12 Hi, I’m Jonathan Marmor, a software developer at exfm. Today I’m going to talk about * what exfm does, * how exfm uses MongoDB, * and tell you a little about the Monthly Music Hackathon I’m organizing. First I should tell you a little about me, to lower your expectations a bit. :) * musician, all of my schooling is in music * use python as tool to help compose music * not an expert in mongo * not going to talk about advanced topics * instead will talk basic practicalities of how mongo is used at exfm * if you want more details, get in touch and I’ll pass you off to our CTO, Lucas
MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 3. Monthly Music Hackathon NYC Tuesday, October 2, 12 what exfm does: going to get into this in some depth how exfm uses mongo: environment which software we use models how our data is organized, how our code is organized server architecture brief overview of our hardware management and tools monitoring, scripting, handy stuff future plans how we’re going to blow it up and put it back together again monthly music hackathon nyc: fun part
We have a browser extension It turns websites into playlists It makes it easier to listen to music which has been posted on a website For example: (next)
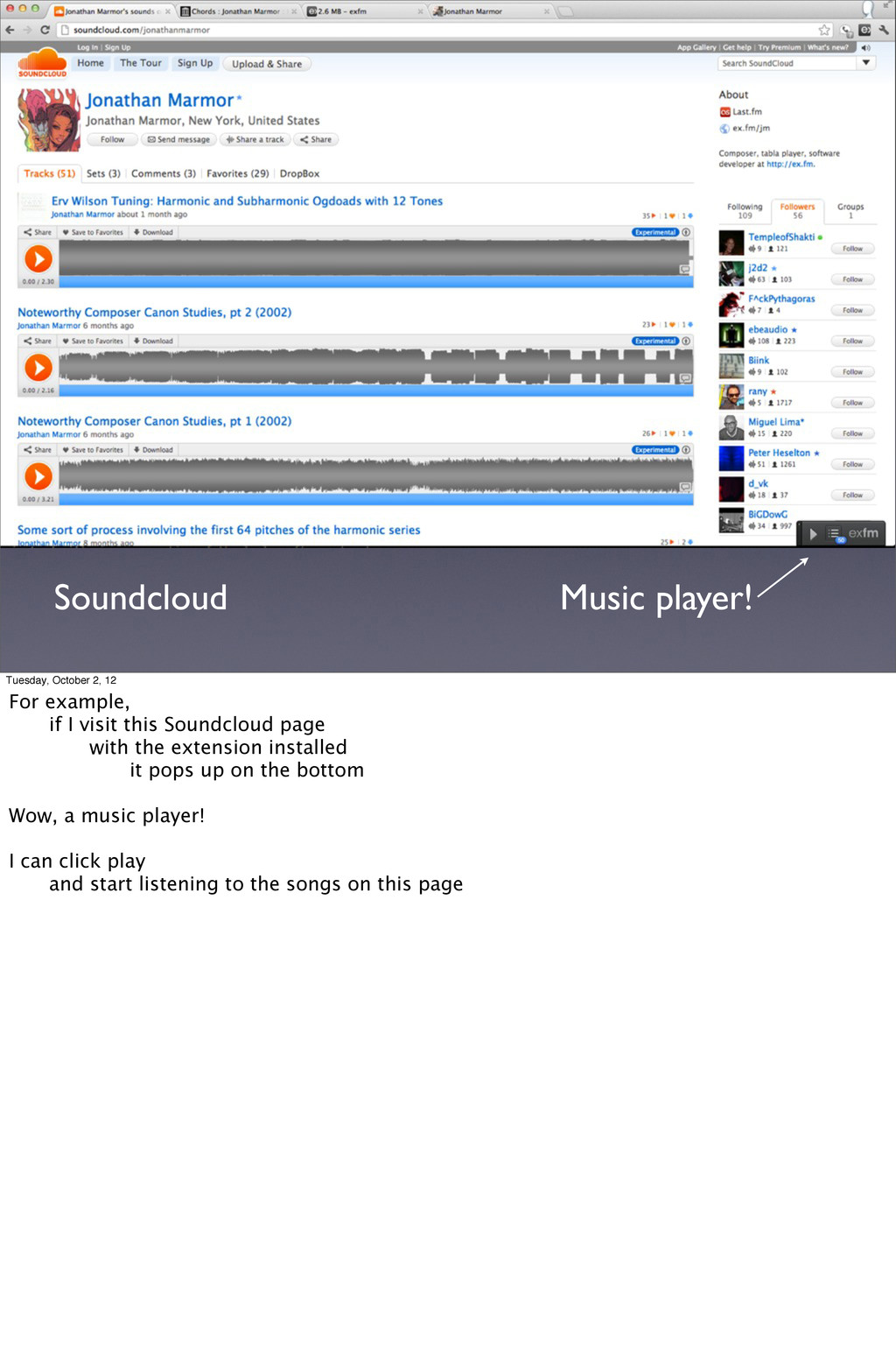
I visit this Soundcloud page with the extension installed it pops up on the bottom Wow, a music player! I can click play and start listening to the songs on this page
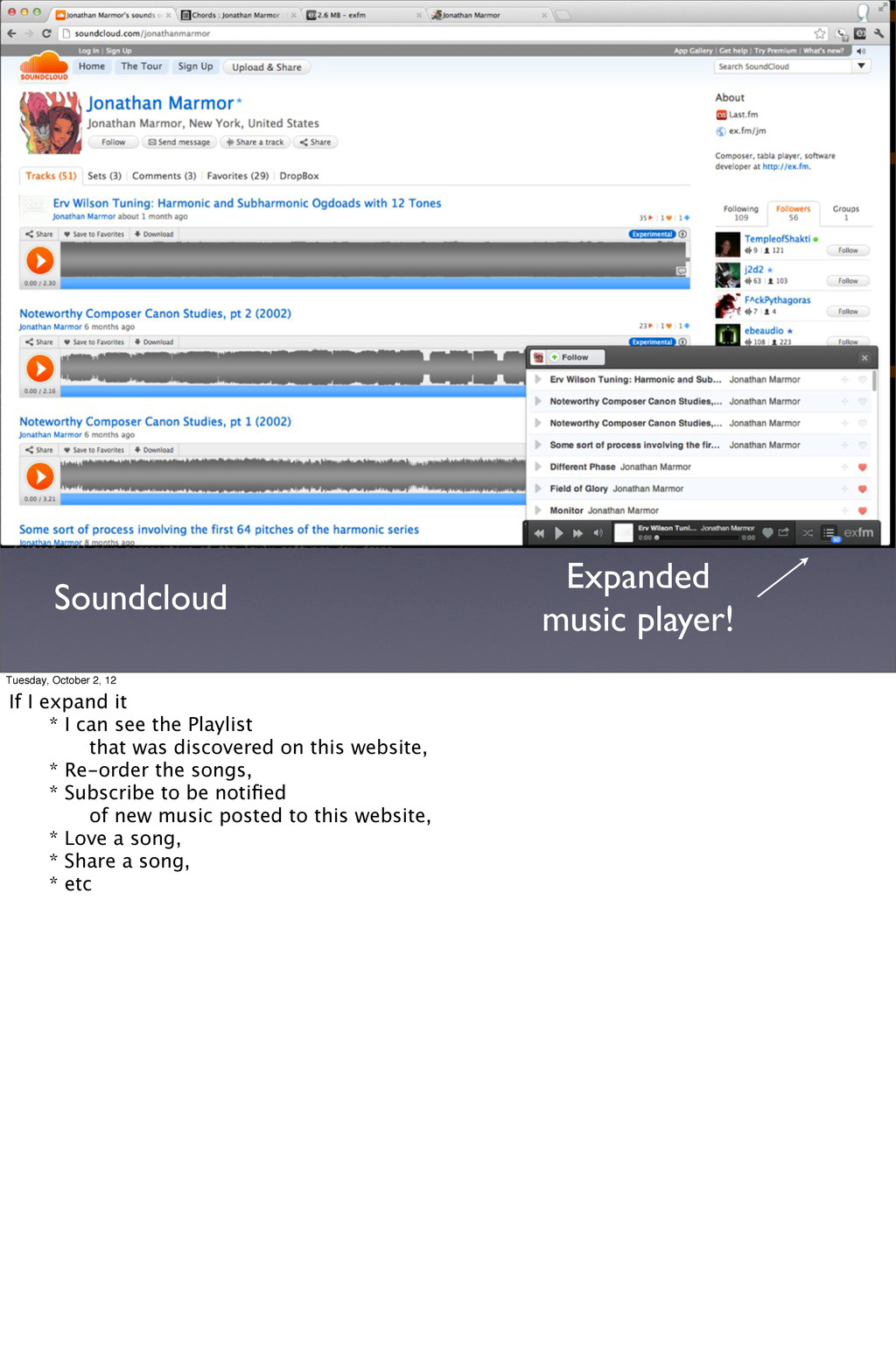
expand it * I can see the Playlist that was discovered on this website, * Re-order the songs, * Subscribe to be notified of new music posted to this website, * Love a song, * Share a song, * etc
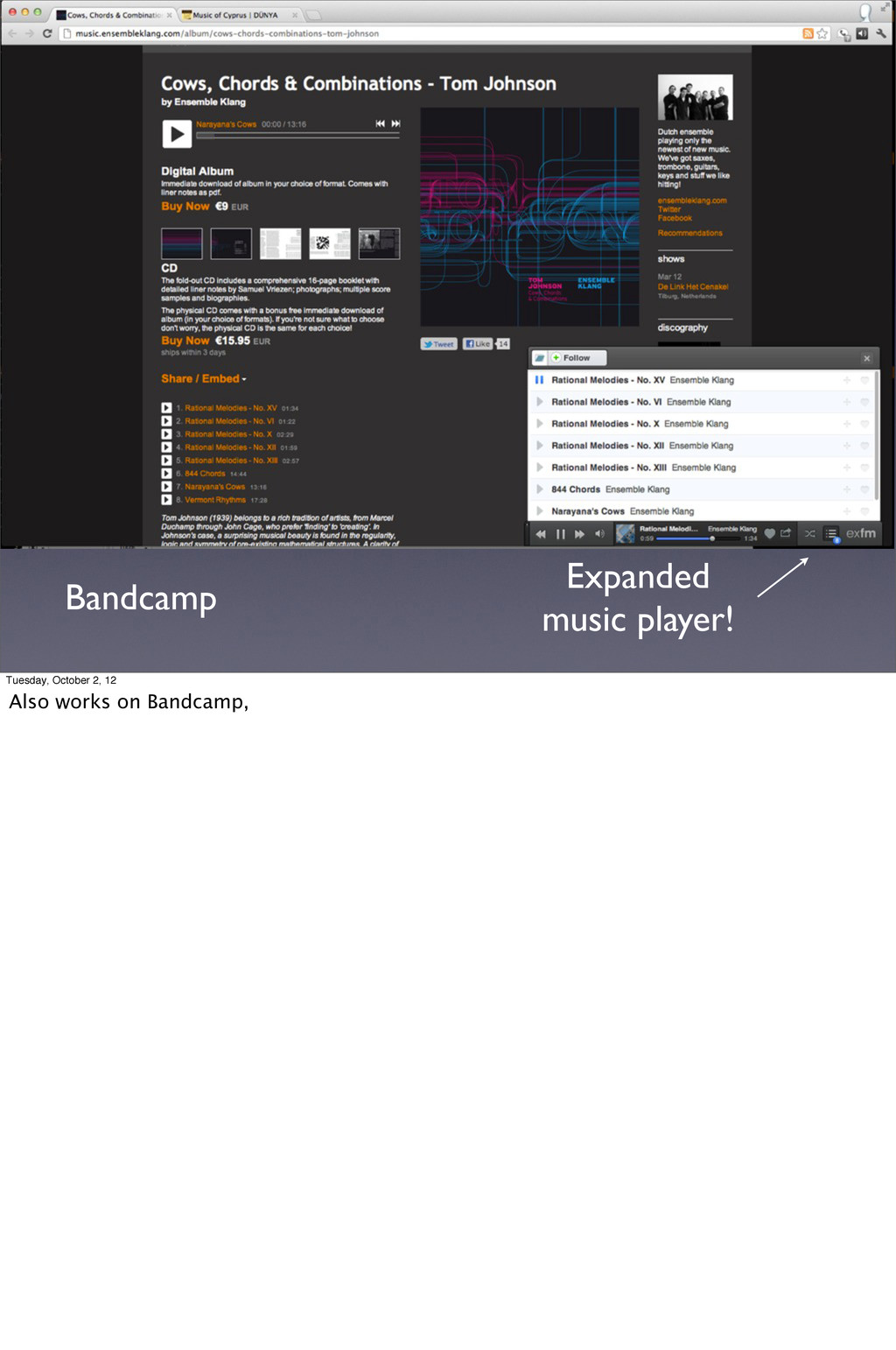
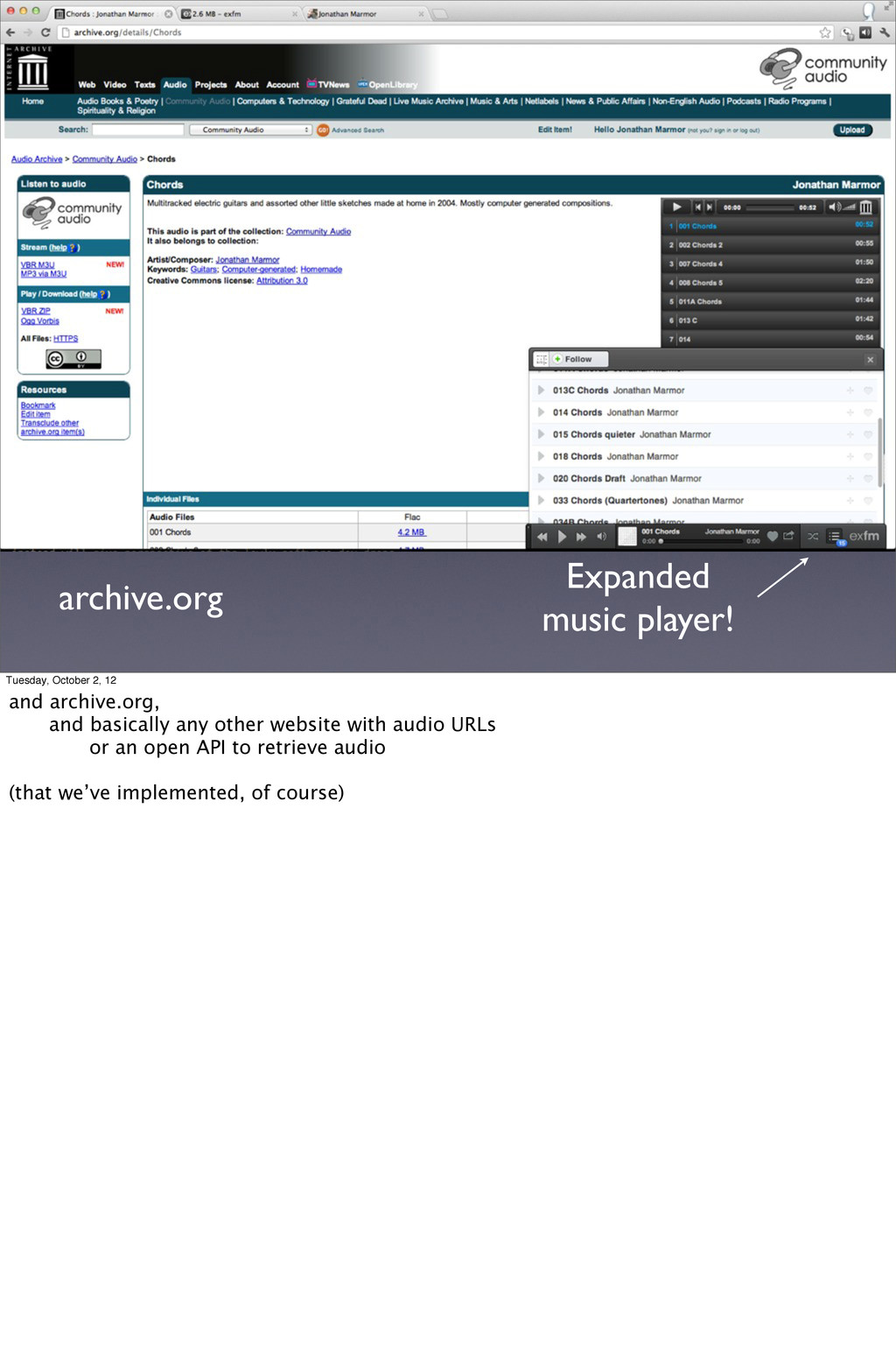
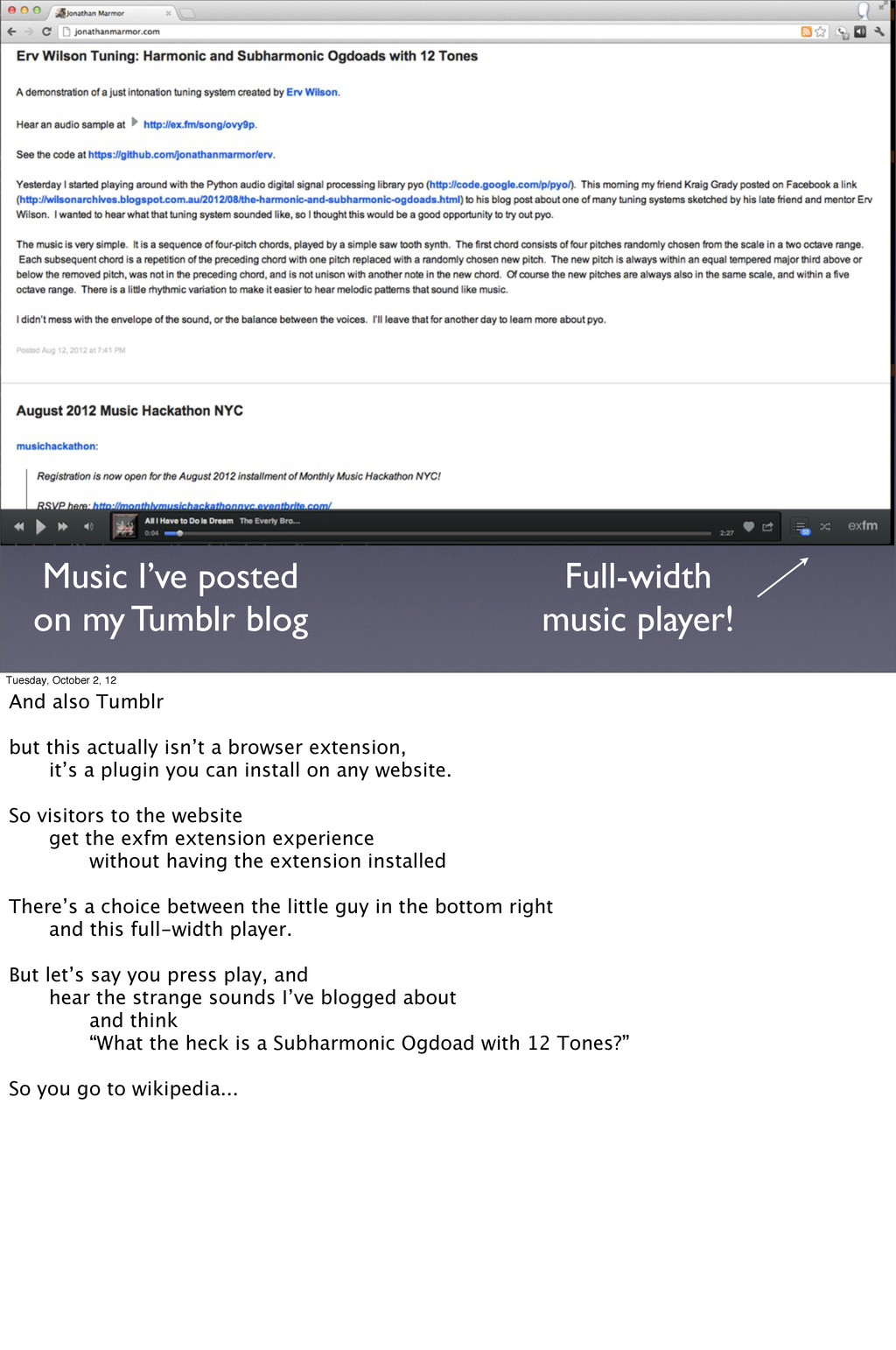
