Kubernetes Meetup Tokyo #73
https://k8sjp.connpass.com/event/379883/
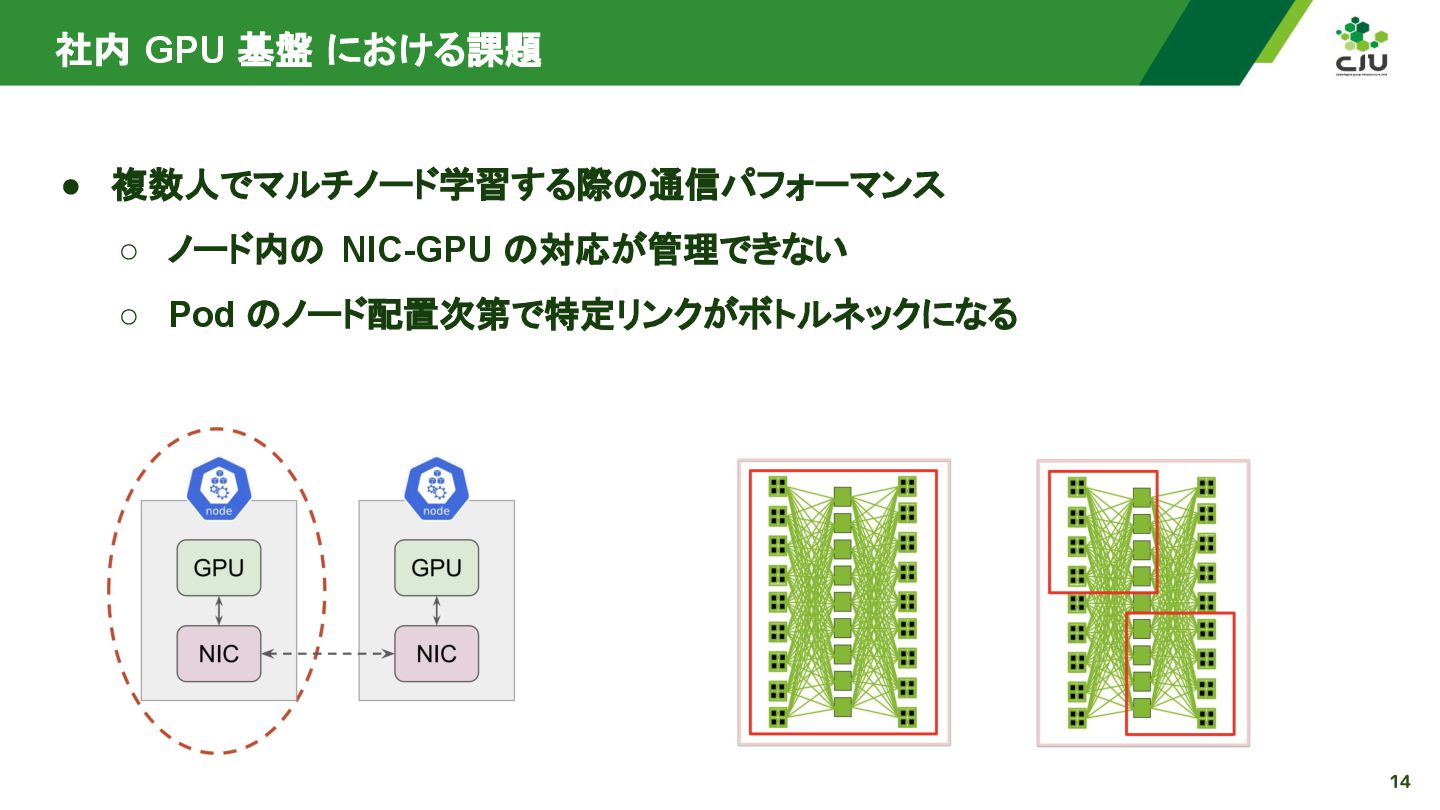
Kubernetes 1.34 で GA となった DRA 関連セッションの Recap します。 メンテナセッションを中心にユースケースのセッションをいくつかまとめて、社内GPU 