Characterizing and Contrasting Container Orchestrators
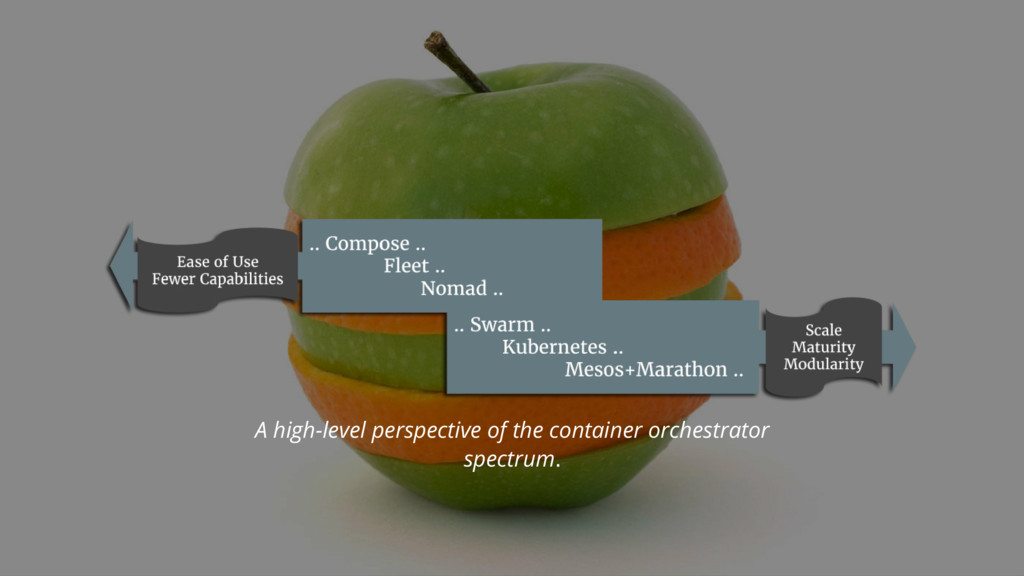
Running a few containers? No problem. Running hundreds or thousands? Enter the container orchestrator. Let’s take a look at the characteristics of the three most popular container orchestrators and what makes them alike, yet unique.
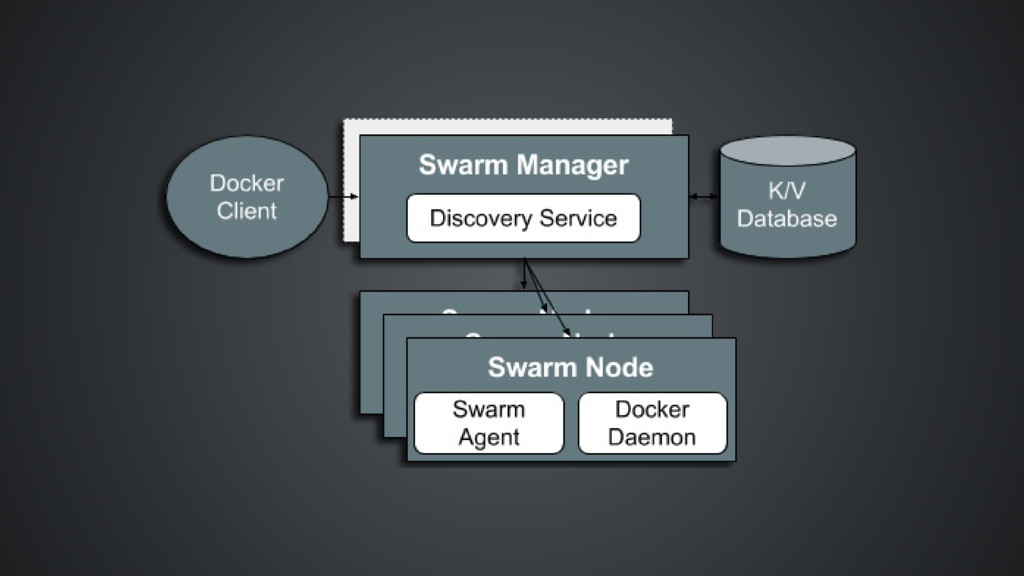
An imperative system, Swarm is responsible for the clustering and scheduling aspects of orchestration. Swarm’s architecture is not complex as those of Kubernetes and Mesos has Manager(s) and Agent(s) Written in Golang, Swarm is lightweight, modular, portable, and extensible
contributors in all), and for Docker Compose, the numbers are approximately the same Swarm leverages the same API for Docker engine which over 23,000 commits and 1,350 contributors ~250 Docker meetups worldwide Announced as production-ready 5 months ago (Nov 2015) image: digital trends
of clusters by the Manager to discover for Nodes (hosts). Service Discovery Swarm has a concept of services through network aliases and round robin DNS image: iStock
of strategies and filters/constraint: Strategies Random Binpack Spread* Filters container constraints (affinity, dependency, port) are defined as environment variables in the specification file node constraints (health, constraint) must be specified when starting the docker daemon and define which nodes a container may be scheduled on. image: pickywallpapers
Docker’s networking Docker multi-host networking (requires a K/V store) provides for user-defined overlay networks that are micro-segmentable uses a gossip protocol for quick convergence of neighbor table facilitates container name resolution via embedded DNS server (previously via etc/hosts) You may bring your own network driver Load-balancing is new in 1.11.0 - no documentation available
highly-available configuration (out of experimental in 1.11.0) Active/Standby - an active manager and replicas configuration Rescheduling upon node failure (experimental in 1.11.0) and simple. Rebalancing is not available Rescheduled containers lose access to volumes mounted on the former host. use volume plugins like Flocker to avoid this Does not support multiple failure isolation regions or federation (although, with caveats, ). this is possible
