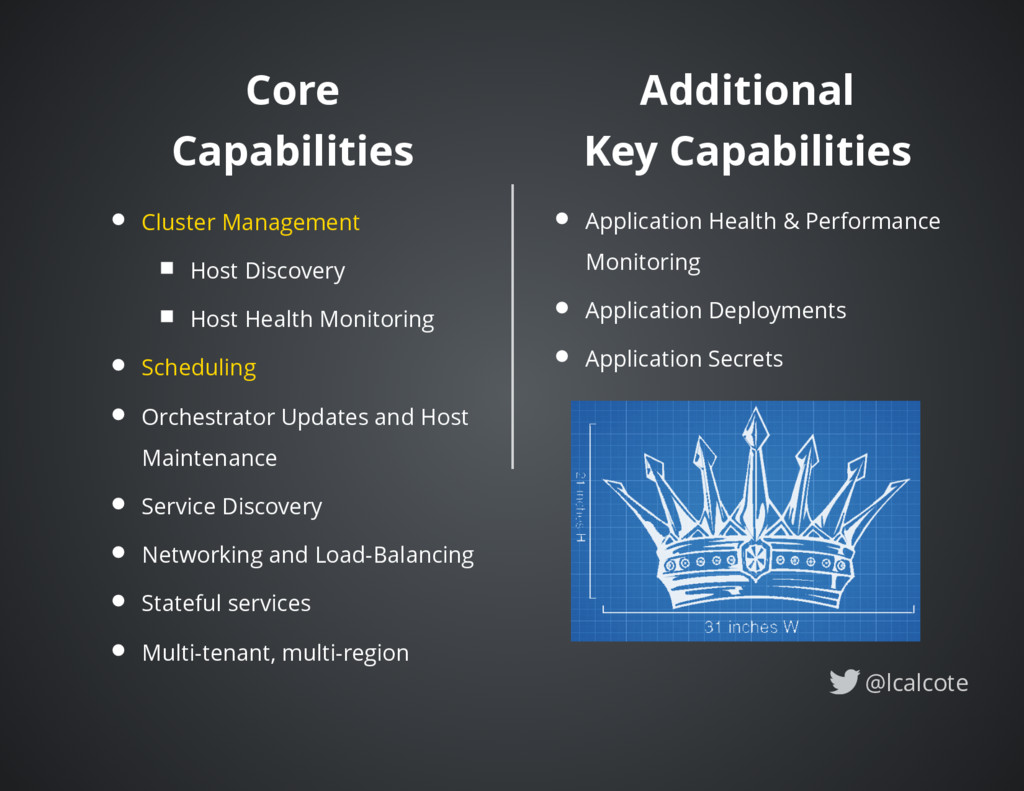
batch processing workloads. cluster manager with declarative job specifications. ensures constraints are satisfied and resource utilization is optimized by efficient task packing. supports all major operating systems and virtualized, containerized or standalone workloads. written in Go and under the Unix philosophy. @lcalcote
has 141 contributors Current release v0.5.4 Nomad Enterprise offering aimed for first half of this year. Supported and governed by HashiCorp HashiConf US '15 had ~300 attendees HashiConf EU '16 had ~320 attendees HashiConf US '16 had ~500 attendees @lcalcote
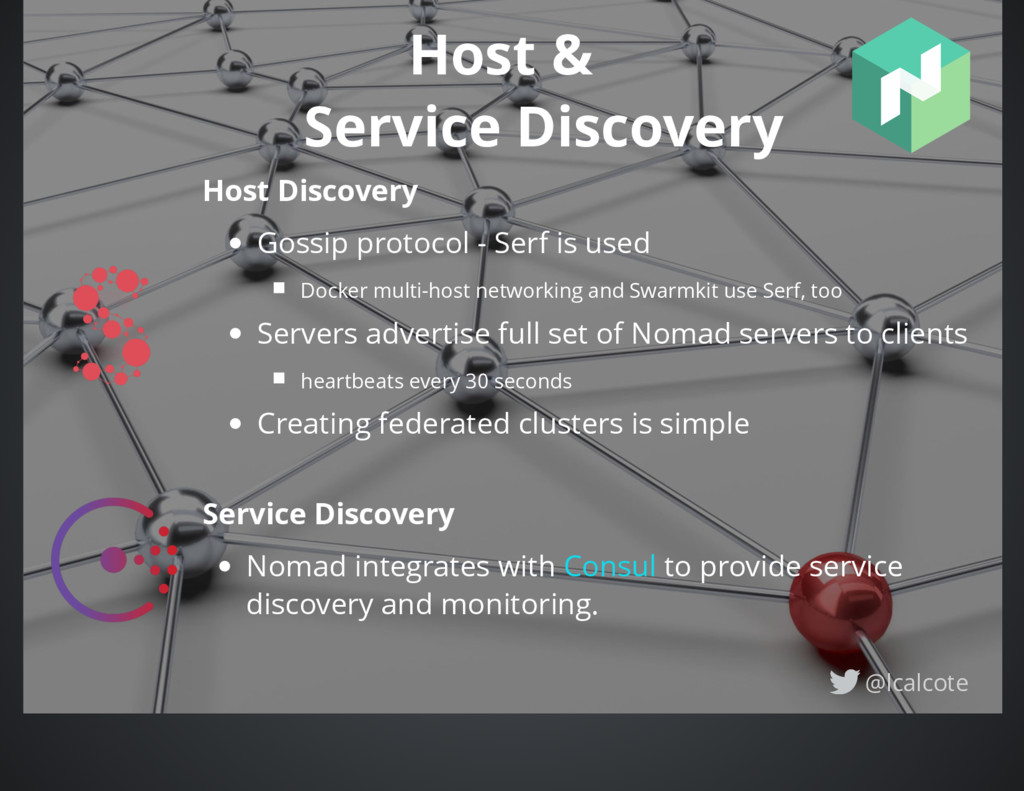
is used Docker multi-host networking and Swarmkit use Serf, too Servers advertise full set of Nomad servers to clients heartbeats every 30 seconds Creating federated clusters is simple Service Discovery Nomad integrates with to provide service discovery and monitoring. Consul @lcalcote
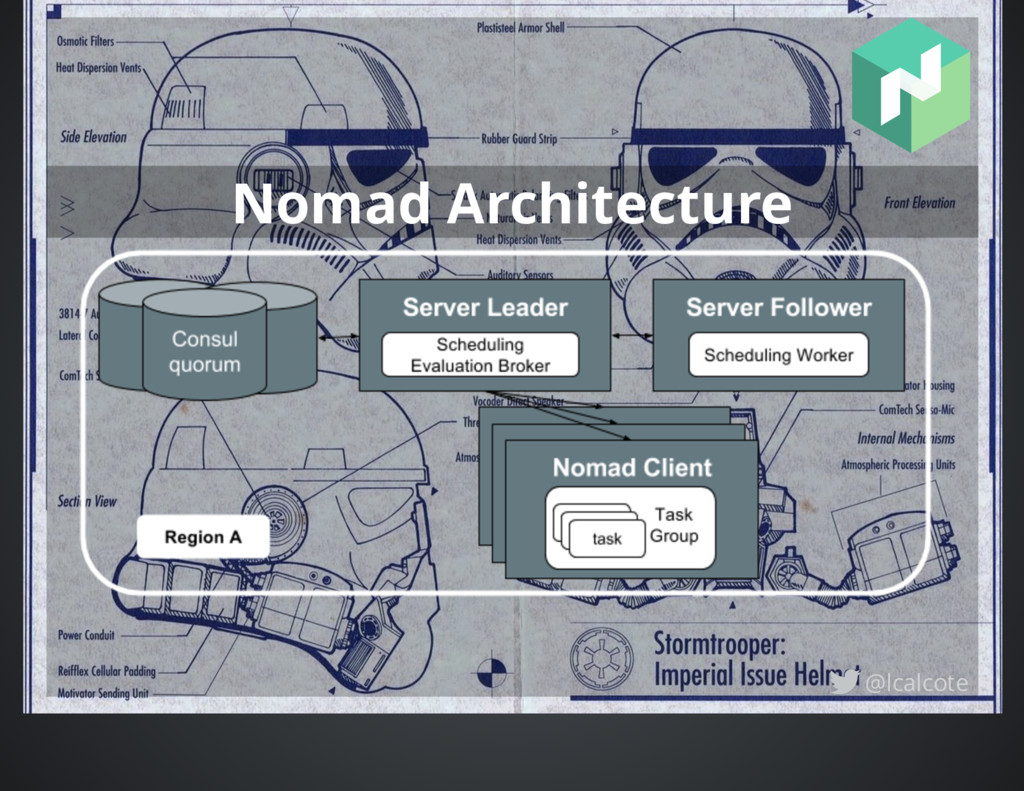
enabling all servers to participate in scheduling decisions which increases the total throughput and reduces latency three scheduler types used when creating jobs: service, batch and system `nomad plan` point-in-time-view of what Nomad will do @lcalcote
execute a task and provide resource isolation. By having extensible task drivers are important for flexibility to support a broad set of workloads (e.g. rkt, lxc). Does not currently support pluggable task drivers, Have to implement task driver interface and compile Nomad binary. @lcalcote
