Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Arch輪読: 詳解システムパフォーマンス 第二版 第6章
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
kota-yata
June 22, 2026
Programming
50
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Arch輪読: 詳解システムパフォーマンス 第二版 第6章
kota-yata
June 22, 2026
More Decks by kota-yata
See All by kota-yata
RG-Arch 輪講資料: Binary Hacks Rebooted 数値演算など
kota_yata
0
71
結局QUICで通信は速くなるの?
kota_yata
10
8k
RG-Arch輪考資料: QUIC is not Quick Enough over Fast Internet
kota_yata
0
170
RG-Arch輪考資料: Implementation and Performance Evaluation of the QUIC Protocol in Linux Kernel
kota_yata
0
200
2024年秋 中村研 WIP発表資料
kota_yata
0
100
パタヘネ輪読: 第五章
kota_yata
0
88
パタヘネ輪読: 第一章
kota_yata
0
340
2023年秋 中村研 WIP発表資料
kota_yata
0
150
2023年春 中澤大越研 WIP発表資料
kota_yata
0
110
Other Decks in Programming
See All in Programming
AIキャラアプリkaiwaの低遅延音声通話基盤をどう作ったか - AWS Gravitonで支える低遅延・低コストAI Agent基盤
mogamit
0
170
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
140
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
110
JAWS-UG横浜 #102 AWSサ終供養LT会 成仏できない AWS サービスたち 〜本日、三体供養します〜
maroon1st
0
210
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
170
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
190
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
520
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
yield再入門 #phpcon
o0h
PRO
0
600
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
150
Performance Engineering for Everyone
elenatanasoiu
0
270
Featured
See All Featured
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
270
The World Runs on Bad Software
bkeepers
PRO
72
12k
WCS-LA-2024
lcolladotor
0
720
Side Projects
sachag
455
43k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Agile that works and the tools we love
rasmusluckow
331
22k
Transcript
詳解システム・パフォーマンス 第2版 第6章 Arch輪読 発表者: kota
今日の範囲 6.3.11〜6.3.15 残りのコンセプト 6.4 CPUアーキテクチャ 6.5 分析メソドロジ 6.6 可観測性ツール 6.7
可視化 6.8 実験 / 6.9 チューニング 2
6.3 コンセプト 3
