Share
日本IBM CSM TEAMのnoteにアップロードする資料です。
クリエイターページのURLは下記となります。 https://note.com/ibmj_csm/
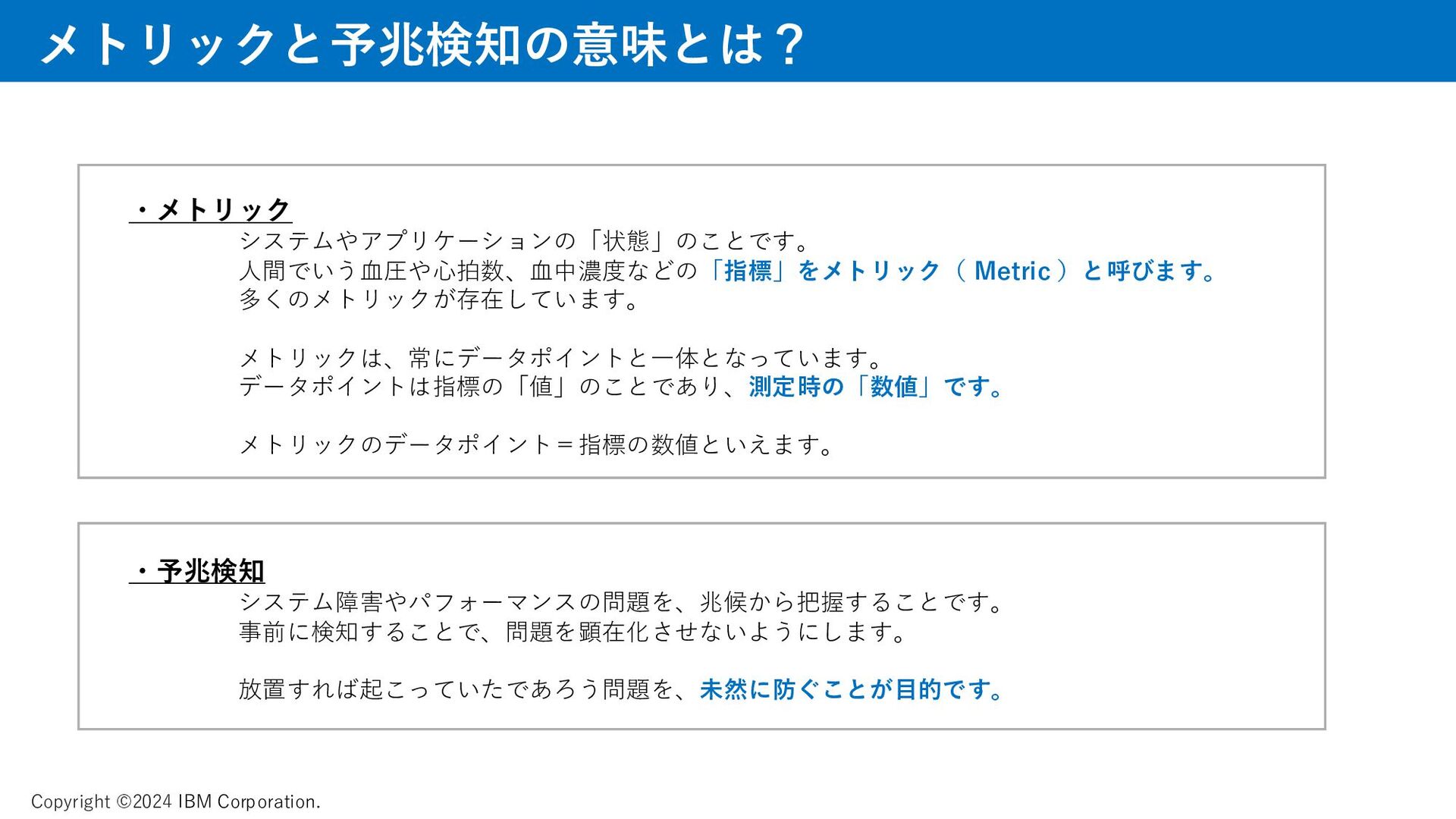
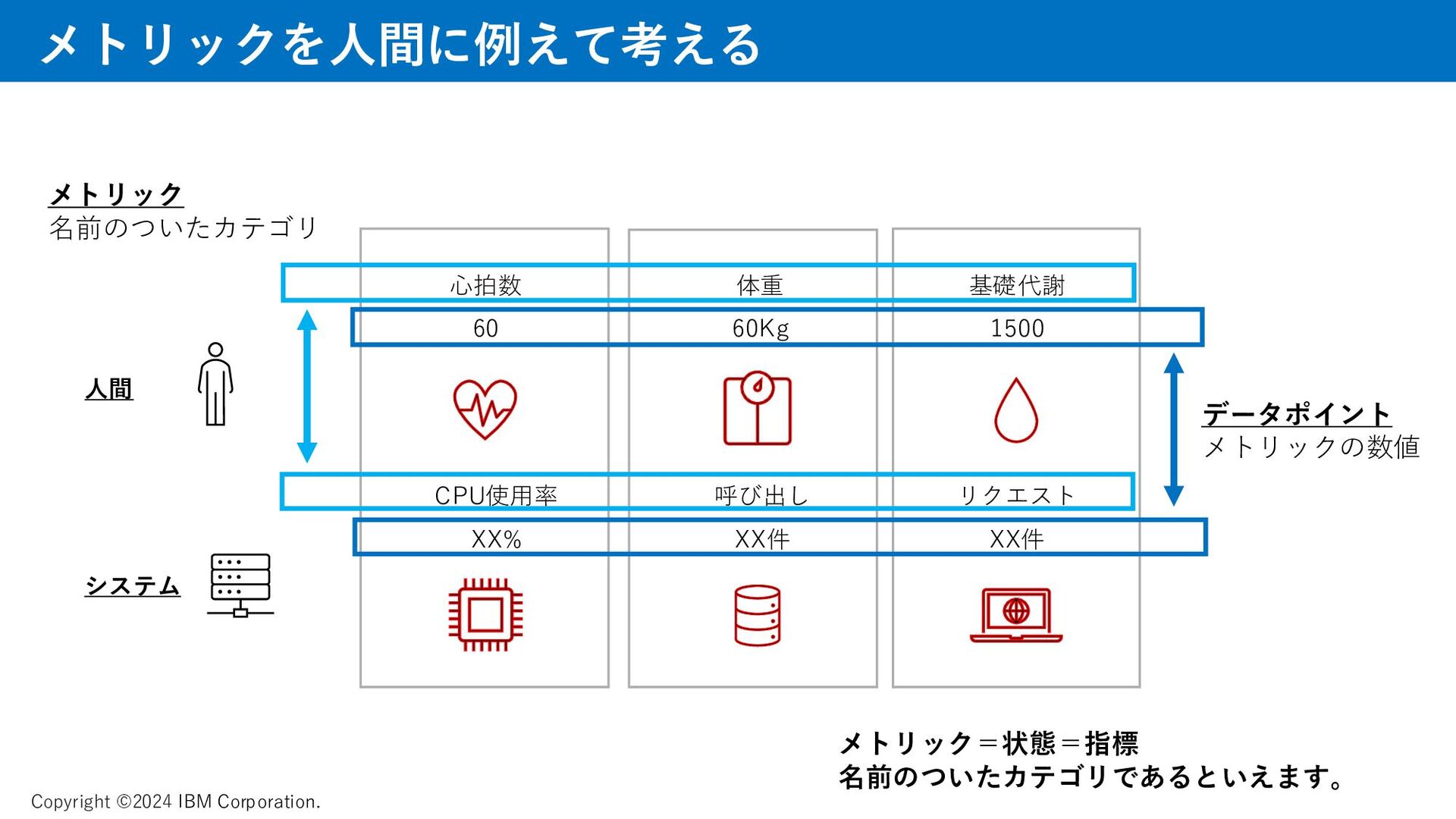
