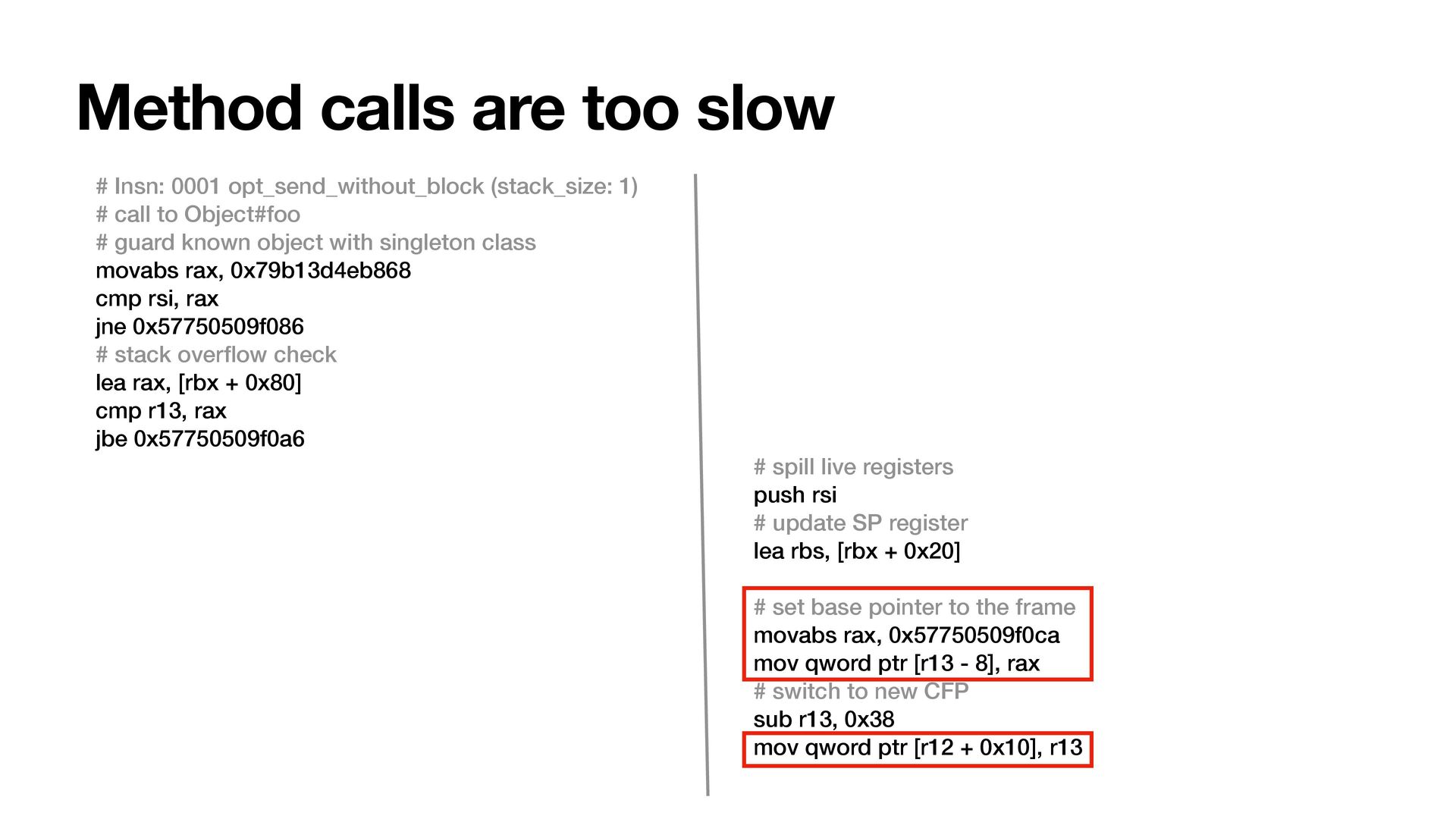
1) # call to Object#foo # guard known object with singleton class movabs rax, 0x79b13d4eb868 cmp rsi, rax jne 0x57750509f086 # stack over fl ow check lea rax, [rbx + 