Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SRE Enabling戦記 - 急成長する組織にSREを浸透させる戦いの歴史
Search
Masaki Ishigaki
February 02, 2026
Technology
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
SRE Enabling戦記 - 急成長する組織にSREを浸透させる戦いの歴史
SRE Kaigi 2026に登壇した際の資料になります。
Masaki Ishigaki
February 02, 2026
More Decks by Masaki Ishigaki
See All by Masaki Ishigaki
100マイクロサービスのTerraform/Kubernetes管理地獄から抜け出すためのAI活用術
markie1009
0
720
Other Decks in Technology
See All in Technology
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
150
Jitera Company Deck
jitera
0
560
書籍セキュアAPIについて
riiimparm
0
330
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
720
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
150
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
170
「休む」重要さ
smt7174
6
1.7k
PHPで作って学ぶリアルタイム音声対話AIとWebSocket入門 by ムナカタ
munakata
0
160
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
310
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
900
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
210
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
210
Featured
See All Featured
ラッコキーワード サービス紹介資料
rakko
1
4M
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
The Limits of Empathy - UXLibs8
cassininazir
1
550
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Become a Pro
speakerdeck
PRO
31
6k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
270
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Thoughts on Productivity
jonyablonski
76
5.3k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
It's Worth the Effort
3n
188
29k
Ruling the World: When Life Gets Gamed
codingconduct
0
290
Transcript
SRE Enabling戦記 株式会社LegalOn Technologies 急成⻑する組織にSREを浸透させる戦いの歴史 2026/1/31
登壇者プロフィール ⽯垣 雅基 (いしがき まさき) 株式会社LegalOn Technologies SRE 最近はObservability頑張ってます
会社・事業紹介
