Detection in Text | Kuncahyo Setyo Nugroho ▪ Software Engineer ITC and Data Center, Widya Gama University, Indonesia ▪ Master Student of Computer Science Faculty of Computer Science, Brawijaya University, Indonesia Intelligent System Laboratory Affective Computing Research Interest Group ▪ Research Interest Artificial Intelligence, Affective Computing, Natural Language Processing 2
in Text | Kuncahyo Setyo Nugroho 4 • Current state-of-the-art in Natural Language Processing (NLP) • What makes BERT "special" and evolved? • How does BERT see the context? • BERT fine-tuning for text-based emotion detection in Indonesian • Future work
Detection in Text | Kuncahyo Setyo Nugroho 6 • Humans learn words from environment and experience, but the machine has no such context. • Word embedding are the basics of deep learning for NLP. • Word is a symbolic representation of semantic. • It has meaning; • Words with similar meanings should have similar vectors; • The distance between vectors for the same concepts should be similar.
on Emotion Detection in Text | Kuncahyo Setyo Nugroho 7 • Word2Vec in 2013 https://arxiv.org/abs/1301.3781 • GloVe in 2014 https://nlp.stanford.edu/pubs/glove.pdf • FastText in 2016 https://arxiv.org/abs/1607.04606
on Emotion Detection in Text | Kuncahyo Setyo Nugroho 8 • Problem: Some words have different meanings (homonym and polysemy) • Word embeddings are applied in a context-free manner • Solution: train contextual representations on a text corpus
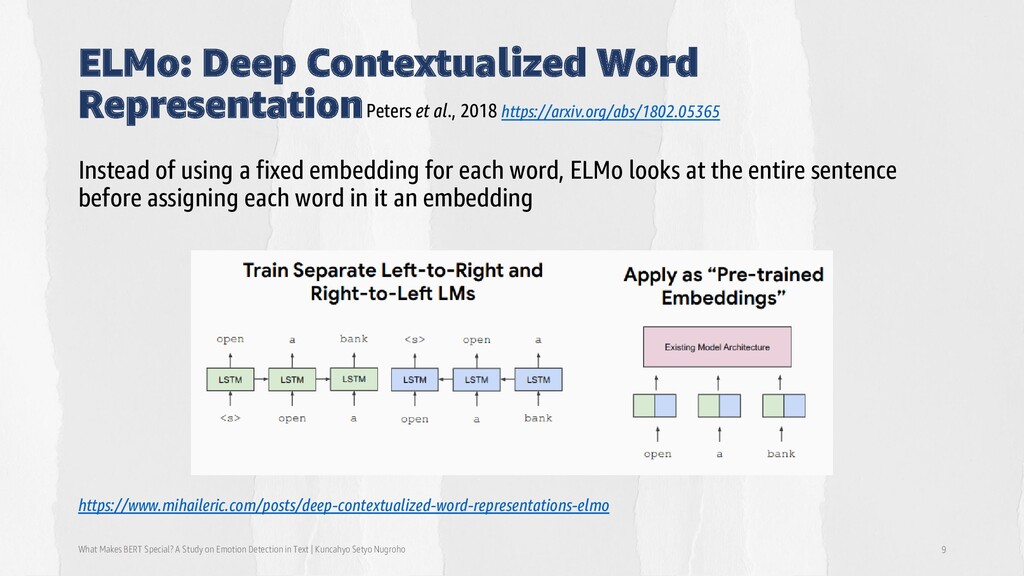
Study on Emotion Detection in Text | Kuncahyo Setyo Nugroho 9 Instead of using a fixed embedding for each word, ELMo looks at the entire sentence before assigning each word in it an embedding https://www.mihaileric.com/posts/deep-contextualized-word-representations-elmo Peters et al., 2018 https://arxiv.org/abs/1802.05365
Text | Kuncahyo Setyo Nugroho 10 What makes BERT “Special” and Evolved? 02 BERT (Bidirectional Encoder Representations from Transformers) Devlin et al., 2018 https://arxiv.org/abs/1810.04805
in Text | Kuncahyo Setyo Nugroho 11 • Problem: Language models only use left context or right context, but language understanding is bidirectional. • Why are LMs unidirectional? • Directionality is needed to generate a well-formed probability distribution • Words can “see themselves” in a bidirectional encoder
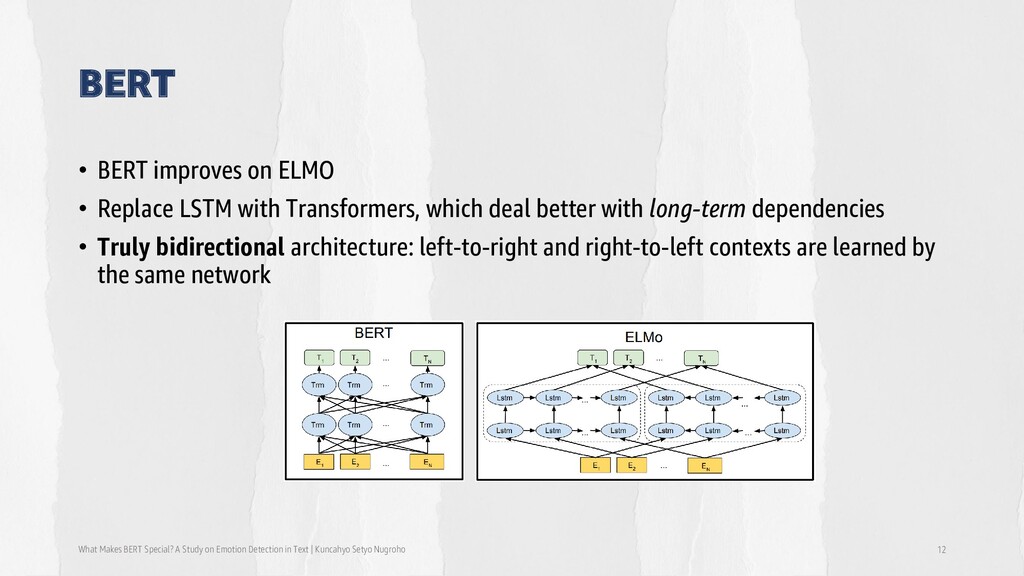
