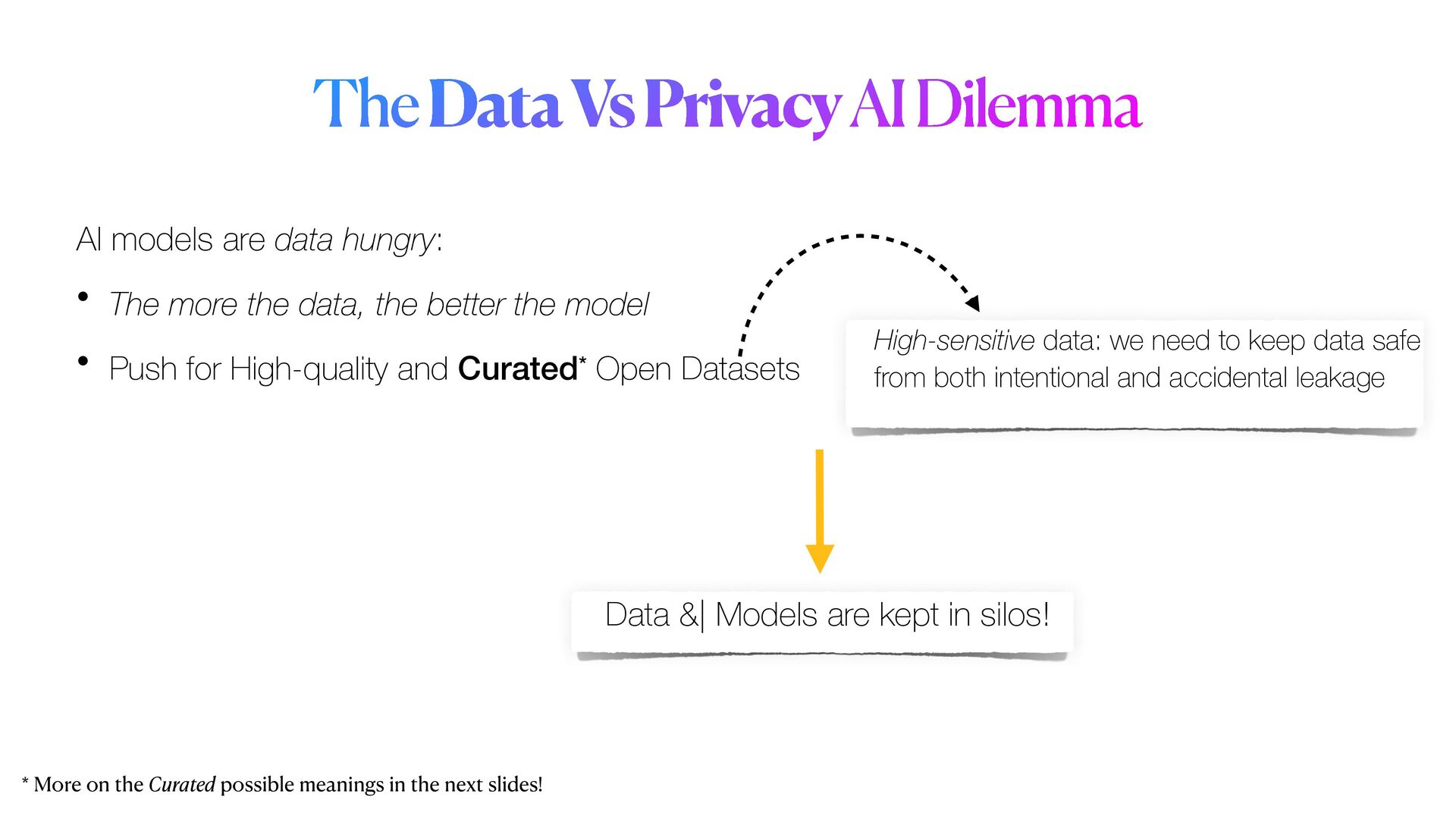
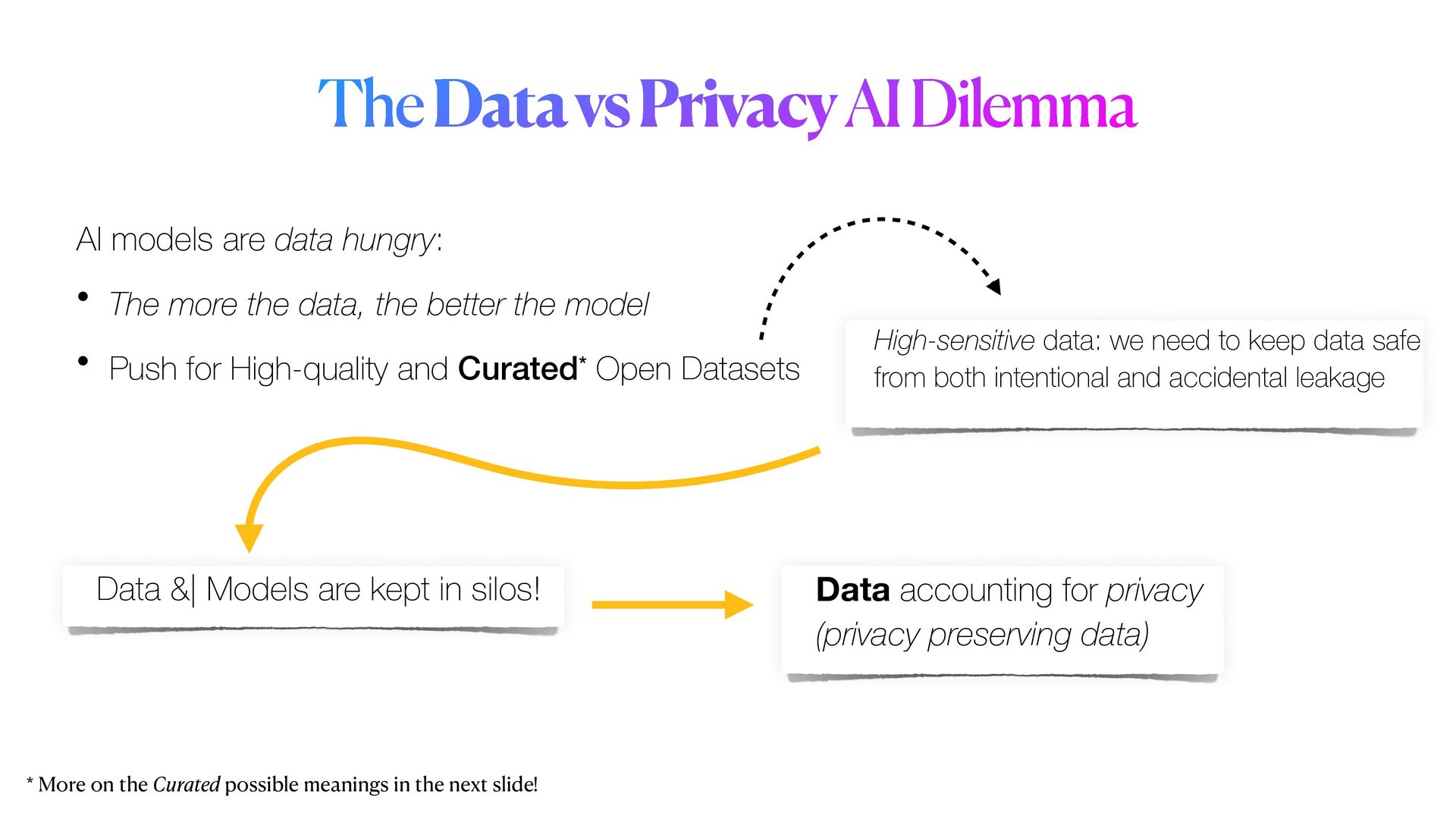
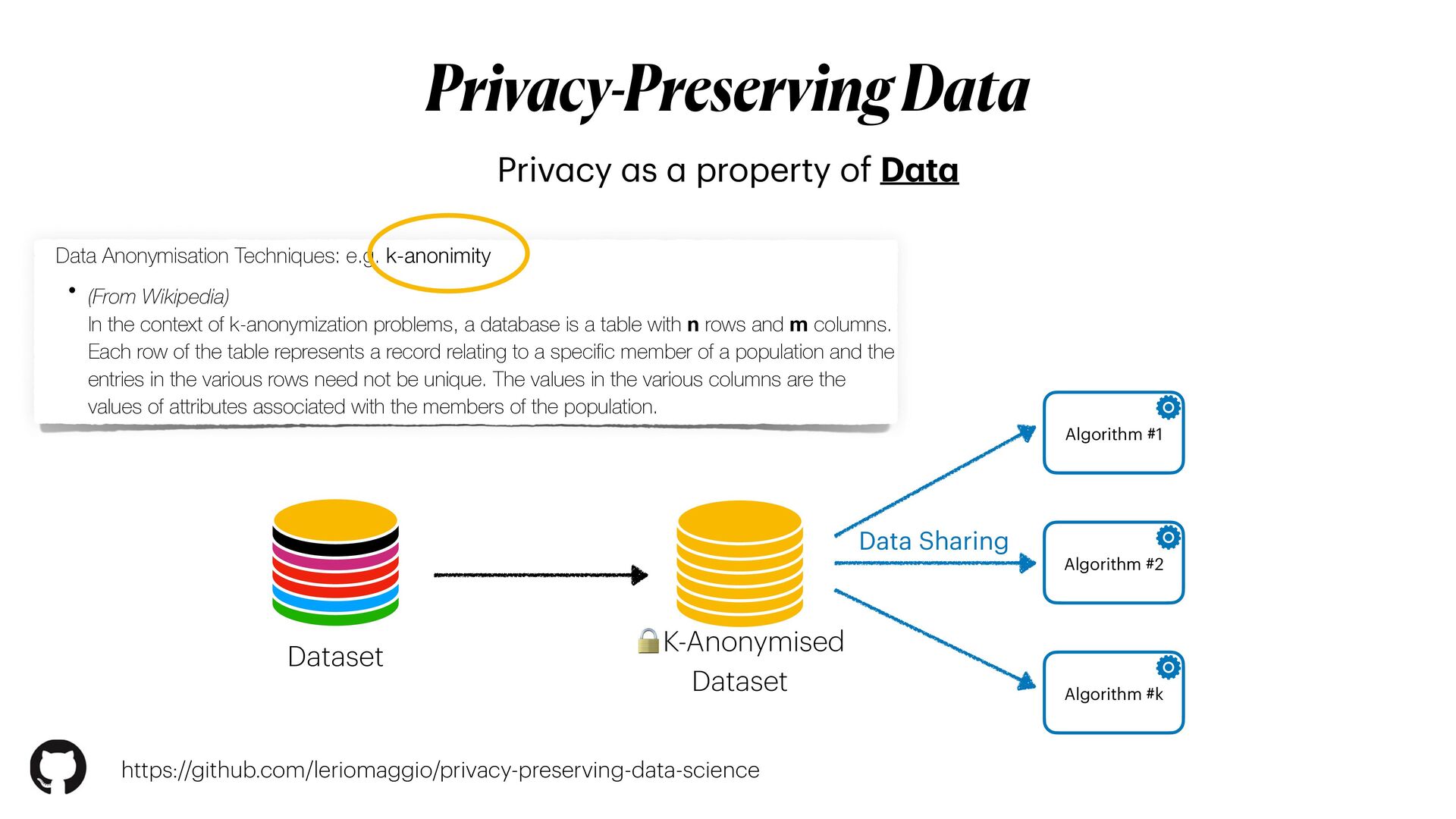
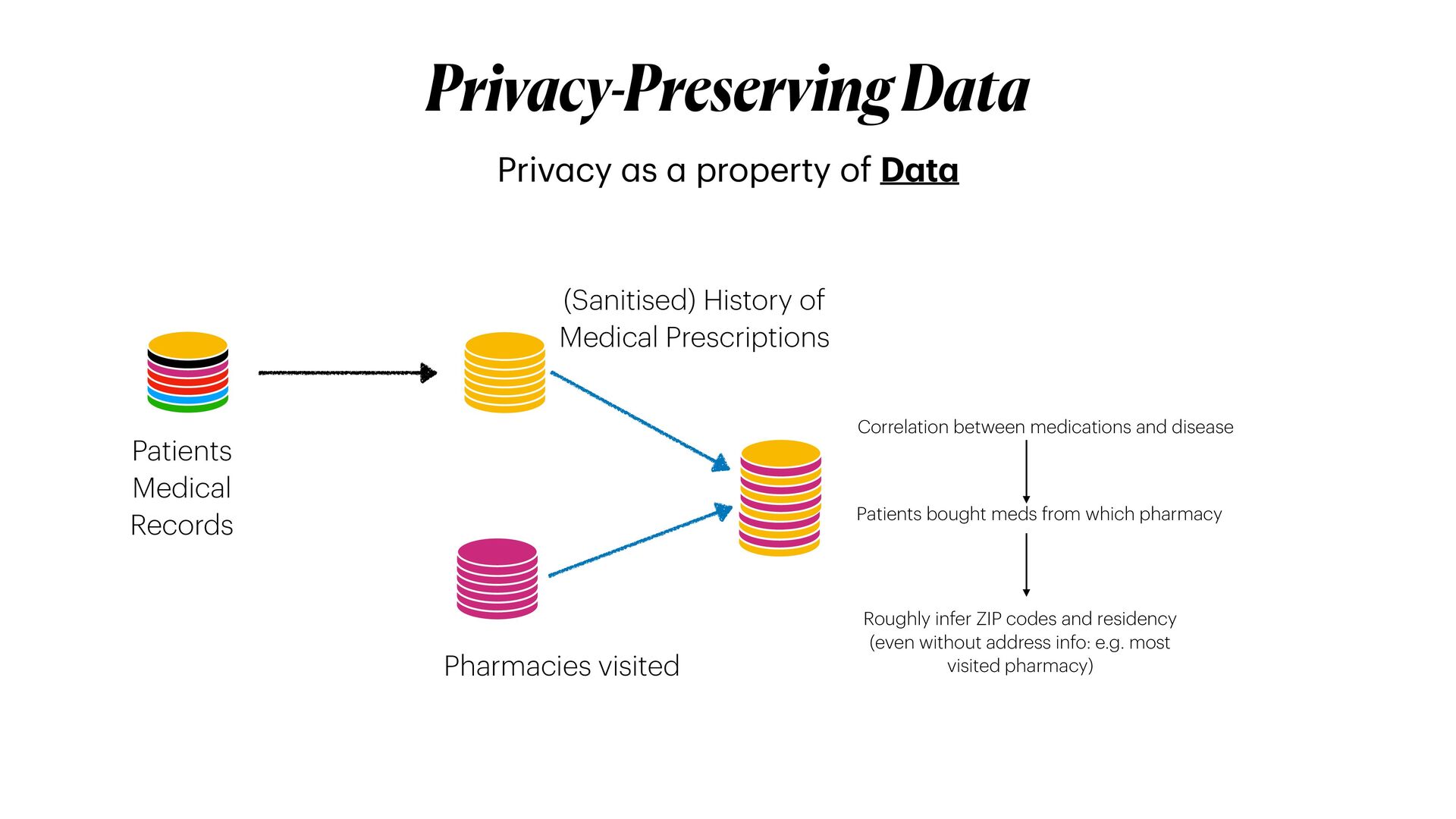
Privacy guarantees are **the** most crucial requirement when it comes to analyse sensitive data. These requirements could be sometimes very stringent, so that it becomes a real barrier for the entire pipeline. Reasons for this are manifold, and involve the fact that data could not be _shared_ nor moved from their silos of resident, let alone analysed in their _raw_ form. As a result, _data anonymisation techniques_ are sometimes used to generate a sanitised version of the original data. However, these techniques alone are not enough to guarantee that privacy will be completely preserved. Moreover, the _memoisation_ effect of Deep learning models could be maliciously exploited to _attack_ the models, and _reconstruct_ sensitive information about samples used in training, even if these information were not originally provided.
