Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kubeflowで作る共通データ基盤 (道半ば編)
Search
JDSC
August 19, 2021
Technology
310
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kubeflowで作る共通データ基盤 (道半ば編)
合同勉強会での資料です。
JDSC
August 19, 2021
More Decks by JDSC
See All by JDSC
会社説明資料2026下期
jdsc
1
16k
JDSC採用ページⅡ
jdsc
0
4.2k
JDSC採用ページ
jdsc
1
110k
Data Meshと私
jdsc
0
270
家電製品の異常検知 (Case Study)
jdsc
0
600
鉄道省エネに向けた車上データ活用事例の紹介
jdsc
0
850
InterpretMLと Explainable Boosting Machineのススメ
jdsc
1
3.2k
Google Cloud Build とAI Platformではじめる軽量MLOps pipelineとAlphaSQL
jdsc
0
520
JDSCの事業・技術
jdsc
0
18k
Other Decks in Technology
See All in Technology
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
420
グローバルチームと挑むプロダクト開発
sansantech
PRO
1
170
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
440
貴方はどのエンジニアリングを磨くのか
hatyibei
0
110
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
2k
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
4.9k
Road to SRE NEXTの今までとこれから
hiroyaonoe
0
260
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.1k
AIDLC_ヤフーショッピングの取り組み
lycorptech_jp
PRO
0
580
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
300
Featured
See All Featured
Writing Fast Ruby
sferik
630
63k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Practical Orchestrator
shlominoach
191
11k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
63
55k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
How to Ace a Technical Interview
jacobian
281
24k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Transcript
Kubeflowで作る共通データ基盤 (道半ば編)
自己紹介 - 石井 正浩 - SIerとか携帯屋さんとかを経て現職 - 朝起きたら”ものもらい”ができてて左目が あかない
今日話すこと - データ基盤開発の課題 - Kubeflow on GKEやってみた
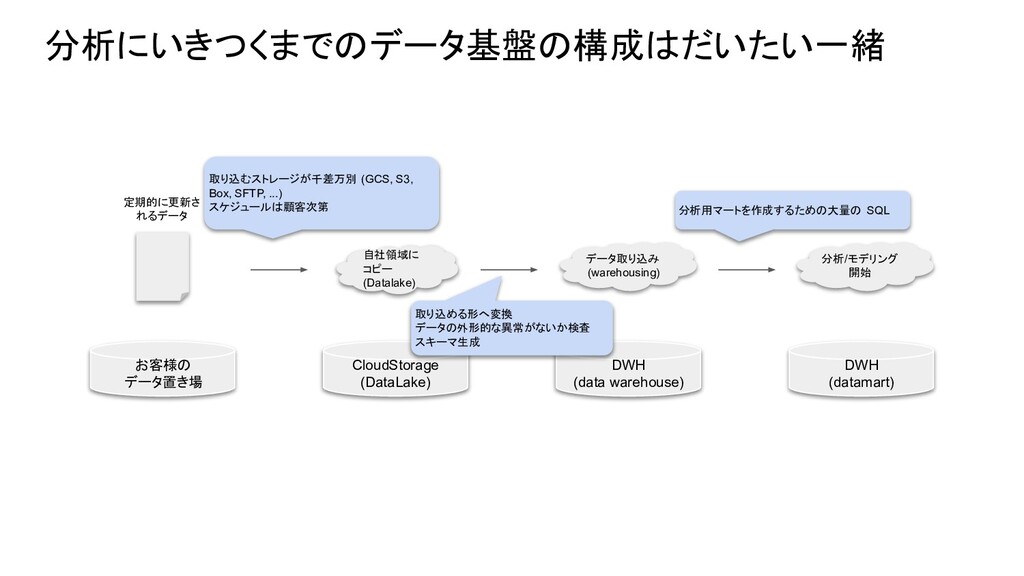
CloudStorage (DataLake) 分析にいきつくまでのデータ基盤の構成はだいたい一緒 お客様の データ置き場 定期的に更新さ れるデータ 自社領域に コピー (Datalake)
DWH (data warehouse) データ取り込み (warehousing) 分析/モデリング 開始 DWH (datamart) 取り込むストレージが千差万別 (GCS, S3, Box, SFTP, ...) スケジュールは顧客次第 取り込める形へ変換 データの外形的な異常がないか検査 スキーマ生成 分析用マートを作成するための大量の SQL