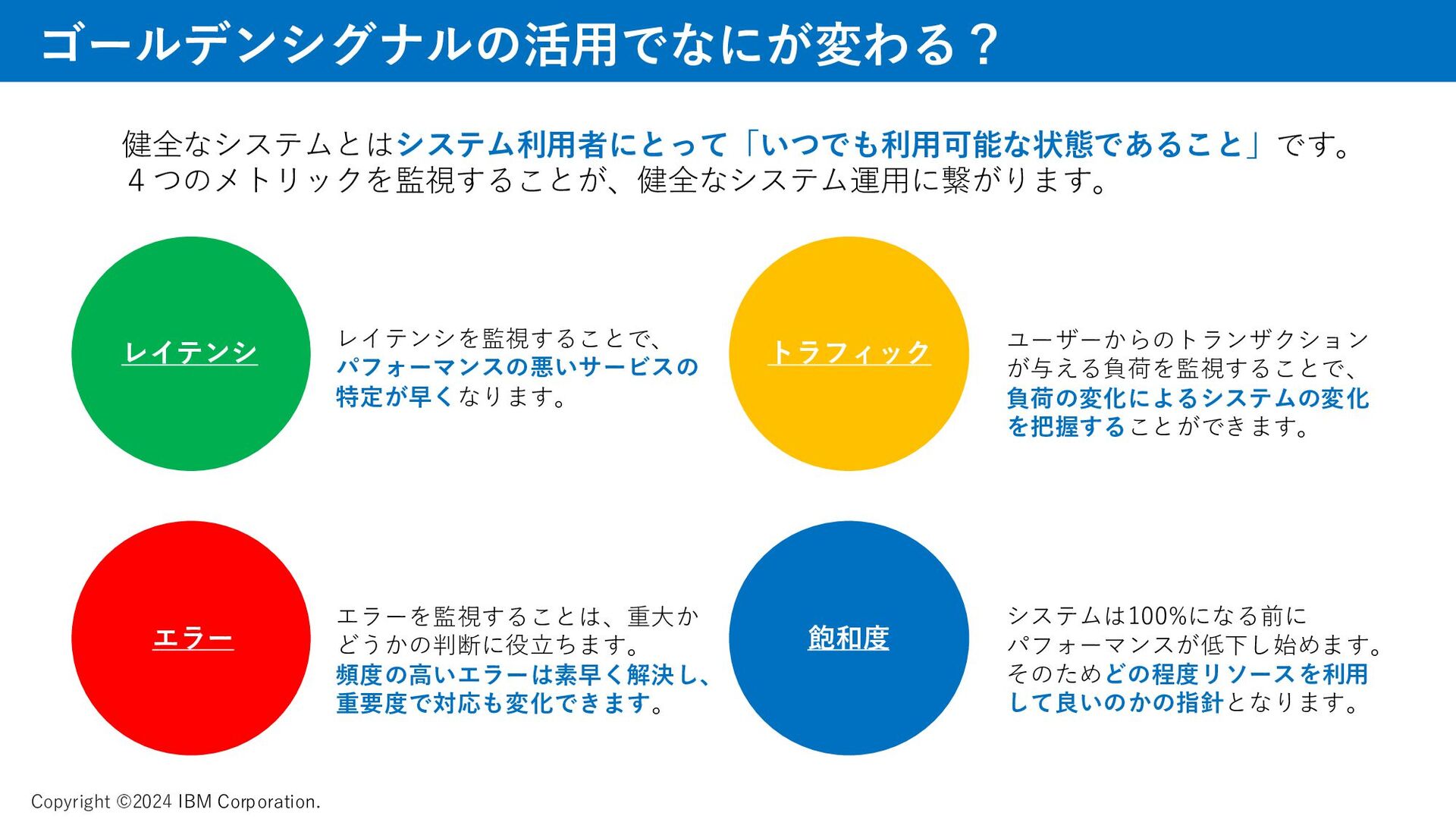