0x80] cmp r13, rax jbe 0x57750509f0a6 # store caller sp lea rax, [rbx] mov qword ptr [r13 + 8], rax # save PC to CFP movabs rax, 0x57750fc997e8 mov qword ptr [r13], rax lea rax, [rbx + 0x20] # push cme, specval, frame type movabs rcx, 0x79b123883e18 mov qword ptr [rax - 0x18], rcx mov qword ptr [rax - 0x10], 0 mov qword ptr [rax - 8], 0x11110003 # push callee control frame mov qword ptr [r13 - 0x30], rax movabs rcx, 0x79b123883ee0 mov qword ptr [r13 - 0x28], rcx mov qword ptr [r13 - 0x20], rsi mov qword ptr [r13 - 0x10], 0 mov rcx, rax sub rcx, 8 mov qword ptr [r13 - 0x18], rcx # local maps: [None, None, None, None, None] # spill_regs: [Some(Stack(0)), None, None, None, None] mov qword ptr [rbx], rsi # update SP register mov rbx, rax # clear local variable types # update cfp->jit_return movabs rax, 0x57750509f0ca mov qword ptr [r13 - 8], rax # switch to new CFP sub r13, 0x38 mov qword ptr [r12 + 0x10], r13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
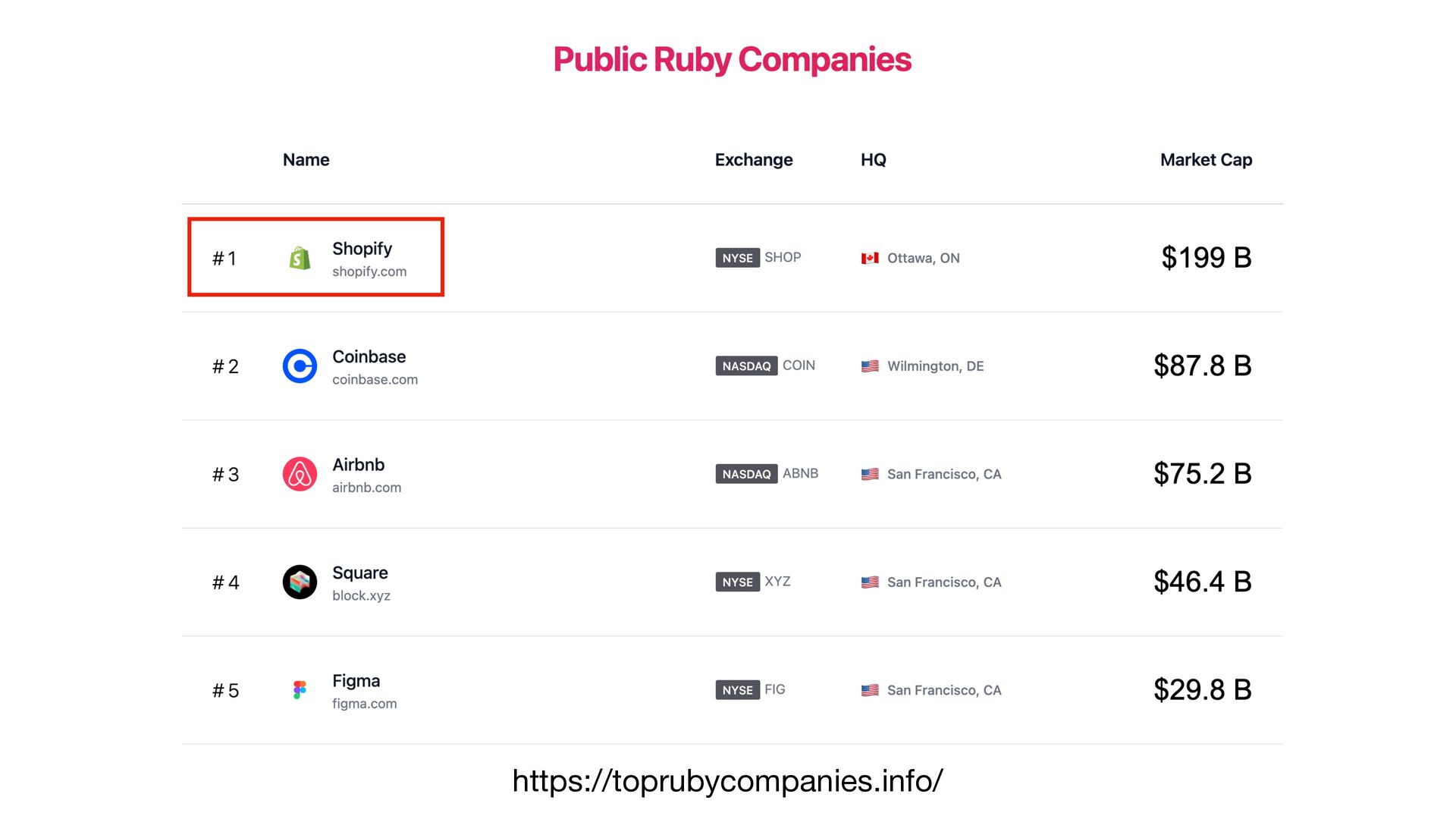{kind=link}