Tuesday, October 2, 12 And also Tumblr but this actually isn’t a browser extension, it’s a plugin you can install on any website. So visitors to the website get the exfm extension experience without having the extension installed There’s a choice between the little guy in the bottom right and this full-width player. But let’s say you press play, and hear the strange sounds I’ve blogged about and think “What the heck is a Subharmonic Ogdoad with 12 Tones?” So you go to wikipedia...
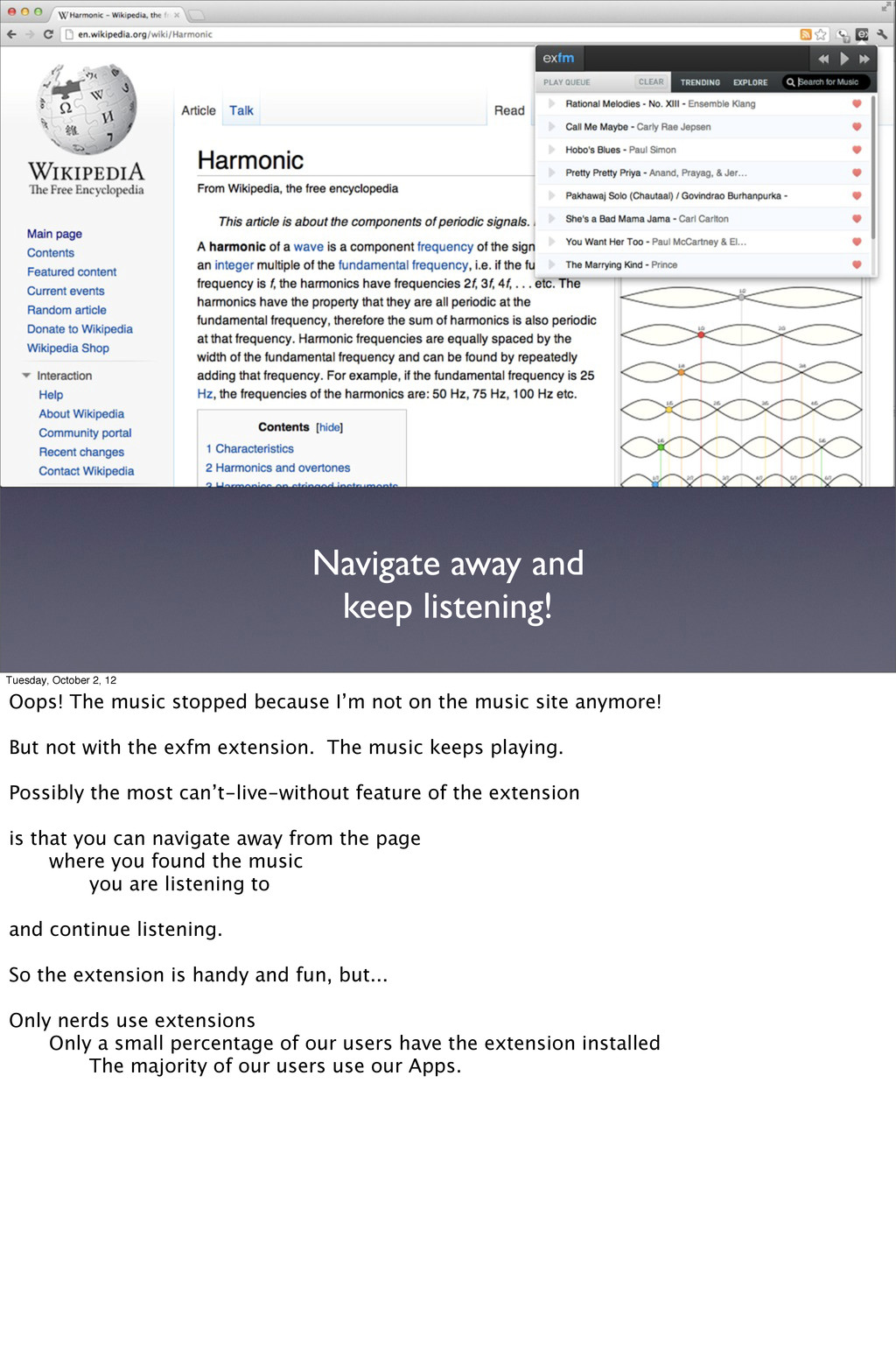
The music stopped because I’m not on the music site anymore! But not with the exfm extension. The music keeps playing. Possibly the most can’t-live-without feature of the extension is that you can navigate away from the page where you found the music you are listening to and continue listening. So the extension is handy and fun, but... Only nerds use extensions Only a small percentage of our users have the extension installed The majority of our users use our Apps.
