Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
慶應義塾大学 機械学習基礎08 再帰型ニューラルネット
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
November 05, 2021
Technology
1k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
慶應義塾大学 機械学習基礎08 再帰型ニューラルネット
Semantic Machine Intelligence Lab., Keio Univ.
PRO
November 05, 2021
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
61
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
73
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
110
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
90
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
6.9k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
1
2.2k
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.6k
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
190
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
390
フルカイテン株式会社 エンジニア向け採用資料
fullkaiten
0
11k
そのタスクオンスケですか?
poropinai1966
0
140
AIペネトレーションテスト・ セキュリティ検証「AgenticSec」紹介資料
laysakura
2
8.1k
AI時代における最適なQA組織の作り方
ymty
3
460
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
1
2.6k
依頼文化をやめる日 EM視点で語るPlatform EngineeringとInclusive SRE / Discussing Platform Engineering and Inclusive SRE from an EM's Perspective
shin1988
4
4.2k
Agentic AI 時代のテスト手法: Kiro とはじめるプロパティベーステスト (AWS Summit Japan 2026 | DEV212)
ymhiroki
0
220
最近評価が難しくなった
maroon8021
0
250
Featured
See All Featured
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
960
Evolving SEO for Evolving Search Engines
ryanjones
0
240
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
440
Speed Design
sergeychernyshev
33
1.9k
GitHub's CSS Performance
jonrohan
1033
470k
Paper Plane
katiecoart
PRO
1
52k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
30 Presentation Tips
portentint
PRO
1
340
Producing Creativity
orderedlist
PRO
348
40k
Transcript
情報工学科 教授 杉浦孔明
[email protected]
慶應義塾大学理工学部 機械学習基礎 第8回 再帰型ニューラルネット
本講義の到達目標と今回の授業の狙い - - 9 本講義の到達目標 ▪ DNNの基礎理論と実装の関係を理解する ▪ 種々のDNNをコーディングできる 今回の授業の狙い
▪ 再帰型ニューラルネットの基礎を習得する ▪ 出席確認: K-LMS上の機械学習基礎のMainページへアクセス
再帰型ニューラルネット - - 10
系列データとは ▪ 順序を持った要素の集まり:「列」 ▪ 例 ▪ 時系列 ▪ 音声・音楽 ▪
自然言語 ▪ 塩基配列 - - 11 日本語・英語など 人工言語でない言語
系列データとは ▪ 順序を持った要素の集まり:「列」 ▪ 長さ がサンプルごとに違う ▪ 説明の都合上、インデックスを時刻と呼ぶ ▪ 扱いたい問題の例
