Share
下記で取り扱ったTransformerの簡易的な解説を公開します。
・Transformer と画像処理 https://lib-arts.booth.pm/items/2741653
TransformerはLLMのベースに用いられるなど、応用の幅が広いので抑えておくと良いと思います。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
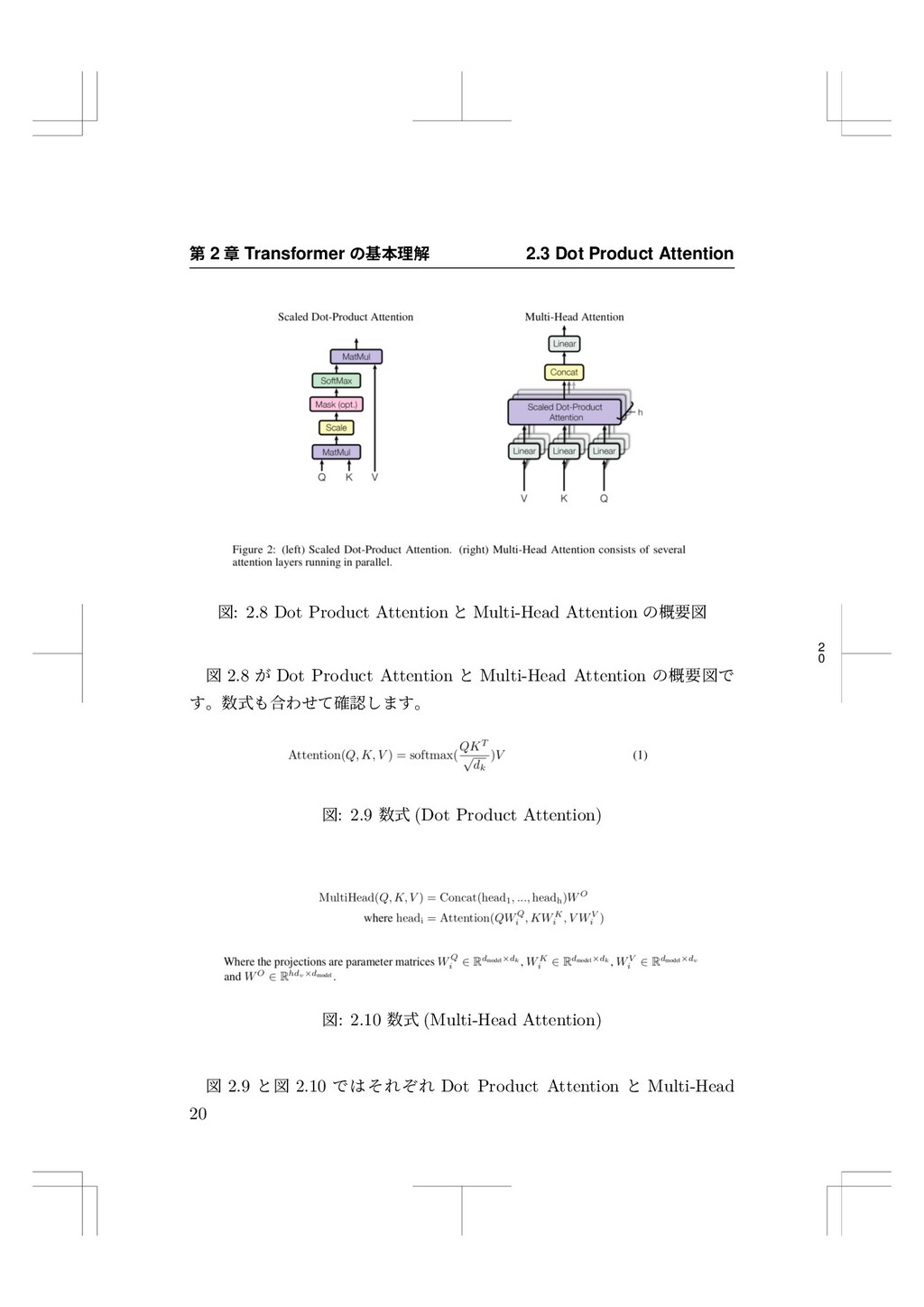{kind=link}
{kind=link}
{kind=link}
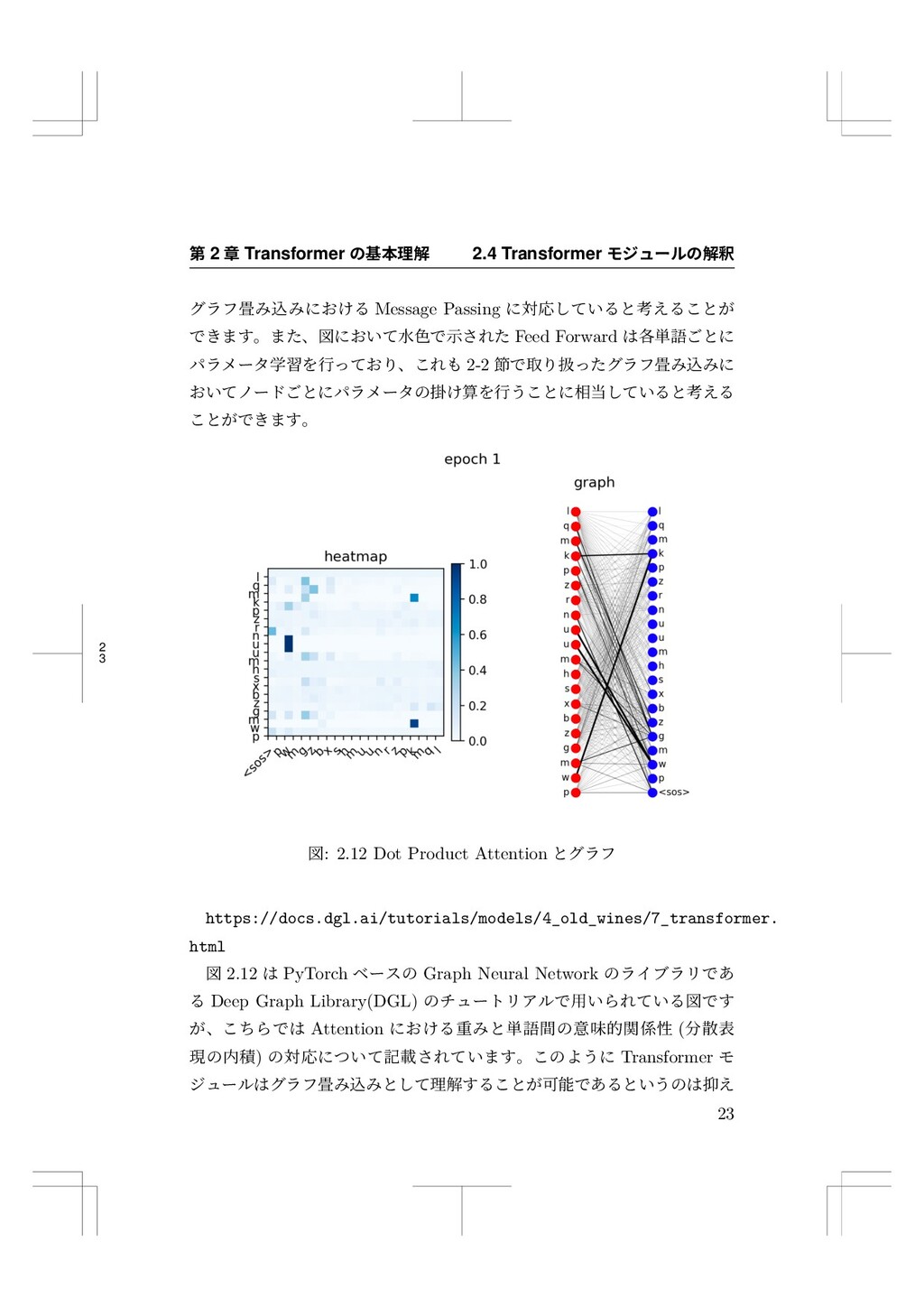{kind=link}
{kind=link}
{kind=link}
{kind=link}