個別 vs 共通 個別に作るときの課題 - 案外大変 - 同じことやってる割に、毎回同じような工 数かかる(データエンジニア1人張り付き 1ヶ月とか)
- 一度や二度ならともかく、何回かやると 飽きる(個人の感想です) - ビジネス上の価値を作るのはあとの フェーズなので、ここは小さくしたい - 案件単位で実装だととっちらかる - 技術スタックが異なってしまう - 同じ機能が微妙に異なる実装で行われ る 共通化するときの課題 - 権限制御ミスると死ぬ - A社にB社のデータが見えてしまった・・・ (さすがにやったことはない ) - 計算リソースの想定がしにくい - 利用者が増えれば増えたぶんだけ、 スケールさせたい - 一方で利用者が少ないとき (時間帯)は 小さくしておきたい
Kubeflow on GKE
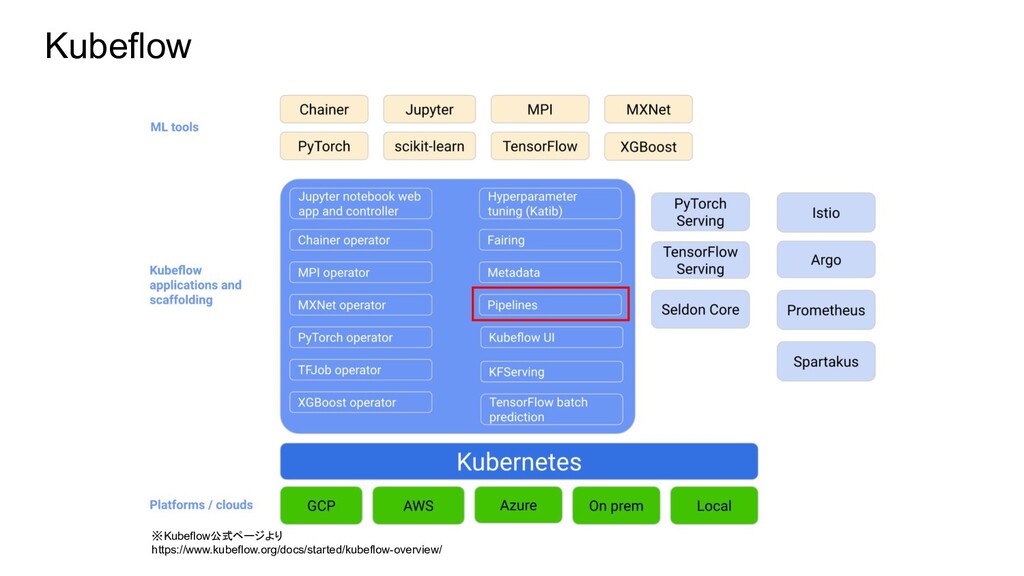
Kubeflow ※Kubeflow公式ページより https://www.kubeflow.org/docs/started/kubeflow-overview/
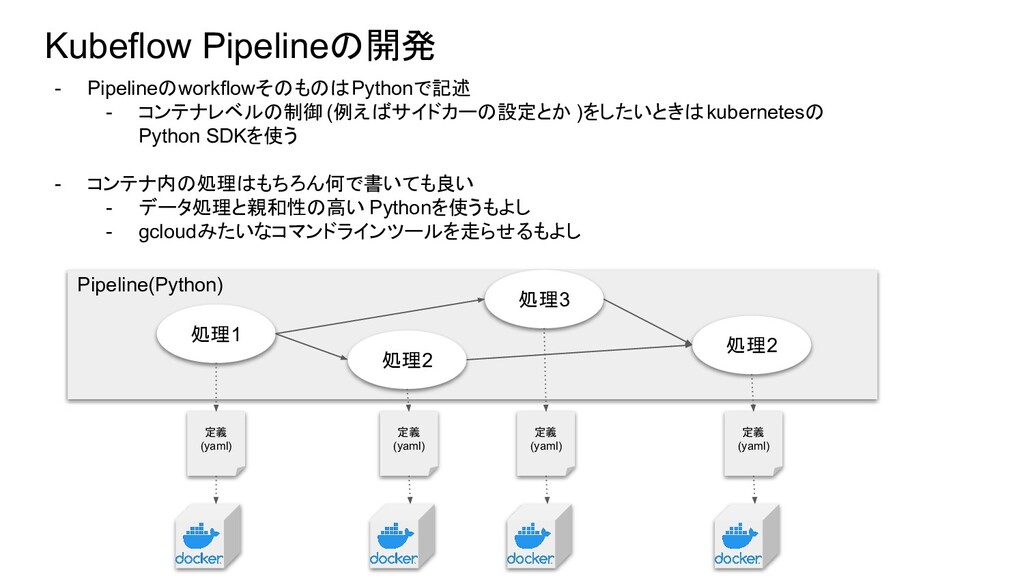
Kubeflow Pipelineの開発 - PipelineのworkflowそのものはPythonで記述 - コンテナレベルの制御 (例えばサイドカーの設定とか )をしたいときはkubernetesの Python SDKを使う
- コンテナ内の処理はもちろん何で書いても良い - データ処理と親和性の高い Pythonを使うもよし - gcloudみたいなコマンドラインツールを走らせるもよし Pipeline(Python) 処理1 処理2 定義 (yaml) 定義 (yaml) 処理3 処理2 定義 (yaml) 定義 (yaml)
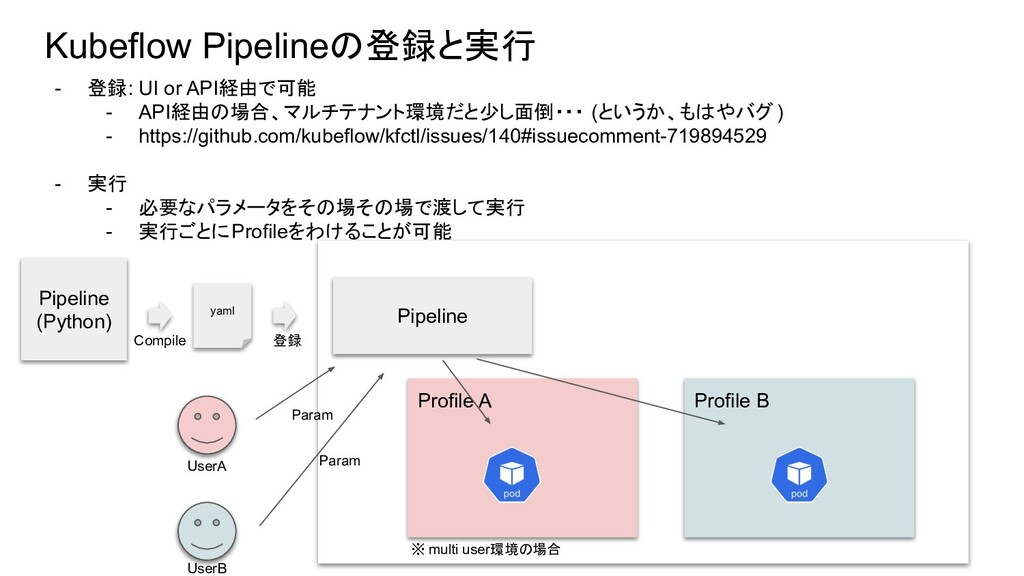
Kubeflow Pipelineの登録と実行 - 登録: UI or API経由で可能 - API経由の場合、マルチテナント環境だと少し面倒・・・ (というか、もはやバグ
