Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can b...
Search
Naoki Kishida
June 19, 2026
Programming
4.9k
12
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
2026/6/19に開催された「コーディングのためのローカルLLM勉強会 in 福岡」での登壇資料です。
https://connpass.com/event/395614/
Naoki Kishida
June 19, 2026
More Decks by Naoki Kishida
See All by Naoki Kishida
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
210
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
180
ローカルLLMでどこまでコードが書けるか / How much code can be written on a local LLM
kishida
2
540
ローカルLLM基礎知識 / local LLM basics 2025
kishida
30
17k
AIエージェントでのJava開発がはかどるMCPをAIを使って開発してみた / java mcp for jjug
kishida
5
1.2k
AIの弱点、やっぱりプログラミングは人間が(も)勉強しよう / YAPC AI and Programming
kishida
13
6.9k
海外登壇の心構え - コワクナイヨ - / how to prepare for a presentation abroad
kishida
2
190
Current States of Java Web Frameworks at JCConf 2025
kishida
0
1.8k
AIを活用し、今後に備えるための技術知識 / Basic Knowledge to Utilize AI
kishida
28
7.5k
Other Decks in Programming
See All in Programming
地域 SRE コミュニティ最前線 - ホンマでっかSRE勉強会
tk3fftk
0
280
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1.1k