基盤を運用する際の課題に照らし合わせて Recap します。
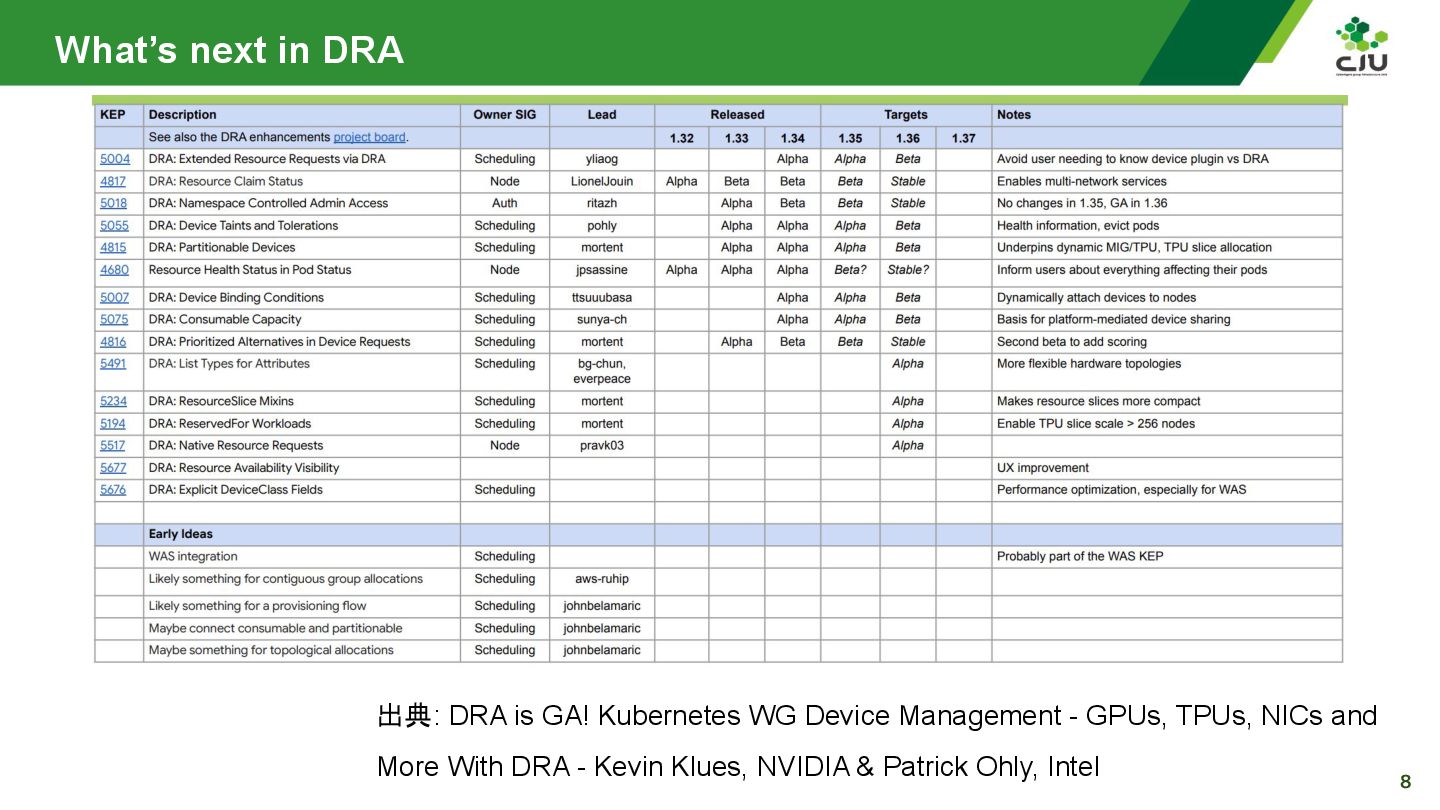
『DRA is GA! Kubernetes WG Device Management - GPUs, TPUs, NICs and More With DRA - Kevin Klues, NVIDIA & Patrick Ohly, Intel 』
