PMPを含まないデータセット:Flickr30k [Plummer+, ICCV15], MS-COCO [Lin+, ECCV14] データセットに操作を加え,PMPを作成 (PMPの割合を0.2, 0.4, 0.6, 0.8に設定) ベースライン • PMPを扱う:NCR [Huang+, NeurIPS21], DECL [Qin+, ACM MM22], RCL [Hu+, TPAMI23] など • PMPを扱わない:SGR, SAF, SGRAF [Diao+, AAAI21] など 評価指標 • Recall@k (k = 1, 5, 10) CC152k [Sharma+, ACL18]
{kind=link}
{kind=link}
{kind=link}
![関連研究:既存手法はPMPを活用できていない - 4 - 手法 概要 NCR [Huang+, NeurIPS21] 画像-テキストペアの信頼度を出力する予測関数を導入](https://files.speakerdeck.com/presentations/f636a869b7d7415786726b1ba41ae92d/slide_3.jpg){kind=link}
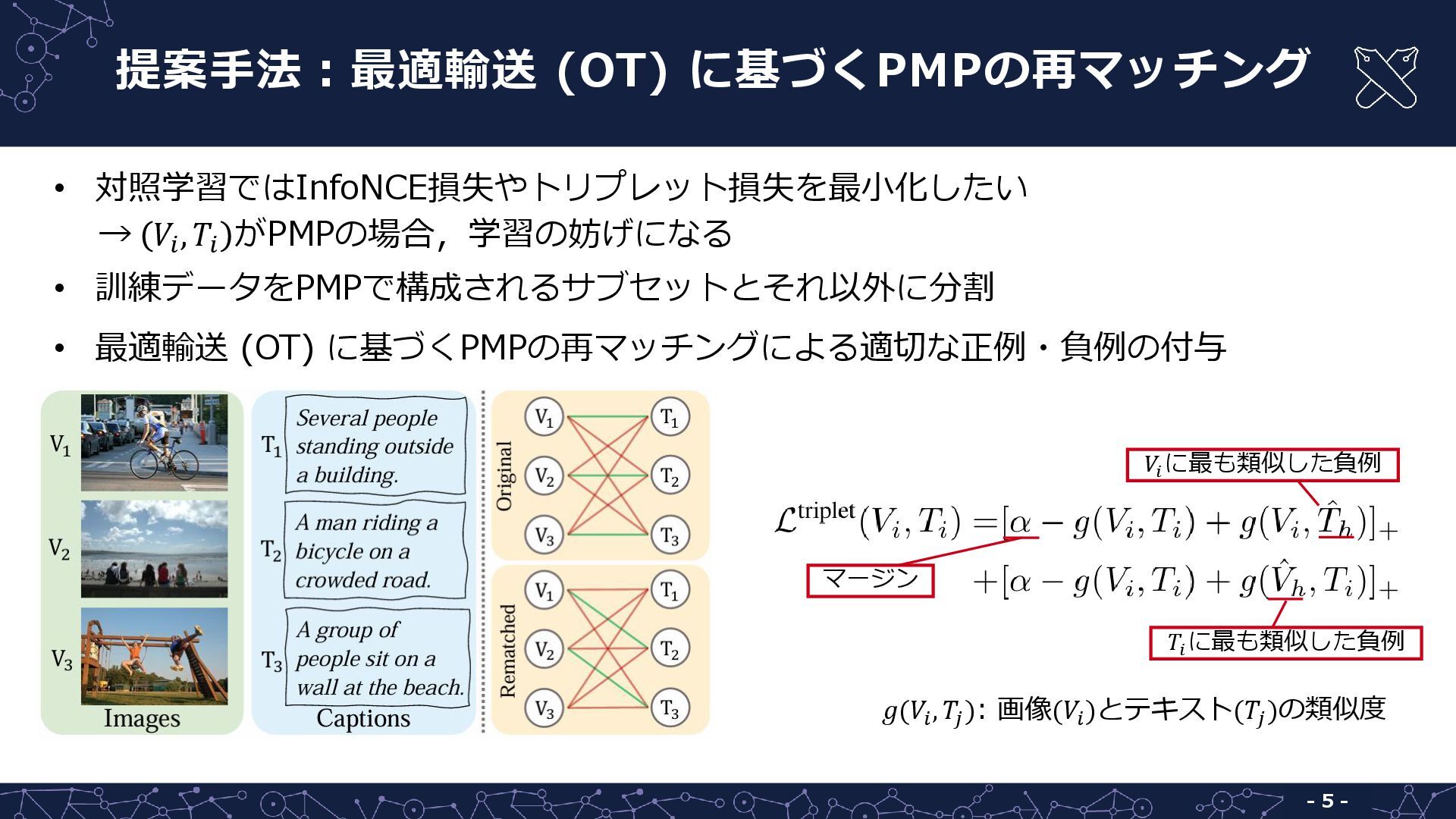{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験設定 - 11 - データセット • PMPを含むデータセット:CC152k [Sharma+, ACL18] •](https://files.speakerdeck.com/presentations/f636a869b7d7415786726b1ba41ae92d/slide_10.jpg){kind=link}
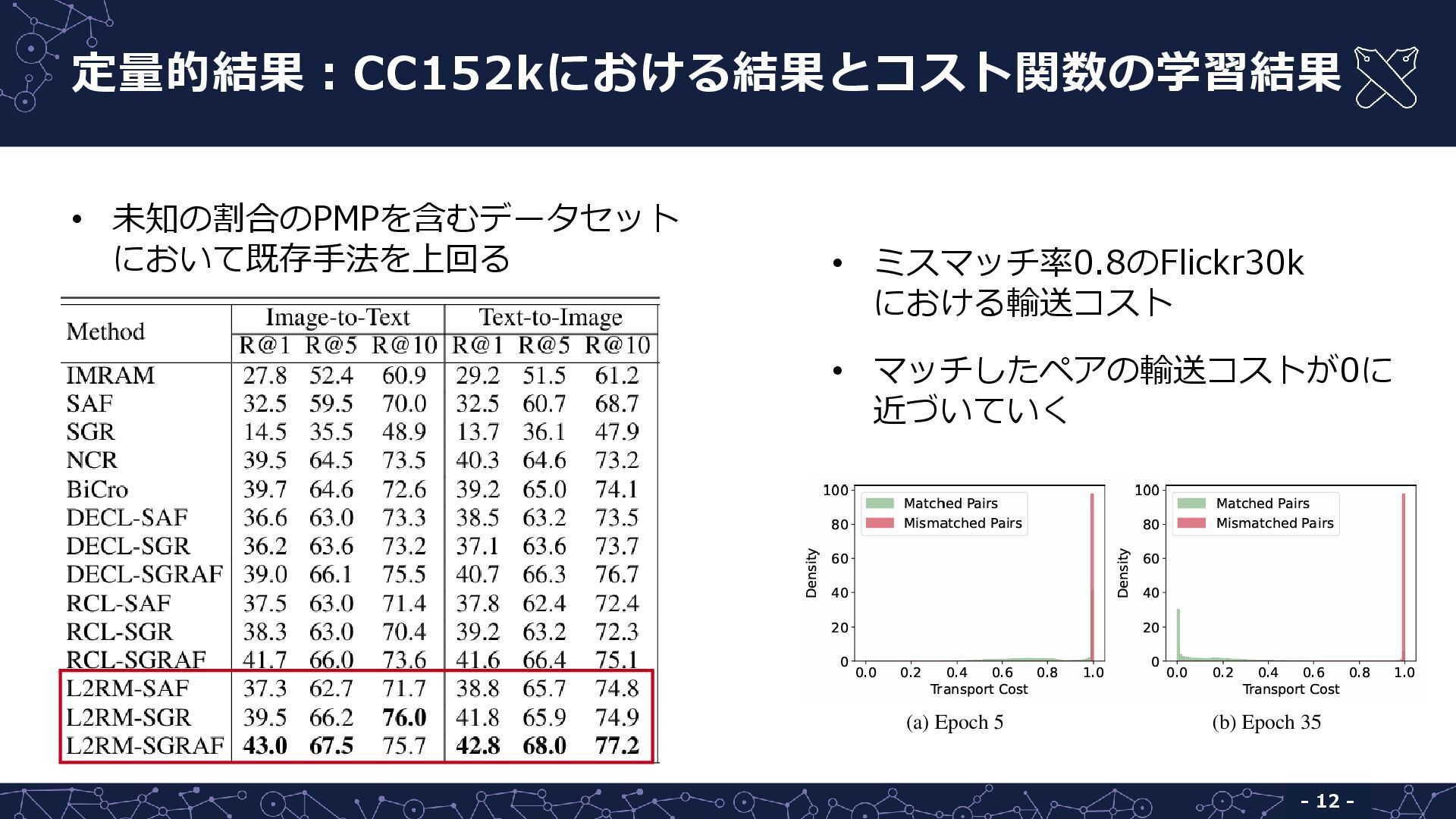{kind=link}
{kind=link}
{kind=link}
{kind=link}
