LLMs are waaaaaay larger than most models Back then it was an issue Ops don’t understand ML infra Path of least resistance: Function as a Service (FaaS) FaaS (then) have limited storage capacity (around 500 MB)
PyTorch team at Facebook in 2017 Was accepted as graduate project in Linux Foundation AI in 2019 Interoperability between frameworks* *https://onnx.ai/supported-tools.html
(Small Language Model)? SLM should be able to run on edge and embedded devices Typically less than 10 billion parameters ONNX serialization does not reduce parameter size Quantization can reduce parameter size GGUF is better for LLM 👀 LLM edition
ONNX Results in faster inference time Significant speed boost from scikit-learn/pytorch/etc to ONNX Using a compiled language (ex. Rust) can speeds it up further
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
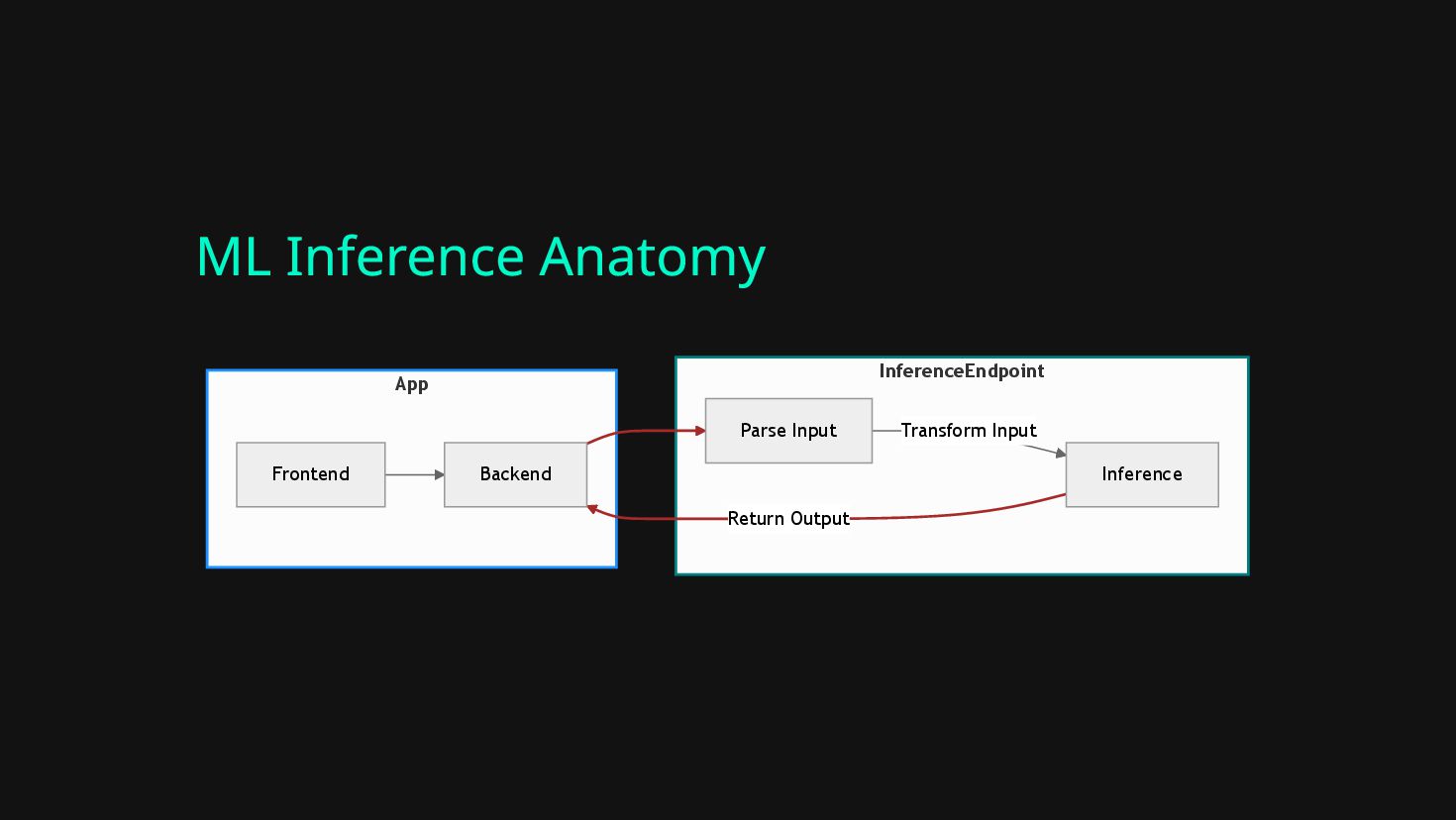{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
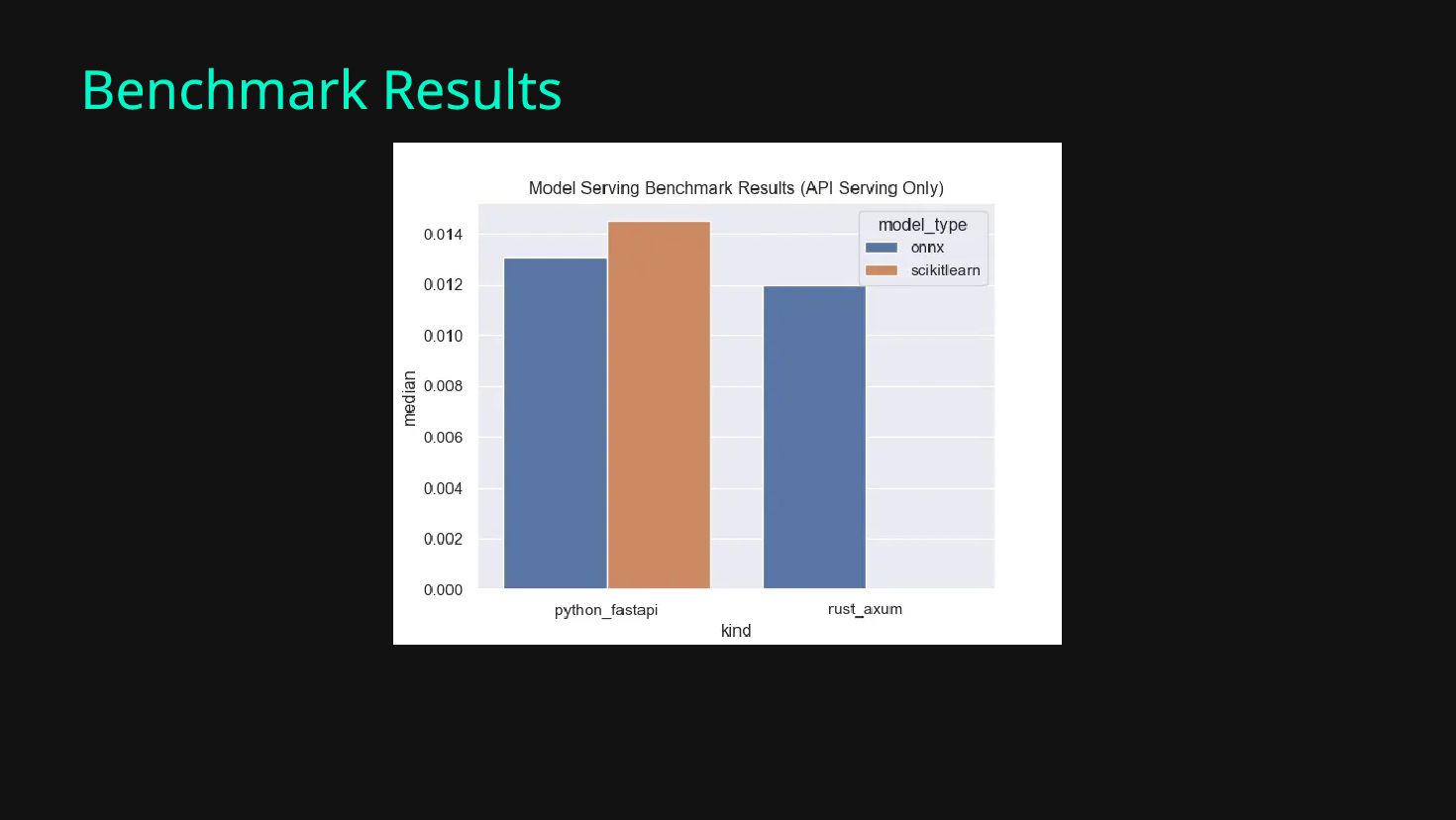{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}