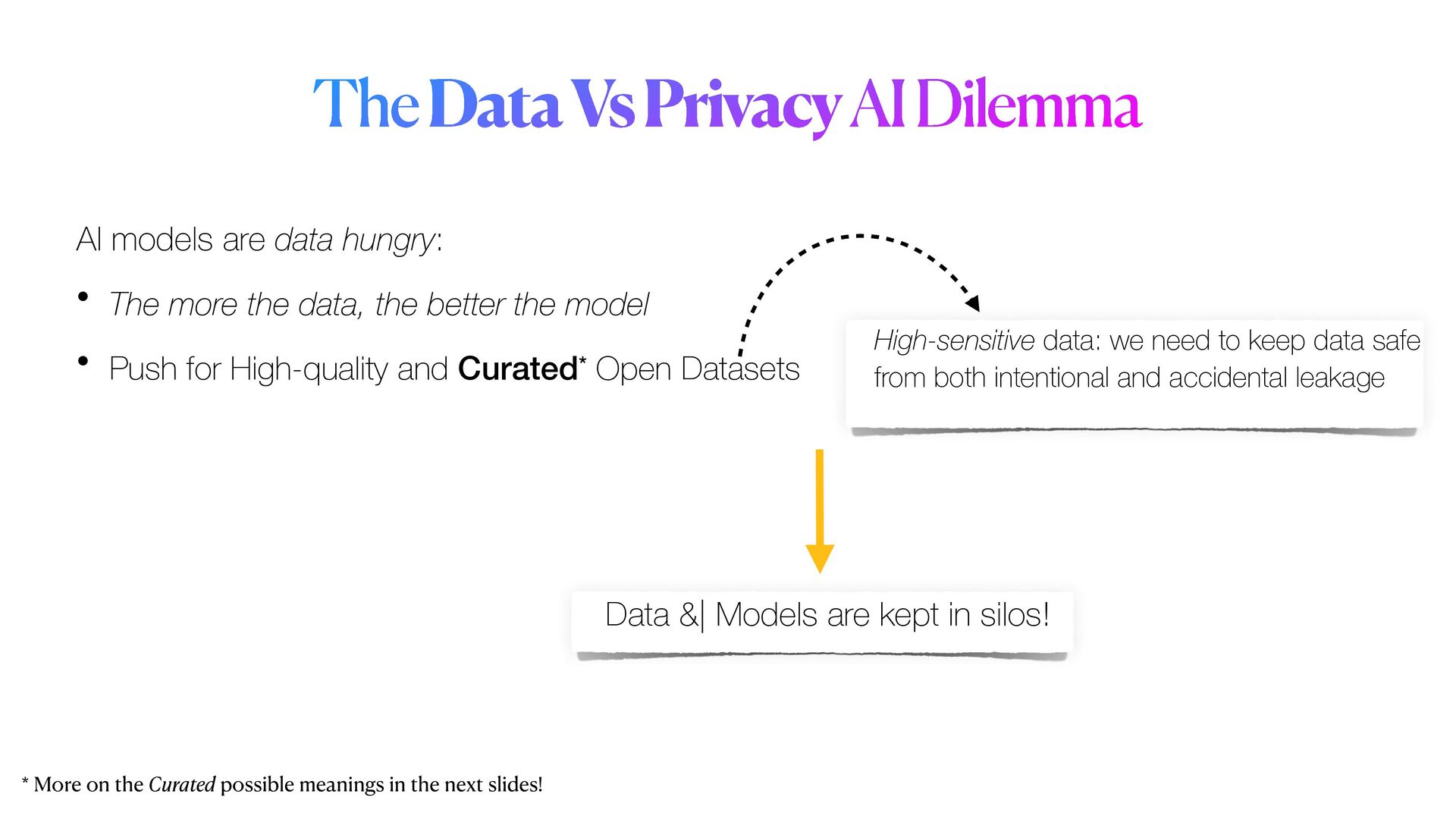
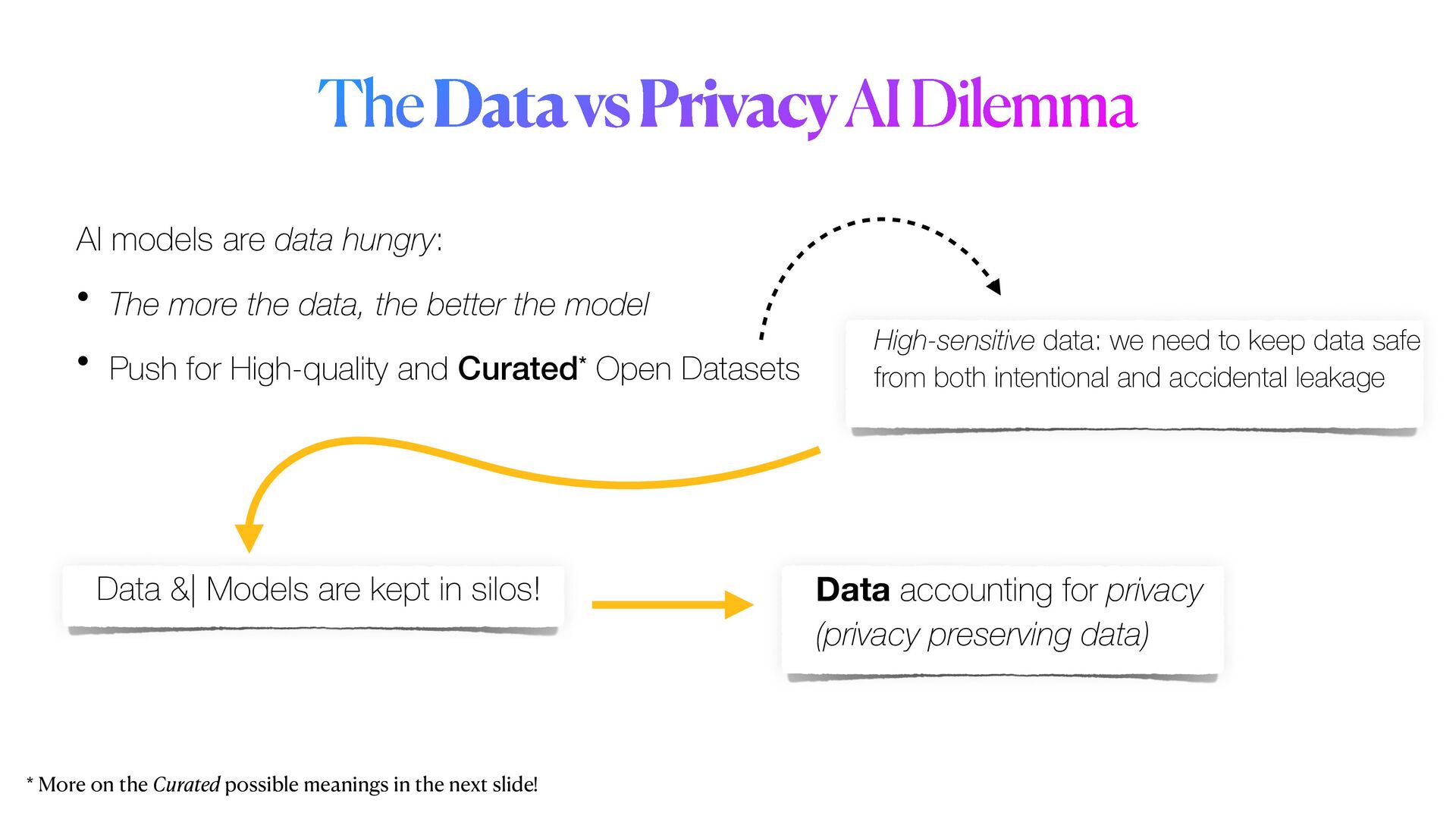
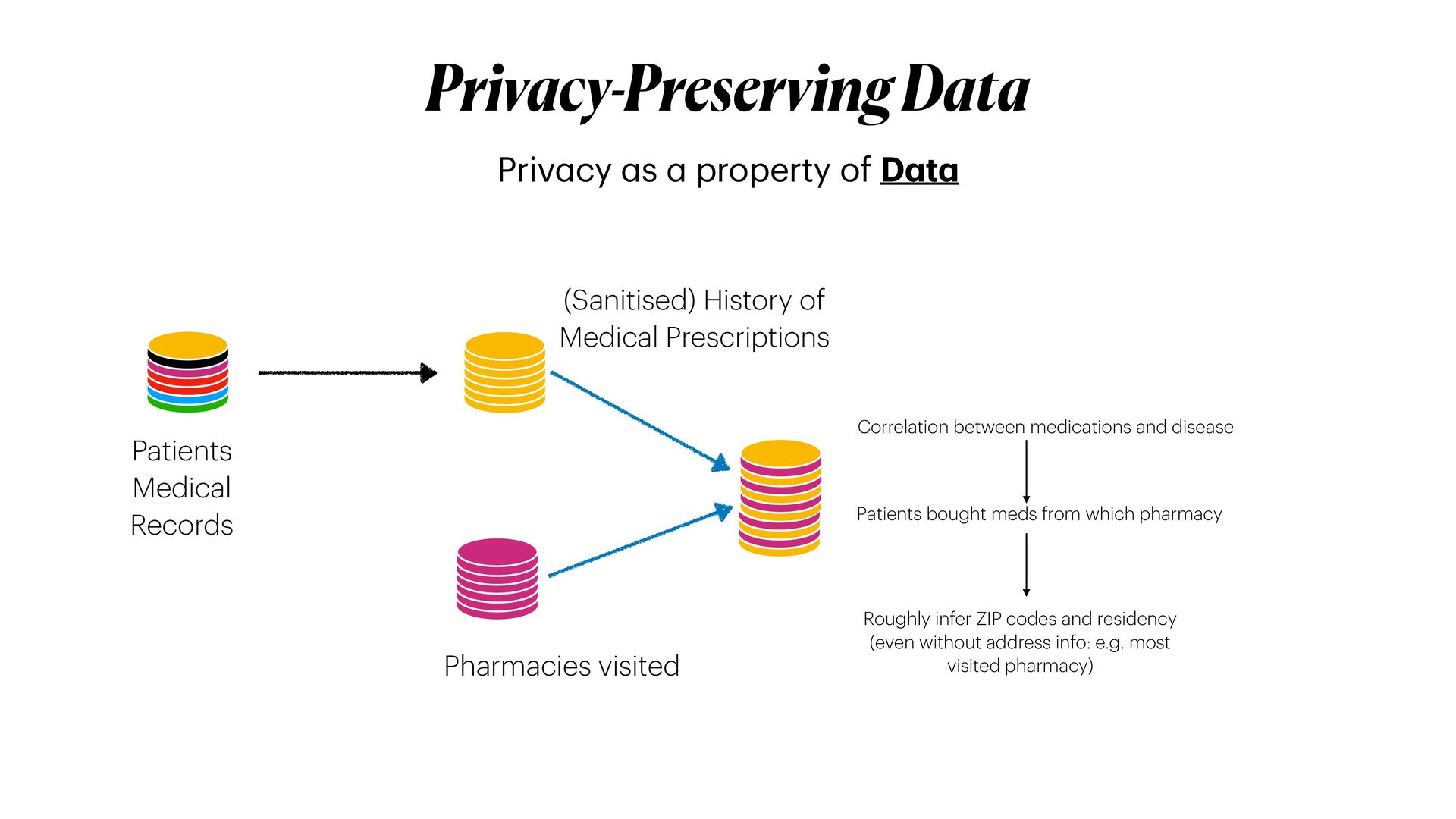
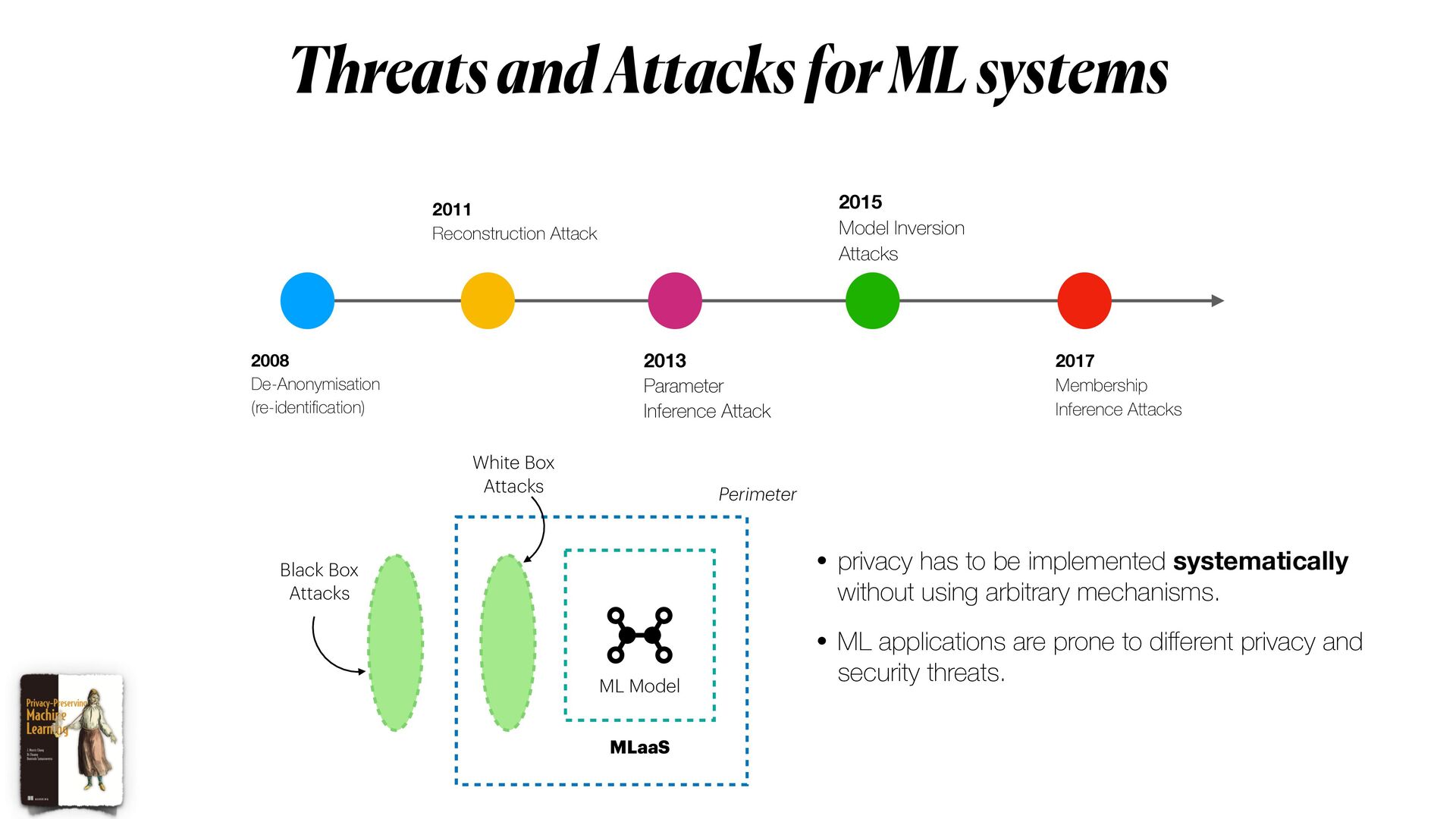
Privacy guarantees are **the** most crucial requirement when it comes to analyse sensitive data. These requirements could be sometimes very stringent, so that it becomes a real barrier for the entire pipeline. Reasons for this are manifold, and involve the fact that data could not be _shared_ nor moved from their silos of resident, let alone analysed in their _raw_ form. As a result, _data anonymisation techniques_ are sometimes used to generate a sanitised version of the original data. However, these techniques alone are not enough to guarantee that privacy will be completely preserved. Moreover, the _memoisation_ effect of Deep learning models could be maliciously exploited to _attack_ the models, and _reconstruct_ sensitive information about samples used in training, even if these information were not originally provided.
