Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ゲームから学ぶ、いちばん速いインシデント対応
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Kazuto Kusama
October 02, 2024
Technology
240
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ゲームから学ぶ、いちばん速いインシデント対応
Cloud Operator Days Tokyo 2024で発表した資料です
Kazuto Kusama
October 02, 2024
More Decks by Kazuto Kusama
See All by Kazuto Kusama
趣味でイベント配信をやっている者だ
jacopen
1
24
自宅LLMの話
jacopen
2
860
プラットフォームエンジニアリングはAI時代の開発者をどう救うのか
jacopen
9
5.5k
OpenClawで回す組織運営
jacopen
3
1.2k
SREの仕事を自動化する際にやっておきたい5つのポイント
jacopen
6
1.7k
AI時代のインシデント対応 〜時代を切り抜ける、組織アーキテクチャ〜
jacopen
4
410
AI時代の開発とPlatform Engineeringについて考える
jacopen
0
270
AI によってシステム障害が増える!? ~AI エージェント時代だからこそ必要な、インシデントとの向き合い方~
jacopen
4
420
インシデント対応に必要となるAIの利用パターンとPagerDutyの関係
jacopen
0
450
Other Decks in Technology
See All in Technology
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
460
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
12
8.1k
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
3.3k
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
410
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.3k
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
3
4k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
210
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
260
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
240
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
3.8k
CIで使うClaude
iwatatomoya
0
280
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
190
Featured
See All Featured
