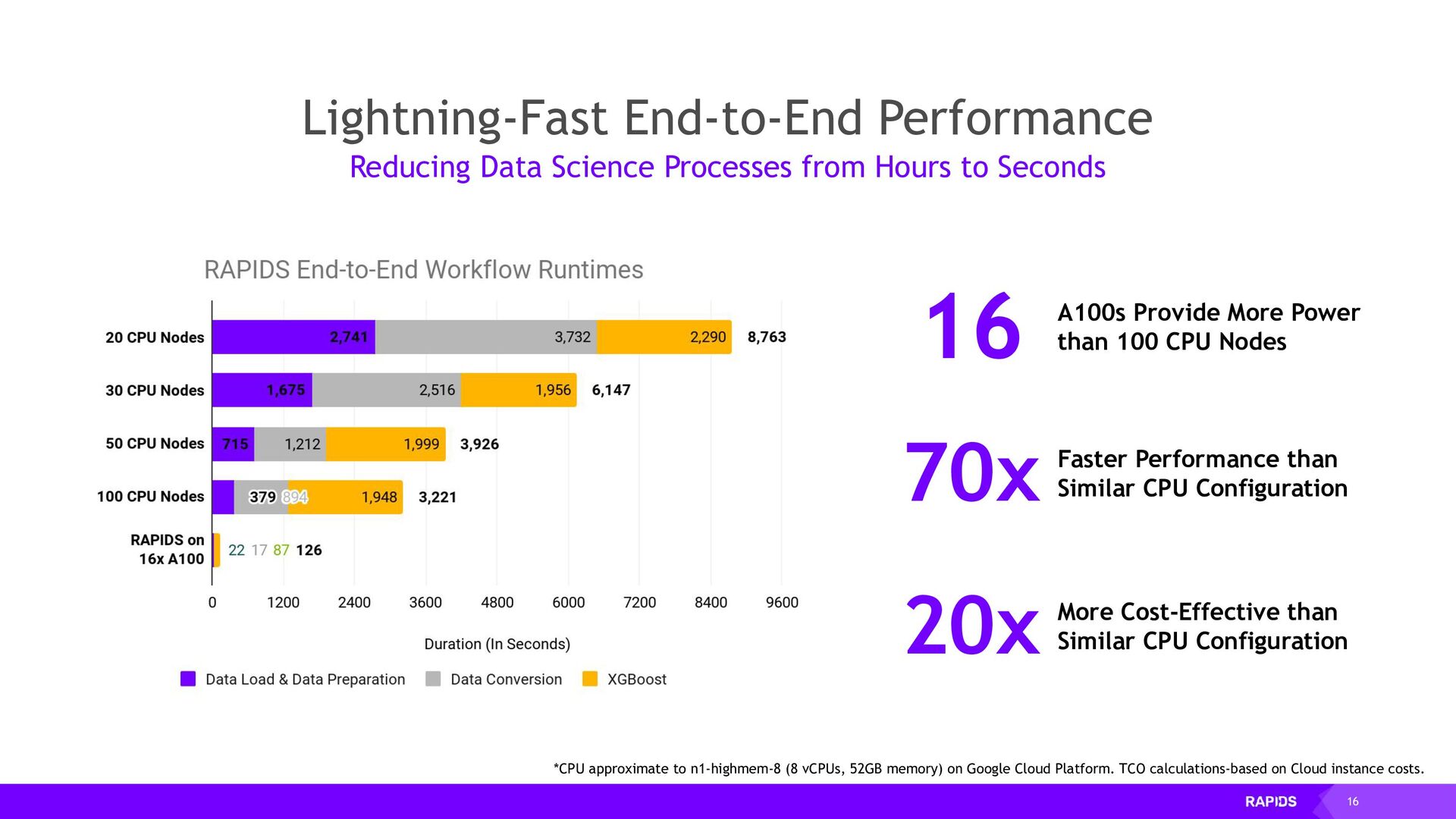
to Seconds *CPU approximate to n1-highmem-8 (8 vCPUs, 52GB memory) on Google Cloud Platform. TCO calculations-based on Cloud instance costs. A100s Provide More Power than 100 CPU Nodes 16 More Cost-Effective than Similar CPU