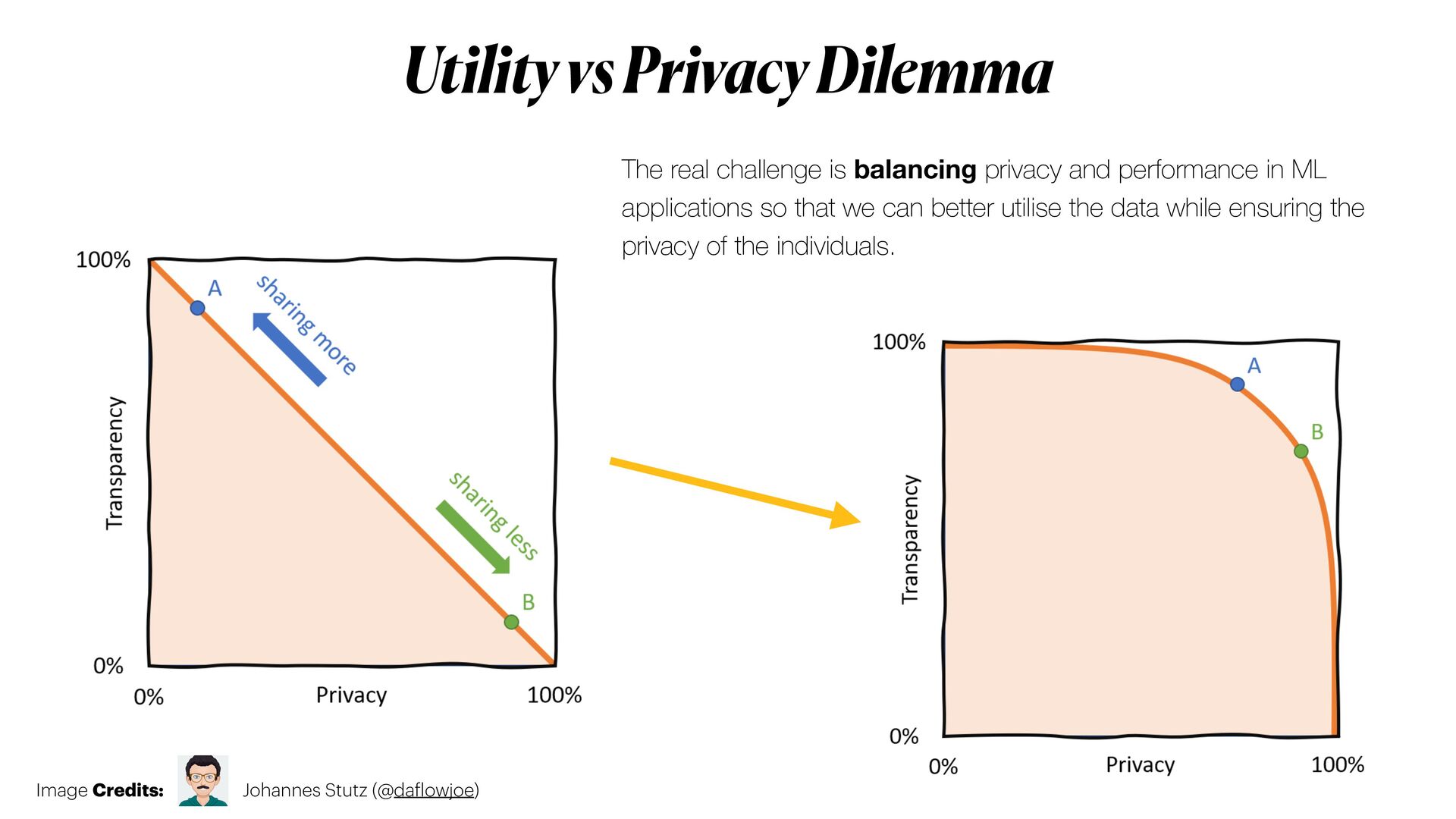
*Privacy-preserving machine learning* (PPML) methods hold the promise to overcome all those issues, allowing to train machine learning models with full privacy guarantees.
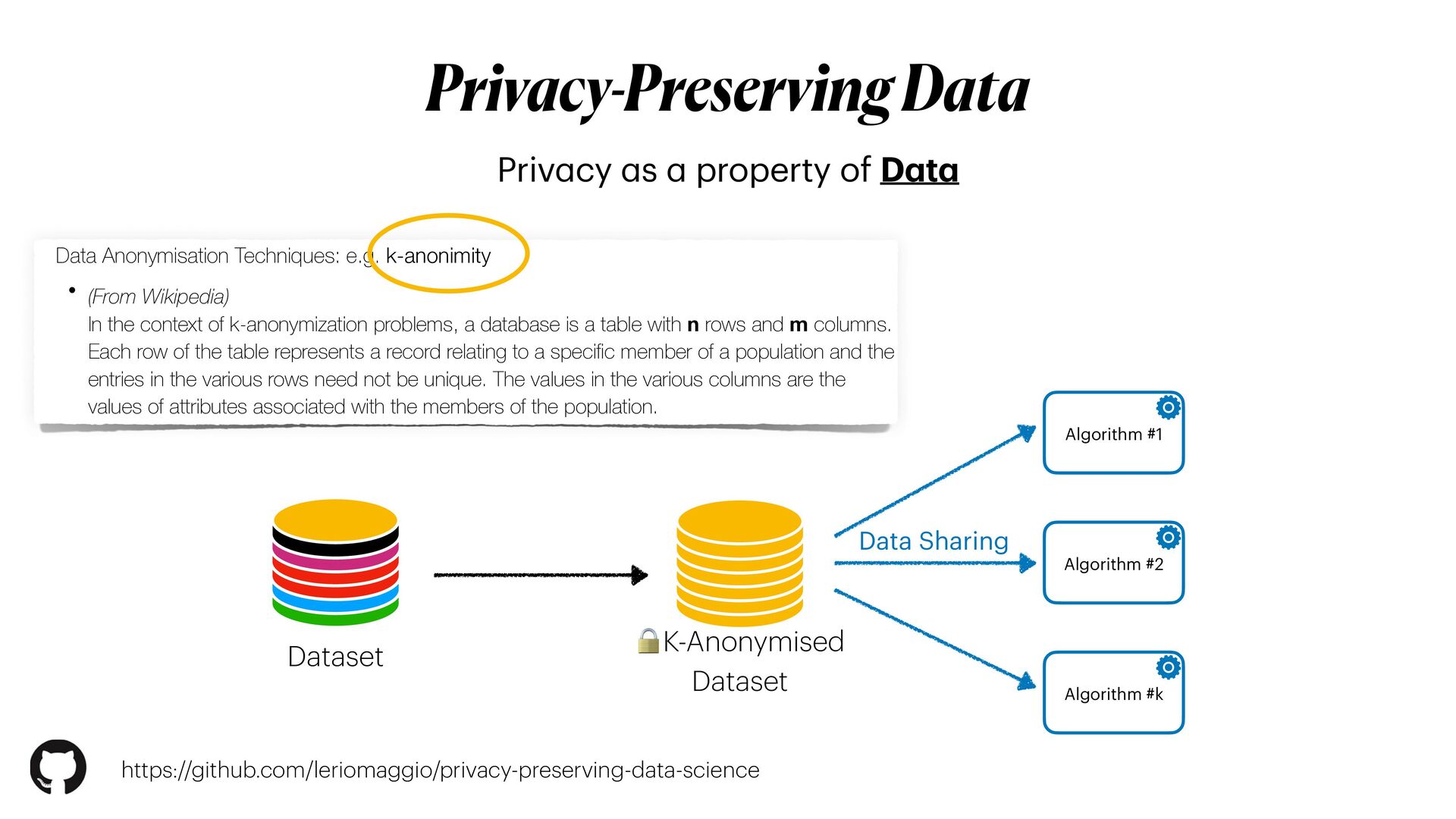
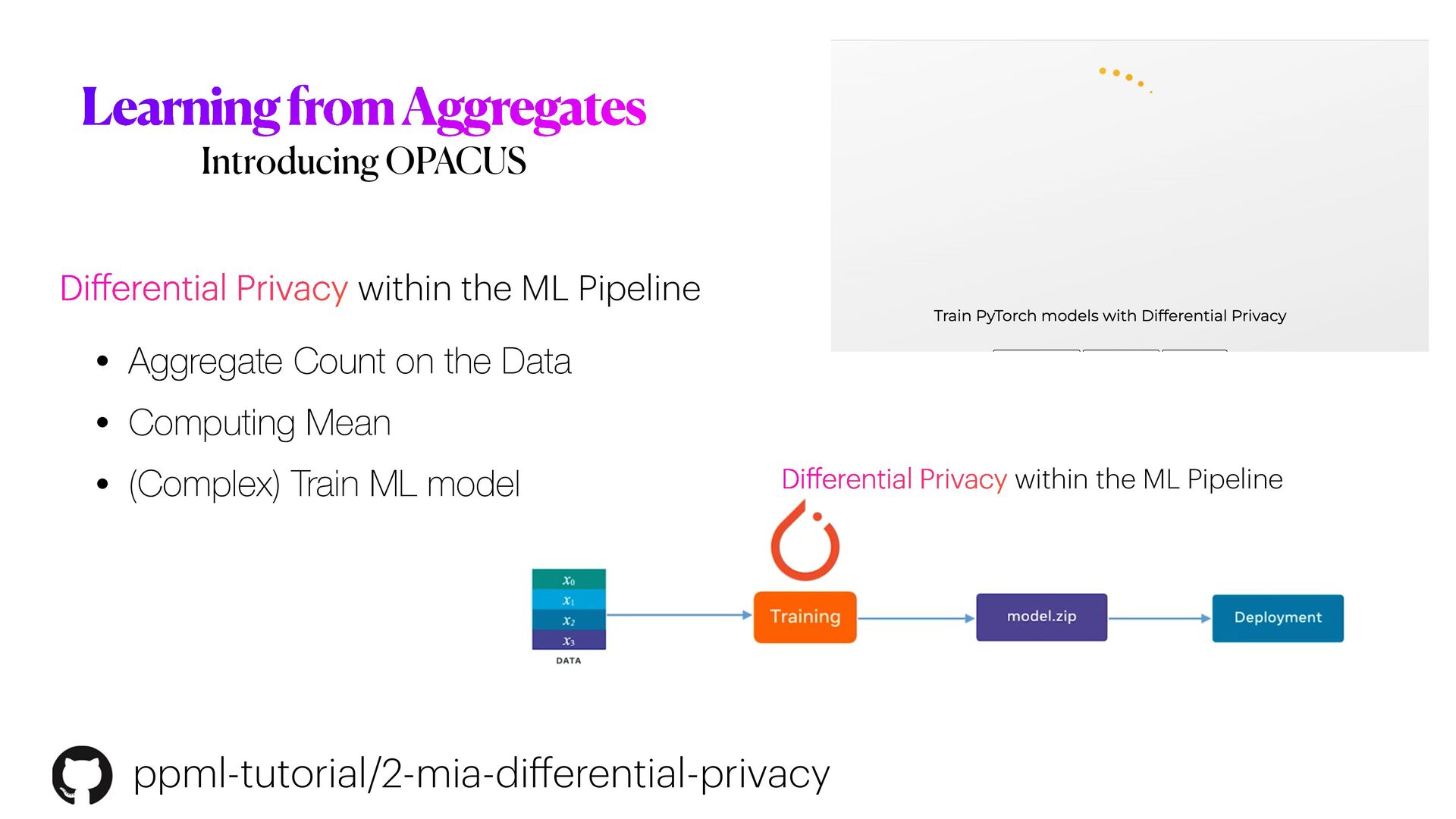
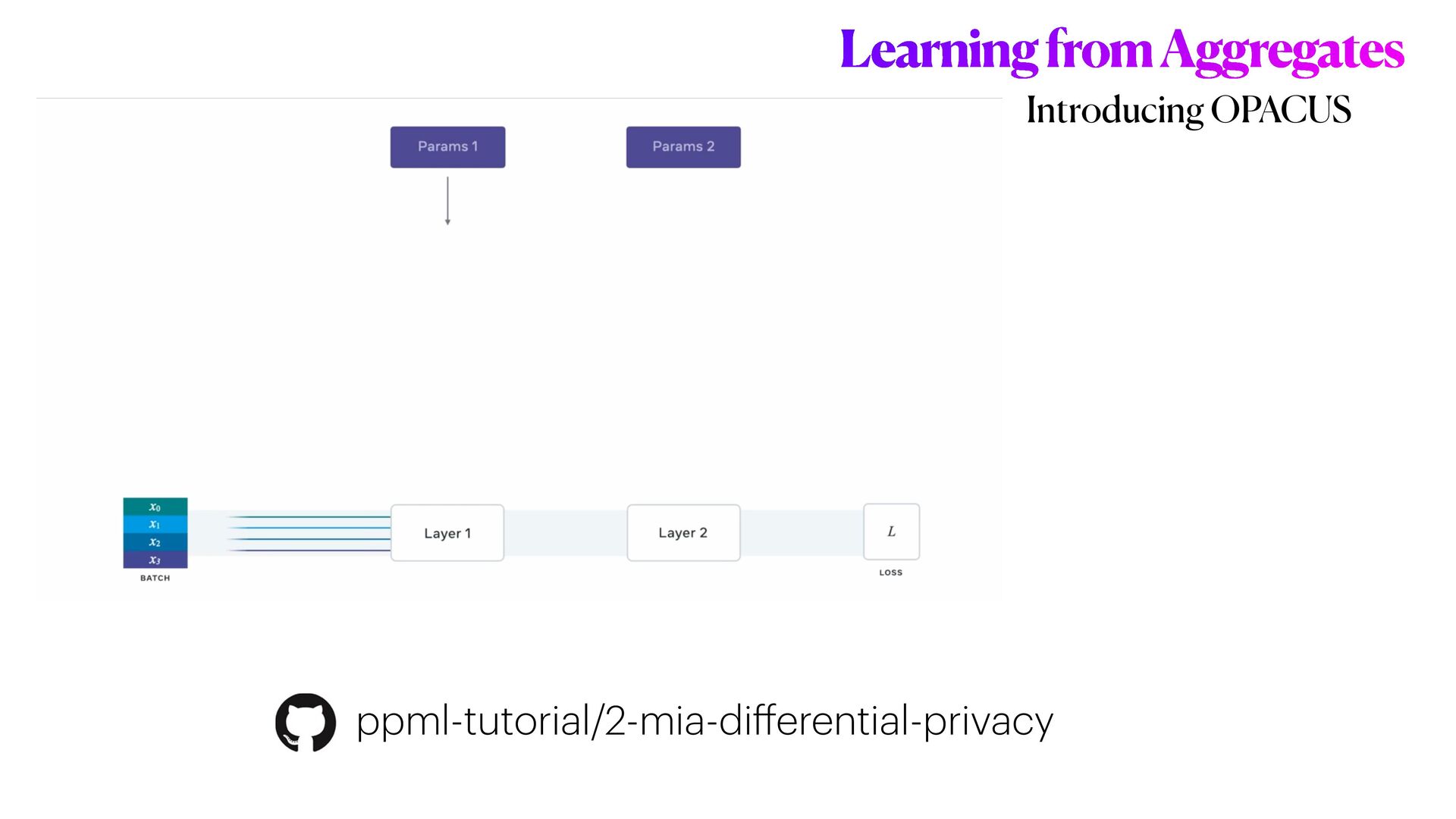