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
190
The Curse of the Amulet
leimatthew05
2
13k
Utilizing Notion as your number one productivity tool
mfonobong
4
400
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
380
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
Design in an AI World
tapps
1
260
A better future with KSS
kneath
240
18k
Transcript
ゲームから学ぶ いちばん速い インシデント対応 PagerDuty - Product Evangelist Kazuto Kusama @jacopen
Kazuto Kusama @jacopen Product Evangelist @PagerDuty Japan Organizer @Platform Engineering
Meetup Founder @Cloud Native Innovators Association
本日ブースでワンオペしてます!
インシデント対応、どうやってますか?
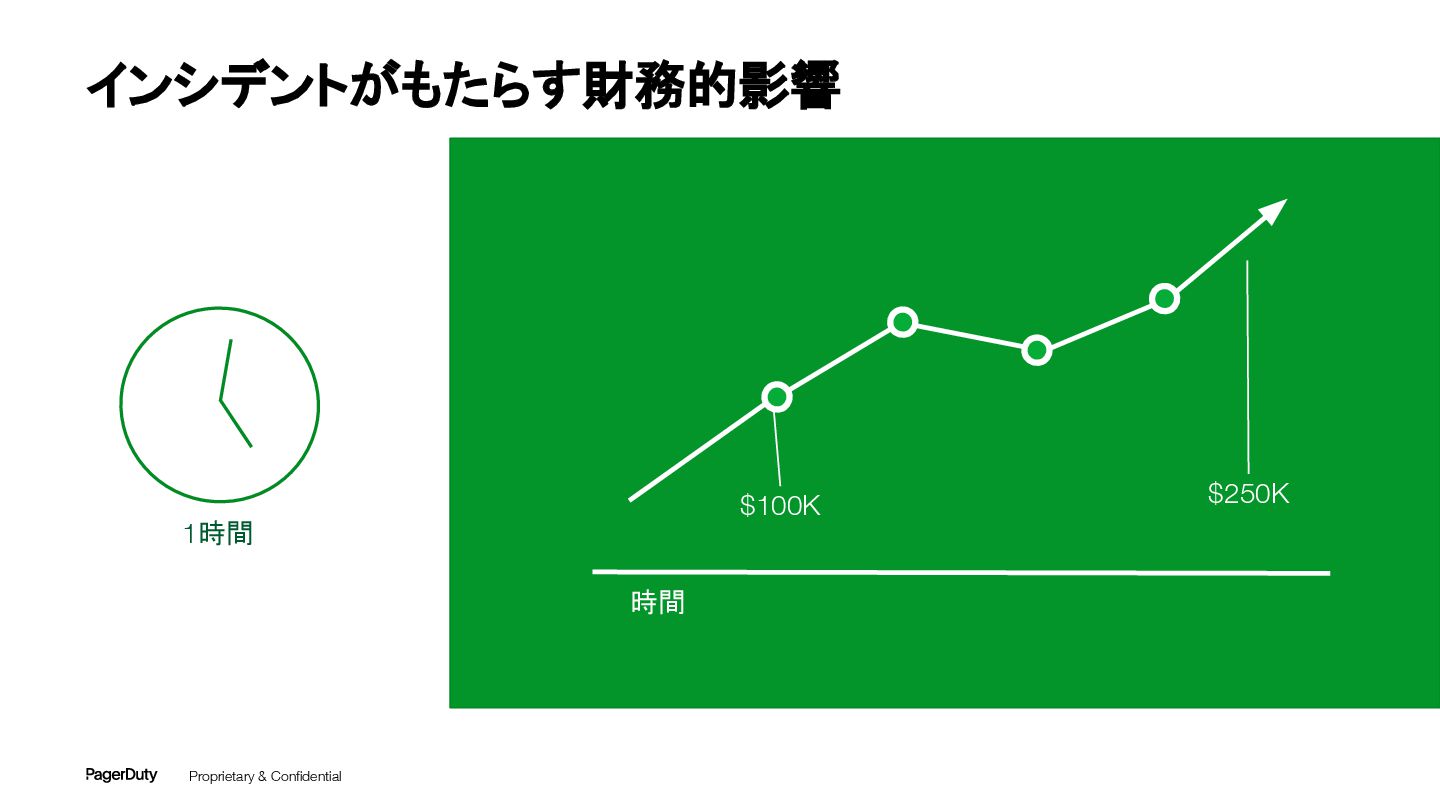
Proprietary & Confidential 1時間 時間 $100K $250K インシデントがもたらす財務的影響
$5.4B フォーチュン 500企業における 財務的な損害額 (推計) Source: Parametrix
