If you talk (a lot) about Deep Learning, sooner or later, it inevitbly happens that you're asked
to explain what actually **Deep Learning** means, and what's all the fuss about it.
Indeed, answering this question in a proper way, may vary (and it has to) depending on
the kind of audience you've been talking to.
If you are talking to machine learning experts, you have to concentrate on what _deep_
means for the multiple learning models you can come up with.
Most importarly, you have to be very convincing about the performance of a deep learning model
against more standard and robust Random Forest or Support Vector Machine.
If your audience is made up of engineers, it is a completely different story.
Engineers don't give a damn.. are definitely more interested in how
implementing Artificial Neural Networks (ANN) in the most productive way, rather than
really understanding what are the implications of different *activations* and *optimizers*.
Eventually, if your audience is made up of data scientists - intended as the perfect mixture of the
previous two categories - according to
[Drew Conway](http://drewconway.com/zia/2013/3/26/the-data-science-venn-diagram) -
they are more or less interested in both the two aspects.
The other way, that is the _unconventional way_, to talk about Deep Learning,
is from the perspective of the computational model it requires to be properly effective.
Therefore, you may want to talk about ANN in terms of matrix multiplications algorithms,
parallel execution models, and GPU computing.
And this is **exactly** the perspecitve I intend to pursue in this talk.
This talk is for PyData scientists who are interested in understanding Deep Learning models
from the unconventional perspective of the GPUs.
Experienced engineers may likely benefit from this talk as well, learning how they can make their
models run fast(er).
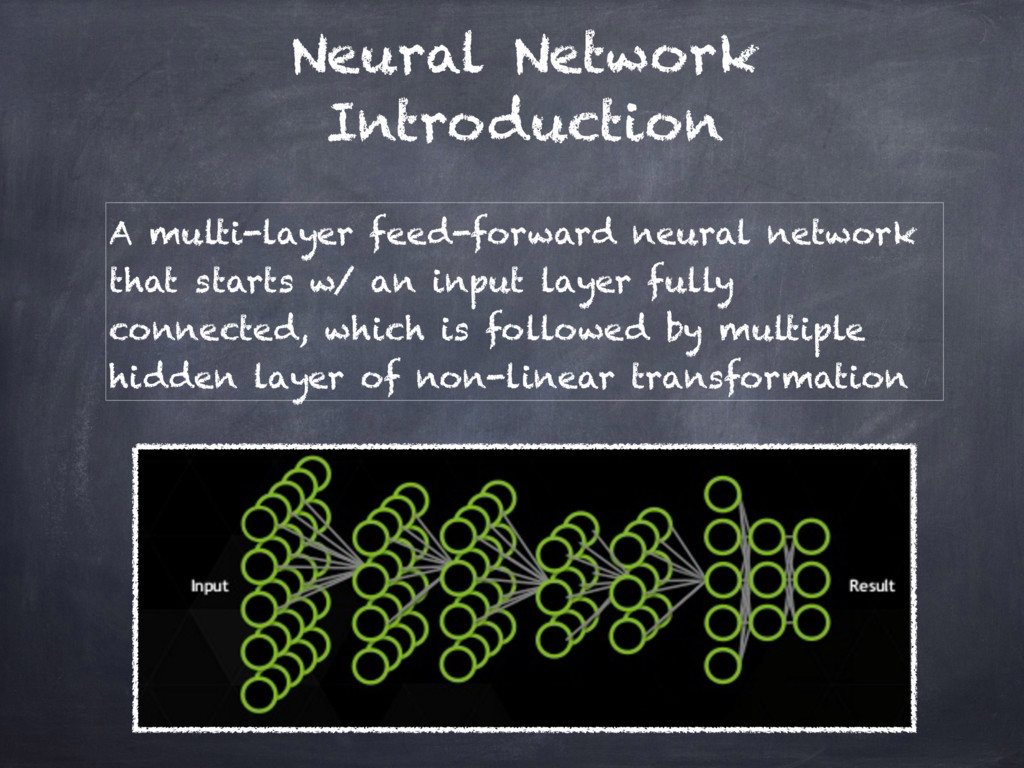
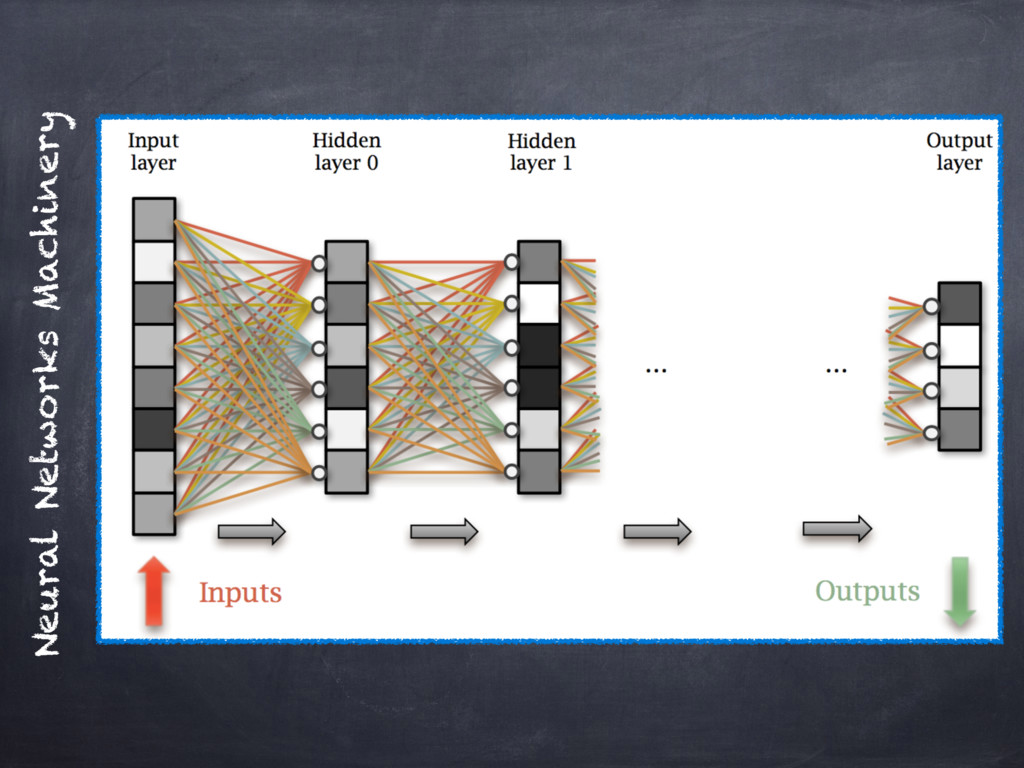
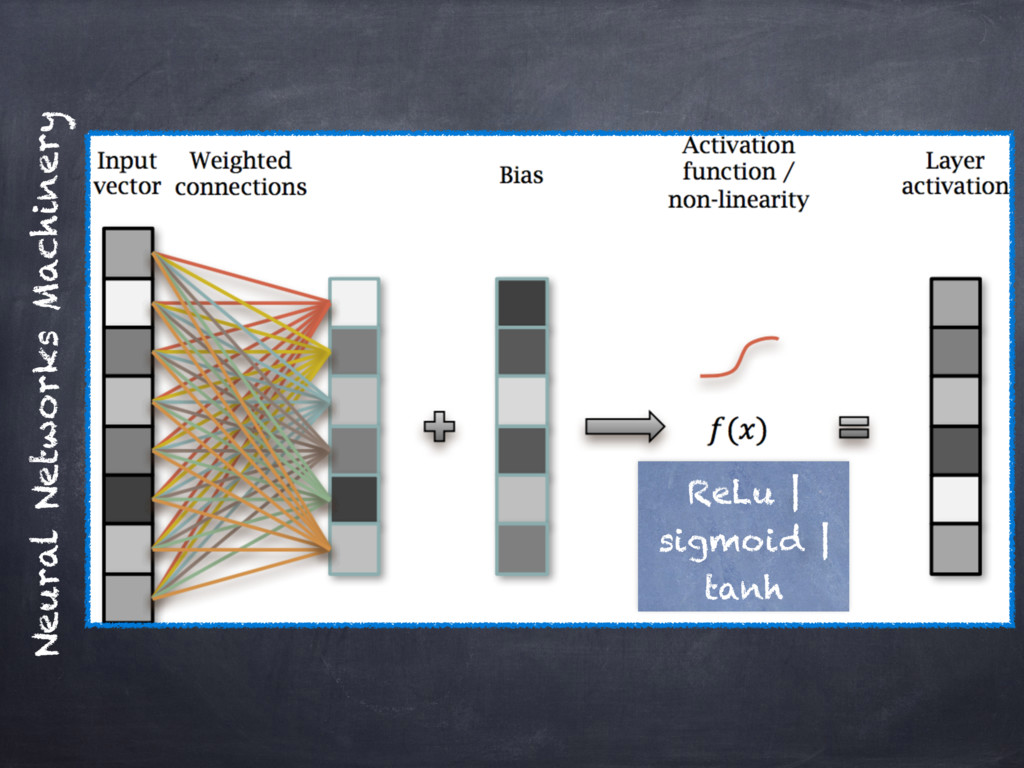
ANNs will be presented in terms of
_Accelerated Kernel Matrix Multiplication_ and the `gem[m|v]` BLAS library.
