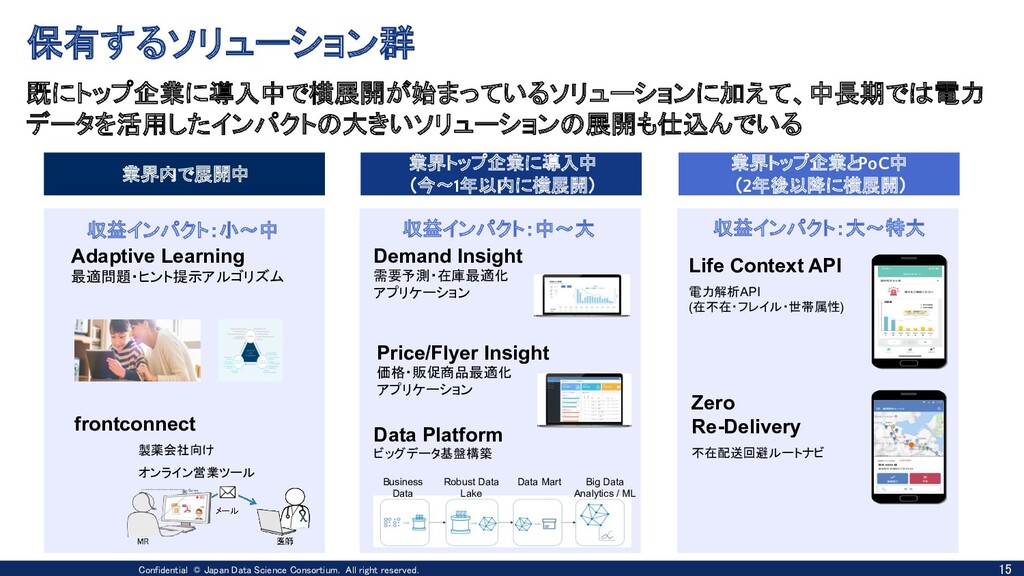
収益インパクト:小~中 収益インパクト:中~大 収益インパクト:大~特大 Zero Re-Delivery 不在配送回避ルートナビ frontconnect 製薬会社向け オンライン営業ツール Price/Flyer Insight 価格・販促商品最適化 アプリケーション Demand Insight 需要予測・在庫最適化 アプリケーション Life Context API 電力解析API (在不在・フレイル・世帯属性) Adaptive Learning 最適問題・ヒント提示アルゴリズム Data Platform ビッグデータ基盤構築 Business Data Robust Data Lake Data Mart Big Data Analytics / ML 