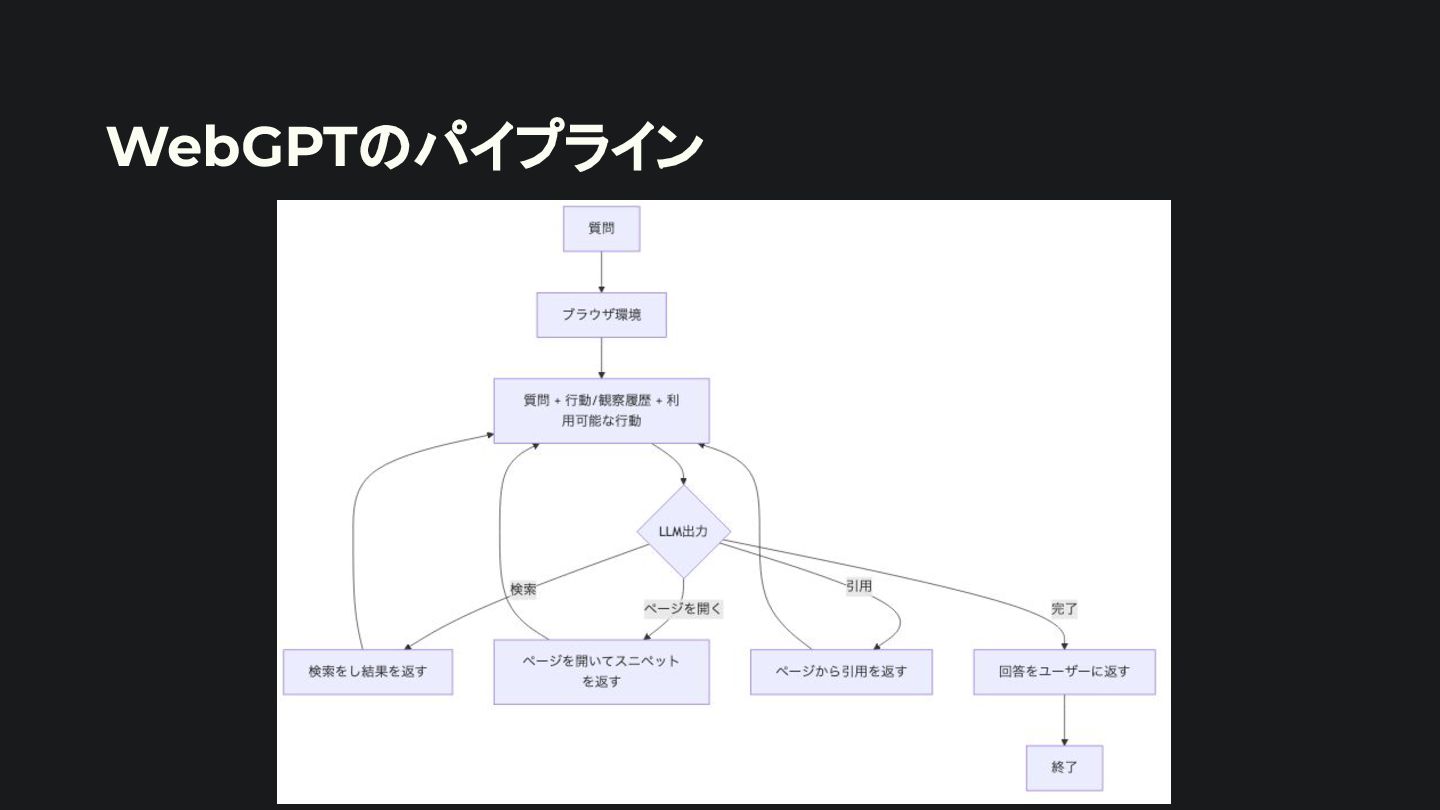
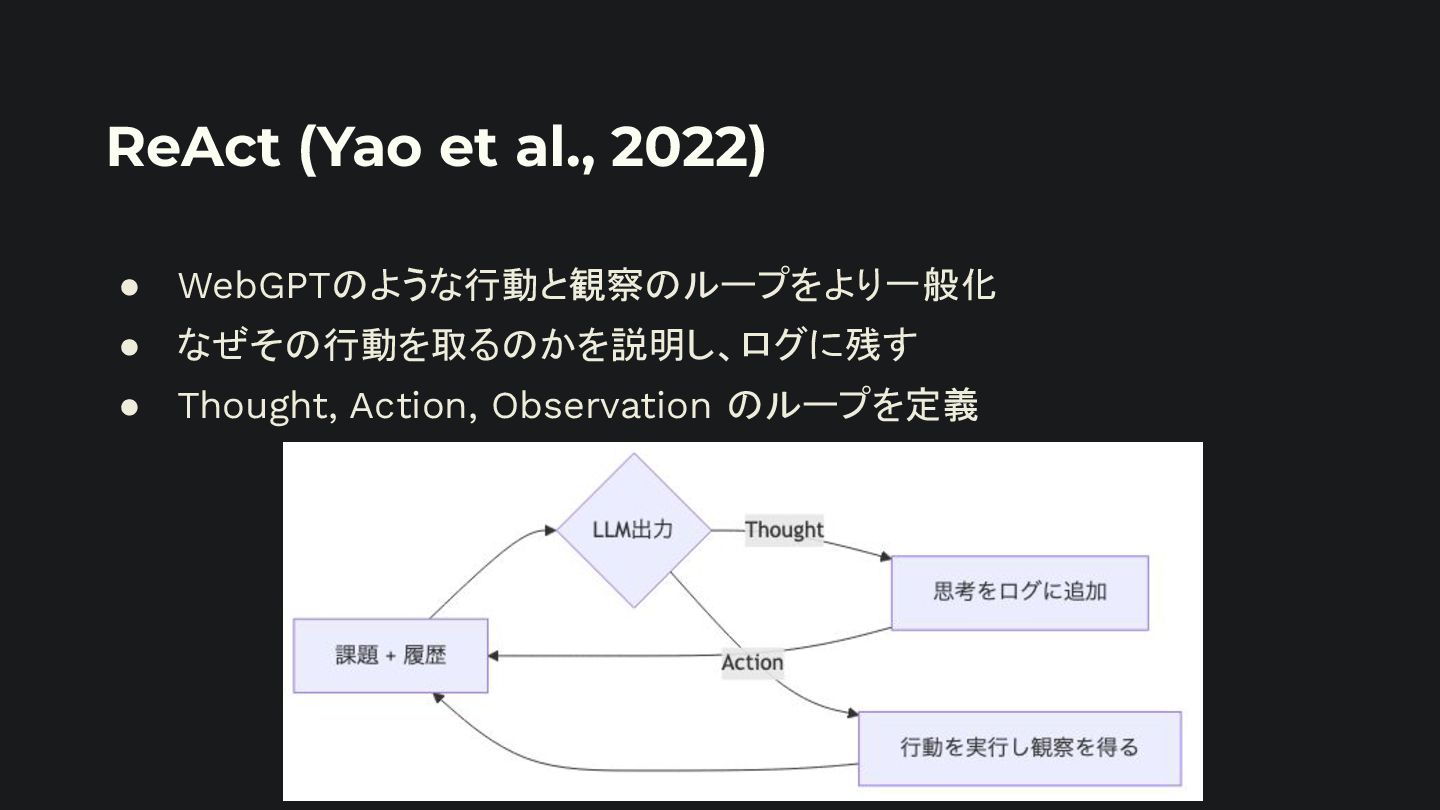
Observation steps. Thought can reason about the current situation, and Action can be three types:<Actionの説明> Here are some examples. <例を示す> Chain of Thought(Wei et al., 2022) と Few-Shot(Brown et al., 2020)を組み合わせたプロン プト
Mukai. Misreading Chat: #143 Can Language Models Resolve Real-World GitHub Issues?. ポッドキャ スト, 2024 • Vaswani, A. et al. 2017. Attention is All You Need. • Radford, A. et al. 2018. Improving Language Understanding by Generative Pre-Training.(GPT)