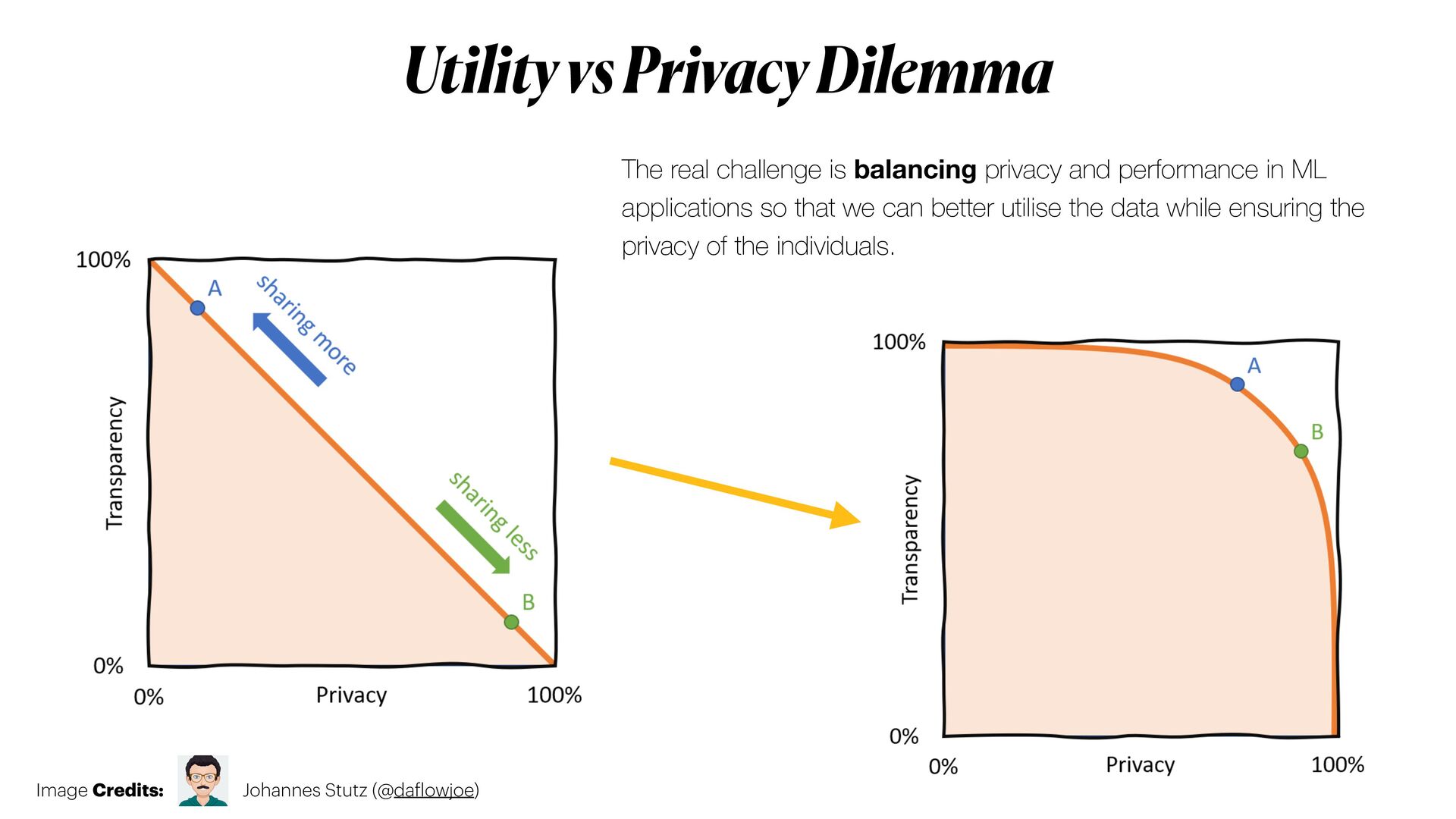
*Privacy-preserving machine learning* (PPML) methods hold the promise to overcome all those issues, allowing to train machine learning models with full privacy guarantees.