Our Purpose 法とテクノロジーの力で、 安心して前進できる社会を創る。 LegalOn Technologiesは、AI分野における⾼度な技術⼒と法律‧契約の専⾨知識を兼ね備えたグローバルリーガルAIカンパ ニーです。設⽴当初から、AIを活⽤したリーガルAIサービスの開発に注⼒し、⼤規模⾔語モデル(LLM)やAIエージェント など最先端のAI技術を製品開発に取り⼊れ、多様な企業課題に応えるソリューションでお客様のビジネスを⽀援します。 会社名 株式会社LegalOn
Technologies 設⽴ 2017年4⽉21⽇ 従業員数 626名(役員含む∕2025年11⽉時点) 所在地 〒150-6219 東京都渋⾕区桜丘町1-1 渋⾕サクラステージSHIBUYAタワー19F 資本⾦ 201.5億円(資本準備⾦等含)
法務AIのグローバルリーダー 7,500+ 顧客数グローバル7,500社を突破 600人 従業員数 7拠点合計 (東京‧⼤阪‧福岡‧名古屋‧サンフラン シスコ‧ロンドン‧ミュンヘン) 20人 弁護⼠資格保有者数
⽇本、NY州、CA州、ドイツの資格者を含む 1000+ 導⼊上記業者数 / 前上場企業者数 3,800社 200人 開発チーム⼈数 286億円 ゴールドマン‧サックス、ソフト バンクなどが出資。全調達ラウン ド累計
法務・契約領域で幅広く最先端の リーガルテックソリューションを提供 法務・契約業務支援 経営支援 世界⽔準の法務 AIで法務業務⽀ 援 様々なコンテン ツでAIリーガル リサーチ⽀援
オンライン法務 学習⽀援サービ ス 契約学習メディ アとコミュニ ティを提供 AIコーポレート ガバナンスプ ラットフォーム 組織の規範運⽤ をAIで⾃動化す るAIカウンセル
None
我々の組織を取り巻く現在の 状況
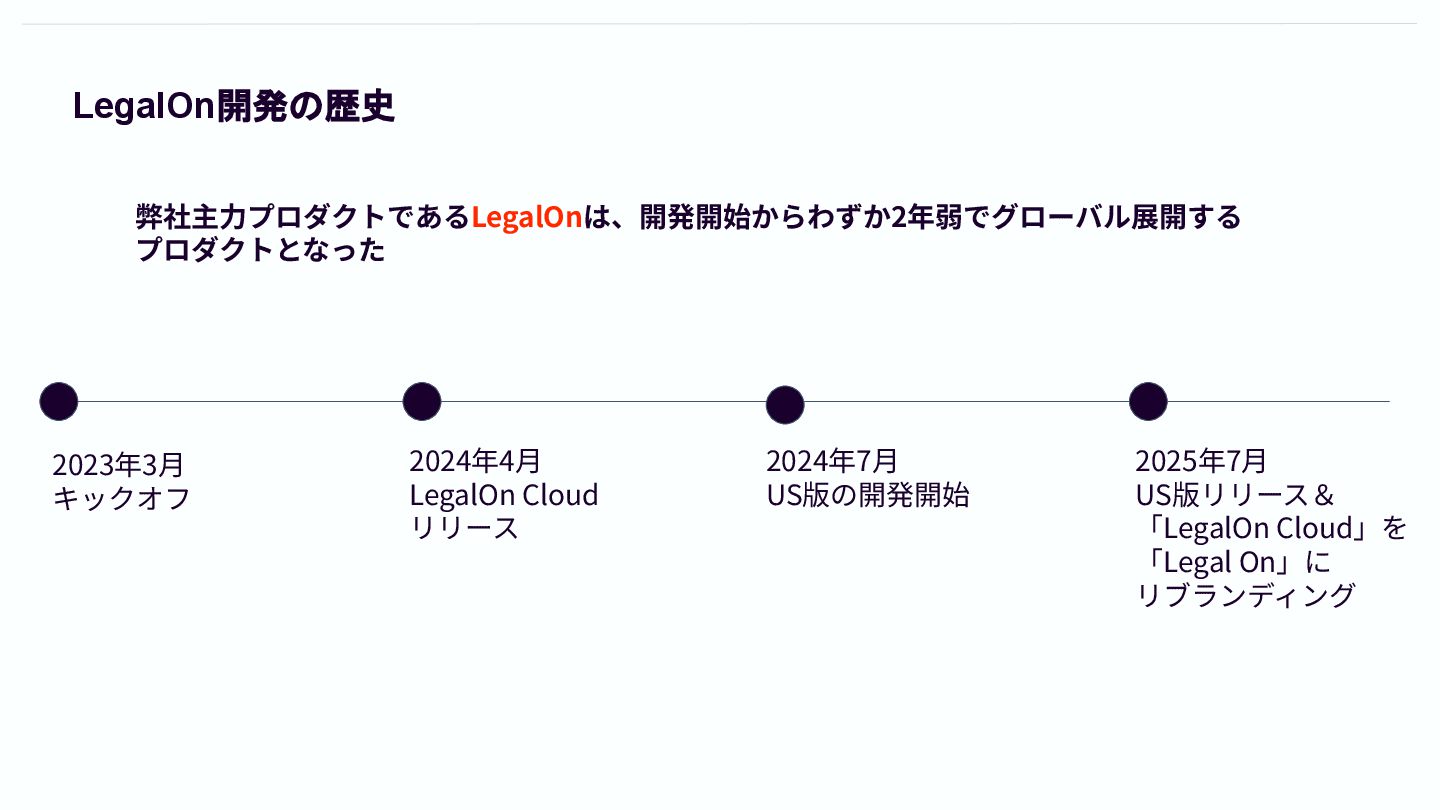
LegalOn開発の歴史 2023年3⽉ キックオフ 2024年4⽉ LegalOn Cloud リリース 2024年7⽉ US版の開発開始 2025年7⽉
US版リリース& 「LegalOn Cloud」を 「Legal On」に リブランディング 弊社主⼒プロダクトであるLegalOnは、開発開始からわずか2年弱でグローバル展開する プロダクトとなった
組織の変遷 • LegalOnは開発スタートからグローバル展開までを 2年で実現したが、急ピッチで開発を進めるため開発 中多くのエンジニアを採用して、開発組織は短い期間で急拡大した • LegalOnはリリース後も、ユーザーの様々なニーズに答えるため日々機能追加を実施しており、それを実 現するために弊社の開発組織も日々拡大している
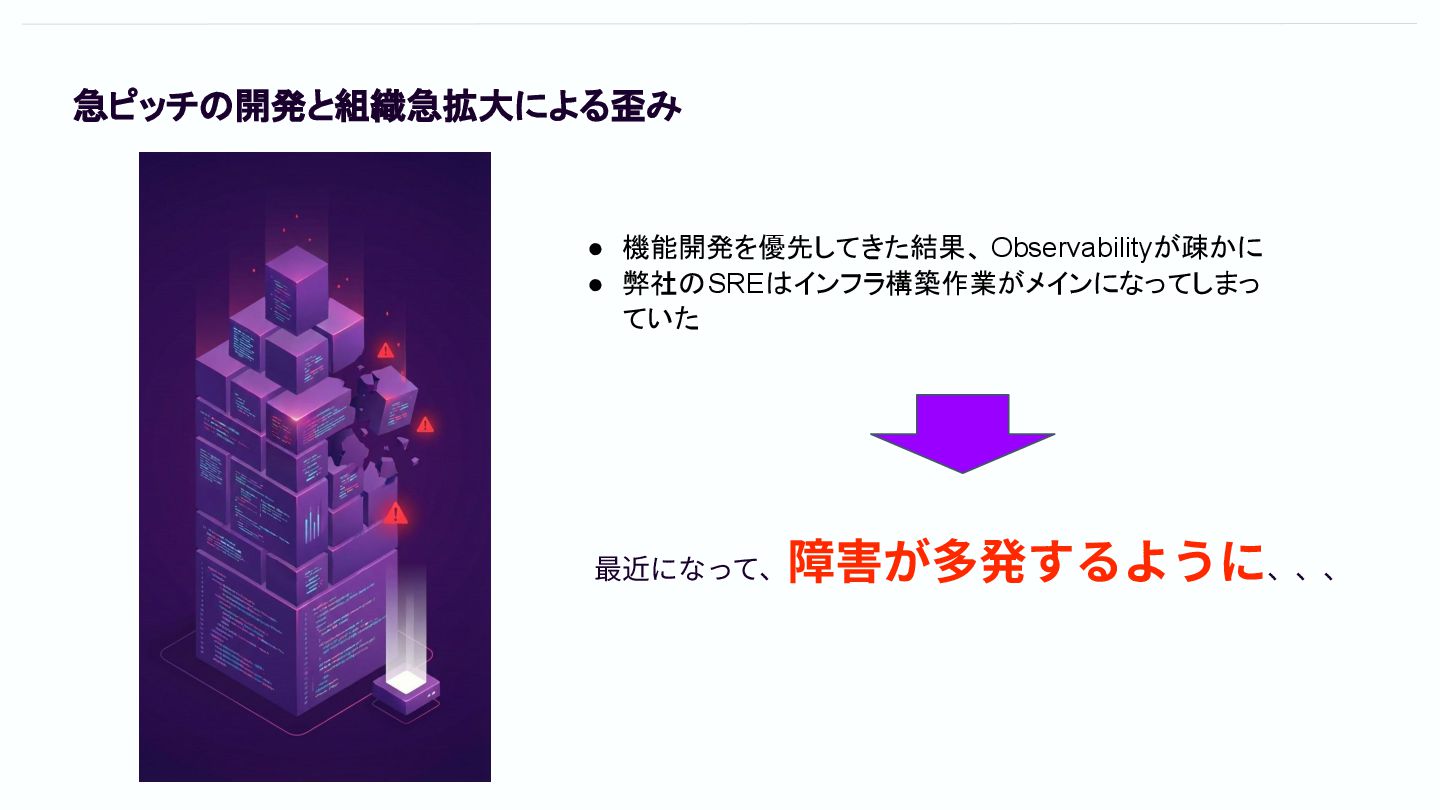
急ピッチの開発と組織急拡大による歪み • 機能開発を優先してきた結果、 Observabilityが疎かに • 弊社のSREはインフラ構築作業がメインになってしまっ ていた 最近になって、 障害が多発するように、、、
None
我々はなぜこれまで”SRE”を できずにいたのか?
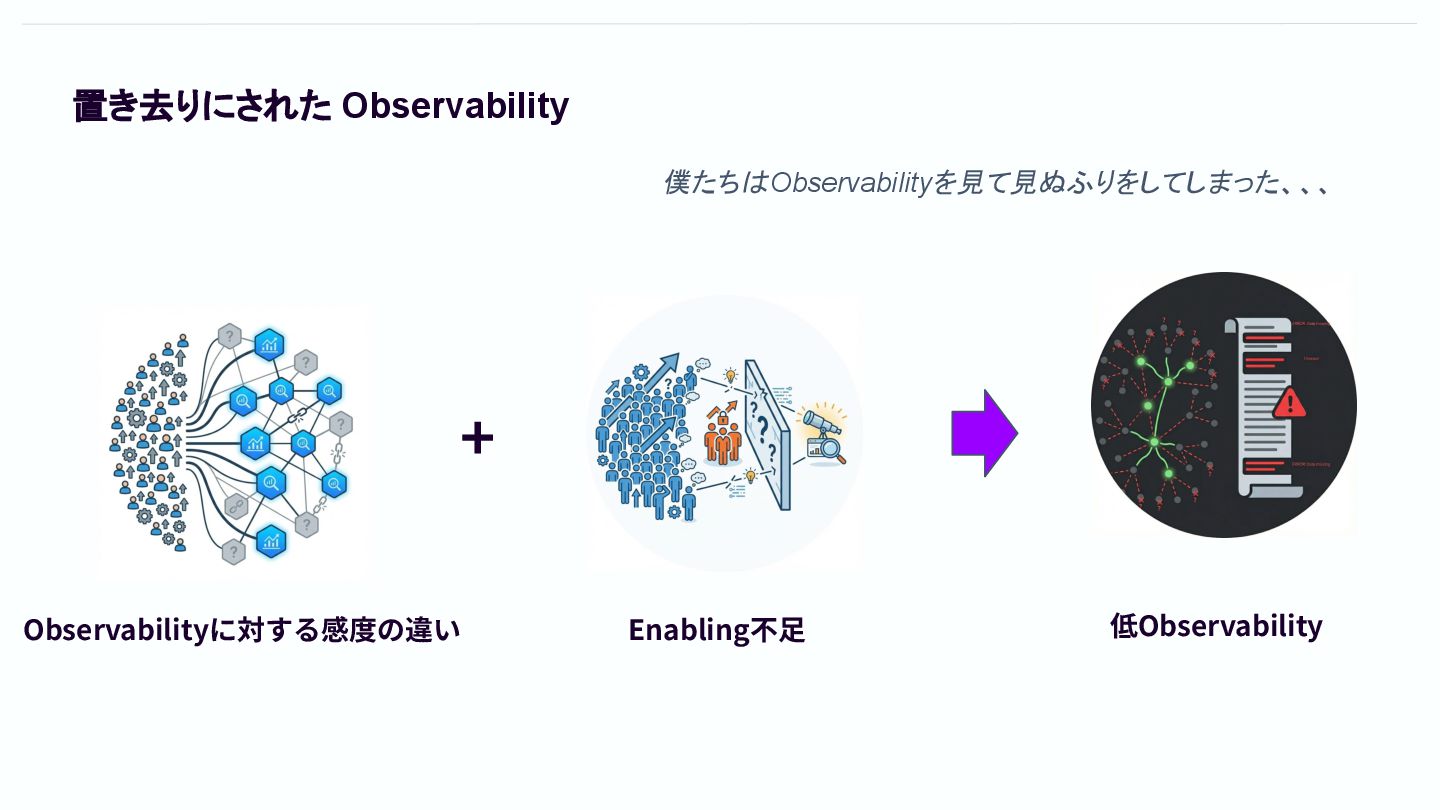
置き去りにされた Observability 低Observability Observabilityに対する感度の違い Enabling不⾜ 僕たちはObservabilityを見て見ぬふりをしてしまった、、、 +
形骸化してしまった SLO - LegalOnリリース時に設定した SLO 一応リリース時には、 SLOを設定してみたのです、、、 扱いやすい microservice APIのAvailability
/ LatencyのSLOから始めることにした • Availability / Latency SLIは、それぞれistio GatewayからGatewayに接した microserviceに対するrequest_countとresponse_latency • SLOのtarget値は、開発チームのEngineering Managerと協議の上決めた • Burn Rate Alertも設定 ここでの後悔は、SLOのEnablingがままらないまま SLOの値を決めさせてしまったこと💦 「SLOの理解がままならないのに、SLOについて決め ることは難しいよね」というのが教訓でした、、、
アラート疲労!!!