integrates with tools like Packer, Consul, and Terraform to support building artifacts, service discovery, monitoring and capacity management. Applications Log rotation (stderr and stdout) no log forward support, yet Rolling updates (via the `update` block in the job specification). @lcalcote
so Nomad can detect failed nodes and migrate the allocations to other healthy clients. Applications currently http, tcp and script In the future Nomad will add support for more Consul checks. `nomad alloc-status` reports actual resource utilization @lcalcote
all tasks and containers it spins up gives secure access to Vault secrets through a workflow which minimizes risk of secret exposure during bootstrapping. @lcalcote
leader election and state replication to provide availability in the face of failures. shared state optimistic scheduler only open source implementation. 1,000,0000 across 5,000 hosts and scheduled in 5 min. Built for managing multiple clusters / cluster federation. @lcalcote
Supports non-containerized tasks and multiple container runtimes Arguably the most advanced scheduler design Upfront consideration of federation / hybrid cloud Broad OS support Outside of scheduler, comparatively less sophisticated Young project Less relative momentum Less relative adoption Less extensible / pluggable @lcalcote
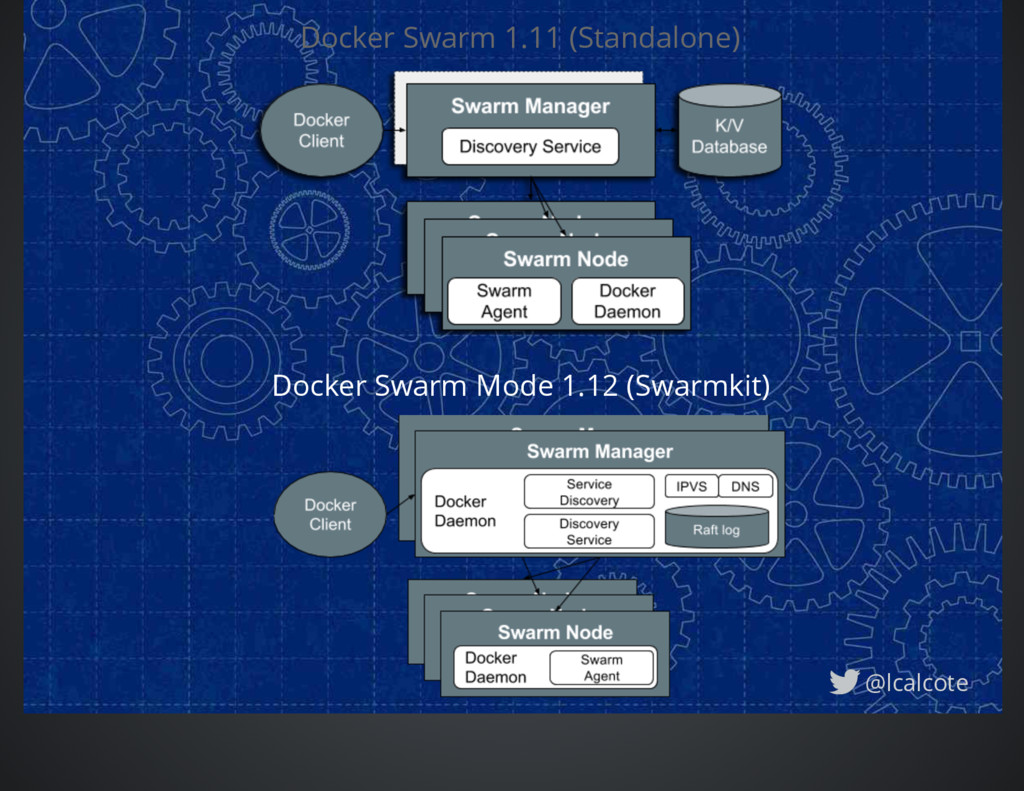
Initially responsible for clustering and scheduling Driving toward application's needs with services, secrets, etc. Originally an imperative system, now declarative. Swarm’s architecture is not complex as those of Kubernetes and Mesos. Written in Go, Swarm is lightweight, modular and somewhat extensible. @lcalcote