Configuration 20x Faster Performance than Similar CPU Configuration 70x
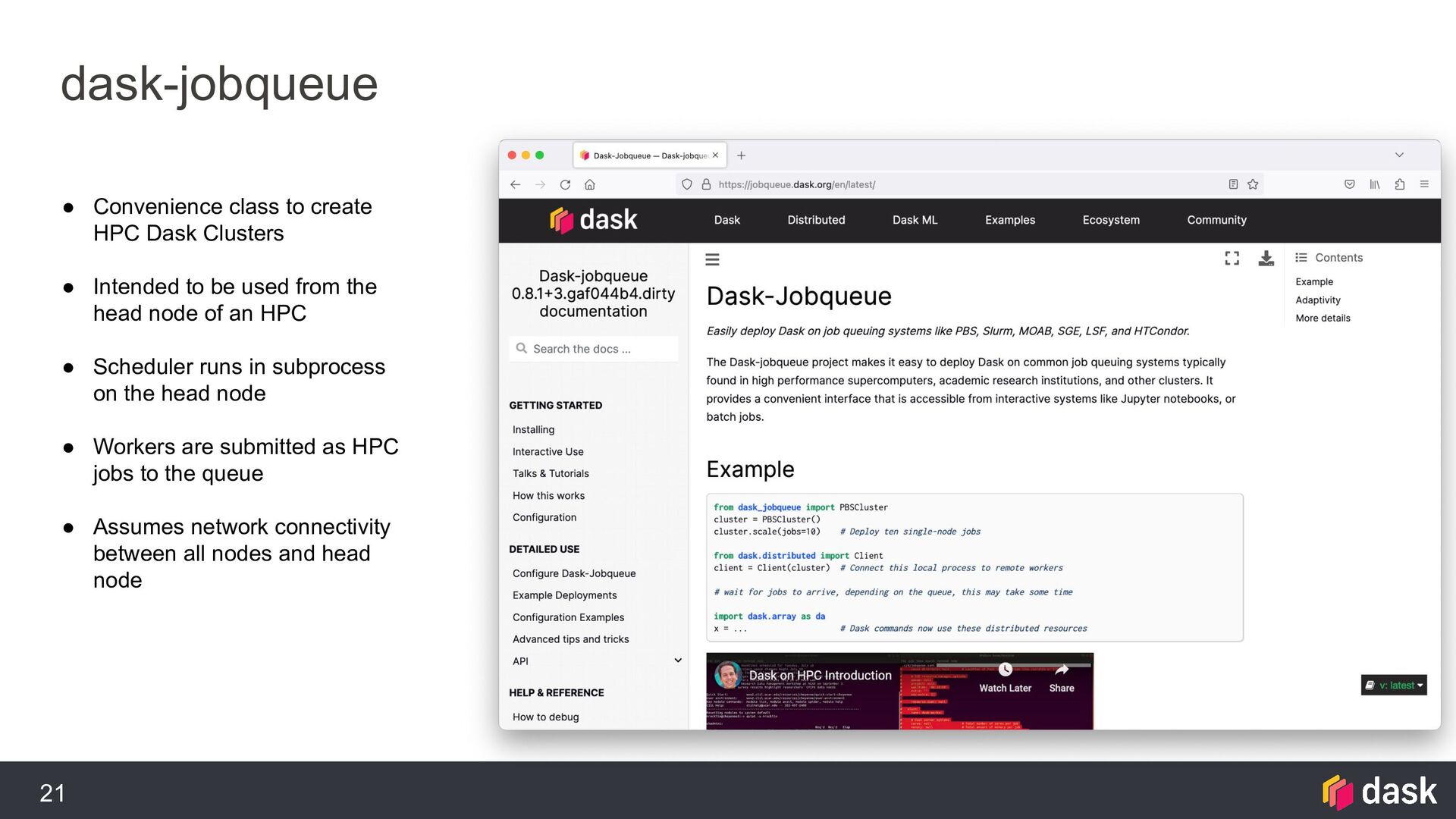
• Intended to be used from the head node of an HPC • Scheduler runs in subprocess on the head node • Workers are submitted as HPC jobs to the queue • Assumes network connectivity between all nodes and head node
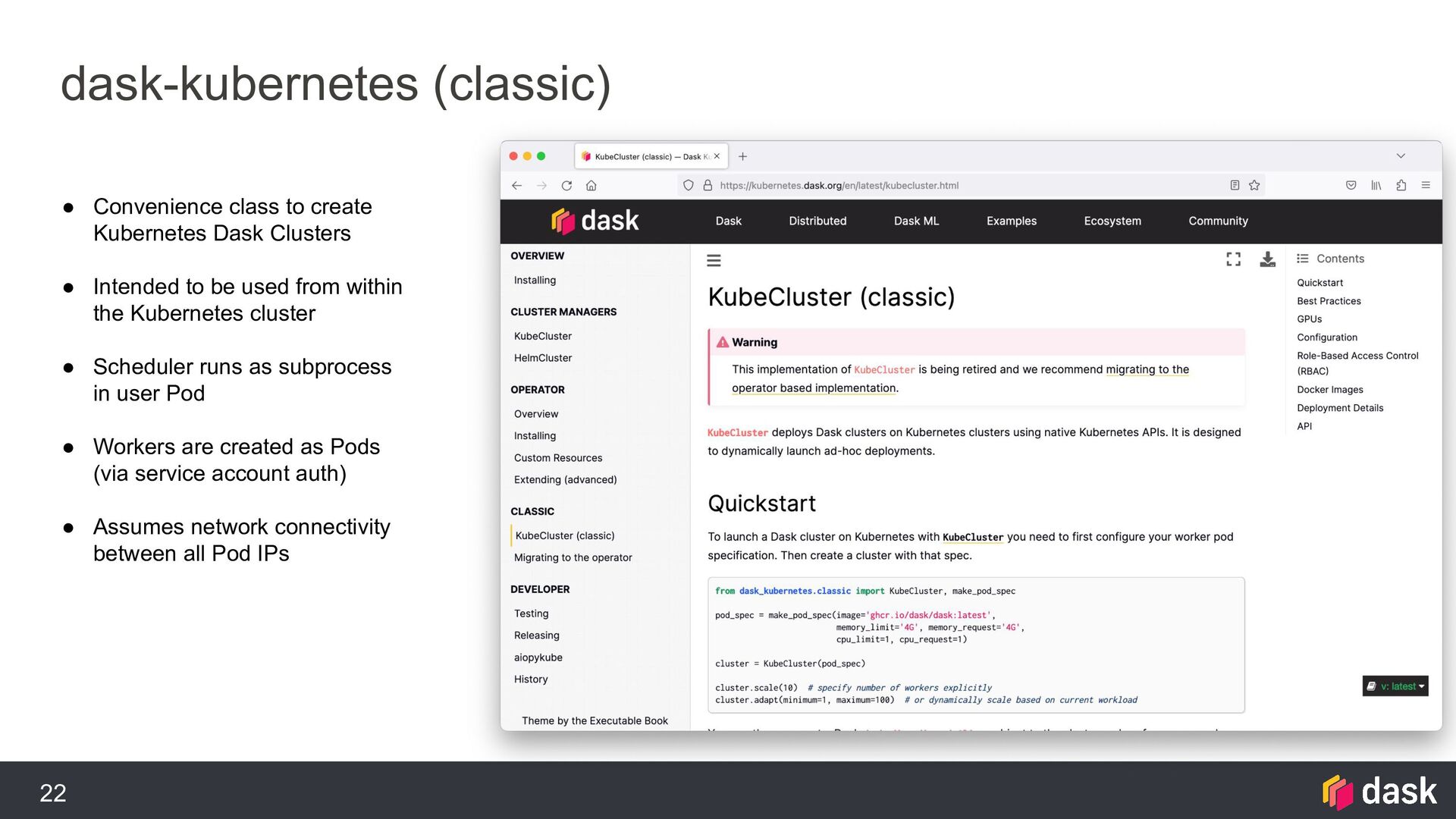
Clusters • Intended to be used from within the Kubernetes cluster • Scheduler runs as subprocess in user Pod • Workers are created as Pods (via service account