in Text | Kuncahyo Setyo Nugroho 12 • BERT improves on ELMO • Replace LSTM with Transformers, which deal better with long-term dependencies • Truly bidirectional architecture: left-to-right and right-to-left contexts are learned by the same network
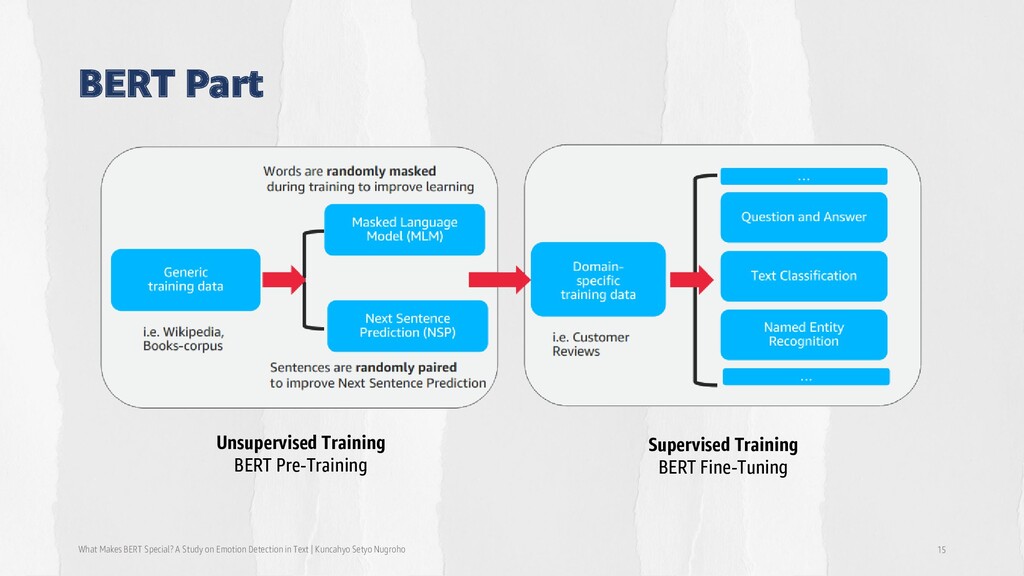
on Emotion Detection in Text | Kuncahyo Setyo Nugroho 13 Mask out k% of the input words, and then predict the masked words. Input: the man went to the [MASK1] he bought a [MASK2] of milk Labels: [MASK1] = store; [MASK2] = gallon
on Emotion Detection in Text | Kuncahyo Setyo Nugroho 14 Learn relationships between sentences, predict whether Sentence B is actual sentence that proceeds Sentence A, or a random sentence Sentence A: the man went to the store. Sentence B: he bought a gallon of milk. Label: IsNextSentence
Text | Kuncahyo Setyo Nugroho 17 BERT under covers: How does BERT see the context? 03 Transformers (Attention Is All You Need) Vaswani et al., 2017 https://arxiv.org/abs/1706.03762
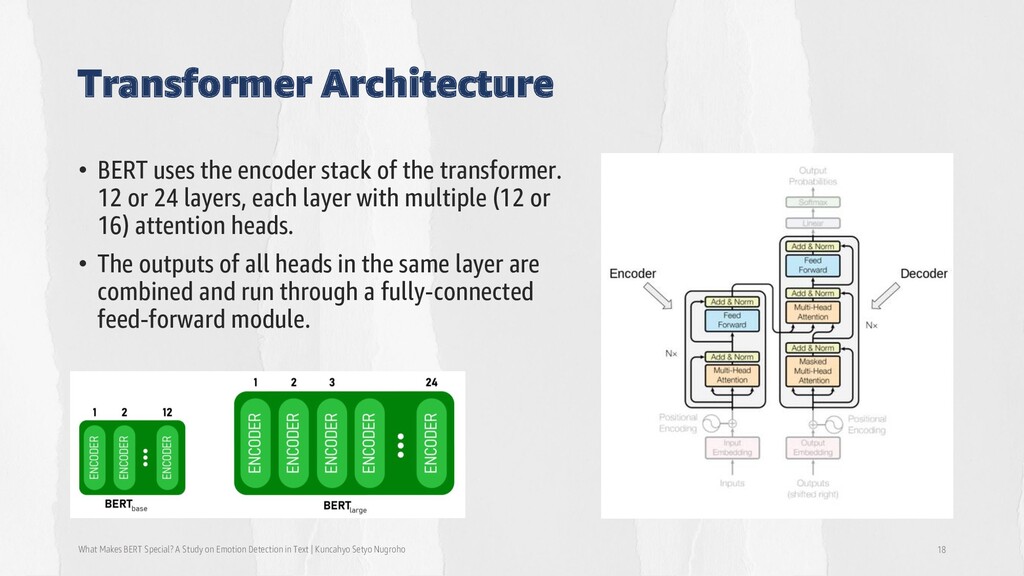
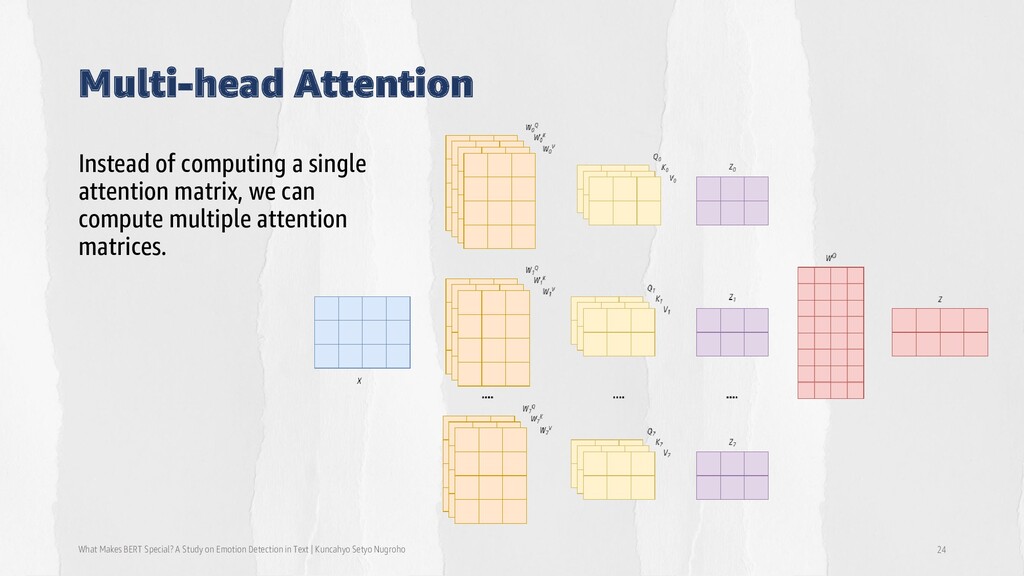
Detection in Text | Kuncahyo Setyo Nugroho 18 • BERT uses the encoder stack of the transformer. 12 or 24 layers, each layer with multiple (12 or 16) attention heads. • The outputs of all heads in the same layer are combined and run through a fully-connected feed-forward module.
