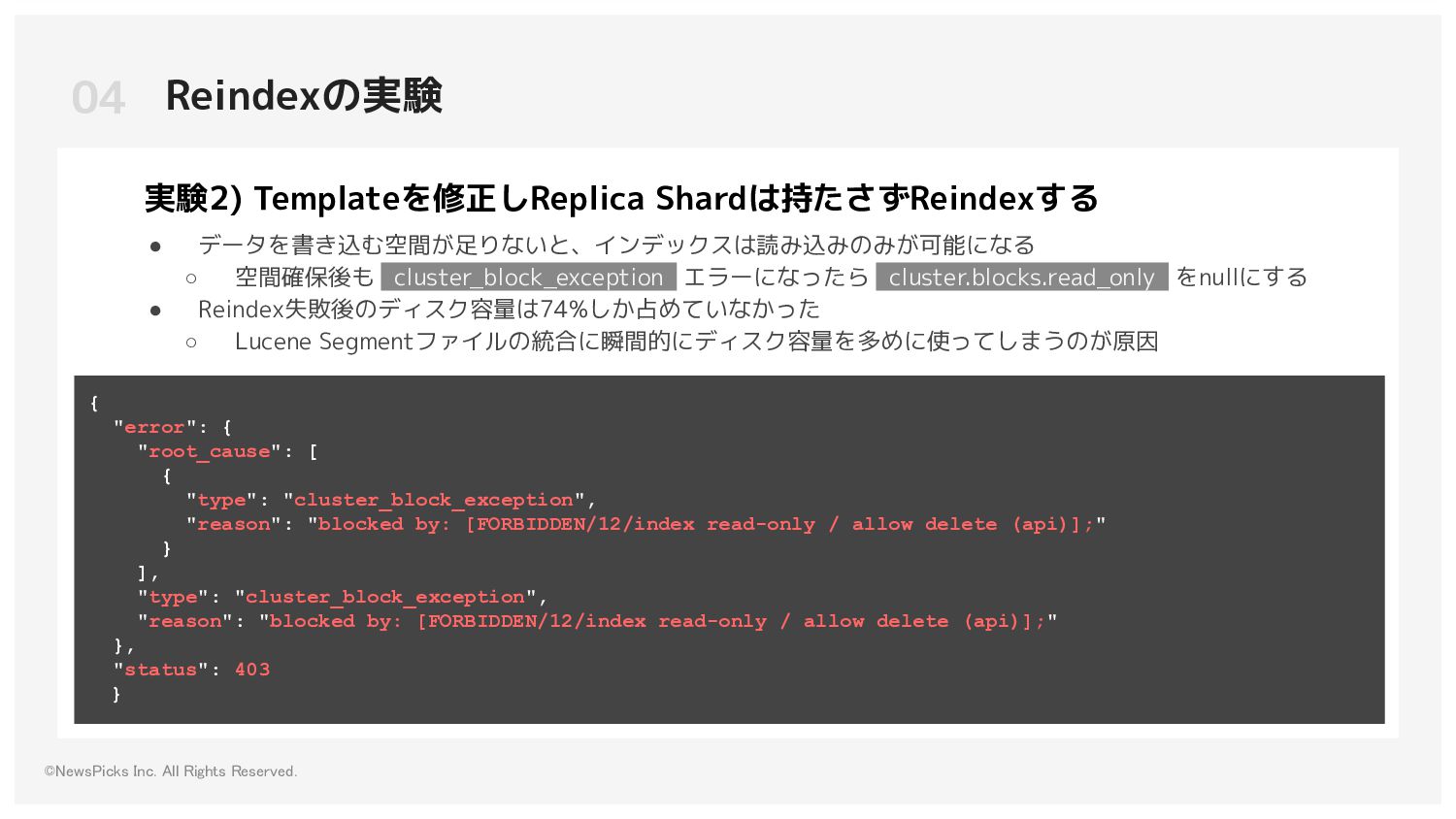
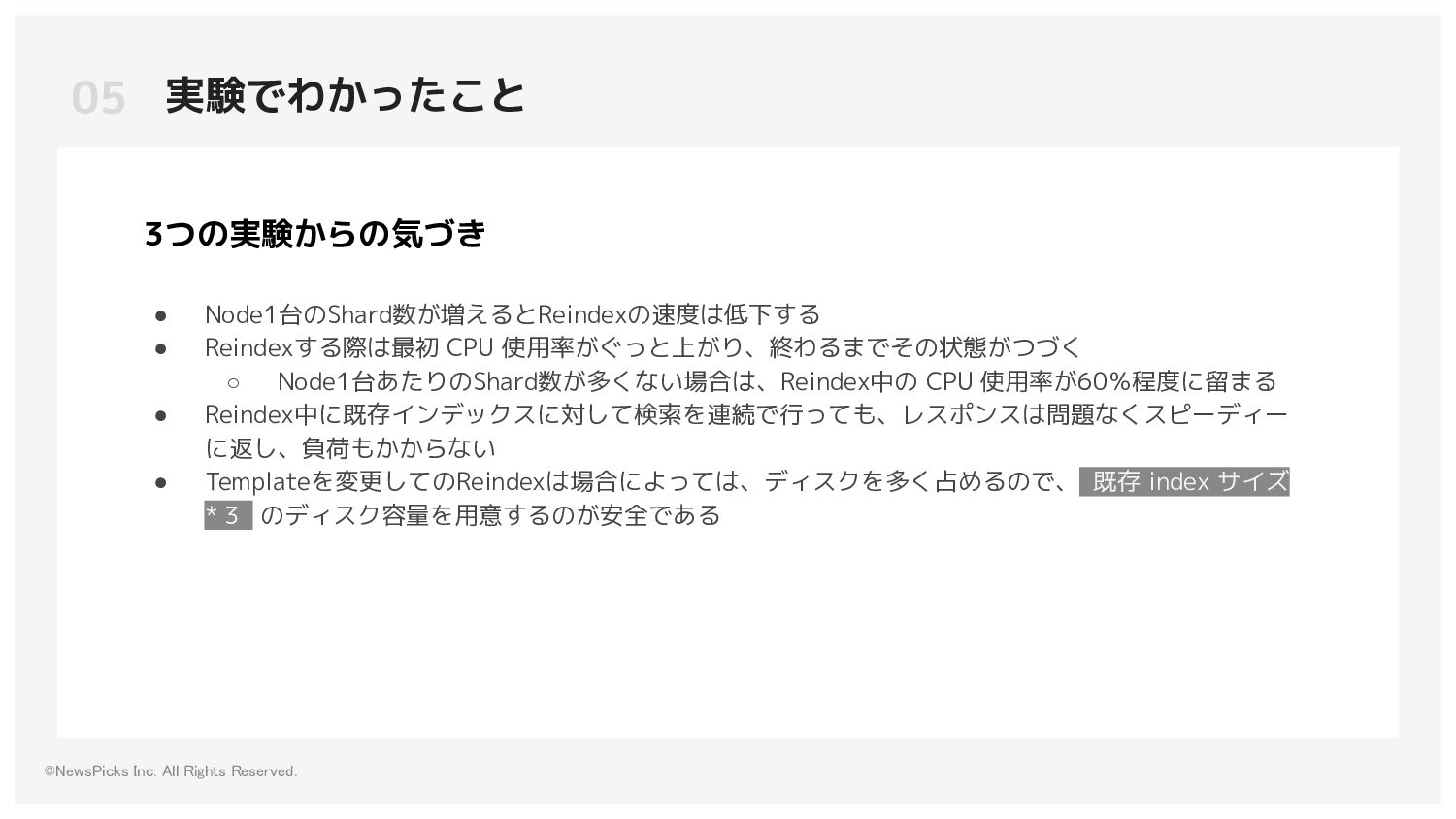
◦ Primary Shard数:1 ◦ Replica Shard数:0 ◦ e(replica shard 数 + 1) * primary shard 数 = (0 + 1) * 1 = 1e になり、Shardは1つのみ 実験結果 • 実験1)よりReindexにかかる時間が3倍短縮できた • Replica Shard数が本番より少ない場合、Node Failureが起きる ◦ 実験に使ったインデックスはNode1台当たり15GBだが、40GBのNode1台に収まらない 実験2) Templateを修正しReplica Shardは持たさずReindexする 04 Reindexの実験 [2022-03-31T03:52:53,741][WARN ][o.e.c.r.a.AllocationService] [ip-{node_ip_address}] failing shard [failed shard, shard [some_index][0], node[{node_id}], relocating [{id}], [P], recovery_source[peer recovery], s[INITIALIZING], a[id={id} rId={id}], expected_shard_size[18148402752], message [shard failure, reason [index]], failure [IOException[No space left on device]], markAsStale [true]]java.io.IOException: No space left on device
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}