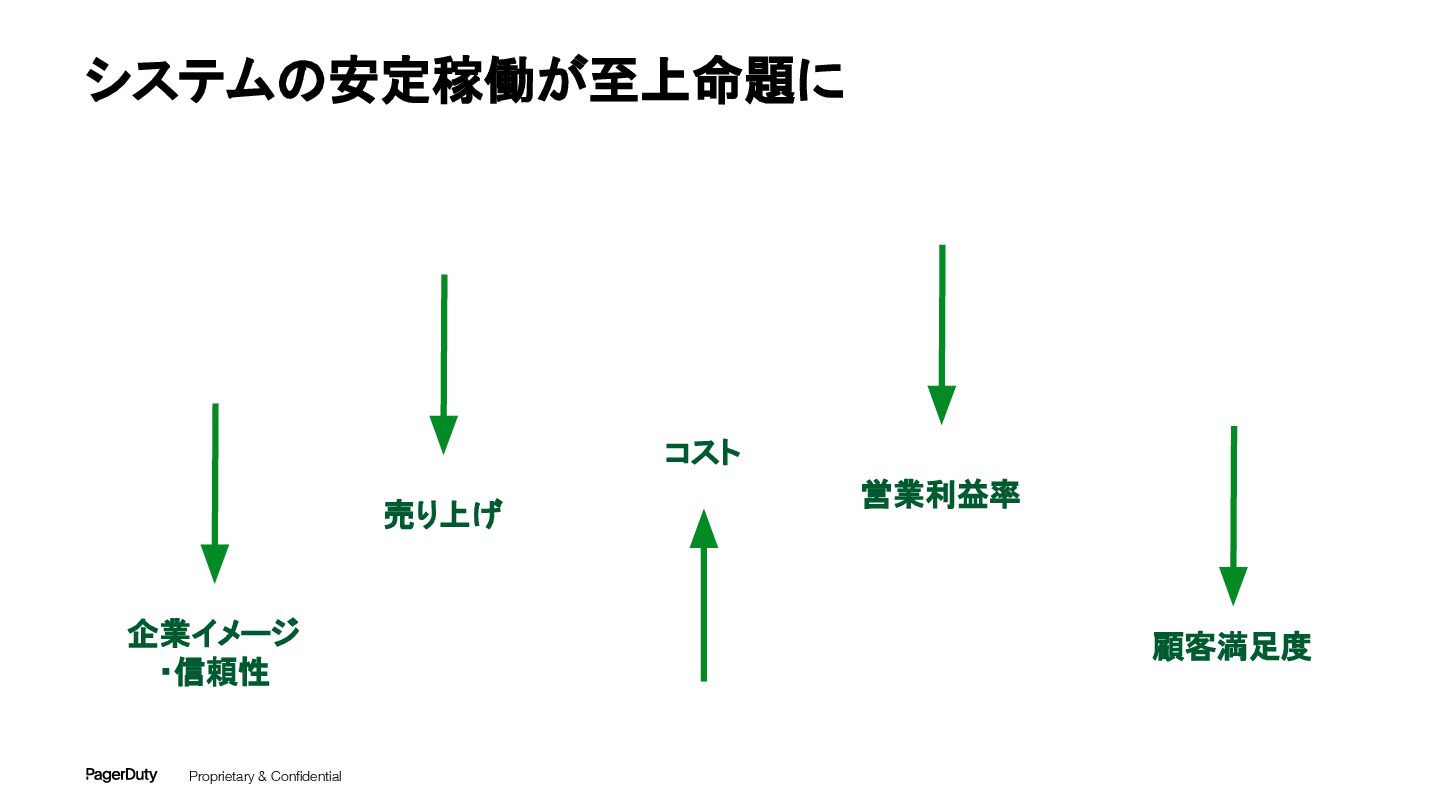
Proprietary & Confidential システムの安定稼働が至上命題に コスト 企業イメージ ・信頼性 売り上げ 顧客満足度 営業利益率
いかに早く インシデント対応できるかが大事
つまり RTA
RTA (Real Time Attack) RTAとは、ゲームをクリアするまでの実時間を競うプレイスタイル。海外では「 Speed Run」とも呼ばれる
RTA (Real Time Attack) RTAとは、ゲームをクリアするまでの実 時間を競うプレイスタイル。海外では 「Speed Run」とも呼ばれる インシデント対応
RTAで大事なこと • 徹底的なゲーム理解 • ゲームのメカニクスを深く理解することが不可欠。仕組みの研究に多大な時間を割く • 完璧な操作の習得 • フレーム単位で入力するスキルが求められる •
ルート最適化の継続 • 常に新しいショートカットやテクニックを模索 • 分析と改善 • 過去のランを記録し、セグメントごとの時間を分析。弱点を特定し重点的に練習 • コミュニティとの連携 • 他のランナーとの情報交換や競争によりモチベーション維持と技術向上 • 健康管理 • 常に安定したパフォーマンスを出すため、また継続して改善を続けるためのサステナビリティ
インシデント対応で大事なこと • 徹底的な理解と準備 • システムやプロセスの深い理解、事前の計画と準備 • 迅速な対応と意思決定 • 問題の素早い検知と初期対応 •
継続的な学習 • 各インシデントからの教訓を活かした継続的な学習と改善 • 分析と改善 • インシデントの詳細な分析と対応プロセスの最適化 • チームワークとコミュニティの重要性 • チーム内の連携や外部ステークホルダーとの協力 • 健康管理 • 常に安定したパフォーマンスを出すため、また継続して改善を続けるためのサステナビリティ