形骸化してしまった SLO - LegalOnリリース時に設定した SLO 次第にBurn Rate Alertが”オオカミ 🐺少年化”してしまい、最終的には SLOの運用を取りやめた
• リリース当初はErrorのハンドリングが適切でないケースが多く、 Burn Rate Alertが発火しても実際に は使用上問題なかったケースが多かった • そもそもObservabilityが担保されていない状態であったので、 Burn Rate Alertが発火したとしても、 Alert発火後の調査が難しかった • SLOを決めるだけで、Error Budget Policyを定めるなどして、運用面などの取り決めまで行えていな かった
形骸化してしまった Postmortem LegalOnリリース時に、 Postmortem運用も導入を することにはした 一応リリース時から、 Postmortemもやってました、、、 当初の運用 高いレベルのインシデントが発生した際は Postmortemを行い、再発防止策の取り決めまで
行ったが、実際に再発防止のアクションまで取られ るケースは少なかった →リリース後しばらくは新機能開発のスケジュール がタイトな状態が続いたので、抜本的な対策まで手 を出すことが難しい状態であった 形骸化の現実 次第にPostmortemも”実施して終わり”という状況が散見されるようになった 😢 崩壊していくPostmortem
まずはやれるところから! Postmortemの運用刷新
改善活動開始! 弊社のSREチームは、こうした現状を打開すべく、本格 的にSREのEnablingに乗り出した。まずは手のつけや すいPostrmoteの運用改善に取り組むことにし、開発 チームのEM、およびQAの方と改善チームを組成して、 改善に取り組み始めた。
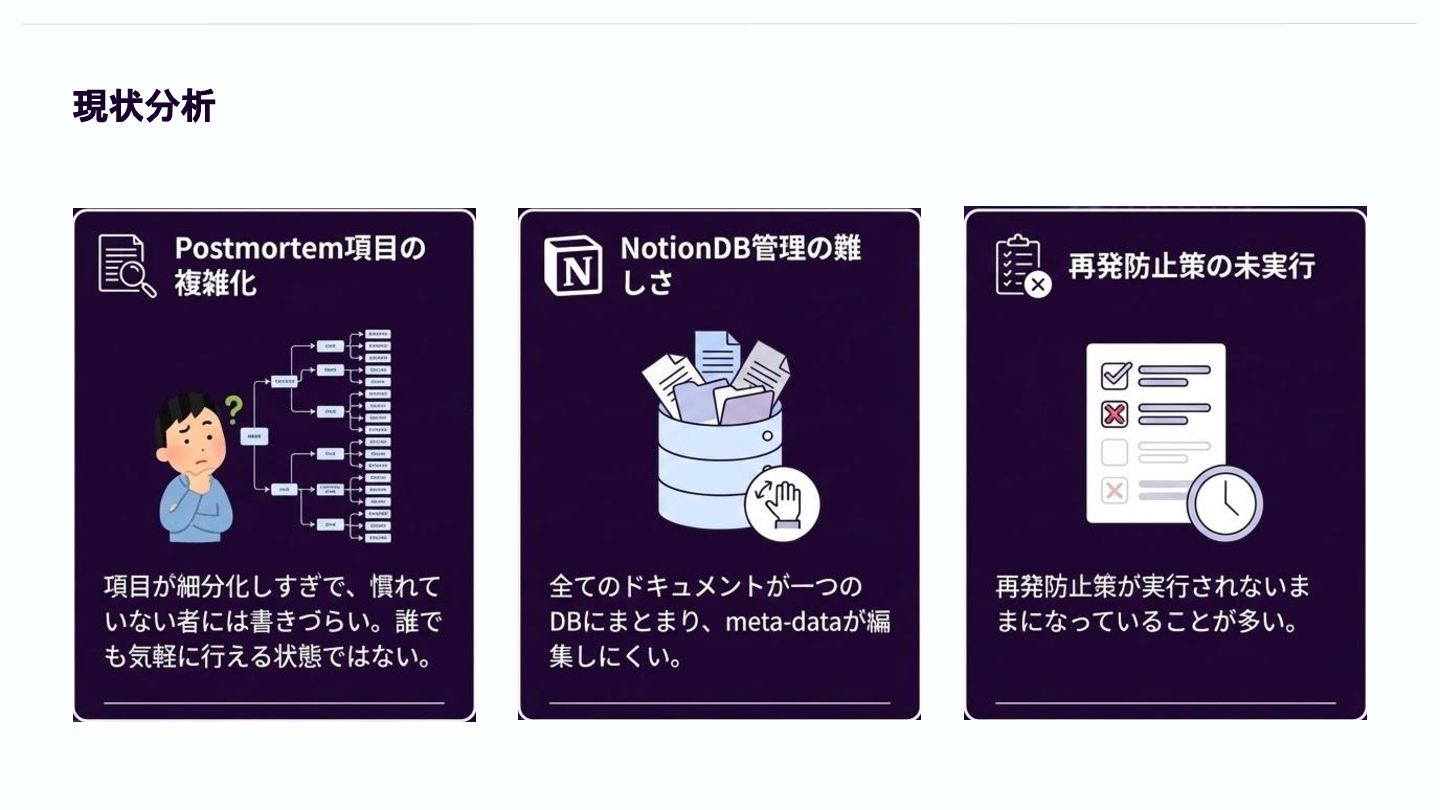
現状分析
対策① - Postmortem運用の改善 ⭐ Postmortemに記載すべき項⽬を簡略化し、重要なポイントだけに絞るようにした -> ✅ 課題”Postmortem項⽬の複雑化”の解消 ⭐ Notion内に、Postmortem⽤のNotionDBとPostmortem