Google Apps Script で Ruby を動かす
kawahara
0
120
The Past, Present, and Future of Enterprise Java
ivargrimstad
0
440
えっ!!コードを読まずに開発を!?
hananouchi
0
280
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
890
人間の目はかわらない、だからJPEGは30年もつ
yuzneri
12
17k
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
190
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
420
今さら聞けない .NET CLI
htkym
0
150
霧の中の代数的エフェクト
funnyycat
1
440
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
140
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
360
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
750
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Building AI with AI
inesmontani
PRO
1
1.1k
Navigating Team Friction
lara
192
16k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
920
The SEO identity crisis: Don't let AI make you average
varn
0
520
The Pragmatic Product Professional
lauravandoore
37
7.4k
ラッコキーワード サービス紹介資料
rakko
1
4.1M
Transcript
ローカルLLMでどこまでコードが書けるのか 2026-06-19 コーディングのためのLLM勉強会 きしだ なおき
2026/06/19 2 自己紹介 • きしだ なおき • X(twitter): @kis •
サブスクも始めました。 • blog: きしだのHatena • (nowokay.hatenablog.com) • 「プロになるJava」というJavaの本を書いてます
3 2023年からの3年で おうちで動くLLMはどう変わったか
2023 「動いて偉い!」 • チャットのできるモデルが出始める • 日本語を学習させないと 日本語は話せない • 「対話できてえらい」 「聞いたことに答えてくれて偉い」
2024「まともに動く!」 • まともな意味のある長文を出す • 特別に学習しなくても日本語で答える
2025「使えそう!」 • Gemma 3/Qwen3登場 • 意味のある動くプログラムを一発で出す • 専門的な内容を解説する
2026「使える!」 • Gemma 4 / Qwen3.6登場 • 英語のレポートを要約して解説 • まとまったプログラムを作る
• エージェントで作業する
2026/6「必要では?」 • 最高モデルが出たらすぐ止まる • 最高だったモデルがなんか性能落ちてる • トークン際限なく使えない • 大きいローカルモデルなら代替がある程度可能
現在の状況(モデル) • 30Bくらいのモデル • 1往復でおわるチャットには十分 • 要約、翻訳、簡単な質問 • 最初のコーディングなら十分 •
デバッグには ハマることがある • 500B以上のモデル • 高度なこと以外には十分 • おうちで使うのは厳しい • メモリ高騰が残念
現在の状況(ビジネス的) • コーディングエージェント使い放題はコストがかさむ • プロプラモデルは制限がきびしい • プロプラモデルは値上がりする • サーバーが足りてない •
新しい高性能モデルは高くなっていってる
今日の話 • 手元のマシンでコーディング作業を行う • 32GB-64GBの統合メモリでQwen3.6 / Gemma 4を動かす • 将来的には192GB-256GBで250B程度を動かす
• 15万トークン以内の作業 • LLM用サーバーで共有はおすすめしない • コーディングの高負荷でサーバーを運用するのは大変 • ある程度をQwen3.6 / Gemma 4でまかなうならコスト回収も大変 • オープンモデルでもAPIを使ったほうがいい • 単にモデル選択と利用料金の問題になる
いま使えるモデル • Dense / MoE • MoEは一部だけ動かす • 速いし知識がある •
Denseは全部動かす • 重いけど賢い • アテンション • フル – O(n^2) 重いけど賢い • スライド – 全体を見れないけど確実な作業 • スパース - 全体を見るけど少しあいまい • 線形 – 計算を工夫してO(n)、誤差で間違いが出やすい