for storing cluster state Pull model - where worker checks-in with the Manager Rate Control - of checks-in with Manager may be controlled at Manager - add jitter Workers don't need to know which Manager is active; Follower Managers will redirect Workers to Leader Service Discovery Embedded DNS and round robin load-balancing Services are a new concept goMemDB @lcalcote
of strategies and filters/constraint: Strategies Random Spread* Binpack Filters container constraints (affinity, dependency, port) are defined as environment variables in the specification file node constraints (health, constraint) must be specified when starting the docker daemon and define which nodes a container may be scheduled on. @lcalcote
Paused Manager weights are used to drain or pause Managers Manual swarm manager and worker updates Applications Rolling updates now supported --update-delay --update-parallelism --update-failure-action @lcalcote
of nodes within the cluster Applications One health check per container may be run check container health by running a command inside the container --interval=DURATION (default: 30s) --timeout=DURATION (default: 30s) --retries=N (default: 3) @lcalcote
provides for user-defined overlay networks that are micro-segmentable uses Hashicorp's Serf gossip protocol for quick convergence of neighbor table facilitates container name resolution via embedded DNS server (previously via etc/hosts) Load-balancing based on IPVS expose Service's port externally L4 load-balancer; cluster-wide port publishing Mesh routing send a request to any one of the nodes and it will be routed automatically send a request to any one of the nodes and it will be internally load balanced @lcalcote
highly-available configuration Active/Standby - only one active Leader at-a-time Maintain odd number of managers Rescheduling upon node failure No rebalancing upon node addition to the cluster Does not support multiple failure isolation regions or federation although, with caveats, . federation is possible @lcalcote
recently added capabilities falling into the application bu Swarmkit is a young project advanced features forthcoming natural expectation of caveats in functionality No rebalancing, autoscaling or monitoring, yet Only schedules Docker containers, not containers using other specificat Does not schedule VMs or non-containerized processes Does not provide support for batch jobs Need separate load-balancer for overlapping ingress ports While dependency and affinity filters are available, Swarm does not pro the ability to enforce scheduling of two containers onto the same host o at all. Filters facilitate sidecar pattern. No “pod” concept. Swarm works. Swarm is simple and easy to deploy. 1.12 eliminated need for much, but not all third-party software Facilitates earlier stages of adoption by organizations viewing containers as faster VMs now with built-in functionality for applications Swarm is easy to extend, if can already know Docker APIs, you can customize Swarm Still modular, but has stepped back here. Moving very fast; eliminating gaps quickly.
