Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Hadoop Operations
Search
Marc Cluet
June 09, 2013
Technology
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Hadoop Operations
Marc Cluet
June 09, 2013
More Decks by Marc Cluet
See All by Marc Cluet
FOSDEM'14 - Autoscaling Best Practices
lynxman
1
120
A metadata ocean in Chef and Puppet
lynxman
0
64
Rackspace Hack Night - Vagrant & Packer
lynxman
0
160
Innovation in the Cloud - Rackspace Zurich Event
lynxman
0
110
Introduction to DevOps - Rackspace Tech Night
lynxman
1
86
Introduction To Hadoop
lynxman
1
120
SSH That Wonderful Thing
lynxman
1
93
Networking & DNS 101
lynxman
0
100
Juju and Puppet - Rapid Harmonious Deployment
lynxman
0
110
Other Decks in Technology
See All in Technology
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
370
最高のシステムプロンプトを作るためにフィードバック機能を導入した話
alchemy1115
1
250
Atlassian Cloudサポート業務でのAIエージェント活用事例
smt7174
0
180
20260608_Codexの可能性_ノンプログラマー向け_大城追記
doradora09
PRO
0
700
AIエージェントに財布を渡す日 ― 承認付き"買い物エージェント"を作って実演
yama3133
0
110
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
190
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
750
組織にどうSREを根付かせるか?〜IVRyの場合〜
abnoumaru
0
180
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
710
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
870
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
2k
基調講演:人とAIをつなぐIoTの今と未来 ー 「フィジカル」と「デジタル」が出会うその先へ【SORACOM Discovery 2026】
soracom
PRO
0
370
Featured
See All Featured
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
Designing for Timeless Needs
cassininazir
1
430
HDC tutorial
michielstock
2
760
Mind Mapping
helmedeiros
PRO
1
290
Chasing Engaging Ingredients in Design
codingconduct
0
250
Skip the Path - Find Your Career Trail
mkilby
1
170
Building the Perfect Custom Keyboard
takai
2
820
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
600
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
470
Odyssey Design
rkendrick25
PRO
2
740
Agile that works and the tools we love
rasmusluckow
331
22k
Transcript
Marc Cluet – Lynx Consultants How Hadoop Works
What we’ll cover? ¡ Understand Hadoop in detail ¡