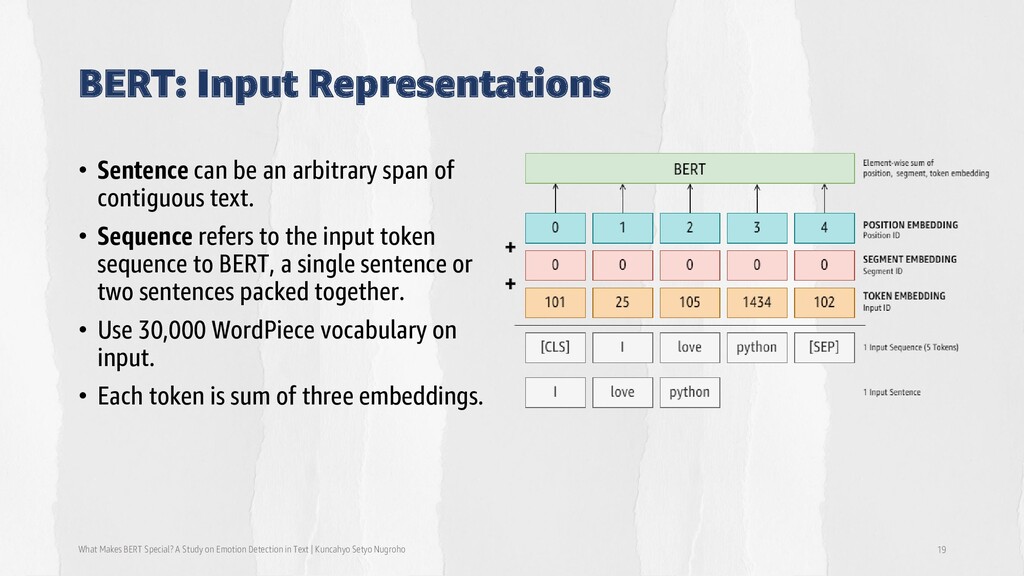
Emotion Detection in Text | Kuncahyo Setyo Nugroho 19 • Sentence can be an arbitrary span of contiguous text. • Sequence refers to the input token sequence to BERT, a single sentence or two sentences packed together. • Use 30,000 WordPiece vocabulary on input. • Each token is sum of three embeddings.
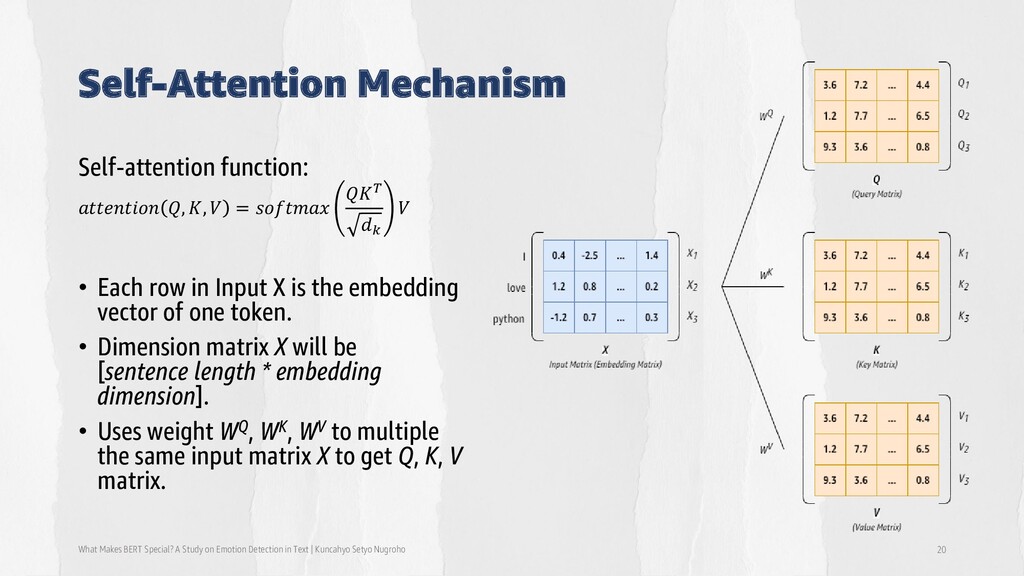
Detection in Text | Kuncahyo Setyo Nugroho 20 Self-attention function: 𝑎𝑡𝑡𝑒𝑛𝑡𝑖𝑜𝑛 𝑄, 𝐾, 𝑉 = 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑄𝐾𝑇 𝑑𝑘 𝑉 • Each row in Input X is the embedding vector of one token. • Dimension matrix X will be [sentence length * embedding dimension]. • Uses weight WQ, WK, WV to multiple the same input matrix X to get Q, K, V matrix.