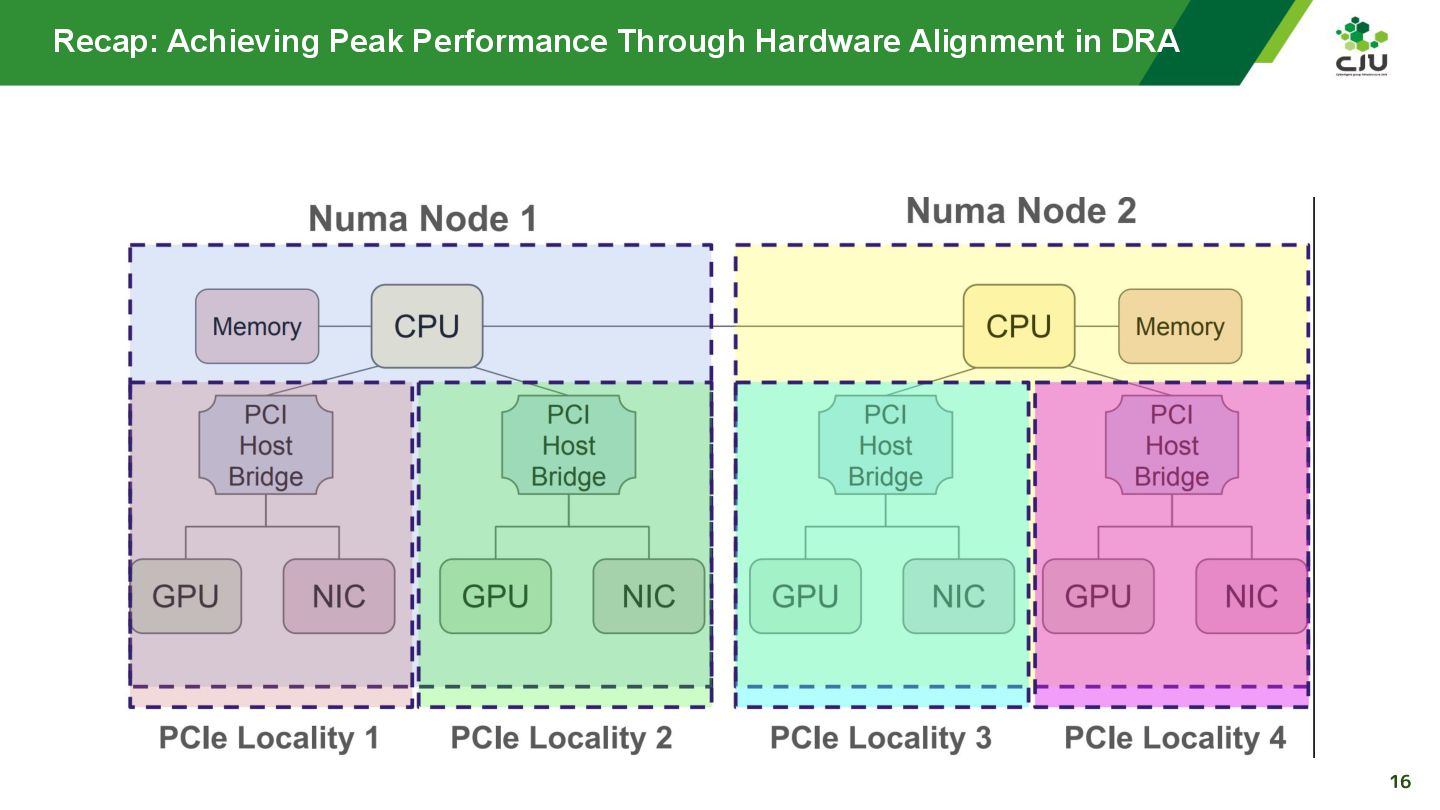
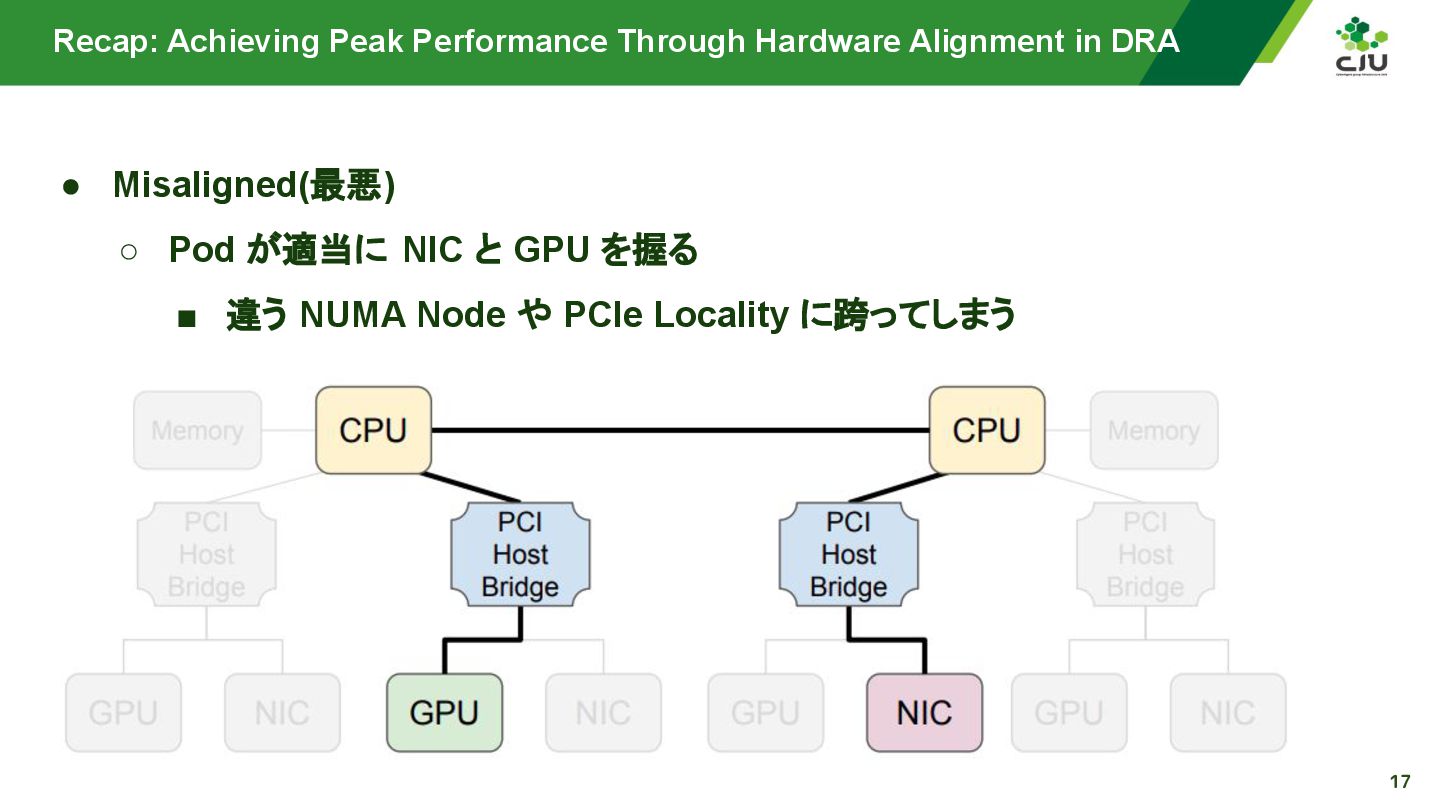
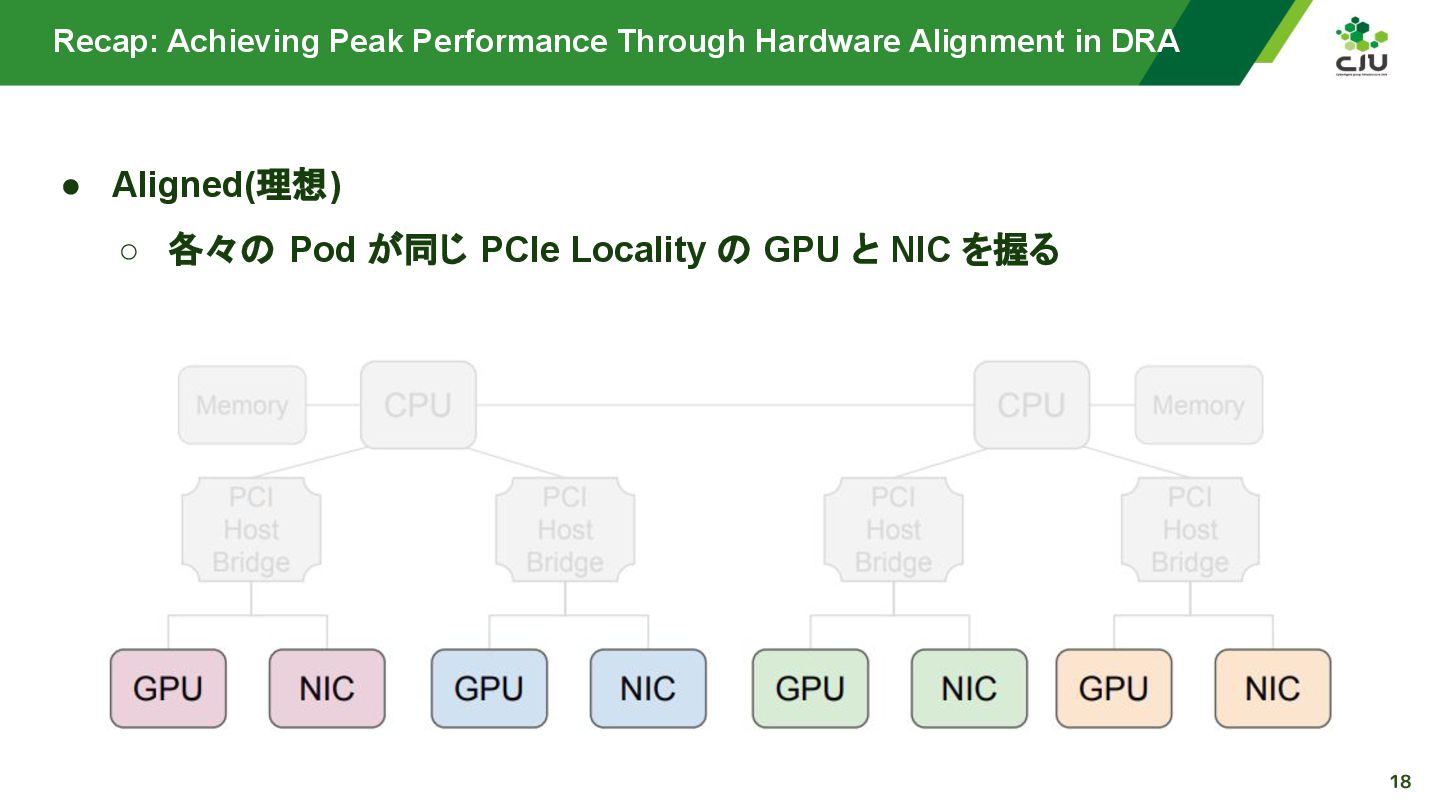
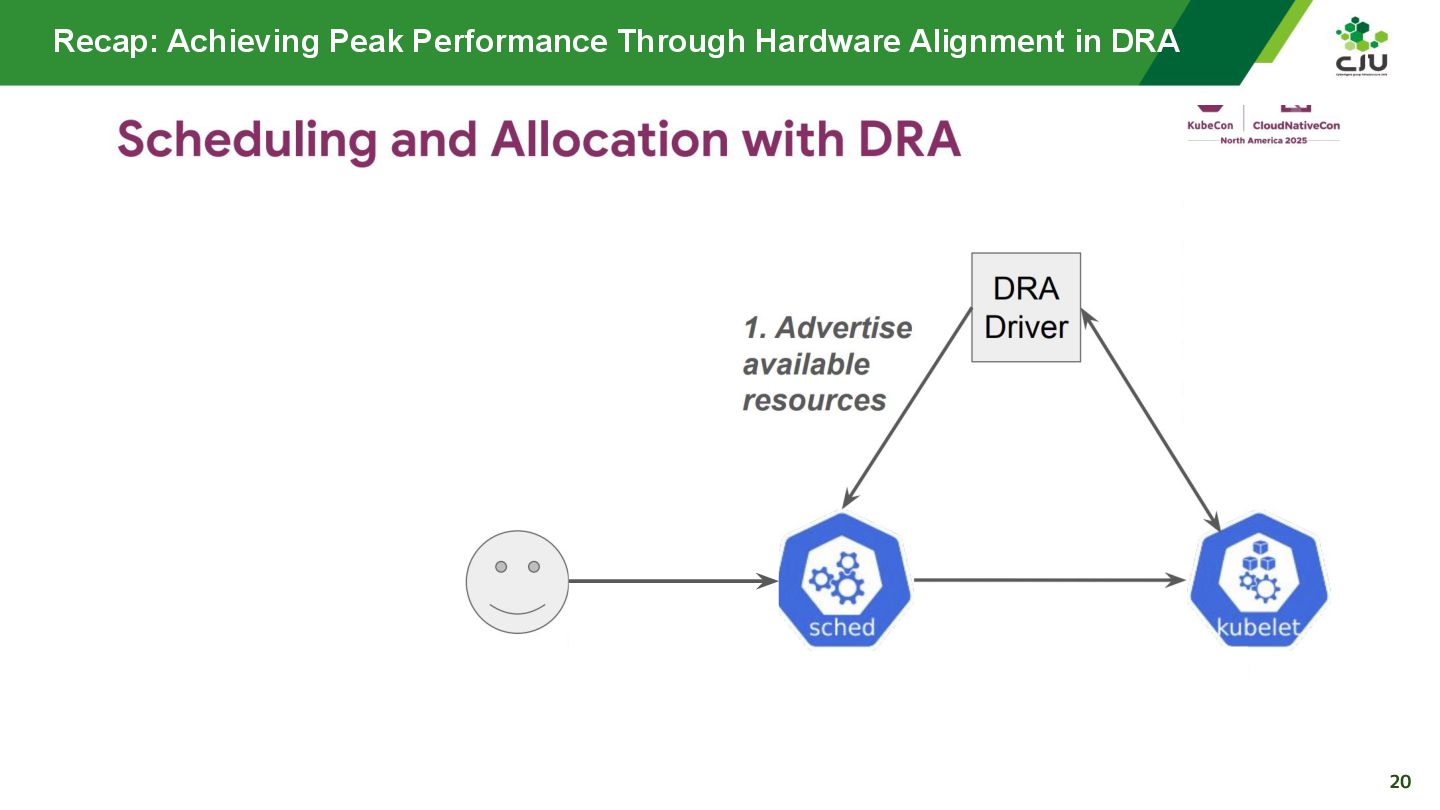