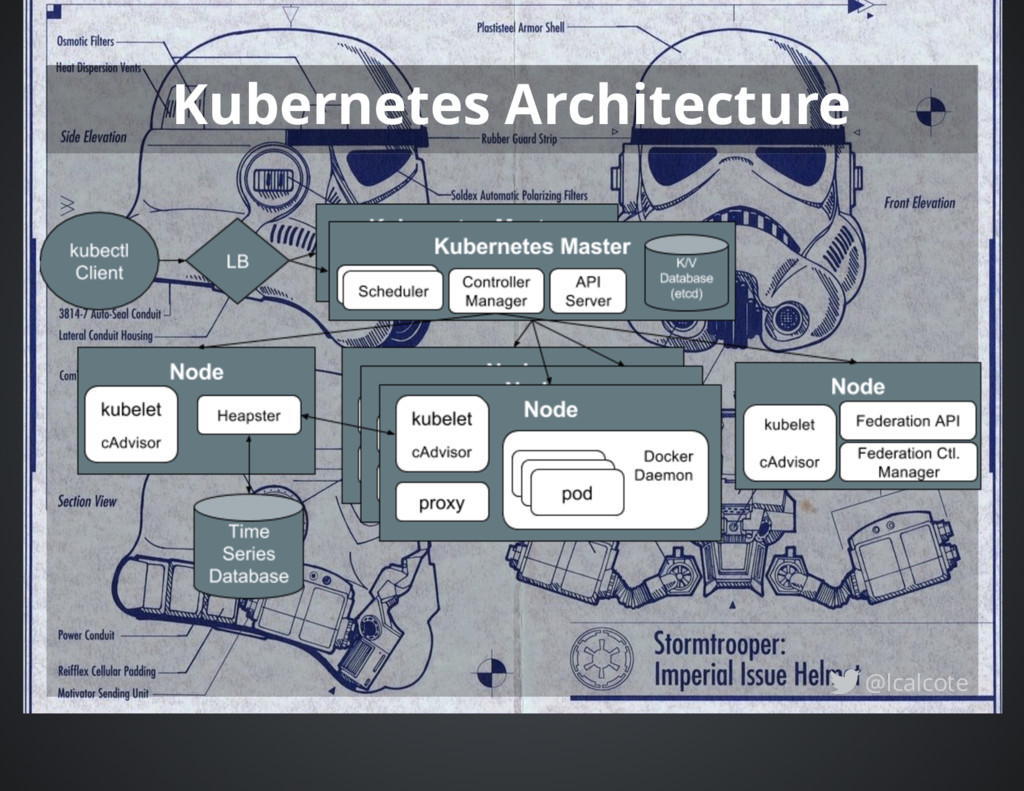
"an open source system for automating deployment, scaling, and operations of applications." Written in Go, Kubernetes is lightweight, modular and extensible considered a third generation container orchestrator led by Google, Red Hat and others. Declaratively, opinionated with many key features included bakes in load-balancing, scale, volumes, deployments, secret management and cross-cluster federated services among other features. @lcalcote
(June 2014) Announced as production-ready 19 months ago (July 2015) Project has over 1,000 commits per month (~44,000 total) reach 1,000 committers (~100 core) Kubernauts in Dec. 2016 ~5,000 commits made in each release (1.5 is latest) ~244 Kubernetes meetups worldwide. Disclaimer: I organize Microservices and Containers Austin. Under the governance of the Cloud Native Computing Foundation KubeCon earlier this year capped at 1,000 attendees @lcalcote
agent (kubelet) is configured to register itself with the master (API server) automating the joining of new hosts to the cluster Service Discovery Two primary modes of finding a Service DNS SkyDNS is deployed as a cluster add-on environment variables environment variables are used as a simple way of providing compatibility with Docker links-style networking @lcalcote
criteria used by kube-scheduler to identify the best-fit node is defined by policy: Predicates (node resources and characteristics): PodFitPorts , PodFitsResources, NoDiskConflict , MatchNodeSelector, HostName , ServiceAffinity, LabelsPresence Priorities (weighted strategies used to identify “best fit” node): LeastRequestedPriority, BalancedResourceAllocation, ServiceSpreadingPriority, EqualPriority @lcalcote
and it being an extensible platform Choice of: database for service discovery or network driver container runtime - may choose to run docker with rkt containers Cluster add-ons optional system components that implement a cluster feature (e.g. DNS, logging, etc.) shipped with the Kubernetes binaries and are considered an inherent part of the Kubernetes clusters @lcalcote
updating applications. Support for rolling back deployments Kubernetes Components Consistently backwards compatible Upgrading the Kubernetes components and hosts is done via shell script Host maintenance - mark the node as unschedulable. existing pods are vacated from the node prevents new pods from being scheduled on the node @lcalcote