既にトップ企業に導入中で横展開が始まっているソリューションに加えて、中長期では電力 データを活用したインパクトの大きいソリューションの展開も仕込んでいる 業界内で展開中 業界トップ企業に導入中 (今~1年以内に横展開) 業界トップ企業とPoC中 (2年後以降に横展開) 保有するソリューション群
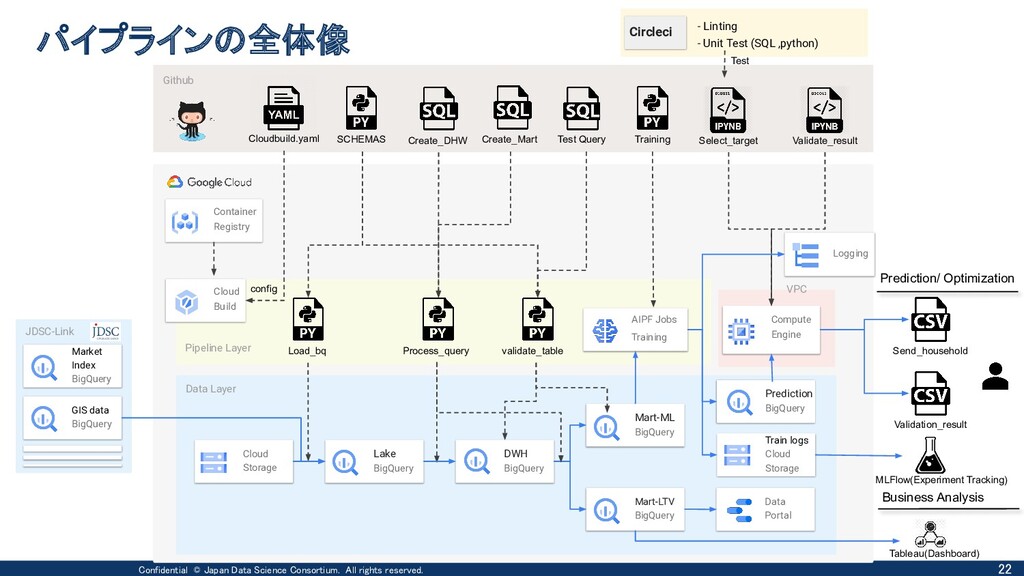
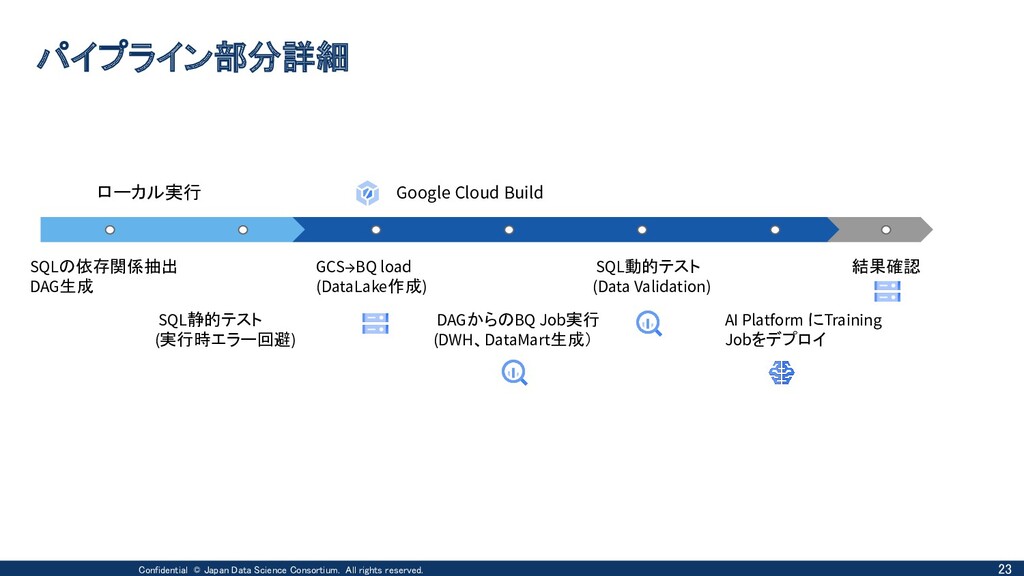
Cloud Buildを用いたMLワークフロー実装のコンセプト ① cloudbuild.yaml上で 必要なステップを記述す ることでパイプラインを定 義 ② 複雑な条件分岐は呼び 出し先のPythonで対応 (社内Package) ③ Computationが必要な場 面は基本マネージドに寄 せる 複数SQLの依存関係抽出&静的解析 依存関係付きSQLの並列実行 AIPF Jobs Training BigQuery 前処理 学習