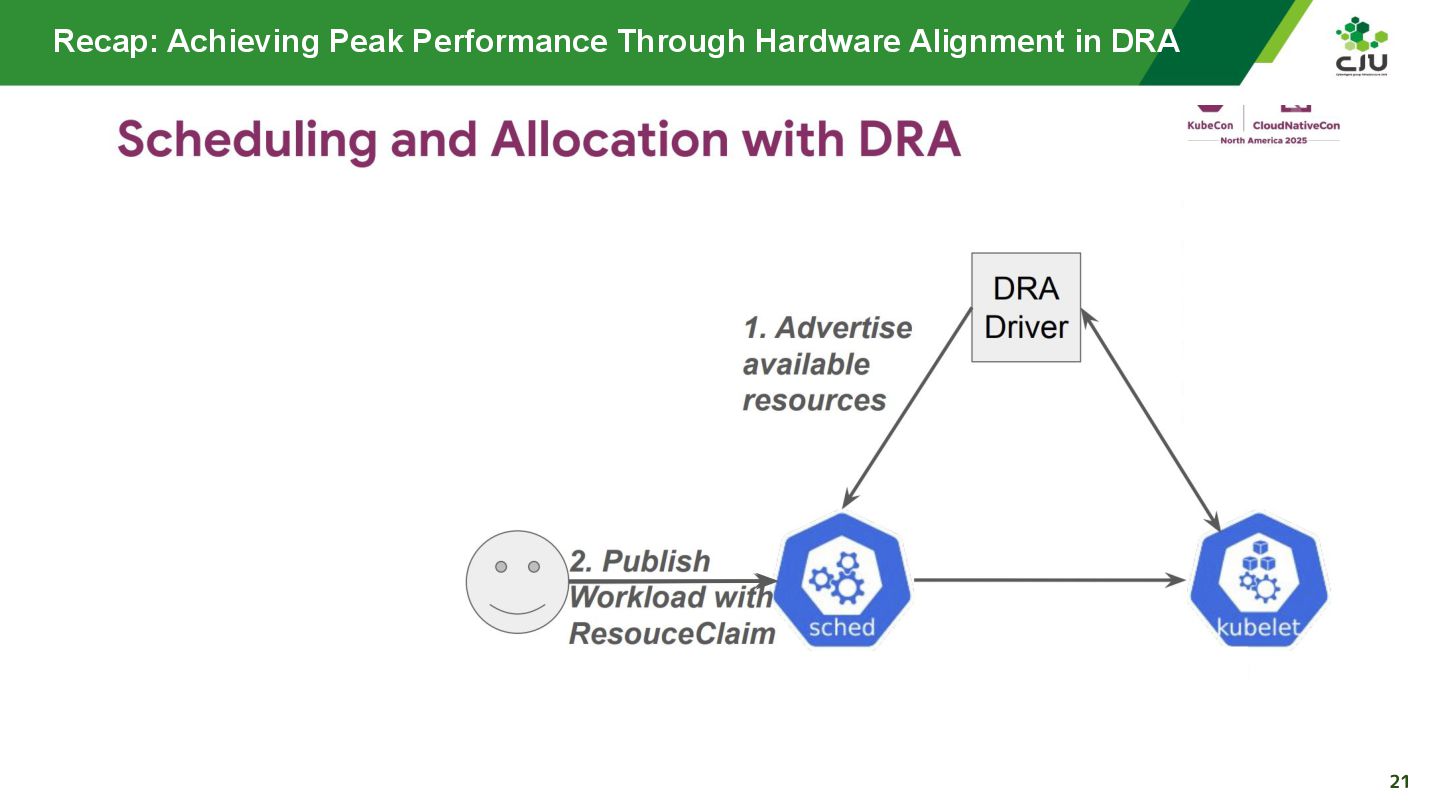
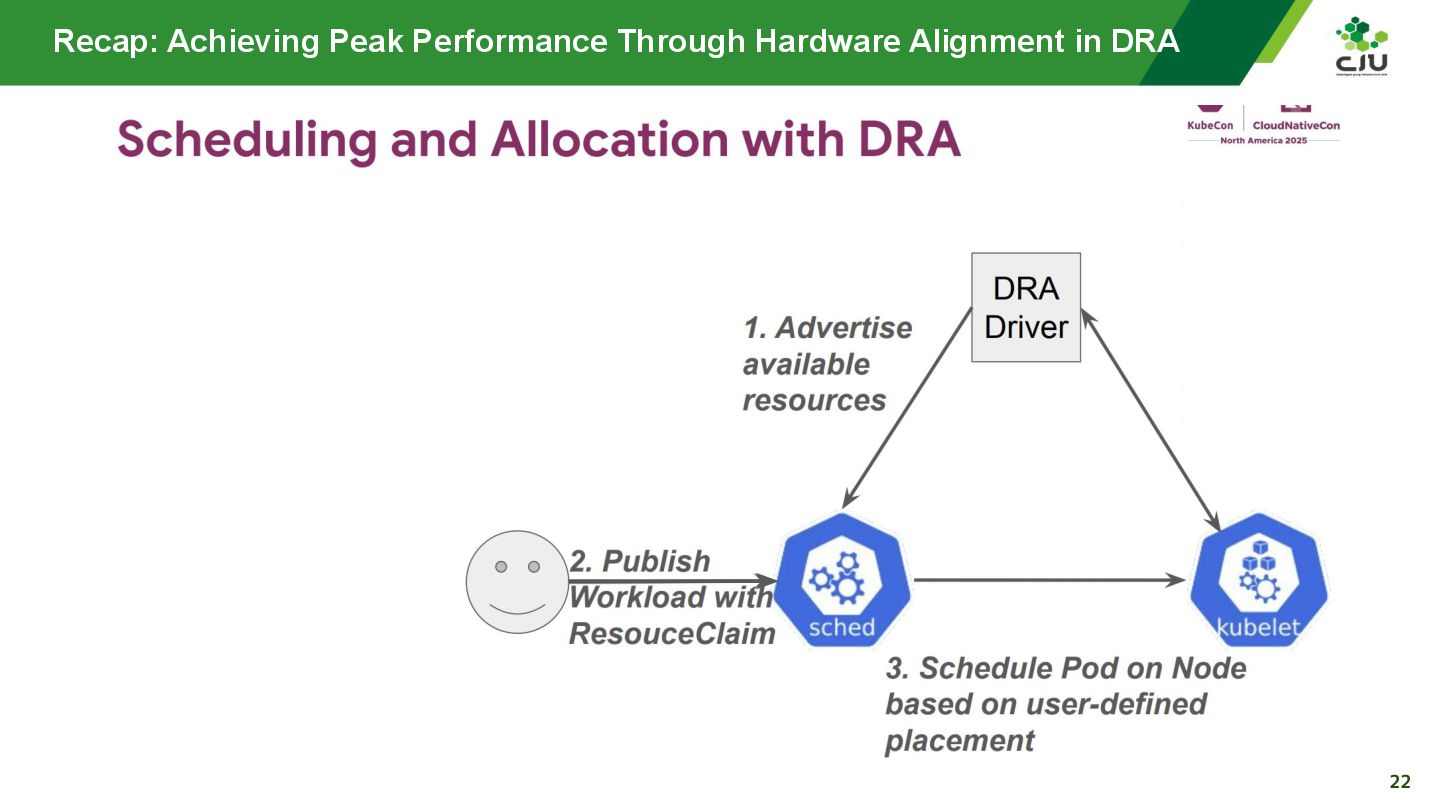
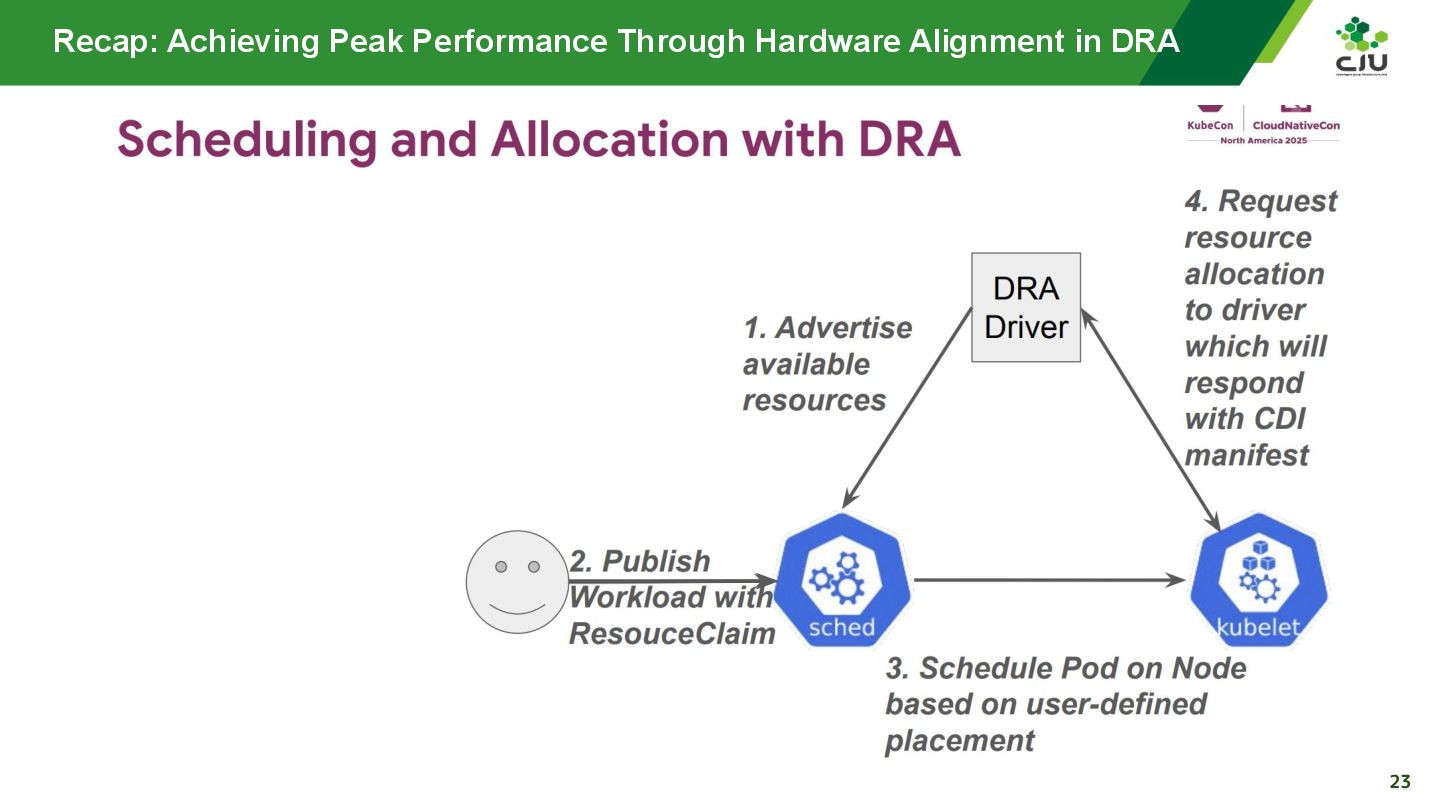
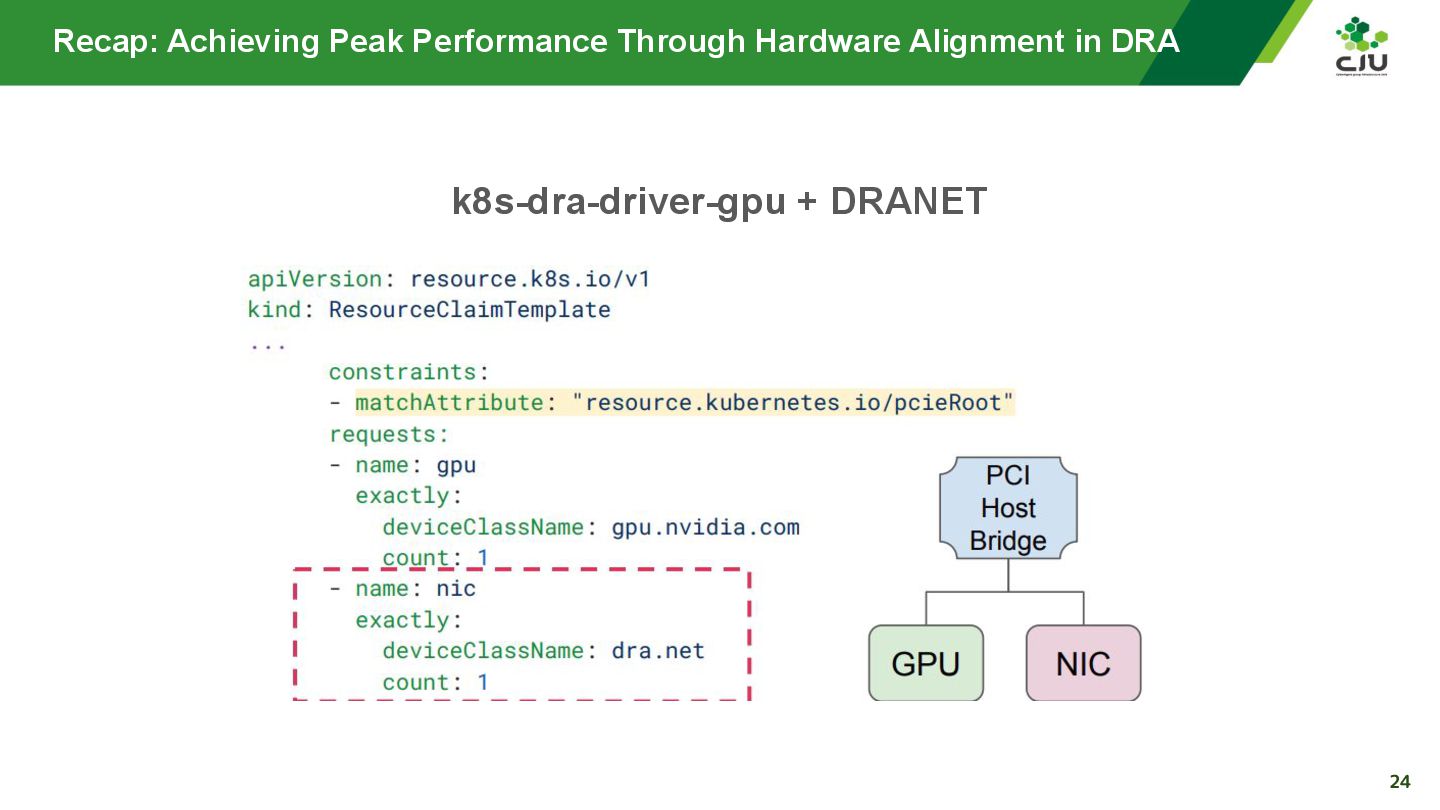
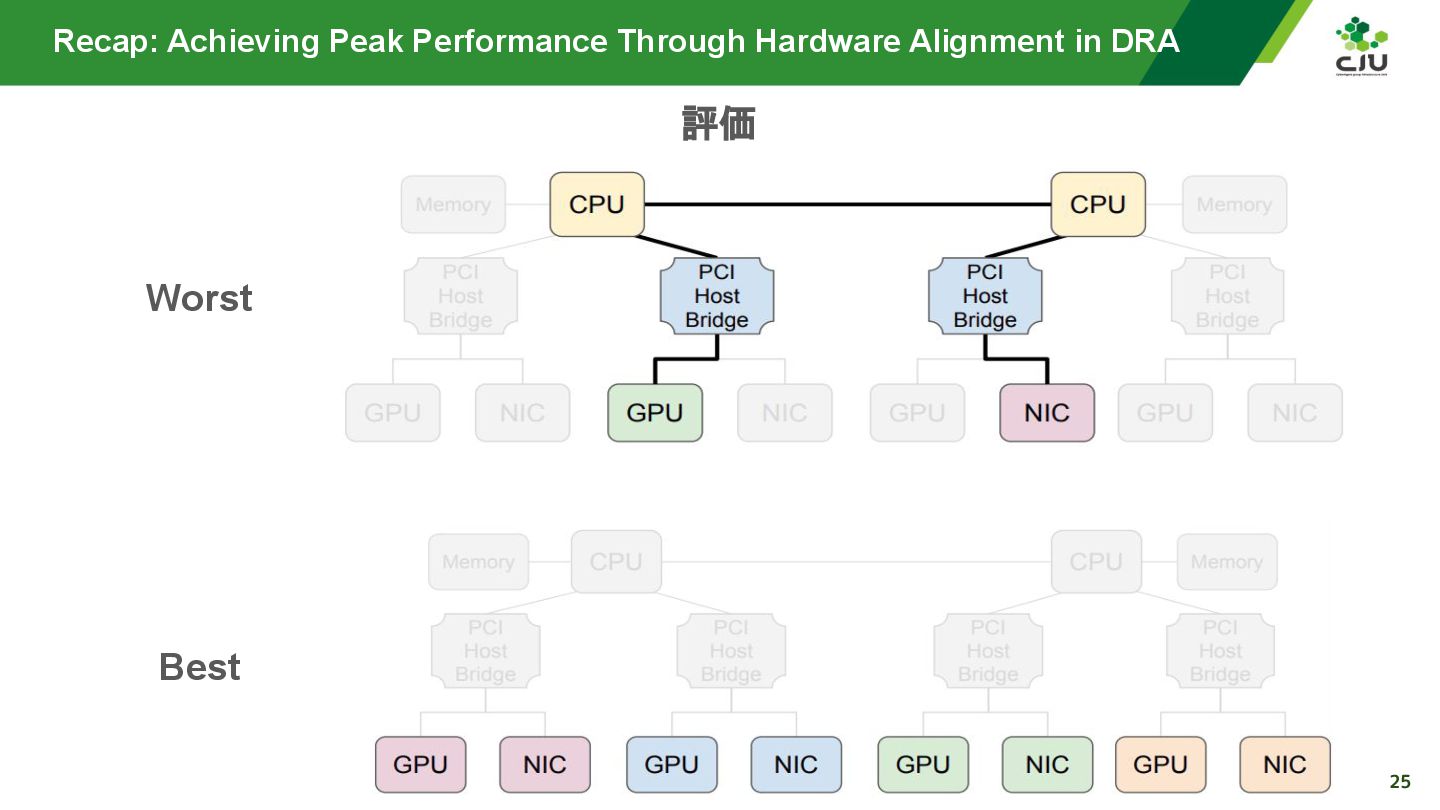