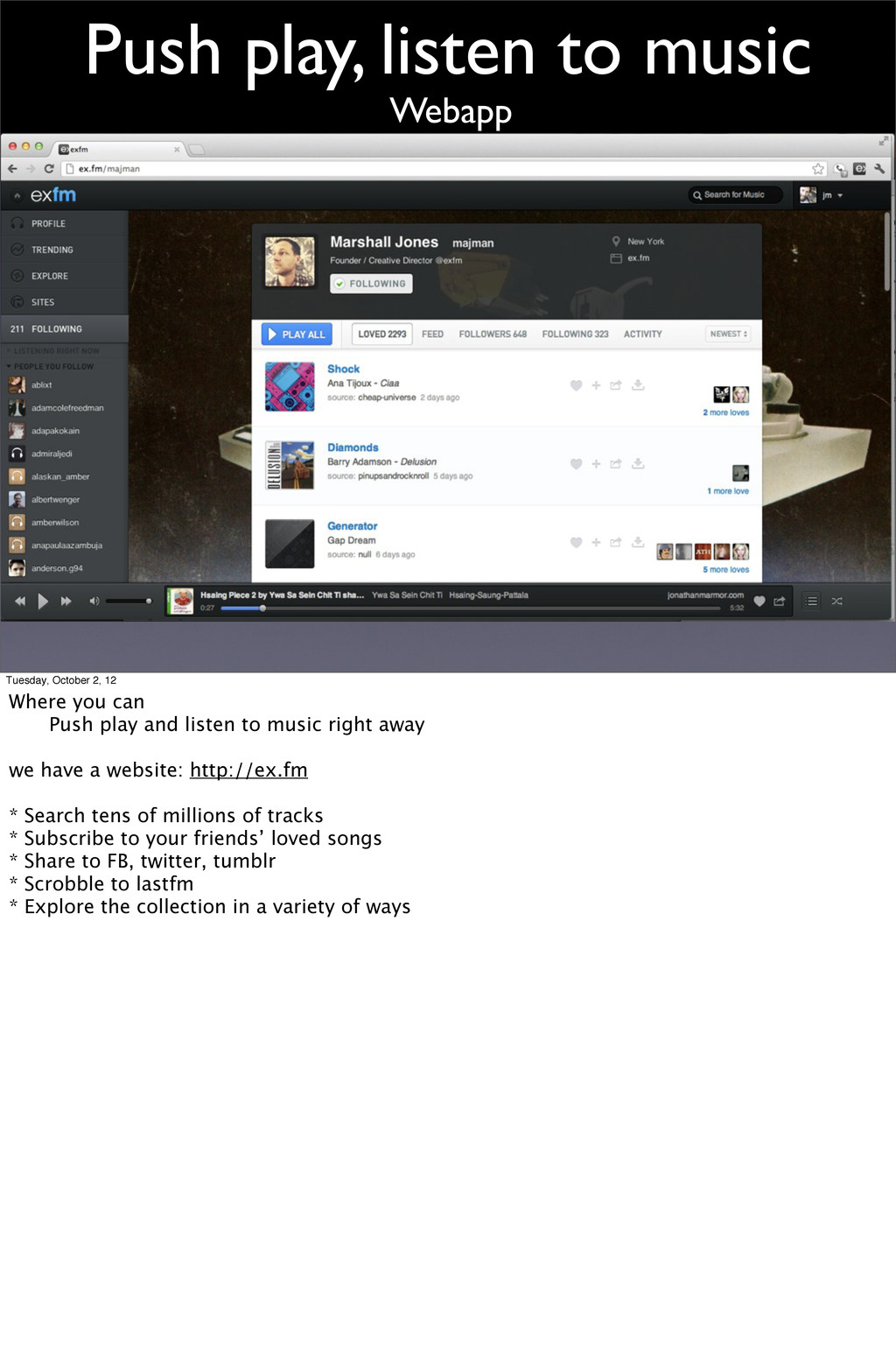
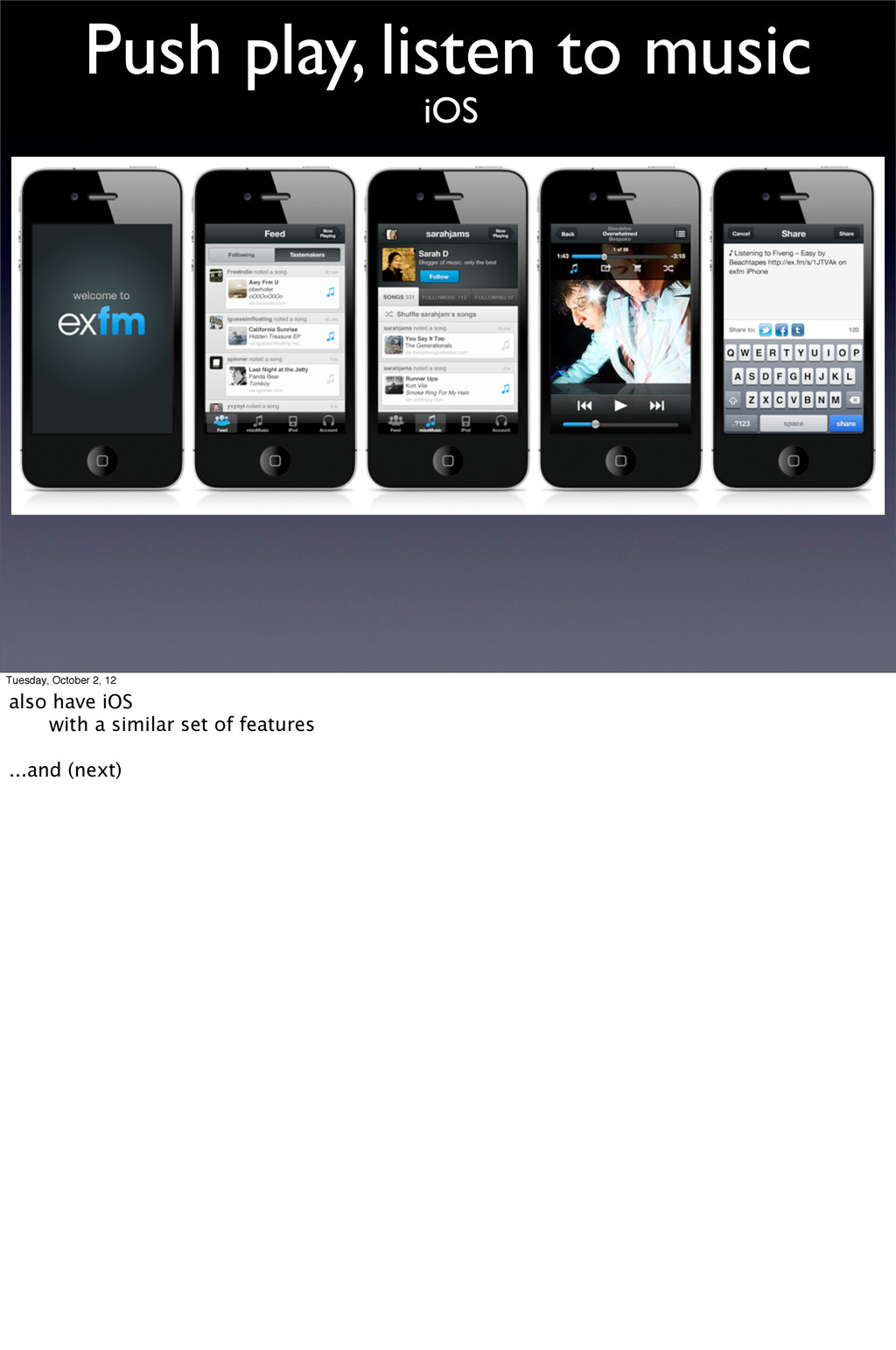
Where you can Push play and listen to music right away we have a website: http://ex.fm * Search tens of millions of tracks * Subscribe to your friends’ loved songs * Share to FB, twitter, tumblr * Scrobble to lastfm * Explore the collection in a variety of ways
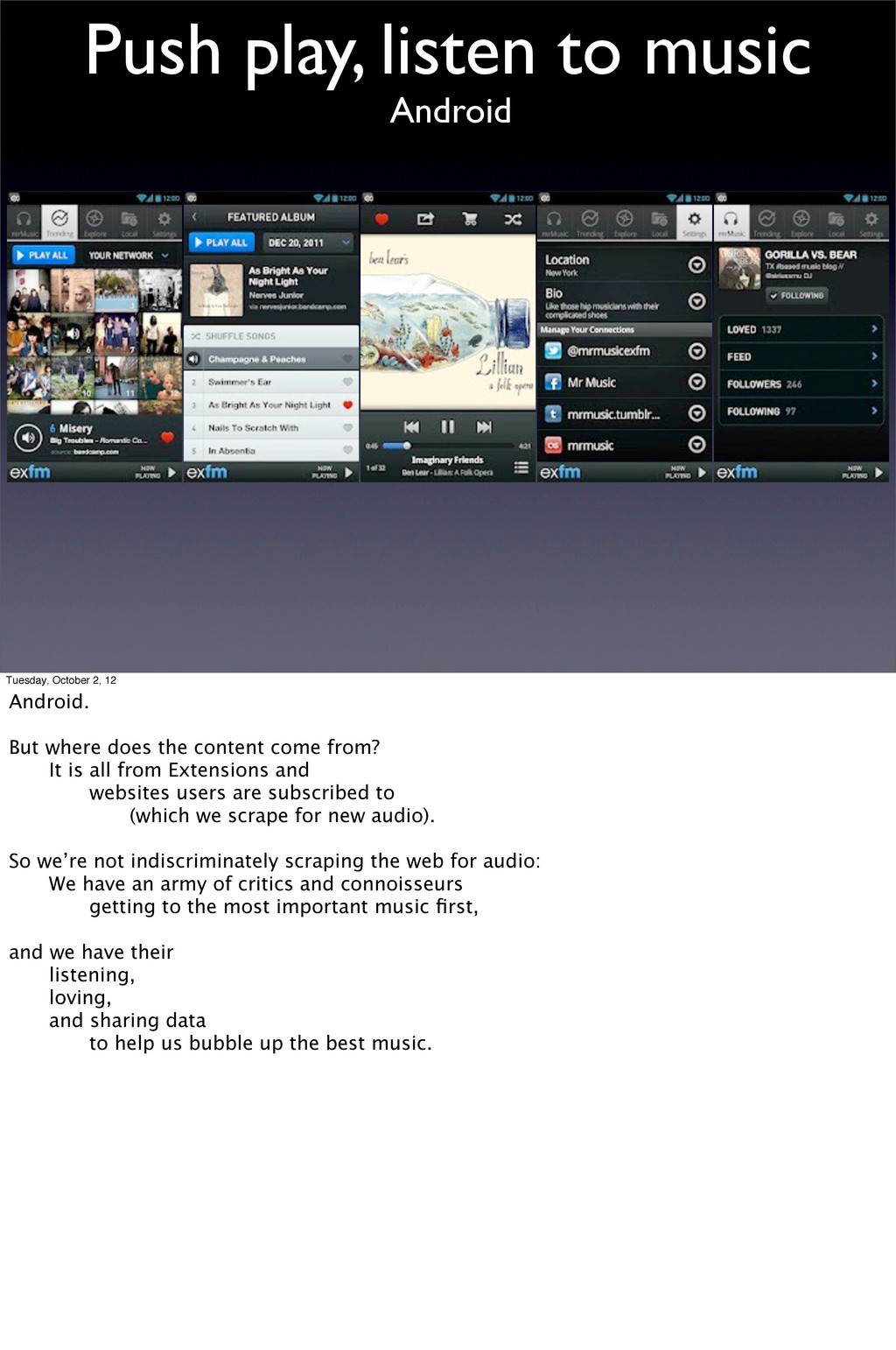
Android. But where does the content come from? It is all from Extensions and websites users are subscribed to (which we scrape for new audio). So we’re not indiscriminately scraping the web for audio: We have an army of critics and connoisseurs getting to the most important music first, and we have their listening, loving, and sharing data to help us bubble up the best music.
MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 3. Monthly Music Hackathon NYC Tuesday, October 2, 12 So that gives of quite a bit of data to take care of. So now, we’ll shift gears and talk about how we deal with the data.
MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 3. Monthly Music Hackathon NYC Tuesday, October 2, 12 What are the core technologies we use?
Ubuntu • Python • Flask web framework • Rabbit/Celery for background tasks • Supervisord for process control • Fabric for deployment and scripting • MongoDB Tuesday, October 2, 12 (read the slide) and of course, MongoDB. If you want to talk to me about any of the non-mongo items on this list please get in touch.
(think ORM, but for document databases) for working with MongoDB from Python. It uses a simple declarative API, similar to the Django ORM." Tuesday, October 2, 12 MongoEngine is a core part of how exfm uses Mongo. Most of our application’s shape and logic are hung from subclasses of MongoEngine’s classes. If you don’t know MongoEngine I highly encourage you to read the source code. It’s good stuff. It makes it easy to describe your data and define methods for creating, getting, and modifying it.