auth) • Assumes network connectivity between all Pod IPs
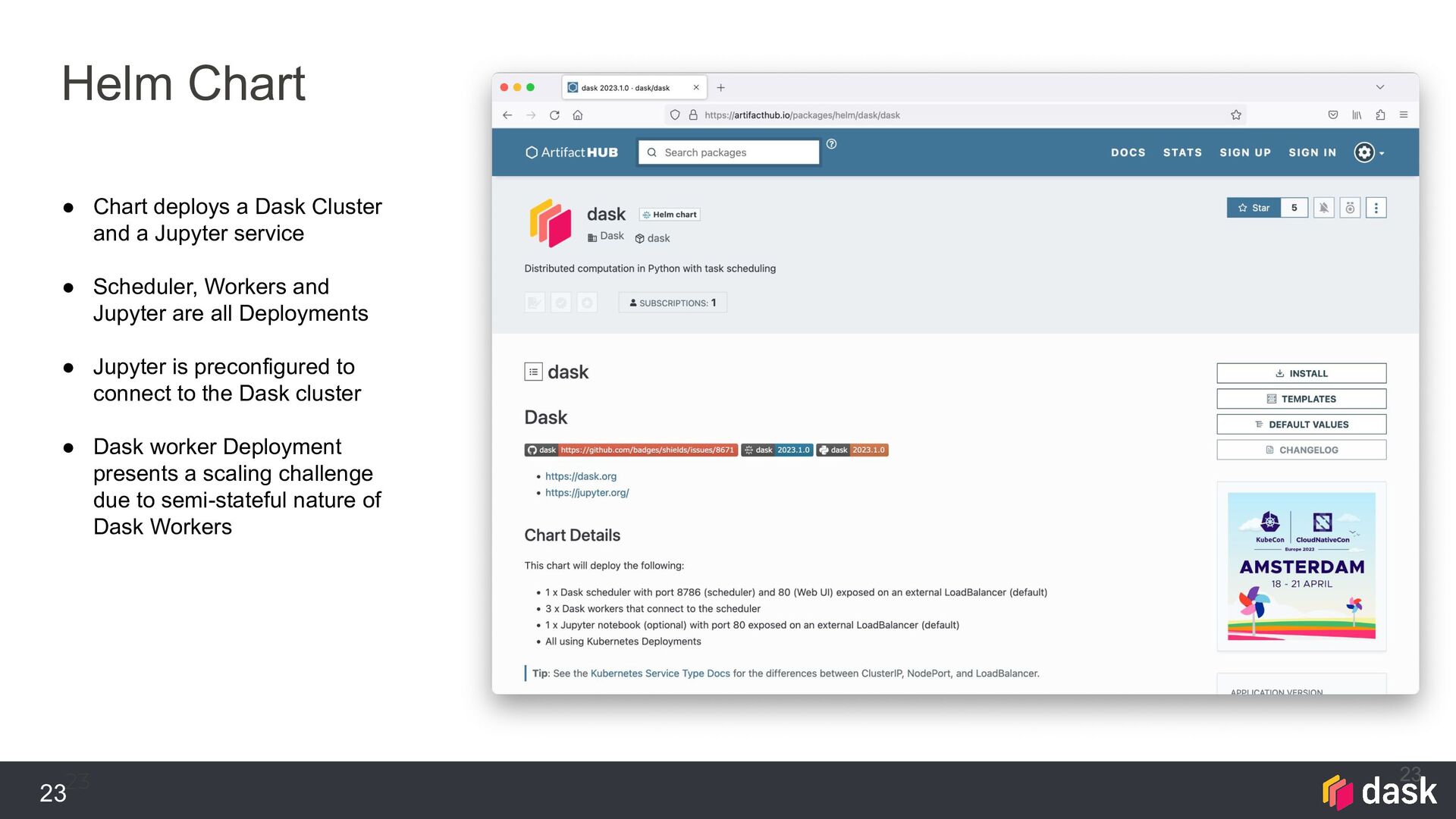
Cluster and a Jupyter service • Scheduler, Workers and Jupyter are all Deployments • Jupyter is preconfigured to connect to the Dask cluster • Dask worker Deployment