Action Item(=再発防⽌策)⽤のNotionDBを 作成して、それぞれ個別に管理するようにした -> ✅課題”NotionDB管理の難しさ”の解消 ⭐ 再発防⽌策を決める時は優先順位を設定するようにして、急いでやるべきものを選別するようにした -> ✅ 課題”再発防⽌策の未実⾏”の解消
対策② - Postmortemの啓蒙 ⭐ Postmortemの意義について社内Meet upイベントで説明会を実施 -> ✅ 課題”再発防⽌策の未実⾏”の解消 元記事
-> https://now.legalontech.jp/n/ndcd0eaf03b23
Observability基盤の刷新
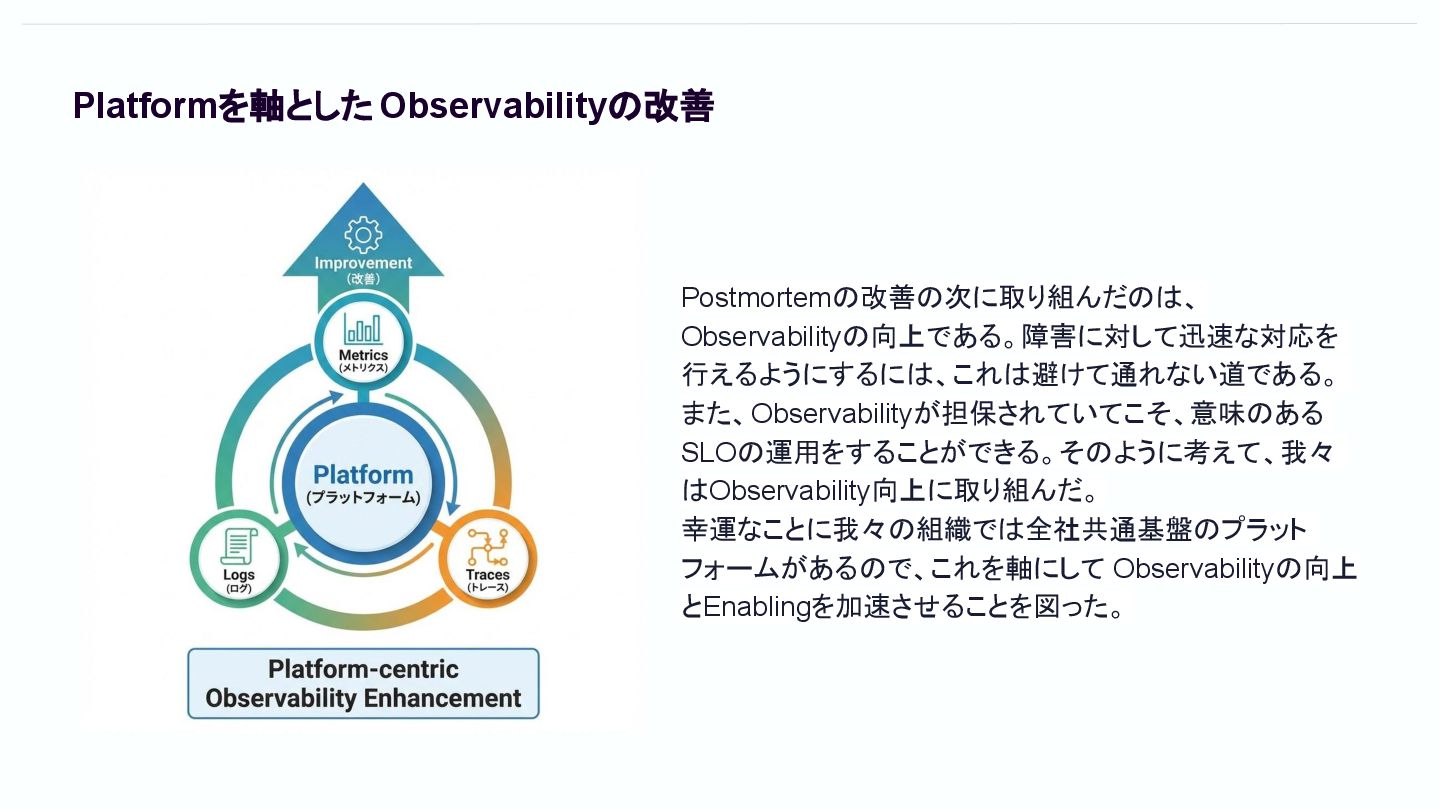
Platformを軸とした Observabilityの改善 Postmortemの改善の次に取り組んだのは、 Observabilityの向上である。障害に対して迅速な対応を 行えるようにするには、これは避けて通れない道である。 また、Observabilityが担保されていてこそ、意味のある SLOの運用をすることができる。そのように考えて、我々 はObservability向上に取り組んだ。 幸運なことに我々の組織では全社共通基盤のプラット フォームがあるので、これを軸にして
Observabilityの向上 とEnablingを加速させることを図った。
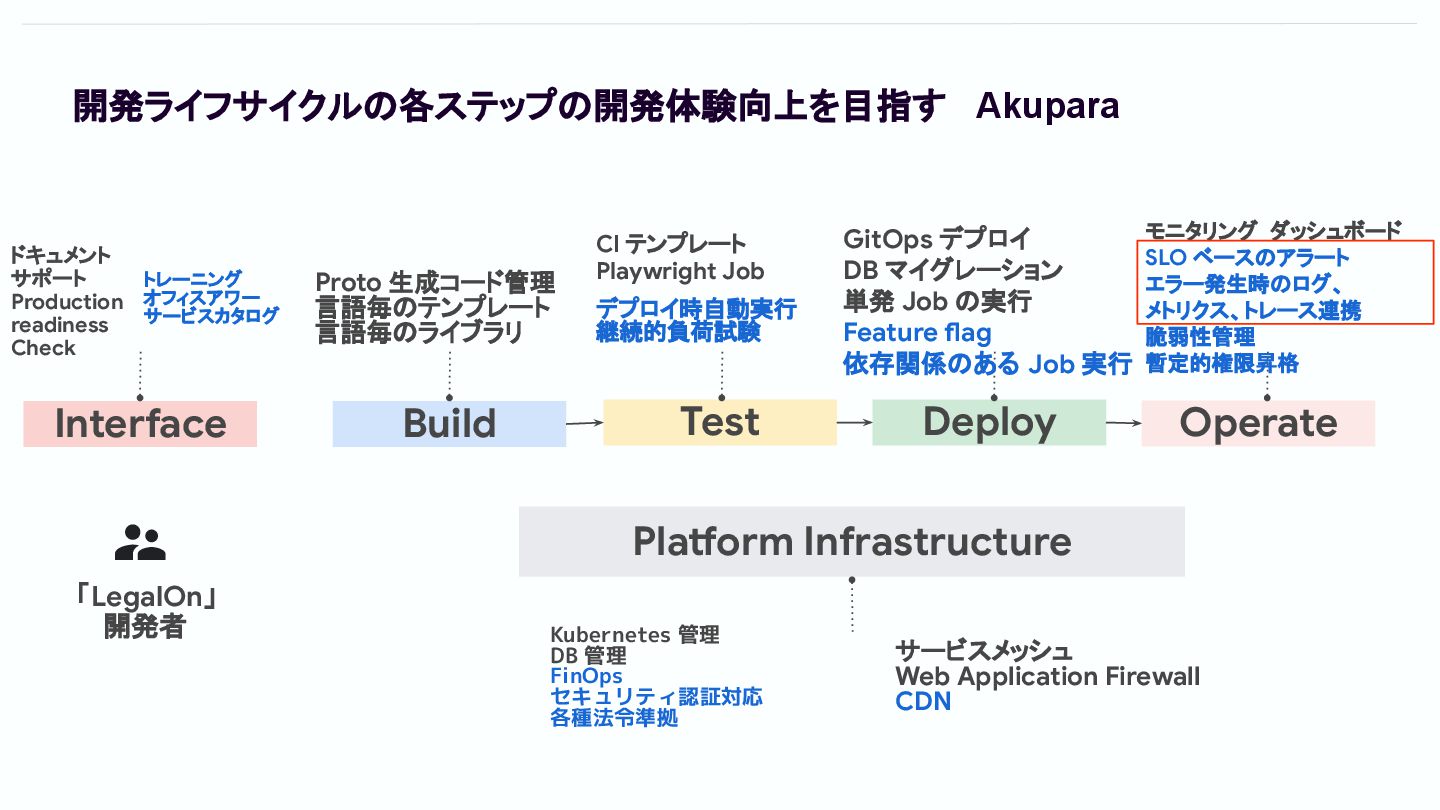
Akupara What is Akupara ? LegalOn Technologiesでプロダクト開発を⾏うにあたり、プロダクトチームが認知負荷低くソフトウェア ライフサイクルを⾃律的に回すための社内開発者向けプロダクト Mission and
Vision of Akupara 開発者にゴールデンパスと堅牢なインフラを提供し、創造的な開発に集中できるようにする
Akuparaについて詳しく知りたい方は 弊社のStaff Platform Engineerの杉⽥が、Platform Engineering Kaigi 2025にてAkuparaについてお話し しているので、ご興味ある⽅は是⾮動画をご視聴ください!! https://www.cnia.io/pek2025/sessions/fee134a5-3254-4d02-aee4-c91b4dc0664e/
開発ライフサイクルの各ステップの開発体験向上を目指す Akupara Interface Build Test Deploy Operate Platform Infrastructure Proto
