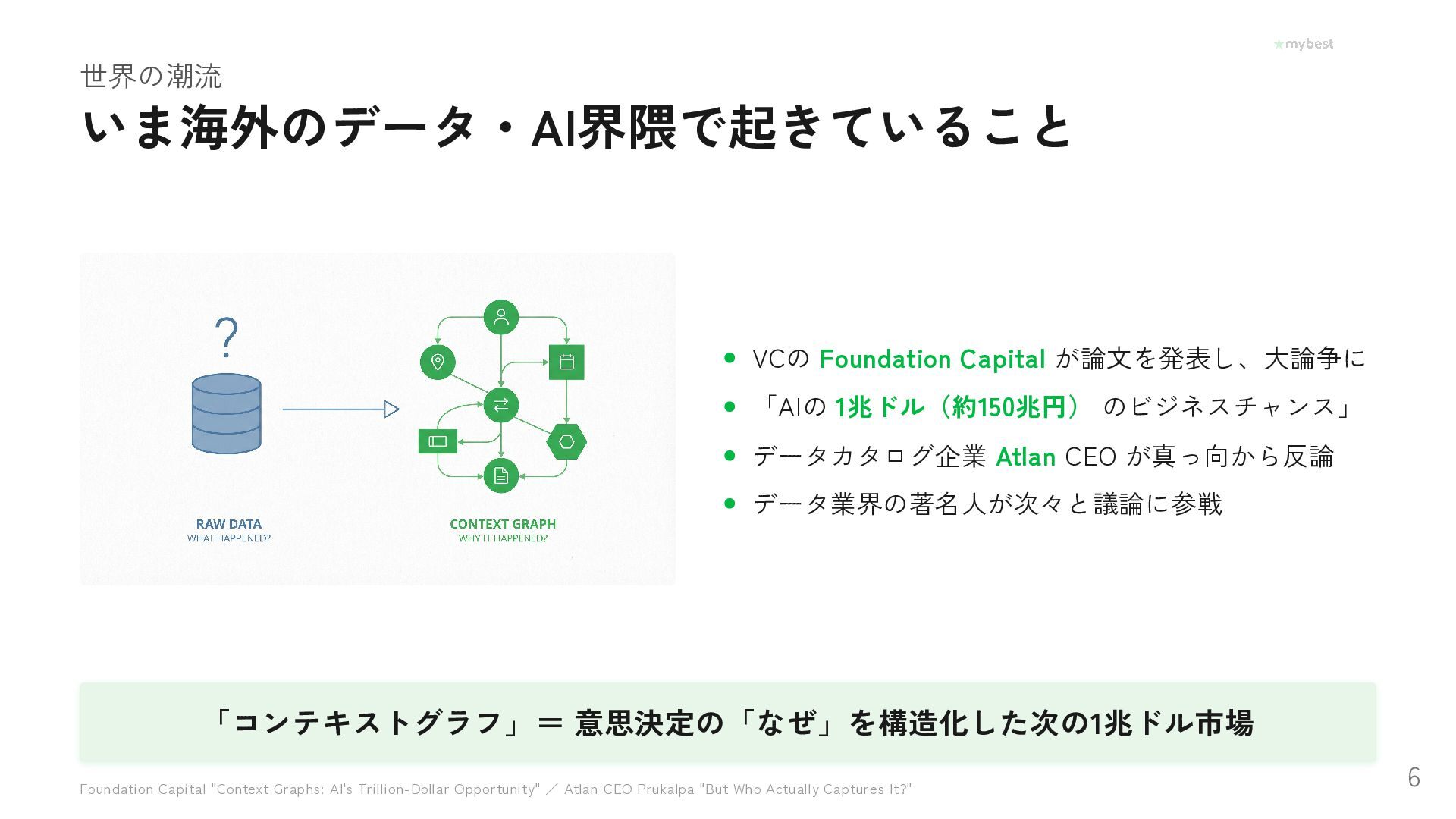
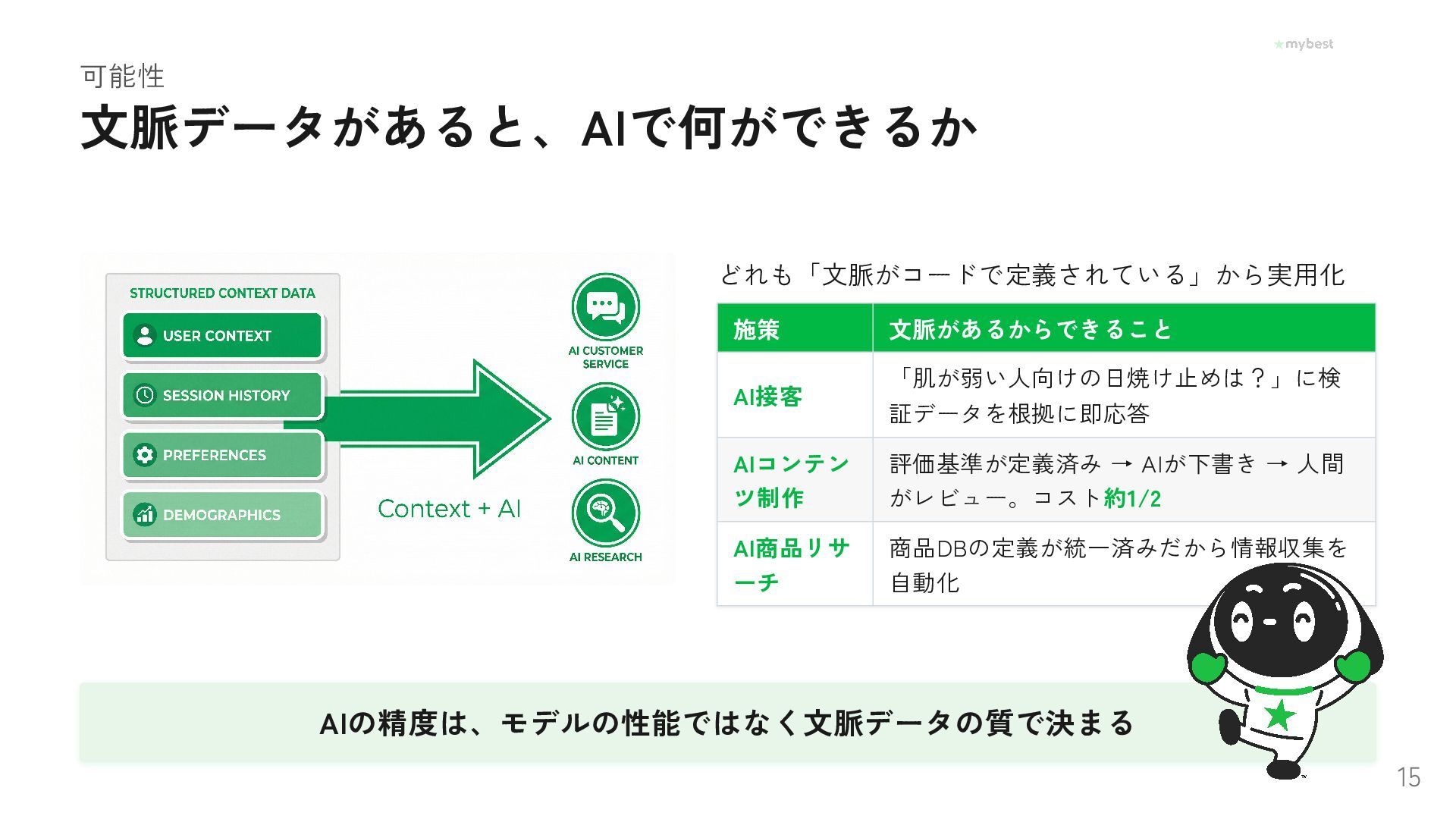
Foundation Capitalが提唱し話題の「コンテキストグラフ」。AIエージェントが賢く動くために必要なのは、データ量ではなく「なぜその選択をしたか」という文脈データだった──。月間3,000万UUの選択行動データを持つマイベストが、OBT・セマンティックレイヤー・ファクトDBで文脈を構造化し、AI-Readyな基盤を泥臭く作っている取り組みを紹介します。