See how Hadoop works operationally ¡ Be able to start asking the right questions from your data Lynx Consultants © 2013
Hadoop Distributions ¡ Cloudera CDH ¡ Hortonworks ¡
MapR Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase ¡ MapRed
¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS § Hadoop Distributed File System
§ Everything sits on top of it § Has 3 copies by default of every block ¡ Hbase ¡ MapRed ¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase § Hadoop
Schemaless Database § Key value Store § Sits on top of HDFS ¡ MapRed ¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase ¡ MapRed
§ Hadoop Map/Reduce § Non-‐pluggable, archaic § Requires HDFS for temp storage ¡ YARN Lynx Consultants © 2013
Hadoop Components ¡ HDFS ¡ Hbase ¡ MapRed
¡ YARN § Hadoop Map/Reduce version 2.0 § Pluggable, you can add your own § Fast and not so much memory hungry Lynx Consultants © 2013
Hadoop Component Breakdown ¡ All these components divide themselves in
§ client/server § master/slave scenarios ¡ We will now check each individual component breakdown Lynx Consultants © 2013
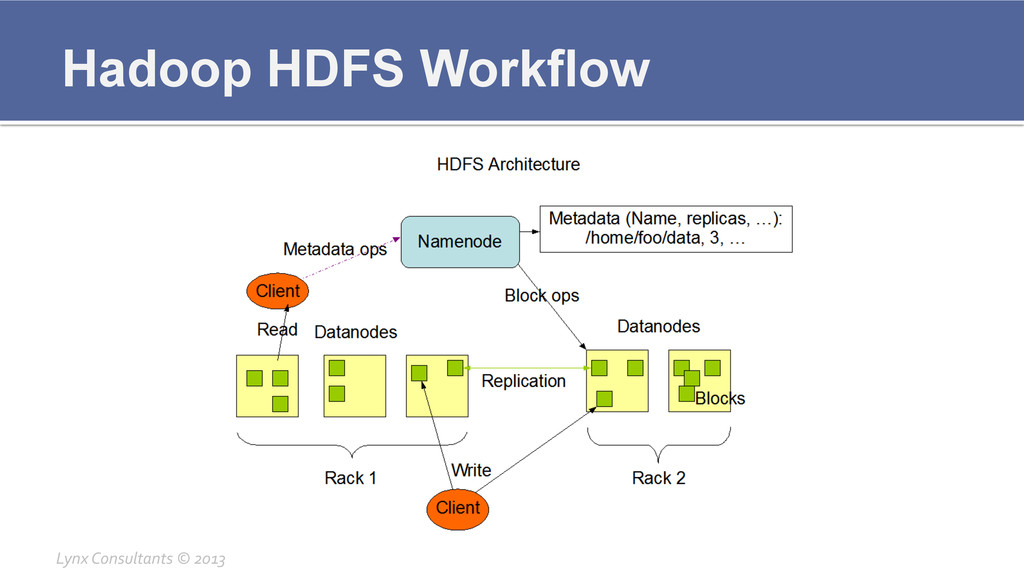
Hadoop Components Breakdown ¡ HDFS § Master Namenode
▪ Keeps track of all file allocation on Datanodes ▪ Rebalances data if one of the namenodes goes down ▪ Is Rack aware § Secondary Namenode ▪ Does cleanup services for the namenode ▪ Not necessarily two different servers § Datanode ▪ Stores the data ▪ Good to have not RAID disks for extra I/O speed Lynx Consultants © 2013
Hadoop Components Breakdown ¡ HDFS § How to access
▪ Client can connect with hadoop client to hdfs://namenode:8020 ▪ Supports all basic Unix commands § Configuration files ▪ /etc/hadoop/conf/core-‐site.xml ▪ Defines major configuration as hdfs namenode and default parameters ▪ /etc/hadoop/conf/hdfs-‐site.xml ▪ Defines configuration specific to namenode or datanode on file locations ▪ /etc/hadoop/conf/slaves ▪ Defines the list of servers that are available in this cluster Lynx Consultants © 2013
Hadoop Components Breakdown ¡ Hbase § Master ▪