▪ を考慮して から を 予測する ▪ を集約し潜在表現を作る - - 12 https://imagen.research.google/ 赤いコートをまとい,本を 読みながらラウンジチェア に座り,大森林の中にいる ハリネズミの写真 例えば文は時間とは関係ないが、 便宜上、時刻と呼ぶ 潜在表現 例えば文の意味が数値化 されたと考えれば良い
順伝播型ニューラルネット(FFNN)で系列データを扱う と何が問題か? ▪ 過去の情報を保持できない ▪ を逐次入力とした場合, 出力 は入力 の関数となり 過去の入力
は考慮されないため ▪ 可変長の系列データを扱うことができない ▪ を一括入力とした場合, 長さ をサンプル間で共通とする必要があるため FFNN - - 13 ※いくつかの仮定を置けばFFNN (系列全体入力)でも可能
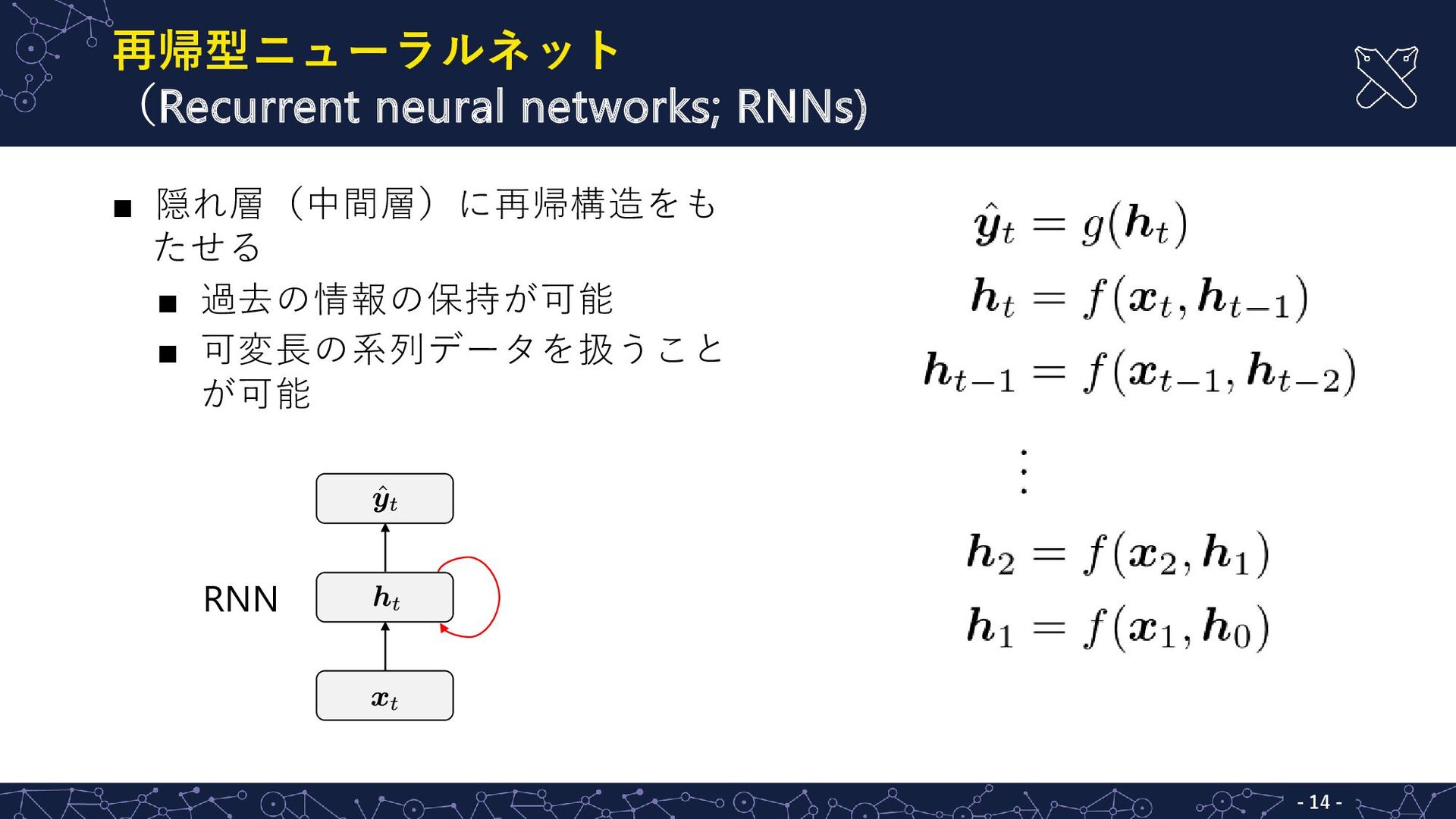
再帰型ニューラルネット (Recurrent neural networks; RNNs) ▪ 隠れ層(中間層)に再帰構造をも たせる ▪ 過去の情報の保持が可能
▪ 可変長の系列データを扱うこと が可能 RNN - - 14
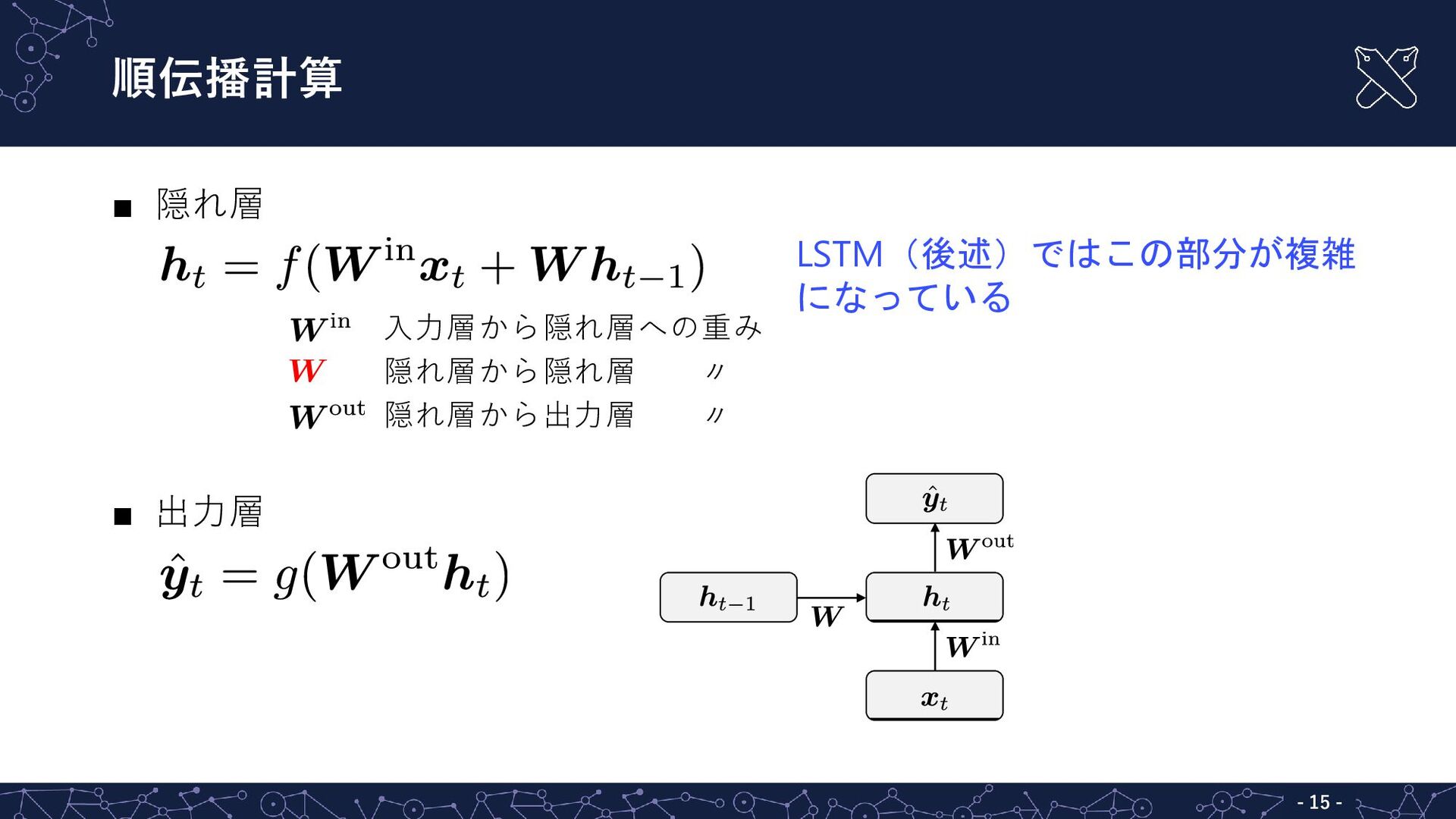
順伝播計算 ▪ 隠れ層 ▪ 出力層 - - 15 LSTM(後述)ではこの部分が複雑 になっている
入力層から隠れ層への重み 隠れ層から隠れ層 〃 隠れ層から出力層 〃
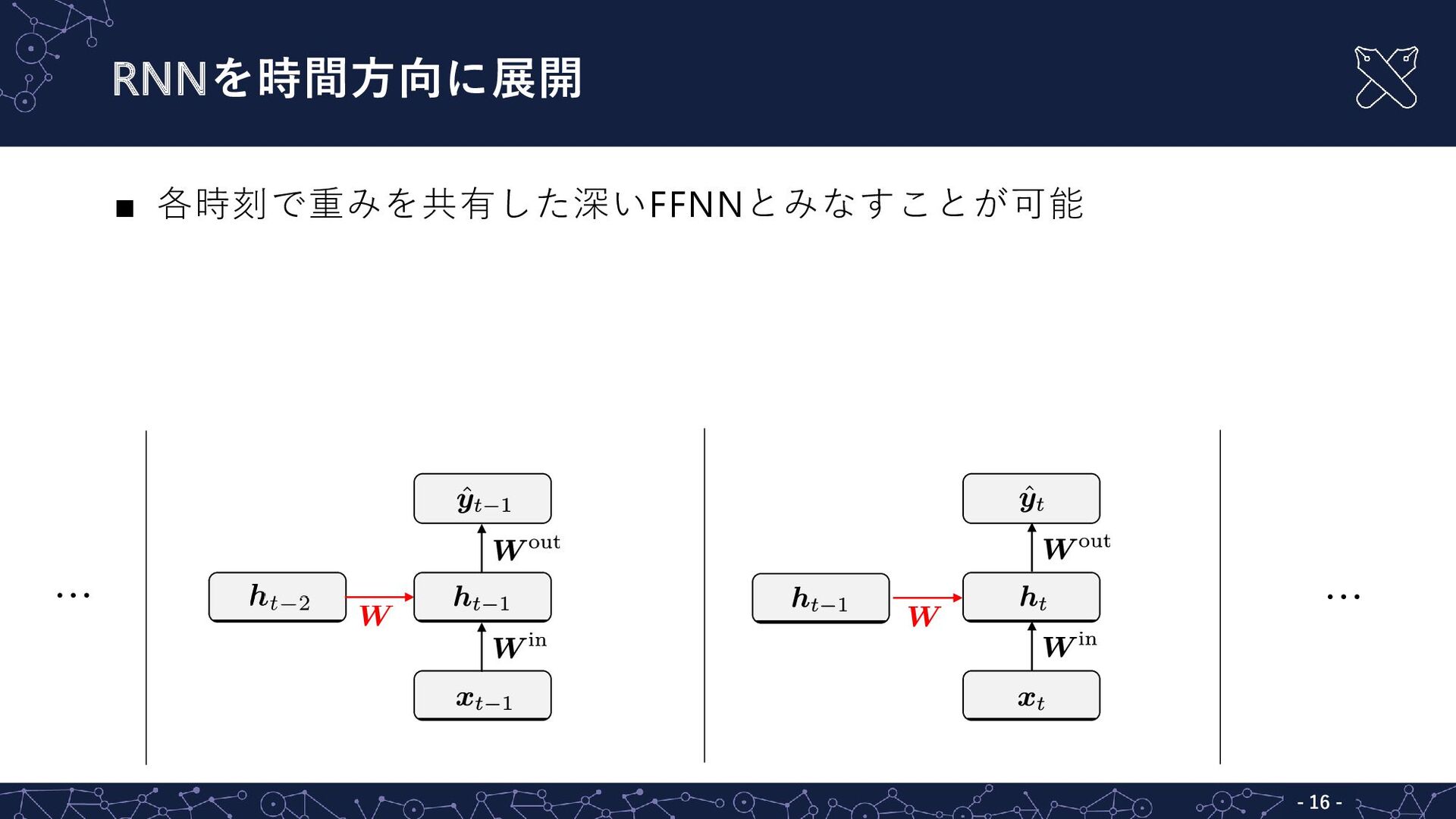
RNNを時間方向に展開 ▪ 各時刻で重みを共有した深いFFNNとみなすことが可能 … - - 16 …
RNNを時間方向に展開 ▪ 各時刻で重みを共有した深いFFNNとみなすことが可能 ▪ 入力層から隠れ層への重み ▪ 隠れ層から隠れ層 〃 各時刻で共通 ▪
隠れ層から出力層 〃 … … - - 17
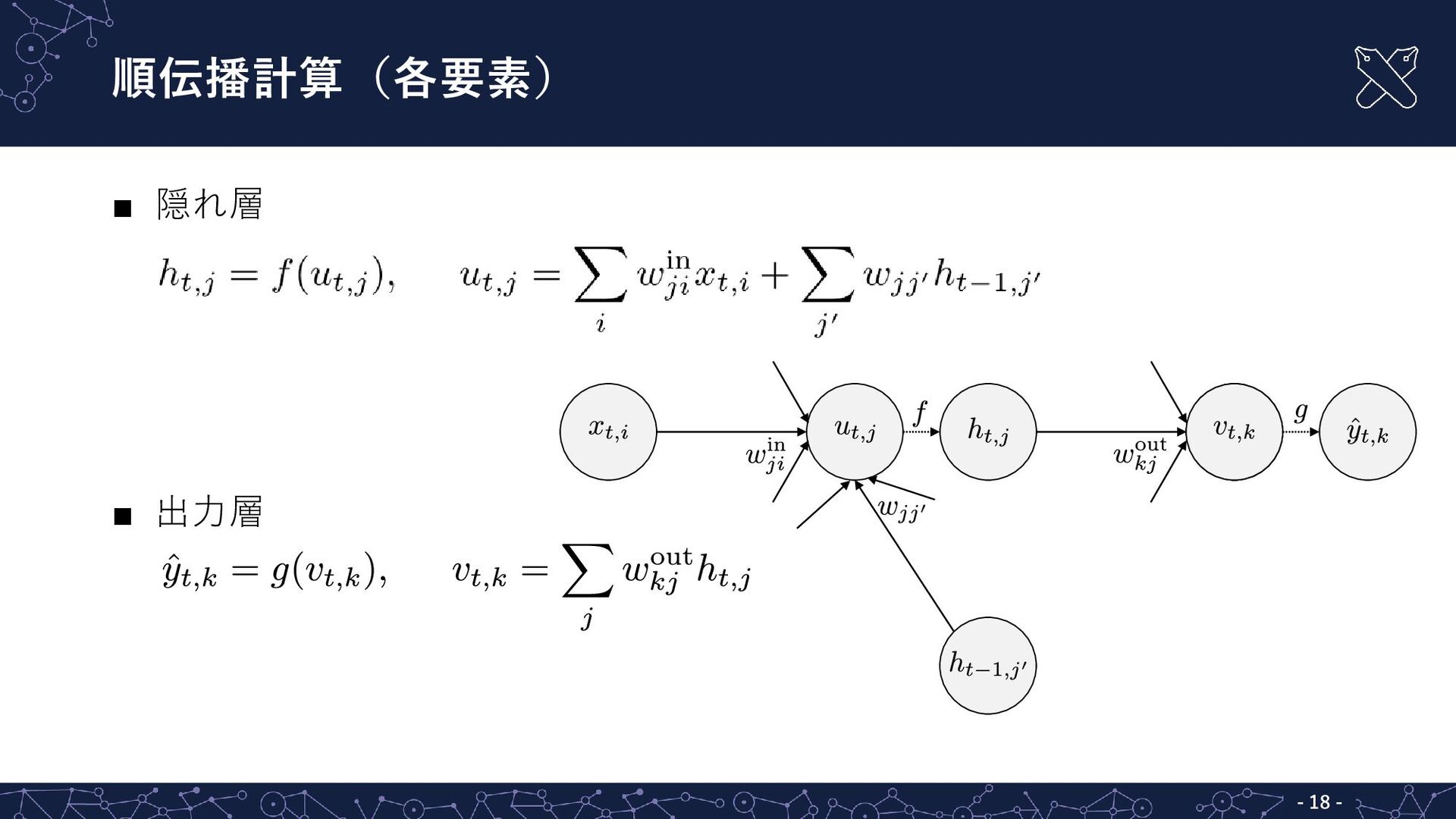
順伝播計算(各要素) ▪ 隠れ層 ▪ 出力層 - - 18
CNNとRNNの違い 畳み込みニューラルネット(CNN) ▪ 画像データの特性に応じてデザインされたネットワーク ▪ 畳み込み層・プーリング層 ▪ 誤差逆伝播(backpropagation)を用いた勾配降下法による学習 再帰型ニューラルネット(recurrent neural
network, RNN) ▪ 系列データの特性に応じてデザインされたネットワーク ▪ 再帰構造を有する隠れ層 ▪ 通時的誤差逆伝播(backpropagation through time: BPTT)を 用いた勾配降下法による学習 - - 19