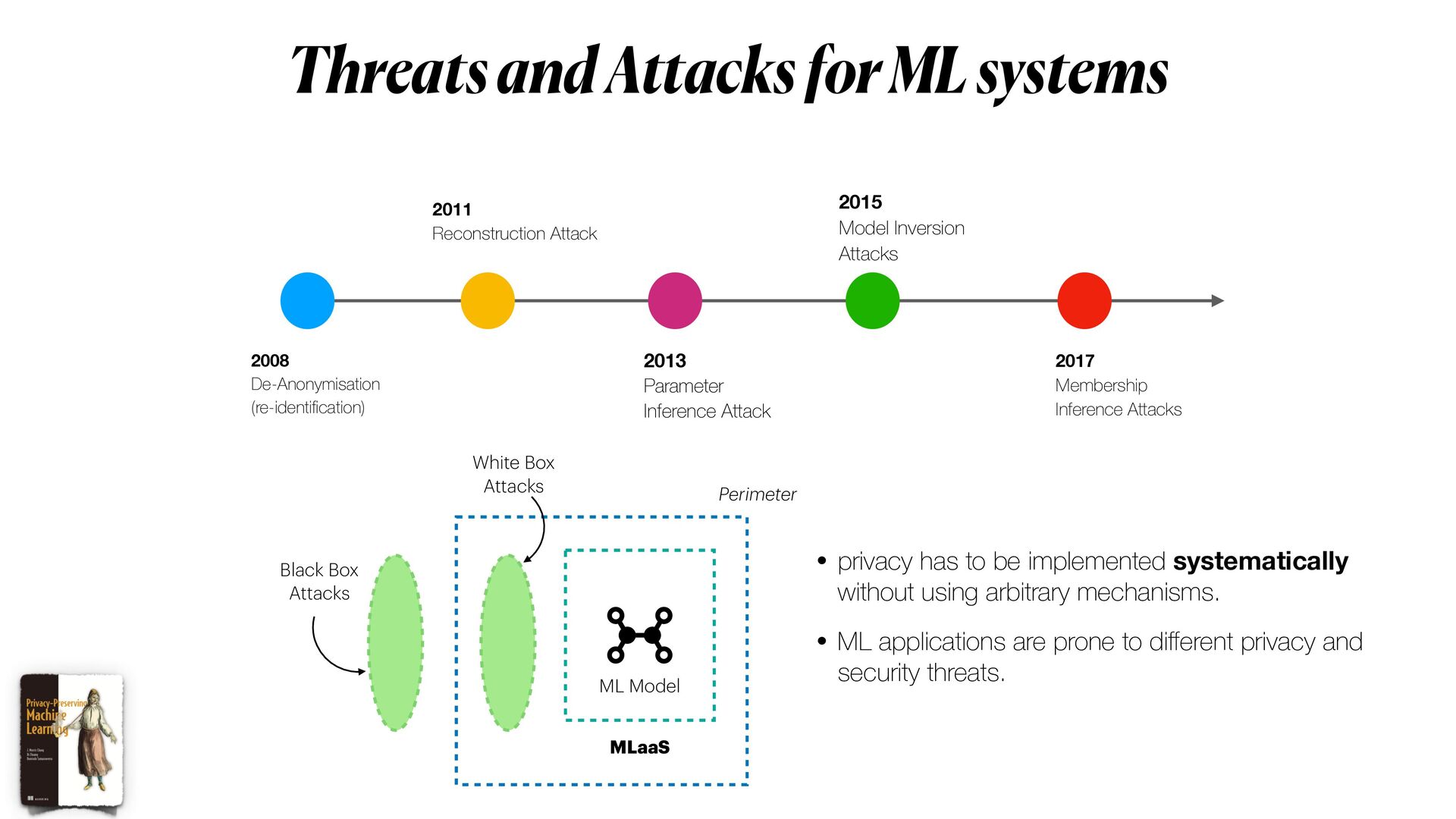
This workshop will be mainly organised in **three** main parts. In the first part, we will introduce the main threats to
data and machine learning models (e.g. _membership inference attack_ ) for privacy.
