This slide deck introduces the concept of Big Data and how Redshift can be an effective data warehousing service. This also introduces the high-level features that Redshift can offer.
untagged and untapped data that is found in data repositories and has not been analyzed or processed • It is similar to big data but differs in how it is mostly neglected by business and IT administrators in terms of its value • also known as dusty data
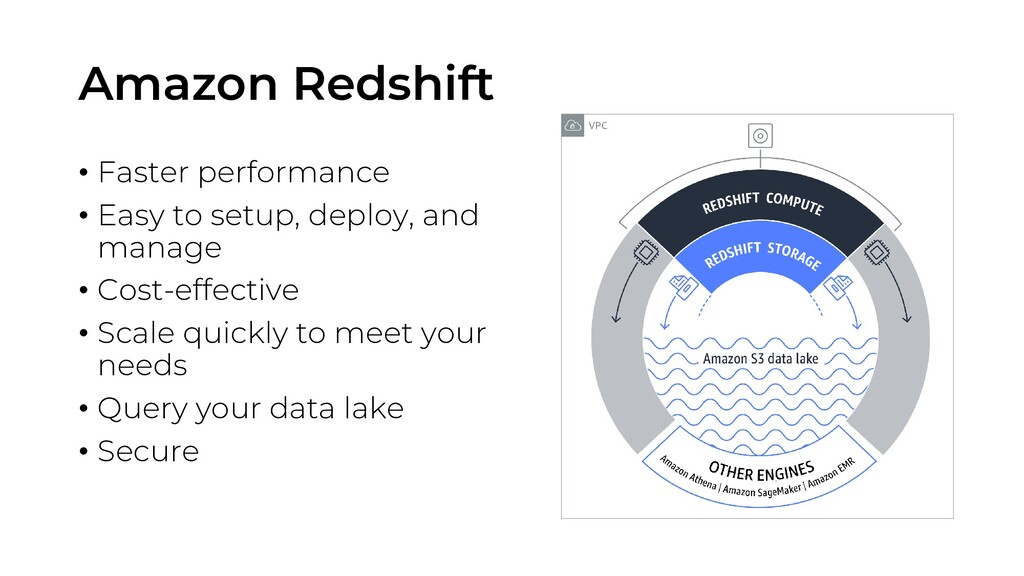
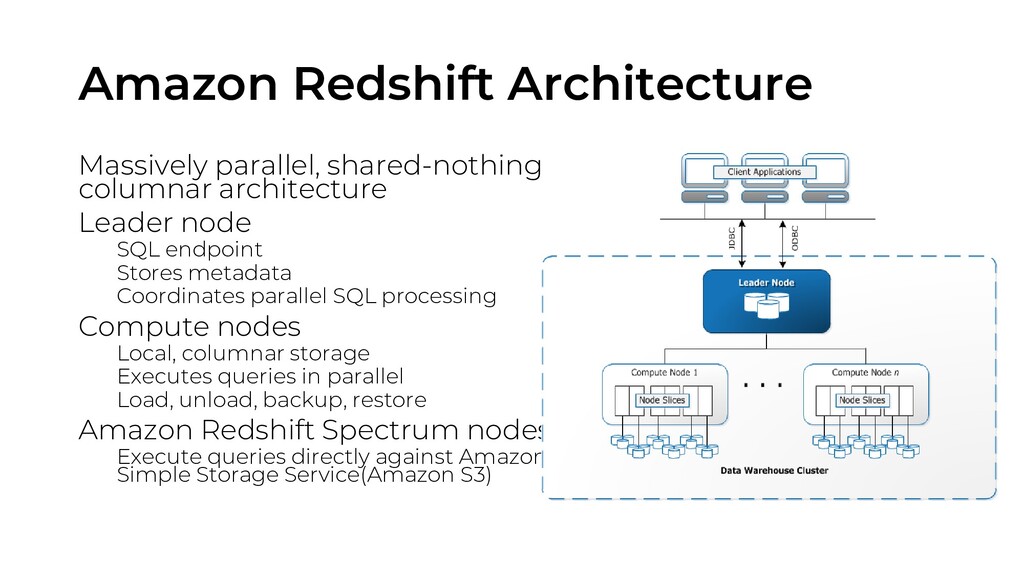
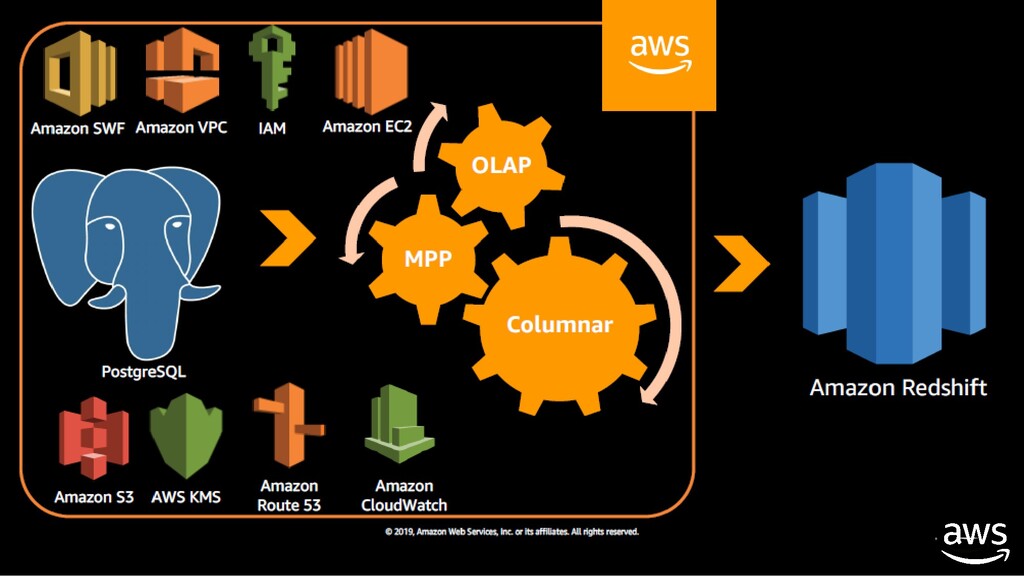
datasets ranging in size from gigabytes to exabytes • uses columnar storage, data compression, and zone maps to reduce the amount of I/O needed to perform queries ✓Machine learning • uses machine learning to deliver high throughout, irrespective of your workloads or concurrent usage • predict incoming query run times, and assigns them to the optimal queue for the fastest processing ✓Result caching • uses result caching to deliver sub-second response times for repeat queries • dashboard, visualization, and business intelligence tools that execute repeat queries experience a significant performance boost
a new data warehouse with just a few clicks in the AWS console, and Redshift automatically provisions the infrastructure for you • focus on your data, not the administration ✓Automated backups • automatically and continuously backs up your data to Amazon S3 • Redshift can asynchronously replicate your snapshots to S3 in another region for disaster recovery ✓Fault tolerant • continuously monitors the health of the cluster ✓Flexible querying • gives you the flexibility to execute queries within the console or connect SQL client tools, libraries, or Business Intelligence tools you love