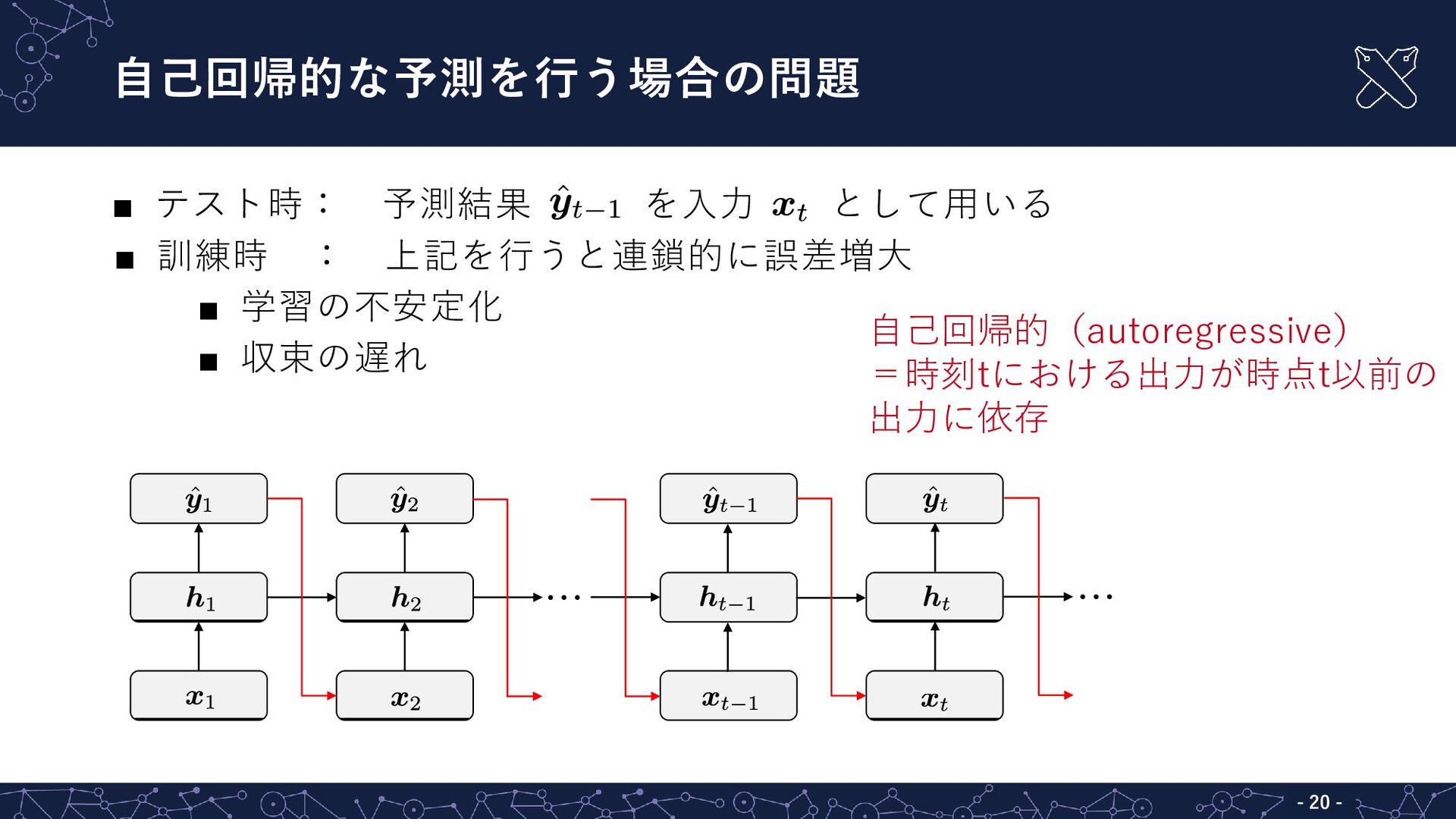
自己回帰的な予測を行う場合の問題 ▪ テスト時: 予測結果 を入力 として用いる ▪ 訓練時 : 上記を行うと連鎖的に誤差増大
▪ 学習の不安定化 ▪ 収束の遅れ … … - - 20 自己回帰的(autoregressive) =時刻tにおける出力が時点t以前の 出力に依存
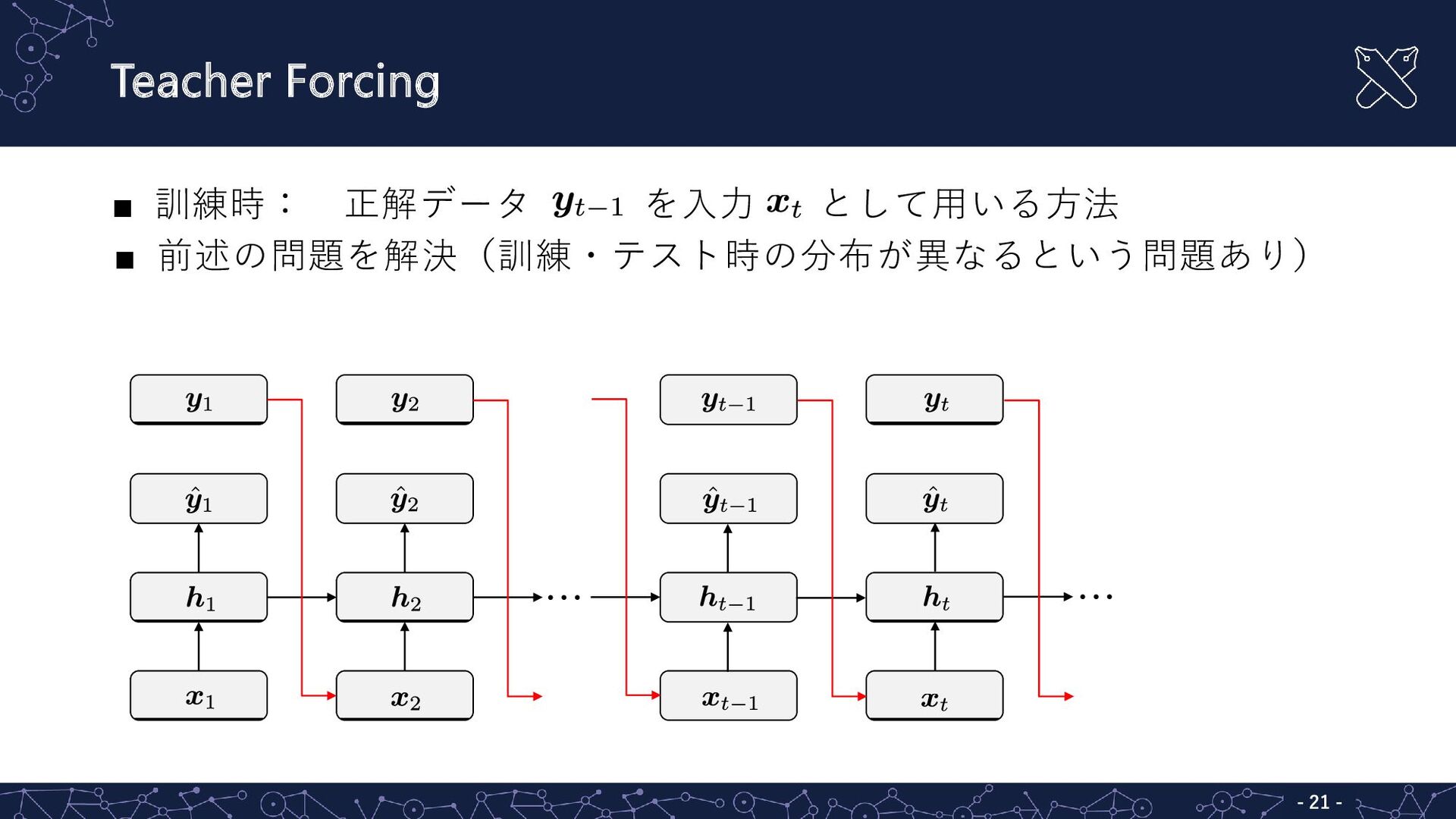
Teacher Forcing ▪ 訓練時: 正解データ を入力 として用いる方法 ▪ 前述の問題を解決(訓練・テスト時の分布が異なるという問題あり) …
… - - 21
勾配降下法に基づくRNNの学習 通時的誤差逆伝播法(backpropagation through time: BPTT) 時間方向に展開したRNNに対して誤差逆伝播法を適用 各時刻での誤差の合計 の勾配を考える
- - 22 … …
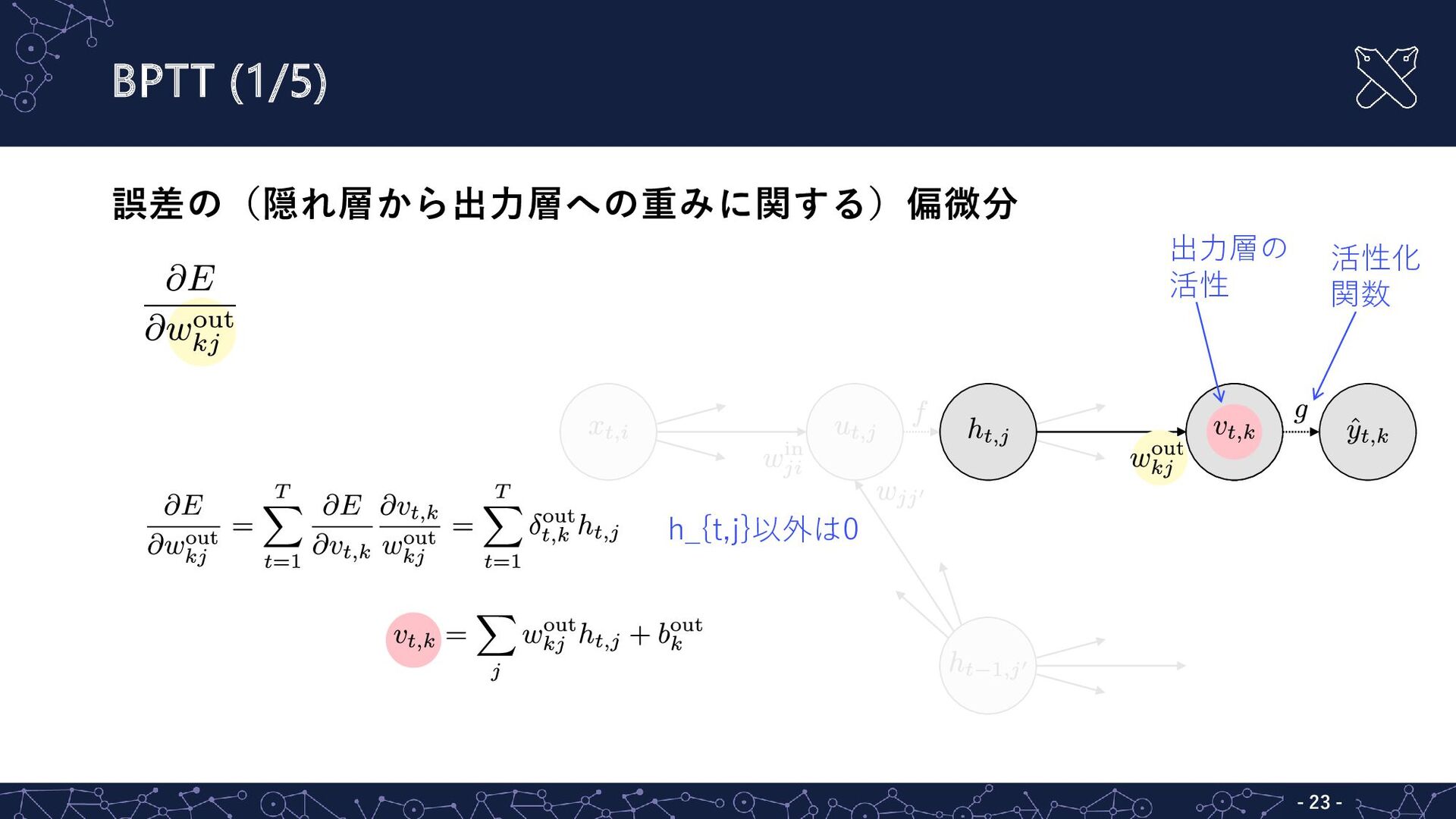
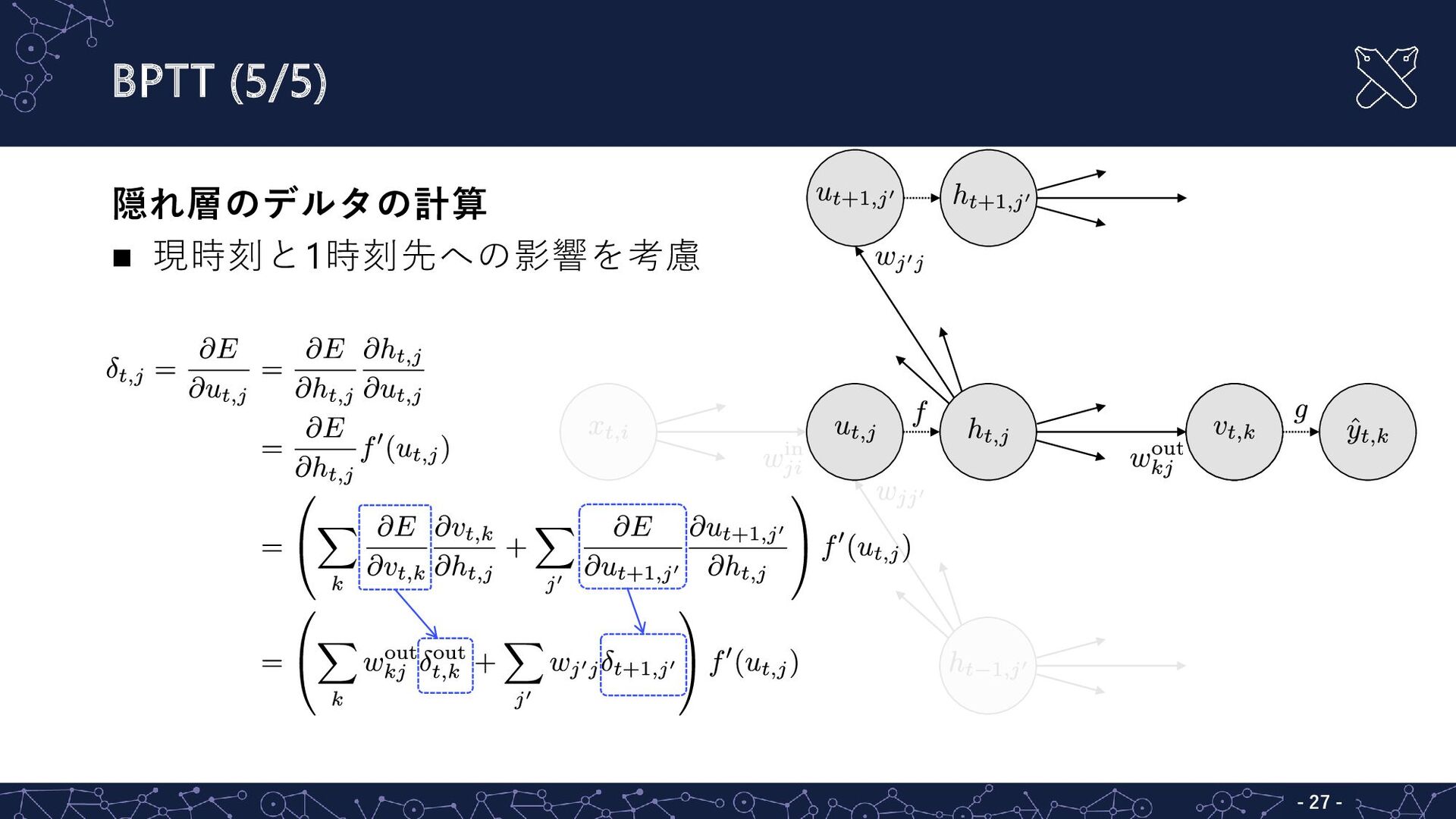
誤差の(隠れ層から出力層への重みに関する)偏微分 - - 23 BPTT (1/5) h_{t,j}以外は0 出力層の 活性 活性化
関数
- - 24 BPTT (2/5) 誤差の(隠れ層から隠れ層への重みに関する)偏微分
- - 25 BPTT (3/5) 誤差の(入力層から隠れ層への重みに関する)偏微分
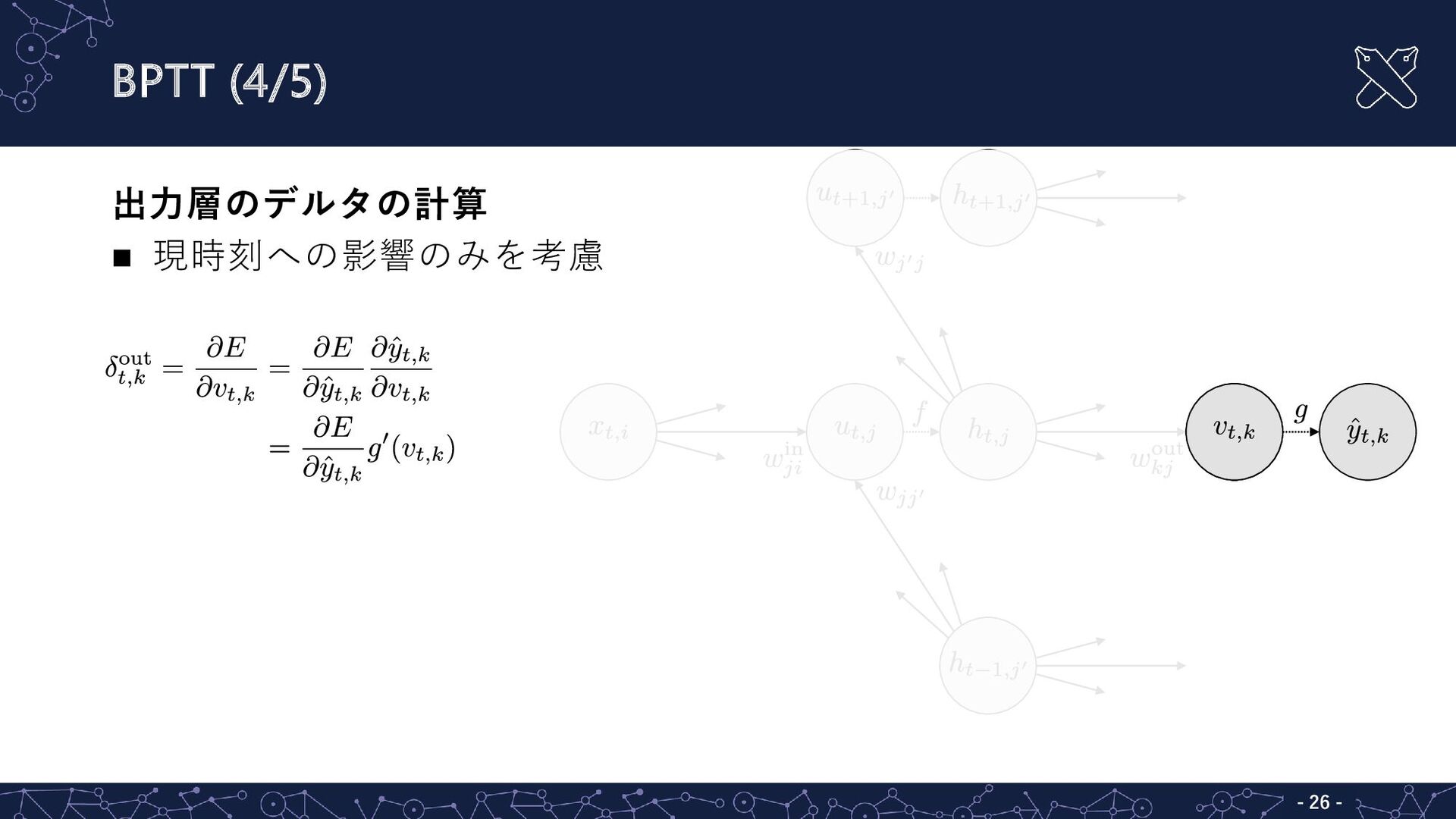
BPTT (4/5) - - 26 出力層のデルタの計算 現時刻への影響のみを考慮
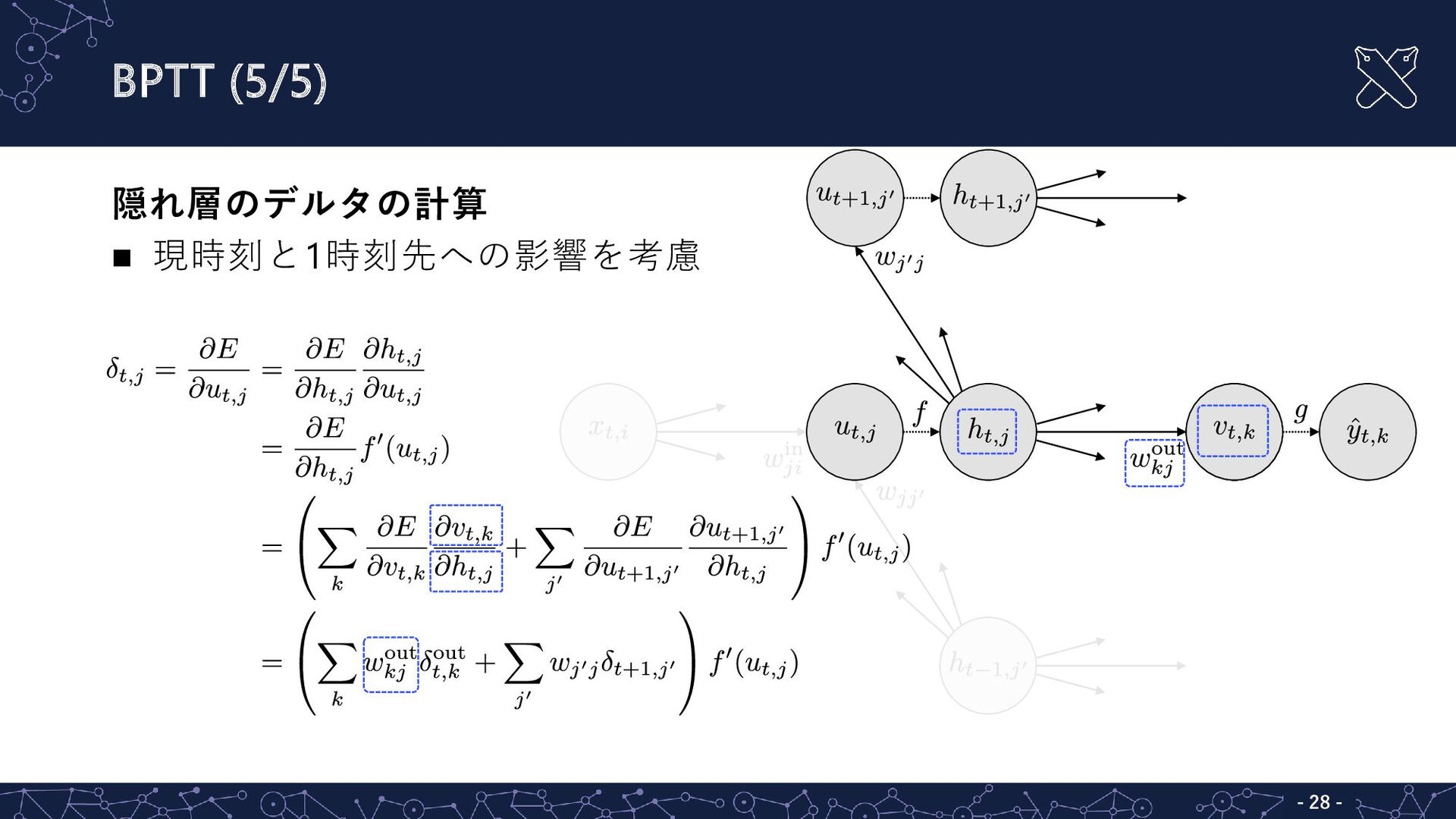
BPTT (5/5) - - 27 隠れ層のデルタの計算 現時刻と1時刻先への影響を考慮
BPTT (5/5) - - 28 隠れ層のデルタの計算 現時刻と1時刻先への影響を考慮
再帰型ニューラルネット(発展) - - 32
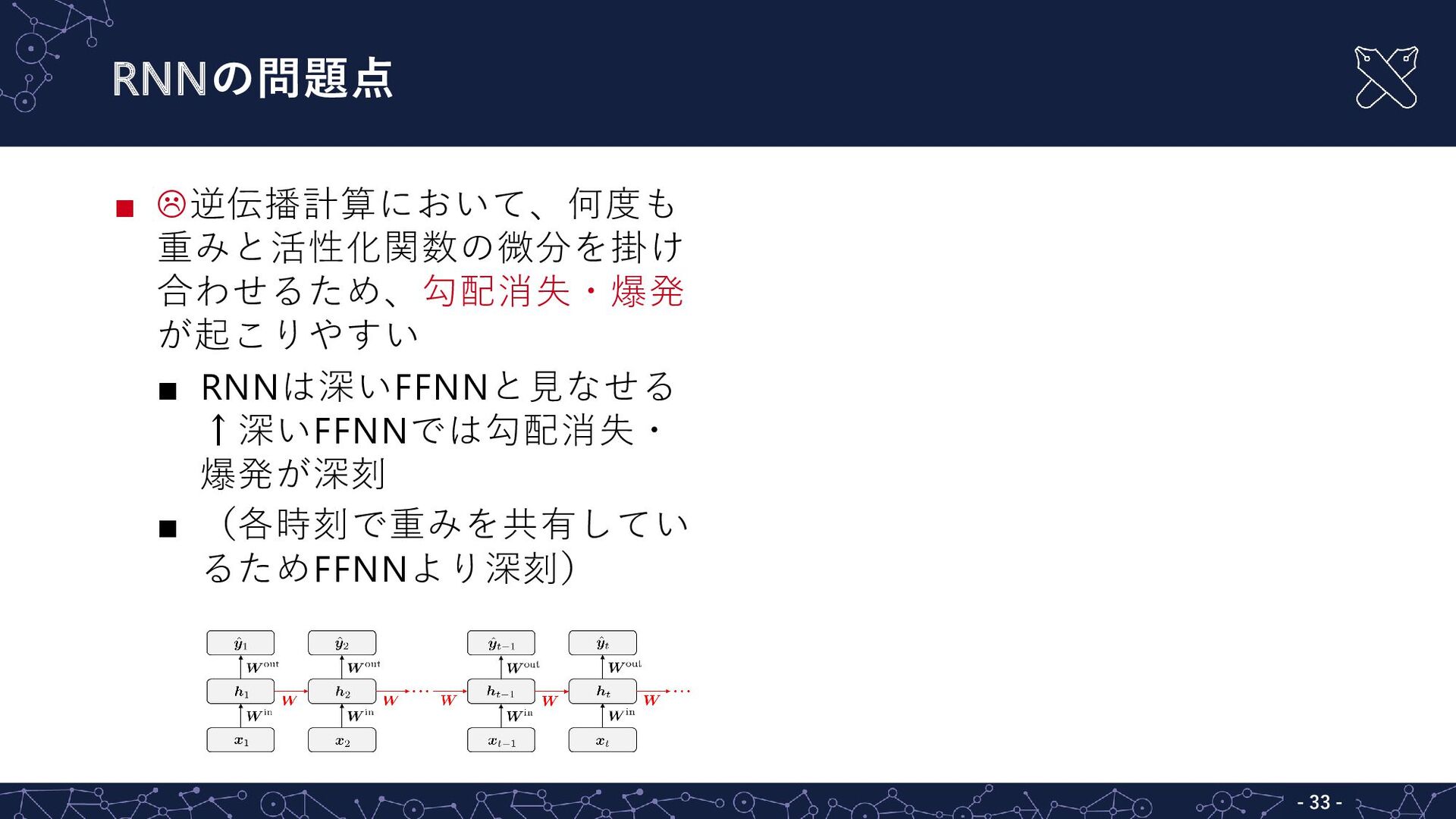
RNNの問題点 - - 33 ▪ 逆伝播計算において、何度も 重みと活性化関数の微分を掛け 合わせるため、勾配消失・爆発 が起こりやすい ▪
RNNは深いFFNNと見なせる ↑深いFFNNでは勾配消失・ 爆発が深刻 ▪ (各時刻で重みを共有してい るためFFNNより深刻)