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
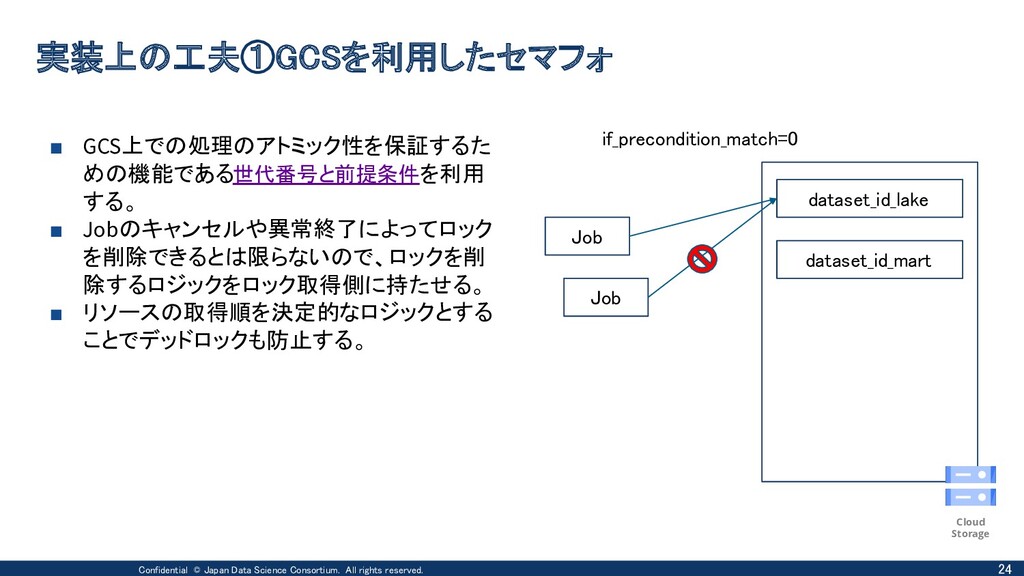{kind=link}
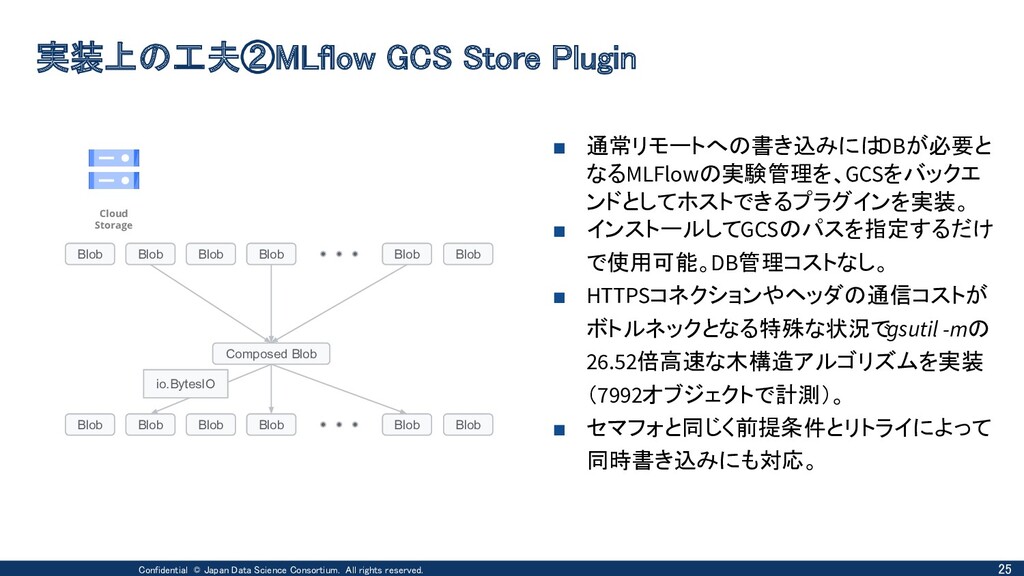{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
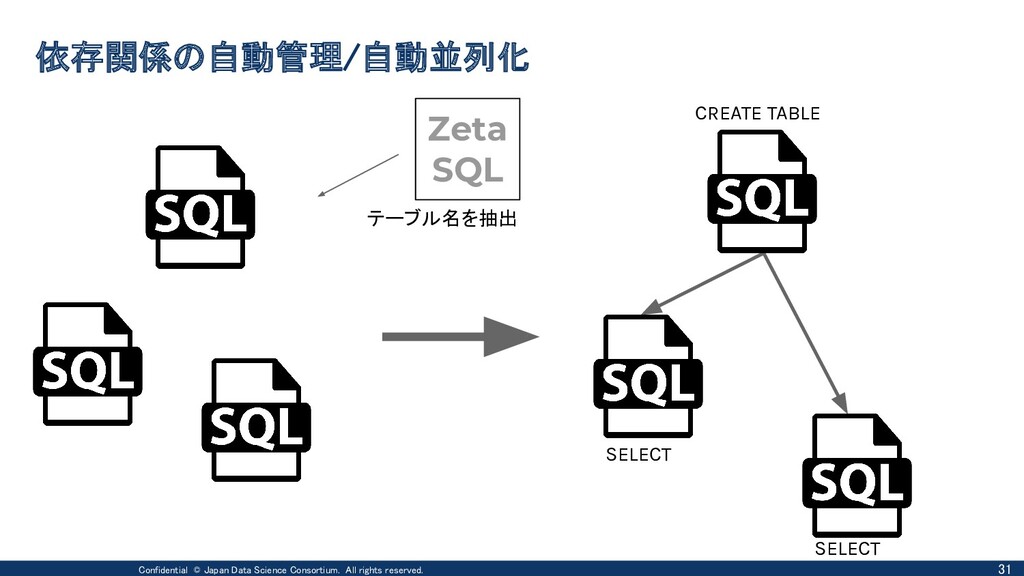{kind=link}
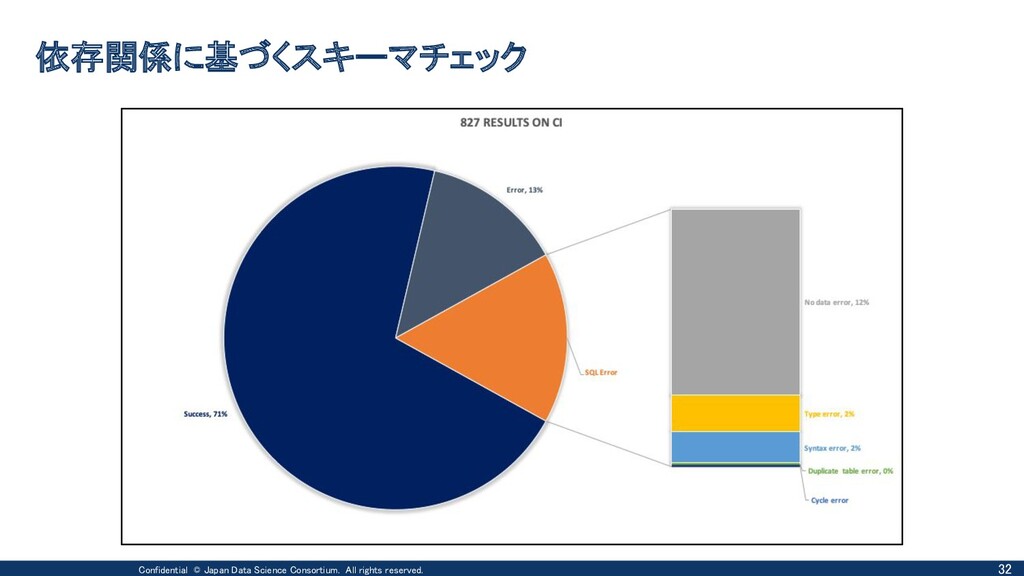{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}