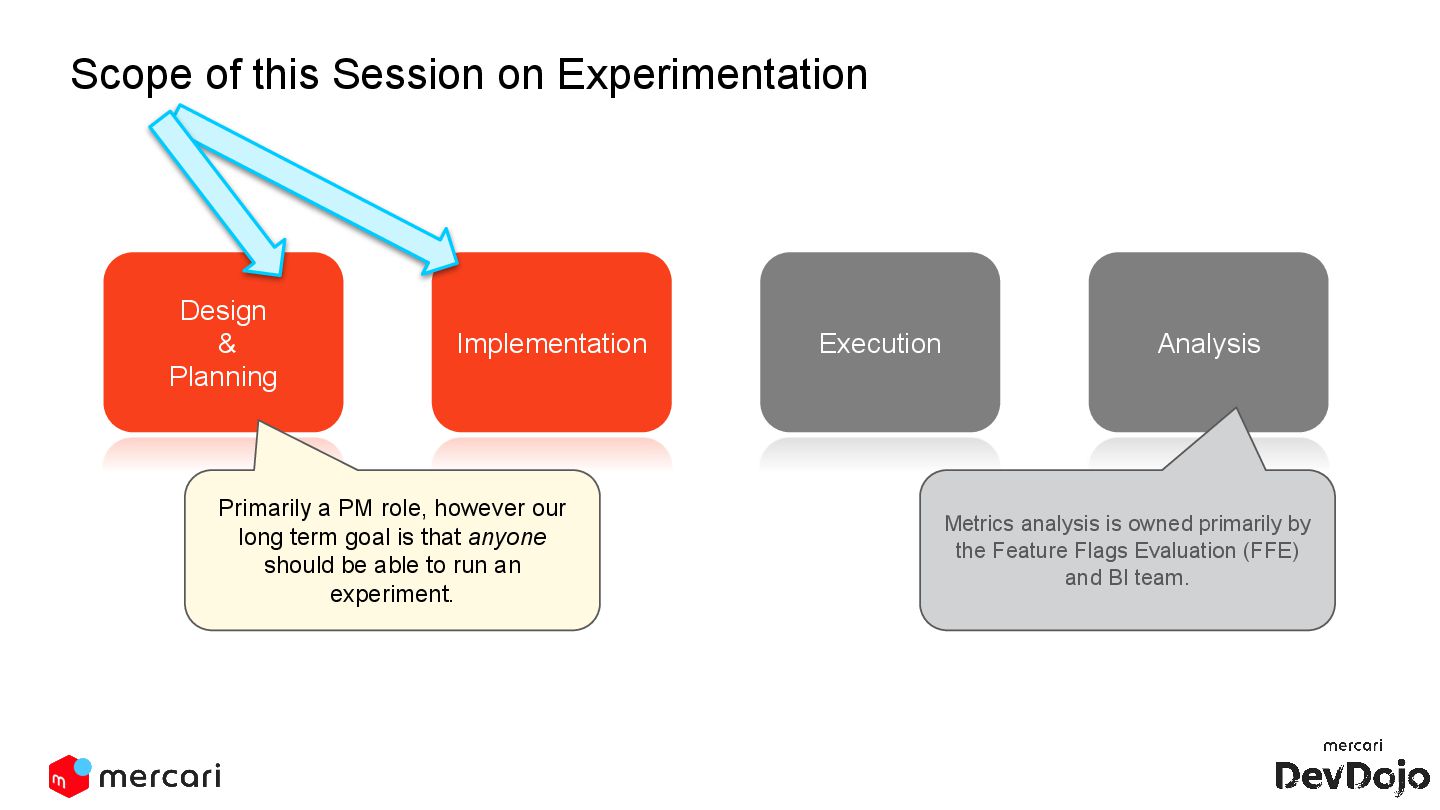
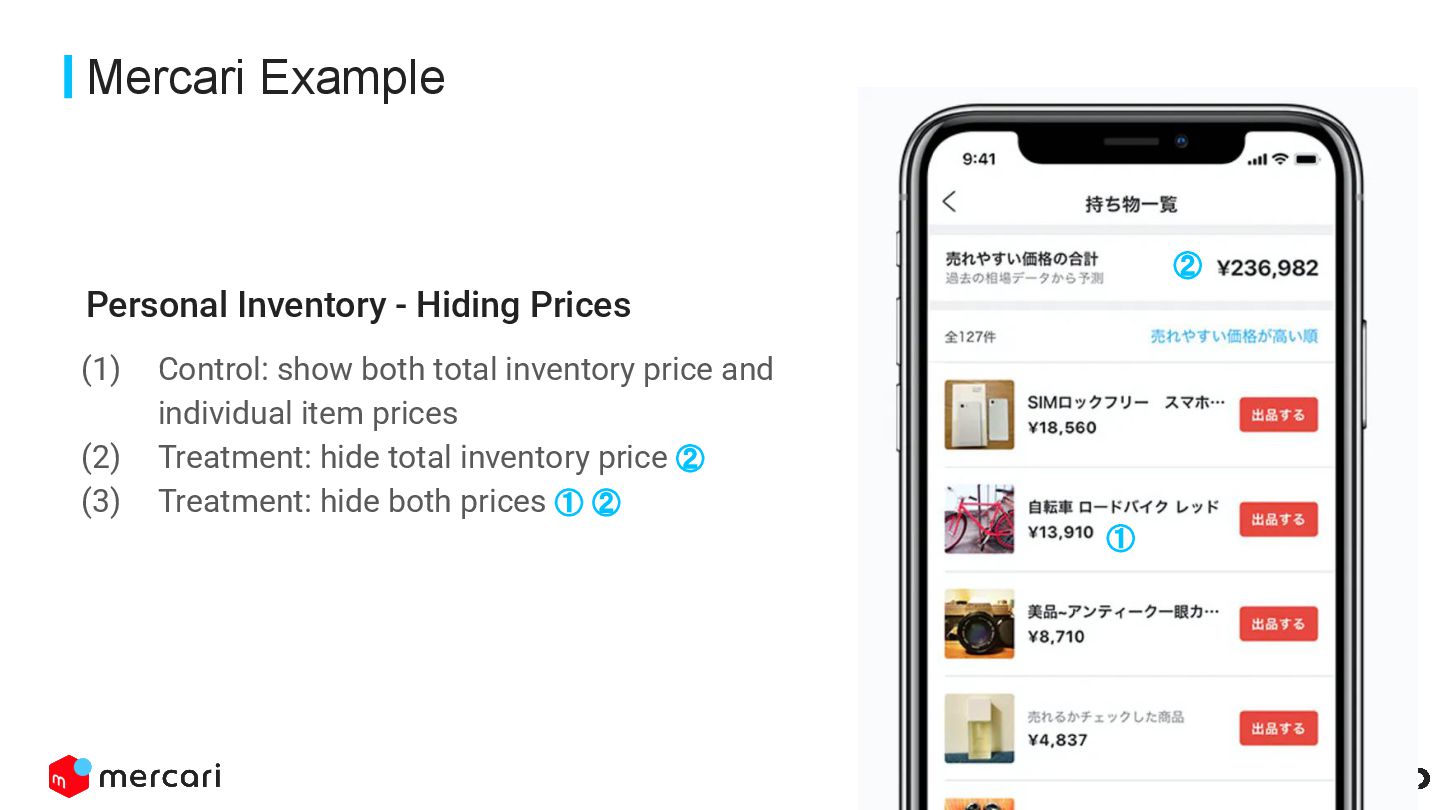