6.3.11 プリエンプション 優先度の高い実行可能スレッドが,実行中スレッドからCPUを奪う. 低優先度スレッド: [========= 実行 =] [========= 実行 ======]
高優先度スレッド: [ キューに追加] [== 実行 ==] ↑ タイマー割り込み Linuxではスレッドごとにスケジューリングポリシーを決められる(kernel/sched/core.c) 期限ベース: SCHED_DEADLINE リアルタイム: SCHED_FIFO, SCHED_RR タイムシェア: SCHED_NORMAL, SCHED_BATCH, SCHED_IDLE スケジューラーは期限ベース→リアルタイム→タイムシェアの順にキューを走査する タイムシェアについてはユーザーが設定できる nice 値を元に重みが決まる より nice 値が小さいほどCPUを占有できる時間が増える 4
6.3.12 優先度の逆転 高優先度 C ── lock 待ち ─────────────────┐ 低優先度 A
── lock 保持 ── preempted ────┤ 中優先度 B ───────────── 実行中 ─────────┘ CはAのロック解放を待つ AはBにCPUを奪われる 結果としてCが,実質的にBに妨げられる 対策の例: 優先度継承 クリティカルセクションを短くする 5
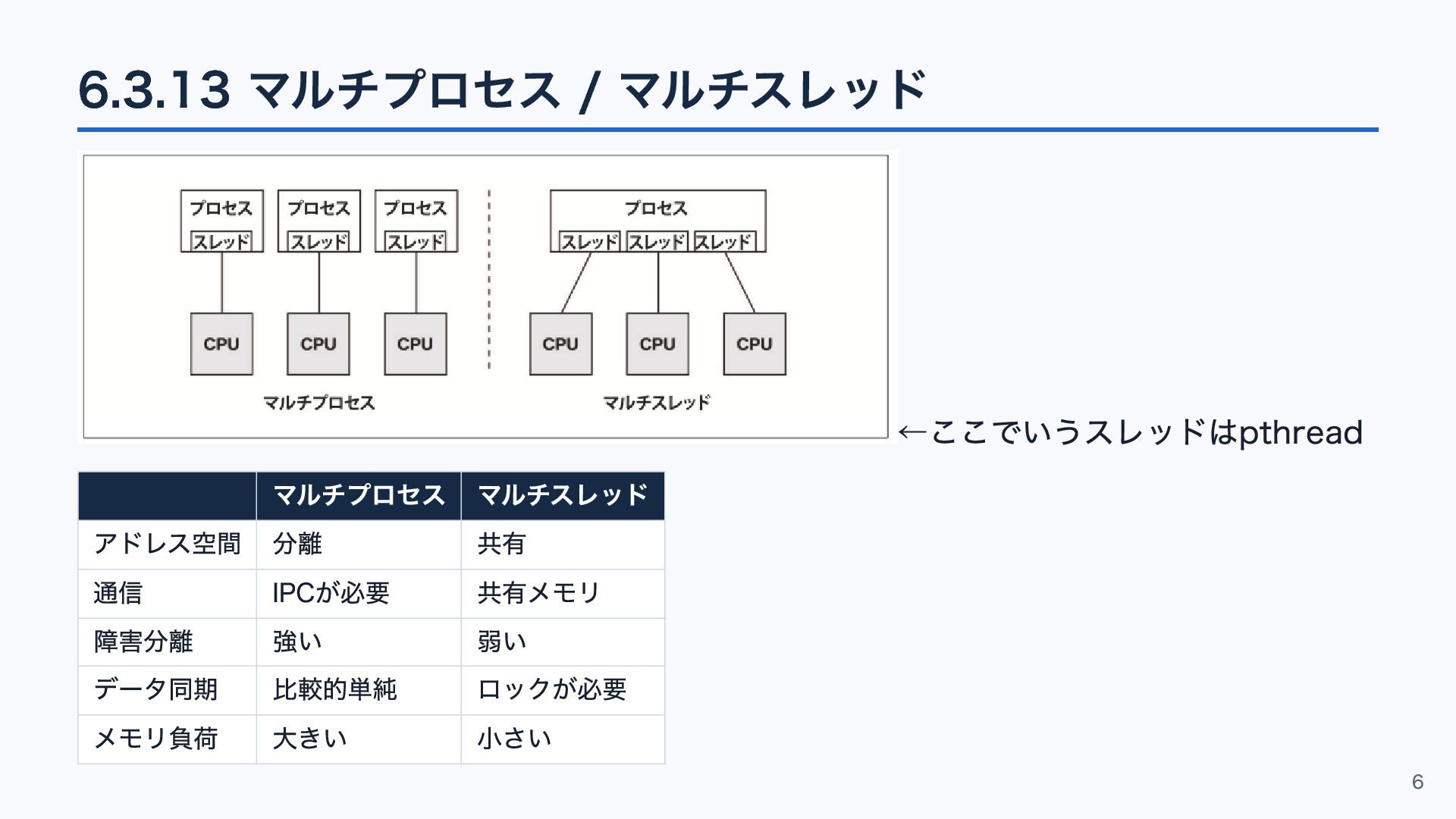
6.3.13 マルチプロセス / マルチスレッド ←ここでいうスレッドはpthread マルチプロセス マルチスレッド アドレス空間 分離 共有
通信 IPCが必要 共有メモリ 障害分離 強い 弱い データ同期 比較的単純 ロックが必要 メモリ負荷 大きい 小さい 6
6.3.14 ワードサイズ ワードサイズはレジスタのサイズ,ポインターのサイズに対応する 大きいワードは一度に扱える情報量を増やす 一方,ポインターのサイズが大きくなるため,メモリ使用量が多くなる場合がある 連結ノードや木などのデータ構造ではポインターを含む構造体を大量に作る ポインターのサイズ増加がアプリ自体のメモリ使用量を大きく増やし得る struct Node {
