T. Fuchs, H. Lipson. “Understanding Neural Networks Through Deep Visualization”. http://yosinski.com/media/papers/Yosinski__2015__ICML_DL__Understanding_Neural_Networks_Through_Deep_Visualization__.pdf [9] K. Gregor, I. Danihelka, A. Graves, D. Rezende, D. Wierstra. “DRAW: Directed Recurrent Attention Writer”. http://arxiv.org/abs/1502.04623 [10] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio. “Generative Adversarial Networks’, NIPS 2014. http://arxiv.org/abs/1406.2661 [11] E. Denton, S. Chintala, A. Szlam, R. Fergus. “Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks”. http://arxiv.org/abs/1506.05751 [12] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, M. Riedmiller. “Playing Atari with Deep Reinforcement Learning”, Nature 2015. https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf [13] A. Brebisson, E. Simon, A. Auvolat. “Taxi Destination Prediction Challenge Winners’ Report.” https://github.com/adbrebs/taxi/blob/master/doc/short_report.pdf [14] K. Cho, B. Merrienboer, C. Gulchere, D. Bahdanau, F. Bougares, H. Schwenk, Y. Bengio. “Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation”. EMNLP 2014. http://arxiv.org/abs/1406.1078 [15] D. Bahdanau, K. Cho, Y. Bengio. “Neural Machine Translation By Jointly Learning To Align and Translate”. ICLR 2015. http://arxiv.org/abs/1409.0473 [16] A. Graves. “Generating Sequences With Recurrent Neural Networks”, 2013. http://arxiv.org/abs/1308.0850 [17] J. Weston, A. Bordes, S. Chopra, T. Mikolov, A. Rush. “Towards AI-Complete Question Answering”. http://arxiv.org/abs/1502.05698
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
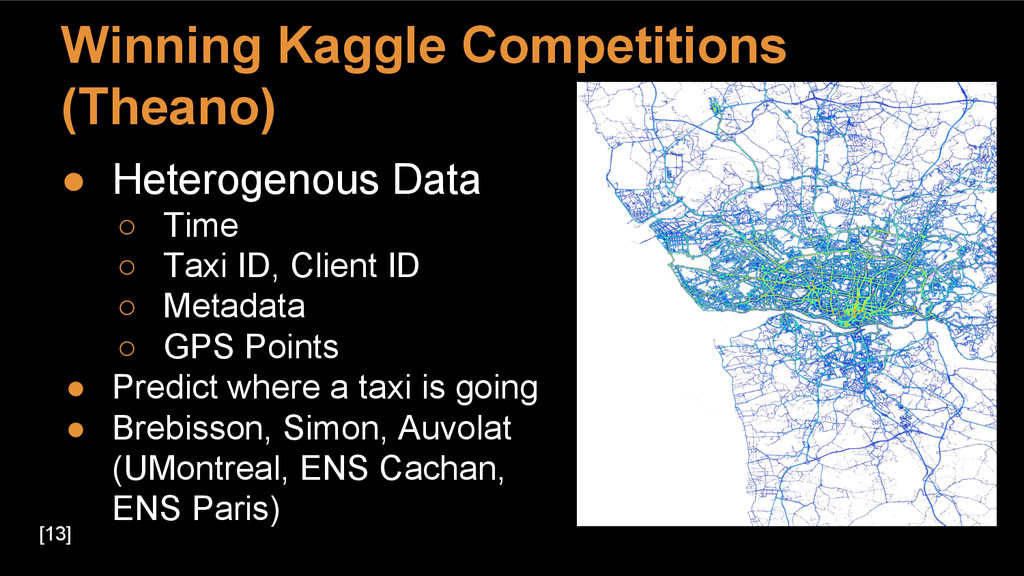
{kind=link}
{kind=link}
{kind=link}
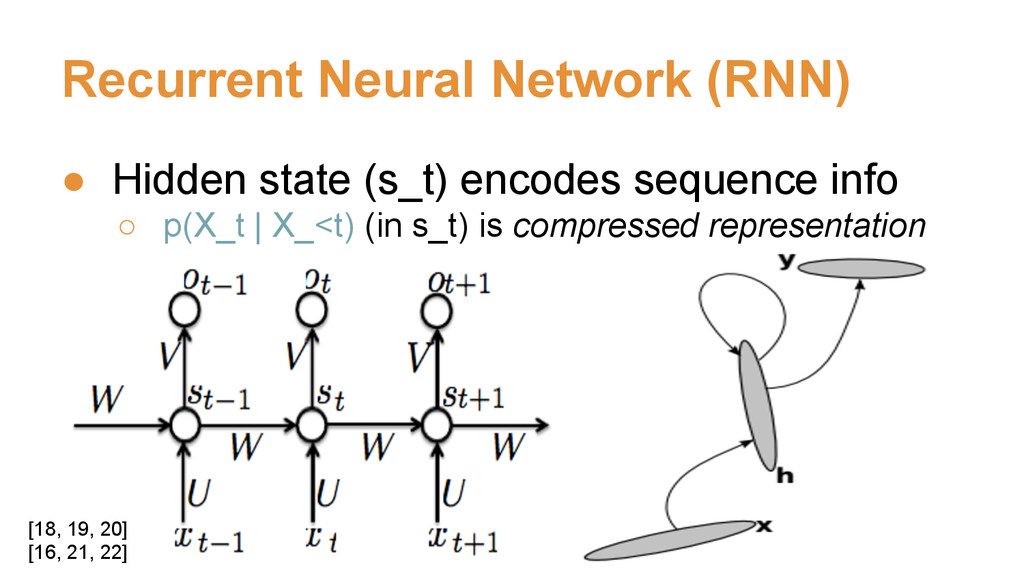
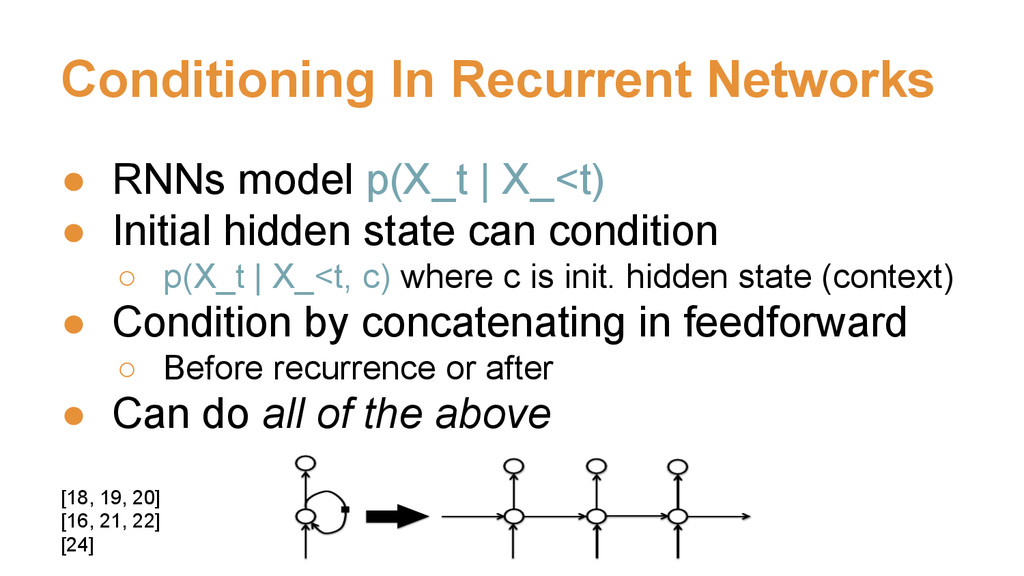
![ENCODER DECODER [18, 19, 20] [26, 27, 28]](https://files.speakerdeck.com/presentations/82e8c41abea543ea85de5efb6aa8a78a/slide_15.jpg){kind=link}