nodes within the cluster via Node Controller Resources - usage monitoring leverages a combination of open source components: cAdvisor, Heapster, InfluxDB, Grafana, Prometheus Applications three types of user-defined application health-checks and uses the Kubelet agent as the the health check monitor HTTP Health Checks, Container Exec, TCP Socket Cluster-level Logging collect logs which persist beyond the lifetime of the pod’s container images or the lifetime of the pod or even cluster standard output and standard error output of each container can be ingested using a agent running on each node Fluentd
scheduling flat networking with each pod receiving an IP address no NAT required, port conflicts localized intra-pod communication via localhost Load-Balancing Services provide inherent load-balancing via kube-proxy: runs on each node of a Kubernetes cluster reflects services as defined in the Kubernetes API supports simple TCP/UDP forwarding and round-robin and Docker-links- based service IP:PORT mapping. @lcalcote
in a pod either: 1. mounted as data volumes 2. exposed as environment variables None of the pod’s containers will start until all the pods' volumes are mounted. Individual secrets are limited to 1MB in size. Secrets are created and accessible within a given namespace, not cross-namespace. @lcalcote
in a highly- available configuration. Active/Standby configuration Federated clusters / multi-region deployments Scale v1.2 support for 1,000 node clusters v1.3 supports 2,000 node clusters Horizontal Pod Autoscaling (via Replication Controllers ). Cluster Autoscaling (if you're running on GCE with AWS support is coming soon). @lcalcote
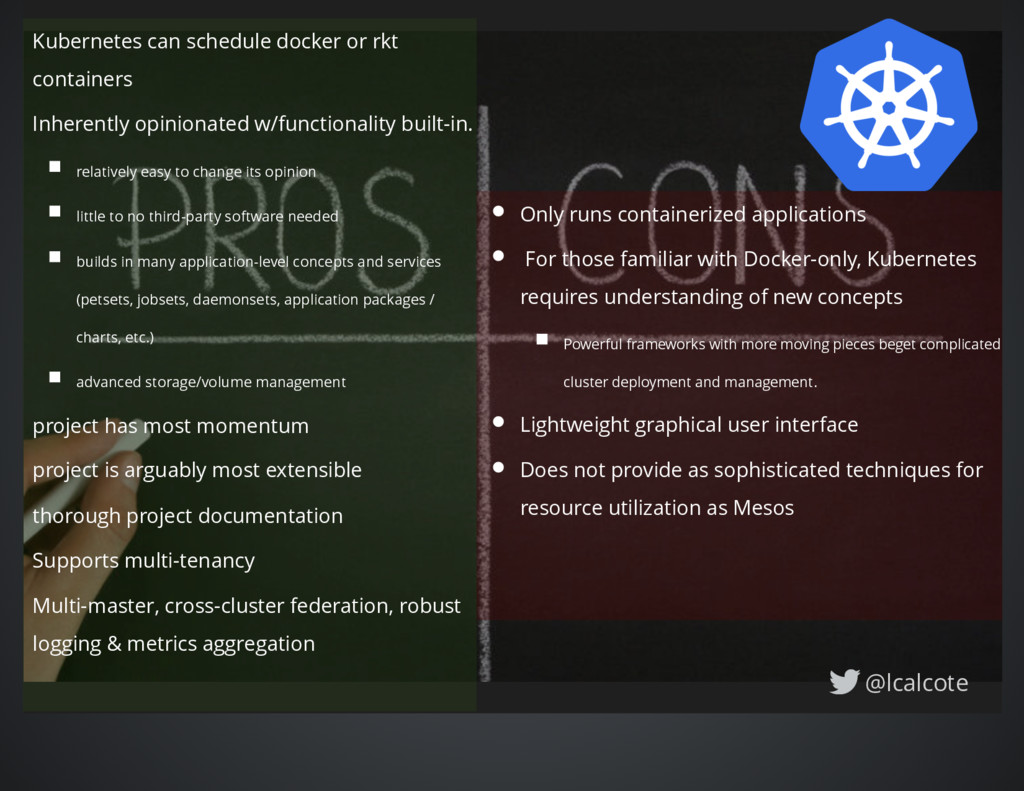
requires understanding of new concepts Powerful frameworks with more moving pieces beget complicated cluster deployment and management. Lightweight graphical user interface Does not provide as sophisticated techniques for resource utilization as Mesos Kubernetes can schedule docker or rkt containers Inherently opinionated w/functionality built-in. relatively easy to change its opinion little to no third-party software needed builds in many application-level concepts and services (petsets, jobsets, daemonsets, application packages / charts, etc.) advanced storage/volume management project has most momentum project is arguably most extensible thorough project documentation Supports multi-tenancy Multi-master, cross-cluster federation, robust logging & metrics aggregation @lcalcote