int value; // 4B struct Node* next; // 4B なら構造体は8B .8B の場合16B }; 同じページサイズ,キャッシュ容量の時,格納できる変数の数が減りキャッシュヒット率 が下がるおそれもある 7
6.3.15 コンパイラ最適化 Cコンパイラだと -O2 とかで設定できる 最適化の手法は無限にある コンパイル時に計算できる定数の畳み込み,伝播 インライン展開 末尾再帰最適化 SIMD命令の利用
etc. コンパイラのバージョン変更だけで結果が変わり得るため,バージョンも測定条件になる. 8
6.4 ハードウェア 9
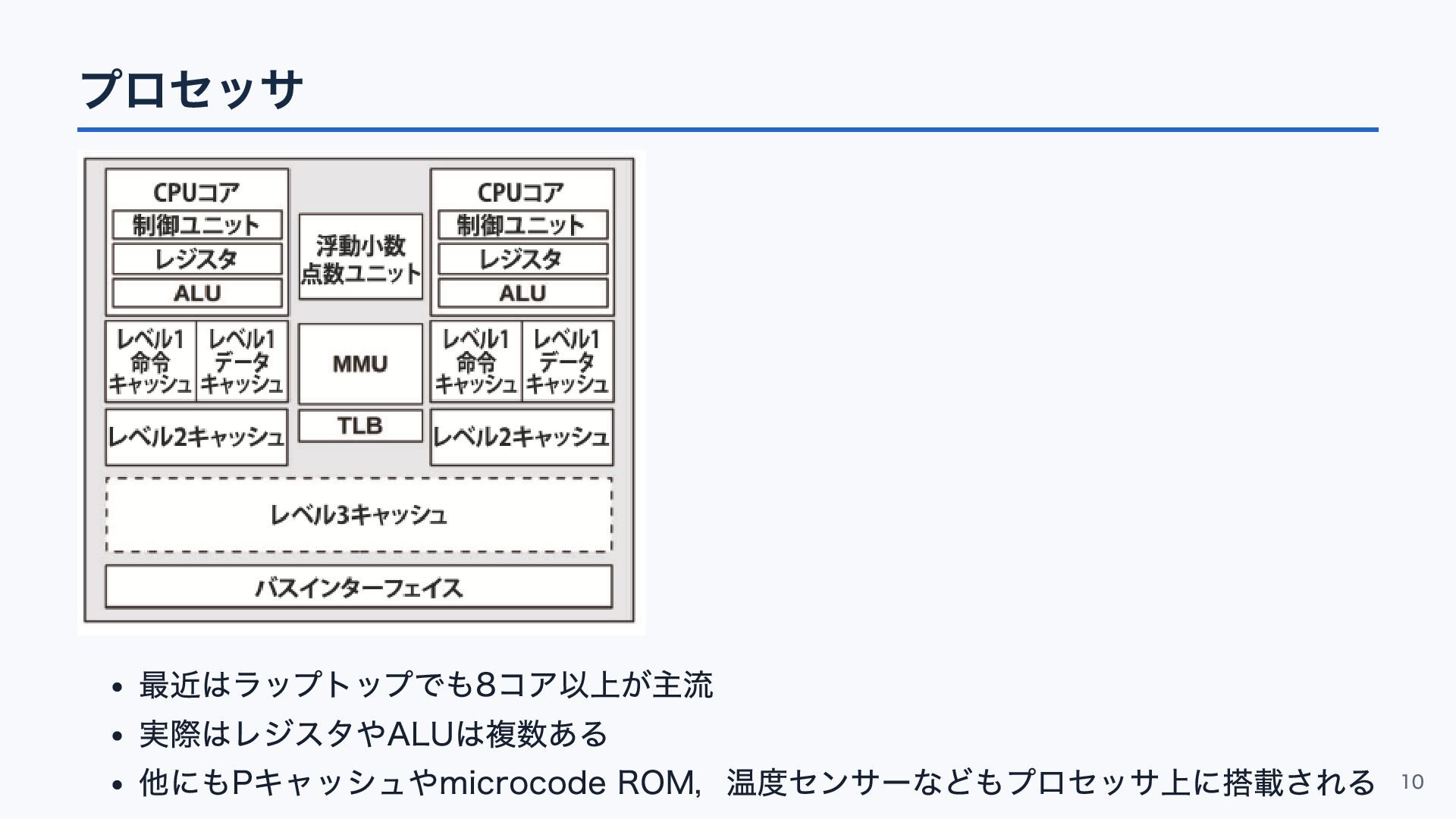
プロセッサ 最近はラップトップでも8コア以上が主流 実際はレジスタやALUは複数ある 他にもPキャッシュやmicrocode ROM,温度センサーなどもプロセッサ上に搭載される 10
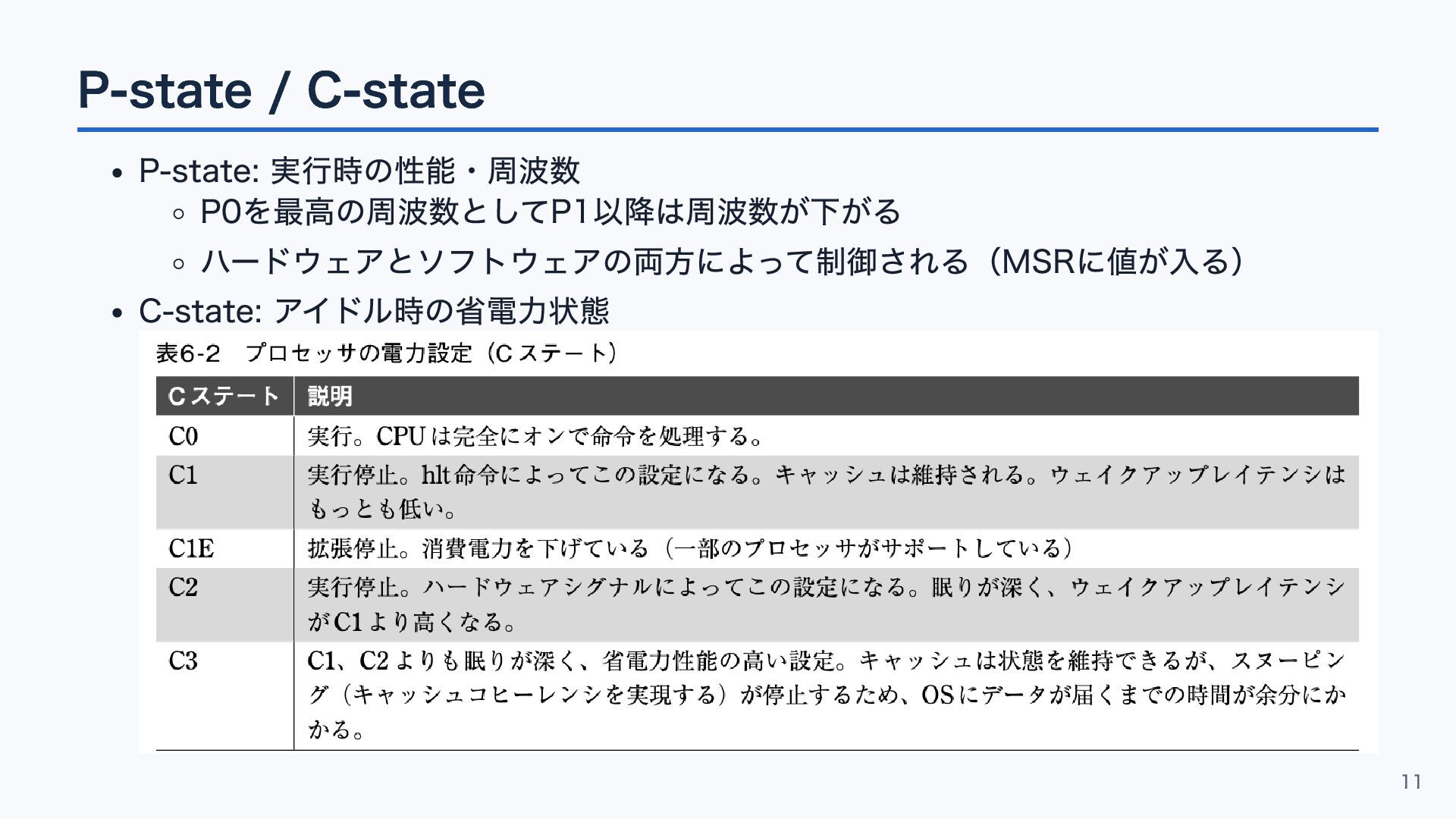
P-state / C-state P-state: 実行時の性能・周波数 P0を最高の周波数としてP1以降は周波数が下がる ハードウェアとソフトウェアの両方によって制御される(MSRに値が入る) C-state: アイドル時の省電力状態 11
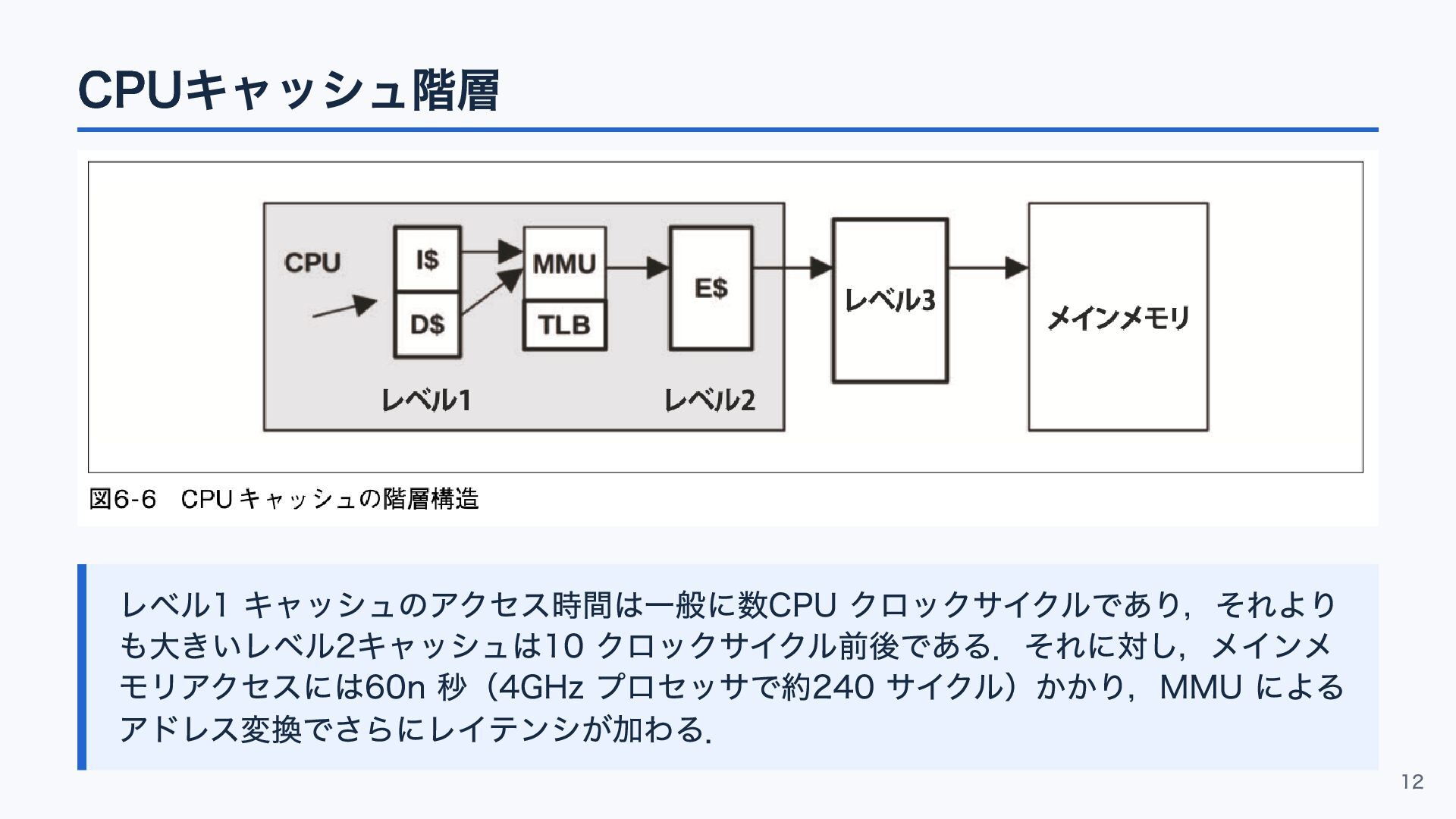
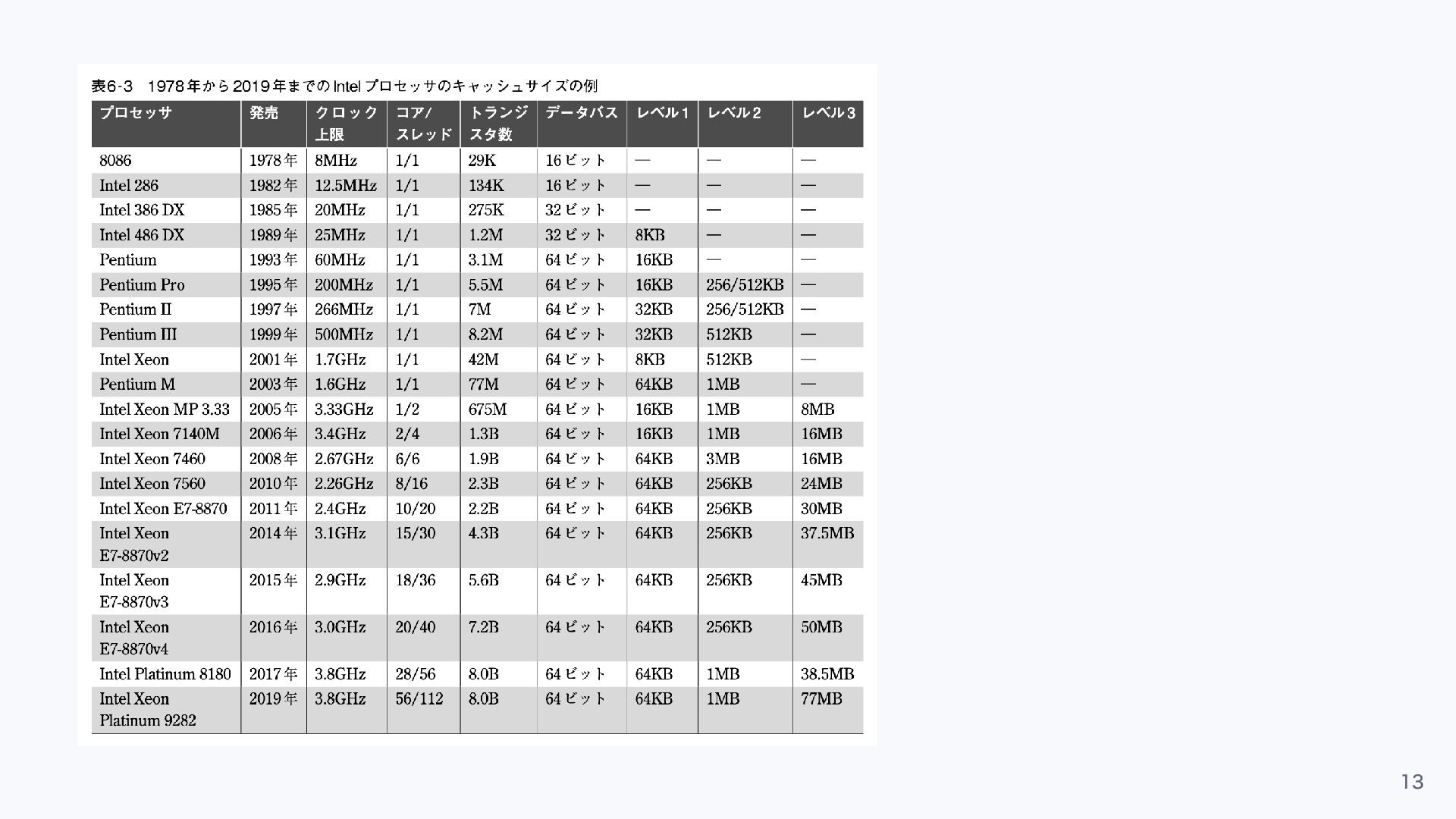
CPUキャッシュ階層 レベル1 キャッシュのアクセス時間は一般に数CPU クロックサイクルであり,それより も大きいレベル2キャッシュは10 クロックサイクル前後である.それに対し,メインメ モリアクセスには60n 秒(4GHz プロセッサで約240 サイクル)かかり,MMU
による アドレス変換でさらにレイテンシが加わる. 12
13
キャッシュの連想度 ダイレクトマップもフルアソシアティブも,セットアソシアティブの部分集合といえる 14
キャッシュラインとコヒーレンシ キャッシュは通常,1変数ではなくライン単位で転送 x86だと典型的には64バイト コアごとにキャッシュが分かれていても常に正しい状態のメモリにアクセスしたい MESI/MOESIなどのCoherency担保のプロトコルを使う (TODO: MESI/MOESIの説明) 15