presents a scaling challenge due to semi-stateful nature of Dask Workers
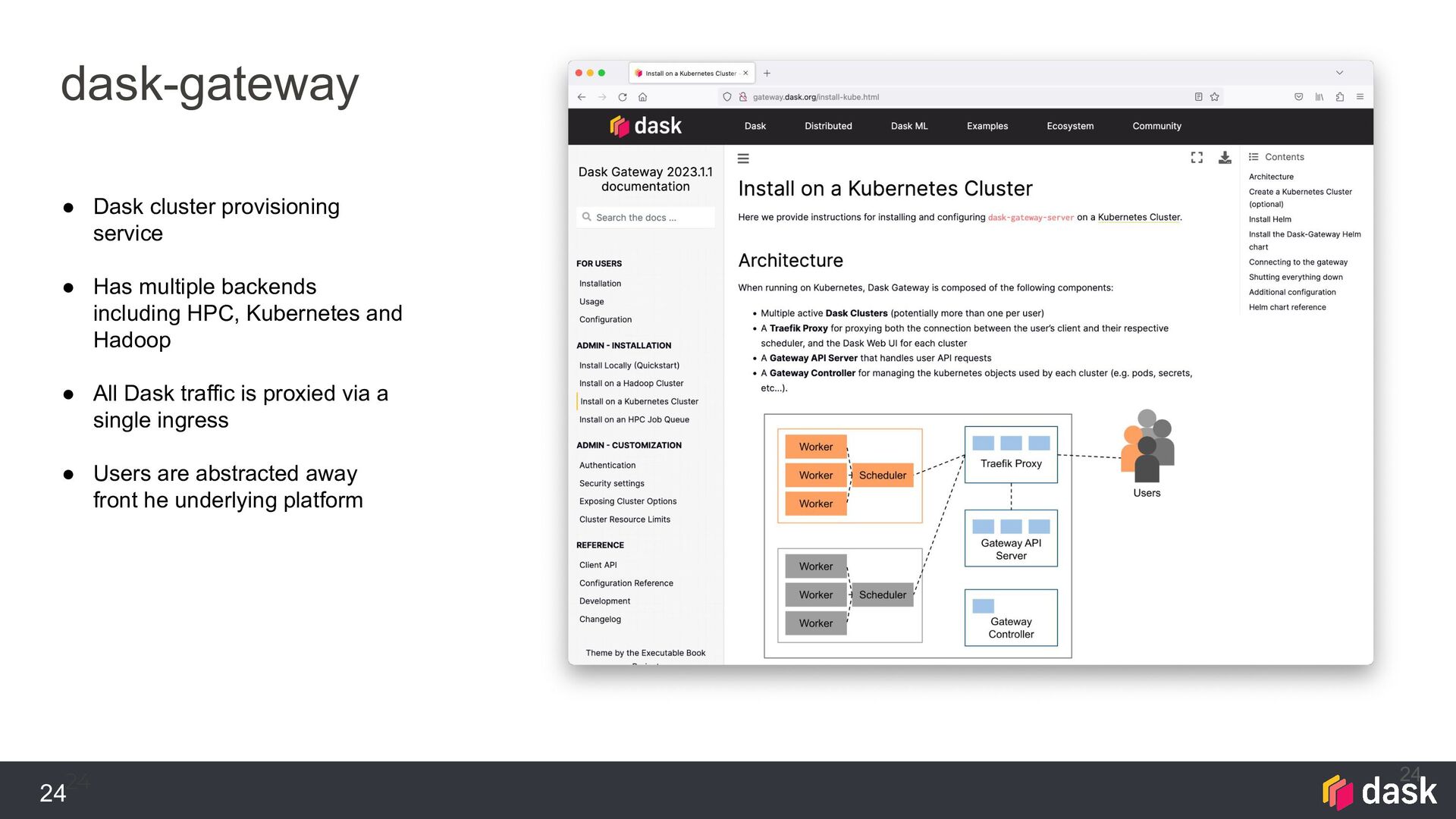
Has multiple backends including HPC, Kubernetes and Hadoop • All Dask traffic is proxied via a single ingress • Users are abstracted away front he underlying platform