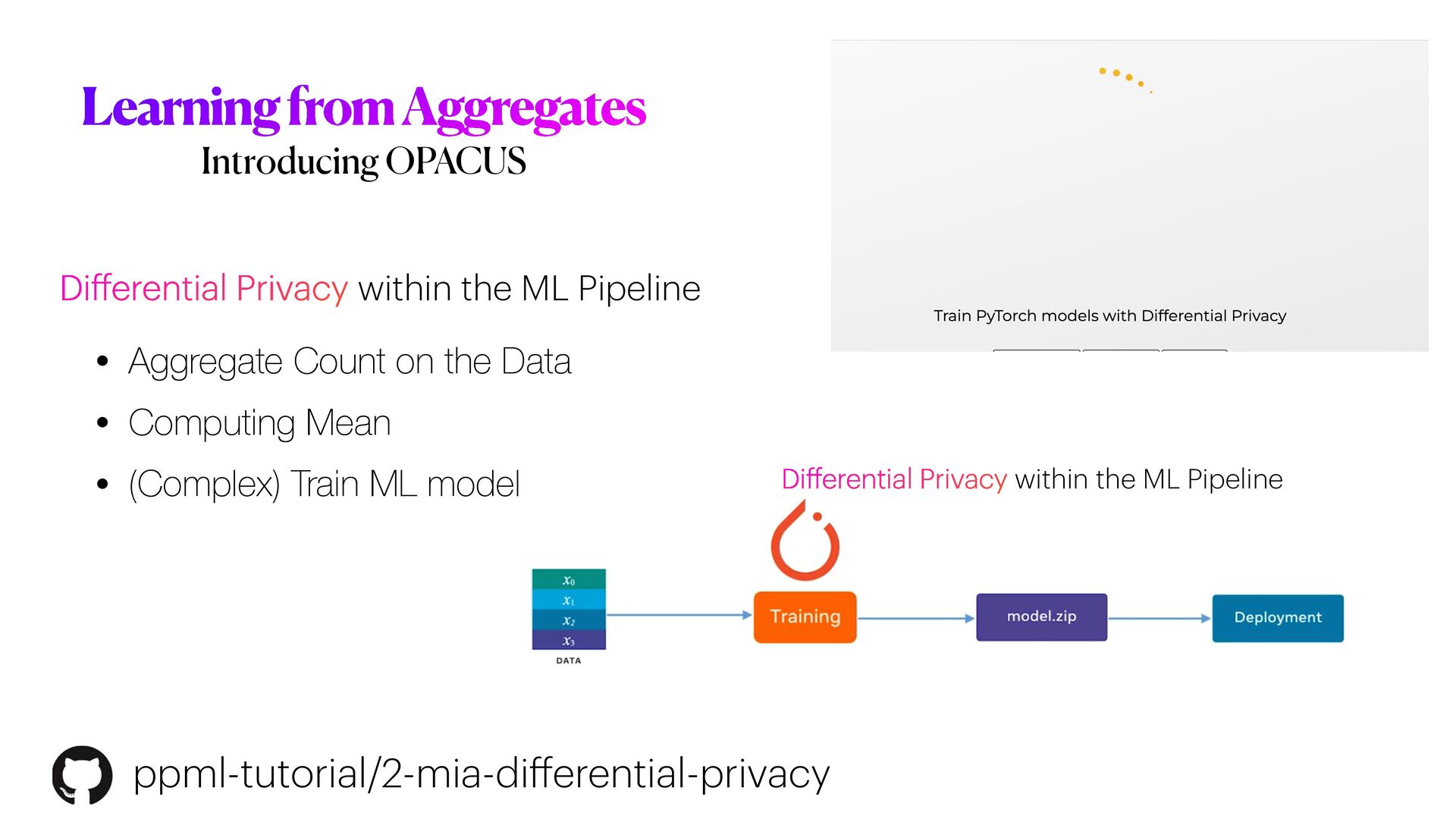
In the second part, we will work our way towards **differential privacy**: what is it, and how this method works, and
how differential privacy could be used with Machine learning.