Redshift is the most cost-effective data warehouse, and you pay only for the resources you provision ✓Predictable cost • allows customers to scale with minimal cost-impact, as each cluster earns up to one hour of free Concurrency Scaling credits per day. ✓Choose your node type • Dense Compute (DC) nodes allow you to create very high performance data warehouses using fast CPUs, large amounts of RAM, and solid-state disks (SSDs) • Dense Storage (DS) node types that use larger hard disk drives for a very low price point
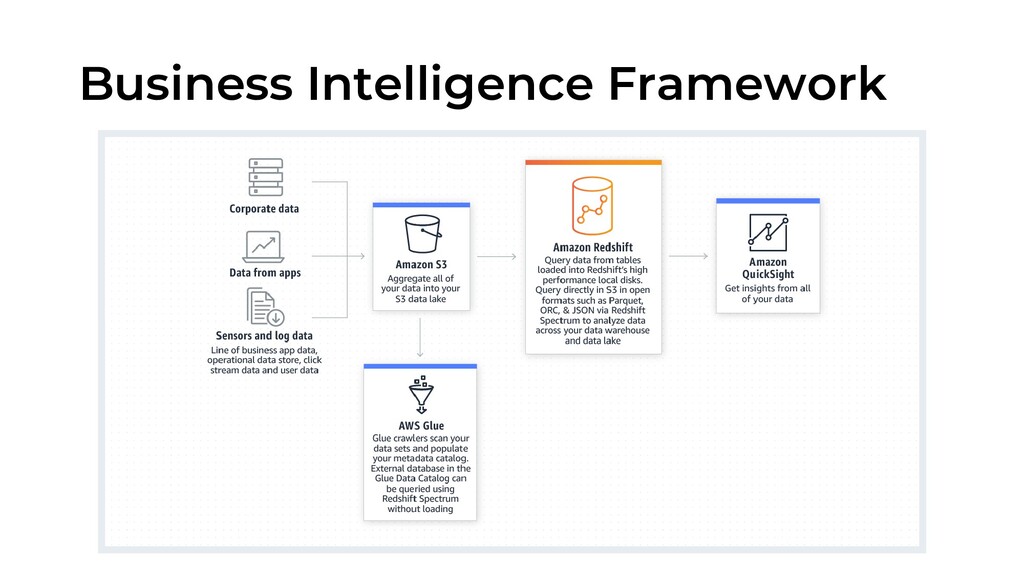
simple and quickly scales as your needs change ✓Exabyte-scale data lake analytics • Redshift Spectrum, a feature of Redshift, enables you to run queries against exabytes of data in Amazon S3 without having to load or transform any data • You can use S3 as a highly available, secure, and cost-effective data lake to store unlimited data in open data formats ✓Limitless concurrency • automatically adds transient capacity as concurrency increases
Redshift is the only data warehouse that extends your queries to your Amazon S3 data lake without loading data. ✓AWS analytics ecosystem • AWS Glue can extract, transform, and load (ETL) data into Redshift • Amazon Kinesis Data Firehose is the easiest way to capture, transform, and load streaming data into Redshift for near real-time analytics • Amazon QuickSight to create reports, visualizations, and dashboards • To accelerate your migration to Amazon Redshift, you can use the AWS Database Migration Service (DMS)
settings, you can set up Amazon Redshift to use SSL to secure data in transit, and hardware- accelerated AES-256 encryption for data at rest ✓Network isolation • enables you to configure firewall rules to control network access to your data warehouse cluster • isolate your data warehouse cluster in your own virtual network and connect it to your existing IT infrastructure using industry-standard encrypted IPsec VPN ✓Audit and compliance • integrates with AWS CloudTrail to enable you to audit all Redshift API calls • logs all SQL operations, including connection attempts, queries, and changes to your database
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}