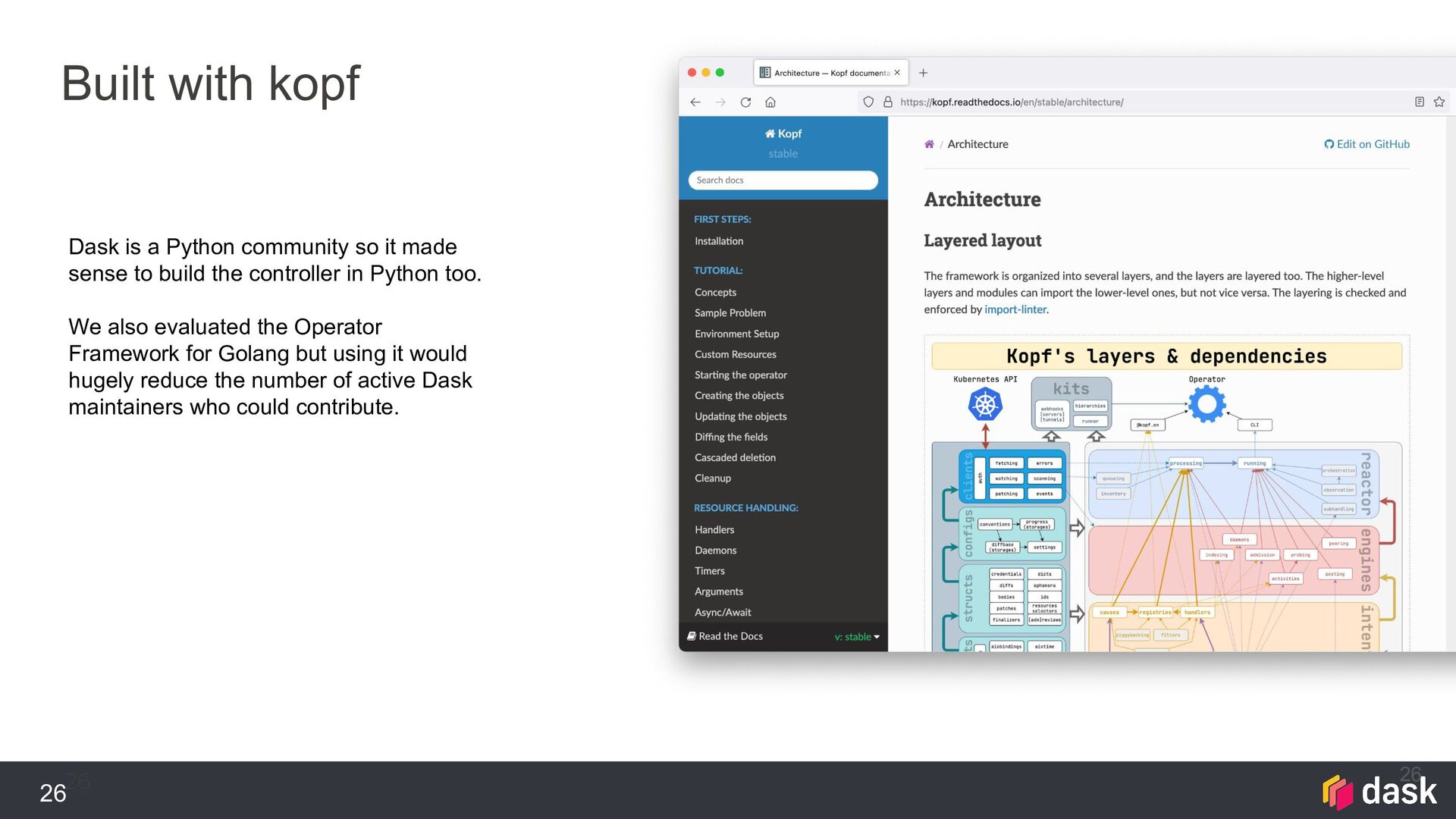
community so it made sense to build the controller in Python too. We also evaluated the Operator Framework for Golang but using it would hugely reduce the number of active Dask maintainers who could contribute.