生成コード管理 言語毎のテンプレート 言語毎のライブラリ CI テンプレート Playwright Job デプロイ時自動実行 継続的負荷試験 ドキュメント サポート Production readiness Check GitOps デプロイ DB マイグレーション 単発 Job の実行 Feature flag 依存関係のある Job 実行 「LegalOn」 開発者 モニタリング ダッシュボード SLO ベースのアラート エラー発生時のログ、 メトリクス、トレース連携 脆弱性管 暫定的権限昇格 Kubernetes 管理 DB 管理 FinOps セキュリティ認証対応 各種法令準拠 サービスメッシュ Web Application Firewall CDN トレーニング オフィスアワー サービスカタログ
これまでの Observability これまで弊社ではObservabilityツールとして、Google Cloud Observability (Cloud Monitoring / Trace /
Logging)のみを使⽤していた Observabilityの向上&self-service化を進めていくために以下のことを実施したかったが、Google Cloud Observabilityだけでは難しい側⾯があった • 各microservice⽤のDashboard作成を抽象化するためのTerraform Moduleを作りたい -> Google Cloud Terraform Providerでは、うまく抽象化するのはやや難しい • APIごとにAvailability / Latencyを測りたい -> Cloud Traceにはspanをmetricsに変更する機構がな いので、やるのであれば⾃前計測 • Frontendの監視をしたい -> Google Cloud ObservabilityにはFrontend監視に特化した機能はない
ObservabilityツールをDatadogに移行 Akupara⽤のObservabilityツールとして、Datadogも導⼊することに!! ペインポイントの解消 • 各microservice用のDashboard作成を抽象化するための Terraform Moduleを作りたい -> Datadogには powerpackという機能がありdashboard横断で使うwidgetを定義することができ、これをうまく使うことで