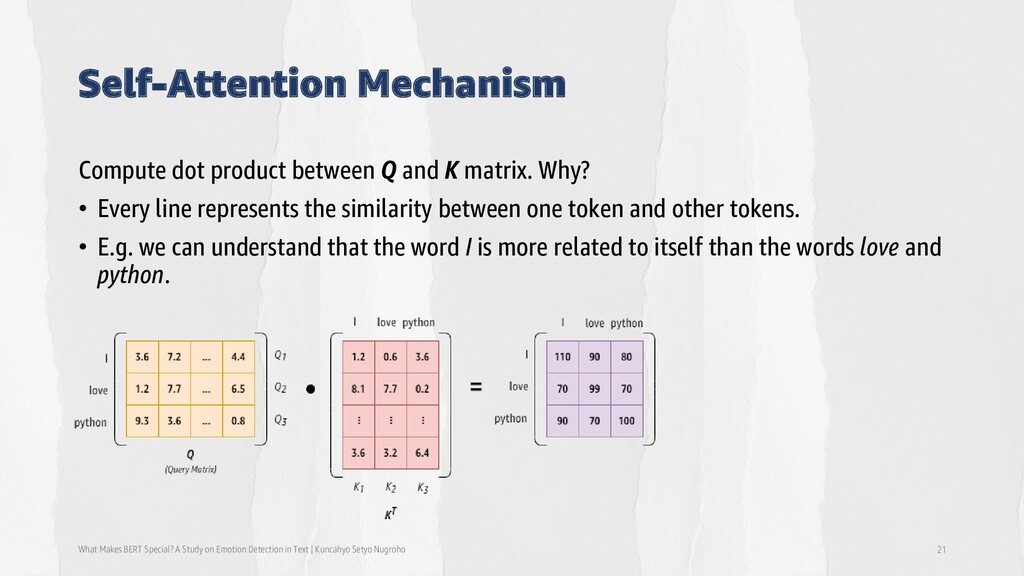
Detection in Text | Kuncahyo Setyo Nugroho 21 Compute dot product between Q and K matrix. Why? • Every line represents the similarity between one token and other tokens. • E.g. we can understand that the word I is more related to itself than the words love and python.