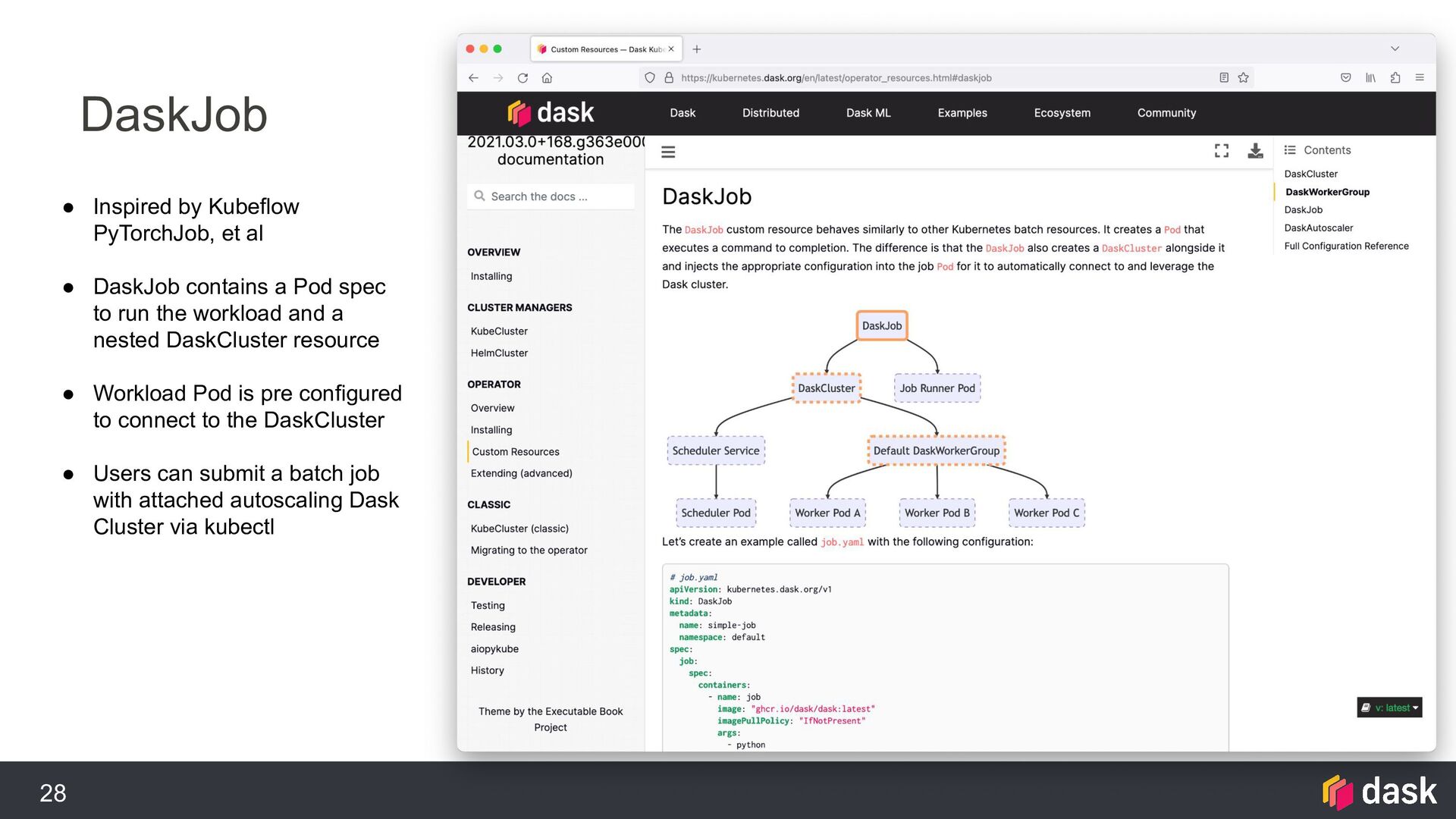
spec: worker: replicas: 3 spec: containers: - name: worker image: "ghcr.io/dask/dask:latest" imagePullPolicy: "IfNotPresent" args: - dask-worker - --name - $(DASK_WORKER_NAME) scheduler: spec: containers: - name: scheduler image: "ghcr.io/dask/dask:latest" imagePullPolicy: "IfNotPresent" args: - dask-scheduler ports: - name: tcp-comm containerPort: 8786 protocol: TCP - name: http-dashboard containerPort: 8787 protocol: TCP readinessProbe: httpGet: port: http-dashboard path: /health initialDelaySeconds: 5 … The Dask Operator has four custom resource types that you can create via kubectl. • DaskCluster to create whole clusters. • DaskWorkerGroup to create additional groups of workers with various configurations (high memory, GPUs, etc). • DaskJob