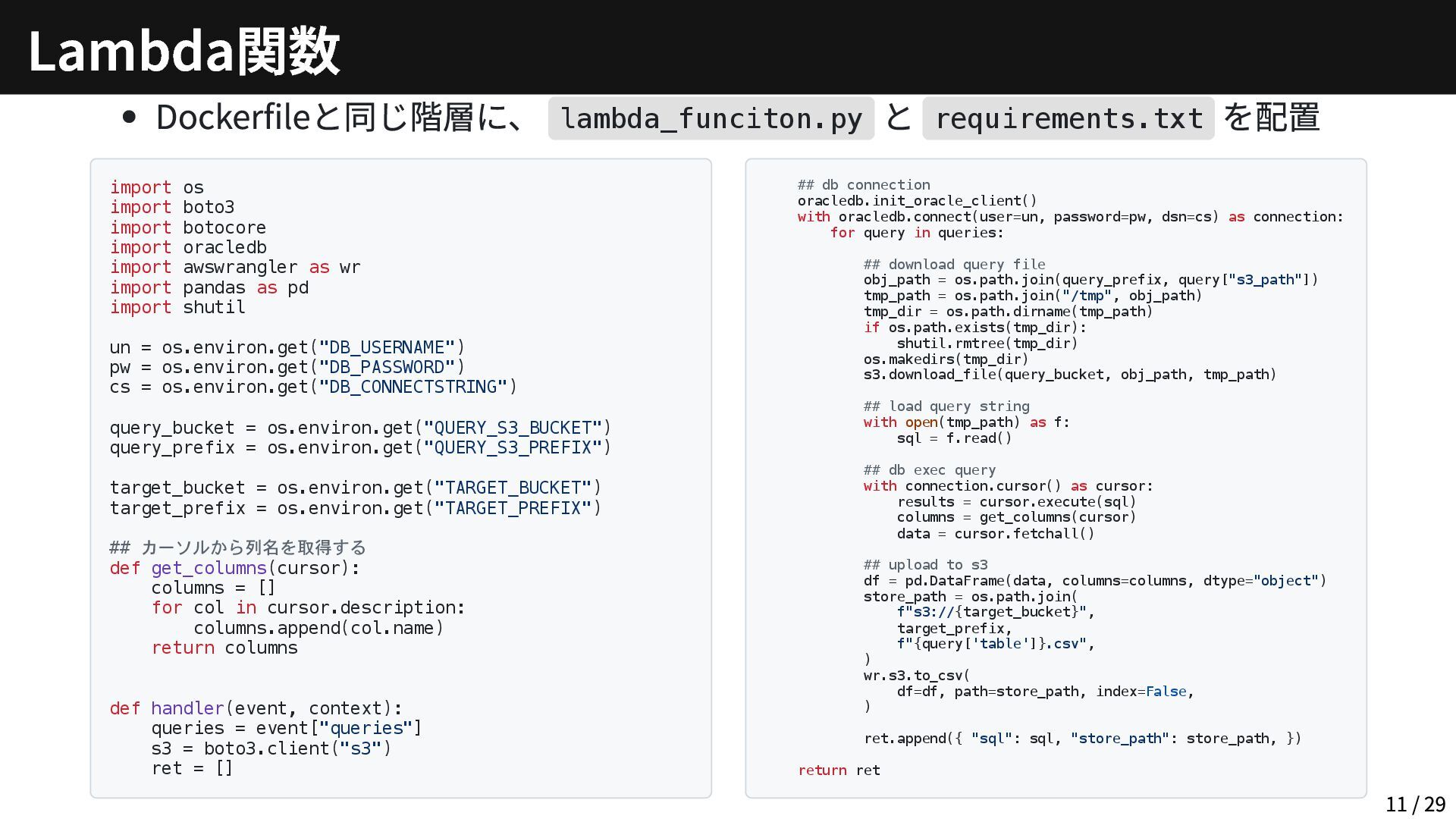
botocore import oracledb import awswrangler as wr import pandas as pd import shutil un = os.environ.get("DB_USERNAME") pw = os.environ.get("DB_PASSWORD") cs = os.environ.get("DB_CONNECTSTRING") query_bucket = os.environ.get("QUERY_S3_BUCKET") query_prefix = os.environ.get("QUERY_S3_PREFIX") target_bucket = os.environ.get("TARGET_BUCKET") target_prefix = os.environ.get("TARGET_PREFIX") ## カーソルから列名を取得する def get_columns(cursor): columns = [] for col in cursor.description: columns.append(col.name) return columns def handler(event, context): queries = event["queries"] s3 = boto3.client("s3") ret = [] ## db connection oracledb.init_oracle_client() with oracledb.connect(user=un, password=pw, dsn=cs) as connection: for query in queries: ## download query file obj_path = os.path.join(query_prefix, query["s3_path"]) tmp_path = os.path.join("/tmp", obj_path) tmp_dir = os.path.dirname(tmp_path) if os.path.exists(tmp_dir): shutil.rmtree(tmp_dir) os.makedirs(tmp_dir) s3.download_file(query_bucket, obj_path, tmp_path) ## load query string with open(tmp_path) as f: sql = f.read() ## db exec query with connection.cursor() as cursor: results = cursor.execute(sql) columns = get_columns(cursor) data = cursor.fetchall() ## upload to s3 df = pd.DataFrame(data, columns=columns, dtype="object") store_path = os.path.join( f"s3://{target_bucket}", target_prefix, f"{query['table']}.csv", ) wr.s3.to_csv( df=df, path=store_path, index=False, ) ret.append({ "sql": sql, "store_path": store_path, }) return ret Lambda関数 11 / 29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