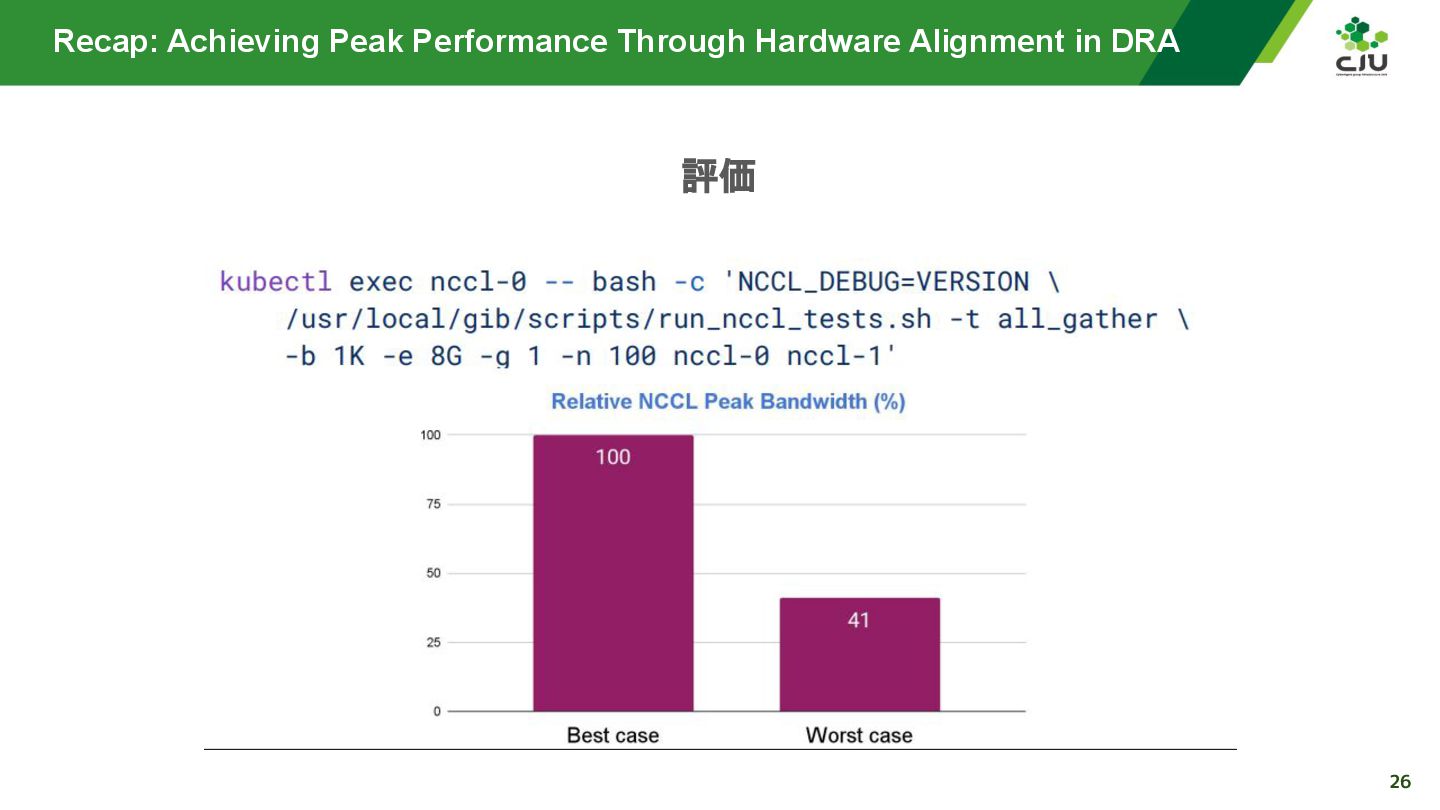
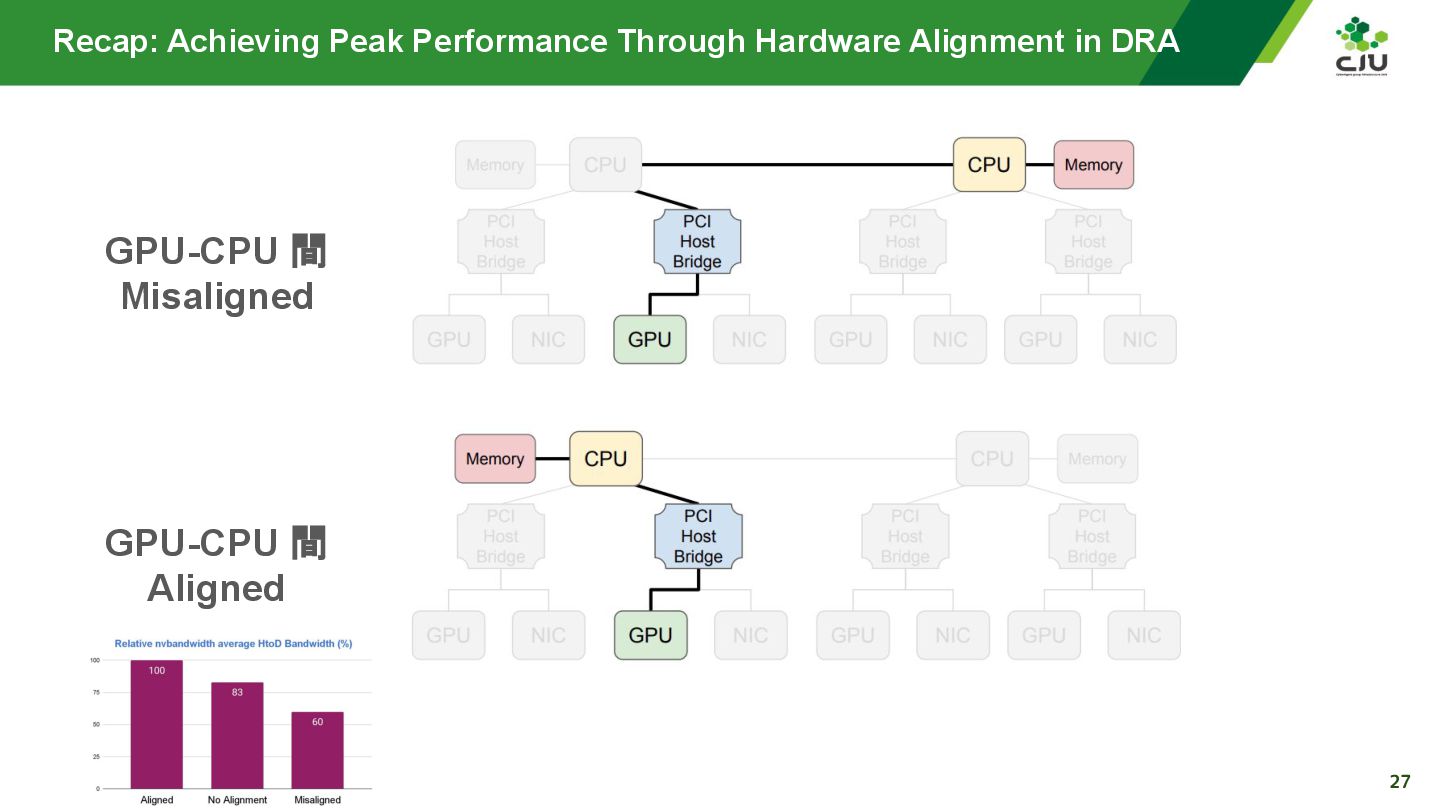
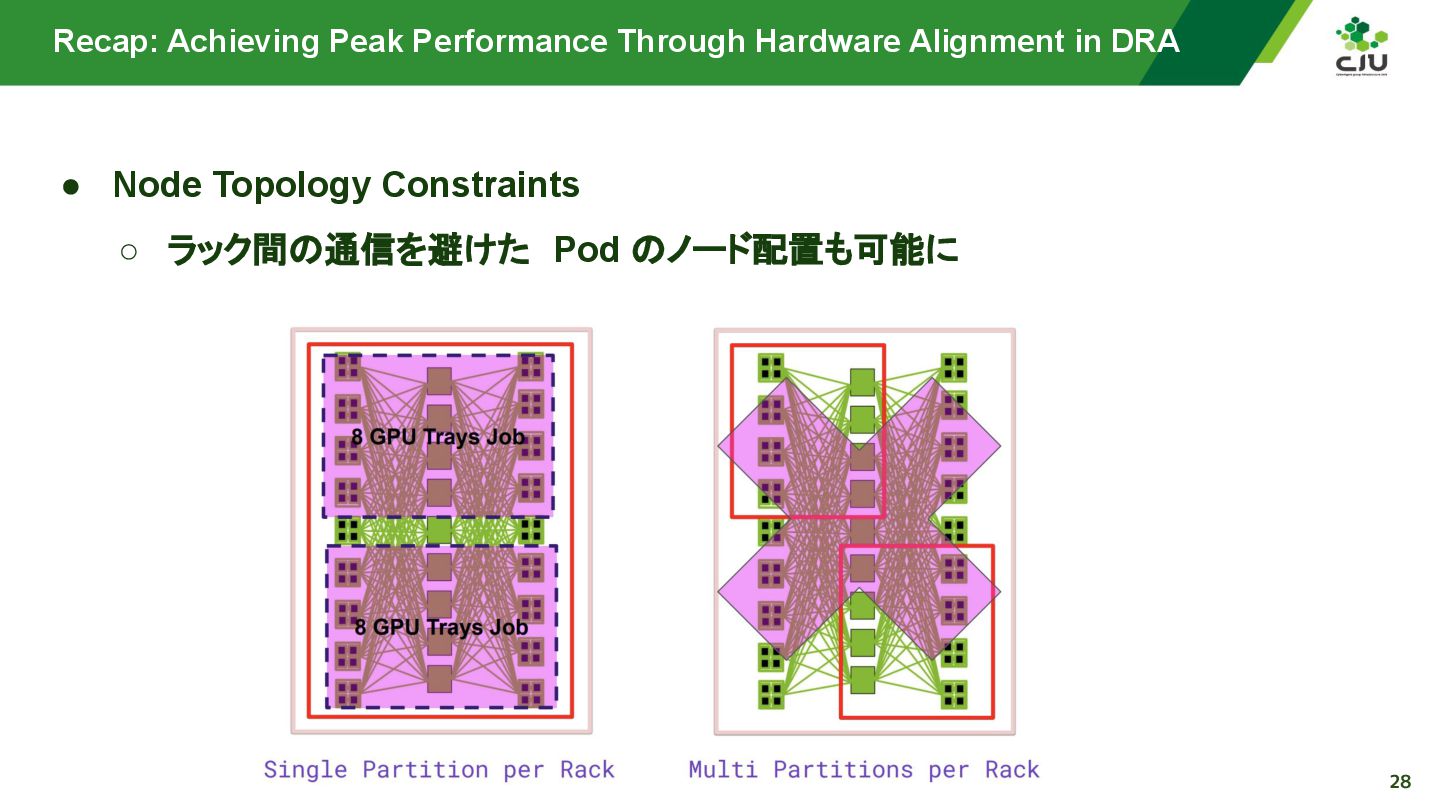
『Achieving Peak Performance Through Hardware Alignment in DRA - Gaurav Ghildiyal, Google & Byonggon Chun, Fluidstack』
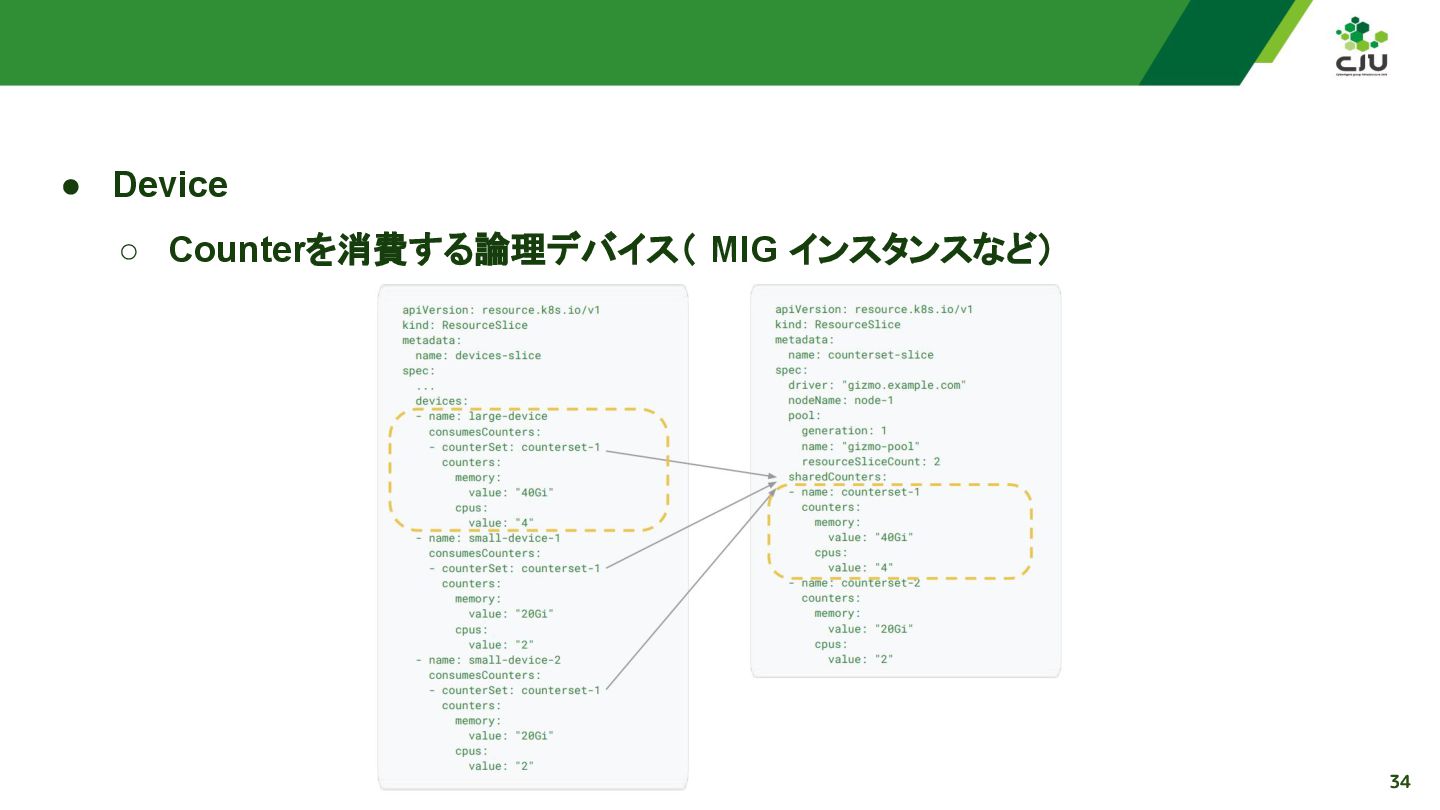
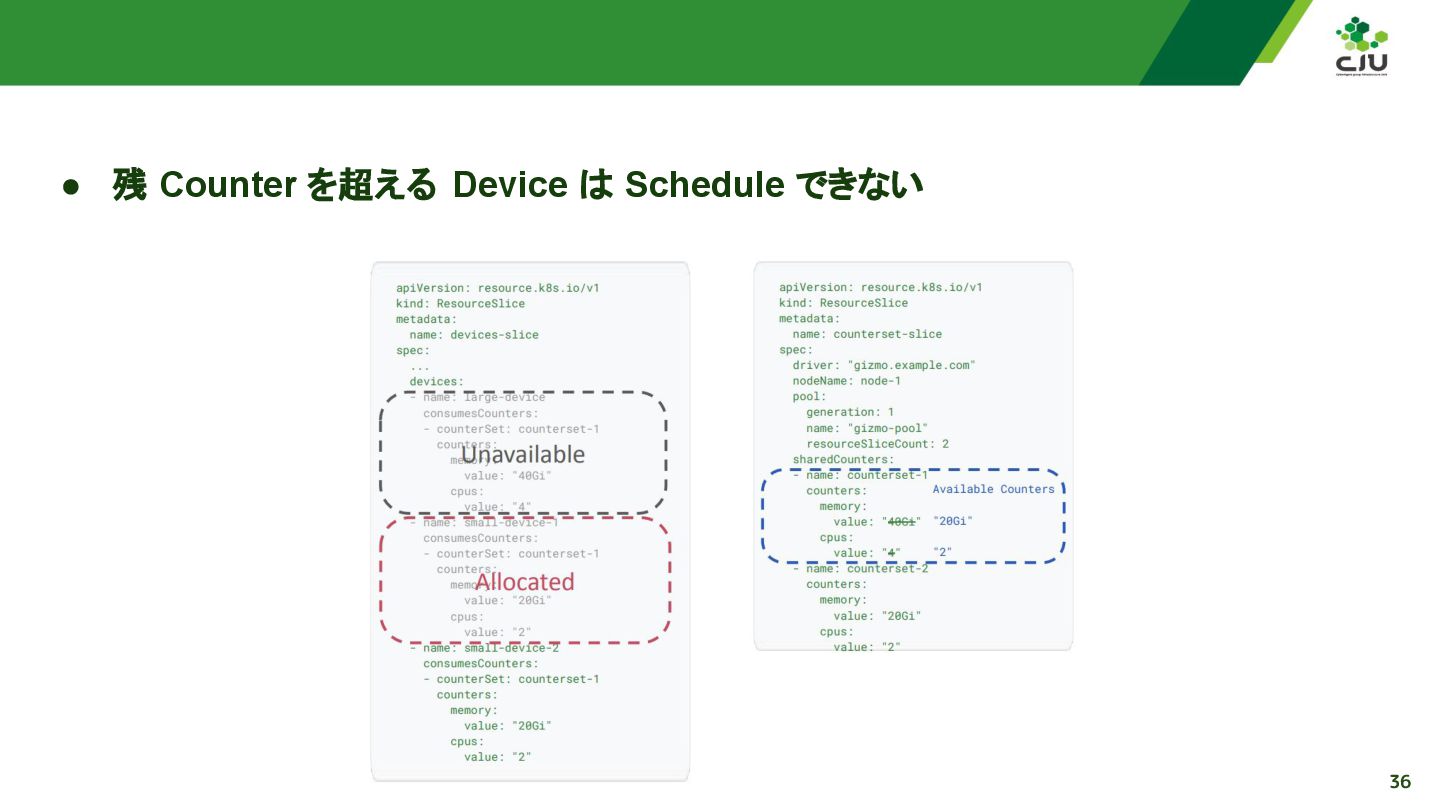
『Partitionable Devices: Putting the "Dynamic" Back in Dynamic Resource