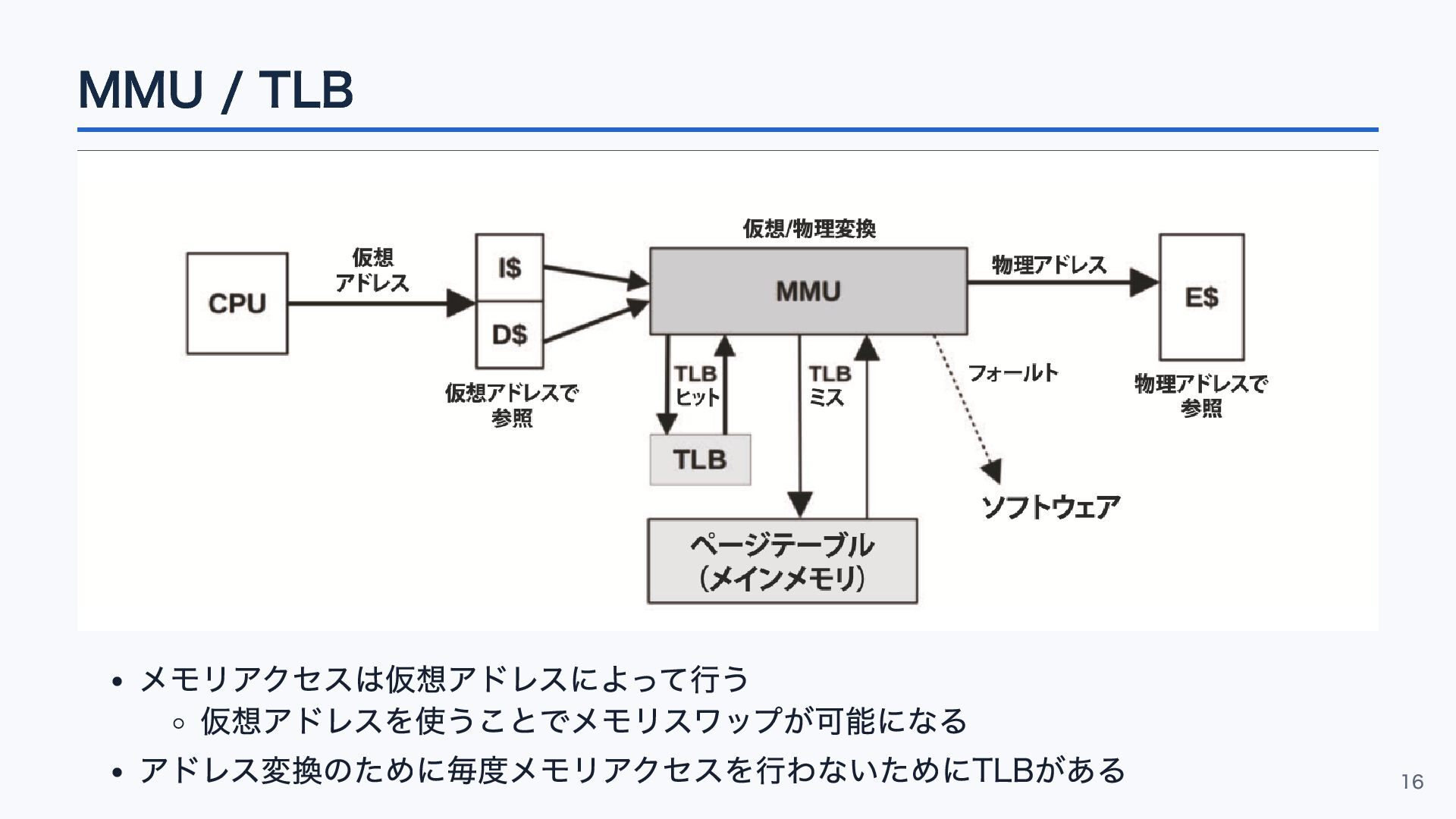
MMU / TLB メモリアクセスは仮想アドレスによって行う 仮想アドレスを使うことでメモリスワップが可能になる アドレス変換のために毎度メモリアクセスを行わないためにTLBがある 16
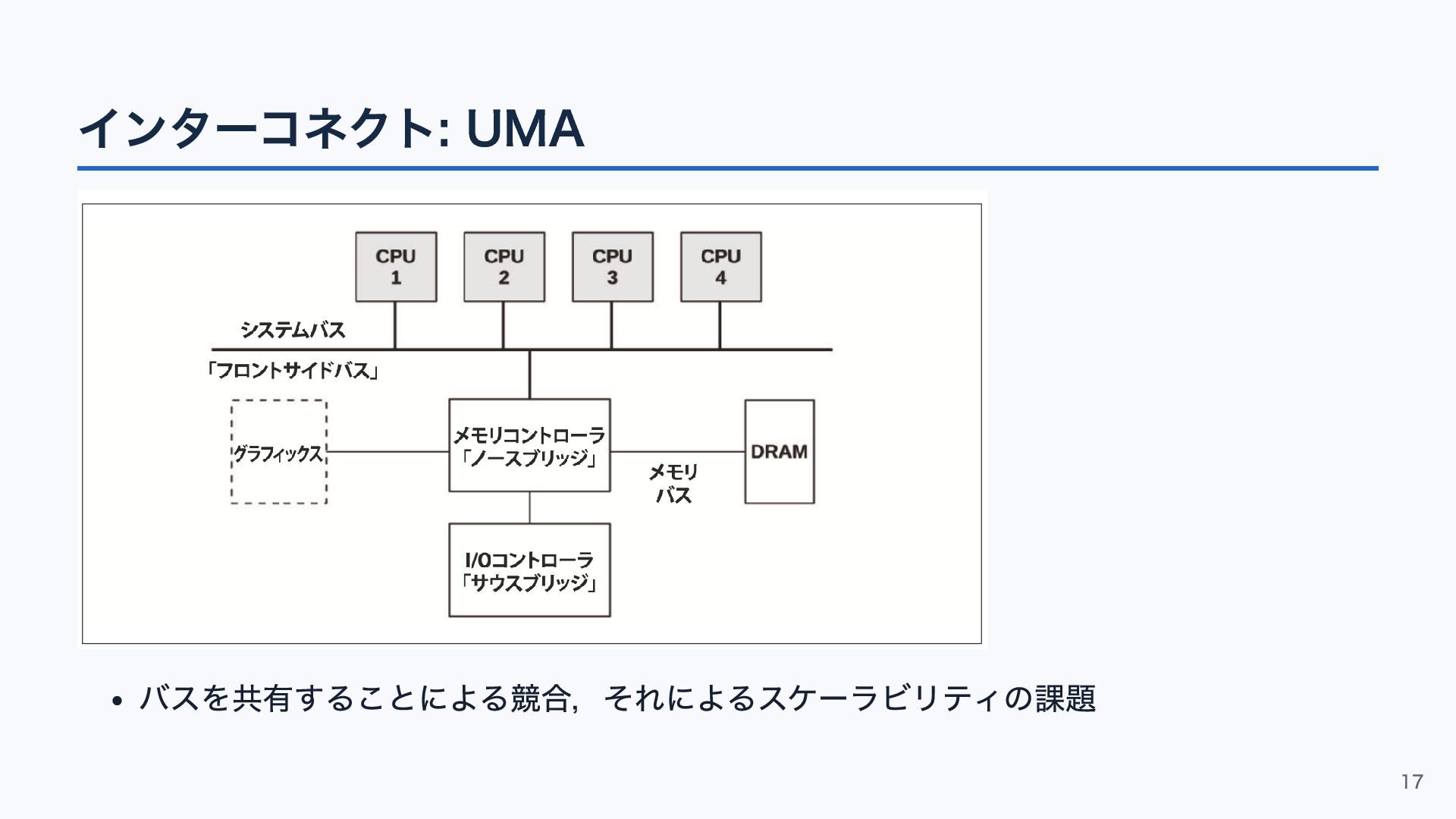
インターコネクト: UMA バスを共有することによる競合,それによるスケーラビリティの課題 17
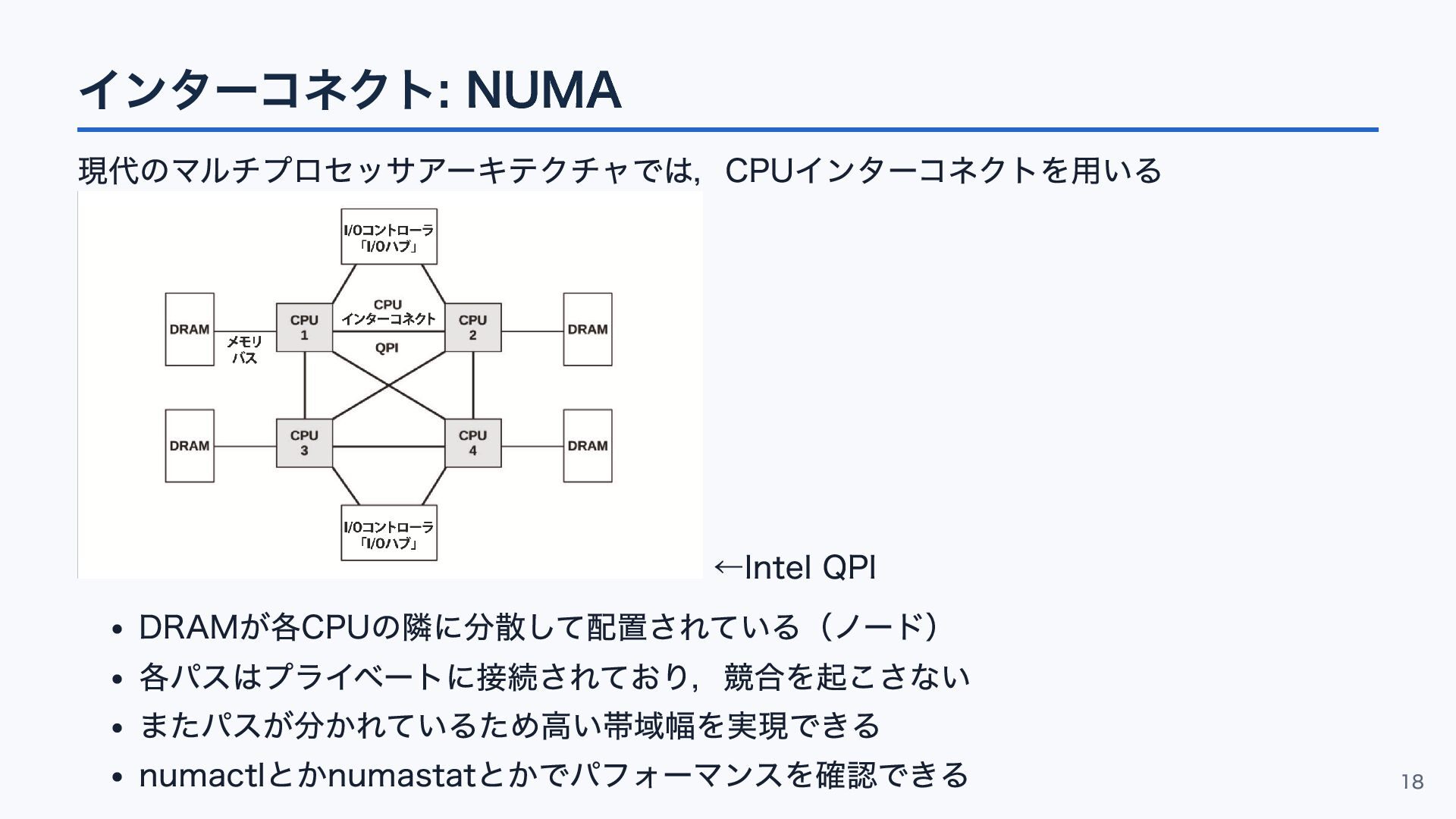
インターコネクト: NUMA 現代のマルチプロセッサアーキテクチャでは,CPUインターコネクトを用いる ←Intel QPI DRAMが各CPUの隣に分散して配置されている(ノード) 各パスはプライベートに接続されており,競合を起こさない またパスが分かれているため高い帯域幅を実現できる numactlとかnumastatとかでパフォーマンスを確認できる 18
Performance Monitoring Counter (PMC) CPUのアクティビティに関するカウンタ CPUサイクル 命令フェッチ キャッシュアクセス(ヒット/ミス) float演算 メモリIO
リソースIO 例えばIntel P6では,4つのMSRレジスタでPMCを提供している 2個はevent-select,2個は読み出し専用のカウンタ またArm8-A/9-Aではサイクルカウンタは固定,カウンタは30個ある 19
GPU ストリーミングプロセッサ(SP)というスレッドを実行できる小さなコア数千個を含む 並列実行できるスレッド群はスレッドブロックという単位にまとめられ,SPの集合であ るストリーミングマルチプロセッサ(SM)によって実行される 20
ソフトウェア: スケジューラ タイムシェアリング プリエンプション CPU間ロードバランシング キャッシュ局所性を考慮したマイグレーション Linuxでは タイマー割り込み scheduler_tick() :