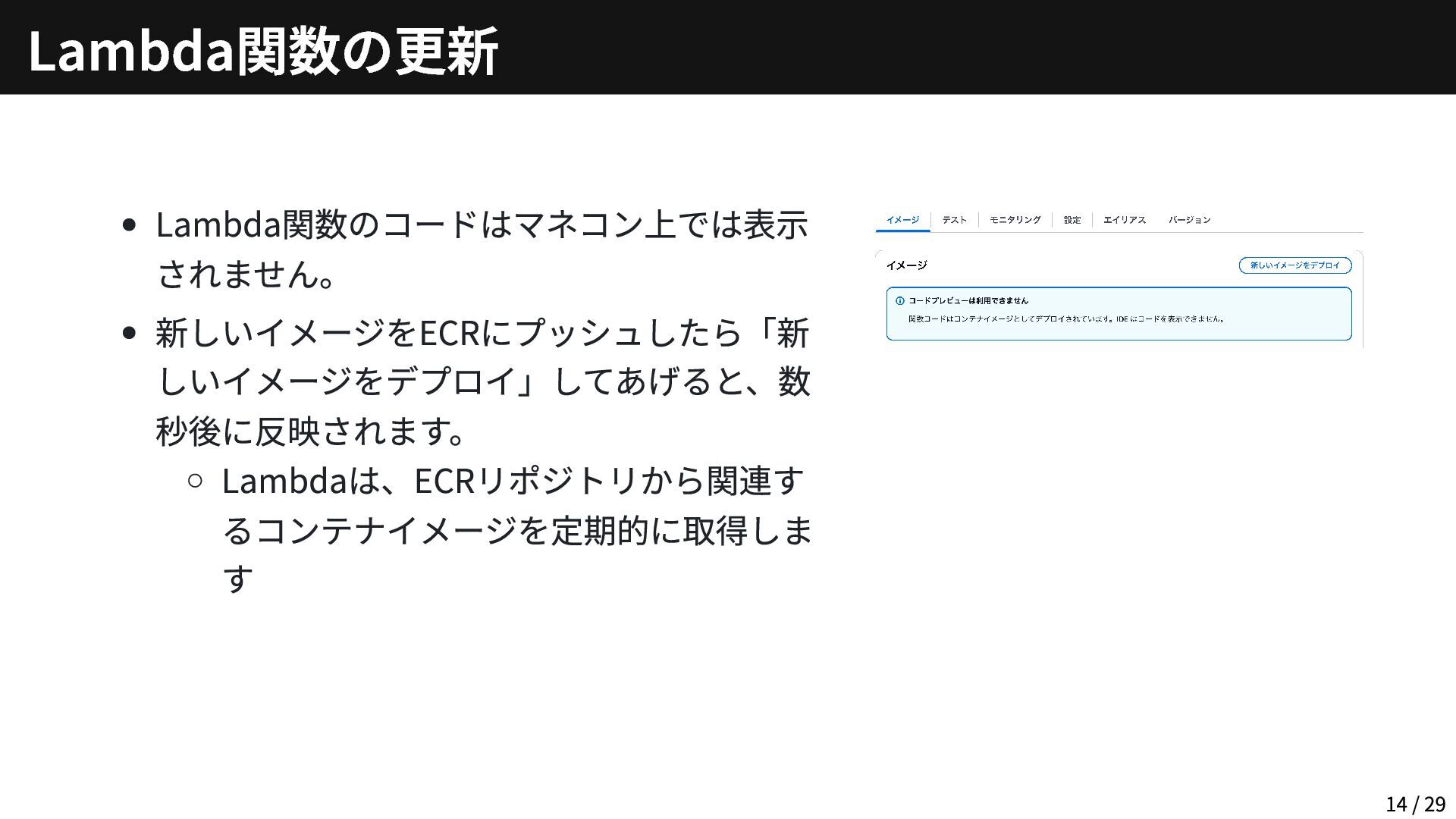{kind=link}
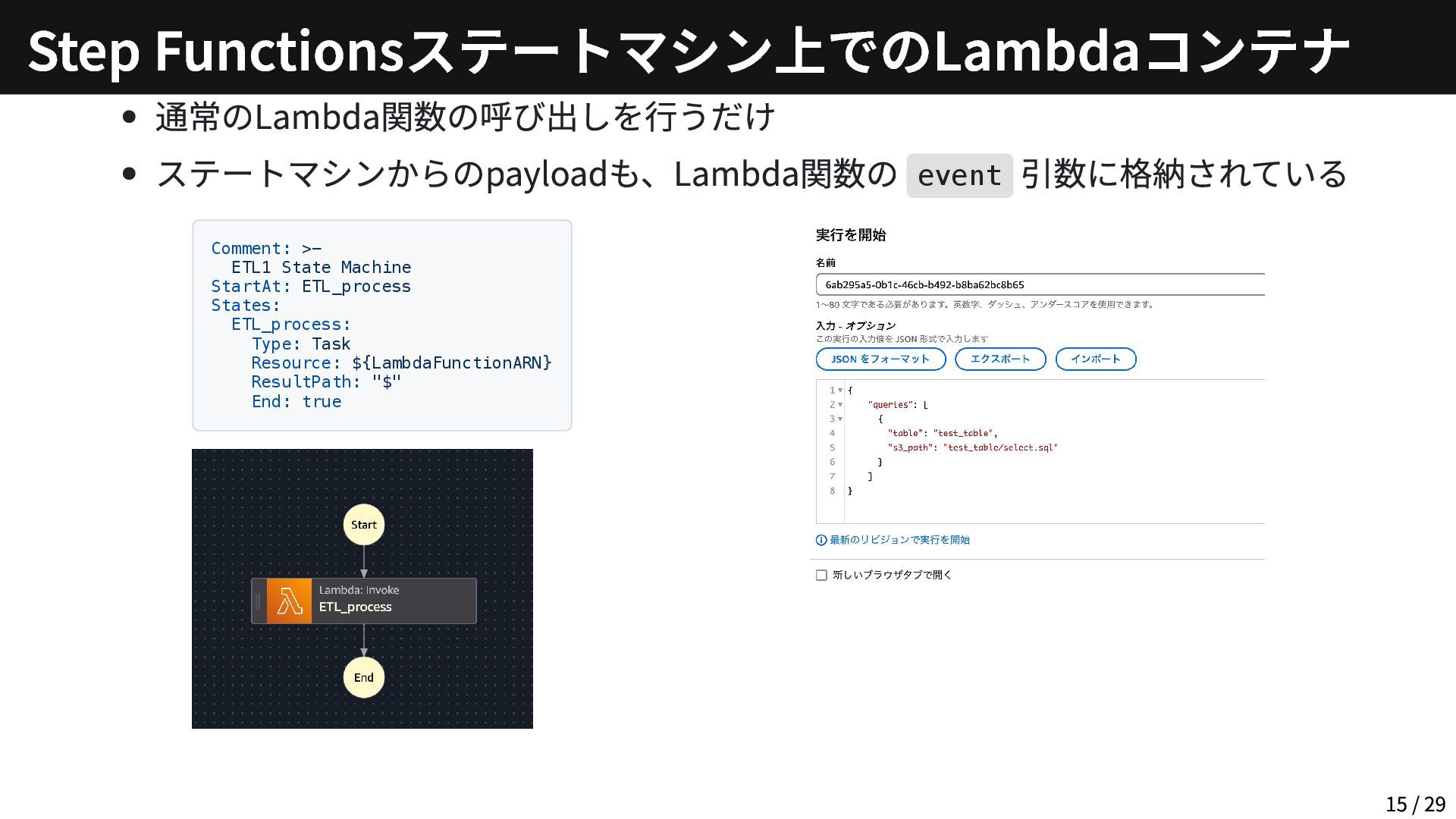{kind=link}
{kind=link}
{kind=link}
{kind=link}
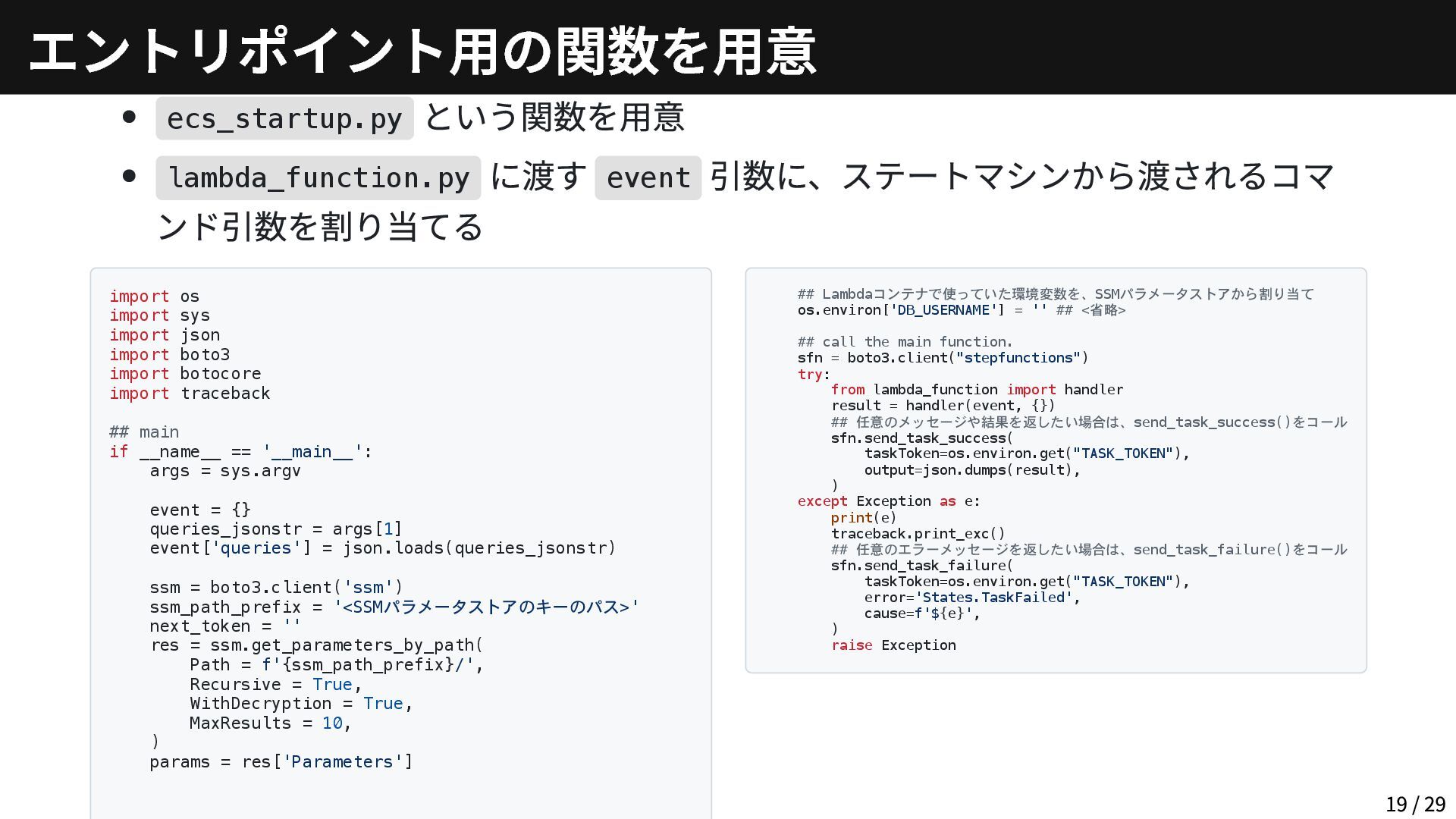{kind=link}
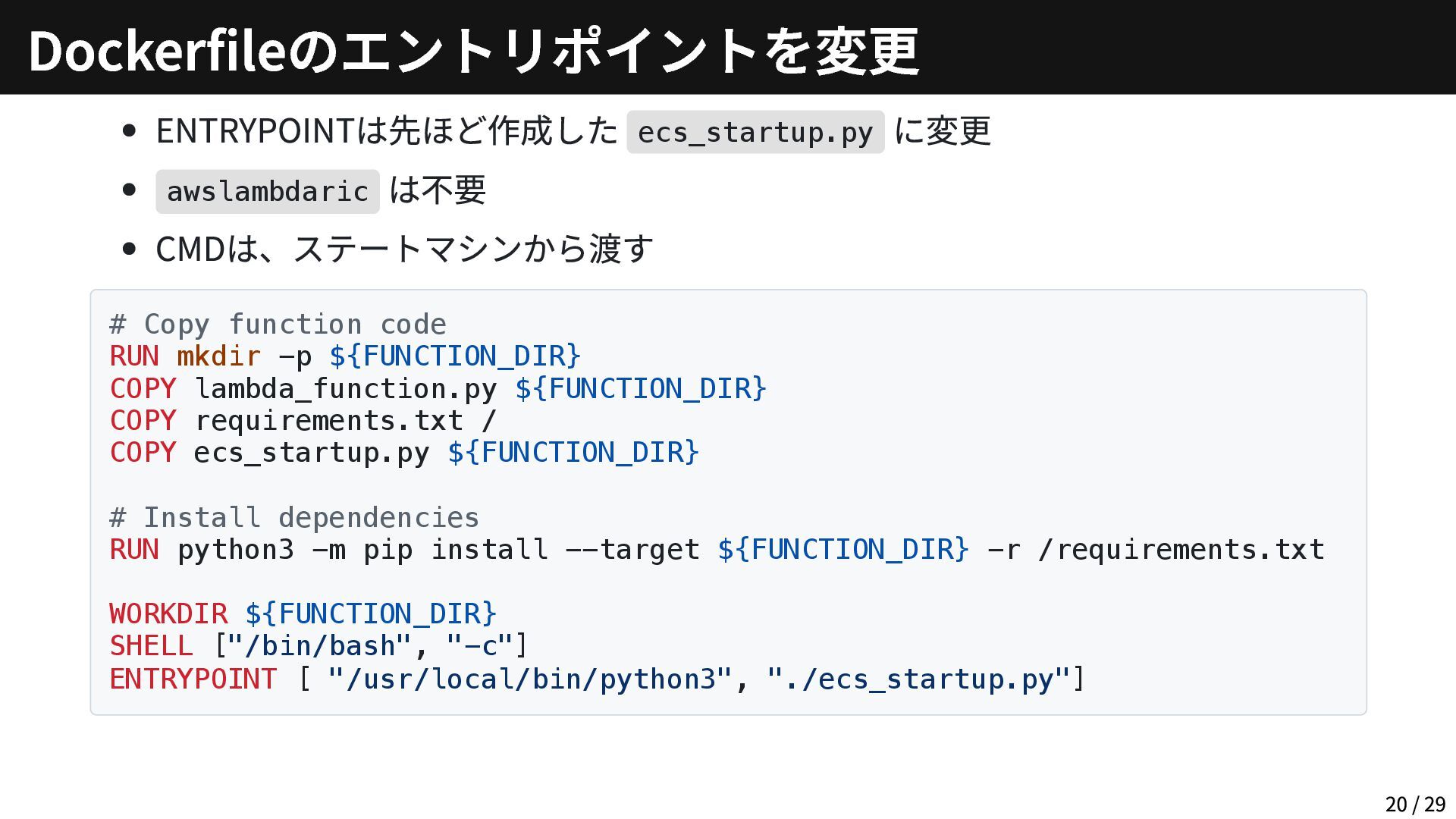{kind=link}
