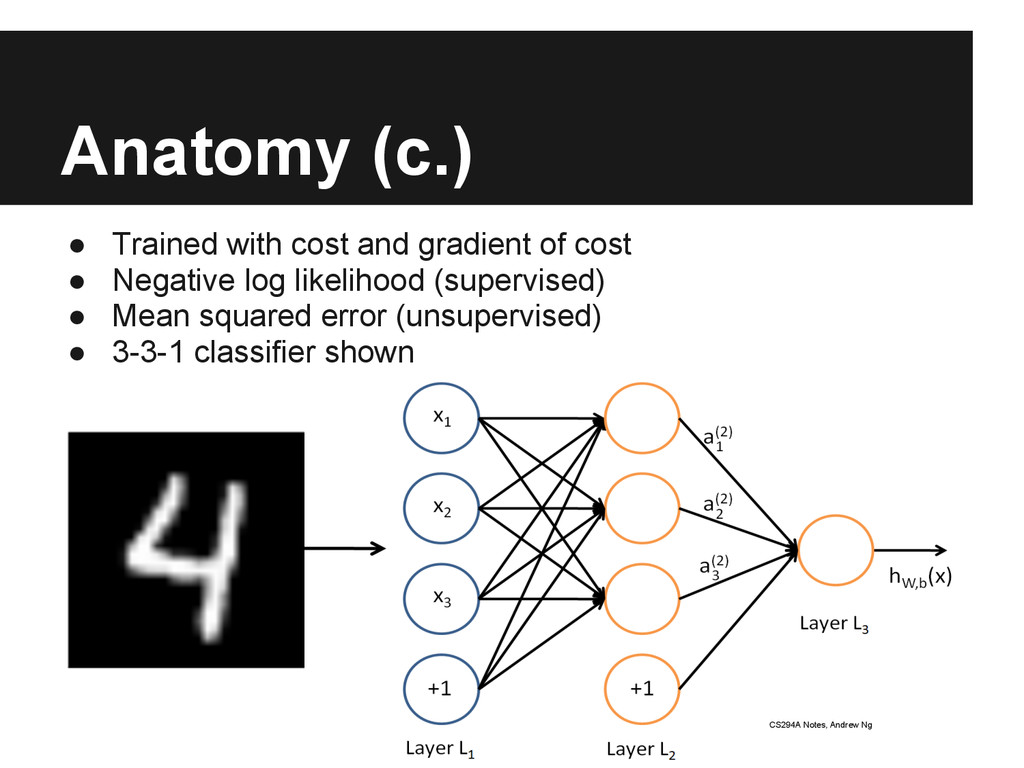
of error gradient ◦ Very important hyperparameter (VI...H?) Dropout ◦ Equivalent to averaging many neural networks ◦ Randomly zero out weights for each training example ◦ Drop 20% input, 50% hidden Momentum ◦ Analogous to physics ◦ Want settle in the lowest “valley”
Input coded values (150) to classifier Score on raw features: 0.8961 Score on encoded features: 0.912 “Borat”, 20th Century Fox The Dawson Academy, thedawsonacademy.org
until overfit • Once overfitting, add dropout • 784-1000-1000-1000-1000-10 architecture • Example achieves ~1.8% error on MNIST • State of the art is < .8% on MNIST digits! www.frontiersin.org
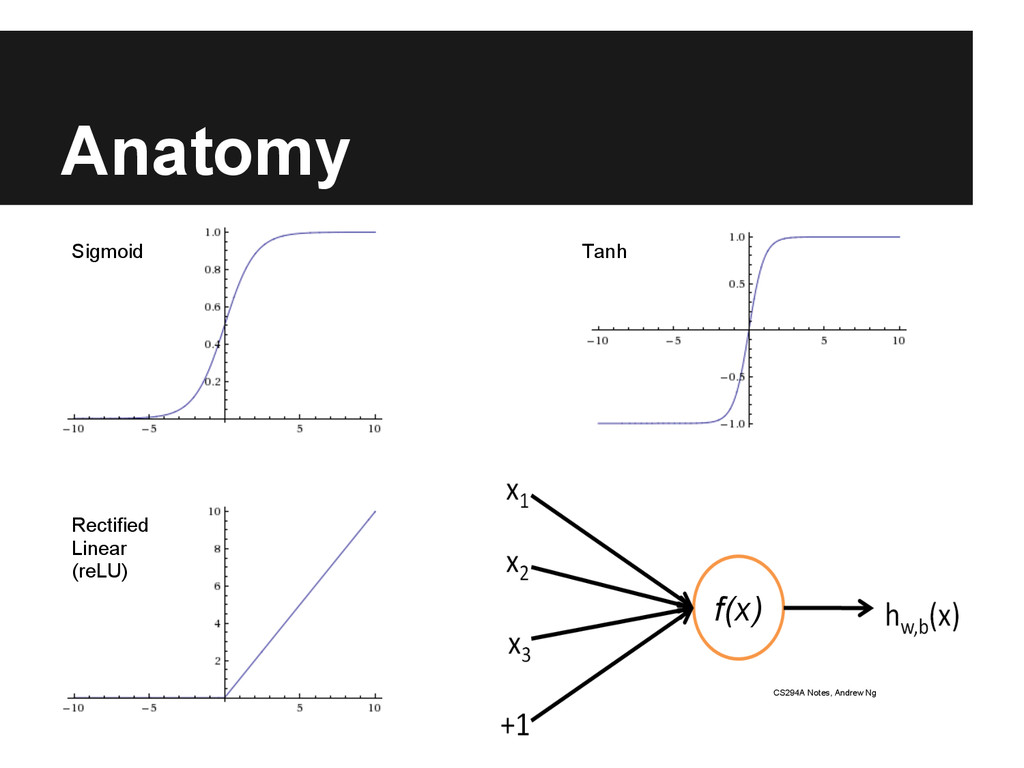
nets • Randomly zero out units (20% input, 50% hidden) Activations • Rectified linear (reLU) with dropout, classification • Sigmoid or tanh, autoencoder (no dropout!)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}