functionality for application containers Swarm is a young project and lacks advanced features. High Availability out of experimental as of latest release (1.11.0) Rescheduling is experimental in 1.11.0 (no Rebalancing, yet) Load-balancing in 1.11.0? Swarm needs to be used with third-party software. Only schedules Docker containers, not containers using other specifications. While dependency and affinity filters are available, Swarm does not provide the ability to enforce scheduling of two containers onto the same host or not at all. Current filters do not facilitate sidecar pattern. No “pod” concept. Swarm works. Swarm is simple and easy to deploy. If you already know Docker CLI, using Swarm is straight-forward facilitates earlier stages of adoption by organizations viewing containers as faster VMs Less built-in functionality for applications Swarm is easy to extend, if can already know Docker APIs, you can customize Swarm Highly modular: Pluggable scheduler Pluggable K/V store for both node and multi- host networking
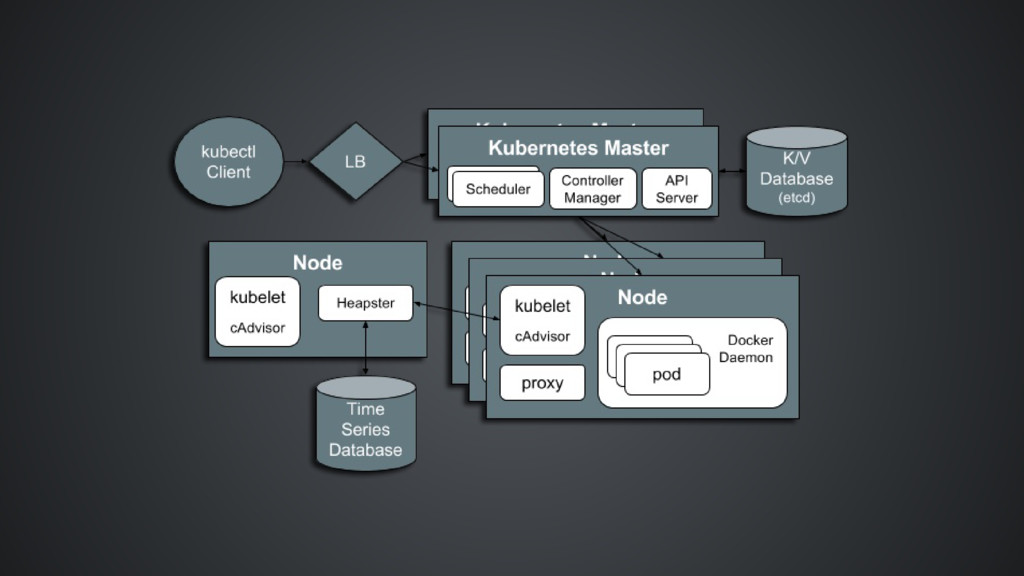
or as its tagline states "an open source system for automating deployment, scaling, and operations of applications." Written in Golang, Kubernetes is lightweight, modular, portable, and extensible considered a third generation container orchestrator led by Google, Red Hat and others. bakes in load-balancing, scale, volumes, deployments and secret management among other features. Declaratively, opinionated with many key features included
Announced as production-ready 10 months ago (July 2015) Project currently has over 1,000 commits per month (~23,000 total) made by about 100 (650 total) Kubernauts (Kubernetes enthusiasts). ~5,000 commits made in the latest release - 1.2. Under the governance of the Cloud Native Computing Foundation Robust set of documentation and ~90 meetups
agent (kubelet) is configured to register itself with the master (API server) automating the joining of new hosts to the cluster. Service Discovery Two primary modes of finding a Service environment variables environment variables are used as a simple way of providing compatibility with Docker links-style networking DNS when enabled is deployed as a cluster add-on image: iStock
criteria used by kube-scheduler to identify the best- fit node is defined by policy: Predicates (node resources and characteristics): PodFitPorts , PodFitsResources, NoDiskConflict , MatchNodeSelector, HostName , ServiceAffinit, LabelsPresence Priorities (weighted strategies used to identify “best fit” node): LeastRequestedPriority, BalancedResourceAllocation, ServiceSpreadingPriority, EqualPriority
Choice of: database for service discovery or network driver container runtime users may choose to run Docker with Rocket containers Cluster add-ons optional system components that implement a cluster feature (e.g. DNS, logging, etc.) shipped with the Kubernetes binaries and are considered an inherent part of the Kubernetes clusters