Dashboard作成をTerraformで抽象化できる • APIごとにAvailability / Latencyを測りたい -> Datadogではtraceを送信すると、spanをmetricsに変換し てくれる • Frontendの監視をしたい -> DatadogにはFrontend監視ツールとしてReal User Monitoringがある
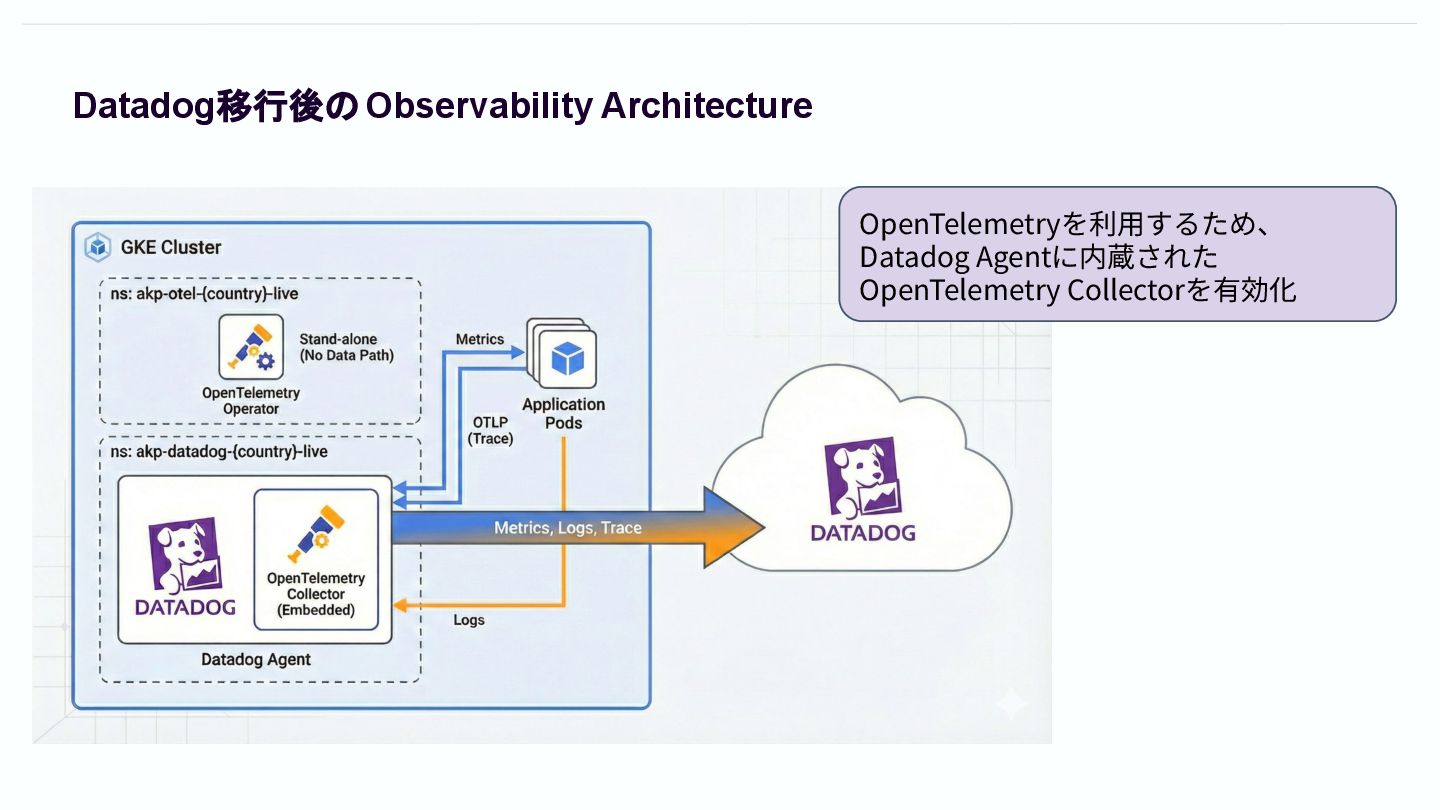
Datadog移行後のObservability Architecture OpenTelemetryを利⽤するため、 Datadog Agentに内蔵された OpenTelemetry Collectorを有効化
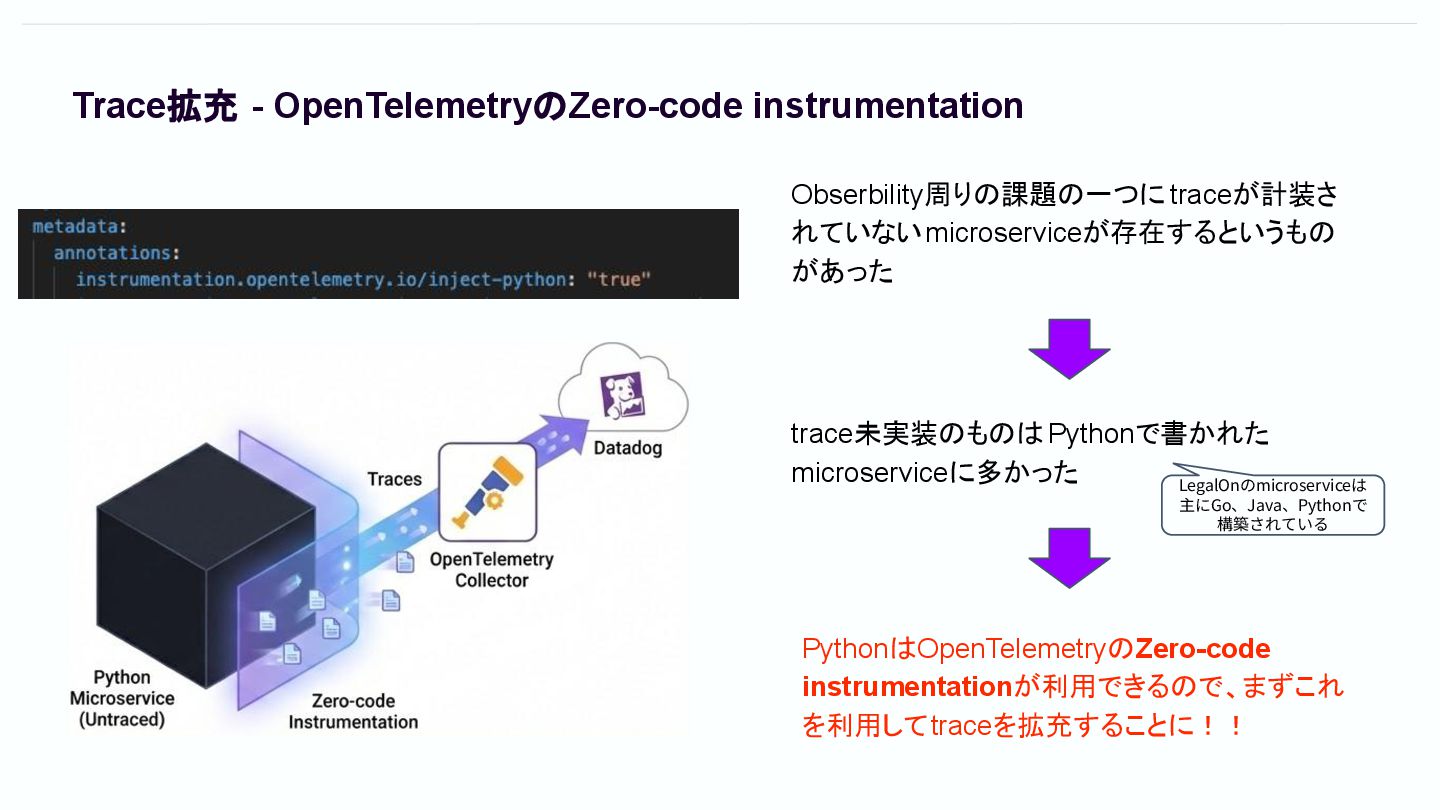
Obserbility周りの課題の一つに traceが計装さ れていないmicroserviceが存在するというもの があった Trace拡充 - OpenTelemetryのZero-code instrumentation trace未実装のものはPythonで書かれた microserviceに多かった
PythonはOpenTelemetryのZero-code instrumentationが利用できるので、まずこれ を利用してtraceを拡充することに!! LegalOnのmicroserviceは 主にGo、Java、Pythonで 構築されている
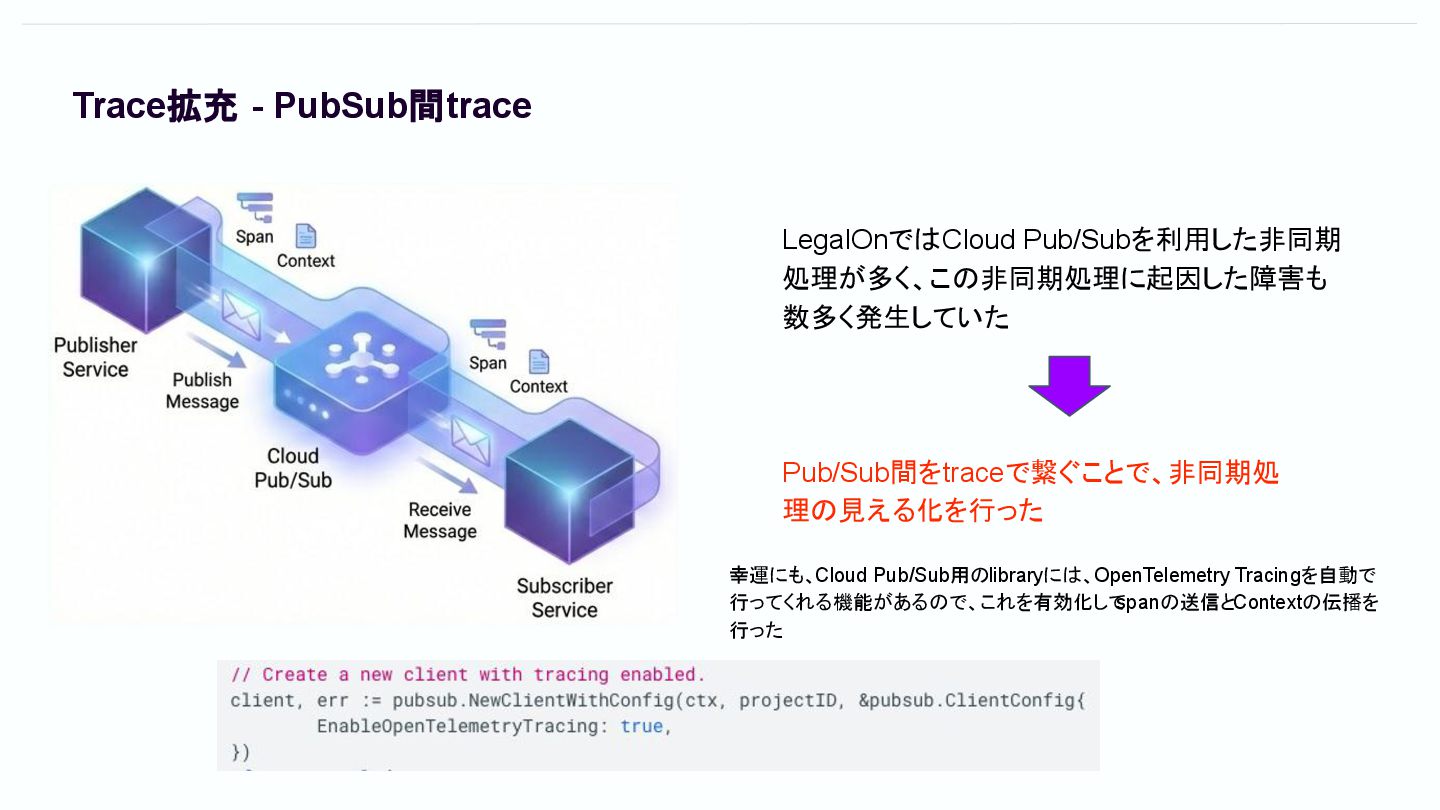
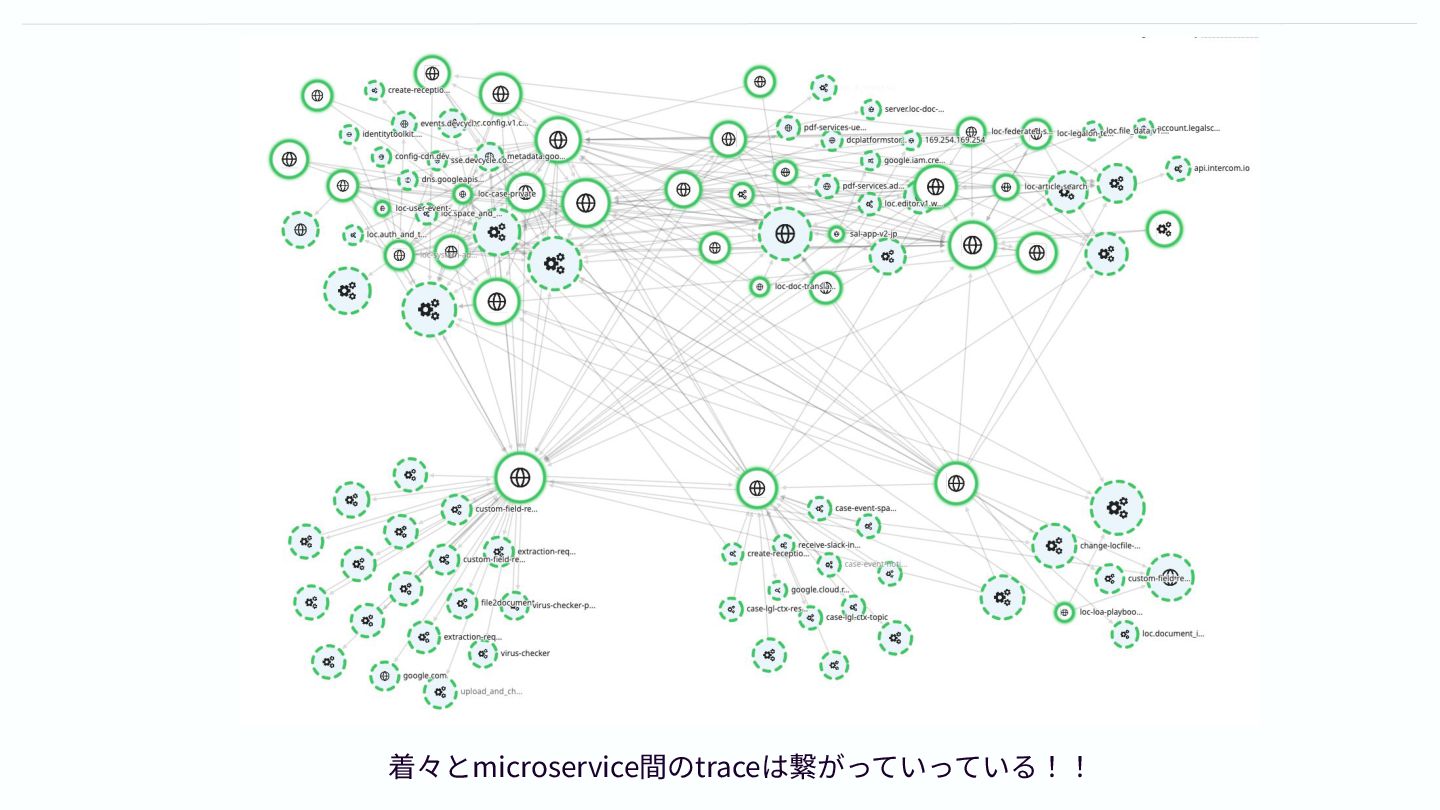
Trace拡充 - PubSub間trace 幸運にも、Cloud Pub/Sub用のlibraryには、OpenTelemetry Tracingを自動で 行ってくれる機能があるので、これを有効化して spanの送信とContextの伝播を 行った LegalOnではCloud
Pub/Subを利用した非同期 処理が多く、この非同期処理に起因した障害も 数多く発生していた Pub/Sub間をtraceで繋ぐことで、非同期処 理の見える化を行った
着々とmicroservice間のtraceは繋がっていっている!!