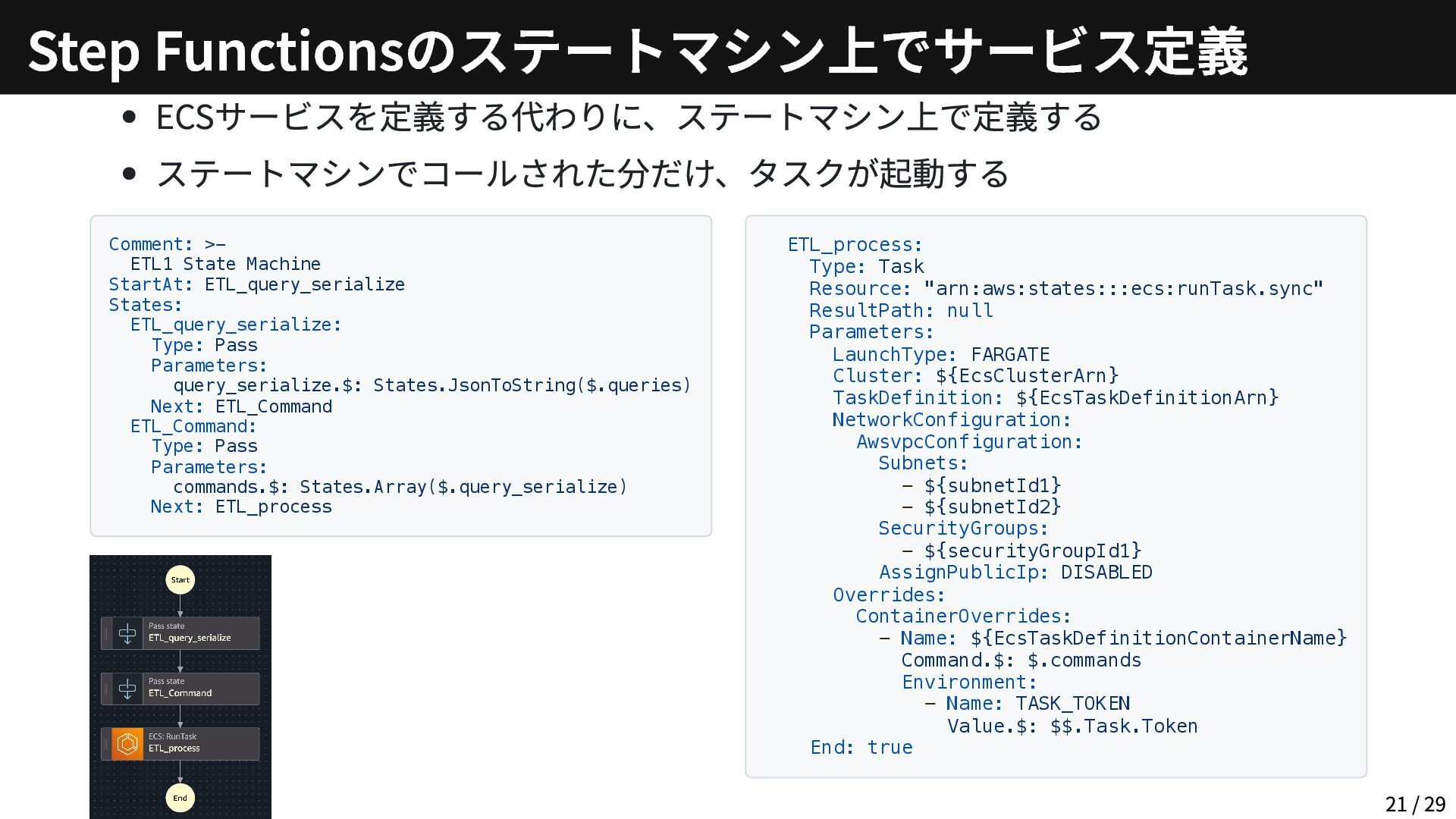{kind=link}
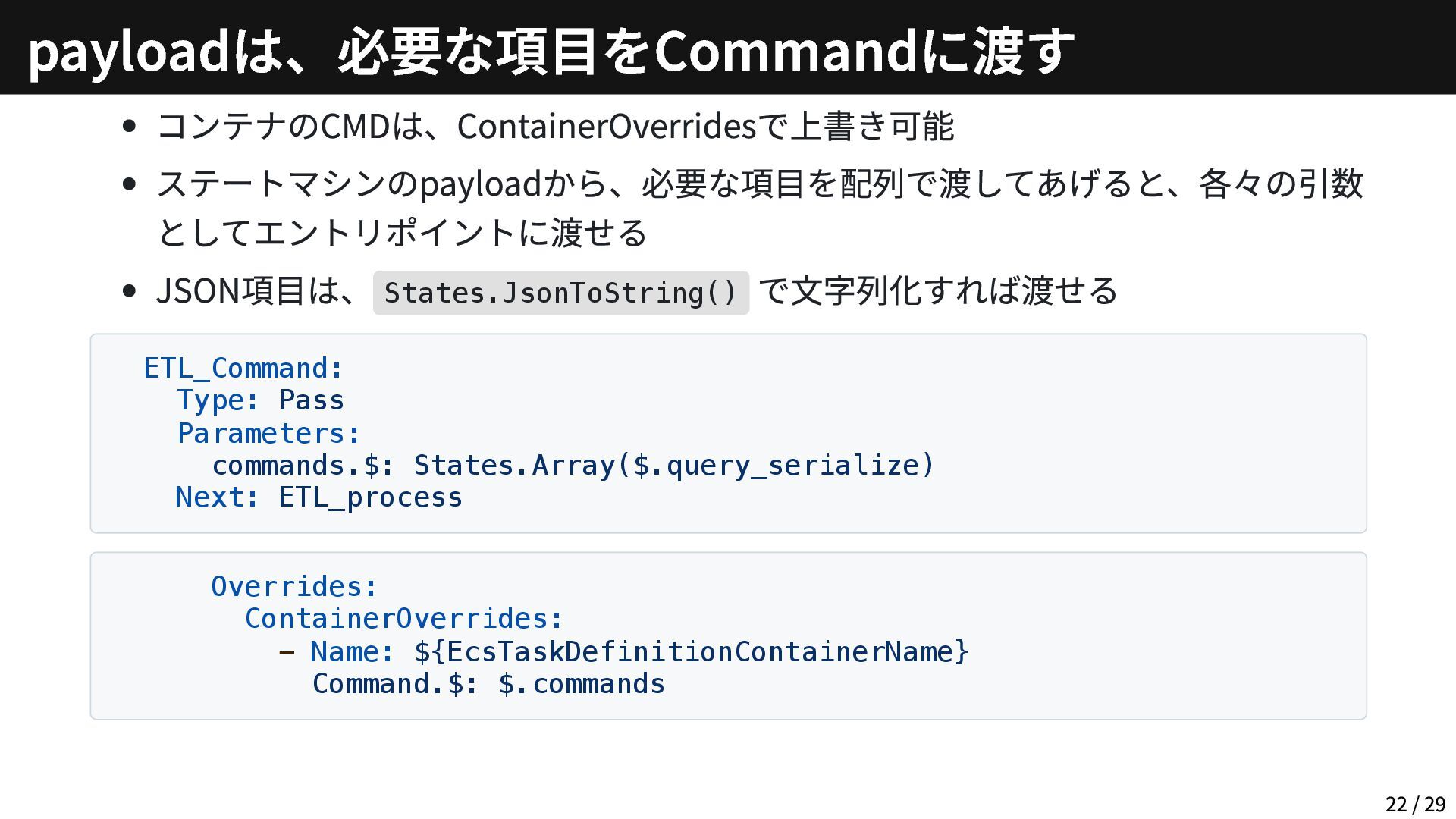{kind=link}
{kind=link}
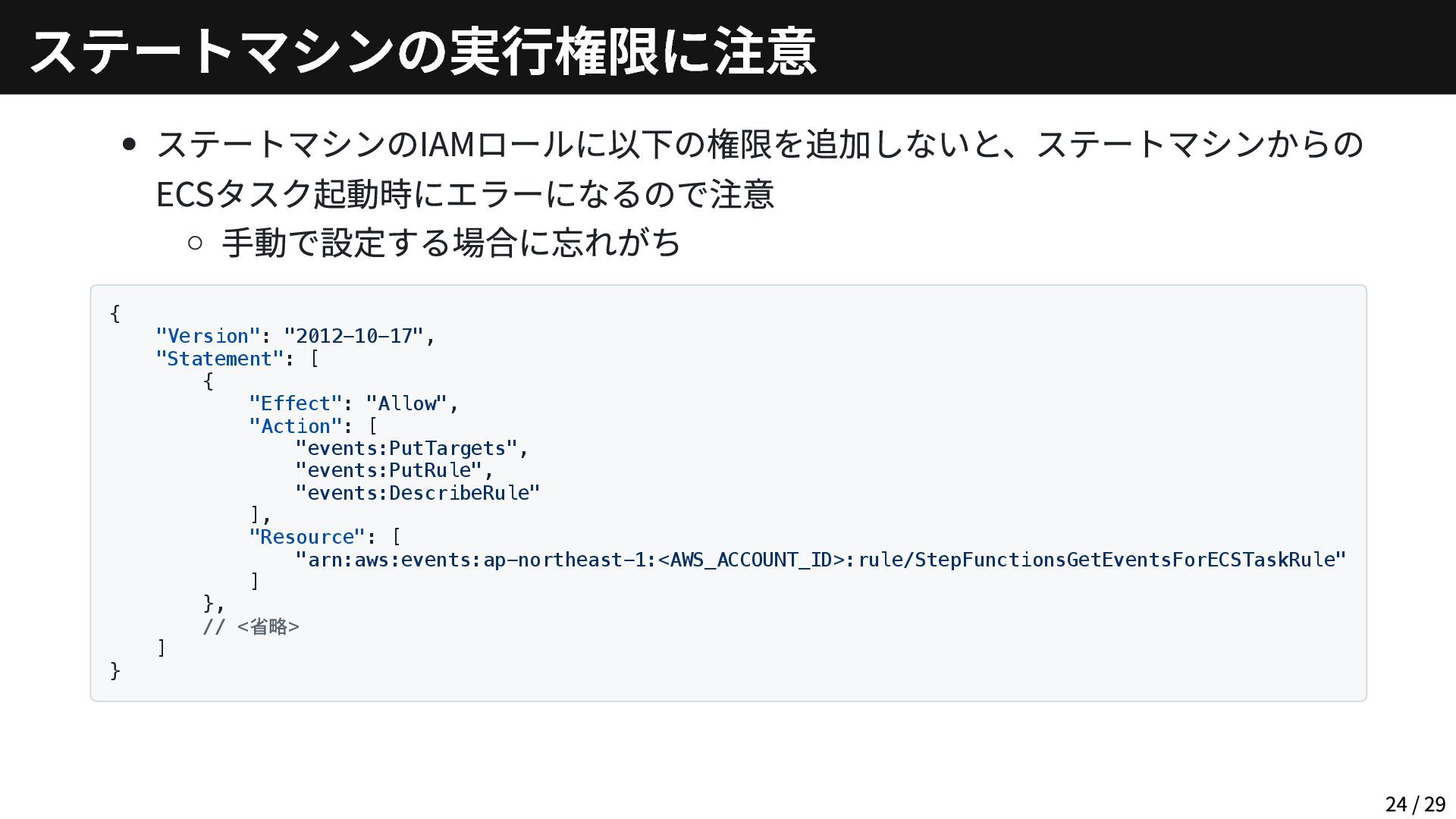{kind=link}
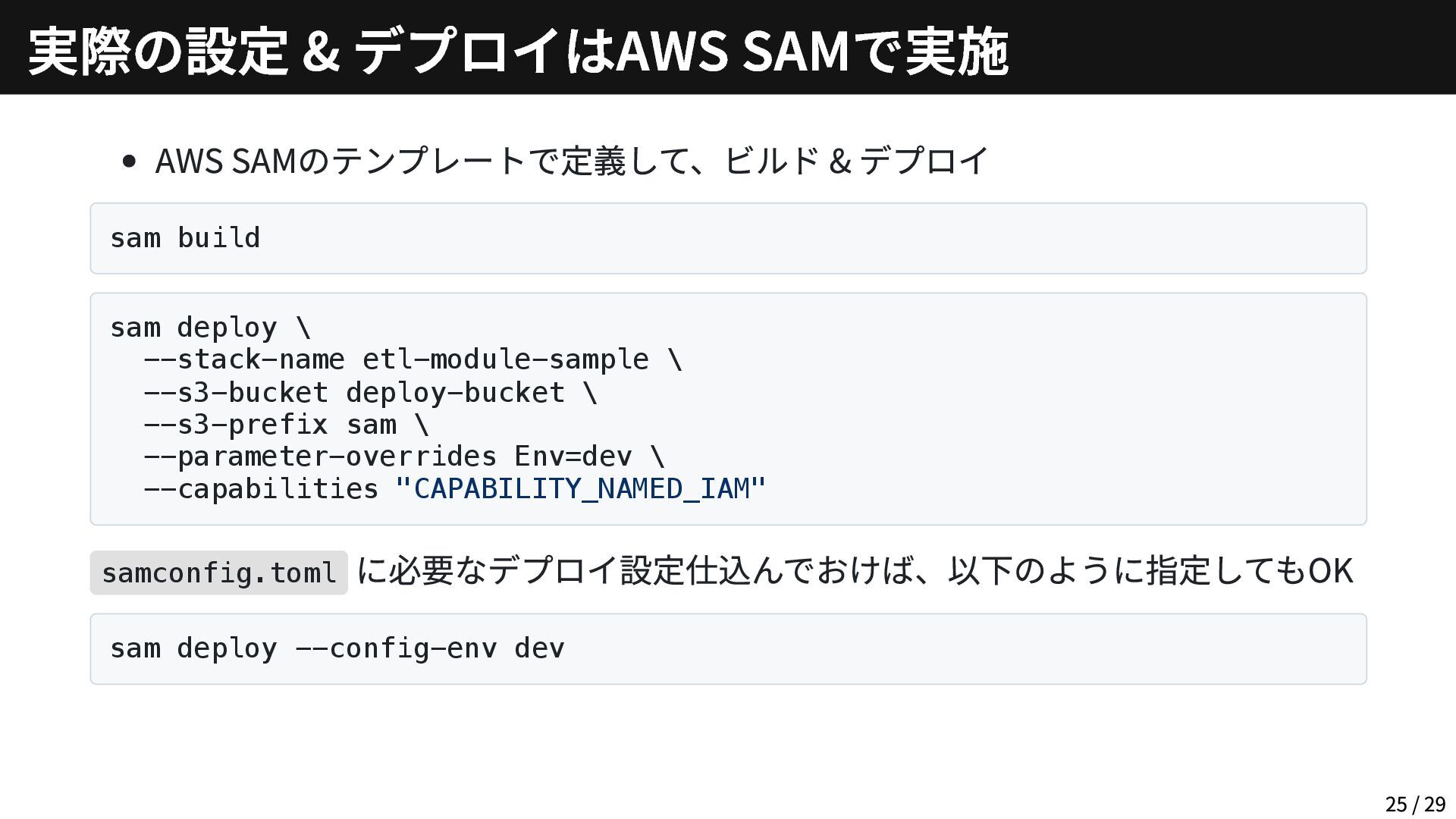{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}