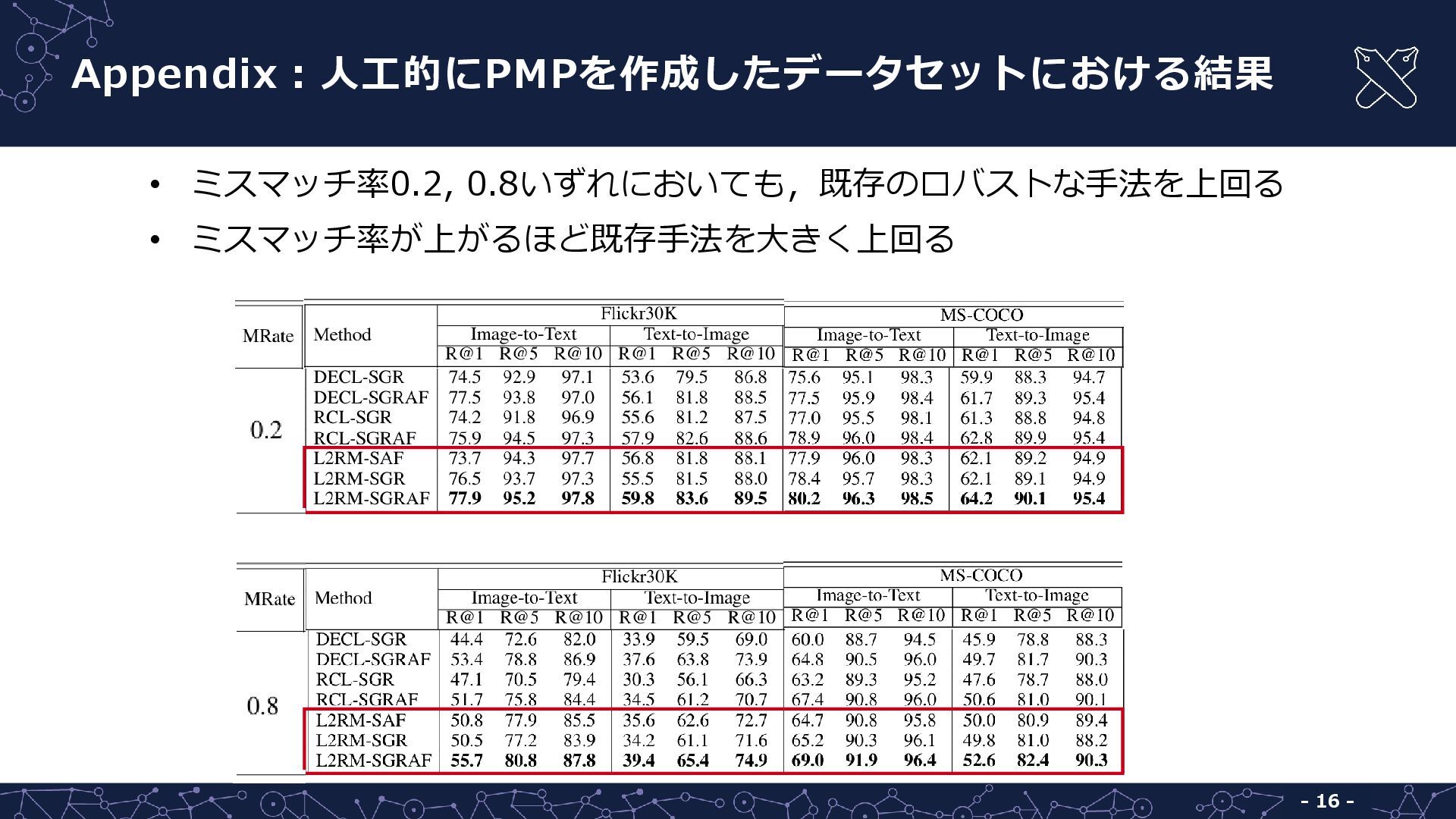{kind=link}
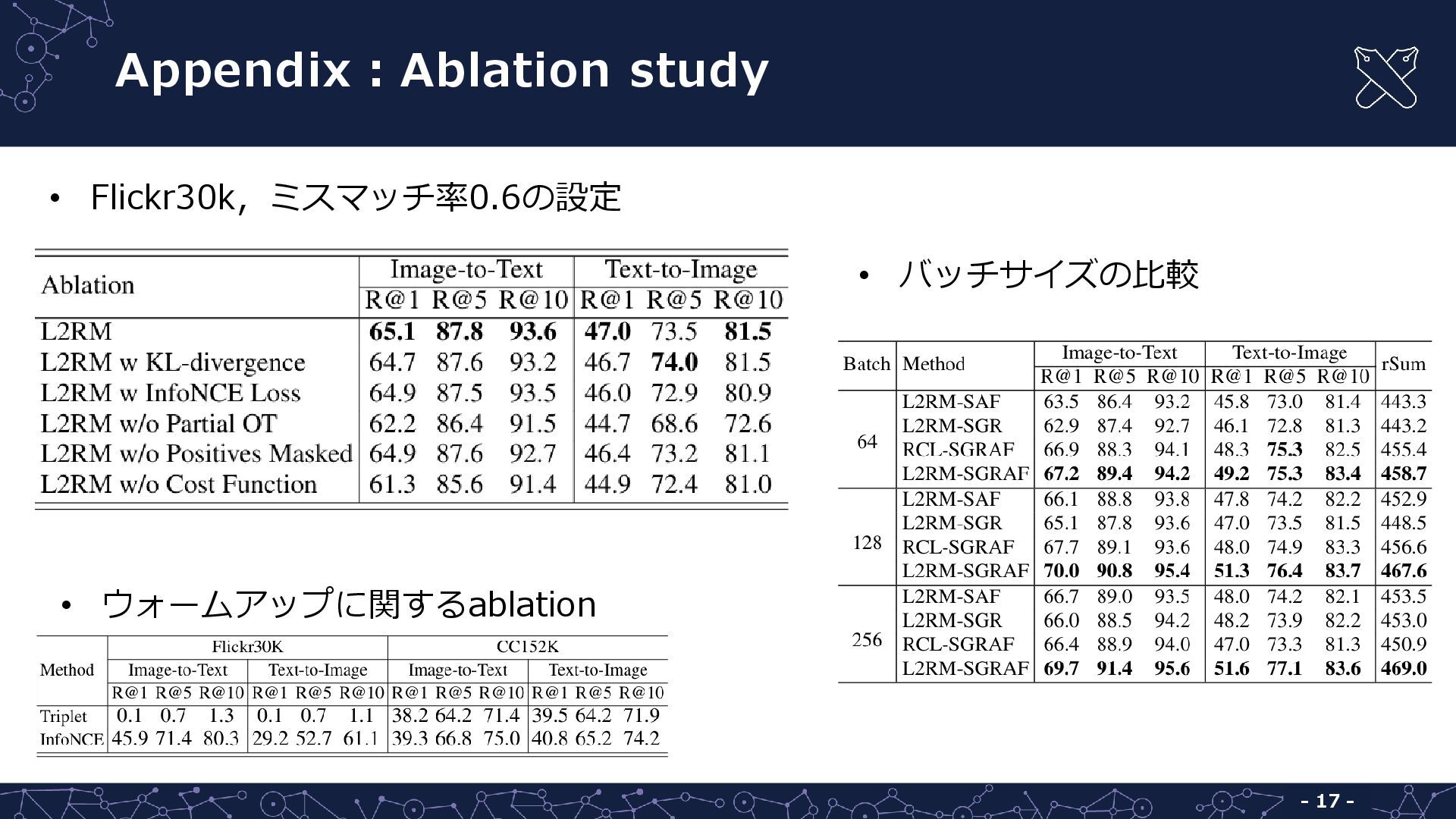{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![- 25 - Appendix:データセットに含まれる画像数 訓練集合 検証集合 テスト集合 CC152k [Sharma+, ACL18]](https://files.speakerdeck.com/presentations/f636a869b7d7415786726b1ba41ae92d/slide_24.jpg){kind=link}