k8s manifestの抽象化 OpenTelemetry Zero-code instrumentationの設定 Datadog Log Autodiscovery用の annotation LegalOnは50以上のmicroserviceで構成されるので、Observability関連の設定をmanifestに忘れずかつ
間違いなく入れておくのは大変 k8s-genによる抽象化
k8s-genを用いたObservability設定の抽象化 k8s-genとは、以下のような機能を有したツール • 標準化されたkubernetes manifest、ディレクトリ構成を生成 ◦ server, worker, jobなどPodの役割に応じて適切な manifestが生成される
• microservice数の増加に伴うmanifest管理の複雑化の防止 ◦ マニフェスト作成・更新の属人化を回避 • セキュリティのベストプラクティスも含まれており、開発者は意識することなく infraをセキュアな状態にす ることができる k8s-genをupdateして、開発者が意識することなくObservabilityの設定ができるようにした
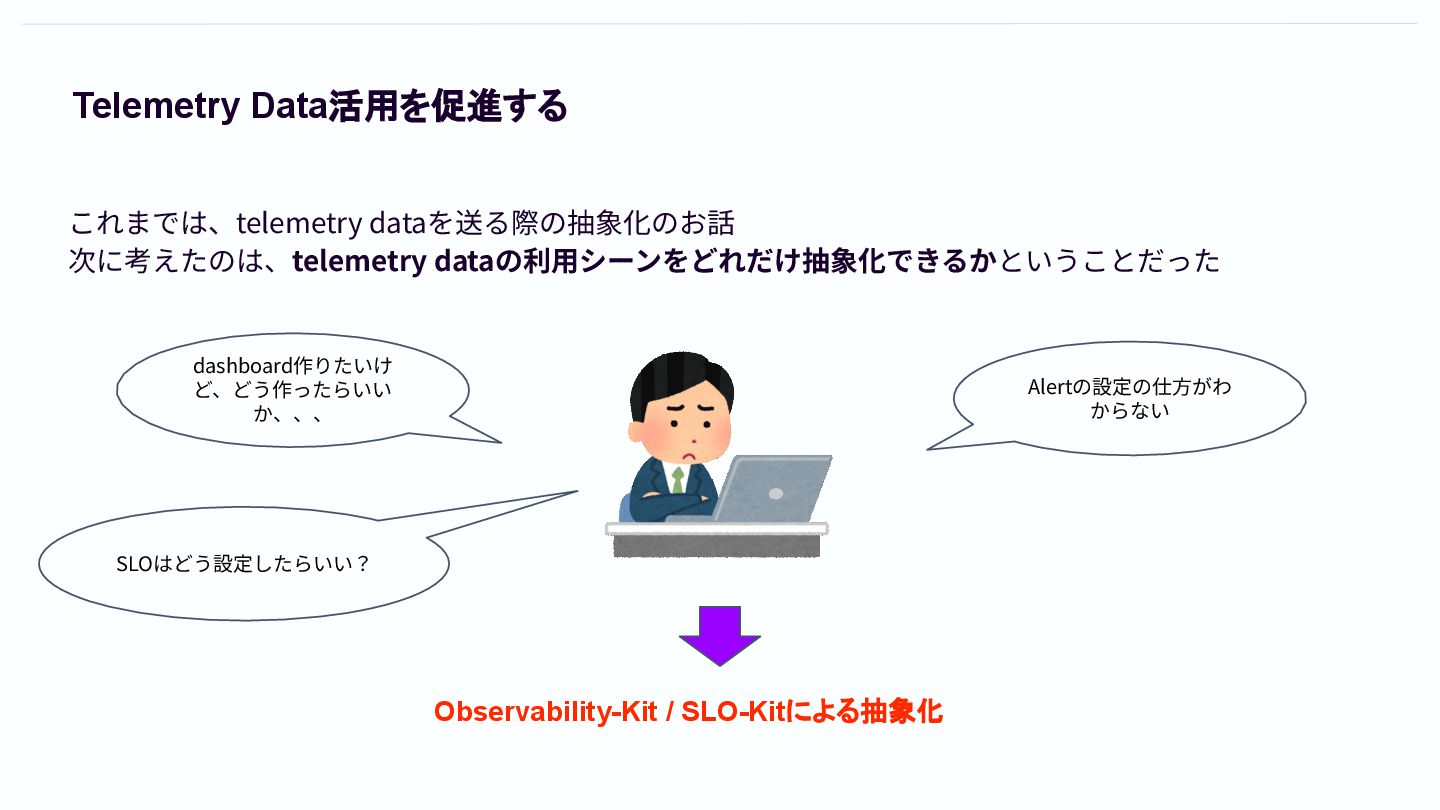
Telemetry Data活用を促進する これまでは、telemetry dataを送る際の抽象化のお話 次に考えたのは、telemetry dataの利⽤シーンをどれだけ抽象化できるかということだった dashboard作りたいけ ど、どう作ったらいい か、、、 Alertの設定の仕⽅がわ
からない Observability-Kit / SLO-Kitによる抽象化 SLOはどう設定したらいい?
Observability-Kit Observability-Kitとは、以下のDatadogリソースを簡 単に作成可能なTerraform Module • Software Catalog • Dashboard •
Monitor • RUM Application
None
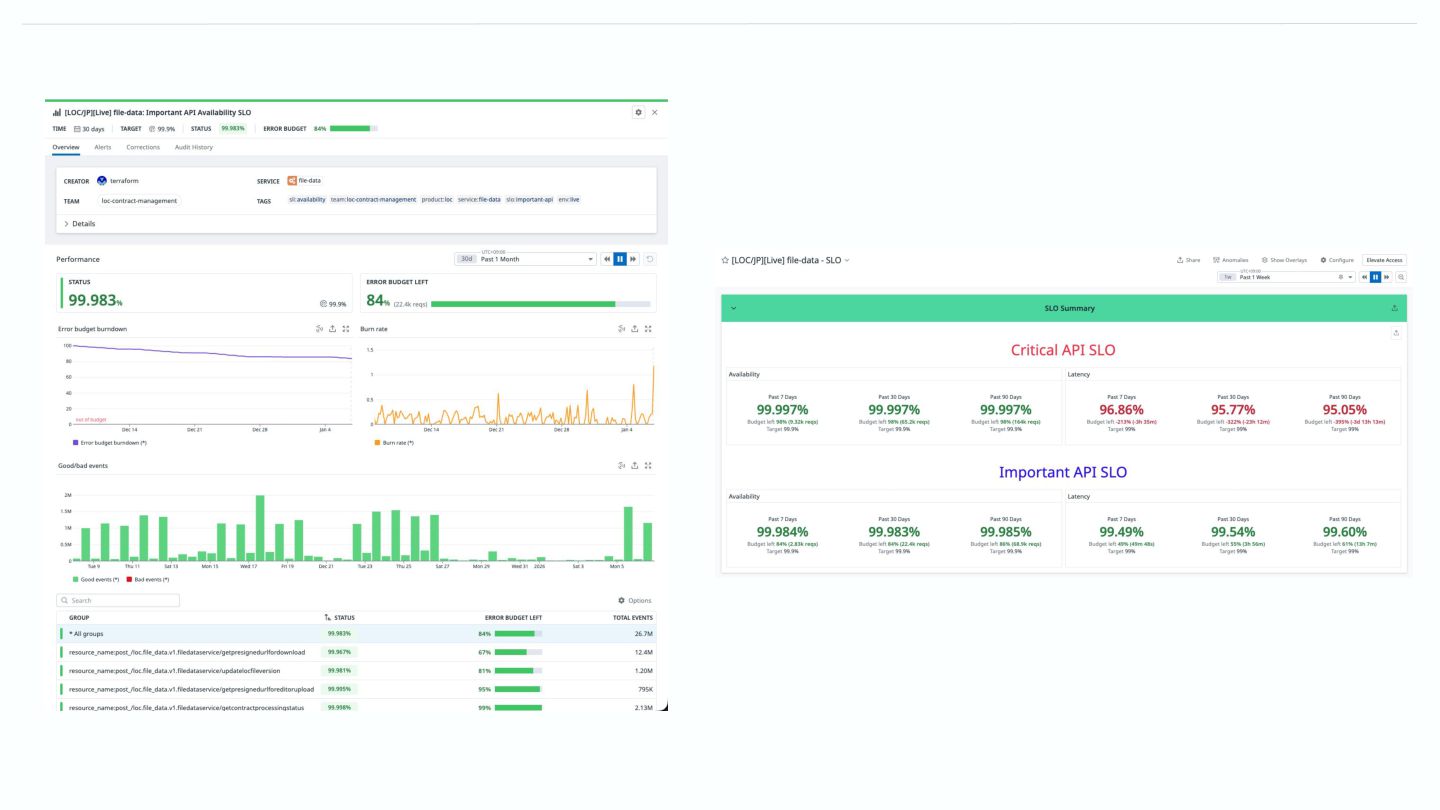
SLO-Kit SLO-Kitとは、microservice APIのAvailability / Latency SLO、Burn Rate Alert、Dashboardを簡単に作 成可能なTerraform Module
trace spanのmetricsをSLIとして、critical / importAPI をchoiceしてSLOを設定する
None
SREの日の出 準備はできた、さあ、Enabling やっていきましょう
Postmortem改善後日談 • Postmortemの改善を⾏ったが、今回⾏った改善だけで完全に良くなったという訳ではもちろんな く、まだまだ改善の余地はある • 実際に、templateをもう少し改善してほしいという声も上がっている • ただ、開発者内で自律的にフィードバックループが回りだしたようなので、 SREとしては適宜それをサ ポートしていけば良いと考えている
◦ 開発チームの方で、 Postmortem改善のタスクフォースが立ち上がって、日々改善に取り組まれて いる SREが改善の最初の一歩を踏み出したことで、そこに続く形で開発チームで自律的に改善を進めるように なってくれたので、今回の改善はやってよかった
Observabilityの推進 - 社内勉強会 Datadogを導⼊したり、便利ツールを作ったり したとしても、結局は使ってもらわないと意味 がないわけで、、、 開発者に向けてDatadog、ツールの使い⽅に 関する説明会を実施