with human feedback. • Chen, M. et al. 2021. Evaluating Large Language Models Trained on Code.(HumanEval / Codex) • Hendrycks, D. et al. 2021. Measuring Coding Challenge Competence with APPS. • Ouyang, L. et al. 2022. Training language models to follow instructions with human feedback.(InstructGPT)
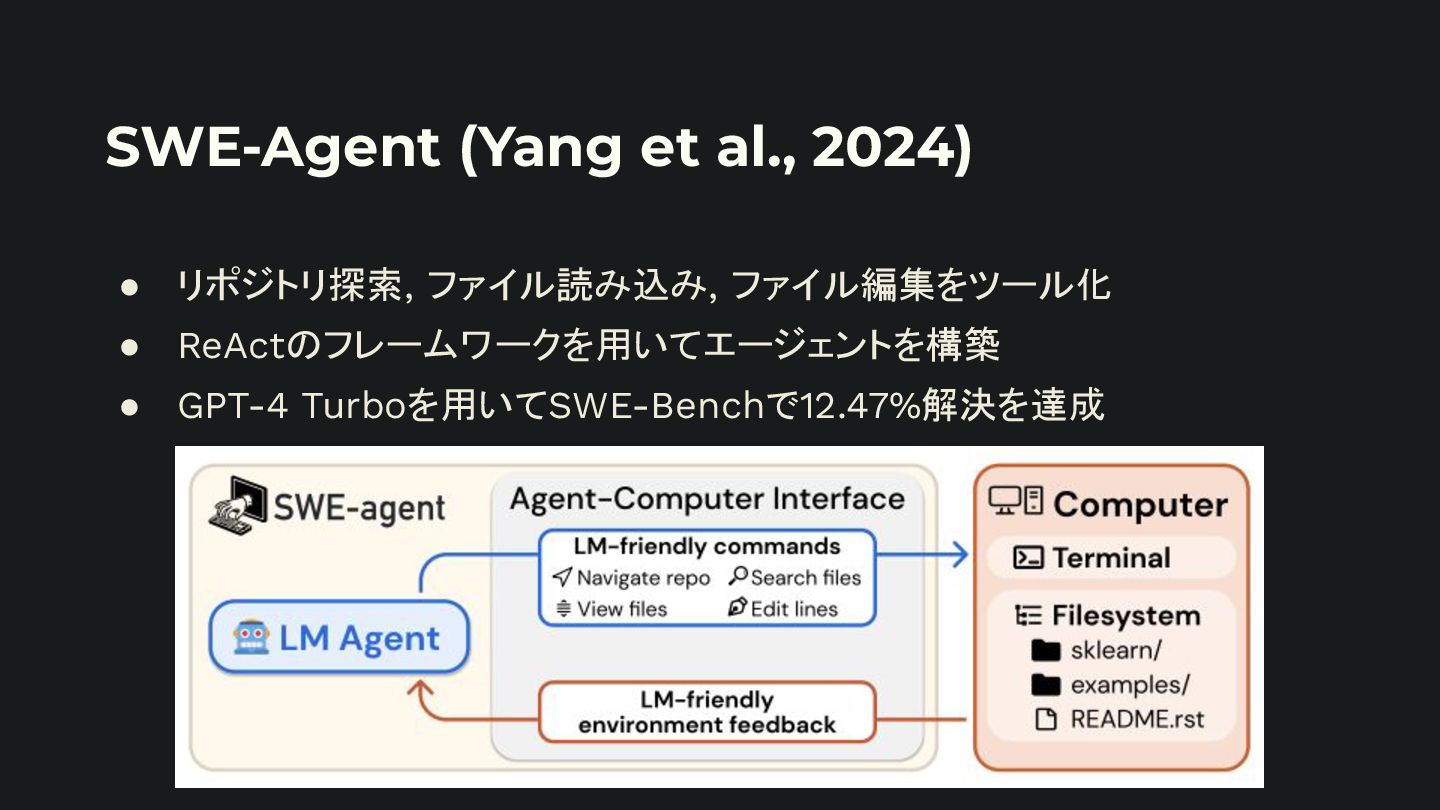
Reasoning in Large Language Models. • Yao, S. et al. 2022. ReAct: Synergizing Reasoning and Acting in Language Models. • Liu, H. et al. 2023. Lost in the Middle: How Language Models Use Long Context. • Shinn, N. et al. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[AD]Perl Anybatrossやっています https://perlbatross.kayac.com/ • 