現在のタスクの使用時間更新,クラスごとのtick呼び出し check_preempt_curr() : wakeupしたタスクと現在タスクの比較(優先度など) __schedule() : need_resched=1 の時,現在のタスクをランキューに戻す pick_next_task() : 次のタスクを選ぶ 21
6.5 分析メソドロジ 22
6.5.1 ツールメソッド 利用できるツールを順に試し,主要な指標から手がかりを探す. ツール 見るもの uptime , top ロードアベレージの増減 vmstat
システム全体のCPU使用率 mpstat CPUごとの偏り,ホットCPU top , pidstat CPUを使うプロセス・スレッド perf , profile CPUが使われるコードパス showboost , turbostat , dmesg 周波数低下や温度スロットリング 弱点: ツールで直接見えない問題を見落としやすい. 23
6.5.2 USEメソッド CPUごとに,ボトルネックとエラーを初期調査する. 観点 CPUでの意味 Utilization アイドル以外を実行していた時間の割合 Saturation 実行可能だがon-CPUを待つスレッド Errors
corrected error,offline CPUなど エラーは解釈しやすいので最初に確認する 使用率はシステム全体ではなくCPU単位でも見る クラウドでは物理CPUだけでなく,CPUクォータに対する使用率も見る GPUなどのアクセラレータも,取れる指標があれば同じ考え方で見る 24
6.5.3 ワークロードの特性の把握 ロードアベレージ(使用率 + 飽和度) ユーザー時間 / システム時間の比率 システムコールの頻度 自発的コンテキストスイッチの頻度
割り込みの頻度 追加で確認する問い: CPU使用率はシステム全体・CPUごと・コアごとでどうか 負荷はどれだけ並列化されているか どのアプリ・ユーザー・カーネルスレッドがCPUを使うか 割り込み,インターコネクト,コールパス,ストールサイクルはどうか 時間帯ごと,時期ごとのそれぞれの特性はどのように変化するか 25