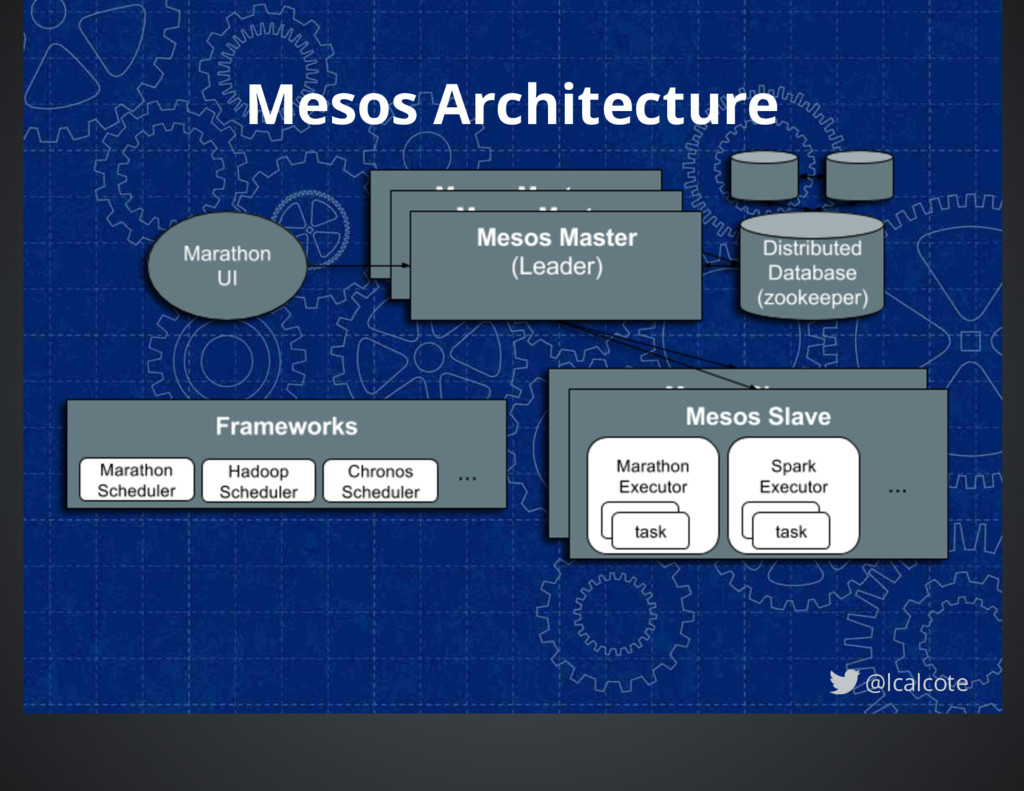
together many different machines into a logical computer Mesos has been around the longest (launched in 2009) and is arguably the most stable, with highest (proven) scale currently Mesos is written mostly in C++ with Java, Python and C++ APIs Marathon as a Framework Marathon is one of a number of frameworks (Chronos and Aurora other examples) that may be run on top of Mesos Frameworks have a scheduler and executor. Schedulers get resource offers. Executors run tasks. Marathon is written in Scala @lcalcote
MesosCon 2015 in Seattle had 700 attendees up from 262 attendees in 2014 Mesos has 224 contributors Marathon has 227 contributors Mesos under the governance of Apache Foundation Marathon under governance of Mesosphere Mesos is used by Twitter, AirBnb, eBay, Apple, Cisco, Yodle Marathon is used by Verizon and Samsung @lcalcote
each Mesos task including Marathon application instances Marathon will ensure that all dynamically assigned service ports are unique Mesos-DNS is particularly useful when: apps are launched through multiple frameworks (not just Marathon) you are using an IP-per-container solution like you use random host port assignments in Marathon Project Calico @lcalcote
on allocation policy, which decides which framework get resources. Second-level scheduling happens at Framework scheduler, which decides what tasks to execute. Provide reservations, over-subscriptions and preemption. @lcalcote
concurrently Modules extend inner-workings of Mesos by creating and using shared libraries that are loaded on demand many types of Modules Replacement, Isolator, Allocator, Authentication, Hook, Anonymous @lcalcote
Marathon does not. Mesos API backwards compatible from v1.0 forward Applications Marathon can be instructed to deploy containers based on that component using a blue/green strategy where old and new versions co-exist for a time. @lcalcote
metrics to monitor resource usage Applications support for health checks (HTTP and TCP) an event stream that can be integrated with load- balancers or for analyzing metrics @lcalcote
