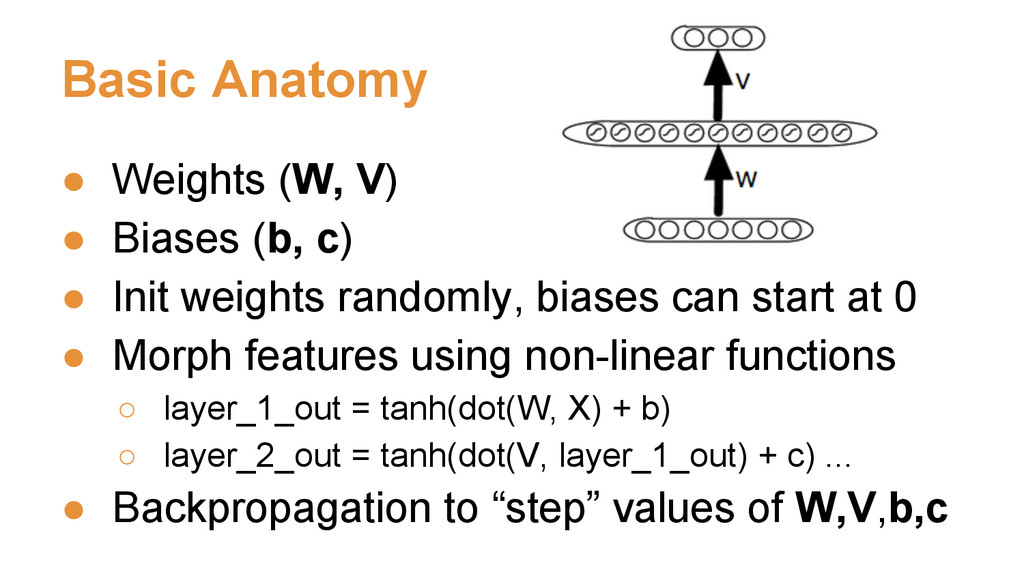
• Init weights randomly, biases can start at 0 • Morph features using non-linear functions ◦ layer_1_out = tanh(dot(W, X) + b) ◦ layer_2_out = tanh(dot(V, layer_1_out) + c) ... • Backpropagation to “step” values of W,V,b,c
return X * (X > 0) • Optimization ◦ RMSProp w. momentum, ADaM (easiest to tune) ◦ Stochastic Gradient Descent w. momentum (harder) • Regularize with Dropout ◦ https://www.cs.toronto.edu/~hinton/csc2535/notes/lec6a.ppt • Great initialization reference ◦ https://plus.google.com/+SoumithChintala/posts/RZfdrRQWL6u
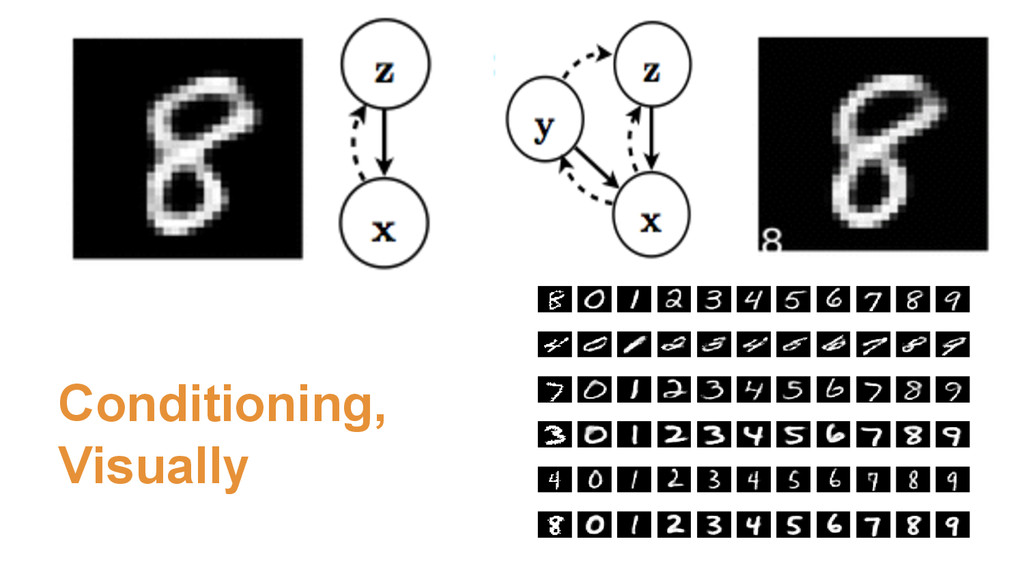
| z) vs. p(x_hat | z, y) • Can give control or add prior knowledge • Classification is an even stronger form ◦ Prediction is learned by maximizing p(y | x) ! ◦ In classification, don’t worry about forming a useful z
p(y | X_1 … X_n, L_1 … L_n) • One hot label L (scikit-learn label_binarize) • Could also be real valued • Concat followed with multiple layers to “mix”
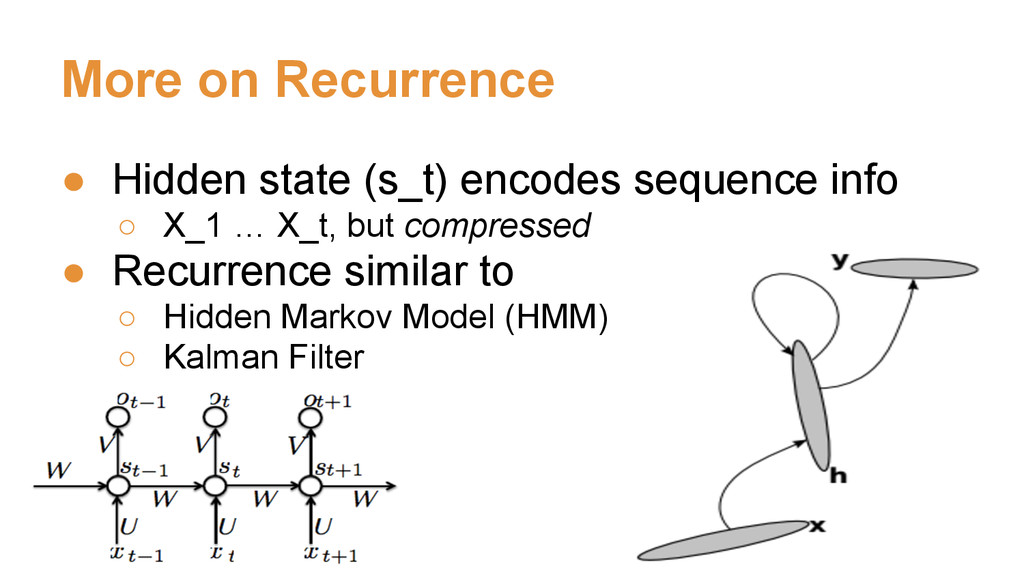
orthogonal ◦ Use U from U, S, V = svd(randn_init) • Long short term memory or gated recurrent ◦ {LSTM, GRU} fancy recurrent activations • {Sentences, dialogues, sounds} are sequences ◦ Many-to-one (sequence recognition) ◦ Many-to-many (sequence to sequence) ◦ One-to-many (sequence generation) ◦ Many-to-one-to-many (encode-decode)
• linear, linear -> Gaussian with mean, log_var • softmax, linear, linear -> Gaussian mixture • Depends crucially on the cost • Can combine with recurrence ◦ Learned, dynamic distributions over sequences ◦ Incredibly powerful
from “where” ◦ Similar to attention • Combine with reinforcement learning ◦ No more labels? ◦ Deep Q Learning - playing Atari from video! ◦ https://www.youtube.com/watch?v=V1eYniJ0Rnk#t=1m12s
modeling ◦ Different tools, same conceptual idea ◦ Conditional probability modeling is key • Put knowledge in model structure, not features • Let features be learned from data • Use conditioning to control or constrain
be uploaded to https://speakerdeck.com/kastnerkyle sklearn-theano, a scikit-learn compatible library for using pretrained networks : http: //sklearn-theano.github.io/ Neural network tutorial by @NewMu / Alec Radford : https://github. com/Newmu/Theano-Tutorials Theano Deep Learning Tutorials: http://deeplearning.net/tutorial/
how many ◦ Similar to output size of feedforward layer • Parameter sharing ◦ Small filter moves over entire input ◦ Local statistics consistent over all regions • Condition by concatenating ◦ Along “channel” axis ◦ http://arxiv.org/abs/1406.2283
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}