to run end-to-end tasks like a Kubernetes Job but with an adjacent DaskCluster. • DaskAutoscaler behaves like an HPA but interacts with the Dask scheduler to make scaling decisions Create Dask Clusters with kubectl
DaskJob contains a Pod spec to run the workload and a nested DaskCluster resource • Workload Pod is pre configured to connect to the DaskCluster • Users can submit a batch job with attached autoscaling Dask Cluster via kubectl
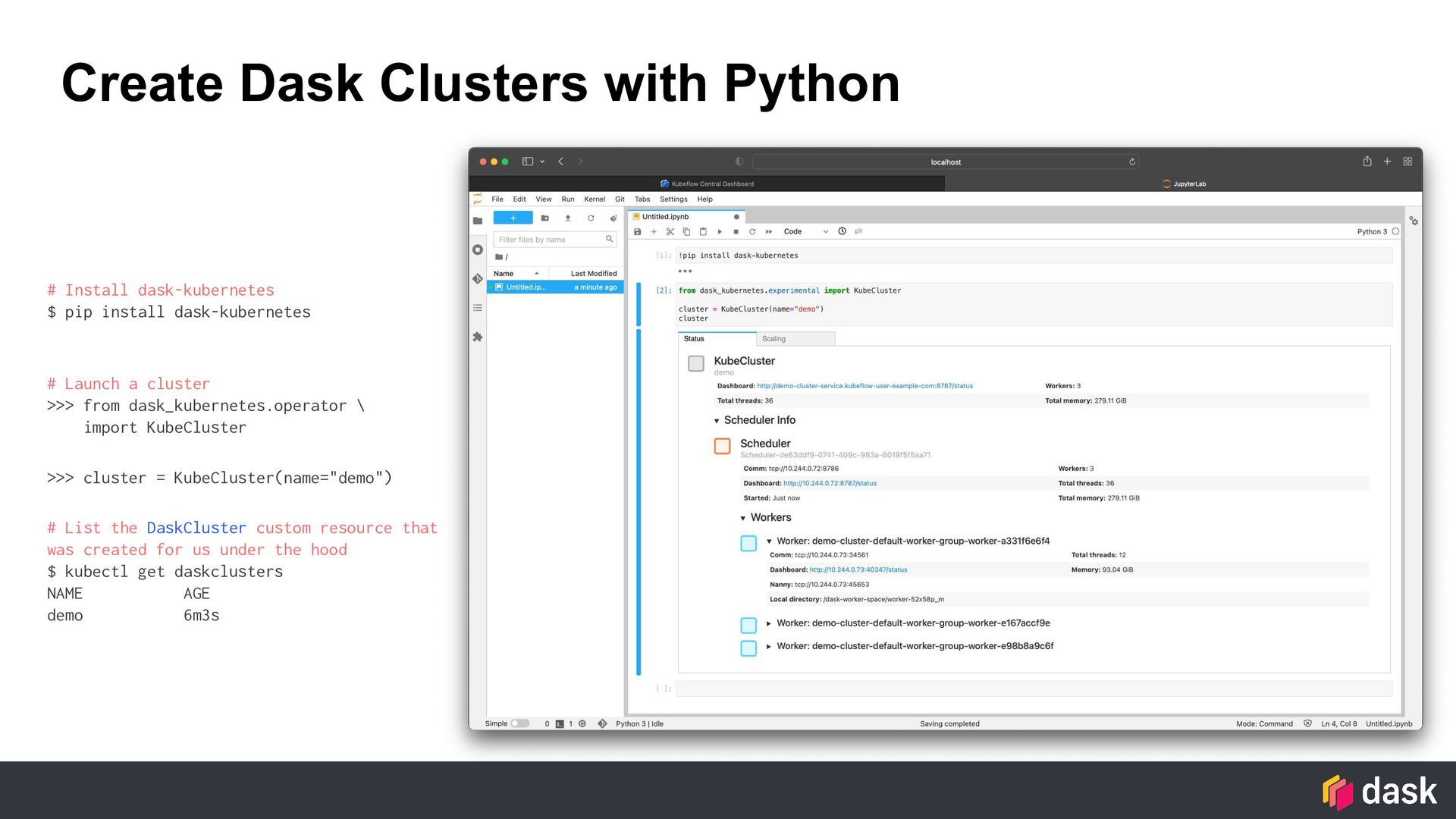
install dask-kubernetes # Launch a cluster >>> from dask_kubernetes.operator \ import KubeCluster >>> cluster = KubeCluster(name="demo") # List the DaskCluster custom resource that was created for us under the hood $ kubectl get daskclusters NAME AGE demo 6m3s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}