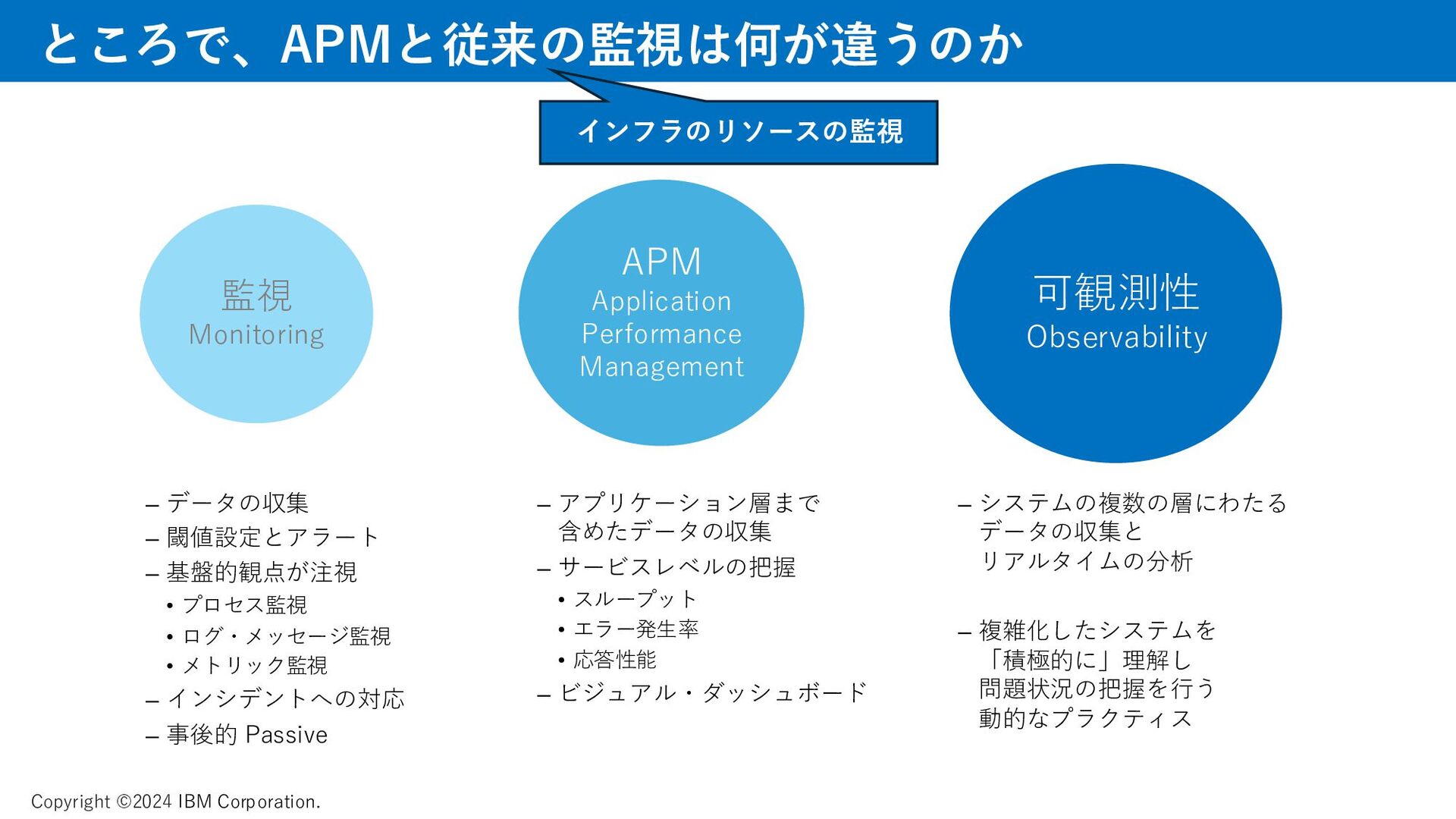
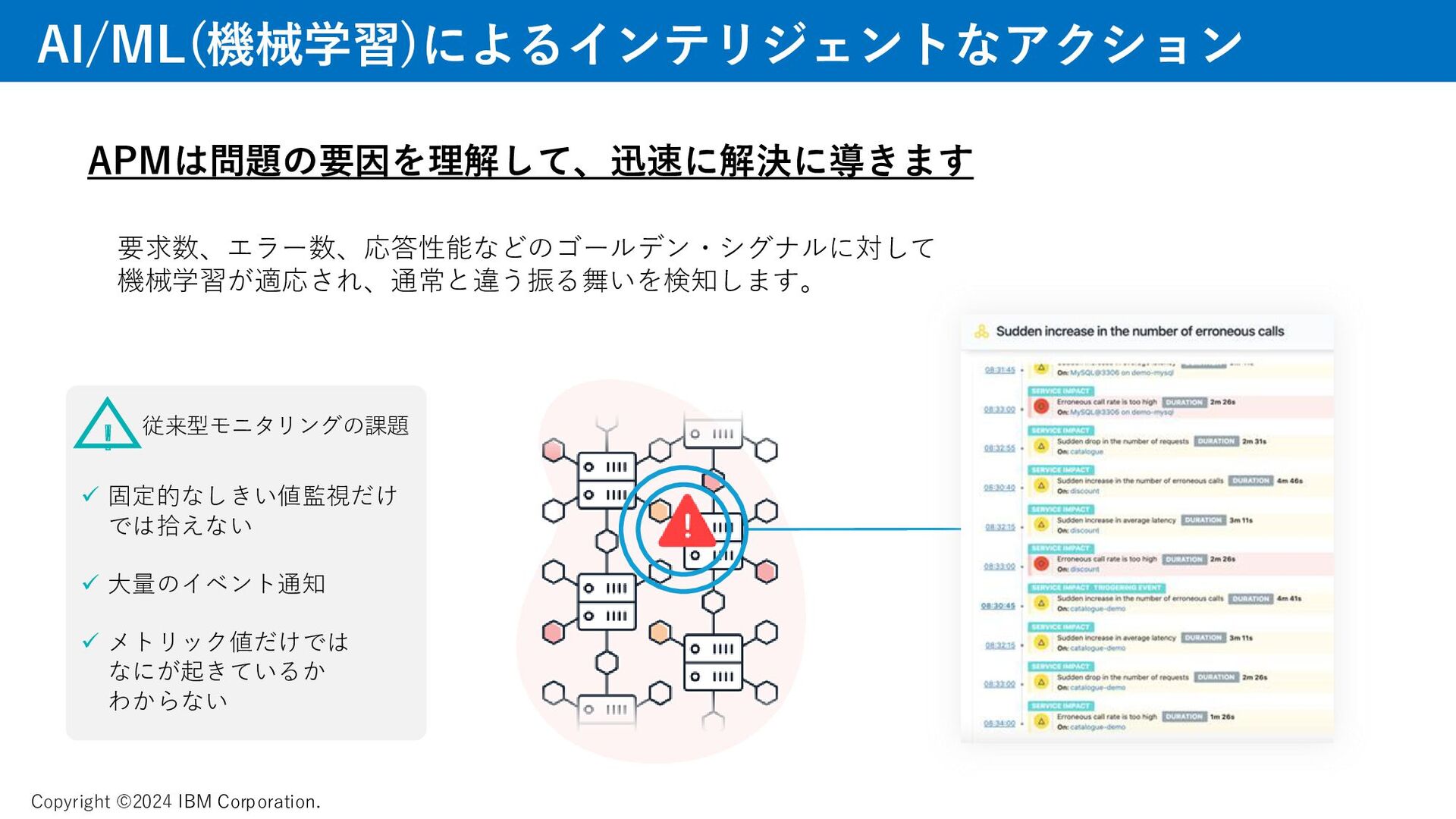