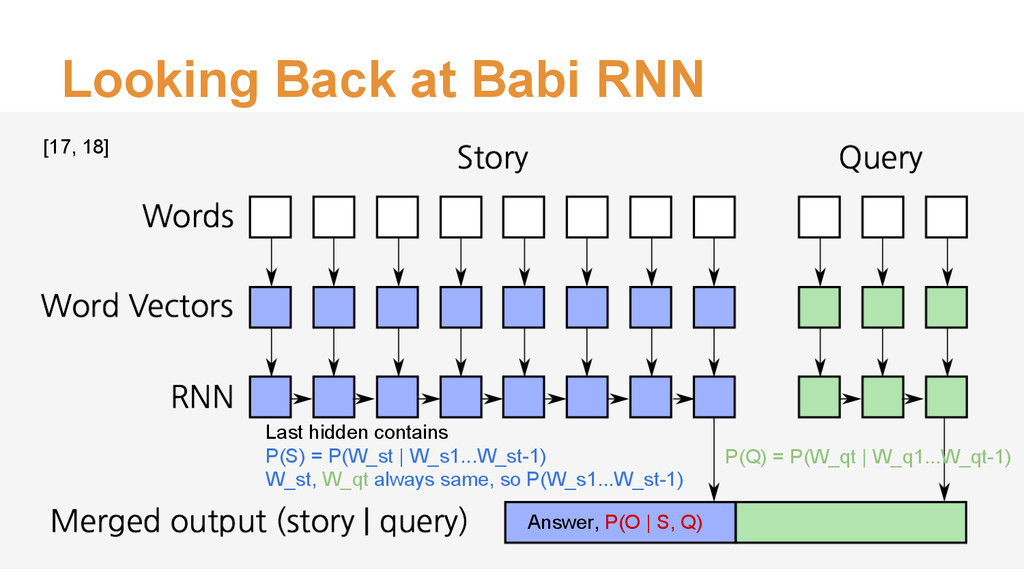
![Conditioning, Visually [26, 27, 28]](https://files.speakerdeck.com/presentations/82e8c41abea543ea85de5efb6aa8a78a/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
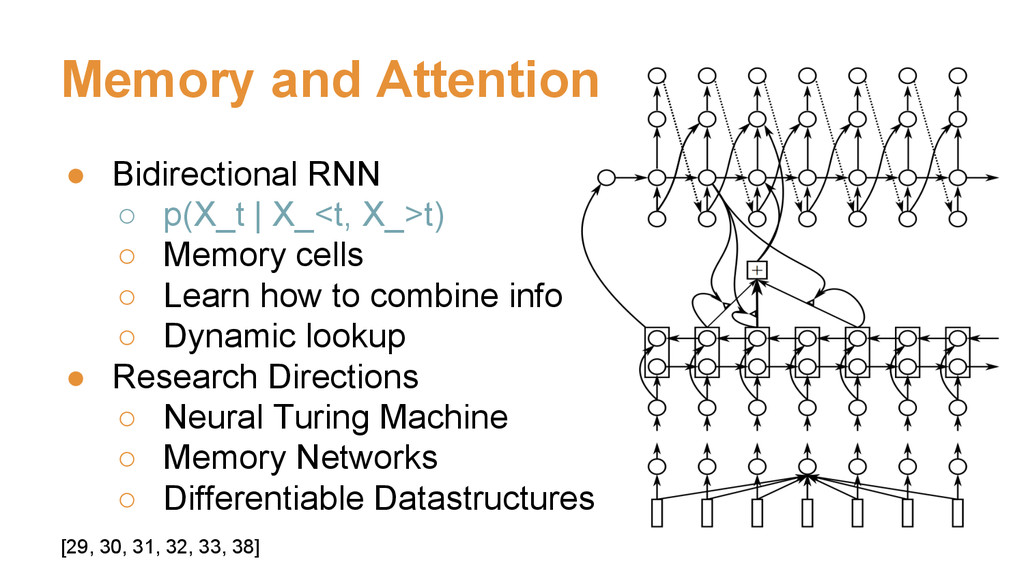{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References (1) [1] F. Bastien, P. Lamblin, R. Pascanu, J.](https://files.speakerdeck.com/presentations/82e8c41abea543ea85de5efb6aa8a78a/slide_24.jpg){kind=link}
![References (2) [8] J. Yosinski, J. Clune , A. Nguyen,](https://files.speakerdeck.com/presentations/82e8c41abea543ea85de5efb6aa8a78a/slide_25.jpg){kind=link}
![References (3) [18] Y. Bengio, I. Goodfellow, A. Courville. “Deep](https://files.speakerdeck.com/presentations/82e8c41abea543ea85de5efb6aa8a78a/slide_26.jpg){kind=link}
![[29] A. Graves, G. Wayne, I. Danihelka. “Neural Turing Machines”.](https://files.speakerdeck.com/presentations/82e8c41abea543ea85de5efb6aa8a78a/slide_27.jpg){kind=link}