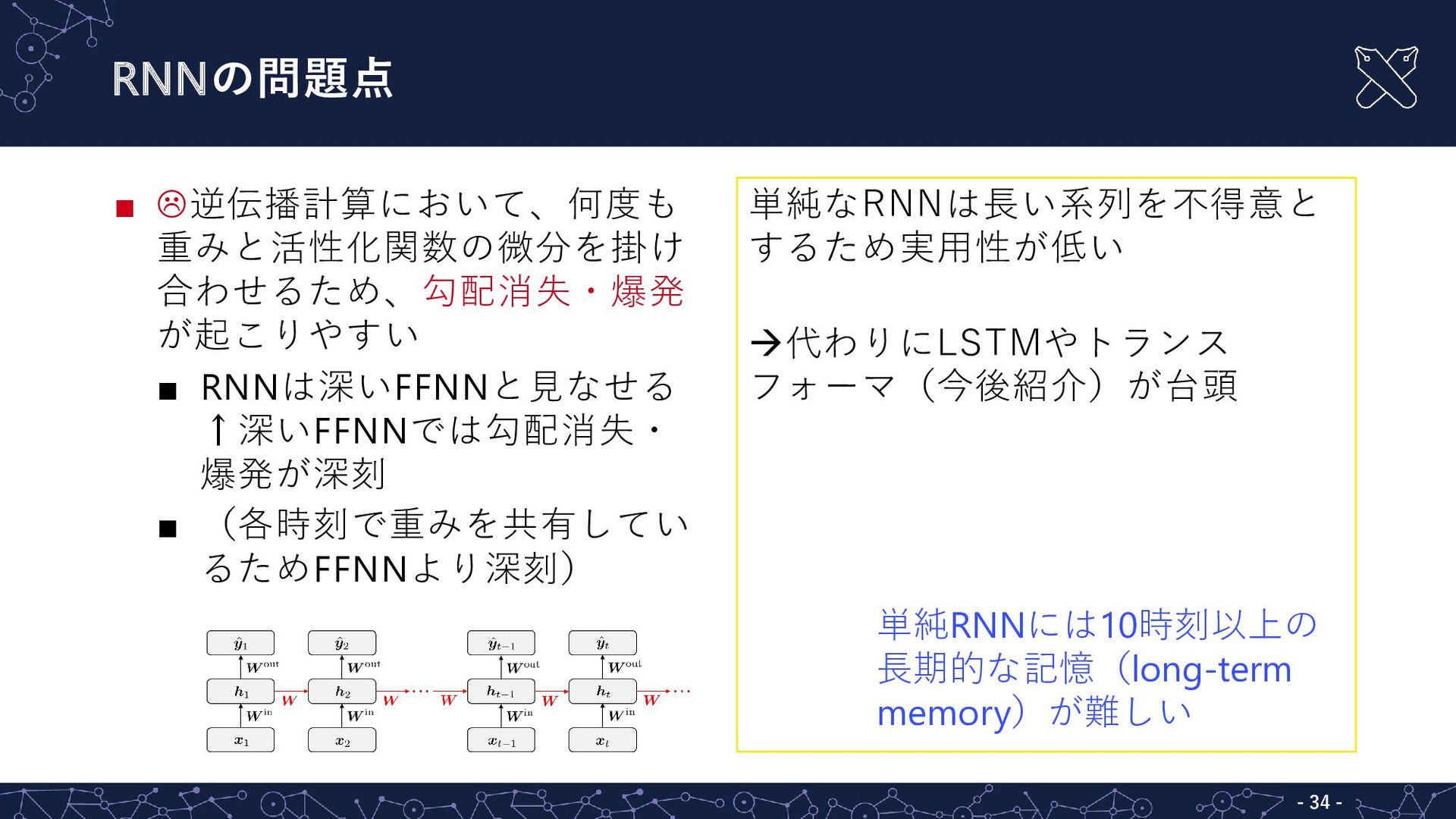
RNNの問題点 - - 34 ▪ 逆伝播計算において、何度も 重みと活性化関数の微分を掛け 合わせるため、勾配消失・爆発 が起こりやすい ▪
RNNは深いFFNNと見なせる ↑深いFFNNでは勾配消失・ 爆発が深刻 ▪ (各時刻で重みを共有してい るためFFNNより深刻) 単純なRNNは長い系列を不得意と するため実用性が低い 代わりにLSTMやトランス フォーマ(今後紹介)が台頭 単純RNNには10時刻以上の 長期的な記憶(long-term memory)が難しい
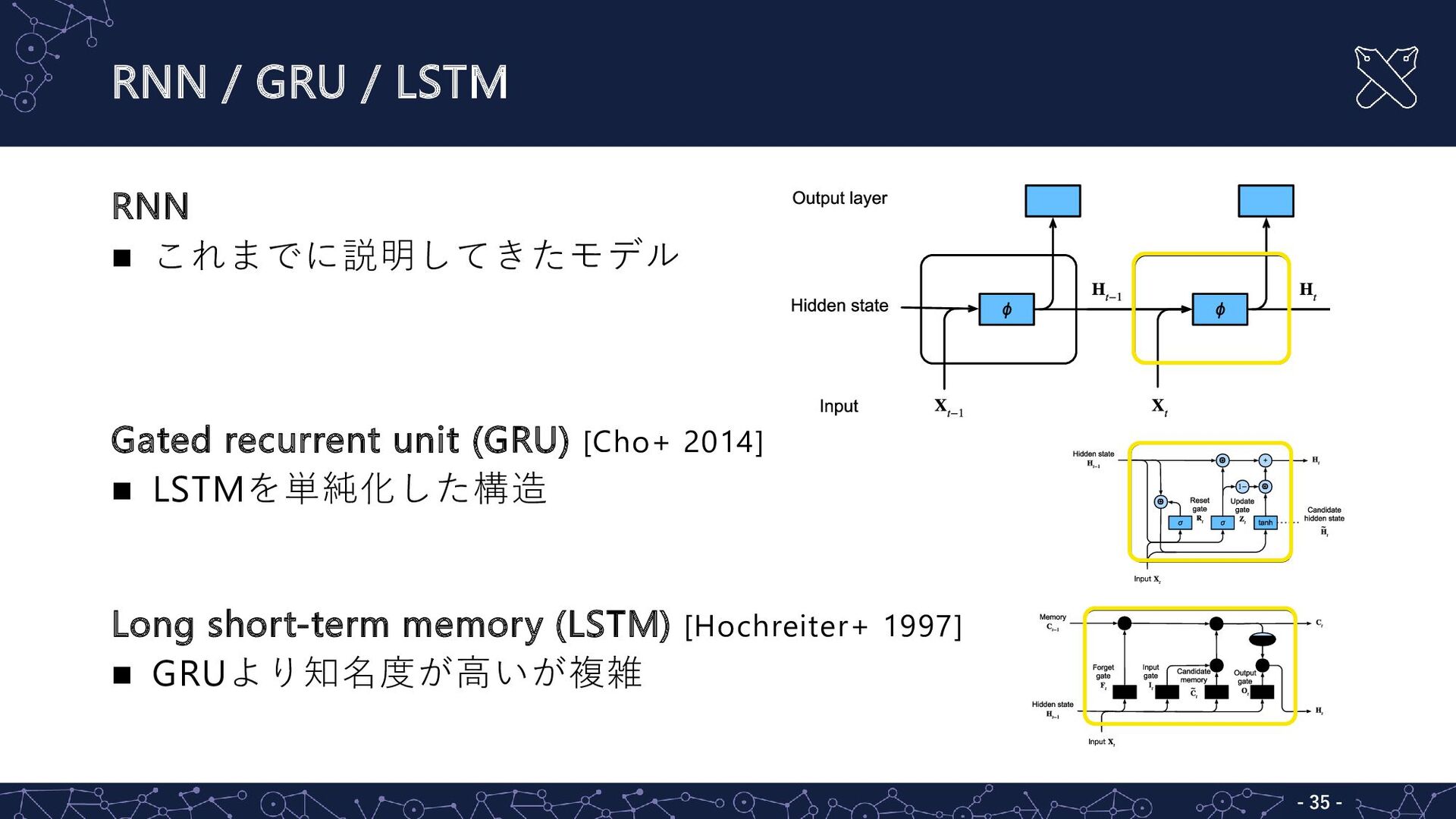
RNN / GRU / LSTM - - 35 RNN
これまでに説明してきたモデル Gated recurrent unit (GRU) [Cho+ 2014] LSTMを単純化した構造 Long short-term memory (LSTM) [Hochreiter+ 1997] GRUより知名度が高いが複雑
LSTM (long short-term memory, 長・短期記憶) [Hochreiter+ 1997] - - 36
▪ DNN時代より前に提案され、DNN時代に再注目された ▪ 短期と長期の記憶のバランスを調整可能 RNNの弱点を克服 ▪ 構造の特徴 ▪ メモリーセル:RNNの中間層のユニットの代わり ▪ ゲート機構
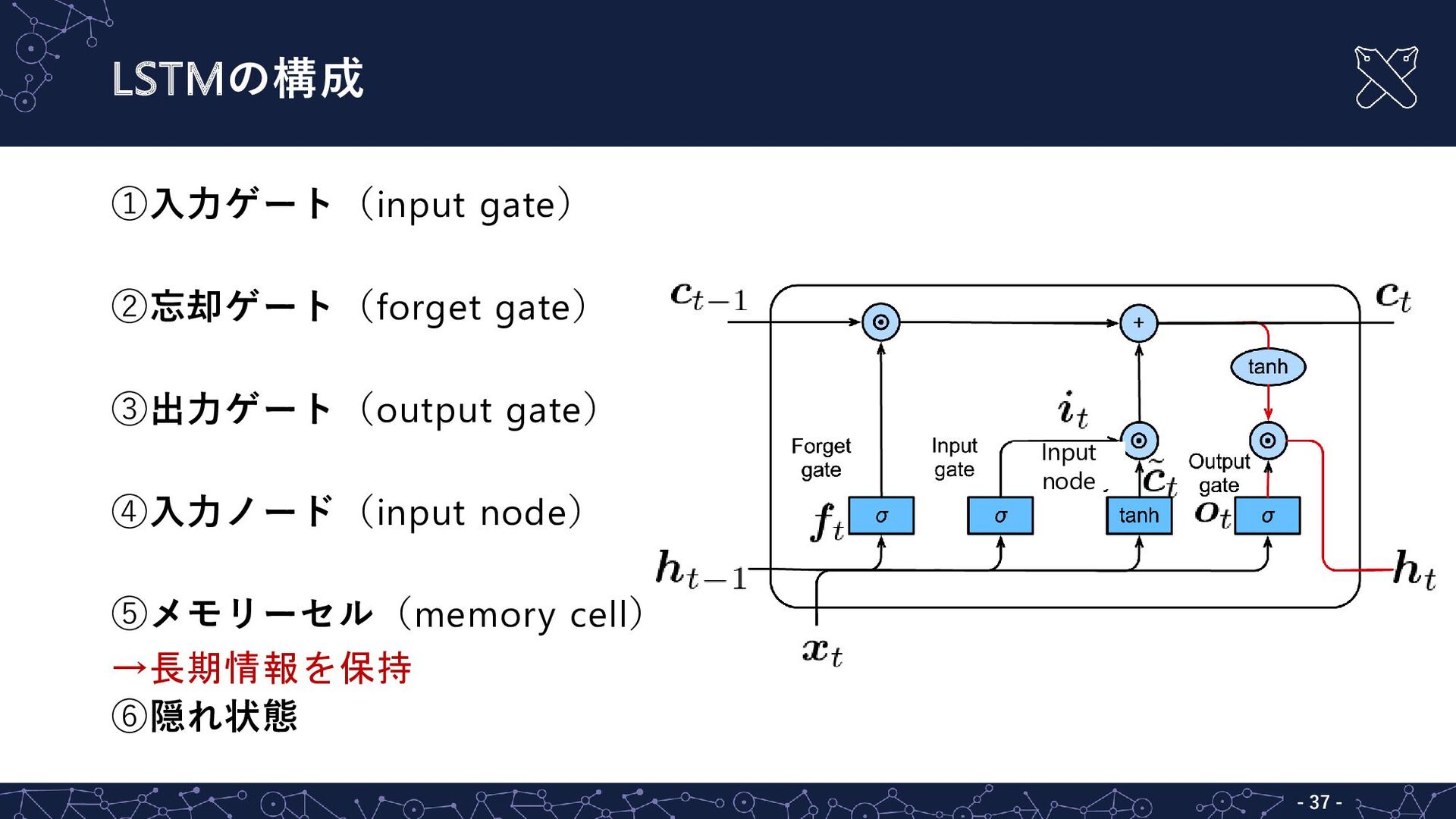
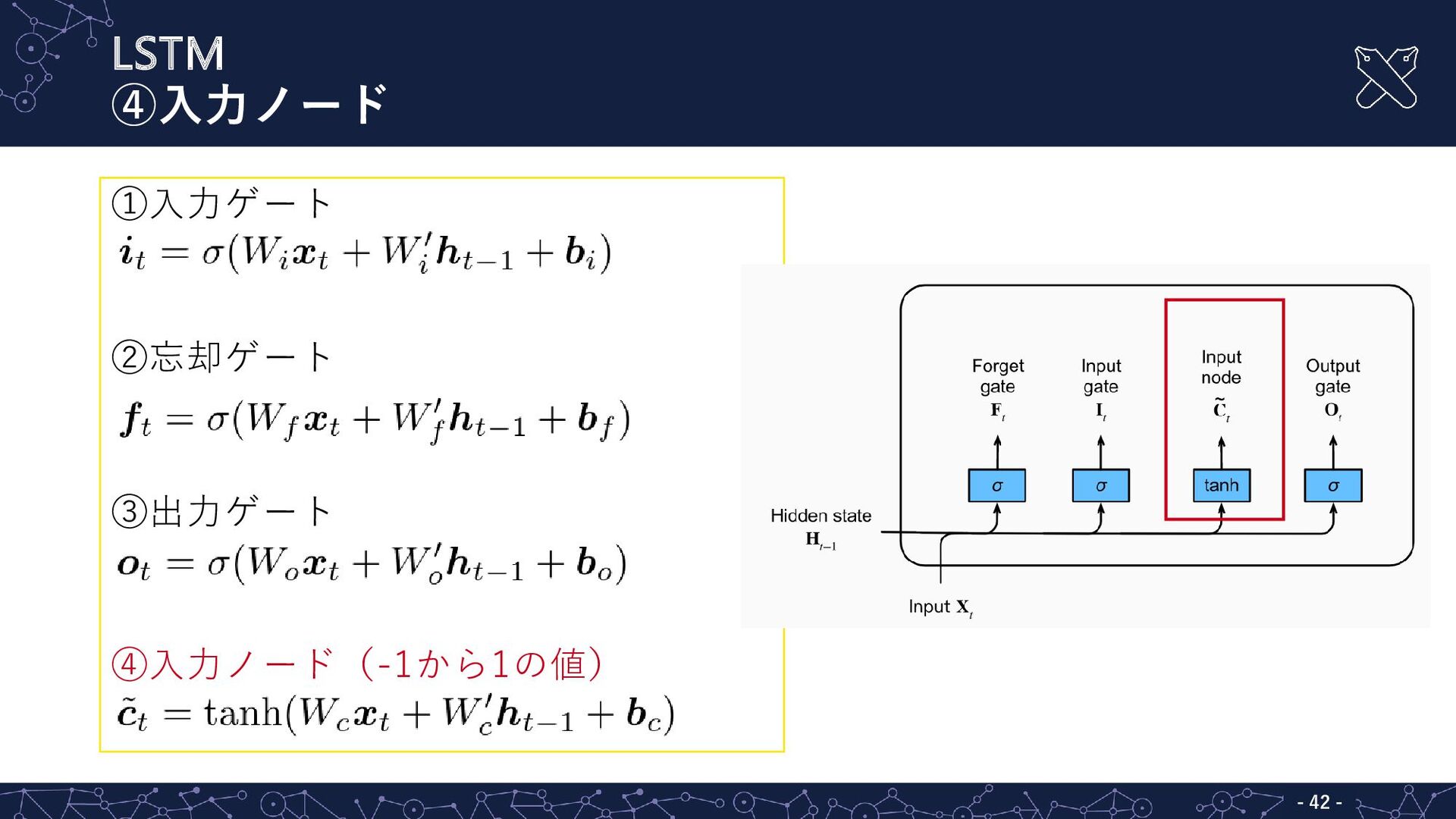
LSTMの構成 - - 37 ①入力ゲート(input gate) ②忘却ゲート(forget gate) ③出力ゲート(output gate)
④入力ノード(input node) ⑤メモリーセル(memory cell) →長期情報を保持 ⑥隠れ状態 Input node
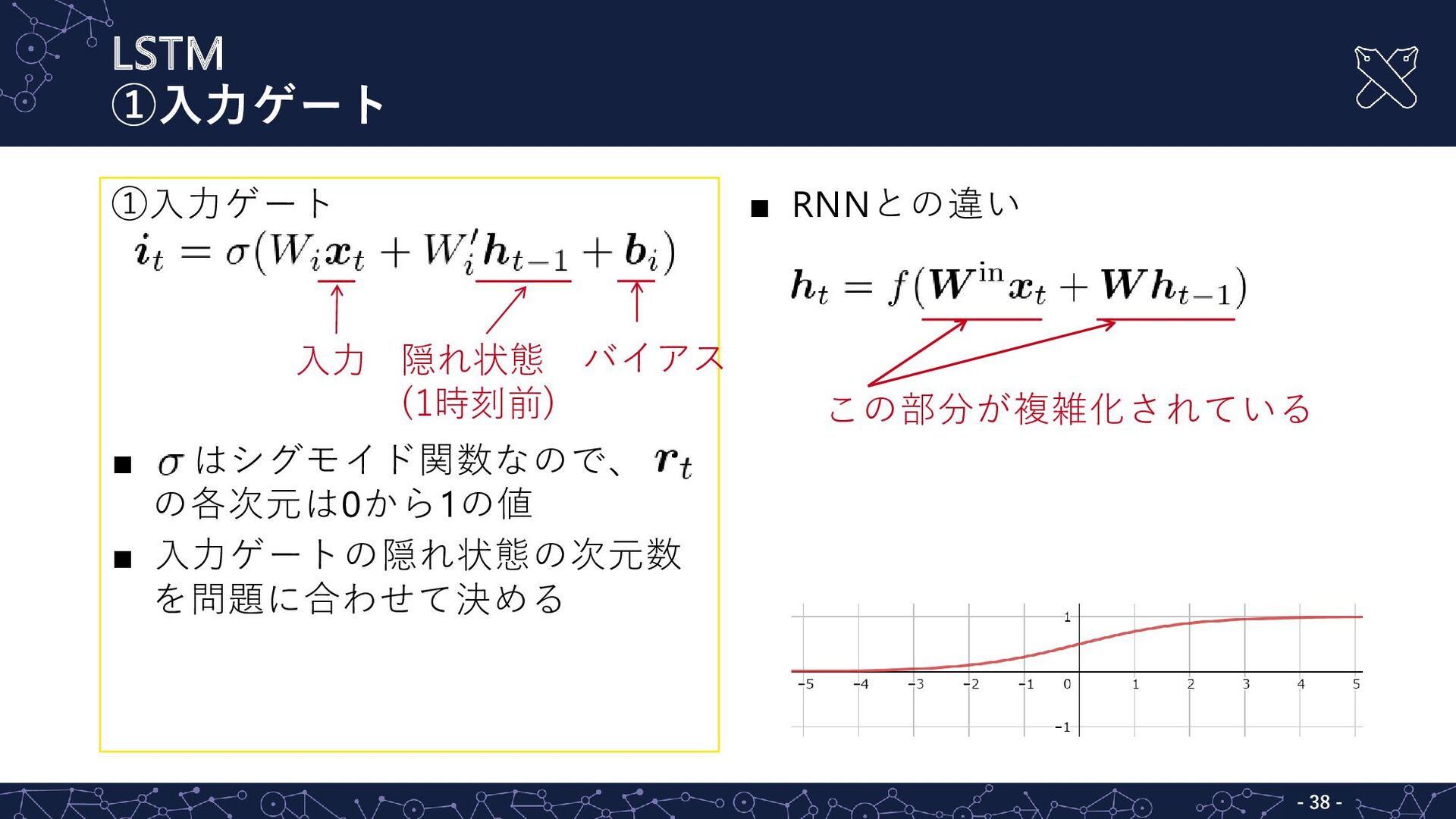
LSTM ①入力ゲート - - 38 ①入力ゲート ▪ はシグモイド関数なので、 の各次元は0から1の値 ▪
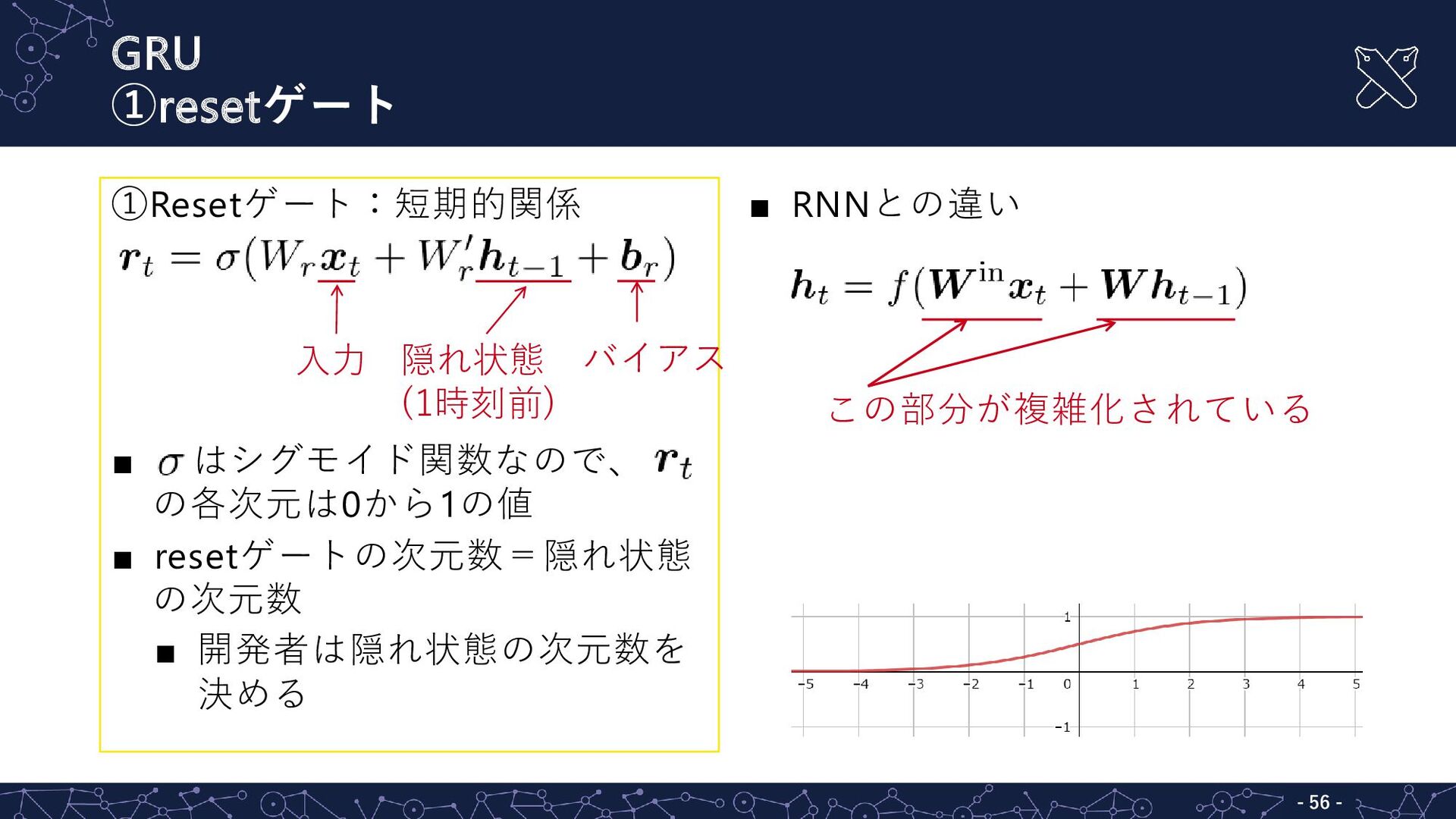
入力ゲートの隠れ状態の次元数 を問題に合わせて決める ▪ RNNとの違い この部分が複雑化されている 入力 隠れ状態 (1時刻前) バイアス
LSTM ①入力ゲート - - 39 ①入力ゲート ▪ はシグモイド関数なので、 の各次元は0から1の値 ▪