longer share the node's IP Helps remove port conflicts Enables 3rd party network drivers isolator with MesosContainerizer Load-Balancing Marathon offers two TCP/HTTP proxies A simple shell script and a more complex one called `marathon-lb` that has more features. Pluggable (e.g. Traefik for load-balancing) Container Network Interface (CNI) @lcalcote
in ZooKeeper, exposed as ENV variables in Marathon Secrets shorter than eight characters may not be accepted by Marathon. By default, you cannot store a secret larger than 1MB. @lcalcote
masters to form a quorum using ZooKeeper (point of failure) only one Active (Leader) master at-a-time in Mesos and Marathon Scale is a strong suit for Mesos. TBD for Marathon. Autoscale `marathon-autoscale.py` - autoscales application based on the utilization metrics from Mesos - request rate-based autoscaling with Marathon. Great at short-lived jobs. High availability built-in. Referred to as the “golden standard” by Solomon Hykes, Docker CTO. marathon-lb-autoscale
Docker friendly (hard to get at volumes and registry) May need a dedicated infrastructure IT team an overly complex solution for small deployments Universal Containerizer abstract away from docker, rkt, kurma?, lxc? Can run multiple frameworks, including Kubernetes and Swarm. Supports multi-tenancy. Good for Big Data shops and job / task-oriented workloads. Good for mixed workloads and with data-locality policies Mesos is powerful and scalable, battle-tested Good for multiple large things you need to do 10,000+ node cluster system Marathon UI is young, but promising. @lcalcote
{kind=link}
![Lee Calcote linkedin.com/in/leecalcote @lcalcote blog.gingergeek.com [email protected] clouds, containers, infrastructure, applications](https://files.speakerdeck.com/presentations/55f38c55136e41ff903765ebe8524d0b/slide_1.jpg){kind=link}
{kind=link}
![[kuh n-tey-ner] [awr-kuh-streyt-or] Definition: @lcalcote](https://files.speakerdeck.com/presentations/55f38c55136e41ff903765ebe8524d0b/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Lee Calcote linkedin.com/in/leecalcote @lcalcote blog.gingergeek.com [email protected] Thank you. Questions? clouds,](https://files.speakerdeck.com/presentations/55f38c55136e41ff903765ebe8524d0b/slide_65.jpg){kind=link}