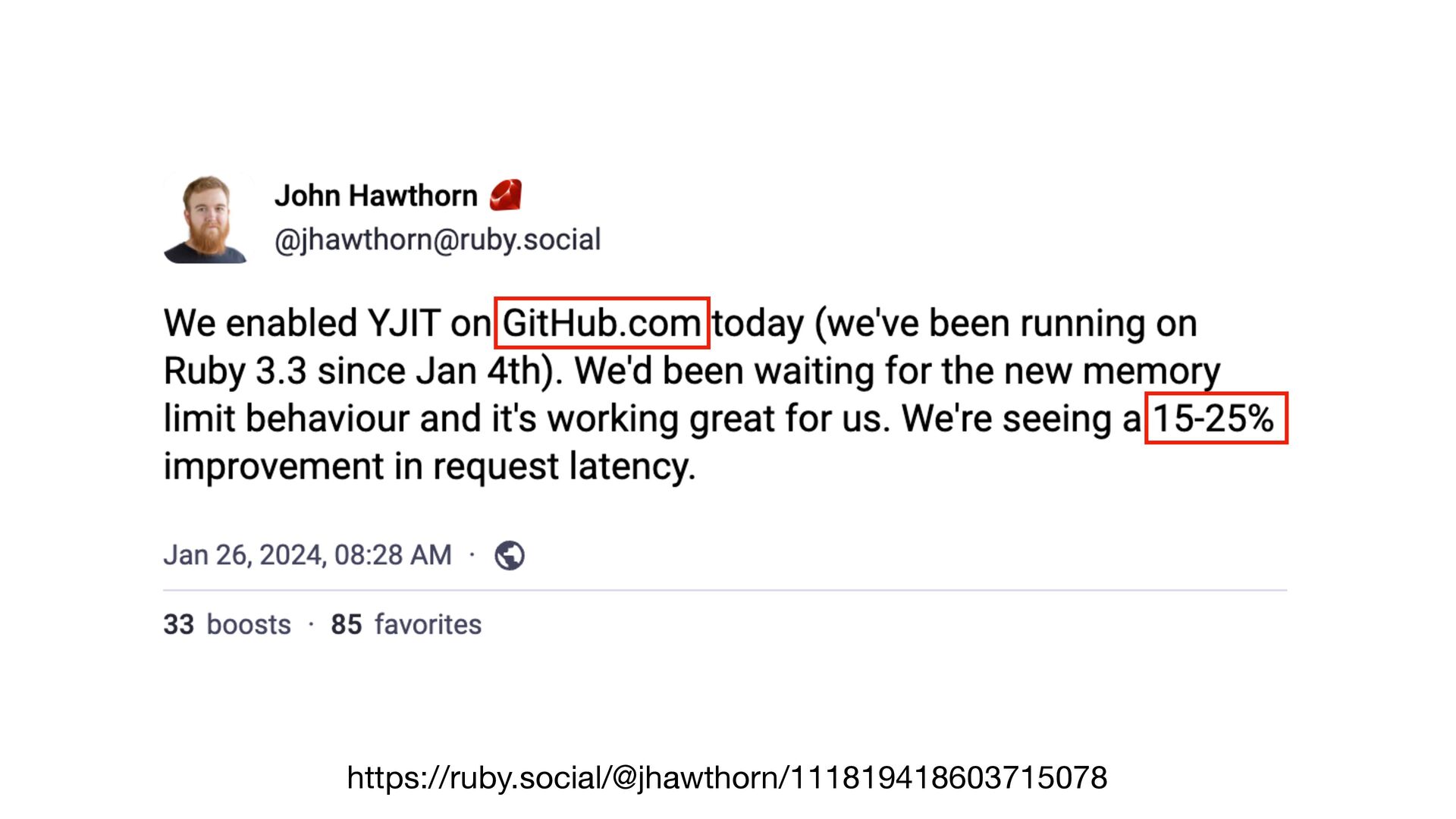{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
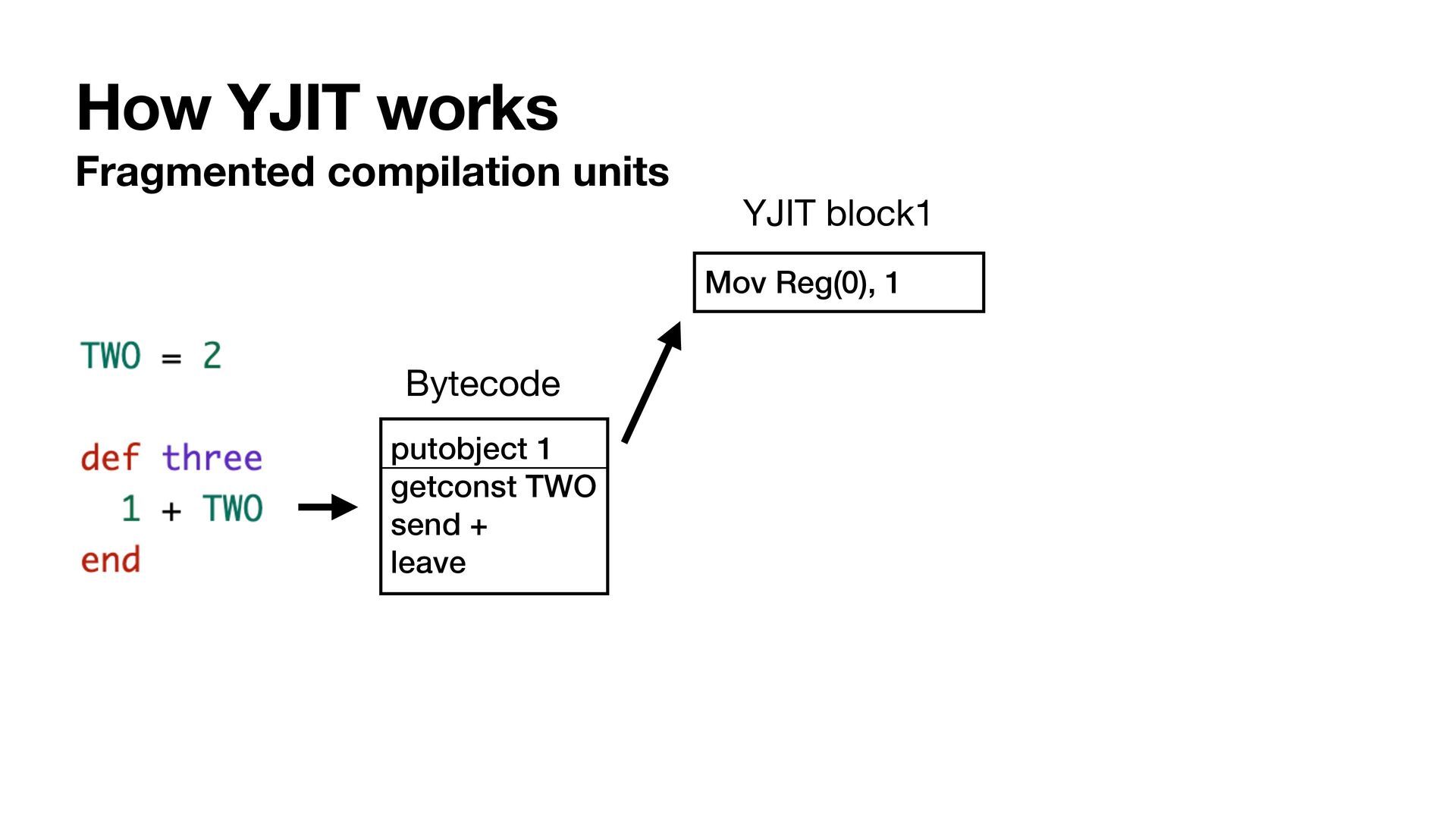{kind=link}
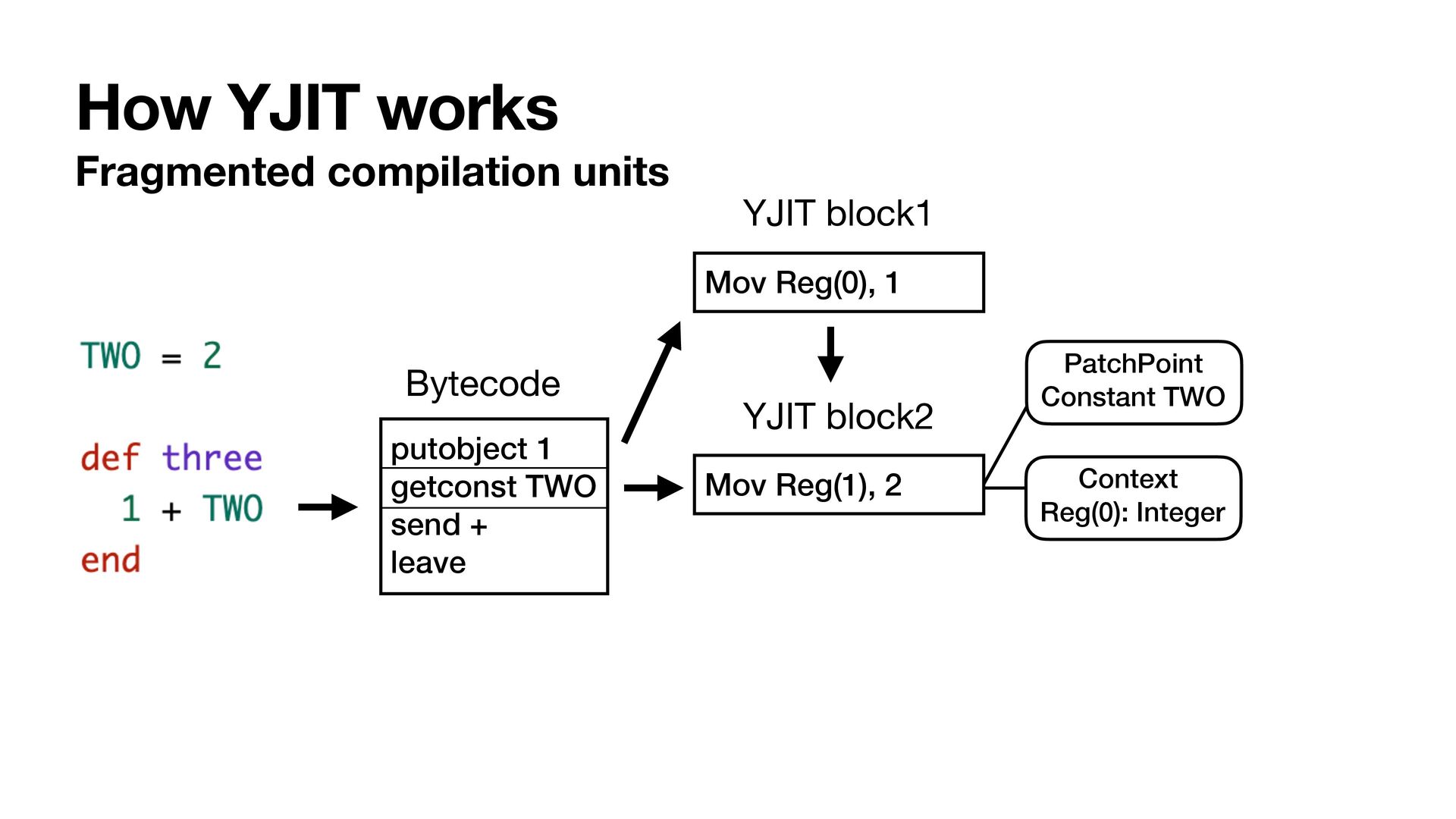{kind=link}