入力ゲートの隠れ状態の次元数 を問題に合わせて決める ▪ 入力ゲートは現状情報の影響を 制御(後述) ▪ 例 ▪ 入力:1次元、隠れ状態:2 次元の場合の要素表現 入力 隠れ状態 (1時刻前) バイアス
LSTM ②忘却ゲートと③出力ゲート - - 40 ①入力ゲート ②忘却ゲート ③出力ゲート ▪ 数式上は②③と①は似ている
▪ 例 ▪ 入力:1次元、隠れ状態:2 次元の場合の要素表現 忘却ゲートは、過去情報をどれだけ キープするかに影響
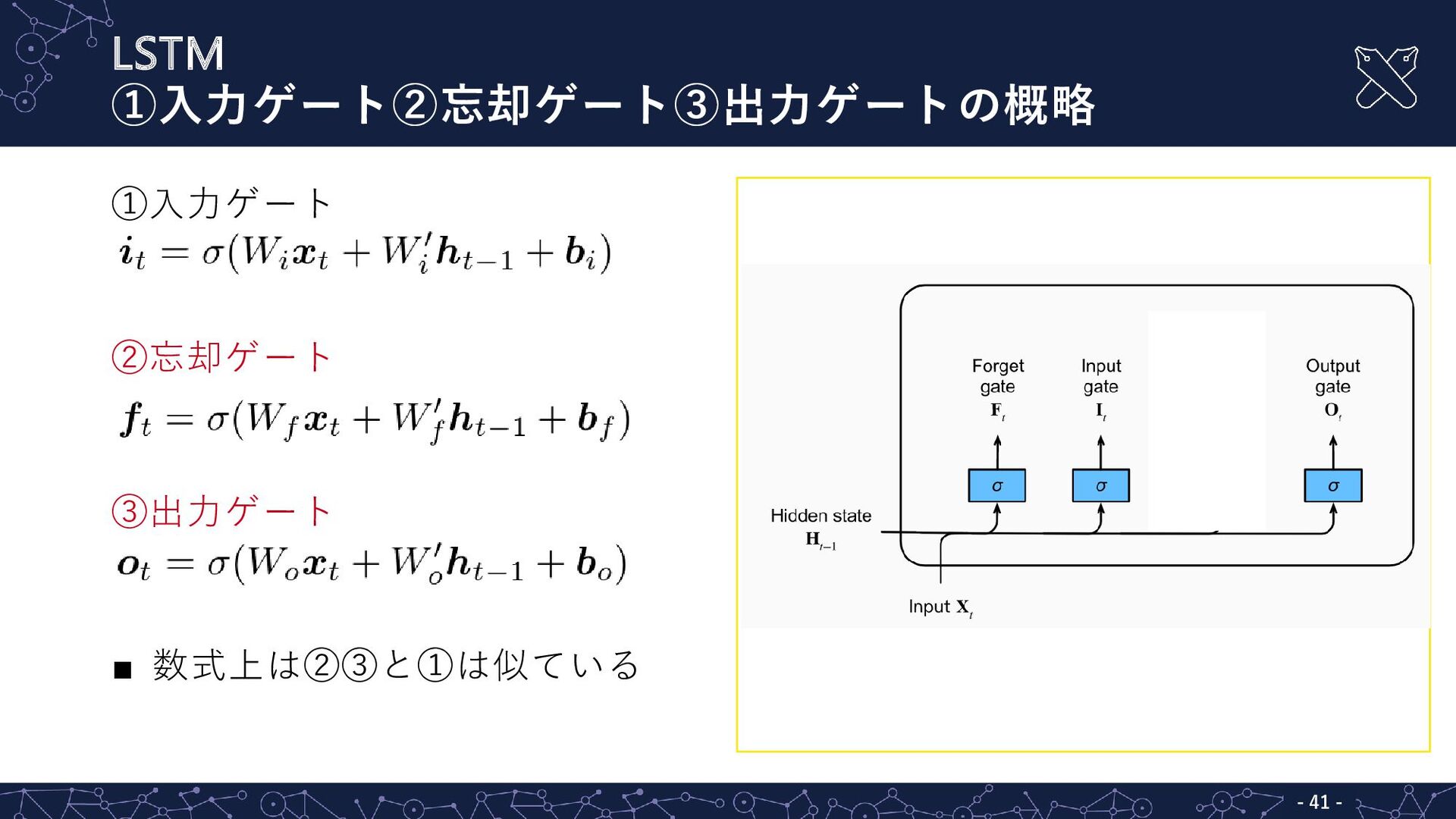
LSTM ①入力ゲート②忘却ゲート③出力ゲートの概略 - - 41 ①入力ゲート ②忘却ゲート ③出力ゲート ▪ 数式上は②③と①は似ている
LSTM ④入力ノード - - 42 ①入力ゲート ②忘却ゲート ③出力ゲート ④入力ノード(-1から1の値)
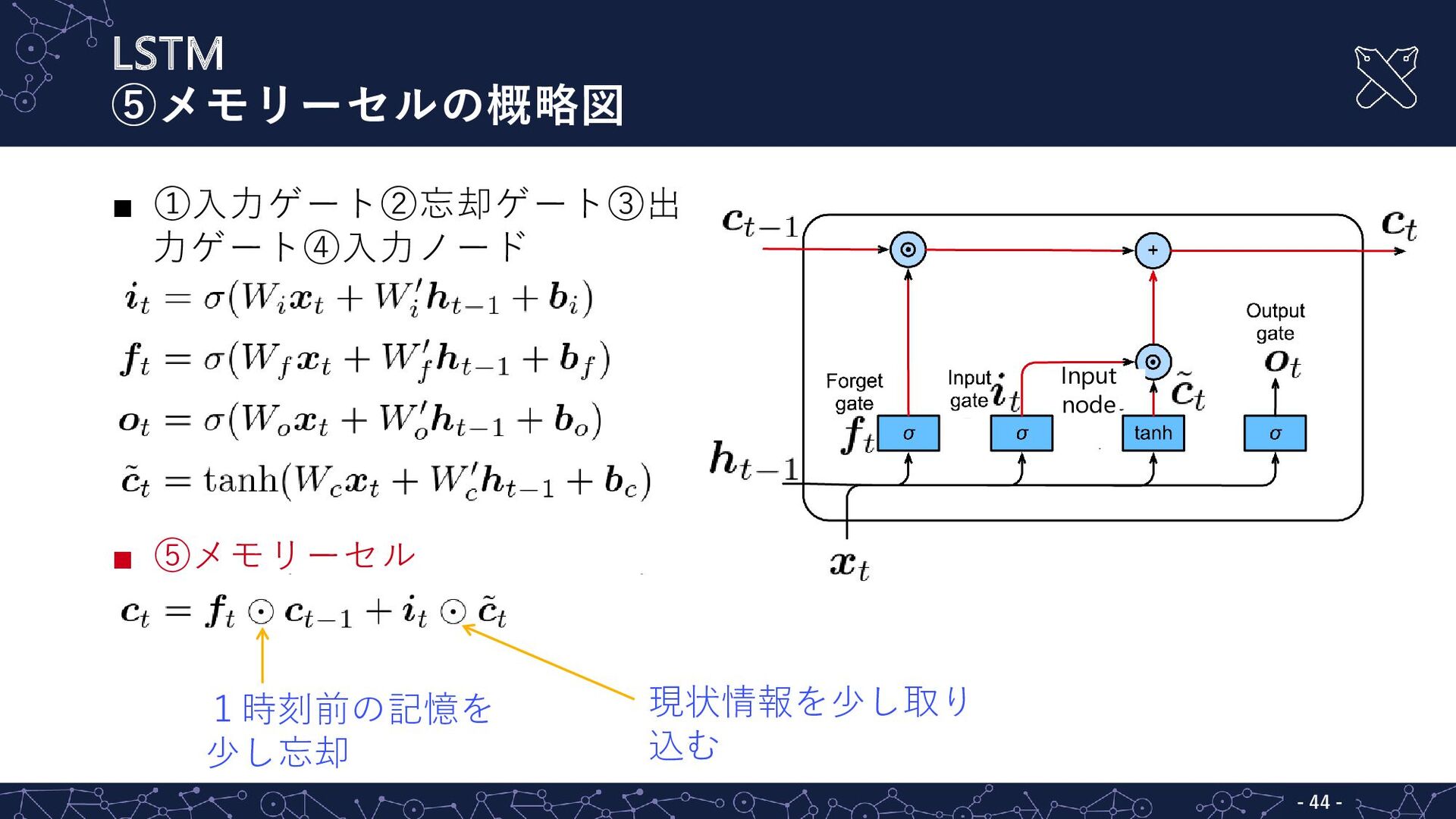
LSTM ⑤メモリーセル - - 43 ▪ ①入力ゲート②忘却ゲート③出 力ゲート④入力ノード ▪ ⑤メモリーセル
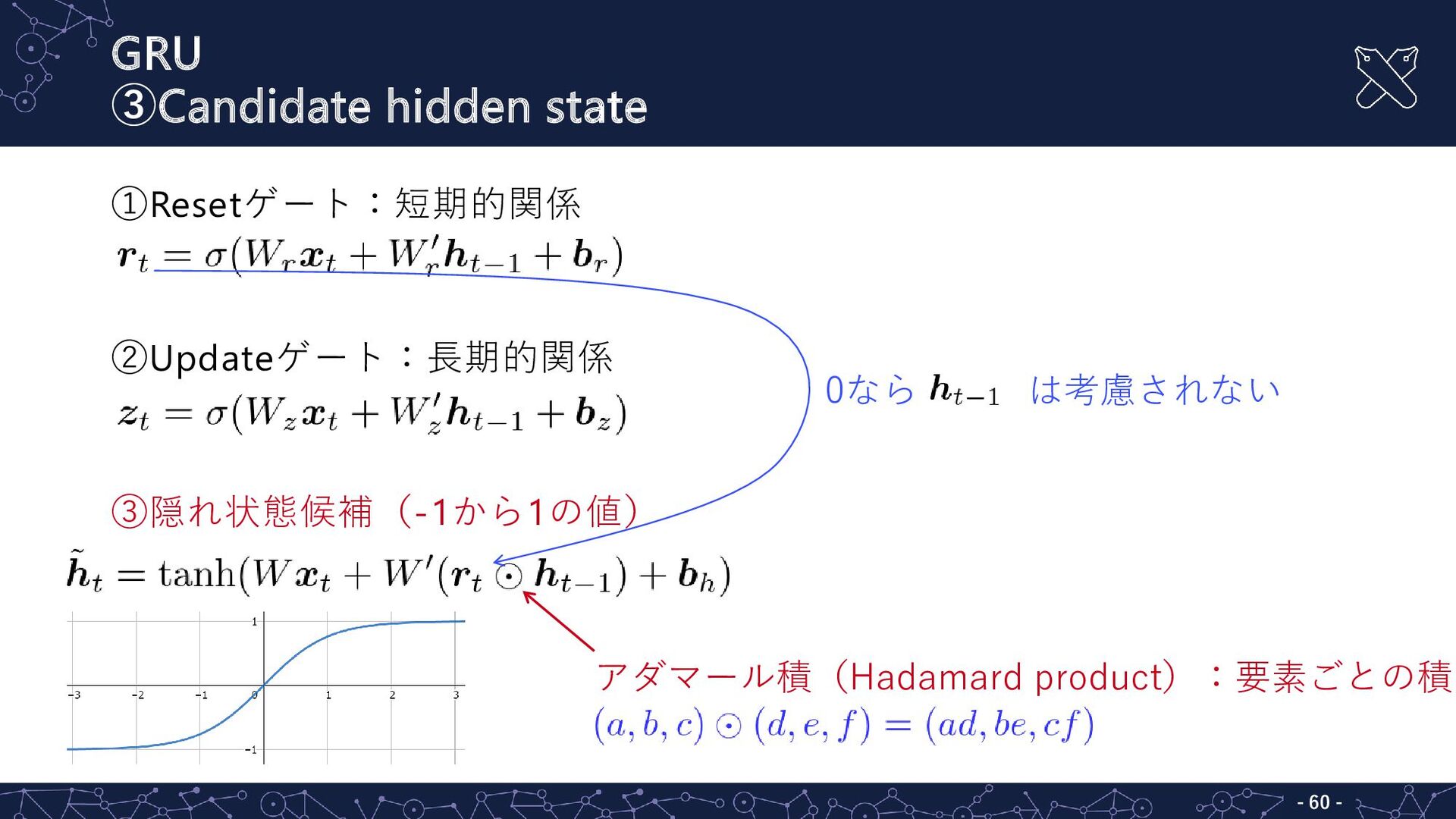
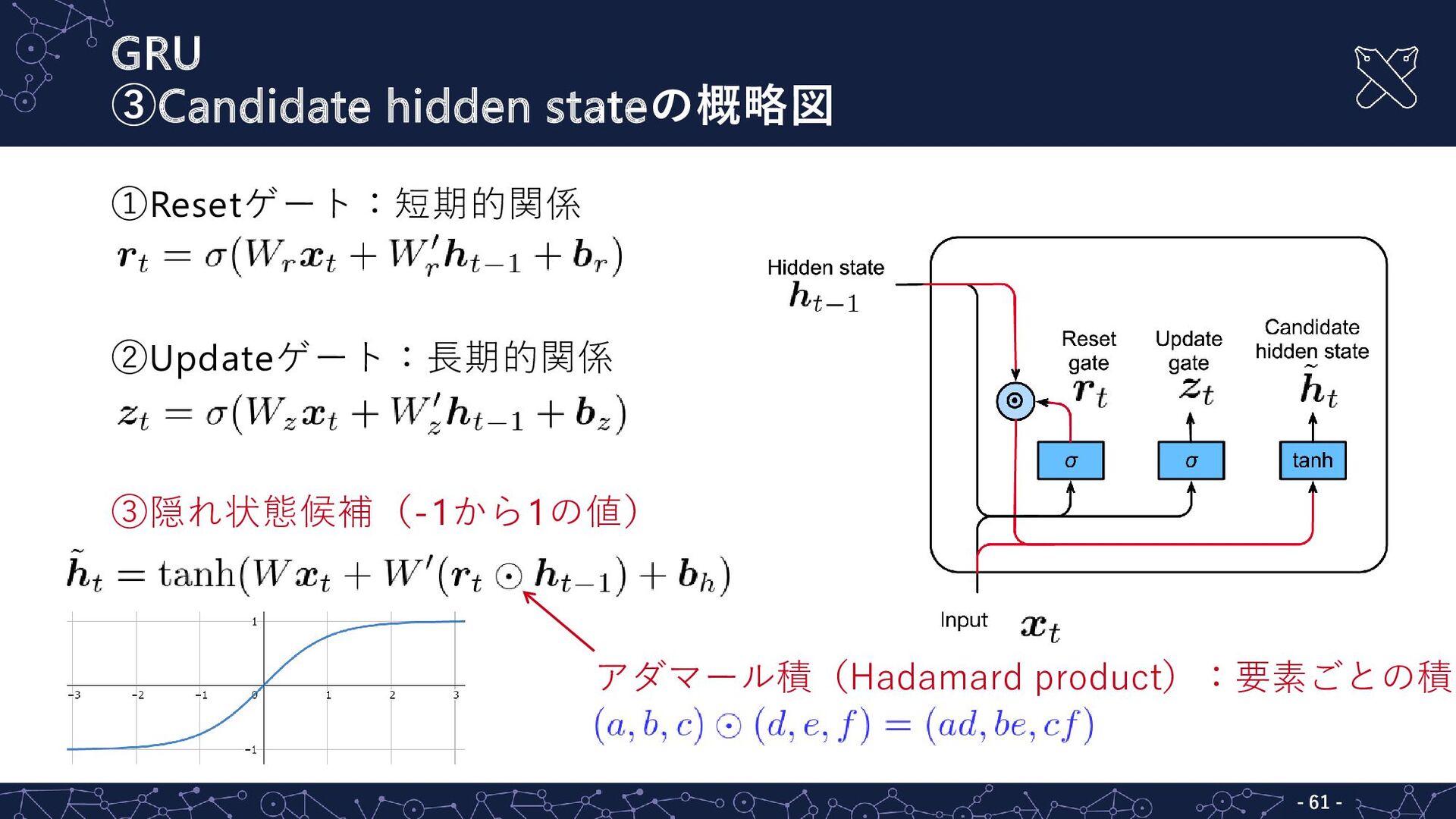
アダマール積(Hadamard product):要素ごとの積
LSTM ⑤メモリーセルの概略図 - - 44 ▪ ①入力ゲート②忘却ゲート③出 力ゲート④入力ノード ▪ ⑤メモリーセル
1時刻前の記憶を 少し忘却 現状情報を少し取り 込む Input node
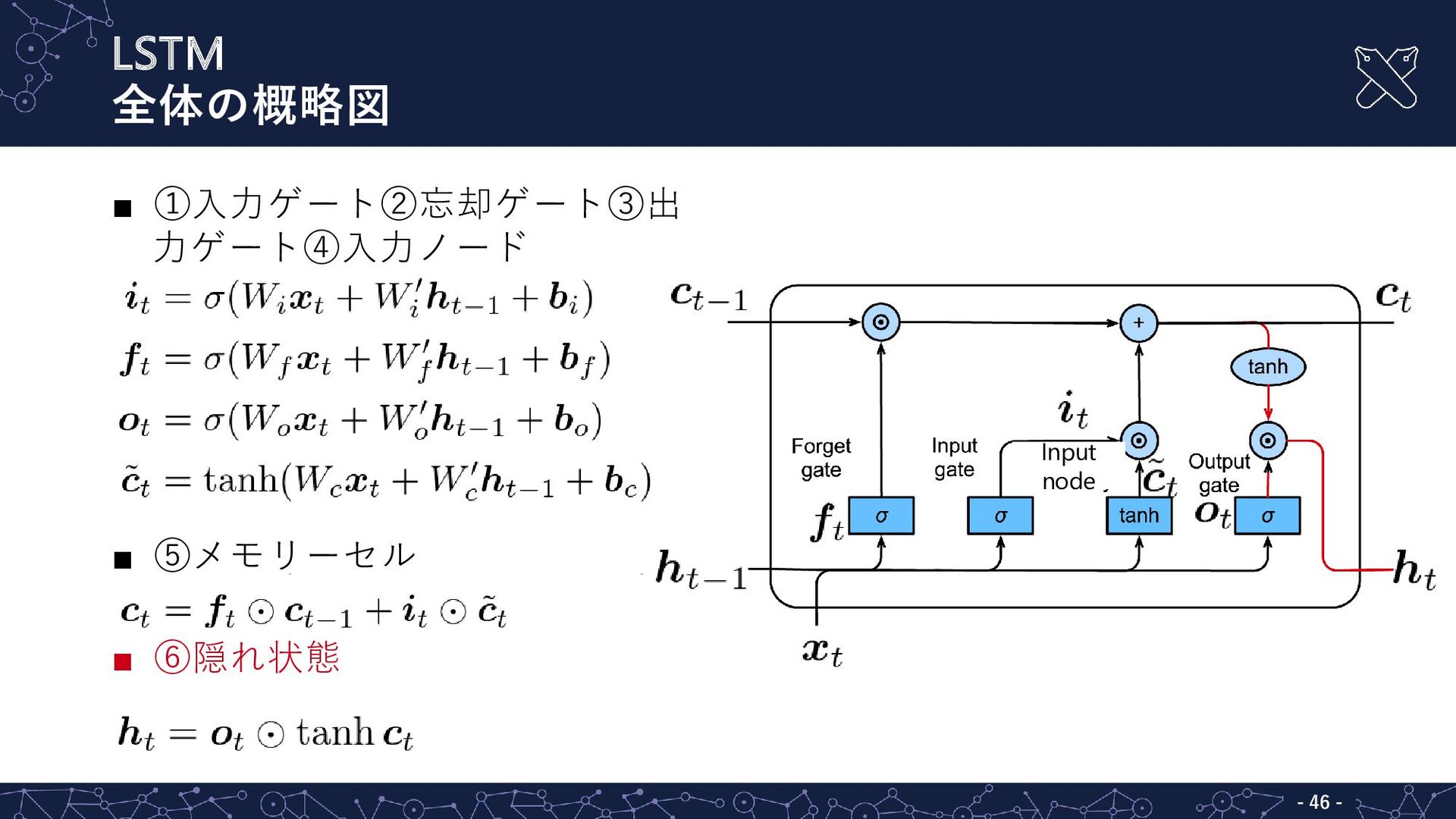
LSTM ⑥隠れ状態 - - 45 ▪ ①入力ゲート②忘却ゲート③出 力ゲート④入力ノード ▪ ⑤メモリーセル
▪ ⑥隠れ状態 ▪ 隠れ状態は-1から1の値 ▪ 出力ゲートは0から1 ▪ tanhは-1から1
LSTM 全体の概略図 - - 46 ▪ ①入力ゲート②忘却ゲート③出 力ゲート④入力ノード ▪ ⑤メモリーセル
▪ ⑥隠れ状態 Input node
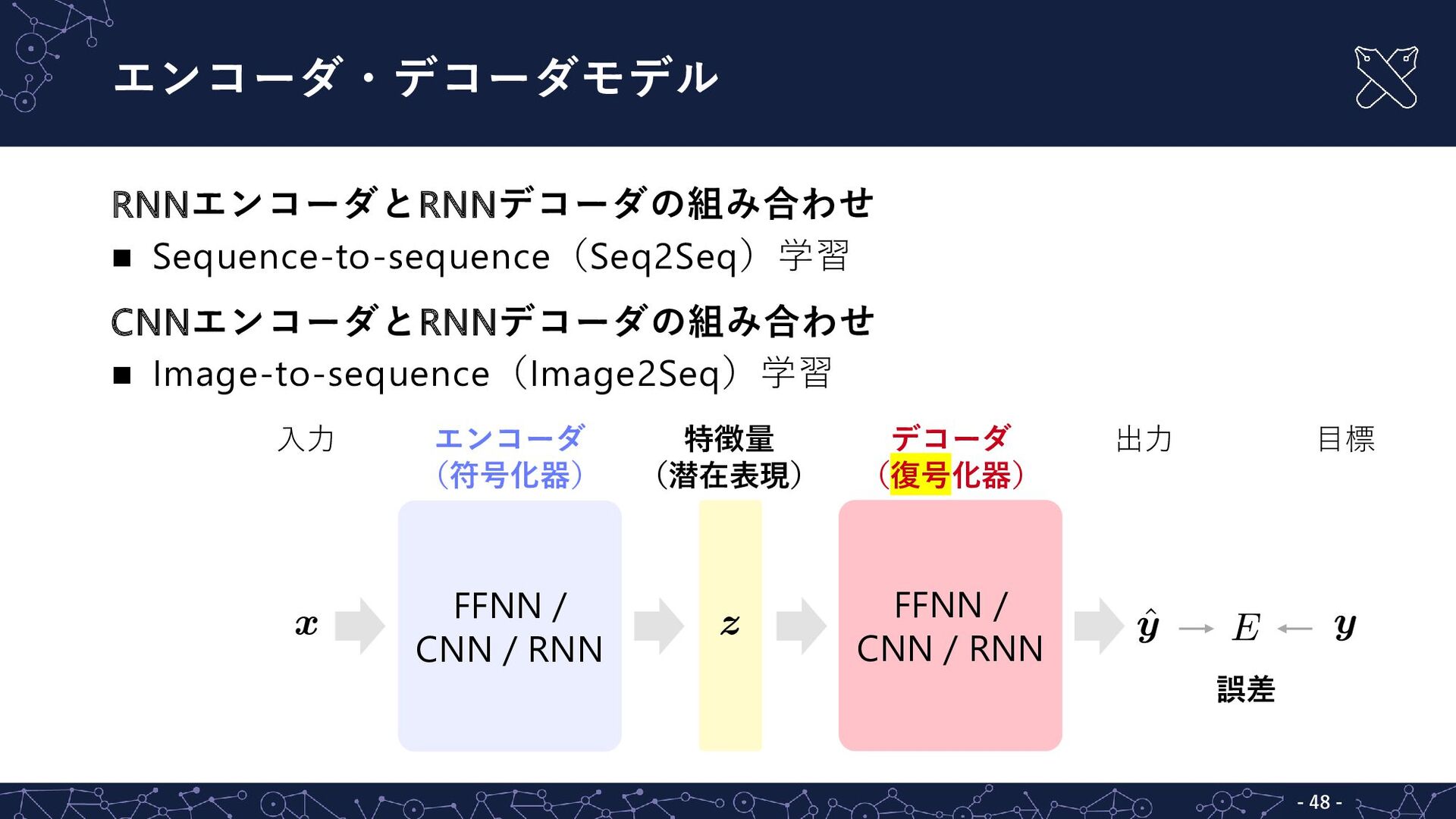
エンコーダ・デコーダモデル 異なるデータへの変換を学習 End-to-end 学習 入力 (変換元)を符号化することで特徴量(潜在表現) を抽出