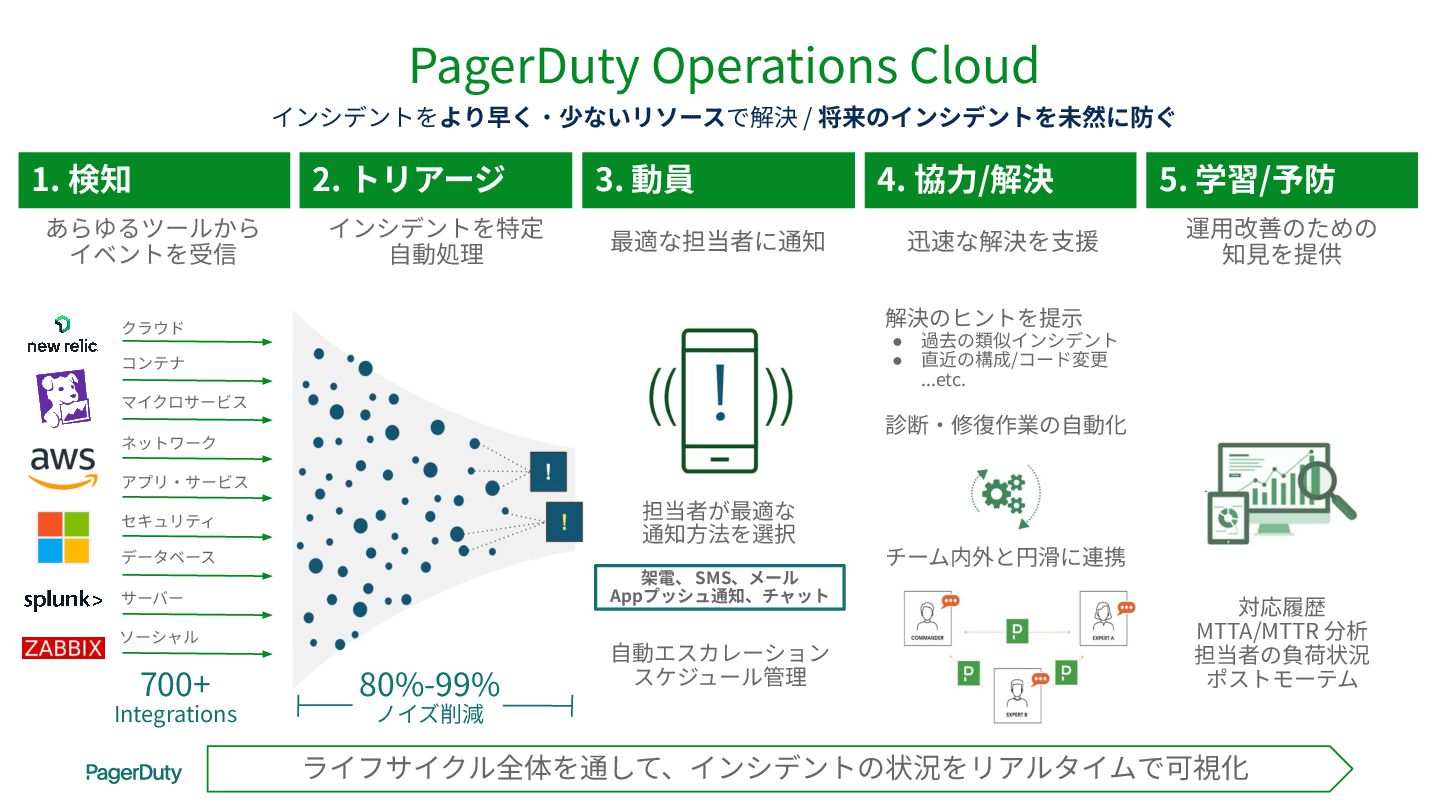
1. 検知 2. トリアージ 3. 動員 4. 協⼒/解決 5. 学習/予防
ライフサイクル全体を通して、インシデントの状況をリアルタイムで可視化 インシデントを特定 ⾃動処理 運⽤改善のための 知⾒を提供 最適な担当者に通知 迅速な解決を⽀援 あらゆるツールから イベントを受信 架電、 SMS、メール Appプッシュ通知、チャット ⾃動エスカレーション スケジュール管理 診断‧修復作業の⾃動化 チーム内外と円滑に連携 クラウド コンテナ マイクロサービス ネットワーク アプリ‧サービス セキュリティ データベース サーバー ソーシャル PagerDuty Operations Cloud インシデントをより早く‧少ないリソースで解決 / 将来のインシデントを未然に防ぐ 担当者が最適な 通知⽅法を選択 対応履歴 MTTA/MTTR 分析 担当者の負荷状況 ポストモーテム 解決のヒントを提⽰ • 過去の類似インシデント • 直近の構成/コード変更 ...etc. 80%-99% ノイズ削減 700+ Integrations
インシデント対応で大事なこと • 徹底的な理解と準備 • システムやプロセスの深い理解、事前の計画と準備 • 迅速な対応と意思決定 • 問題の素早い検知と初期対応 •
継続的な学習 • 各インシデントからの教訓を活かした継続的な学習と改善 • 分析と改善 • インシデントの詳細な分析と対応プロセスの最適化 • チームワークとコミュニティの重要性 • チーム内の連携や外部ステークホルダーとの協力 • 健康管理 • 常に安定したパフォーマンスを出すため、また継続して改善を続けるためのサステナビリティ