fully- managed search service in the cloud” Tuesday, October 2, 12 Amazon CloudSearch is also a core part of how we use Mongo. It mercifully replaced Solr for us. Allowed us to remove indexes of non-primary key fields. Many complex queries are done via CloudSearch. We dump data from Mongo, upload to S3, CloudSearch indexes. Queries to CloudSearch spit out primary keys of our Mongo collections so retrieval from Mongo is trivial. (from a query perspective)
MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 3. Monthly Music Hackathon NYC Tuesday, October 2, 12 So that’s our environment. Now to our models.
documents • Several collections that express relationships between Users, Songs, and Sites Collections Tuesday, October 2, 12 We have three primary collections (that I’ll be talking about today) 1. Songs 2. Users 3. Sites Then we also have numerous embedded documents that are literally a part of the documents of the three primary collections. And several collections that express relationships between songs users and sites
song.py, site.py • Base engine.py file with custom middleware building on top of MongoEngine File organization Tuesday, October 2, 12 We like to keep things simple: we have one file for each collection: song.py user.py site.py Then an engine.py file where we extend some MongoEngine classes and have some custom middleware. (next)
updating documents and querying collections • _ExfmQuerySet: convenience methods for handling query results, such as paging and updating the returned documents • cached_property: decorator to cache a value in the local object rather than grabbing from the DB • Logging setup Custom middleware Tuesday, October 2, 12 _ExfmDocument: Base Class for all our document classes such as Song, User, and Site has convenience methods for initializing, saving, reloading, and updating documents and querying collections _ExfmQuerySet: inherits mongoengine.queryset.QuerySet. Is what all our queries return. has convenience methods for handling query results, such as paging and updating the returned documents We also have other nice little things in engine.py, like logging setup, document method wrappers, etc.