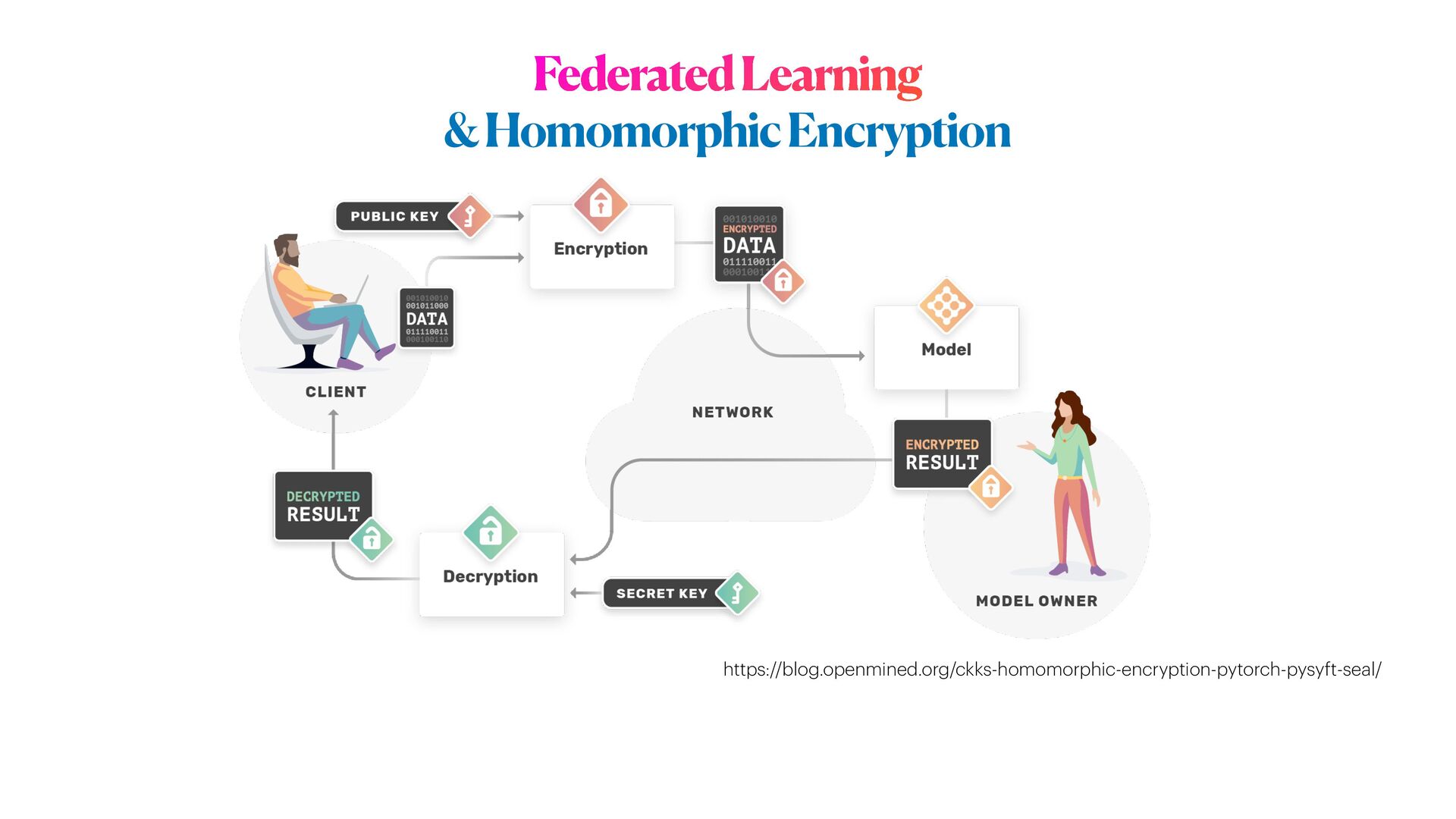
Lastly, we will conclude the tutorial considering more complex ML scenarios to train Deep learning networks on encrypted data, with specialised _distributed_ settings for **remote analytics**.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Privacy Issues Source: https://venturebeat.com/2020/04/07/2020-census-data-may-not-be-as-anonymous-as-expected/ […] (we) show how these](https://files.speakerdeck.com/presentations/86b7668f2cb7428e8f2aa40a58cadc47/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Valerio Maggio @leriomaggio [email protected]](https://files.speakerdeck.com/presentations/86b7668f2cb7428e8f2aa40a58cadc47/slide_42.jpg){kind=link}