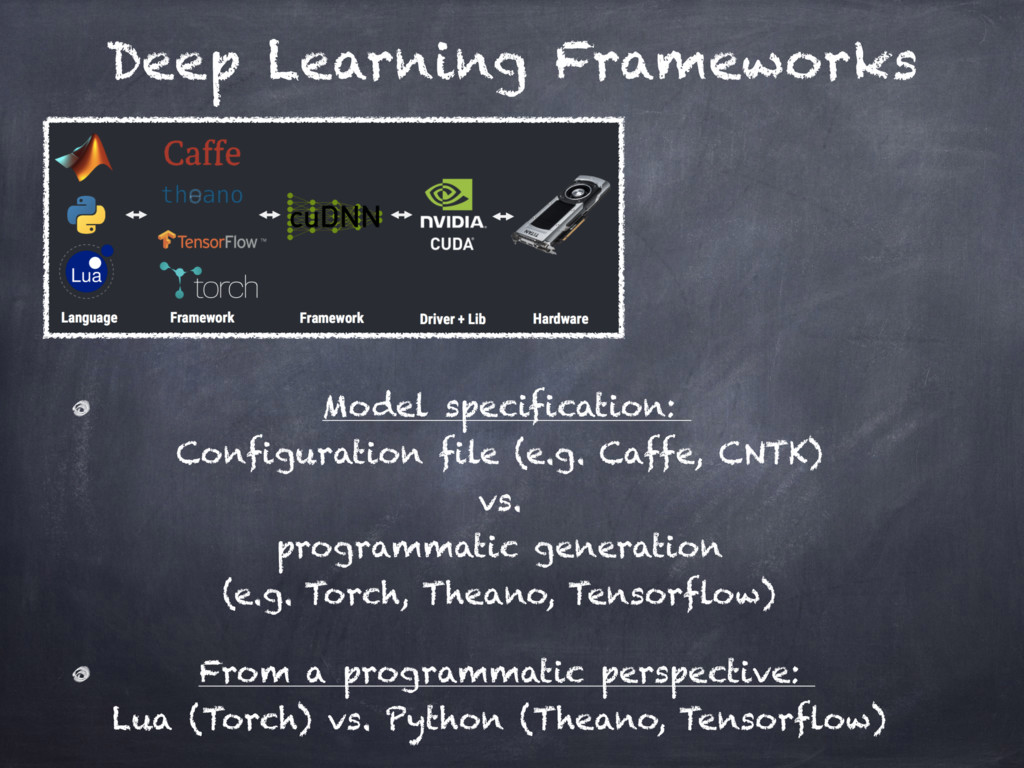
Different libraries and tools from the Python ecosystem will be presented (e.g. `numba`, `theano`, `tensorflow`).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
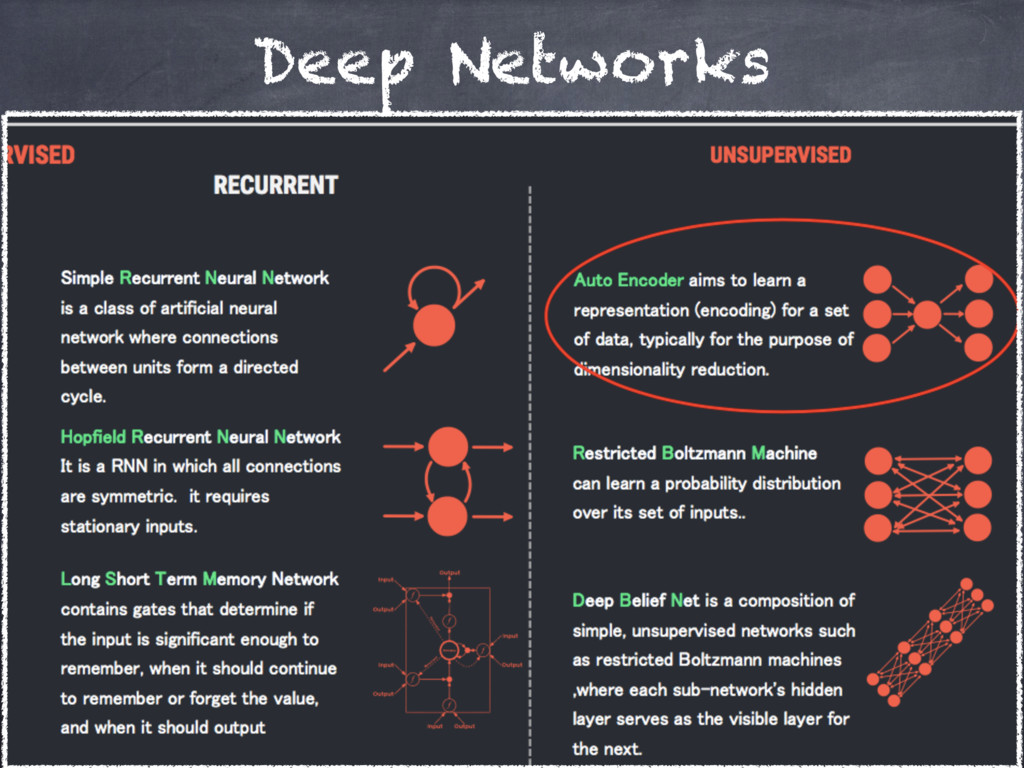{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
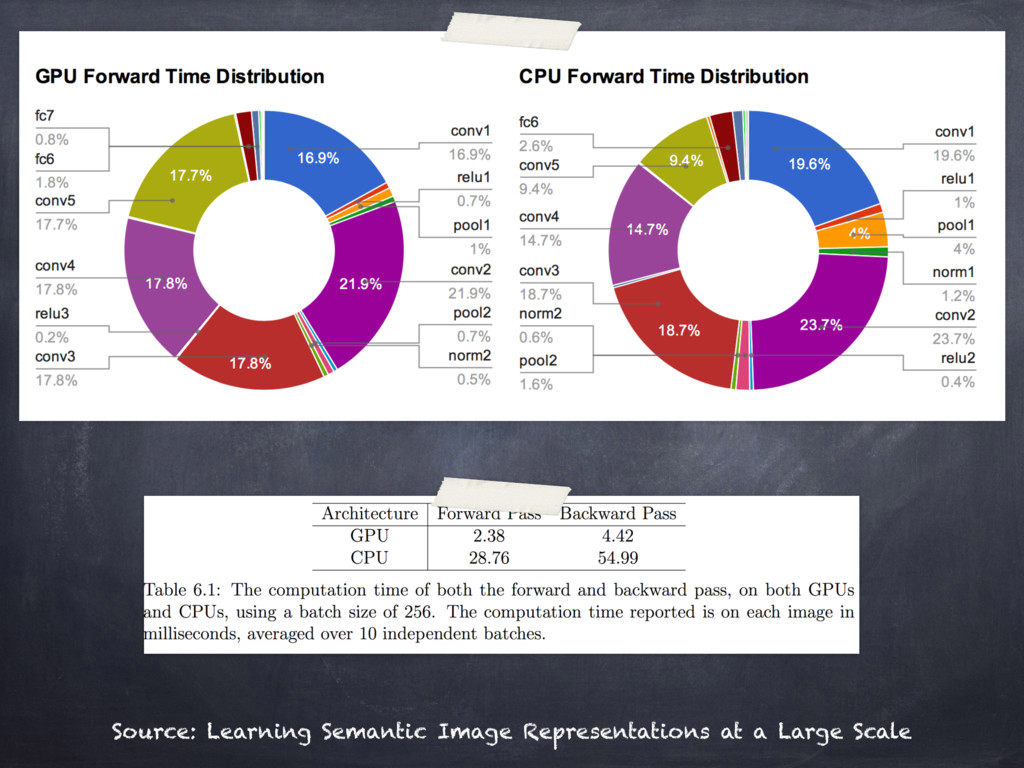{kind=link}
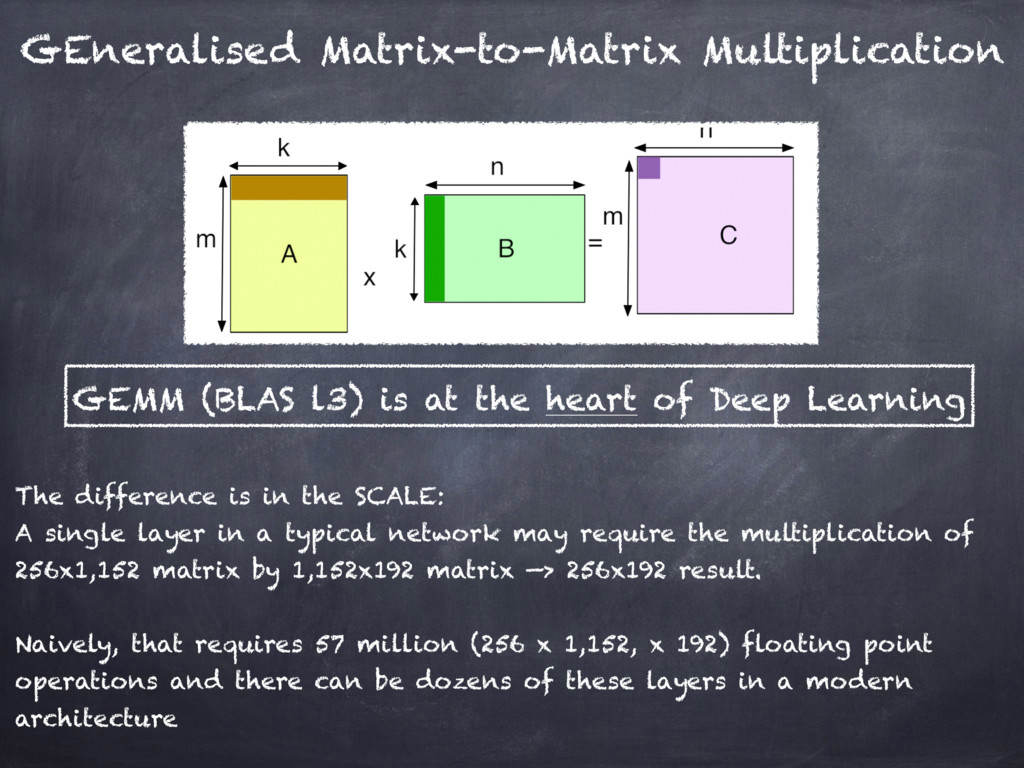{kind=link}
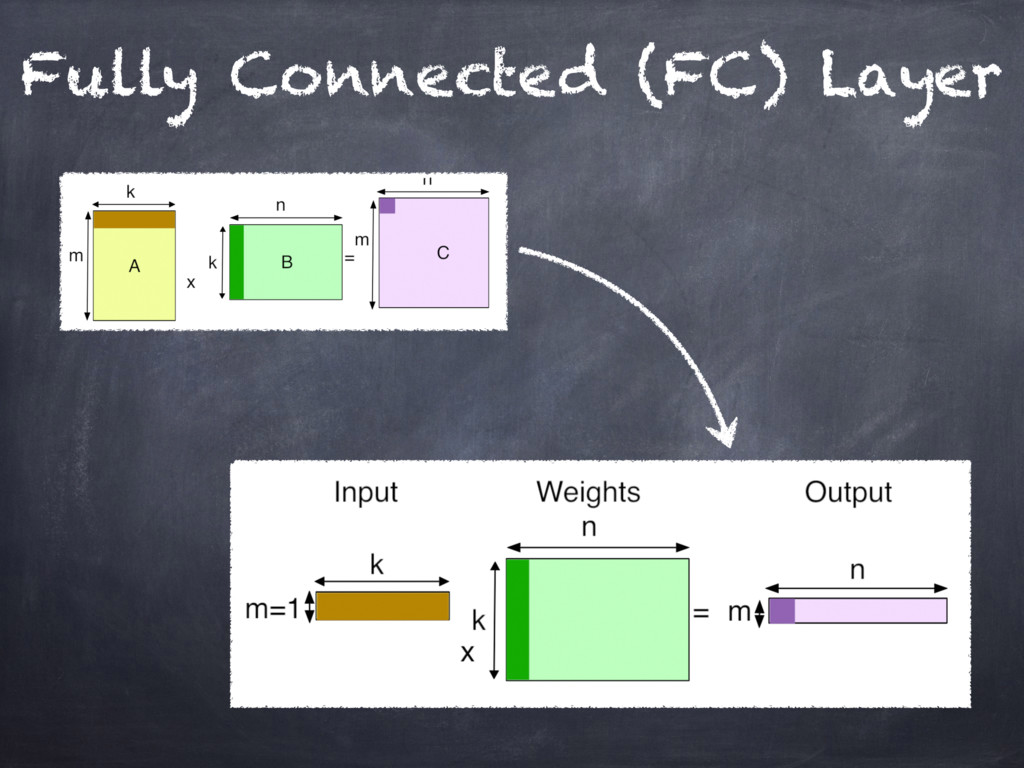{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![tf requires explicit evaluation In [1]: import numpy as np](https://files.speakerdeck.com/presentations/43a741a55d3b4cd286f8de347dcf9dff/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Logistic Neuron In [1]: import tensorflow as tf In [2]:](https://files.speakerdeck.com/presentations/43a741a55d3b4cd286f8de347dcf9dff/slide_44.jpg){kind=link}
![Logistic Neuron In [6]: learning_rate = 0.01 In [7]: #](https://files.speakerdeck.com/presentations/43a741a55d3b4cd286f8de347dcf9dff/slide_45.jpg){kind=link}
{kind=link}
{kind=link}