updating applications. Kubernetes Components Upgrading the Kubernetes components and hosts is done via shell script Host maintenance - mark the node as unschedulable. existing pods are not vacated from the node prevents new pods from being scheduled on the node image: 123RF
nodes within the cluster via Node Controller Resources - usage monitoring leverages a combination of open source components: cAdvisor, Heapster, InfluxDB, Grafana Applications three types of user-defined application health-checks and uses the Kubelet agent as the the health check monitor HTTP Health Checks, Container Exec, TCP Socket Cluster-level Logging collect logs which persist beyond the lifetime of the pod’s container images or the lifetime of the pod or even cluster standard output and standard error output of each container can be ingested using a
scheduling flat networking with each pod receiving an IP address no NAT required, port conflicts localized intra-pod communication via localhost Load-Balancing Services provide inherent load-balancing via kube- proxy: runs on each node of a Kubernetes cluster reflects services as defined in the Kubernetes API supports simple TCP/UDP forwarding and round-robin and Docker-links- based service IP:PORT mapping.
in a highly- available configuration. Active/Standby configuration In terms of scale, v1.2 brings support for 1,000 node clusters and a step toward fully-federated clusters (Ubernetes) Application-level auto-scaling is supported within Kubernetes via Replication Controllers
Docker-only, Kubernetes requires understanding of new concepts Powerful frameworks with more moving pieces beget complicated cluster deployment and management. Lightweight graphical user interface Does not provide as sophisticated techniques for resource utilization as Mesos Kubernetes can schedule docker or rkt containers Inherently opinionated with functionality built- in. no third-party software needed to run services, load- balancing, builds in many application-level concepts and services (secrets, petsets, jobsets, daemonsets, rolling updates, etc.) Kubernetes arguably moving the quickest Relatively thorough project documentation Multi-master, Robust logging & metrics aggregation
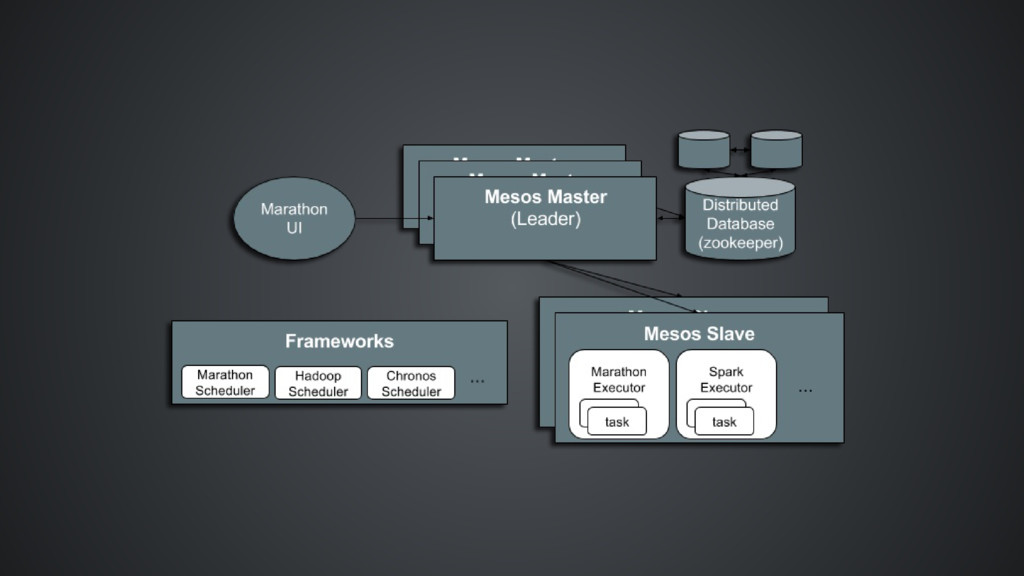
together many different machines into a logical computer Mesos has been around the longest (launched in 2009) and is arguably the most stable, with highest (proven) scale currently Mess is written in C++ with Java, Python and C++ APIs Frameworks Marathon is one of a number of frameworks (Chronos and Aurora other examples) that may be run on top of Mesos Frameworks have a scheduler and executor. Schedulers get resource offers. Executors run tasks. Marathon is written in Scala