Allocation - Morten Jæger Torkildsen, Google & Jan-Philip Gehrcke, NVIDIA』
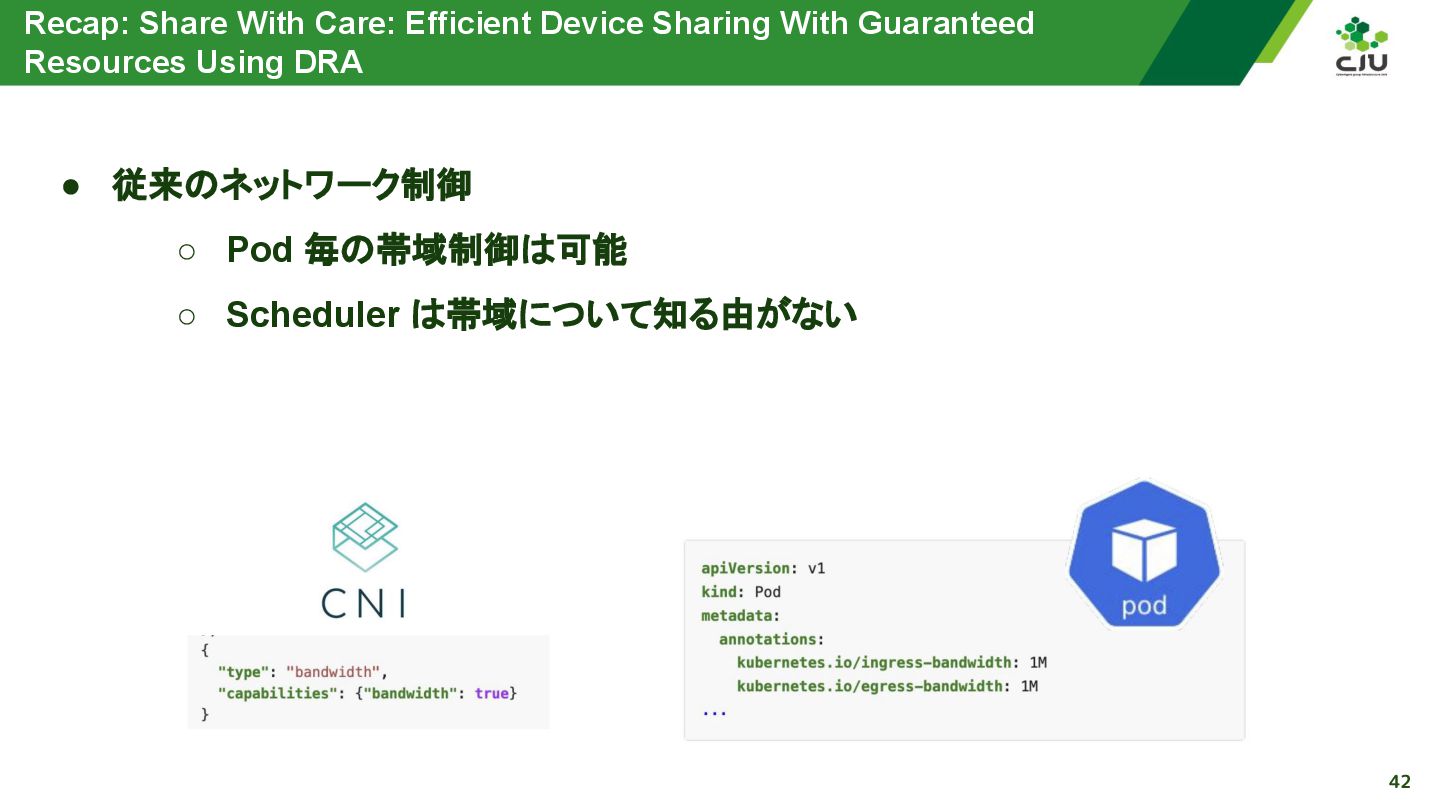
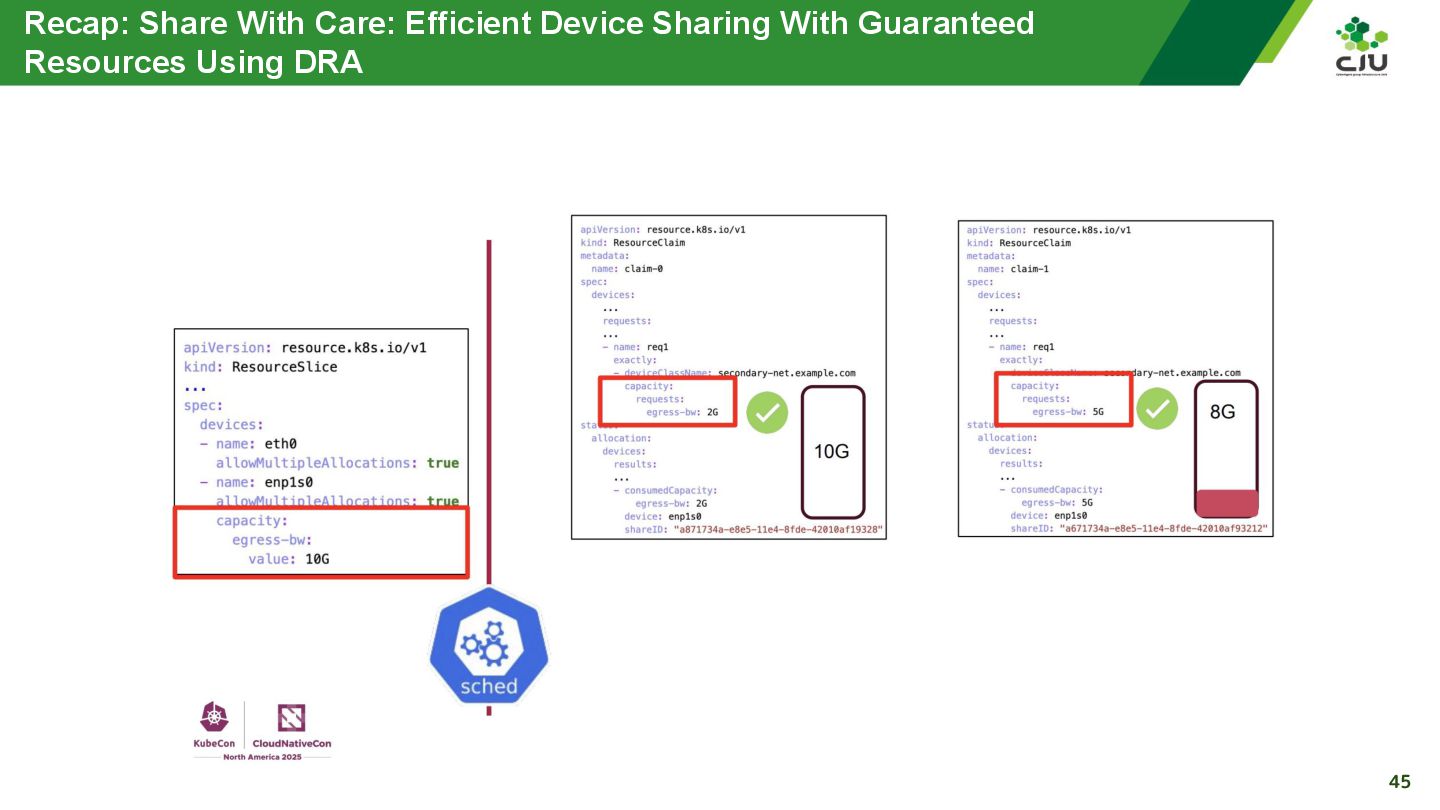
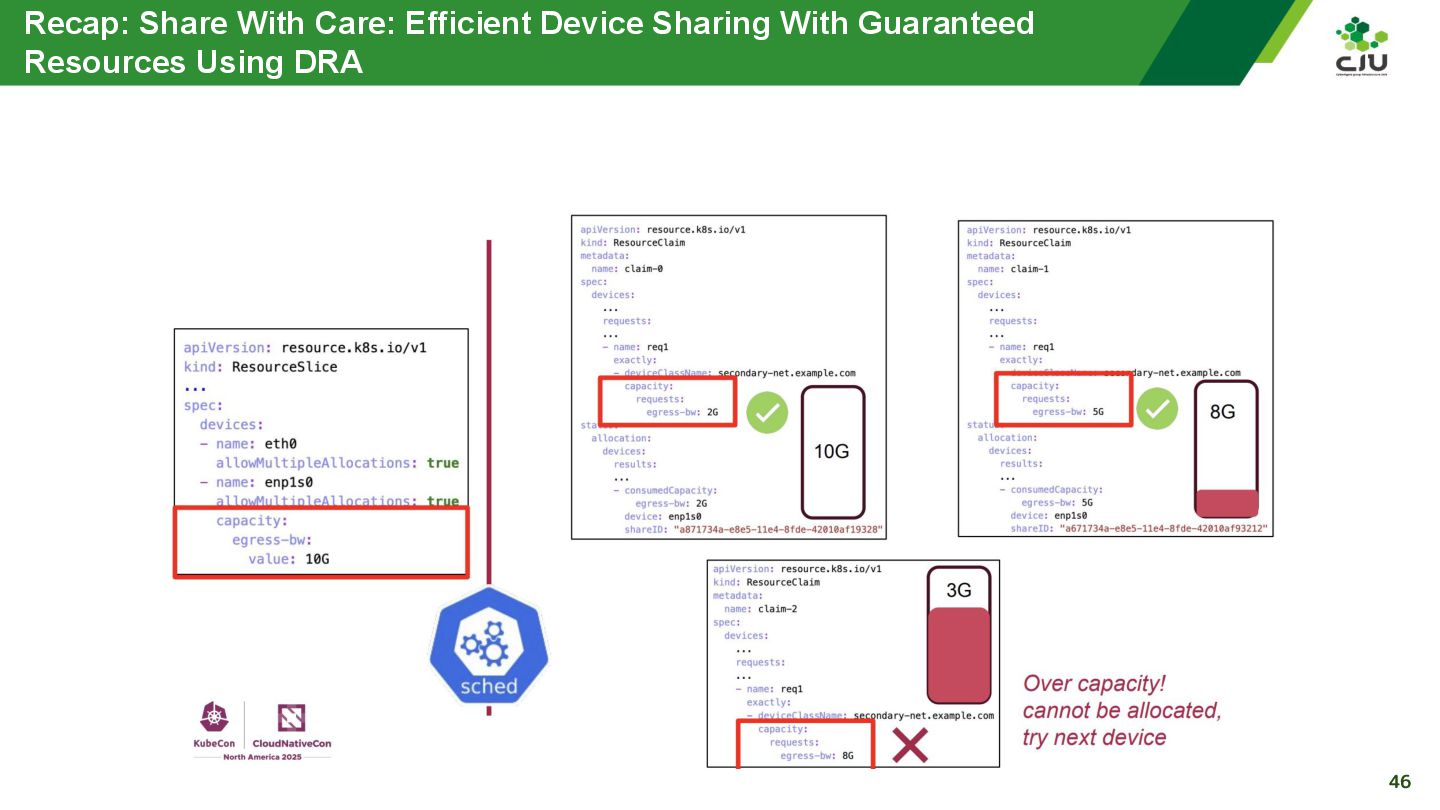
『Share With Care: Efficient Device Sharing With Guaranteed Resources Using DRA - Sunyanan Choochotkaew, IBM Research & John Belamaric, Google』
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}