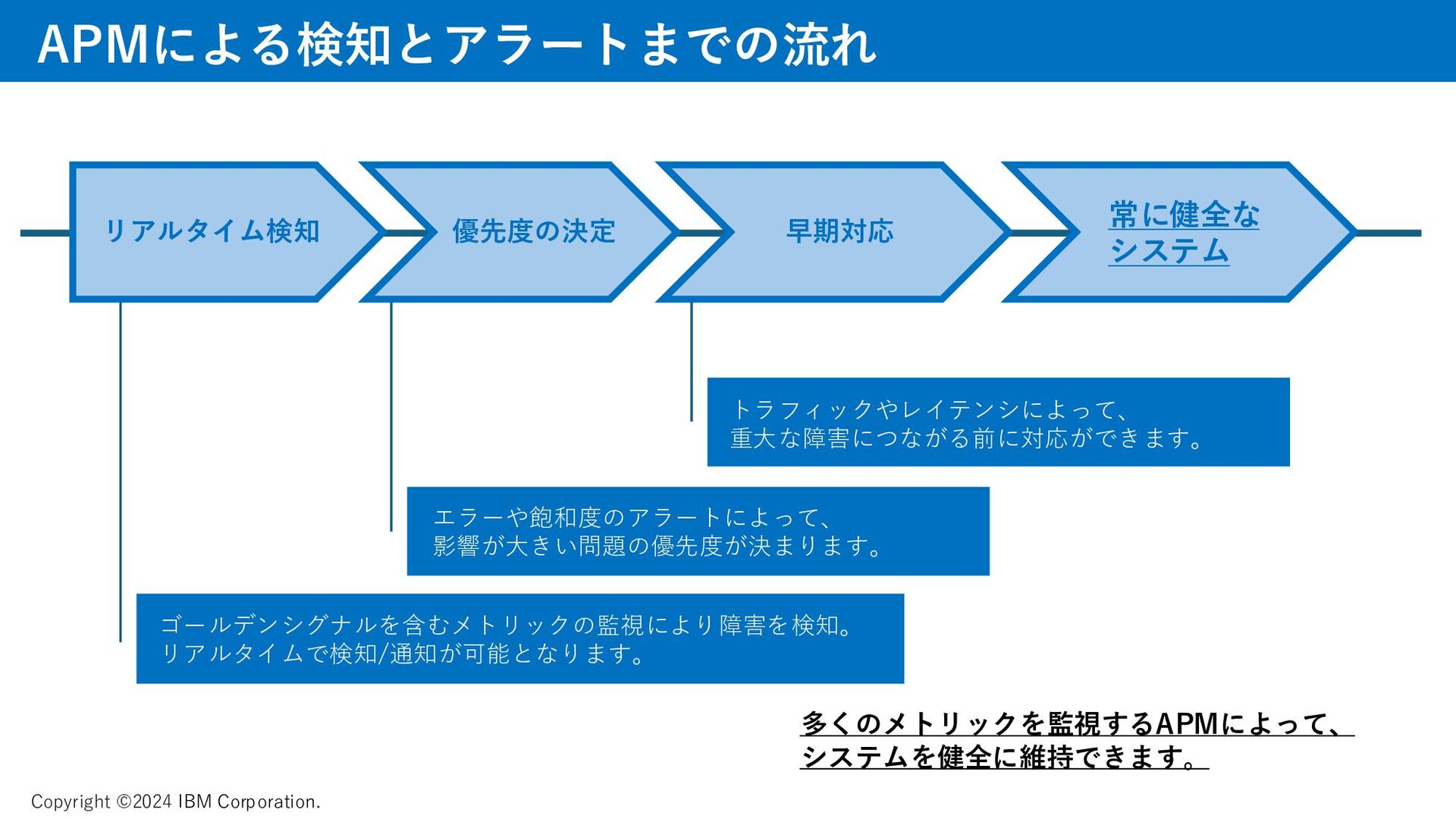
メトリック、ゴールデンシグナルについて、資料では取り上げています。 AI、機械学習によって迅速に課題を見つけるAPMの動きについて、説明をしています。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}