特徴量 を復号化することで出力 (変換先)を生成 - - 47 入力 出力 FFNN / CNN / RNN FFNN / CNN / RNN 目標 誤差 エンコーダ (符号化器) デコーダ (復号化器) 特徴量 (潜在表現)
エンコーダ・デコーダモデル RNNエンコーダとRNNデコーダの組み合わせ Sequence-to-sequence(Seq2Seq)学習 CNNエンコーダとRNNデコーダの組み合わせ Image-to-sequence(Image2Seq)学習 - - 48
入力 出力 FFNN / CNN / RNN FFNN / CNN / RNN 目標 誤差 エンコーダ (符号化器) デコーダ (復号化器) 特徴量 (潜在表現)
Sequence-to-sequence(Seq2Seq)学習 [Sutskever+ 2014] - - 49 応用例 翻訳 /
文書要約 / 対話 / 質問応答 仕組み RNNエンコーダで翻訳元言語の文(例:英語)を読み込む RNNエンコーダの隠れ層の最終状態をRNNデコーダに入れる RNNデコーダで翻訳先言語の 文(例:フランス語)を 生成する
本講義全体の参考図書 - - 50 ▪ ★機械学習スタートアップシリーズ これならわかる深層学習入門 瀧雅人著 講談 社(本講義では、異なる表記を用いることがあるので注意)
▪ ★Dive into Deep Learning (https://d2l.ai/) ▪ 深層学習 改訂第2版 (機械学習プロフェッショナルシリーズ) 岡谷貴之著 講談社 ▪ ディープラーニングを支える技術 岡野原大輔著 技術評論社 ▪ 画像認識 (機械学習プロフェッショナルシリーズ) 原田達也著 講談社 ▪ 深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ) 坪井祐太、 海野裕也、鈴木潤 著、講談社 ▪ 東京大学工学教程 情報工学 機械学習 中川 裕志著、東京大学工学教程編纂委員会 編 丸善出版 ▪ パターン認識と機械学習 上・下 C.M. ビショップ著 丸善出版
参考文献 - - 51 1. Hochreiter, S., & Schmidhuber, J.
(1997). Long short-term memory. Neural computation, 9(8), 1735-1780. 2. Cho, K., Van Merriënboer, B., Bahdanau, D., & Bengio, Y. (2014). On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259.