Sites: MD5 hash of URL • Try to avoid too much variation in primary key size • Frequently use compound keys, eg: jonathan_facebook, and deal with parsing the string rather than using a complex query Primary Keys Tuesday, October 2, 12 Now a bit about our schema design. Choosing what your primary keys are is really important. Through trial and error, we’ve settled on IDs that don’t screw up performance and allow us to simplify queries. We try to avoid extreme variation in ID length within a collection. For example, if a URL is your ID, make a hash that has a fixed width. http://ex.fm is not the same size as some super long URL. Also, we use “compound keys” that have meaningful data in them. This allows us to skip some queries entirely: For example: I have a UserService object’s key: “jonathan_facebook.” I don’t need the UserService object, I just need the User with username “jonathan” So I just parse out the username from the UserService key and query the User collection with the username jonathan and skip querying the UserService collection. There are several other ways compound keys are helpful as well.
Users: username, email, MD5 hash of username • Sites: MD5 hash of URL • Always retrieve by MD5 hash Indexes Tuesday, October 2, 12 Choosing which fields are indexed is also critical. We used to have 5 to 10 indexes per collection. This created huge bloat in our memory usage. So we try to get away with only accessing objects by primary key.
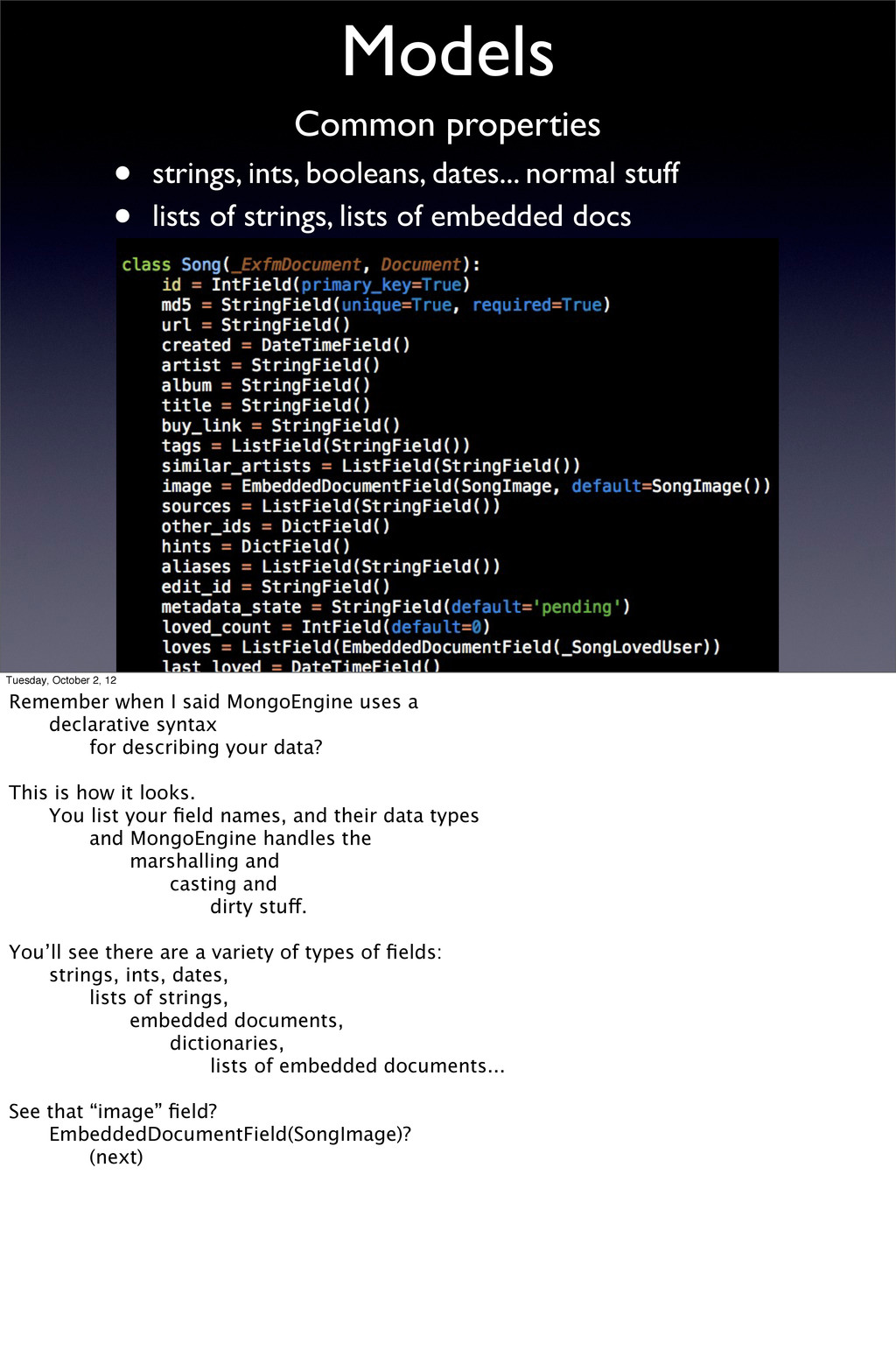
of strings, lists of embedded docs Common properties Tuesday, October 2, 12 Remember when I said MongoEngine uses a declarative syntax for describing your data? This is how it looks. You list your field names, and their data types and MongoEngine handles the marshalling and casting and dirty stuff. You’ll see there are a variety of types of fields: strings, ints, dates, lists of strings, embedded documents, dictionaries, lists of embedded documents... See that “image” field? EmbeddedDocumentField(SongImage)? (next)
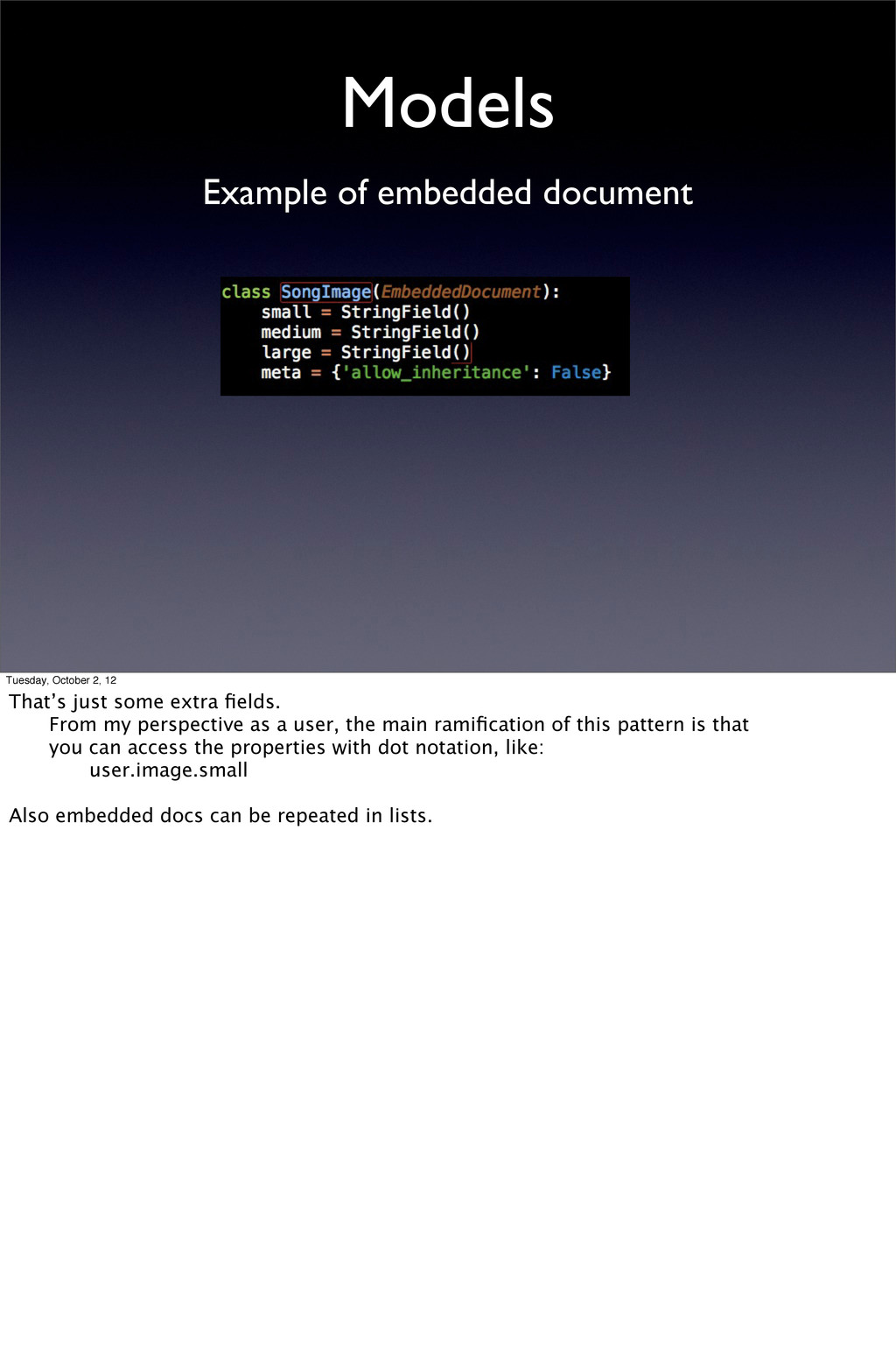
just some extra fields. From my perspective as a user, the main ramification of this pattern is that you can access the properties with dot notation, like: user.image.small Also embedded docs can be repeated in lists.