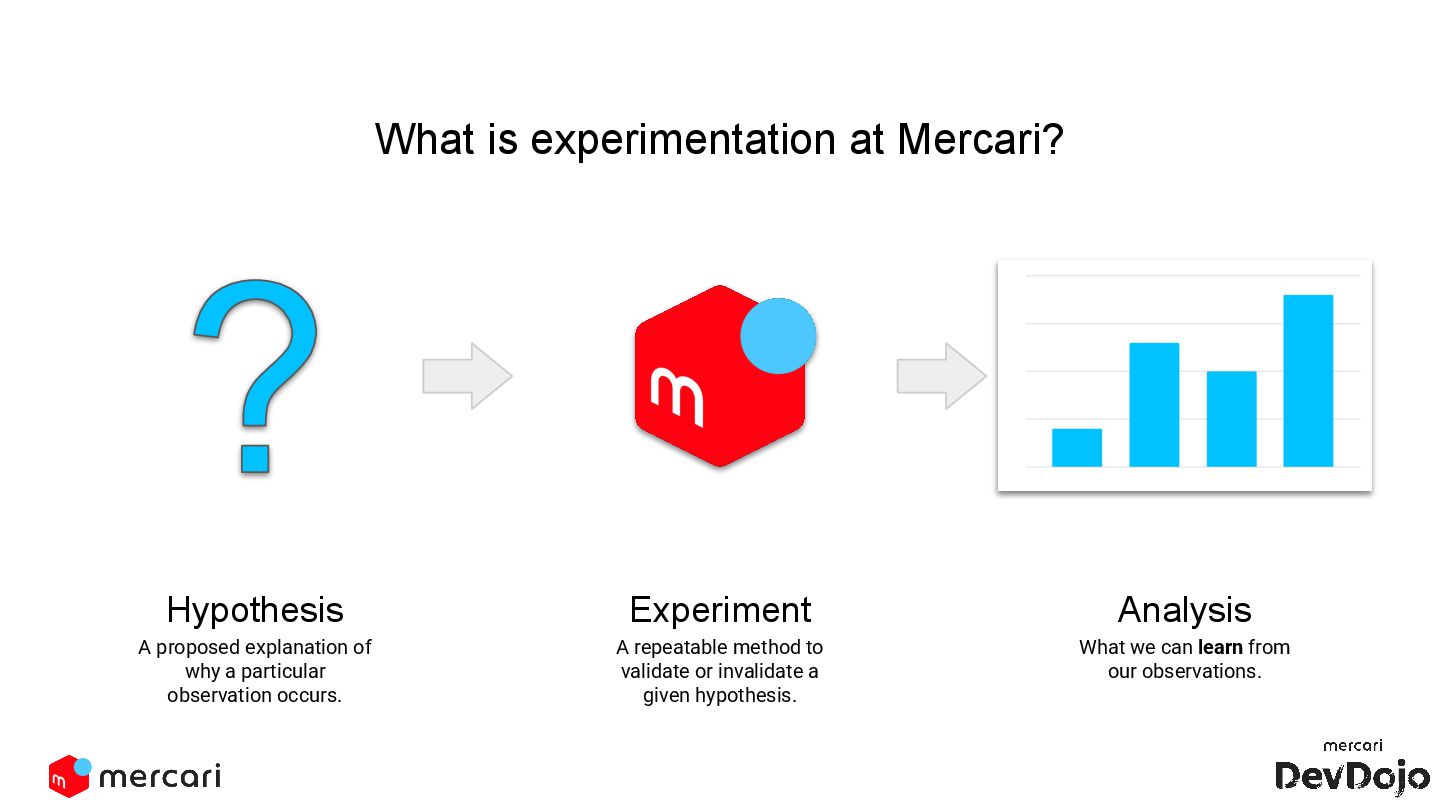
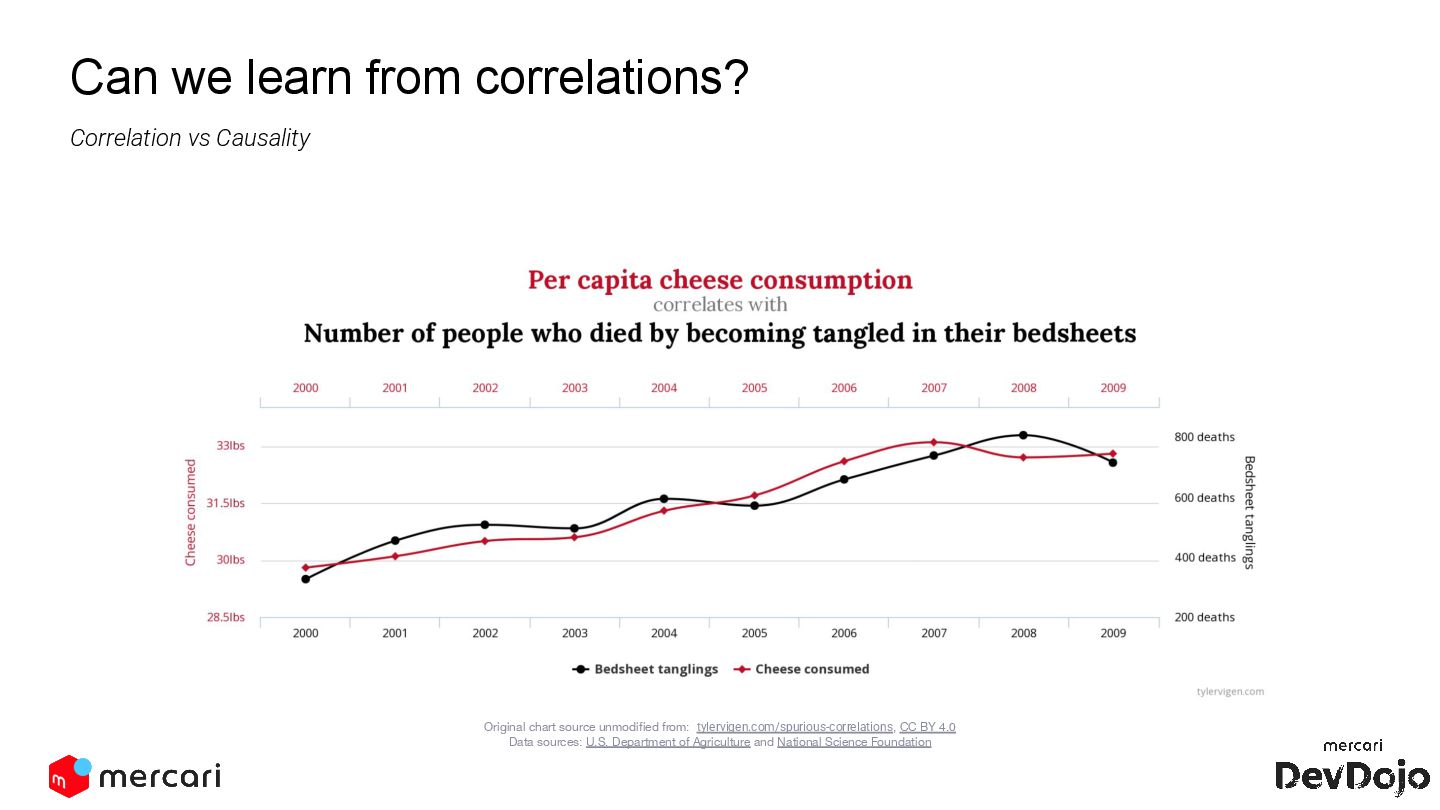
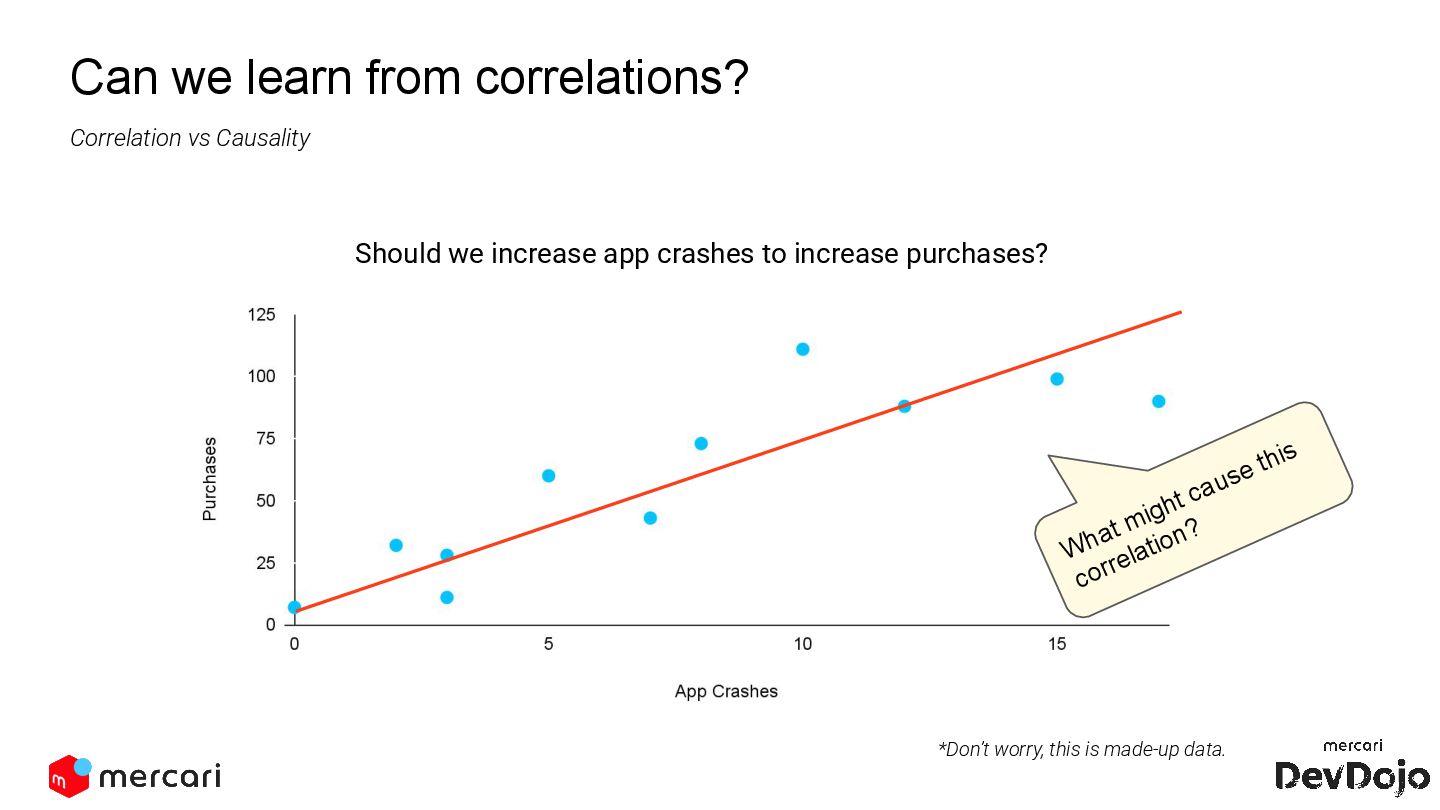