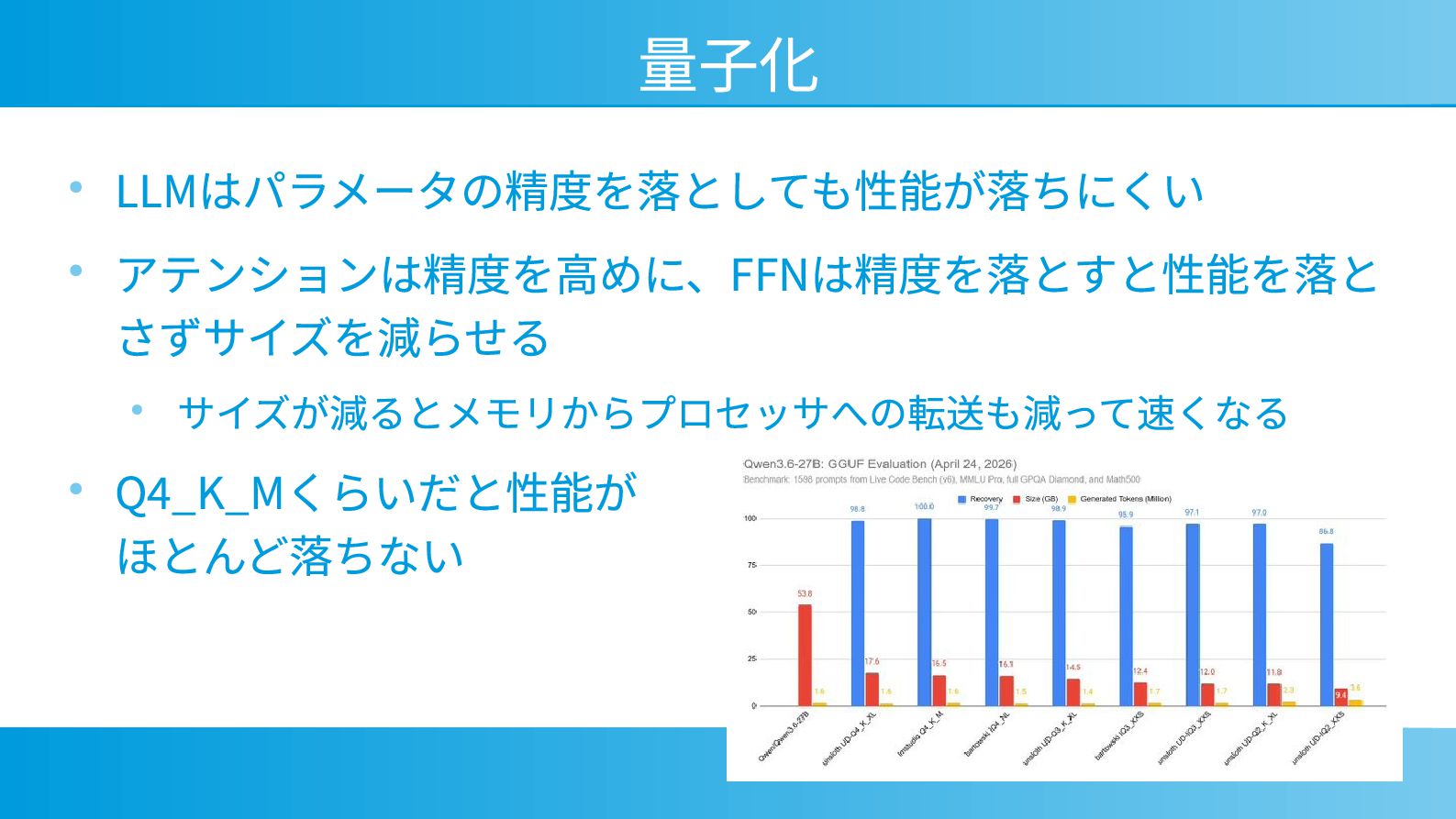
量子化 • LLMはパラメータの精度を落としても性能が落ちにくい • アテンションは精度を高めに、FFNは精度を落とすと性能を落と さずサイズを減らせる • サイズが減るとメモリからプロセッサへの転送も減って速くなる • Q4_K_Mくらいだと性能が
ほとんど落ちない
Q4_K_MとかQ4_K_Sってなに? • Q4はわかる • Kもなんかアルゴリズムらしい • MとかLとかSって? • アテンションなど大事なところは 精度が高いものを使う
• その比率がLは高くSは低い Qwen3-0.6 Q4_K_M Q4_K_S
ハードウェア • SoC – CPU/NPU/GPUを統合したチップ • AMD Ryzen AI Max+
395 – EVO-X2: 128GB / 48万円 • Intel Core Ultra 7 – MINISFORM M2 32GB / 22万円 • NVIDIA GB10 – Ascent GX10: 128GB / 58万円 • Apple Silicon – Mac Studio: 96GB / 60万円 • GPU(32GB) • RTX 5060 Ti 16GB x2 / 20万円 • Intel Arc Pro B70 / 22万円 • Radeon AI Pro R9700 / 25万円 • RTX 5090 / 60万円~ • RTX PRO 4500 / 60万円
ソフトウェア • 推論エンジン • llama.cpp • MLX • チャット •
Open WebUI • 統合ツール • LM Studio • Ollama • コーディングエージェント • OpenCode • Claude Code • Codex
推論エンジン • llama.cpp • 汎用 • GGUF • 量子化が多い •
mlx-llm • Macのみ • vLLM, SGLang • 複数で同時に使うサーバー用
チャットUI • Open WebUI • RAGやコード実行などもできる • LM Studio •
UIついてる • llama.cpp • Web UIが結構つかえる
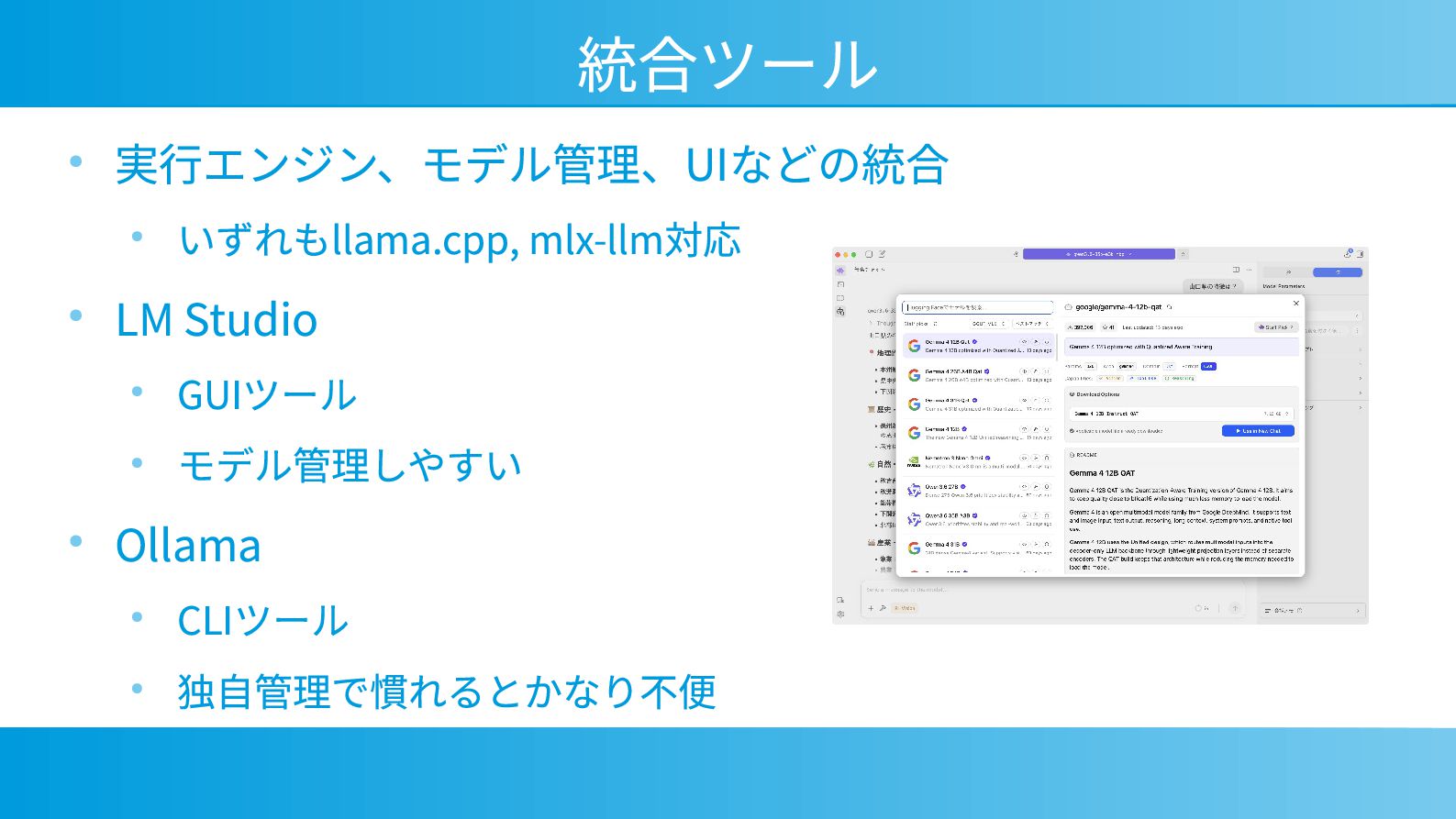
統合ツール • 実行エンジン、モデル管理、UIなどの統合 • いずれもllama.cpp, mlx-llm対応 • LM Studio •