前回,前々回のYAPCでも行なったコードゴルフコンテスト • 今回からPerl以外の言語にも対応しました](https://files.speakerdeck.com/presentations/cd7fba011b0842d3943c66ee3a6ab829/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [ ] APIクライアントを作成 • [ ] メッセージを受け取ってLLMに投げて応答を表示 • [](https://files.speakerdeck.com/presentations/cd7fba011b0842d3943c66ee3a6ab829/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [x] APIクライアントを作成 • [x] メッセージを受け取って LLMに投げて応答を表示 • [ ]](https://files.speakerdeck.com/presentations/cd7fba011b0842d3943c66ee3a6ab829/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [x] APIクライアントを作成 • [x] メッセージを受け取ってLLMに投げて応答を表示 • [x] Perlコードの生成 •](https://files.speakerdeck.com/presentations/cd7fba011b0842d3943c66ee3a6ab829/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [x] APIクライアントを作成 • [x] メッセージを受け取ってLLMに投げて応答を表示 • [x] Perlコードの生成 •](https://files.speakerdeck.com/presentations/cd7fba011b0842d3943c66ee3a6ab829/slide_49.jpg){kind=link}
{kind=link}
{kind=link}
![• [x] APIクライアントを作成 • [x] メッセージを受け取ってLLMに投げて応答を表示 • [x] Perlコードの生成 •](https://files.speakerdeck.com/presentations/cd7fba011b0842d3943c66ee3a6ab829/slide_52.jpg){kind=link}
{kind=link}
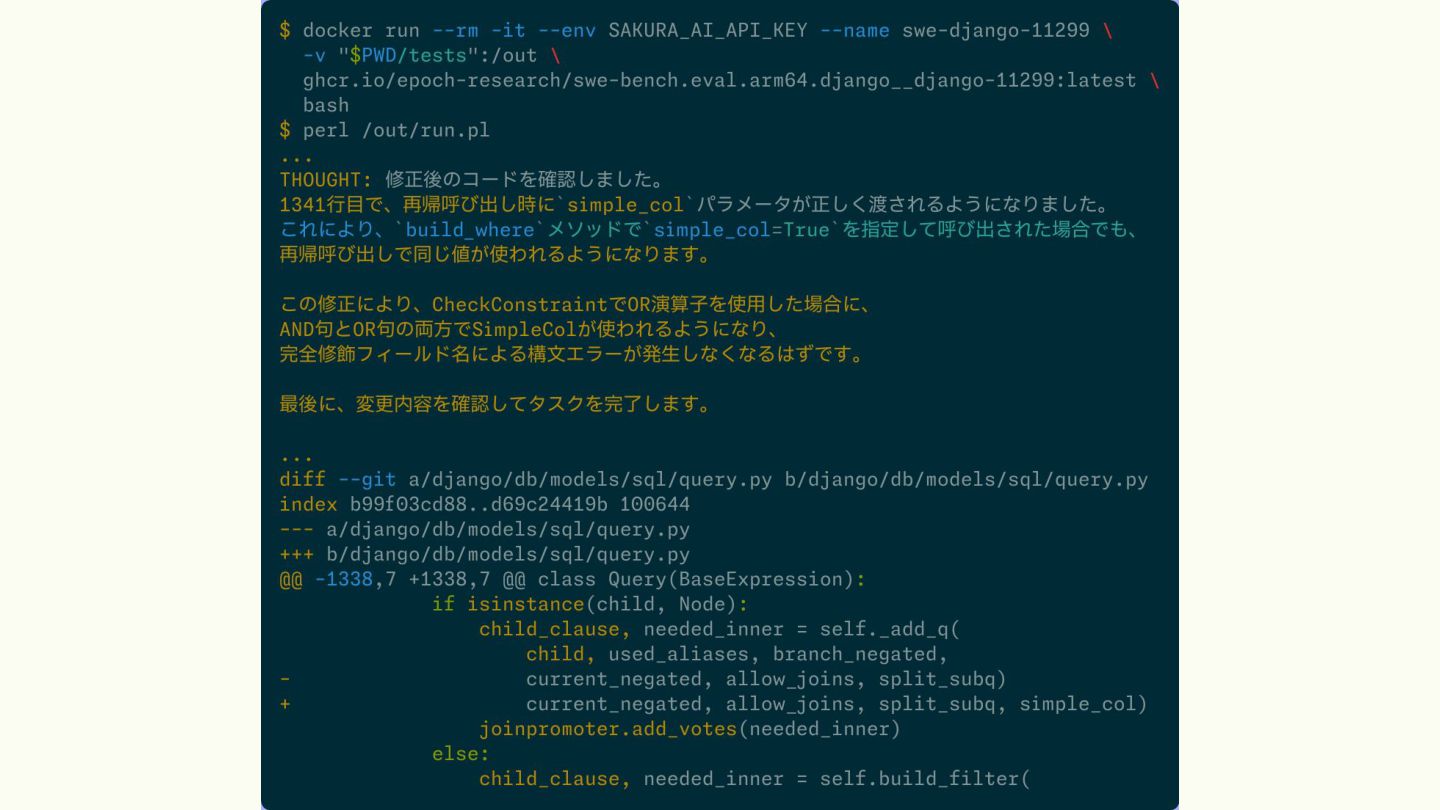{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}