6.5.4 プロファイリング CPUが使われている理由を,実行中のコードパスから見る. タイマーベース 99Hzなど若干周波数をずらして関数/スタックトレースのサンプルを収集する 本番環境では収集時間を伸ばして頻度を下げるなど,オーバーヘッドにならないよう にする profile ではプロファイリング結果の要約を出力する 長時間のプロファイルだとファイルの書き出し時に無視できないディスクIOが発
生するため 関数のトレーシング 関数の前後に計測処理を入れるなどして所要時間を計測する タイマーベースと比較してオーバーヘッドが大きいので本番環境ではあまり使われな い 26
6.5.5 サイクル分析 PMCを使い,CPUサイクルがどこで消費・停止しているかを見る. 主にIPC(Instruction Per Cycle)を見る IPCが低い: 1命令の実行に時間がかかっている(平均) ストールしているサイクルを特定する I/Dキャッシュミス,分岐予測失敗など
IPCが高い: 命令の実行時間は問題がない≒単純に命令数が多い 命令数を減らす 27
6.5.7 静的パフォーマンスチューニング 動いているワークロードではなく,構成された環境の問題を調べる. チェック項目: 利用可能なCPU数は何個か.コアかハードウェアスレッドか GPUなどのアクセラレータはあるか,使われているか CPUアーキテクチャ,キャッシュサイズ,共有関係はどうか クロックスピードは固定か動的か.Turbo Boost /
SpeedStepは有効か BIOSの省電力・バス・CPU関連機能はどう設定されているか プロセッサやBIOSのエラッタに性能問題はあるか マイクロコード更新や脆弱性緩和が性能に影響していないか(?) クラウドではリソース制限も確認する必要がある(cgroup) 28
6.5.8 優先度のチューニング nice : 正の値で優先度を下げ,負の値で優先度を上げる renice : 実行中プロセスのnice値を変更する 優先度の低い処理例: 監視エージェント,バックアップ,バッチ処理
効果の確認: 優先度の高い要求のスケジューラレイテンシが下がるか 低優先度側の遅延が許容できるか スケジュールクラスもユーザーレベルで指定できる リアルタイムクラスで無限ループなどのバグを仕込むと管理シェルなど修正に必要なプロ セスがCPUを使えなくなる場合がある 29