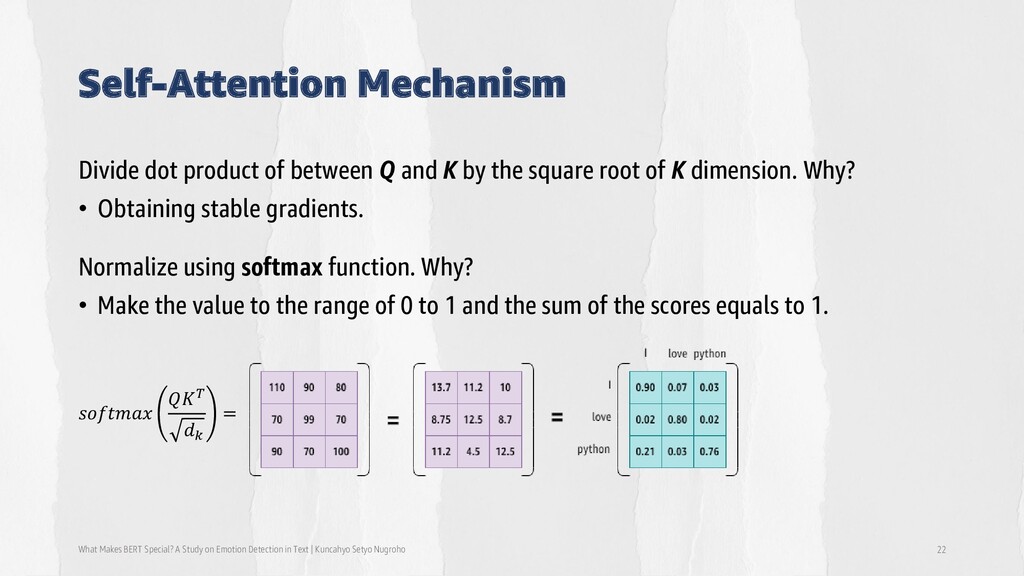
Detection in Text | Kuncahyo Setyo Nugroho 22 Divide dot product of between Q and K by the square root of K dimension. Why? • Obtaining stable gradients. Normalize using softmax function. Why? • Make the value to the range of 0 to 1 and the sum of the scores equals to 1. 𝑠𝑜𝑓𝑡𝑚𝑎𝑥 𝑄𝐾𝑇 𝑑𝑘 =
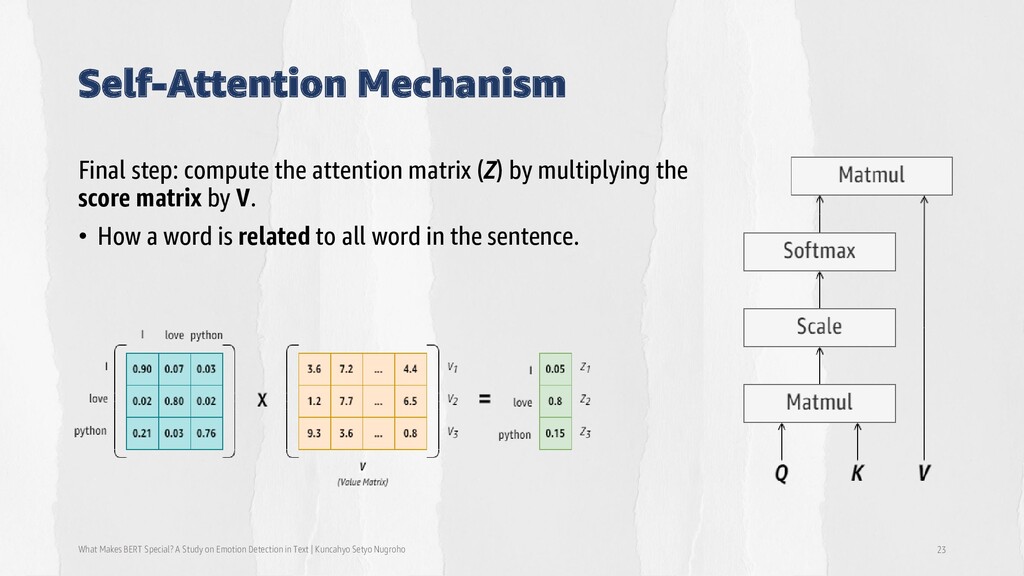
Detection in Text | Kuncahyo Setyo Nugroho 23 Final step: compute the attention matrix (Z) by multiplying the score matrix by V. • How a word is related to all word in the sentence.
on Emotion Detection in Text | Kuncahyo Setyo Nugroho 25 Open source tool for visualizing attention in Transformer models https://github.com/jessevig/bertviz Attention Head View Neuron View
Emotion Detection in Text | Kuncahyo Setyo Nugroho 27 • Dataset • Computing resource • Code • A cup of coffee ☕ Challenge: • Need more data, more and more … • Powerful computer resource (GPU or TPU)
on Emotion Detection in Text | Kuncahyo Setyo Nugroho 30 # Pre-Trained Name Author Dataset 1 BERT multilingual Devlin et al., 2018 •104 language from Wikipedia dump 2 IndoBERT Wilie et al., 2020 •Indo4B dataset (4B words / 250M sentences) 3 IndoBERT Koto et al., 2020 •Indonesian Wikipedia (74M words) •News articles (55M words) •Indonesian Web Corpus (90M words) 4 IndoBERTweet Koto et al., 2021 26M tweets (409M word tokens) https://huggingface.co
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}