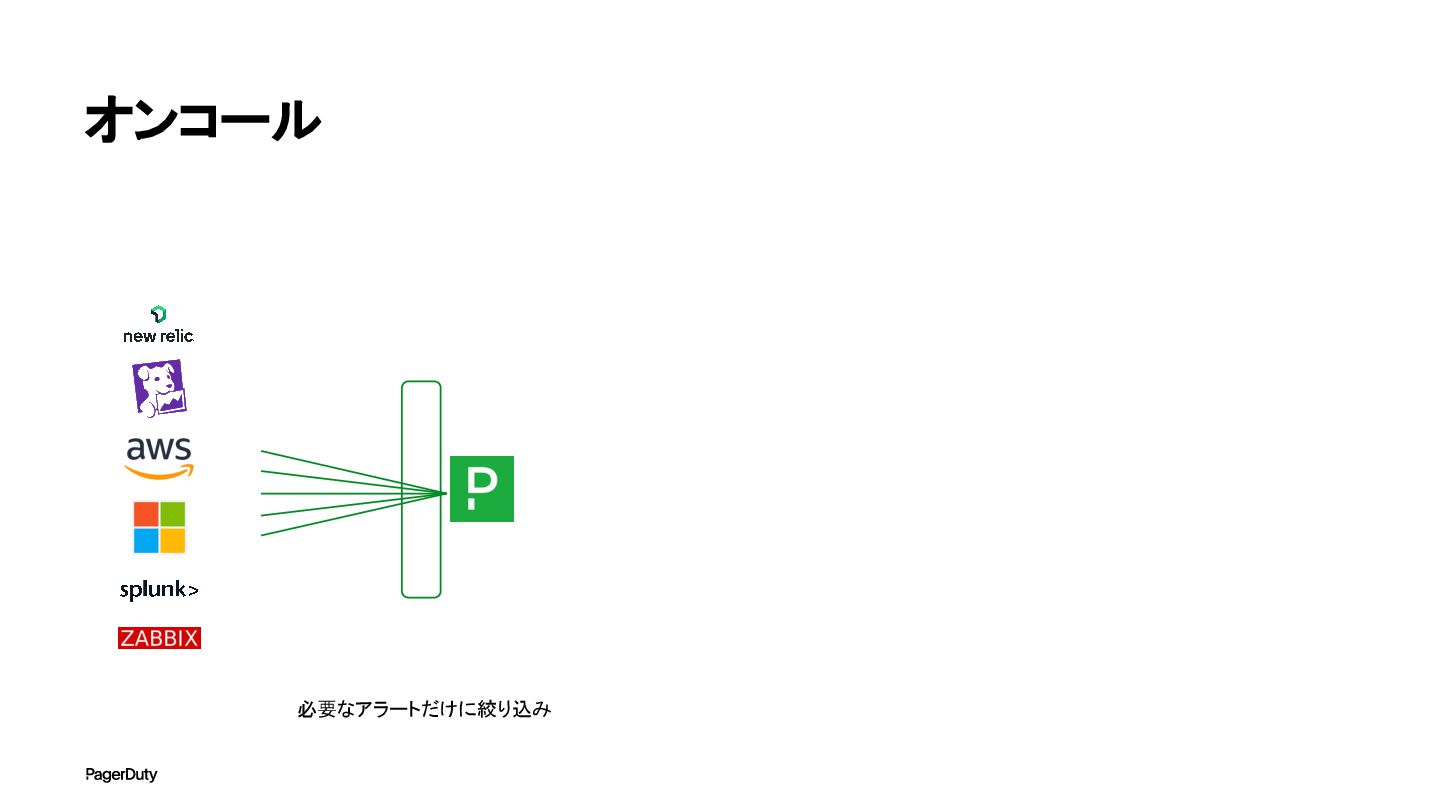
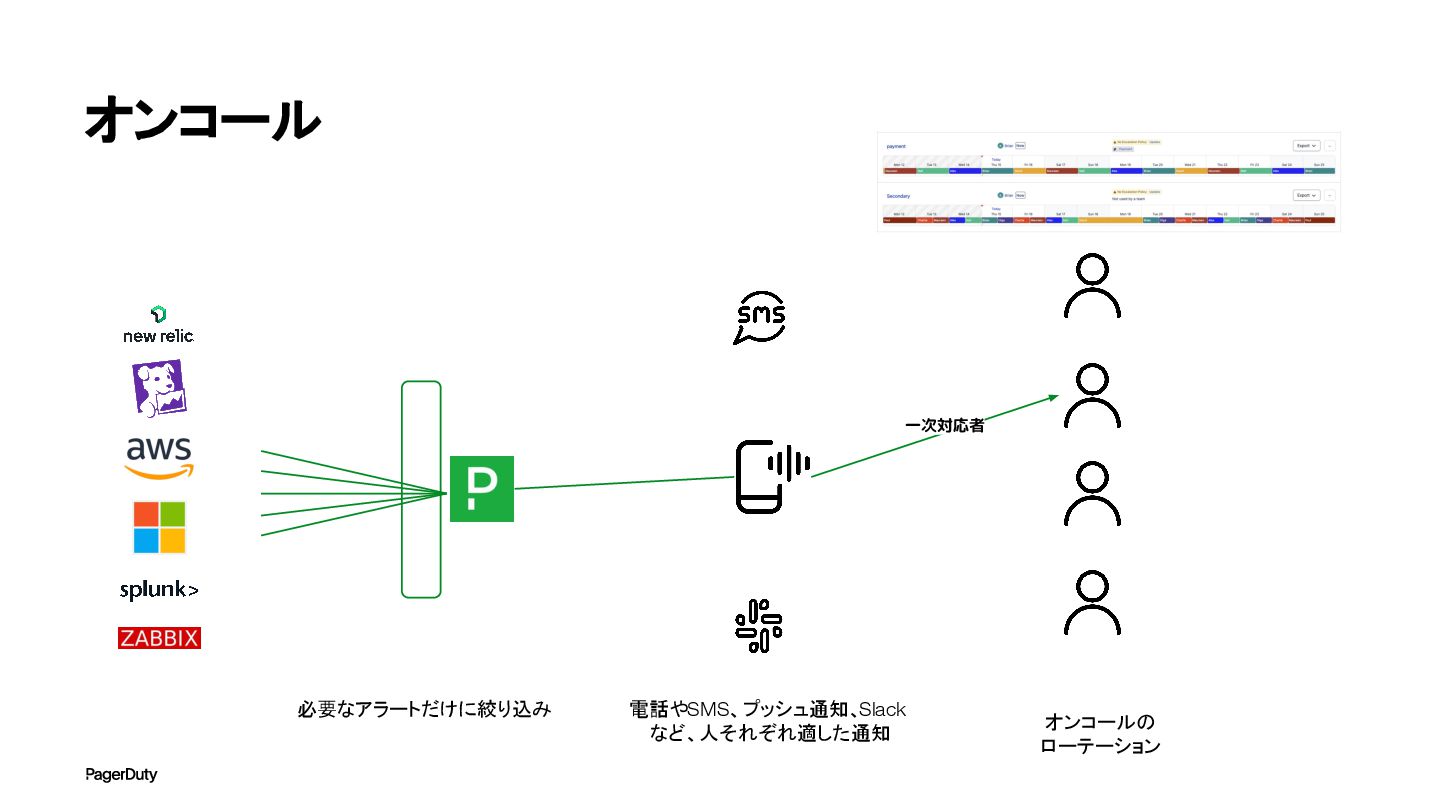
オンコール 必要なアラートだけに絞り込み
オンコール 必要なアラートだけに絞り込み 電話やSMS、プッシュ通知、Slack など、人それぞれ適した通知 一次対応者 オンコールの ローテーション
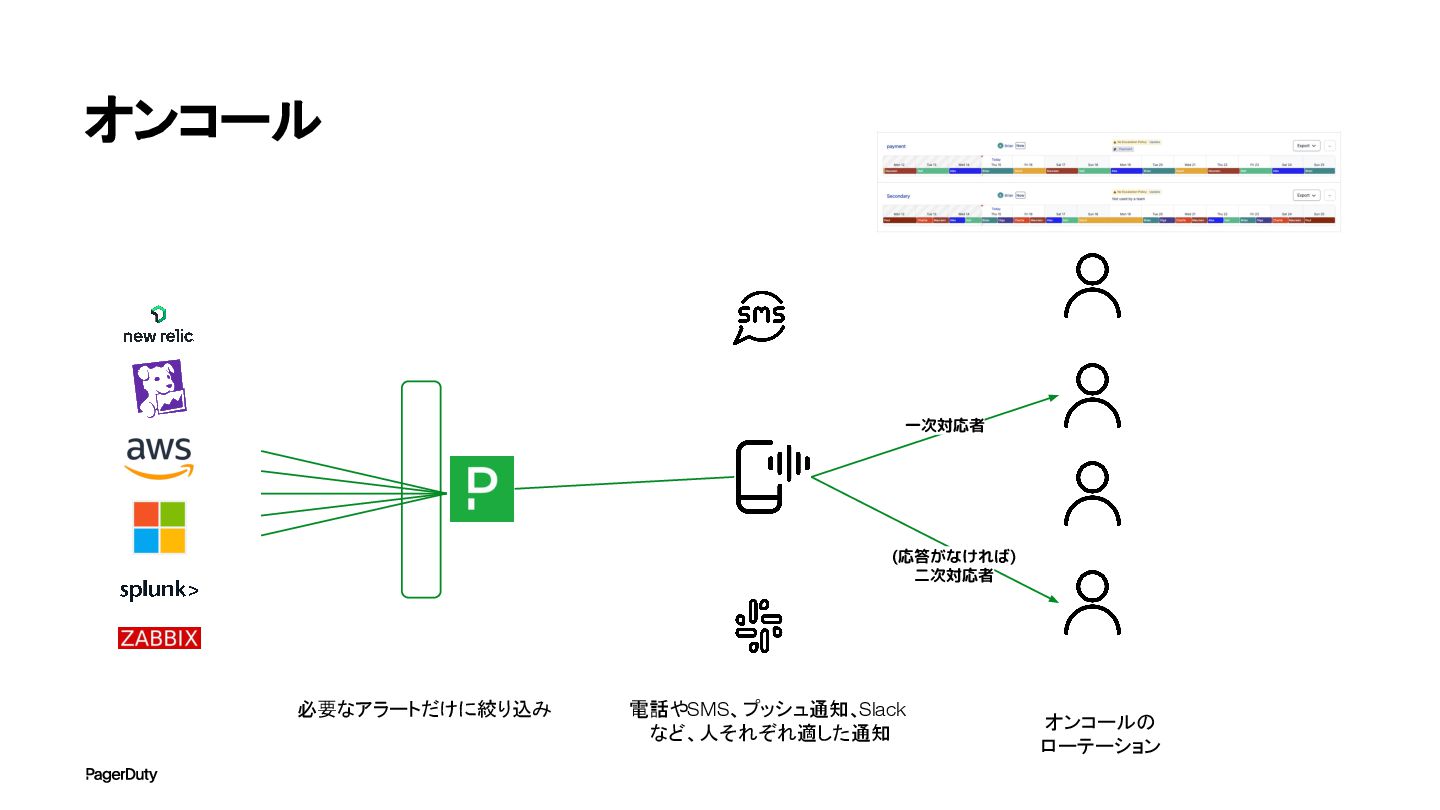
オンコール 必要なアラートだけに絞り込み 電話やSMS、プッシュ通知、Slack など、人それぞれ適した通知 一次対応者 (応答がなければ) 二次対応者 オンコールの ローテーション
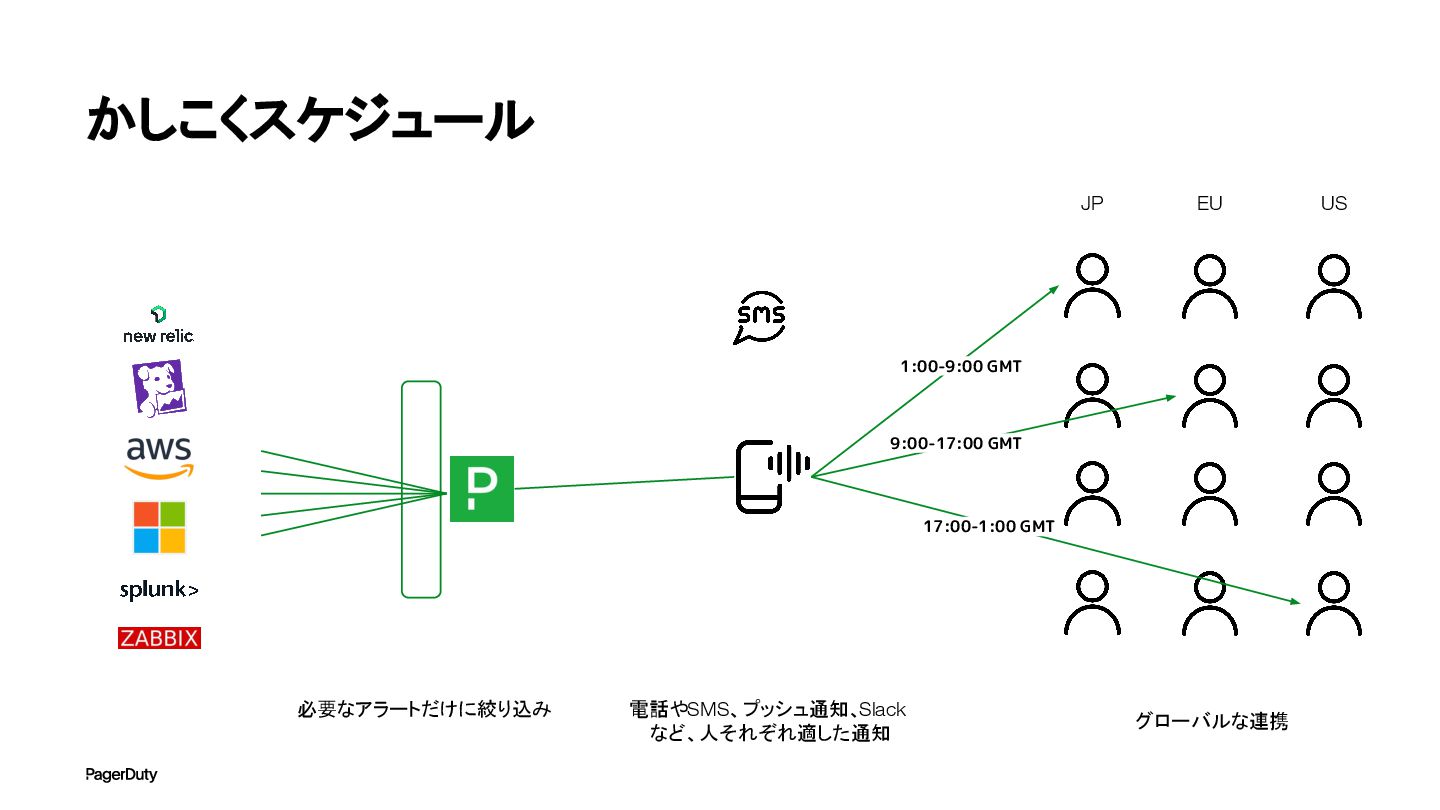
かしこくスケジュール 必要なアラートだけに絞り込み 電話やSMS、プッシュ通知、Slack など、人それぞれ適した通知 9:00-17:00 GMT グローバルな連携 JP EU US
17:00-1:00 GMT 1:00-9:00 GMT
インシデント対応で大事なこと • 徹底的な理解と準備 • システムやプロセスの深い理解、事前の計画と準備 • 迅速な対応と意思決定 • 問題の素早い検知と初期対応 •
継続的な学習 • 各インシデントからの教訓を活かした継続的な学習と改善 • 分析と改善 • インシデントの詳細な分析と対応プロセスの最適化 • チームワークとコミュニティの重要性 • チーム内の連携や外部ステークホルダーとの協力 • 健康管理 • 常に安定したパフォーマンスを出すため、また継続して改善を続けるためのサステナビリティ