Controls the Hbase cluster, knows where the data is allocated and provides a client listening socket using Thrift and/or a RESTful API § Regionserver ▪ Hbase node, stores some of the information in one of the regions, it’d be equivalent to sharding § Thrift / REST ▪ Interface to connect to HBase Lynx Consultants © 2013
Hadoop Components Breakdown ¡ Hbase § How to access
▪ Through the Hbase client (using Thrift) ▪ Through the RESTful API § Configuration files ▪ /etc/hbase/conf/hbase-‐site.xml ▪ Defines all the basic configuration for accessing hbase ▪ /etc/hbase/conf/hbase-‐policy.xml ▪ Defines all the security (ACL) and all the hbase memory tweaks ▪ /etc/hbase/conf/regionservers ▪ List all the regionservers available to this cluster Lynx Consultants © 2013
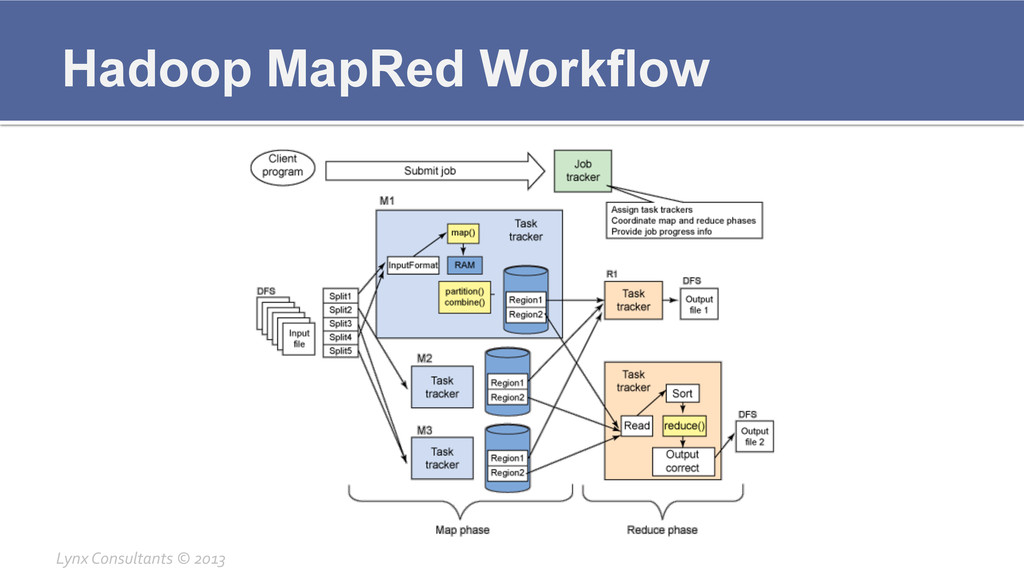
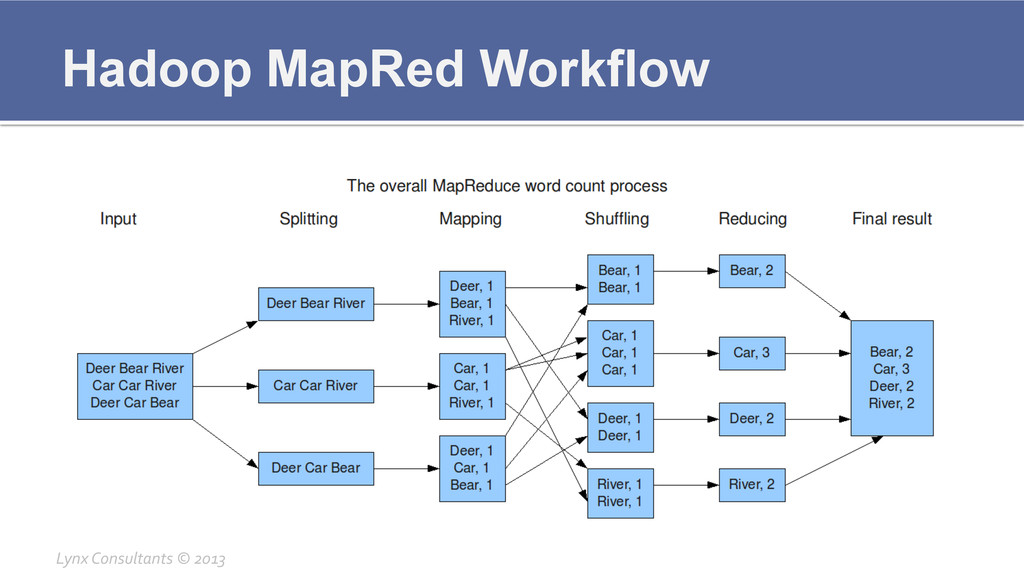
Hadoop Components Breakdown ¡ MapRed § JobTracker ▪
Creates the Map/Reduce jobs ▪ Stores all the intermediate data ▪ Keeps track of all the previous results through the HistoryServer § TaskTracker ▪ Executed Tasks related to the Map/Reduce job ▪ Very CPU and memory intensive ▪ Stores intermediate results which then are pushed to JobTracker Lynx Consultants © 2013
Hadoop Components Breakdown ¡ MapRed § How to access
▪ Through the Hadoop Client ▪ Through any MapRed client like Pig or Hive ▪ Own Java code § Configuration files ▪ /etc/hadoop/conf/mapred-‐site.xml ▪ Defines how to contact this MapRed Cluster ▪ /etc/hadoop/conf/mapred-‐queue-‐acls.xml ▪ Defines ACL structure for accessing MapRed, normally not necessary ▪ /etc/hadoop/conf/slaves ▪ Defines the list of TaskTrackers in this cluster Lynx Consultants © 2013
Hadoop Components Breakdown ¡ YARN § Same structure as
MapRed (lives on top of it) § Configuration files ▪ /etc/hadoop/conf/yarn-‐site.xml ▪ All required configuration for YARN Lynx Consultants © 2013
Hadoop Cluster Breakdown ¡ Namenode Server § HDFS Namenode
§ Hbase Master ¡ Secondary Namenode Server § HDFS Secondary Namenode ¡ JobTracker Server § MapRed JobTracker § MapRed History Server Lynx Consultants © 2013
Hadoop Cluster Breakdown ¡ Datanode Server § HDFS Datanode
§ Hbase RegionServer § MapRed TaskTracker Lynx Consultants © 2013
