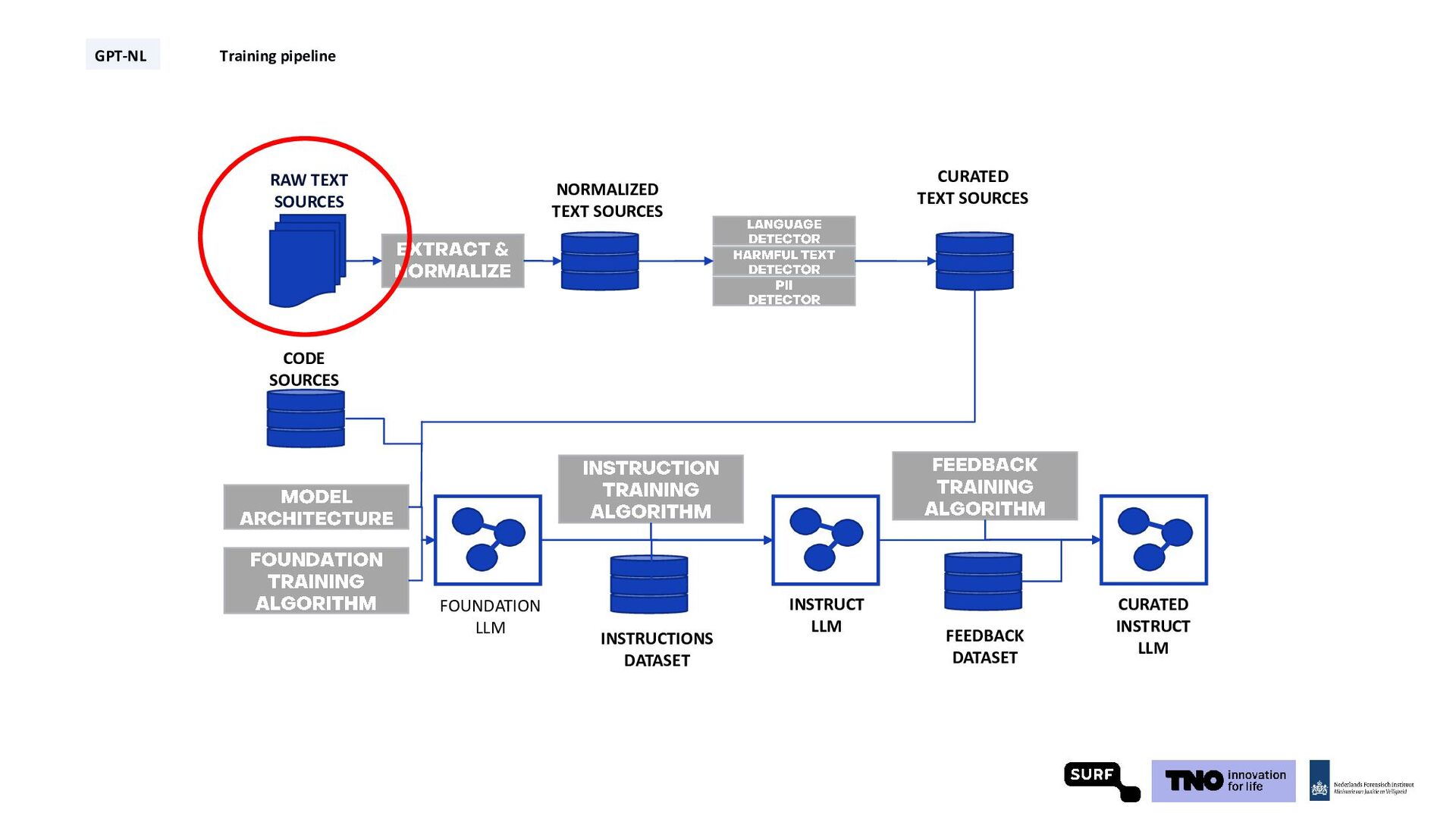
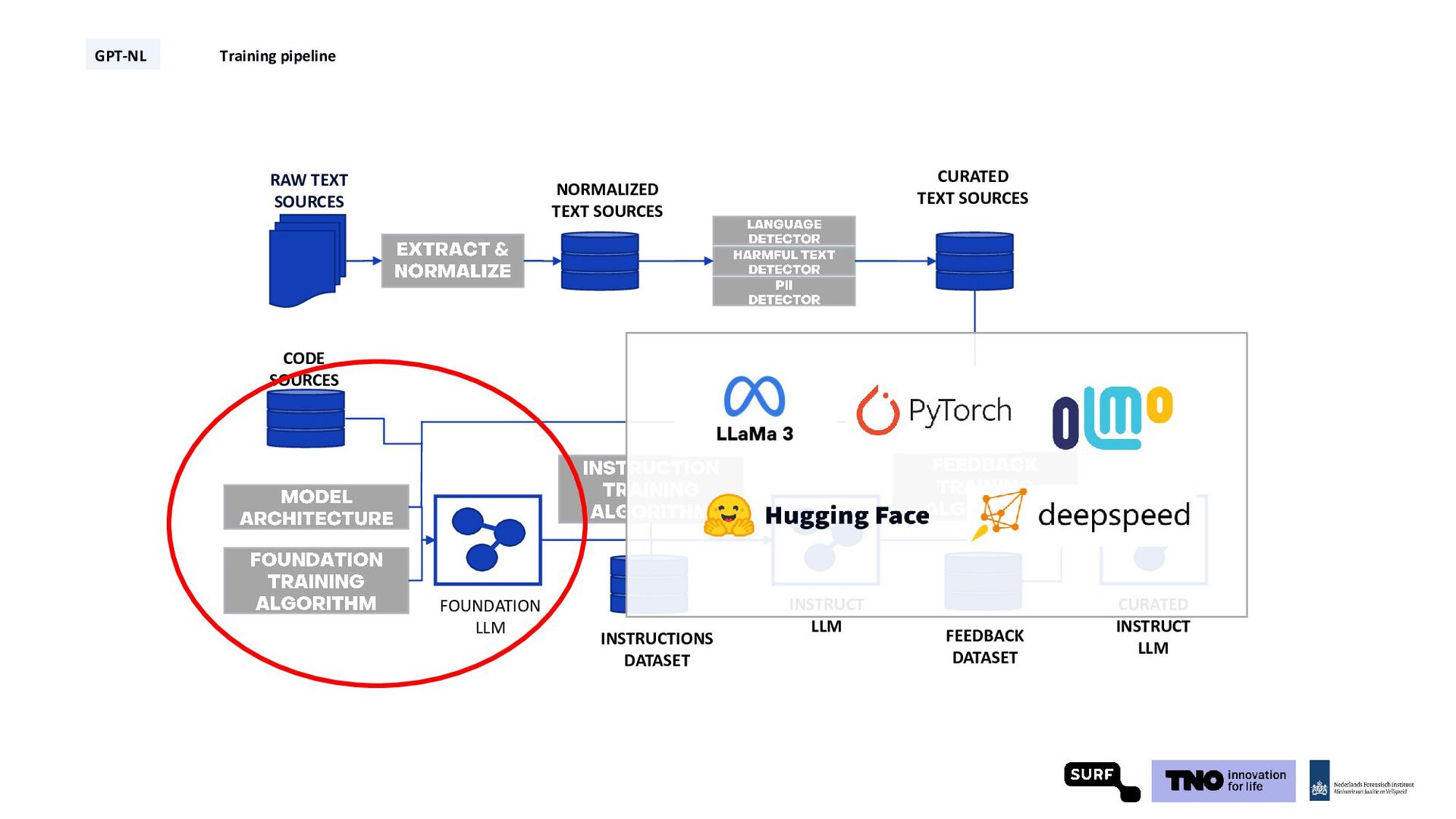
Technical Report: Pretraining in Days, Not Months (2024), Gunasekar et al., Textbooks Are All You Need (2023), Sachdeva et al., How to Train Data-Efficient LLMs (2024) GPT-NL Training pipeline synthetic data* code data high quality web data w/ permissive licenses proprietary data from contributors * Still under consideration
![[email protected]](https://files.speakerdeck.com/presentations/bacd0e73713a4beeb320b8810bf5abad/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}