+ だと Past Incidents 過去の類似インシデント一覧と、 発生時期・回数のヒートマップを表示。 Related Incidents 他サービスで現在発生している、 関連性の高いインシデントを表示。
インシデント対応のカテゴリ インシデント対応はAny%ではない Any%とは・・・ 達成率関係なし、バグ利用あり、とにかく早ければいい 制約 • 安全性の確保。2次災害を起こしてはいけない • 証拠の適切な収集と保全 •
ステークホルダーへの適切な情報提供 • 根本原因分析の徹底 • 対処療法ではなく、再発防止のための原因究明
RTAとインシデント対応が異なるところ • RTAは予測可能な世界との戦い • インシデント対応は予測不可能 な世界との戦い • RTAのラン中は自分との戦い • インシデント対応中は自分・チーム・経営陣・顧客などあらゆるステーク
ホルダーが関与
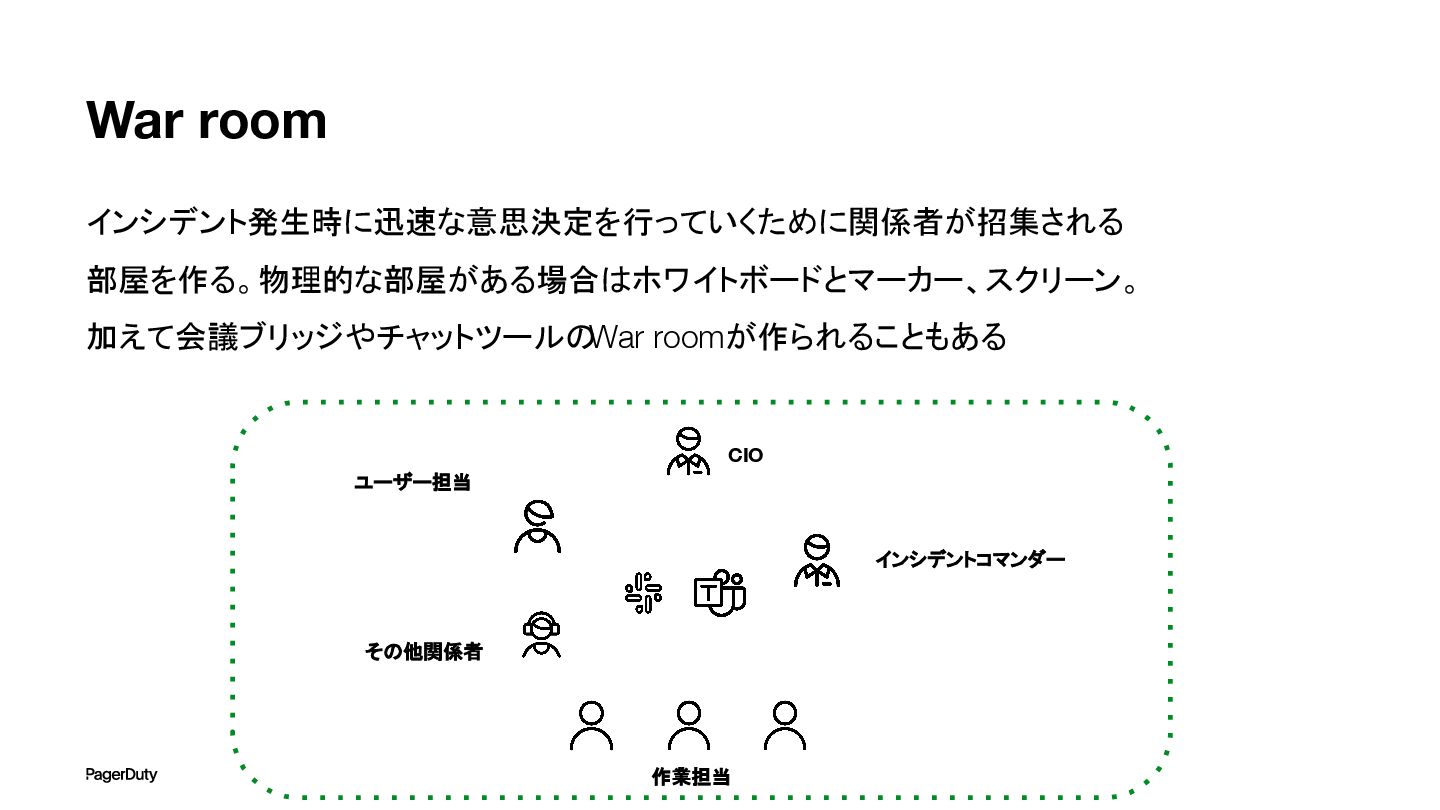
War room インシデント発生時に迅速な意思決定を行っていくために関係者が招集される 部屋を作る。物理的な部屋がある場合はホワイトボードとマーカー、スクリーン。 加えて会議ブリッジやチャットツールの War roomが作られることもある 作業担当 CIO ユーザー担当
その他関係者 インシデントコマンダー
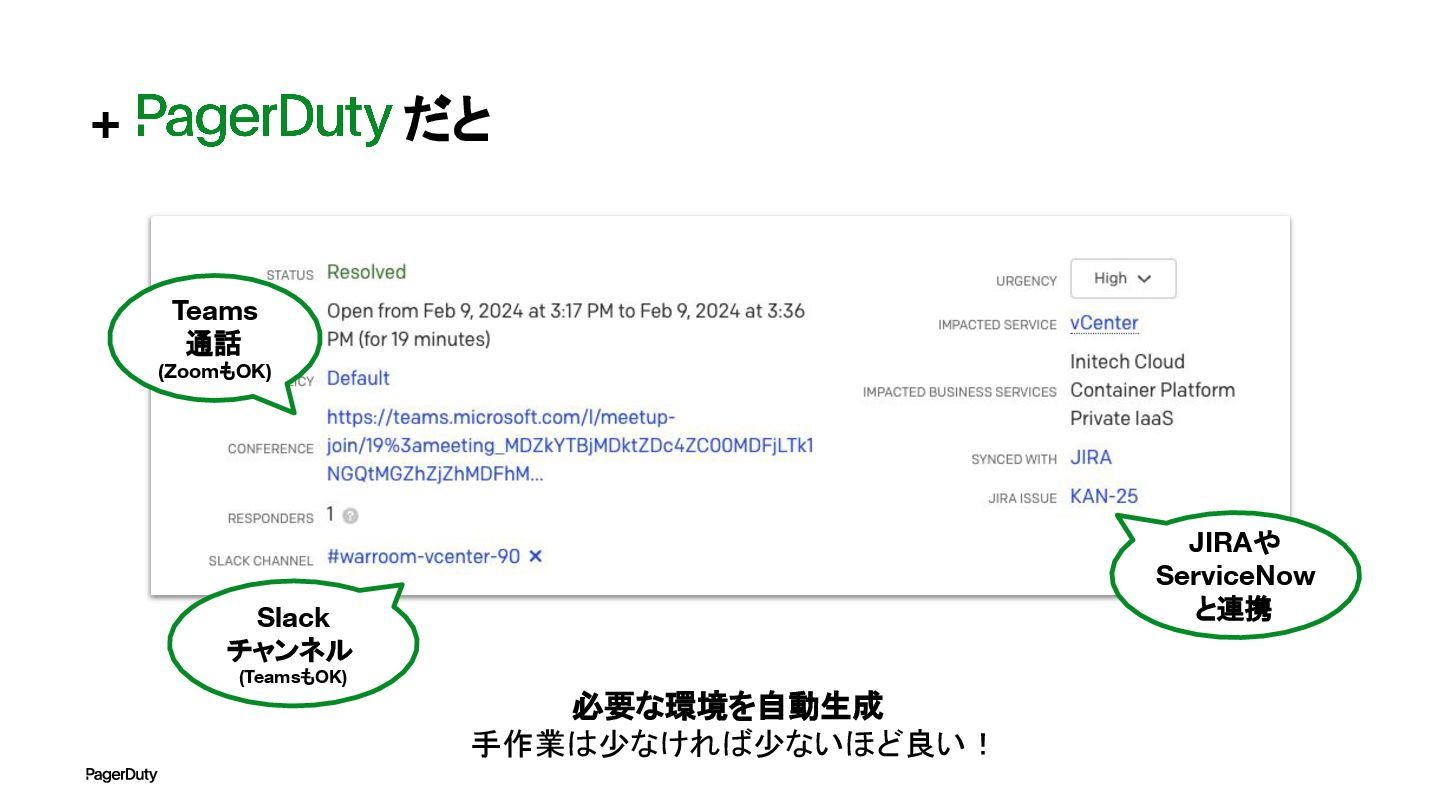
+ だと Teams 通話 (ZoomもOK) Slack チャンネル (TeamsもOK) JIRAや ServiceNow
と連携 必要な環境を自動生成 手作業は少なければ少ないほど良い!