Atlan CEO が真っ向から反論 データ業界の著名人が次々と議論に参戦 「コンテキストグラフ」= 意思決定の「なぜ」を構造化した次の1兆ドル市場 Foundation Capital "Context Graphs: AI's Trillion-Dollar Opportunity" / Atlan CEO Prukalpa "But Who Actually Captures It?" 6
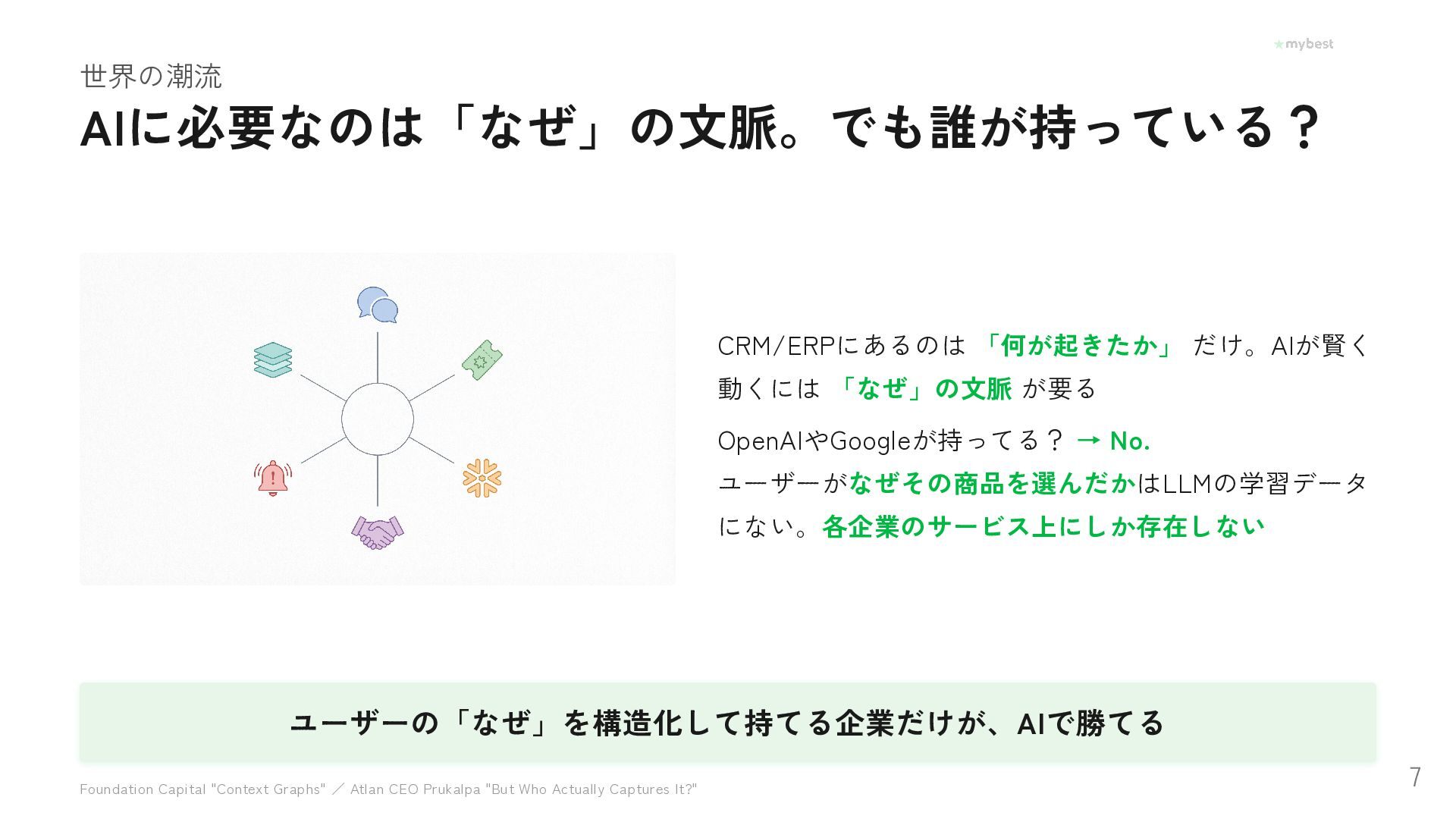
No. ユーザーがなぜその商品を選んだかはLLMの学習データ にない。各企業のサービス上にしか存在しない ユーザーの「なぜ」を構造化して持てる企業だけが、AIで勝てる Foundation Capital "Context Graphs" / Atlan CEO Prukalpa "But Who Actually Captures It?" 7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}