6.5.10 CPUのバインド スレッドを特定のコア(orコアのグループ)にバインドする手法がある キャッシュのヒット率が向上しメモリIOの速度が上がる あるコアを特定のスレッドのみ使えるようにする排他的CPUセットもある 他のスレッドは実行され得ないのでよりキャッシュのヒット率が上がる メモリIOが非常に重要なタスクや性能検証の場合に使える 30
6.5.11 マイクロベンチマーキング 単純な操作を大量に繰り返し,CPUの特定能力を測る. 対象例: CPU命令: 整数演算,浮動小数点演算,ロード/ストア,分岐 メモリアクセス: キャッシュレイテンシ,メモリスループット 高水準言語: インタープリタ/コンパイル言語の処理
OS操作: getpid(2) ,プロセス作成,パイプスループット どのベンチマークを使う場合でも、システム間で結果を比較するときには、実際に何を テストしているのかを理解していることが大切だ。これらのベンチマークは、ベンチマ ークコードやCPU のスピードではなく、コンパイラの異なるバージョンの間で、コンパ イラの最適化機能をテストするだけになってしまっていることがよくある。 31
6.6 可観測性ツール 32
6.9 チューニング 不要な仕事を取り除く 優先順位: 1. 不要な処理をしない 2. 呼び出し回数を減らす 3. データ移動を減らす
4. 局所性を上げる 5. 高価な演算を置き換える 6. 最後に並列化・CPU固定・OS設定 環境チューニングは,コード上の無駄を隠すことがある. 33
{kind=link}
{kind=link}
{kind=link}
![6.3.11 プリエンプション 優先度の高い実行可能スレッドが,実行中スレッドからCPUを奪う. 低優先度スレッド: [========= 実行 =] [========= 実行 ======]](https://files.speakerdeck.com/presentations/53bb13ca983141c189860a69f6ef1ee4/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}