Observabilityの推進 - Documentation ⼀回説明会を実施しただけで、すぐに使えるよ うになるわけはないので、Akupara Guidelineと して、今回作成したObservability-Kit / SLO-Kit のDocumentも⽤意
ツールの使い⽅だけでなく、開発者がiterativeな計装を⾏っ ていけるように、計装ガイドラインみたいなものも今後⽤ 意していきたいと考えている
Observabilityの推進 - Akupara issues Akuparaでは、開発ライフサイクル上の課題を拾えるように、Akupara issuesという取り組みを⾏って おり、開発者は⾃由にissueを上げられるようになっている AkuparaのObservability周りの機能に関しても、このAkupara issuesを介して常に改善していけられ るような体制をとっている
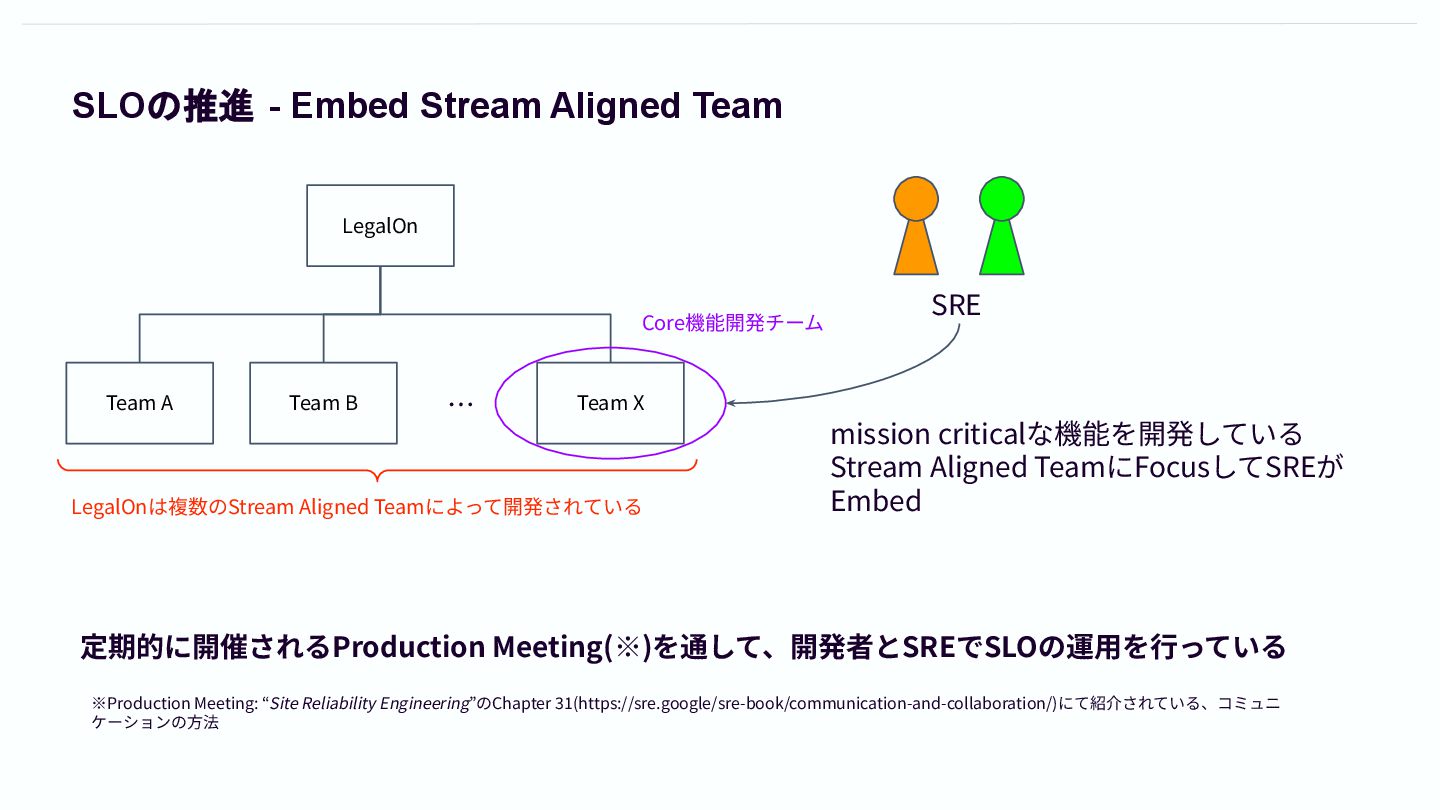
SLOの推進 - Embed Stream Aligned Team LegalOn Team A Team
B Team X … LegalOnは複数のStream Aligned Teamによって開発されている SRE Core機能開発チーム mission criticalな機能を開発している Stream Aligned TeamにFocusしてSREが Embed 定期的に開催されるProduction Meeting(※)を通して、開発者とSREでSLOの運⽤を⾏っている ※Production Meeting: “Site Reliability Engineering”のChapter 31(https://sre.google/sre-book/communication-and-collaboration/)にて紹介されている、コミュニ ケーションの⽅法
SLOの推進 - microservice SLOを超えてCUJ SLOへ SLO-Kitによって、microservice単位でSLOを簡単に作成して運⽤できるようになったものの、、、 “プロダクト全体がHealthyか否か”を判断する基準が策定したいという要望が開発責任者から上がって きた Critical User
Journey(CUJ)に基づいたSLOの必要性 現在、プロダクトのステークホルダーとともにCritical User Journeyを整理している 近い将来、CUJベースのSLOの運⽤を開始して、プロダクト全体の監視ができるような体制を敷いていく 予定
まとめ
まとめ SLOの運⽤は漫然とやってもダメ、Observabilityをキチ ンと整えてからやりましょう • SLOは決めればいいというものではない • SLOのAlertは、”Actionable Alert”なので、Observabilityが整ってなければAlertが発⽕ した後にどうしていいかわからない •
結果、SLOは⾵化してしまう
まとめ ⼤規模組織になればなるほど、Observabilityを促進して いくにはPlatform Engineeringの⼒が必要となる • 組織のスケールとSREチームのスケールは必ずしも⽐例はしない • Observabilityの感度は⼈それぞれなので、できるだけ抽象化する • その上で、SREがEnablingするところ、self-serviceで推進していくところのバランスを
とる
株式会社LegalOn Technologies https://legalontech.jp/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}