実習 - - 52
実習 - - 53 実習の目的 ▪ コーディングと基礎理論の関係を学ぶ 実習課題の場所 ▪ K-LMSから辿る
実習に関する質問 ▪ ChatGPTに説明させる ▪ 教科書で調べる・検索・周囲と相談(私語禁止ではありません) ▪ 上記で解消しなければ挙手→TAが対応
付録 - - 54
GRU [Cho+ 2014] - - 55 GRU(gated recurrent unit, ゲー
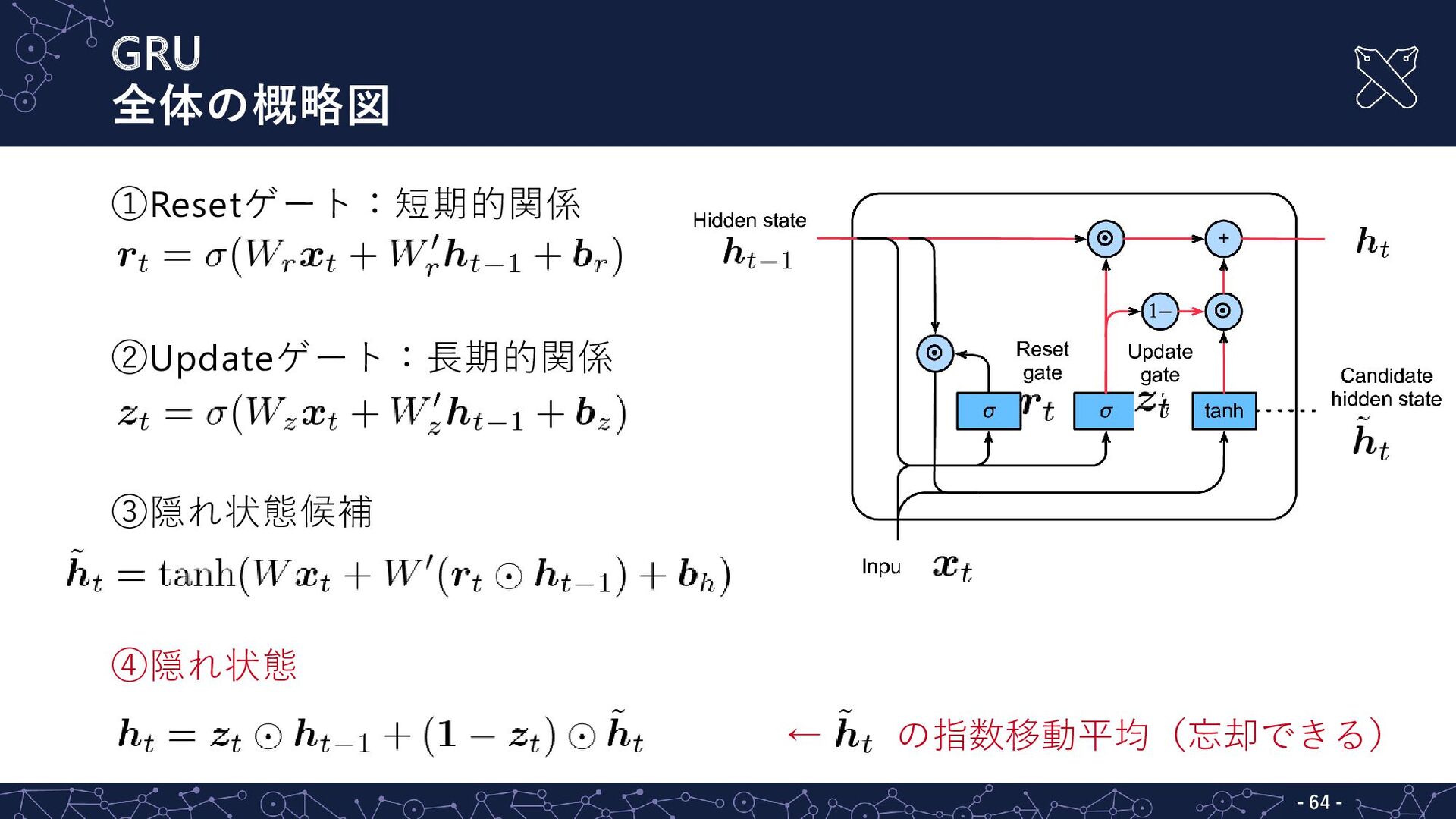
ト付き回帰型ユニット) ▪ 短期と長期の記憶のバランスを 調整可能 ▪ GRUの構成 ① Resetゲート ② Updateゲート ③ Candidate hidden state(隠れ 状態候補) ④ 隠れ状態(hidden state) ▪ RNNとの違い この部分が複雑化されている
GRU ①resetゲート - - 56 ①Resetゲート:短期的関係 ▪ はシグモイド関数なので、 の各次元は0から1の値 ▪
resetゲートの次元数=隠れ状態 の次元数 ▪ 開発者は隠れ状態の次元数を 決める ▪ RNNとの違い この部分が複雑化されている 入力 隠れ状態 (1時刻前) バイアス
GRU ①resetゲートの要素表現の例 - - 57 ①Resetゲート:短期的関係 ▪ はシグモイド関数なので、 の各次元は0から1の値 ▪
resetゲートの次元数=隠れ状態 の次元数 ▪ 開発者は隠れ状態の次元数を 決める ▪ 例 ▪ 入力:1次元、隠れ状態:2 次元の場合の要素表現 入力 隠れ状態 (1時刻前) バイアス
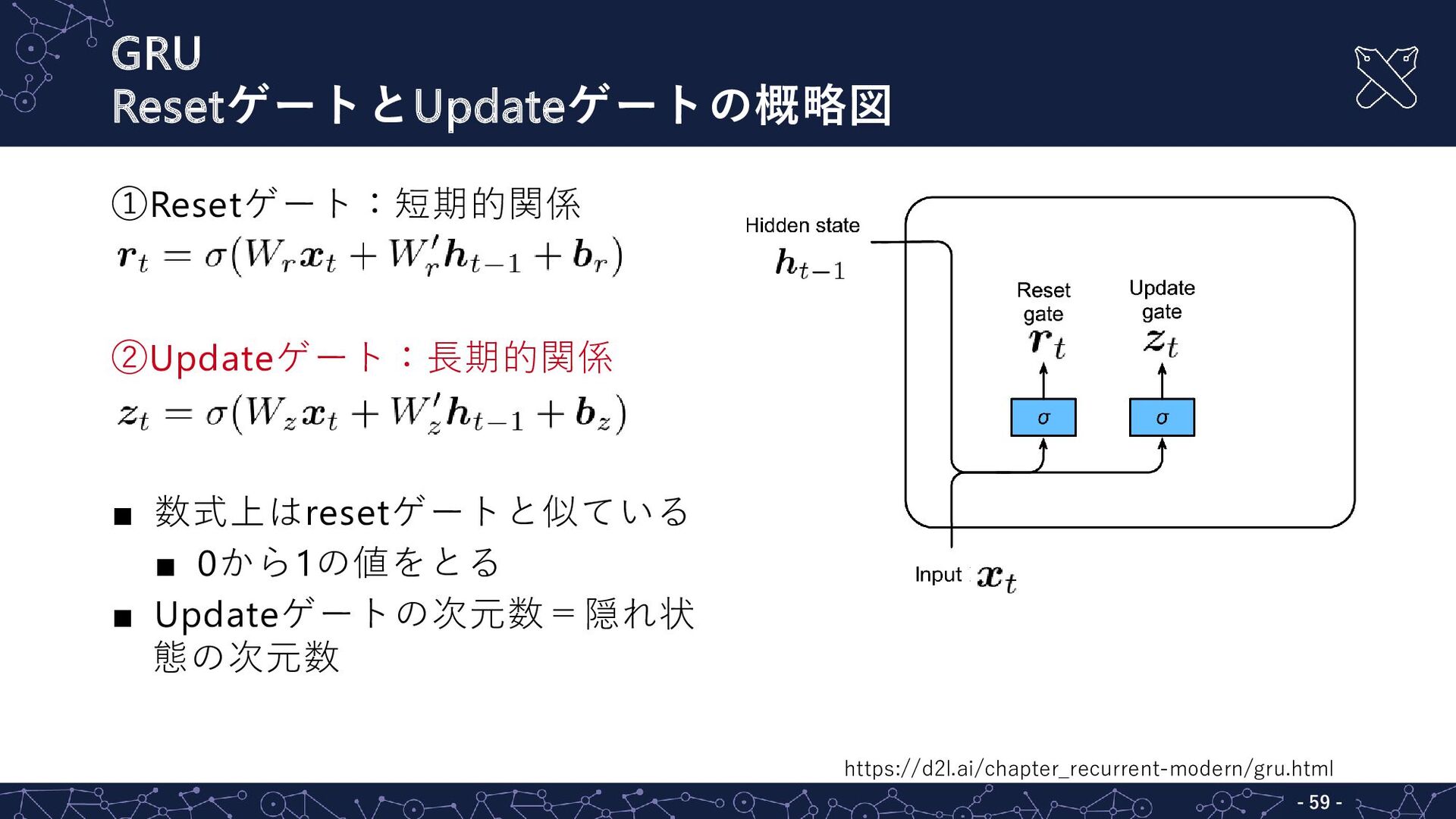
GRU ②Updateゲート - - 58 ①Resetゲート:短期的関係 ②Updateゲート:長期的関係 ▪ 数式上はresetゲートと似ている ▪
0から1の値をとる ▪ Updateゲートの次元数=隠れ状 態の次元数 ▪ 例 ▪ 入力:1次元、隠れ状態:2 次元の場合の要素表現
GRU ResetゲートとUpdateゲートの概略図 - - 59 ①Resetゲート:短期的関係 ②Updateゲート:長期的関係 ▪ 数式上はresetゲートと似ている ▪
0から1の値をとる ▪ Updateゲートの次元数=隠れ状 態の次元数 https://d2l.ai/chapter_recurrent-modern/gru.html
GRU ③Candidate hidden state - - 60 ①Resetゲート:短期的関係 ②Updateゲート:長期的関係 ③隠れ状態候補(-1から1の値)
アダマール積(Hadamard product):要素ごとの積 0なら は考慮されない
GRU ③Candidate hidden stateの概略図 - - 61 ①Resetゲート:短期的関係 ②Updateゲート:長期的関係 ③隠れ状態候補(-1から1の値)
アダマール積(Hadamard product):要素ごとの積
GRU ④隠れ状態 - - 62 ①Resetゲート:短期的関係 ②Updateゲート:長期的関係 ③隠れ状態候補 ④隠れ状態 ▪
Resetゲートとupdateゲートの バランスで隠れ状態を制御する ← の指数移動平均(忘却できる) 1なら は考慮されない
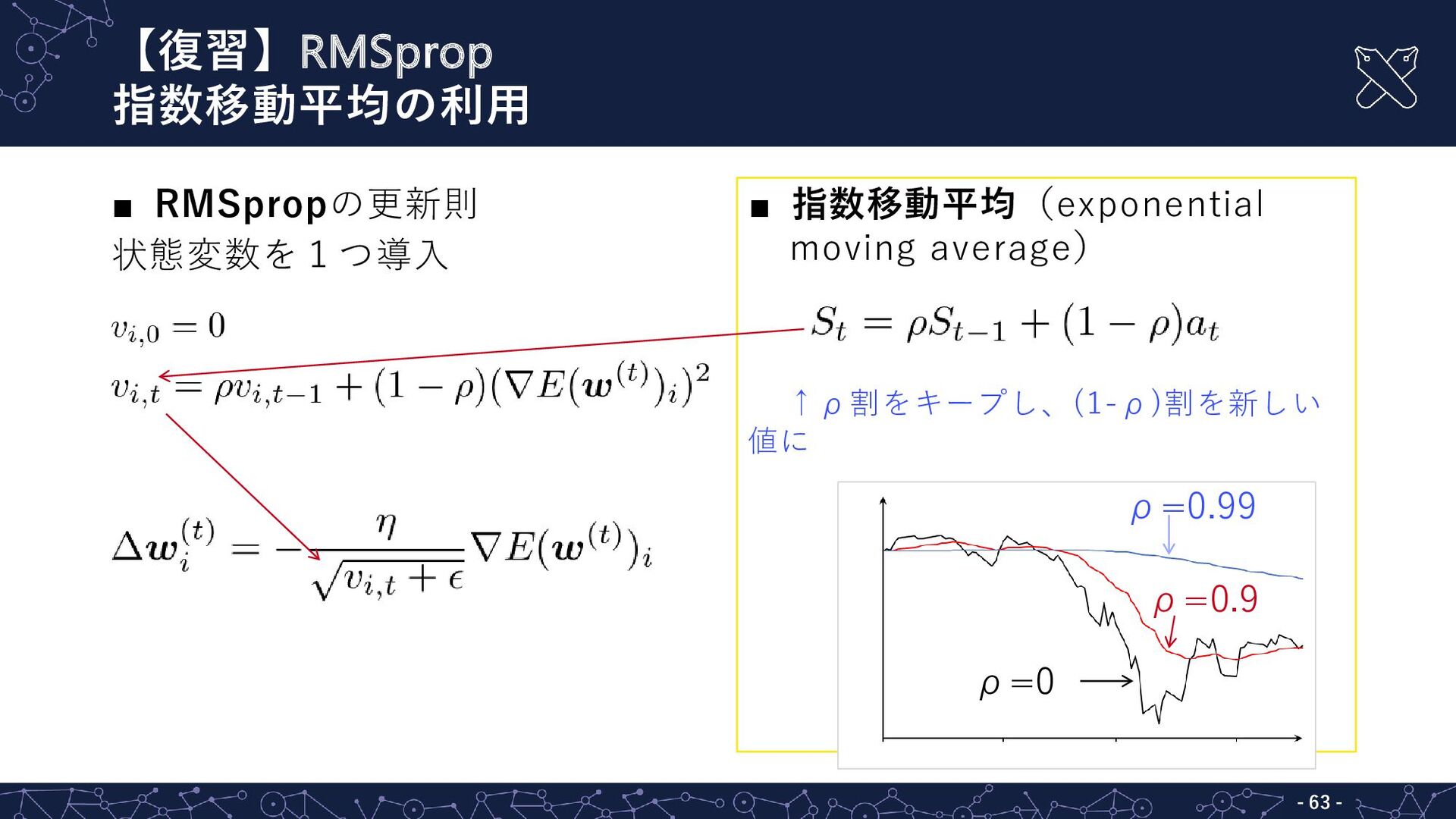
【復習】RMSprop 指数移動平均の利用 - - 63 ▪ RMSpropの更新則 状態変数を1つ導入 ▪ 指数移動平均(exponential
moving average) ↑ρ割をキープし、(1-ρ)割を新しい 値に ρ=0.99 ρ=0 ρ=0.9
GRU 全体の概略図 - - 64 ①Resetゲート:短期的関係 ②Updateゲート:長期的関係 ③隠れ状態候補 ④隠れ状態 ←
の指数移動平均(忘却できる)
単純なRNN ▪ FFNNの隠れ層(中間層)に再帰構造をもたせる ▪ 出力 は入力 の関数 ▪ 過去の情報の保持が可能 ▪
可変長の系列データを扱うことが可能 FFNN RNN - - 65
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第8回 再帰型ニューラルネット](https://files.speakerdeck.com/presentations/a7c1646b1bba4f518121a97377d56394/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![LSTM (long short-term memory, 長・短期記憶) [Hochreiter+ 1997] - - 36](https://files.speakerdeck.com/presentations/a7c1646b1bba4f518121a97377d56394/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sequence-to-sequence(Seq2Seq)学習 [Sutskever+ 2014] - - 49 応用例 翻訳 /](https://files.speakerdeck.com/presentations/a7c1646b1bba4f518121a97377d56394/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GRU [Cho+ 2014] - - 55 GRU(gated recurrent unit, ゲー](https://files.speakerdeck.com/presentations/a7c1646b1bba4f518121a97377d56394/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}