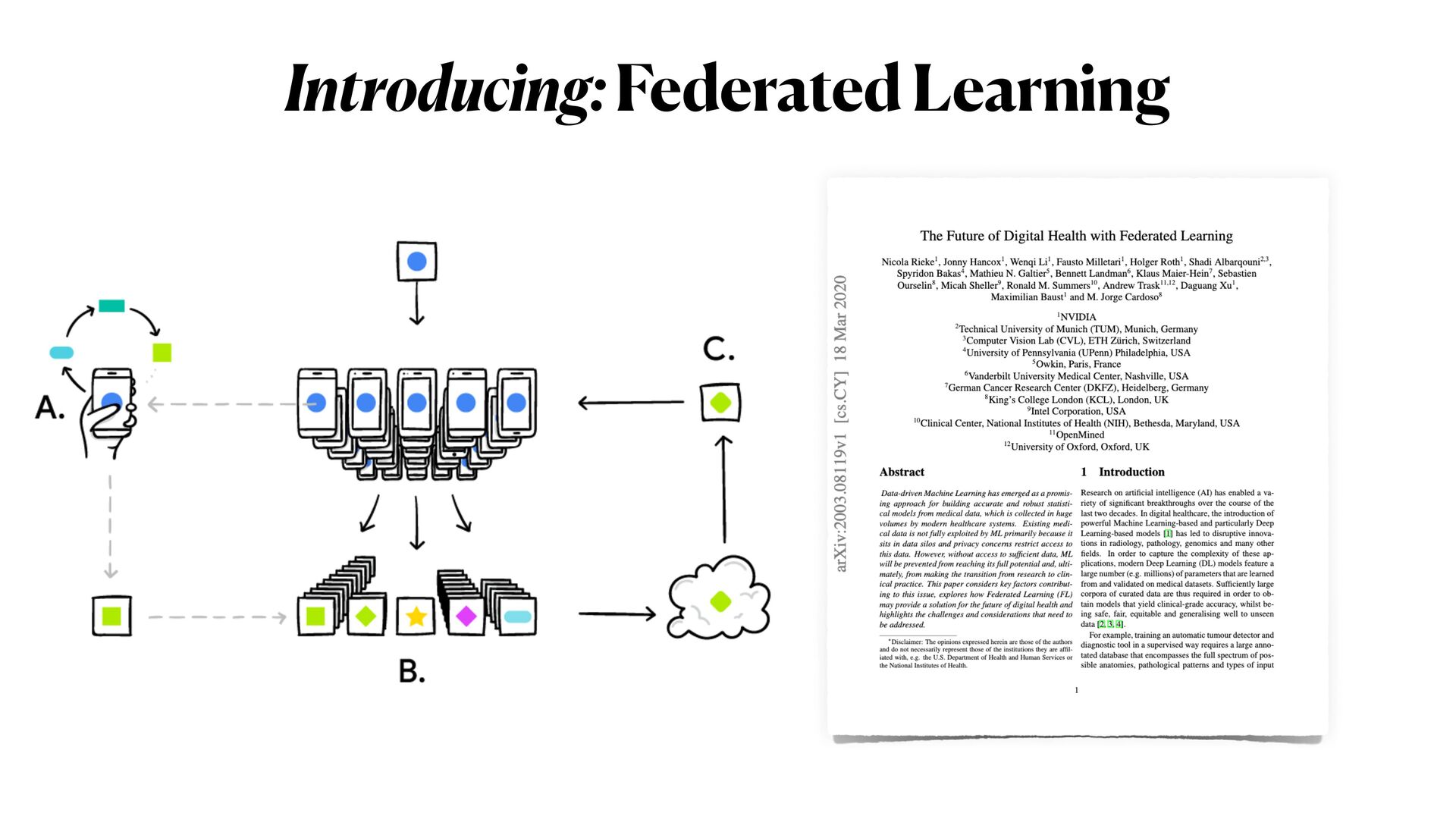
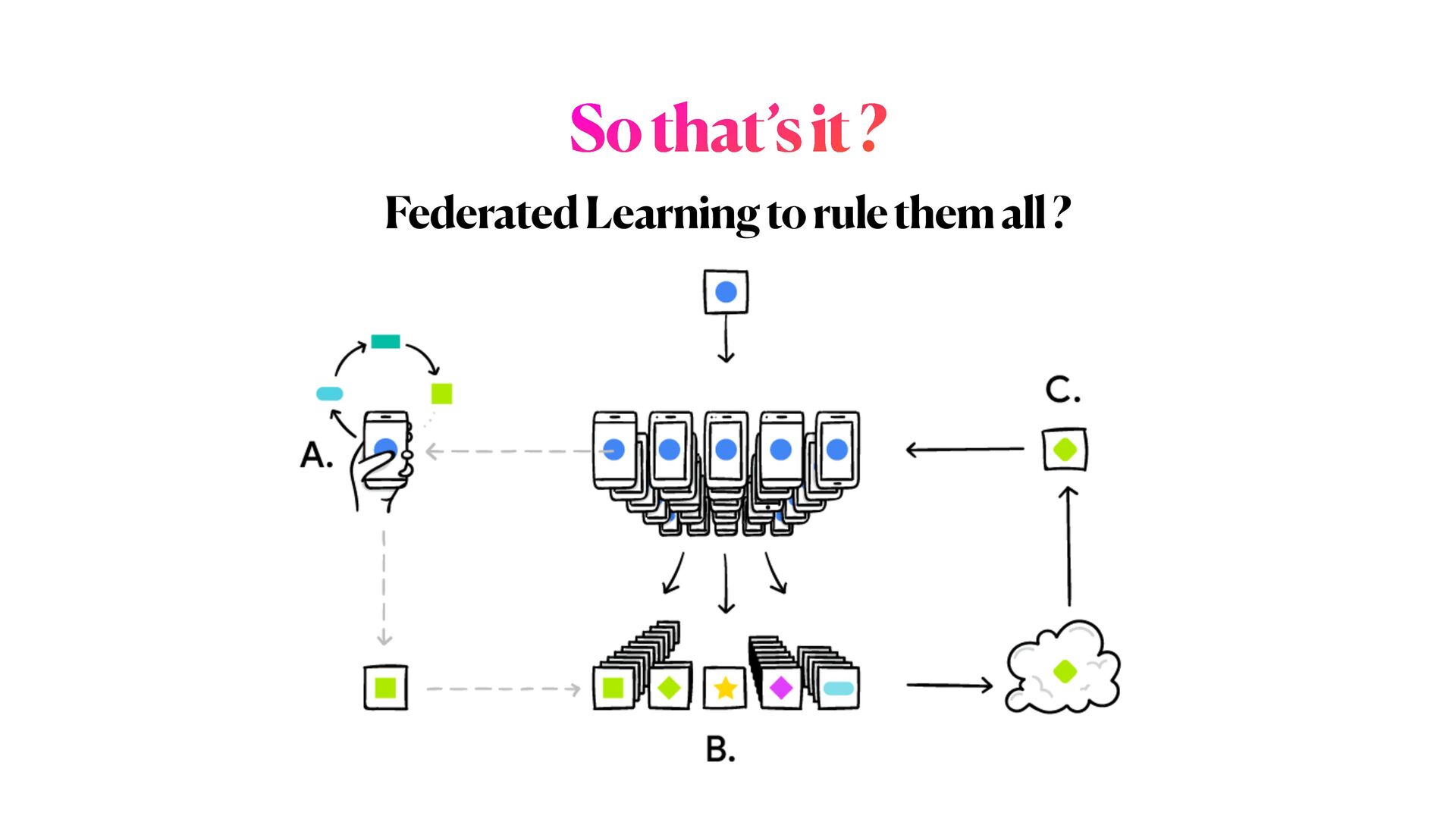
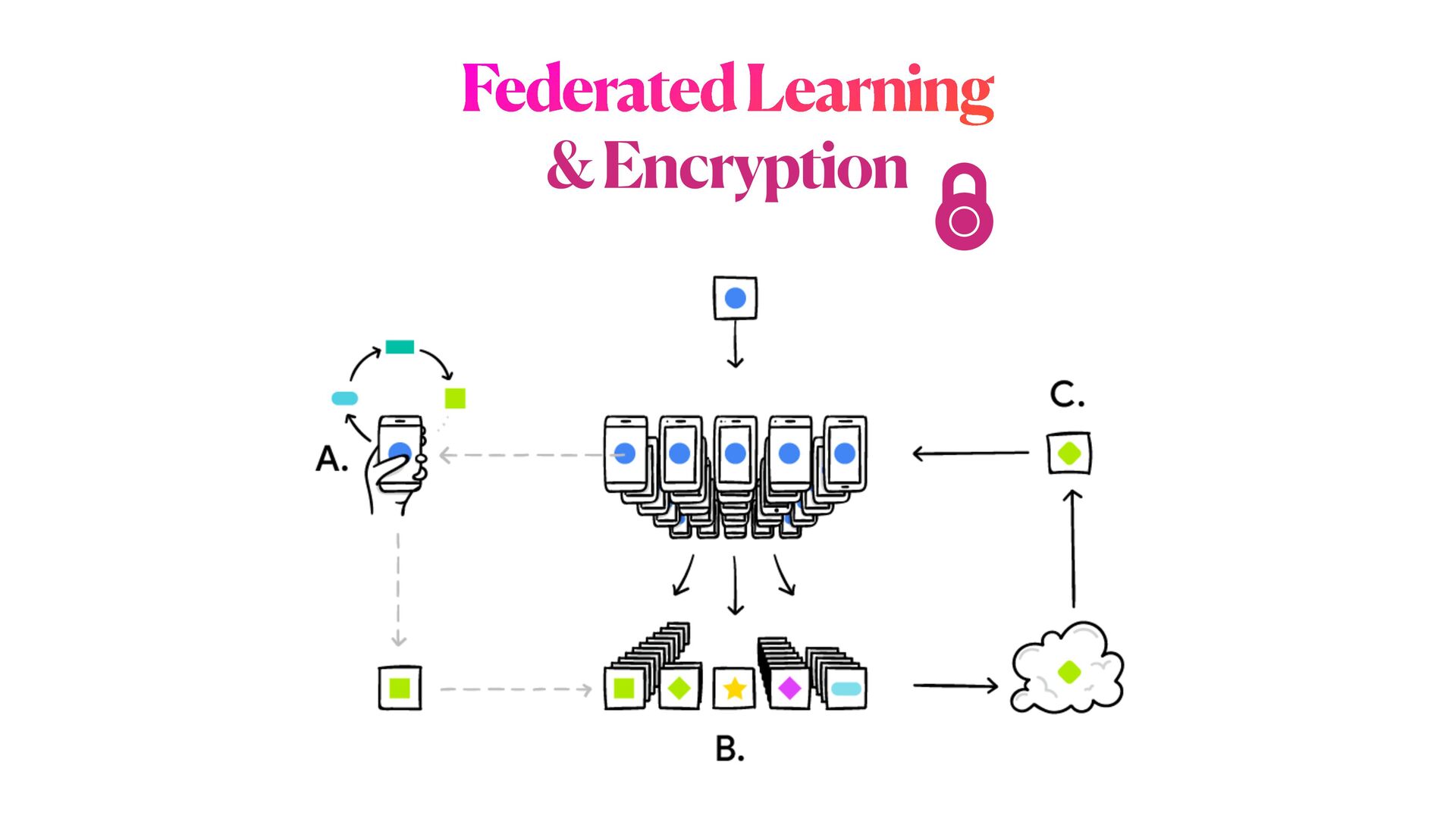
This workshop will be mainly organised in **three** main parts. In the first part, we will introduce the main concepts of **differential privacy**: what is it, and how this method differs from more classical _anonymisation_ techniques (e.g. `k-anonymity`). In the second part, we will focus on Machine learning experiments. We will start by demonstrating how DL models could be exploited (i.e. _inference attack_ ) to reconstruct original data solely analysing models predictions; and then we will explore how **differential privacy** can help us protecting the privacy of our model, with _minimum disruption_ to the original pipeline. Finally, we will conclude the tutorial considering more complex ML scenarios to train Deep learning networks on encrypted data, with specialised _distributed federated_ _learning_ strategies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Privacy Issues Source: https://venturebeat.com/2020/04/07/2020-census-data-may-not-be-as-anonymous-as-expected/ […] (we) show how these](https://files.speakerdeck.com/presentations/e3eaf6d7087c41baa4fefcfa163c71a0/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}