2, 12 Here’s an example of a collection that has documents that express relationships between docs in other collections. The basic gist is that the song is added to a list of songs this user has loved. But this isn’t done on a User object, it’s done in the _UserLoved collection, which has an object for each user, which is just a list of that user’s loved songs (plus some metadata and housekeeping stuff). And the list of songs this user has loved, are embedded documents: the _UserLovedSong object which contains the data pertinent to the event of this user loving this song. Then (not shown here) the mirror image of this process happens on the Song that is being loved: in other words, the user is added to a list of users who have loved the song.
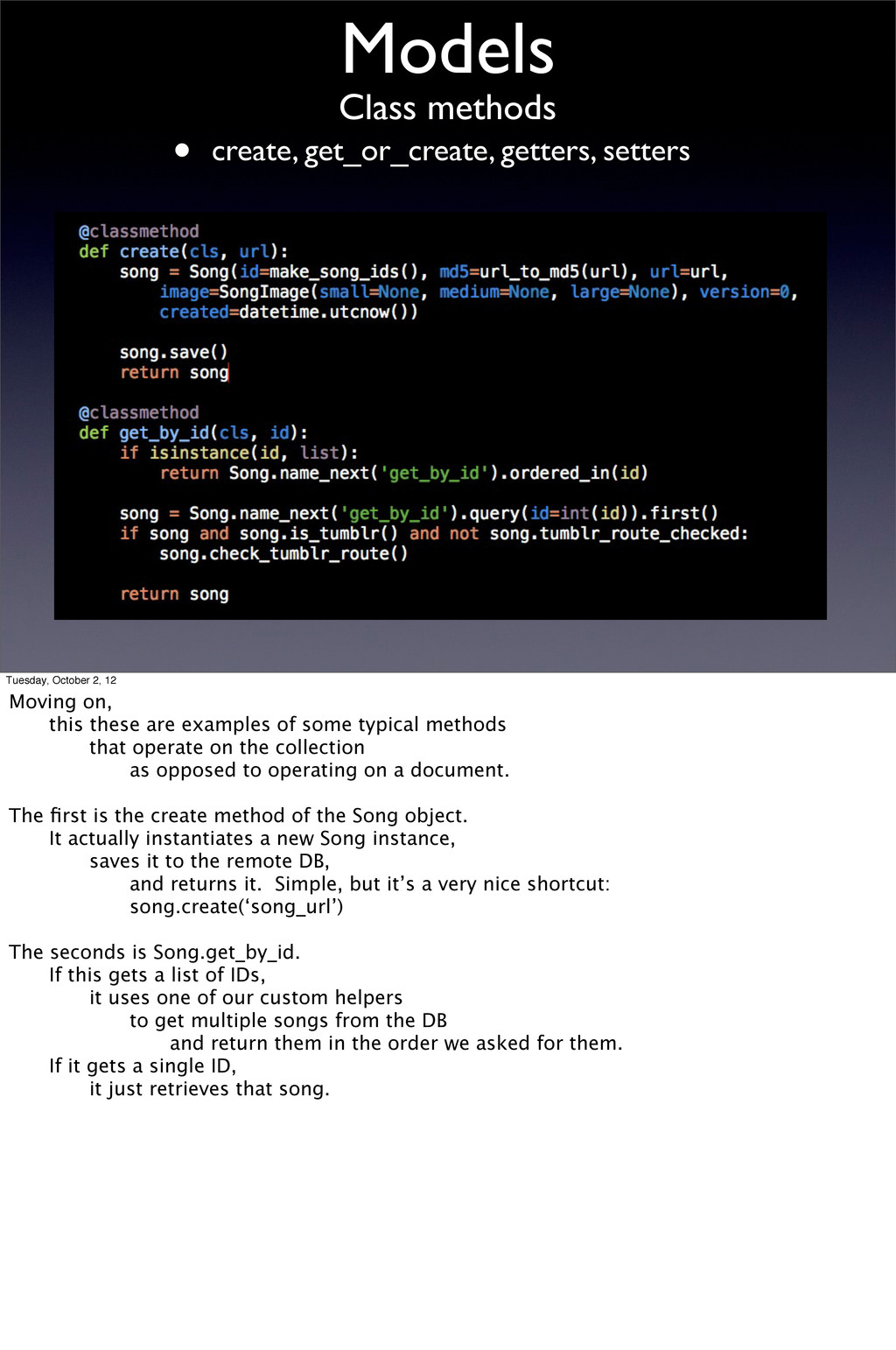
2, 12 Moving on, this these are examples of some typical methods that operate on the collection as opposed to operating on a document. The first is the create method of the Song object. It actually instantiates a new Song instance, saves it to the remote DB, and returns it. Simple, but it’s a very nice shortcut: song.create(‘song_url’) The seconds is Song.get_by_id. If this gets a list of IDs, it uses one of our custom helpers to get multiple songs from the DB and return them in the order we asked for them. If it gets a single ID, it just retrieves that song.