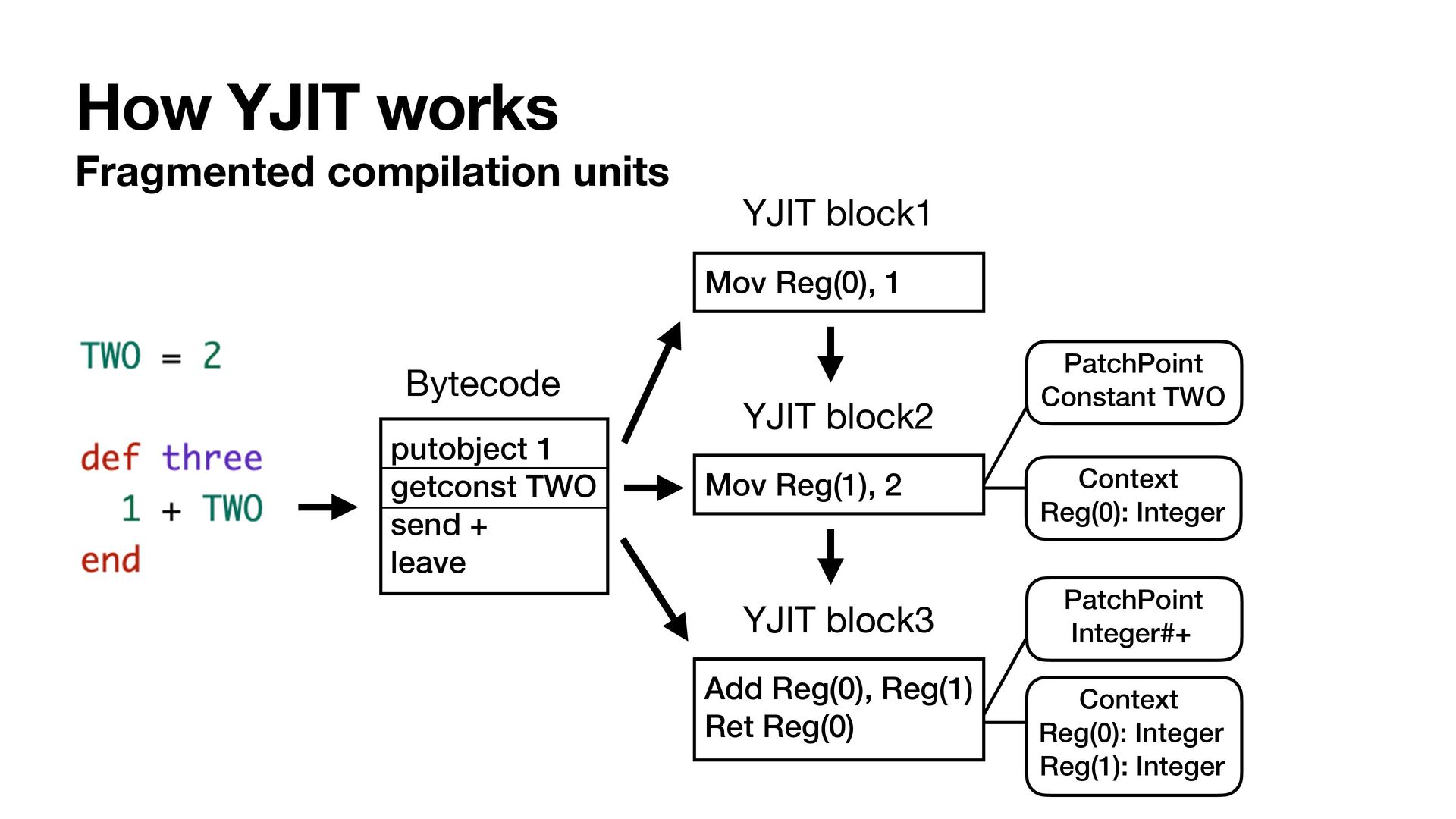{kind=link}
{kind=link}
{kind=link}
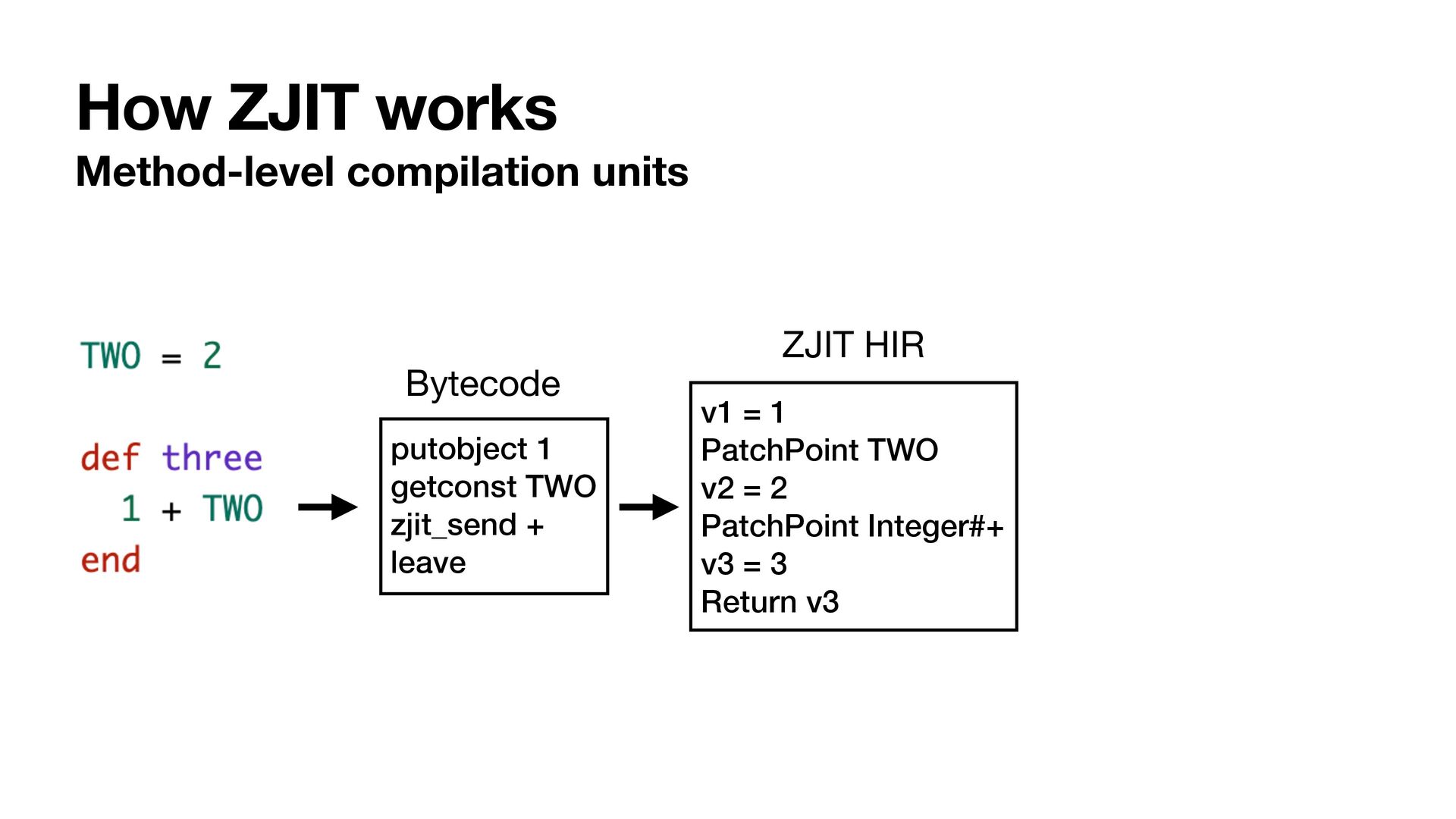{kind=link}
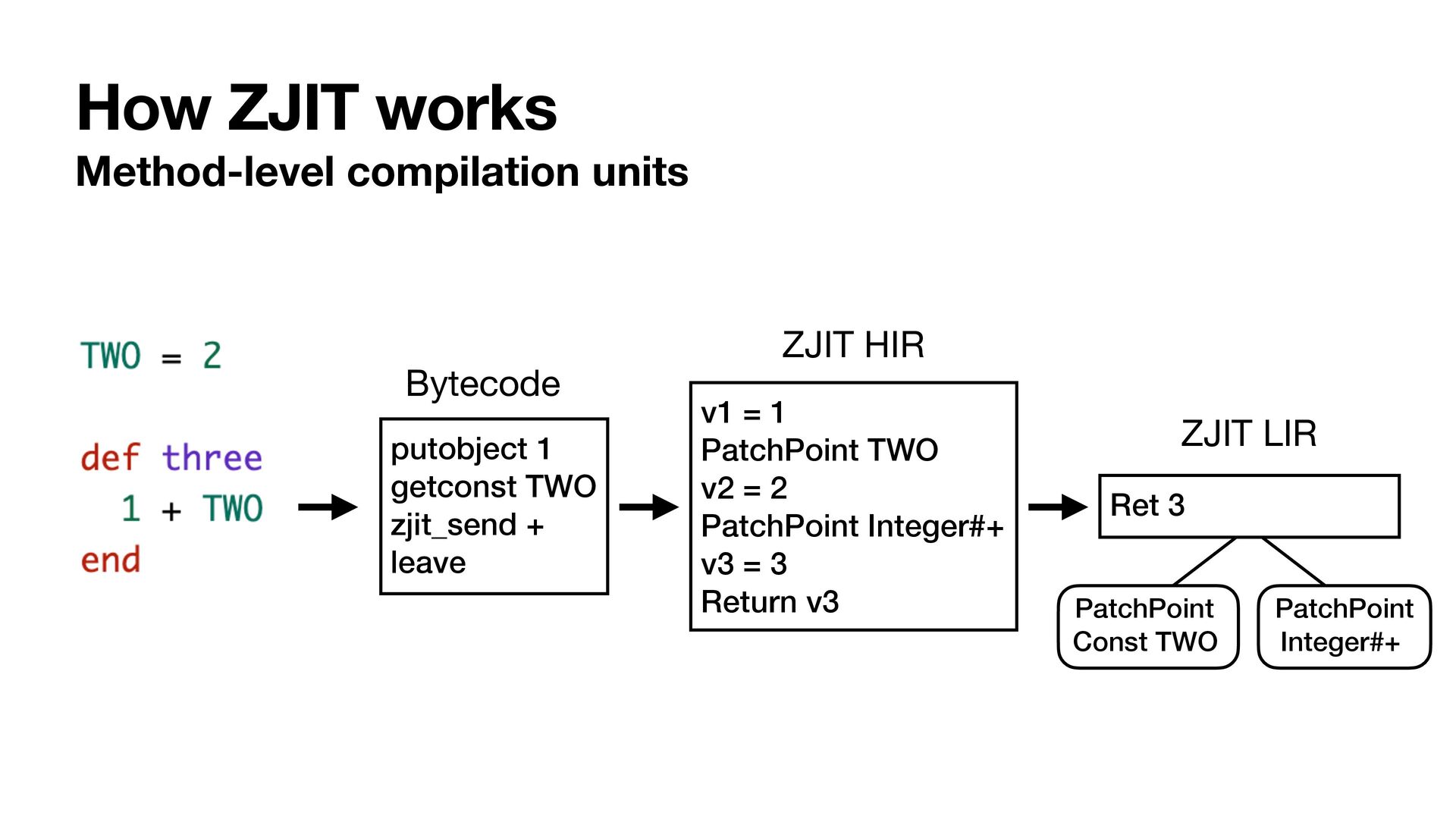{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}