Hadoop Hardware Requirements ¡ Namenode Server § Redundant power
supplies § RAID1 Drives § Enough memory (16Gb) ¡ Secondary Namenode Server § Almost none Lynx Consultants © 2013
Hadoop Hardware Requirements ¡ Jobtracker Server § Redundant power
supplies § RAID1 Drives § Enough memory (16Gb) ¡ Datanode Server § Lots of cheap disk (no RAID) § Lots of memory (32Gb) § Lots of CPU Lynx Consultants © 2013
Hadoop Default Ports ¡ HDFS § 8020: HDFS Namenode
§ 50010: HDFS Datanode FS transfer ¡ MapRed § No defaults ¡ Hbase § 60010: Master § 60020: Regionserver Lynx Consultants © 2013
Hadoop HDFS Workflow Lynx Consultants © 2013
Hadoop MapRed Workflow Lynx Consultants © 2013
Hadoop MapRed Workflow Lynx Consultants © 2013
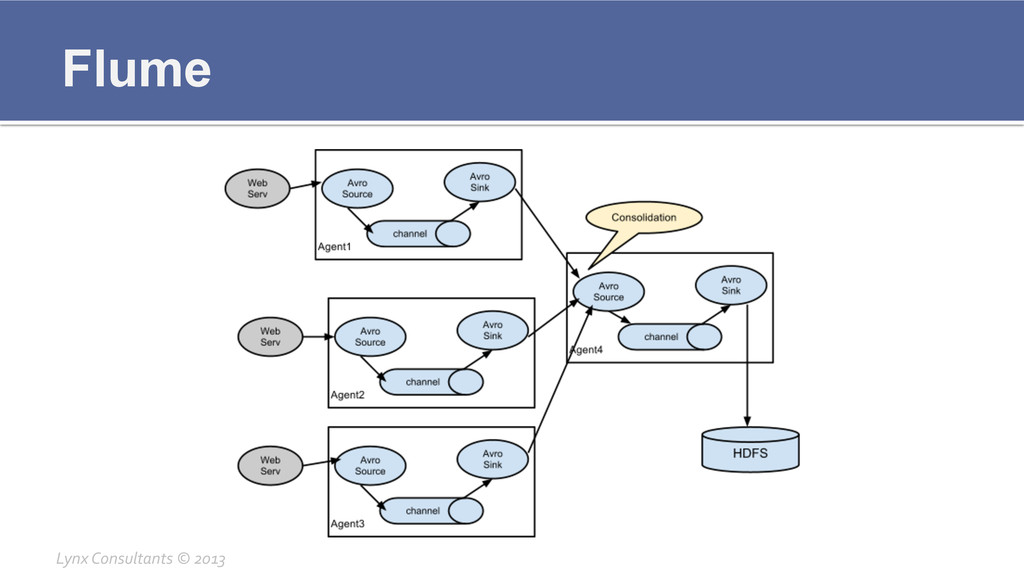
Flume ¡ Transports streams of data from point A to
point B ¡ Source § Where the data is read from ¡ Channel § How the data is buffered ¡ Sink § Where the data is written Lynx Consultants © 2013
Flume ¡ Flume is fault tolerant ¡ Sources are
pointer kept § With some exceptions, but most sources are in a known state ¡ Channels can be fault tolerant § Channel written to disk can recover from where it left ¡ Sinks can be redundant § More than one sink for the same data § Data is serialised and deduplicated using AVRO Lynx Consultants © 2013
Flume Lynx Consultants © 2013
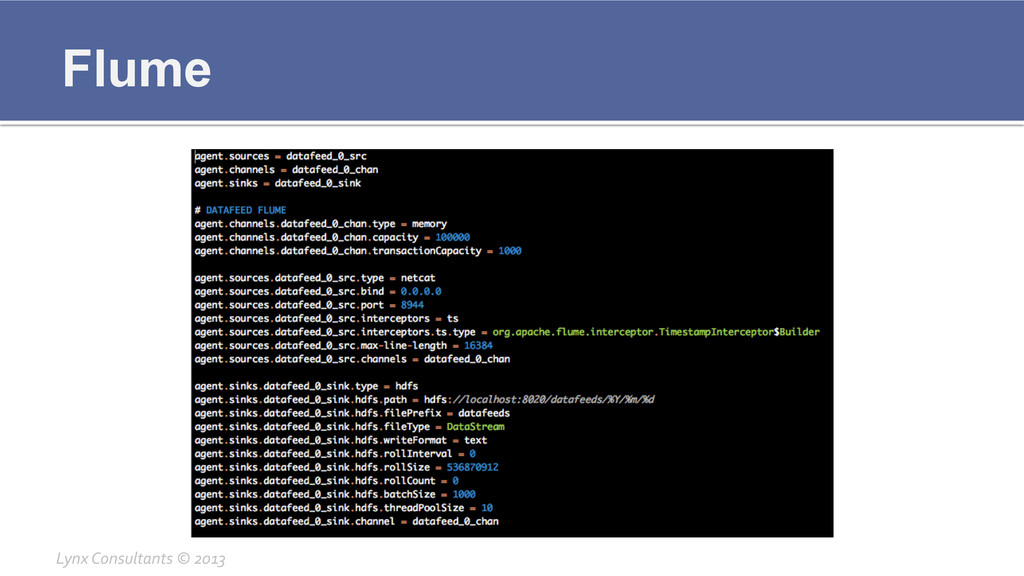
Flume ¡ Configuration files § /etc/flume-‐ng/conf/flume.conf ▪ Defines
the agent configuration with source, channel, sink Lynx Consultants © 2013
Flume Lynx Consultants © 2013
Hadoop Recommended Reads Lynx Consultants © 2013
Hadoop References ¡ Hadoop § http://hadoop.apache.org/docs/stable/cluster_setup.html § http://rc.cloudera.com/cdh/4/hadoop/hadoop-‐yarn/hadoop-‐yarn-‐site/
ClusterSetup.html § http://pig.apache.org/docs/r0.7.0/setup.html § http://wiki.apache.org/hadoop/NameNodeFailover ¡ Hbase § http://hbase.apache.org/book/book.html ¡ Flume § http://archive.cloudera.com/cdh4/cdh/4/flume-‐ng/ FlumeUserGuide.html Lynx Consultants © 2013
Questions? Lynx Consultants © 2013
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}