up from 262 attendees in 2014 78 contributors in the last year Under the governance of Apache Foundation Used by Twitter, AirBnb, eBay, Apple, Cisco, Yodle
each Mesos task including Marathon application instances Marathon will ensure that all dynamically assigned service ports are unique Mesos-DNS is particularly useful when: apps are launched through multiple frameworks (not just Marathon) you are using an IP-per-container solution like you use random host port assignments in Marathon Project Calico image: iStock
master based on allocation policy , which decides which framework get resources Second level scheduling happens at Framework scheduler , which decides what tasks to execute. Provide reservations and over subscriptions
Marathon can be instructed to deploy containers based on that component using a blue/green strategy where old and new versions co-exist for a time. image: 123RF
metrics to monitor resource usage Counters and Gauges Applications support for health checks (HTTP and TCP) an event stream that can be integrated with load- balancers or for analyzing metrics
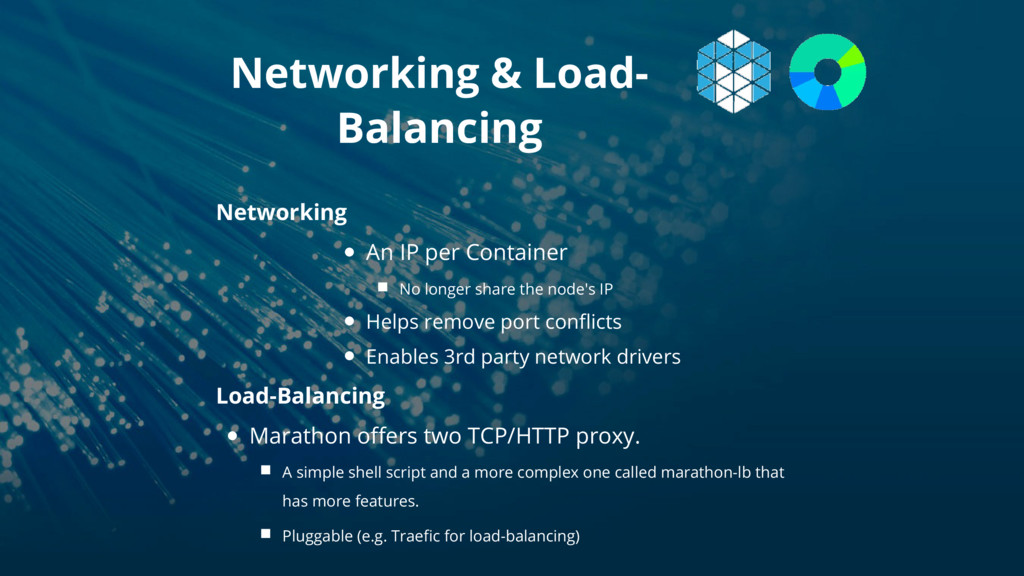
longer share the node's IP Helps remove port conflicts Enables 3rd party network drivers Load-Balancing Marathon offers two TCP/HTTP proxy. A simple shell script and a more complex one called marathon-lb that has more features. Pluggable (e.g. Traefic for load-balancing)
masters to form a quorum using ZooKeeper only one Active (Leader) Marathon master at-a-time Scale is a strong suit for Mesos. Used at Twitter, AirBnB... TBD for Marathon Great at asynchronous jobs. High availability built-in. Referred to as the “golden standard” by Solomon Hykes, Docker CTO.
run multiple frameworks, including Kubernetes and Swarm. Only of the container orchestrators that supports multi-tenancy Good for Big Data house and job-oriented or task-oriented workloads. Good for mixed workloads and with data-locality policies Powerful and scalable, Battle-tested Good for multiple large things you need to do 10,000+ node cluster system Marathon UI is young, but promising Still needs 3rd party tools Marathon interface could be more Docker friendly (hard to get at volumes and registry) May need a dedicated infrastructure IT team an overly complex solution for small deployments
{kind=link}
{kind=link}
![[kuh n-tey-ner] [awr-kuh-streyt-or] Definition:](https://files.speakerdeck.com/presentations/82da67e3994e476e91db8ef3fb28c016/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Lee Calcote linkedin.com/in/leecalcote @lcalcote blog.gingergeek.com [email protected] Thank you. Questions?](https://files.speakerdeck.com/presentations/82da67e3994e476e91db8ef3fb28c016/slide_57.jpg){kind=link}