GUIツール • モデル管理しやすい • Ollama • CLIツール • 独自管理で慣れるとかなり不便
コーディングエージェント • OpenCode • オープンソース • クローズドツールも使える • Codex •
Claude Code
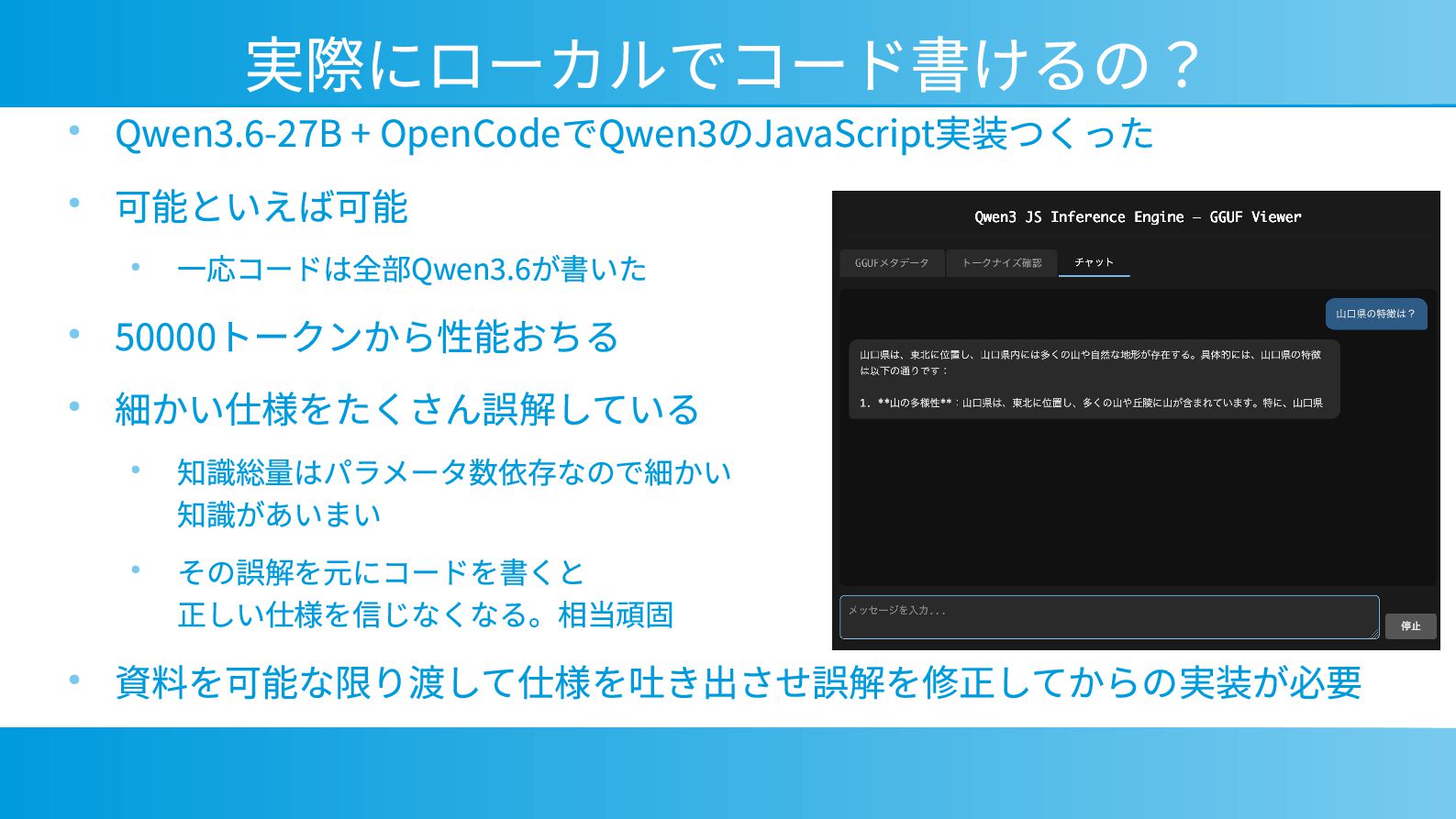
実際にローカルでコード書けるの? • Qwen3.6-27B + OpenCodeでQwen3のJavaScript実装つくった • 可能といえば可能 • 一応コードは全部Qwen3.6が書いた •
50000トークンから性能おちる • 細かい仕様をたくさん誤解している • 知識総量はパラメータ数依存なので細かい 知識があいまい • その誤解を元にコードを書くと 正しい仕様を信じなくなる。相当頑固 • 資料を可能な限り渡して仕様を吐き出させ誤解を修正してからの実装が必要
メモリがないけど大きいモデルを動かしたいよ • なんかQwen3/3.5/3.6のMoEの必要なExpertだけSSDから 読み込む実行エンジンつくってる • 48GBメモリでQwen3.5-122B-A10Bの Q3_K_Mが15tok/sec • 来月くらいにちゃんと公開します
5年後は? • ハードウェアの進化だけでは動かせるモデルは増えない • メモリ → 年率40%成長 → 5年で5.3倍 •
大きいモデルも乗るだけなら乗る • プロセッサ → 年率30%成長 → 5年で3.7倍 • もすこし足りない • 帯域 → 年率20%成長 → 5年で2.4倍 • 今でも2倍欲しいので、2.4倍になっても・・・ • 300Bくらいが主戦場では • 普通にコーディングできる • フロンティアモデルと使い分け(設計やデバッグはフロンティア、作業はローカル)
最適化 • メモリ削減 • TurboQuant • KVキャッシュ(それまでの出力の計算結果)を削減 • 速度向上 •
MTP(multi-token prediction) • 投機的デコード • 軽いモデルに3トークン出させて本番モデルで答え合わせ • エージェントだと遅い
まとめ • かなり実用になってきている • HTML画面の最初の作り起こしなどは十分にまかせれる • コスト削減 • デバッグや設計などはフロンティアモデルを使う •
将来的にはかなりの作業を手元でできるはず • その準備は やっておいたほうがいい • あと、ローカルで動かすの楽しい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}