ポストモーテム SREのプラクティスでおなじみ • インシデントのインパクト • 緩和や解消のために行われたアクション • 根本原因 • インシデントの再発を避けるためのフォローアップ
きちんと纏めておくことで、組織としての成長に繋がる。スタンドプレーだとこのあたりの取り組みが 行われないことが多い
+ だと Postmotems ポストモーテムの作成を支援。受信したイベント、ステータスアップデート、インシデント ノート、Slackの会話などからタイムラインを作成
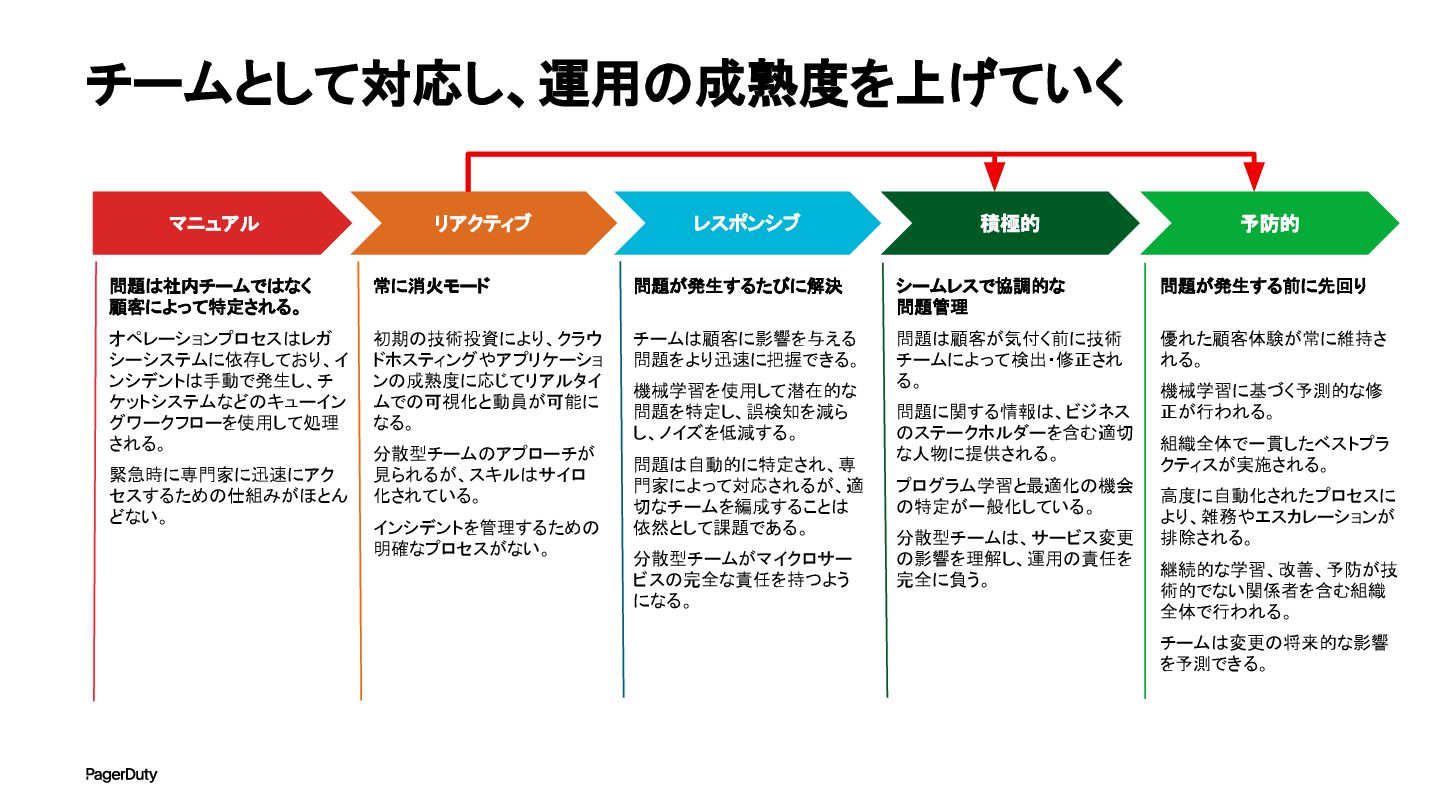
マニュアル リアクティブ レスポンシブ 積極的 予防的 問題は社内チームではなく 顧客によって特定される。 オペレーションプロセスはレガ シーシステムに依存しており、イ ンシデントは手動で発生し、チ
ケットシステムなどのキューイン グワークフローを使用して処理 される。 緊急時に専門家に迅速にアク セスするための仕組みがほとん どない。 常に消火モード 初期の技術投資により、クラウ ドホスティングやアプリケーショ ンの成熟度に応じてリアルタイ ムでの可視化と動員が可能に なる。 分散型チームのアプローチが 見られるが、スキルはサイロ 化されている。 インシデントを管理するための 明確なプロセスがない。 問題が発生する前に先回り 優れた顧客体験が常に維持さ れる。 機械学習に基づく予測的な修 正が行われる。 組織全体で一貫したベストプラ クティスが実施される。 高度に自動化されたプロセスに より、雑務やエスカレーションが 排除される。 継続的な学習、改善、予防が技 術的でない関係者を含む組織 全体で行われる。 チームは変更の将来的な影響 を予測できる。 問題が発生するたびに解決 チームは顧客に影響を与える 問題をより迅速に把握できる。 機械学習を使用して潜在的な 問題を特定し、誤検知を減ら し、ノイズを低減する。 問題は自動的に特定され、専 門家によって対応されるが、適 切なチームを編成することは 依然として課題である。 分散型チームがマイクロサー ビスの完全な責任を持つよう になる。 シームレスで協調的な 問題管理 問題は顧客が気付く前に技術 チームによって検出・修正され る。 問題に関する情報は、ビジネス のステークホルダーを含む適切 な人物に提供される。 プログラム学習と最適化の機会 の特定が一般化している。 分散型チームは、サービス変更 の影響を理解し、運用の責任を 完全に負う。 チームとして対応し、運用の成熟度を上げていく
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}