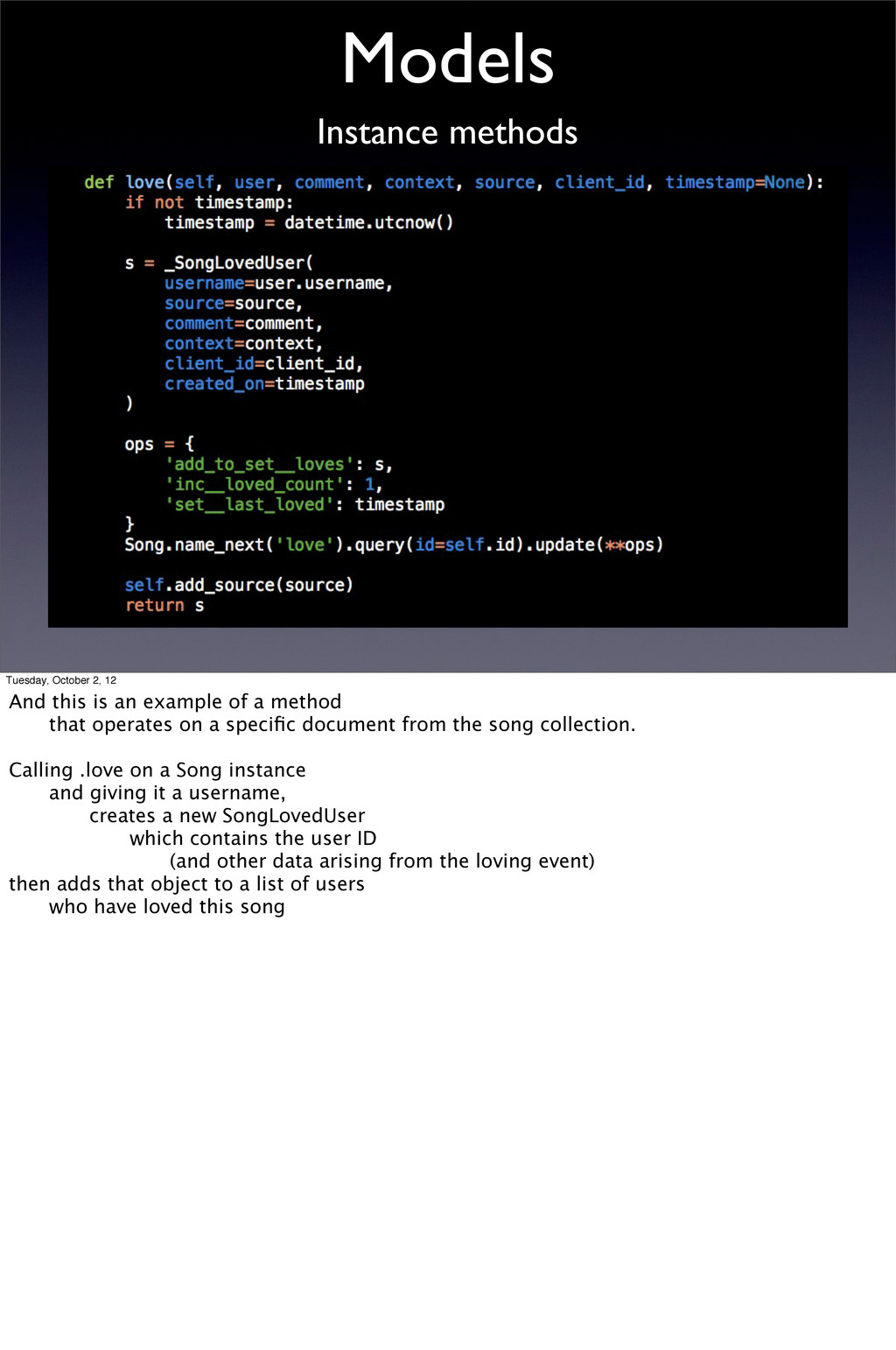
an example of a method that operates on a specific document from the song collection. Calling .love on a Song instance and giving it a username, creates a new SongLovedUser which contains the user ID (and other data arising from the loving event) then adds that object to a list of users who have loved this song
2, 12 I’m not going to get into these here. Our solution for dealing with complex queries: use CloudSearch. Bucketing is our current solution for dealing with objects in the same collection that have very different size. Send me an email if you want to know more.
MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 3. Monthly Music Hackathon NYC Tuesday, October 2, 12 So now briefly I’ll go over our server setup. We use AWS for everything except our laptops, mobile phones, tablets, Raspberry Pis, and we’ve been talking about building a CNC lathe.
• One Arbiter: t1.micro • One shared all-in-one m1.large for staging Tuesday, October 2, 12 We don’t do sharding clustering... we’re still on one gigantic machine. Our primary is the recently released m2.4xlarge, which is a giant honking beast. So is our secondary, which we fail over to should something happen to the primary. This has happened. Failover appears to work. :) There is also a tiny “arbiter” machine. Then we also have one machine for staging which we dump to periodically so it somewhat resembles production.
64-bit RAID0 EBS volume Recent Ubuntu Tuesday, October 2, 12 When these behemoth m2.4xlarges were recently released we immediately upgraded from m2.2xlarges. All that extra memory has definitely made our lives easier. Fewer alerts in the middle of the night. We have a somewhat elaborate Elastic Block Storage RAID0 configuration which I didn’t set up. Send me an email if you want to learn more about that.
How does exfm use MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 4. Monthly Music Hackathon NYC Tuesday, October 2, 12 Here are a few of the tools we use to keep our sanity.
to snapshot EBS volumes from secondary once per hour • 10gen’s backup-agent • also sync to beta for staging (ok, that’s not backup, but it’s a script that works similarly) Backup Tuesday, October 2, 12 Snapshots via AWS using Boto, which an amazing and comprehensive python client for all things AWS, in case you don’t know about it.
October 2, 12 MMS is 10gen’s monitoring system for Mongo, which uses munin. It’s really terrific and critical. AWS CloudWatch is Amazon’s monitoring system for all of their services. Is also terrific and critical for monitoring servers and network stuff. CloudWatch has improved in the past year or so, and has made the great third party monitoring service, ServerDensity, unnecessary for us.
collection stats, test queries, etc. • mongotop: per-collection read write times • iostat -x 2: Monitoring system I/O • tail -f logs/mongo.out.log Handy tools Tuesday, October 2, 12 mongo shell: interactive JS shell. Get collection stats, test queries, etc. mongotop: per-collection read write times iostat -x 2: Monitoring system I/O tail -f logs/mongo.out.log: maybe the most important one. Only slow queries show up here. It’s a great way to find queries that are slowing you down, so you can fix them. We use all of these (and others) multiple times a day.
MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 3. Monthly Music Hackathon NYC Tuesday, October 2, 12 Fortunately, we’re growing really fast. So we’re making some big changes to accommodate more users, more content, and more data.
scale when necessary... ...and it’s currently necessary.” Tuesday, October 2, 12 We currently run one monolithic application with tightly coupled parts. We’re in the process of splitting it into isolated HTTP services: User, Song, Site, Metadata processing, AlbumArt, LoveMachine, etc Our biggest headache has been that a few thousand Songs have thousands of loves, but tens of millions have zero or one love. The LoveMachine is a separate service designed to manage relationships between users and songs and will fix this problem.
Mongoose is like MongoEngine for NodeJS http://mongoosejs.com/ “elegant mongodb object modeling for node.js” Tuesday, October 2, 12 We’re switching from Python to Nodejs. We have a good reason, though: The core competency of our staff is Javascript. There are 9 of us at exfm 7 are developers 6 are most comfortable in JS. I’m the lone Python guy. :( But I’m getting a crash course, and that’s fun. Mongoose, the Mongo ORM for Node, is great so far. I’m just getting started using it.
MongoDB? 1. Environment overview 2. Models 3. Server architecture 4. Management and tools 5. Future plans 3. Monthly Music Hackathon NYC Tuesday, October 2, 12 And now for the funner part.
concert of hacks in Soho @musichackathon monthlymusichackathon.org Tuesday, October 2, 12 If you are a musician or have an interest in music, please come. FREE! The idea is to hack on music, and for the attendees (you) to decide what that means. It could mean working with music streaming company’s APIs, soldering together a new musical instrument, analyzing a library of music with DSP software, or rapidly writing and performing a new piece of music. It ends with a concert of the hacks created that day. Ensemble in residence this month: amazing virtuosic classical guitar/flute duo, that plays some insane music. Sponsored in part by 10gen and exfm.
![Jonathan Marmor Software Developer, exfm [email protected] at Tuesday, October 2,](https://files.speakerdeck.com/presentations/506b00d6797937000206e1a1/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Jonathan Marmor Software Developer, exfm [email protected] at Thank you! Tuesday,](https://files.speakerdeck.com/presentations/506b00d6797937000206e1a1/slide_42.jpg){kind=link}