) - https://github.com/kubeflow/kfctl/issues/140#issuecomment-719894529 - 実行 - 必要なパラメータをその場その場で渡して実行 - 実行ごとにProfileをわけることが可能 Pipeline (Python) yaml Compile 登録 Pipeline UserA UserB Profile A Profile B ※ multi user環境の場合 Param Param
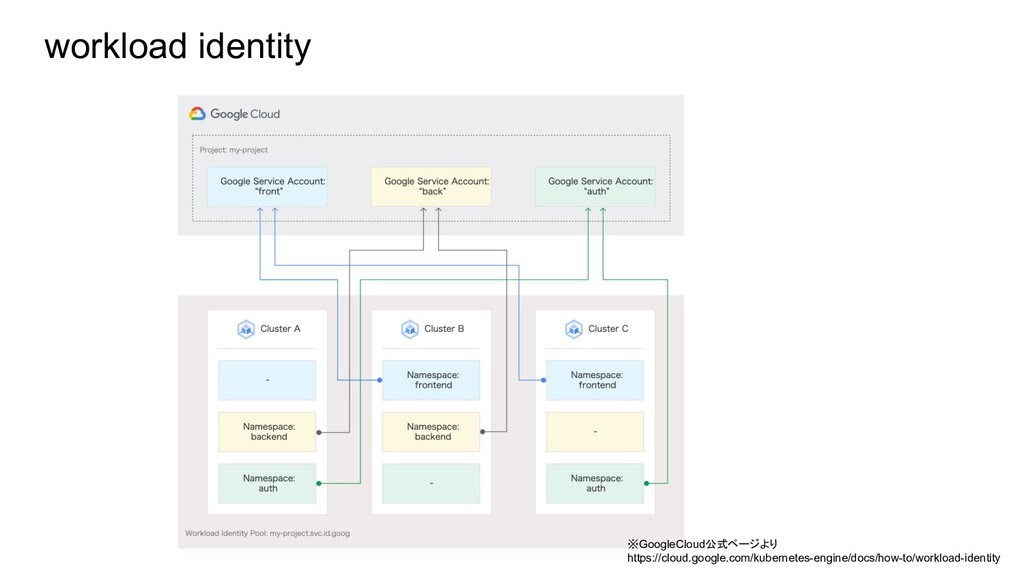
workload identity ※GoogleCloud公式ページより https://cloud.google.com/kubernetes-engine/docs/how-to/workload-identity
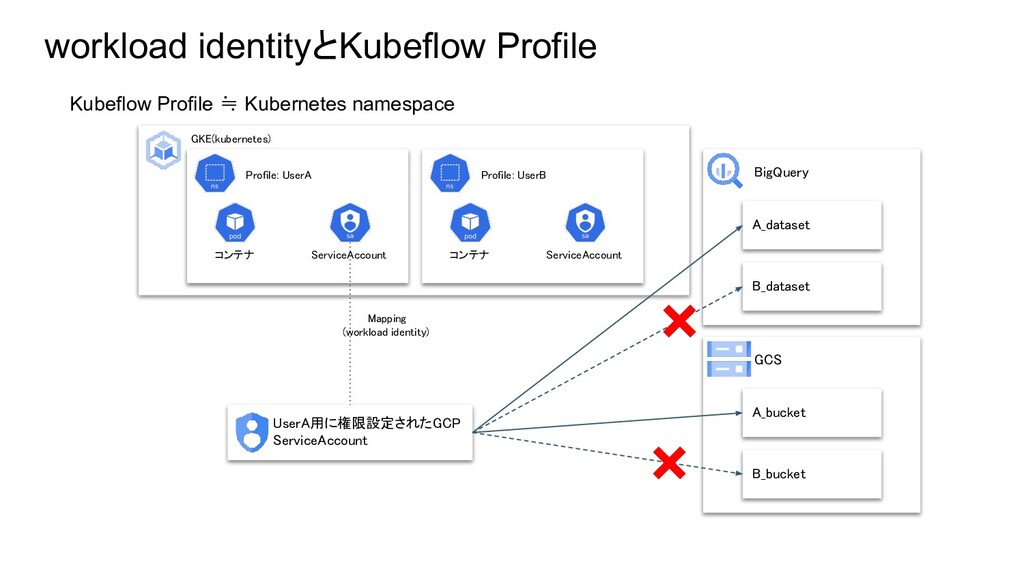
workload identityとKubeflow Profile Kubeflow Profile ≒ Kubernetes namespace UserA用に権限設定されたGCP ServiceAccount
BigQuery A_dataset ServiceAccount Profile: UserA コンテナ B_dataset Mapping (workload identity) GCS A_bucket B_bucket GKE(kubernetes) ServiceAccount Profile: UserB コンテナ
まとめ - Kubeflow on GKE、良いところばっかり書きましたが辛いところも多そうです - ドキュメントはout-of-date感たっぷり、英語しかない - 一度謎に壊れたときは作り直す以外なかった (逆に言えばそういう前提で作っておくと良さそ
う) - ただ、 - GKEと組み合わせたときの使い勝手はなかなか良い - 今回の使い方にはまあハマってそう - なんとなくミライを感じる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}