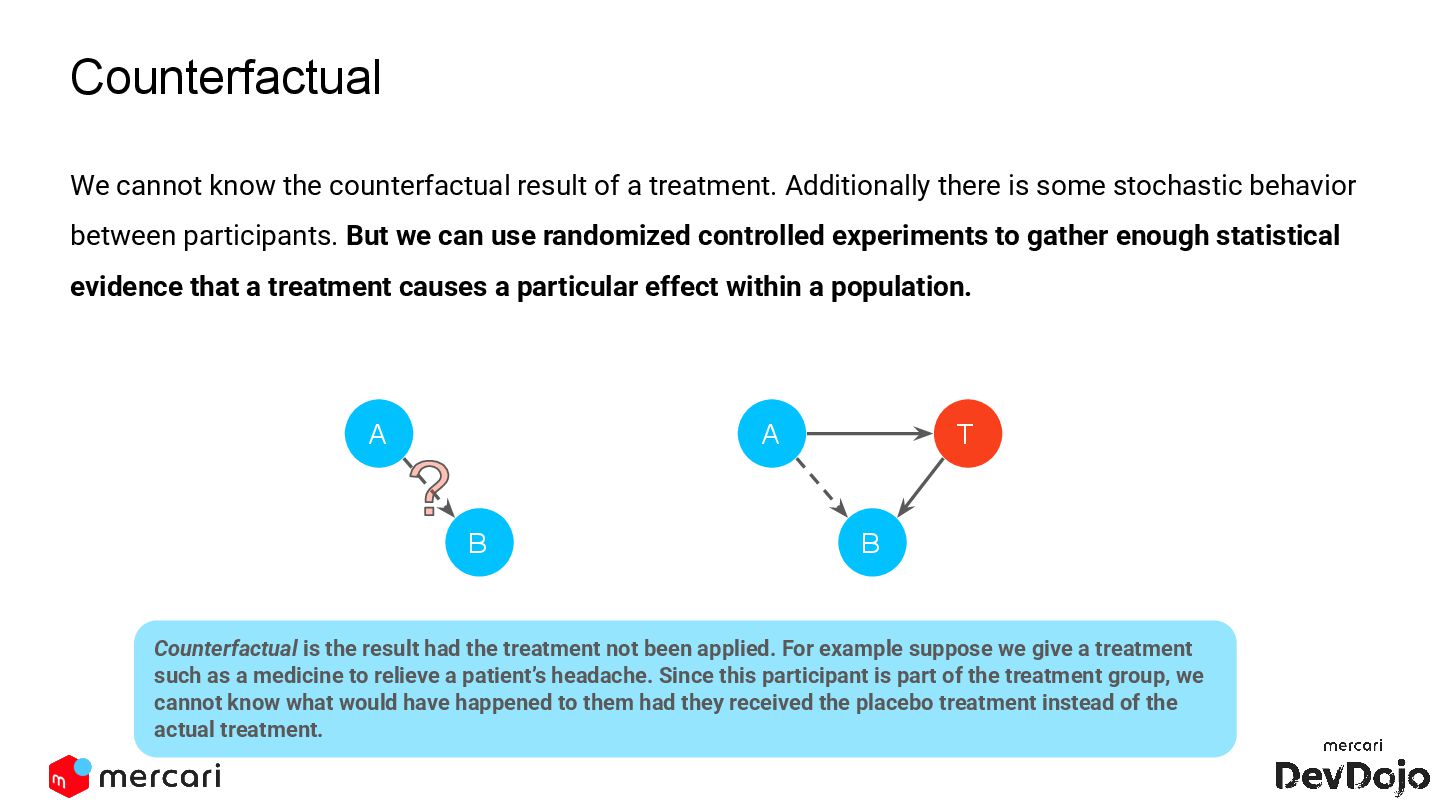
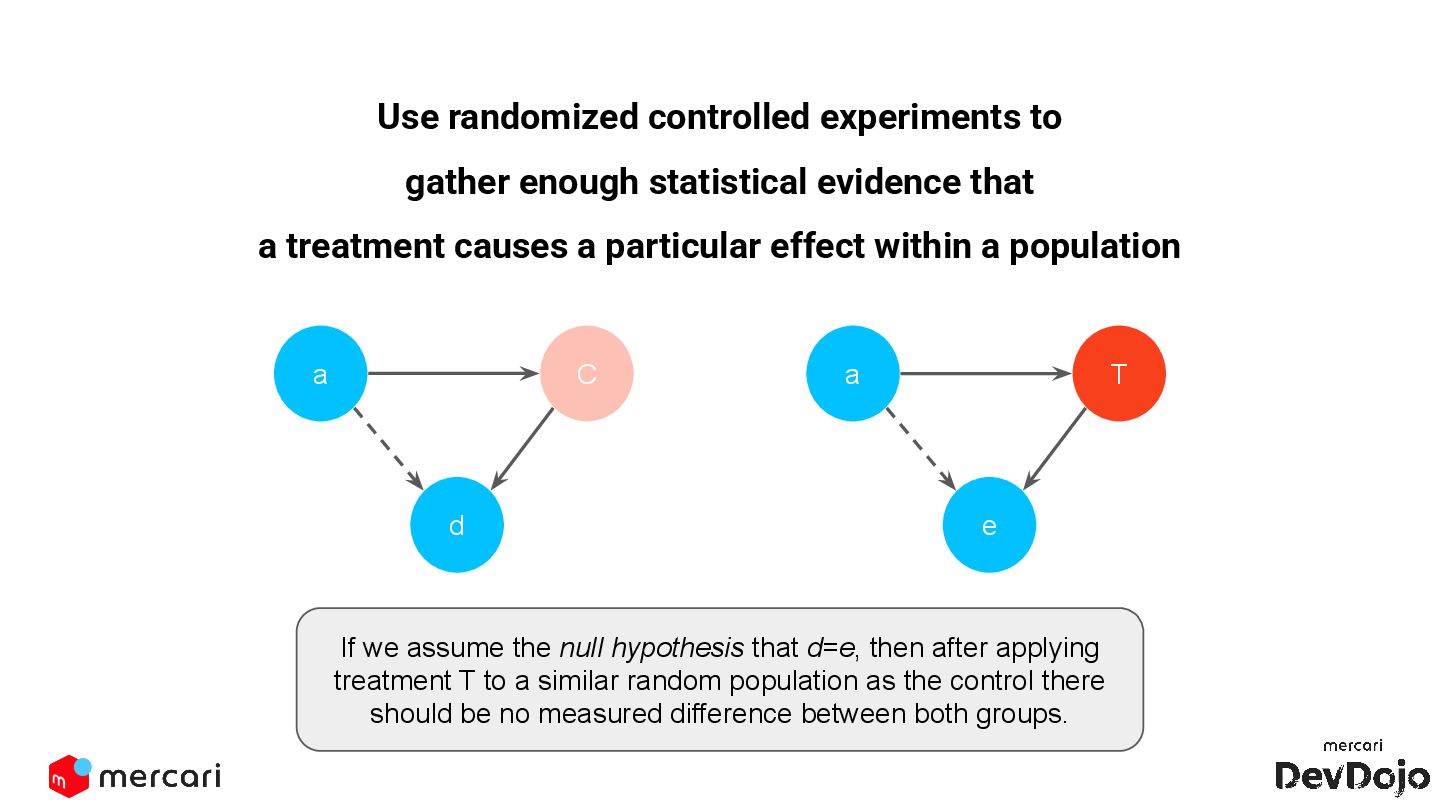
This DevDojo presentation focuses on experimentation, including what it is and why it's run, with a specific look at Mercari's approach. It covers the process of implementing experiments, from design to analysis, emphasizing the importance of establishing causality over mere correlations.
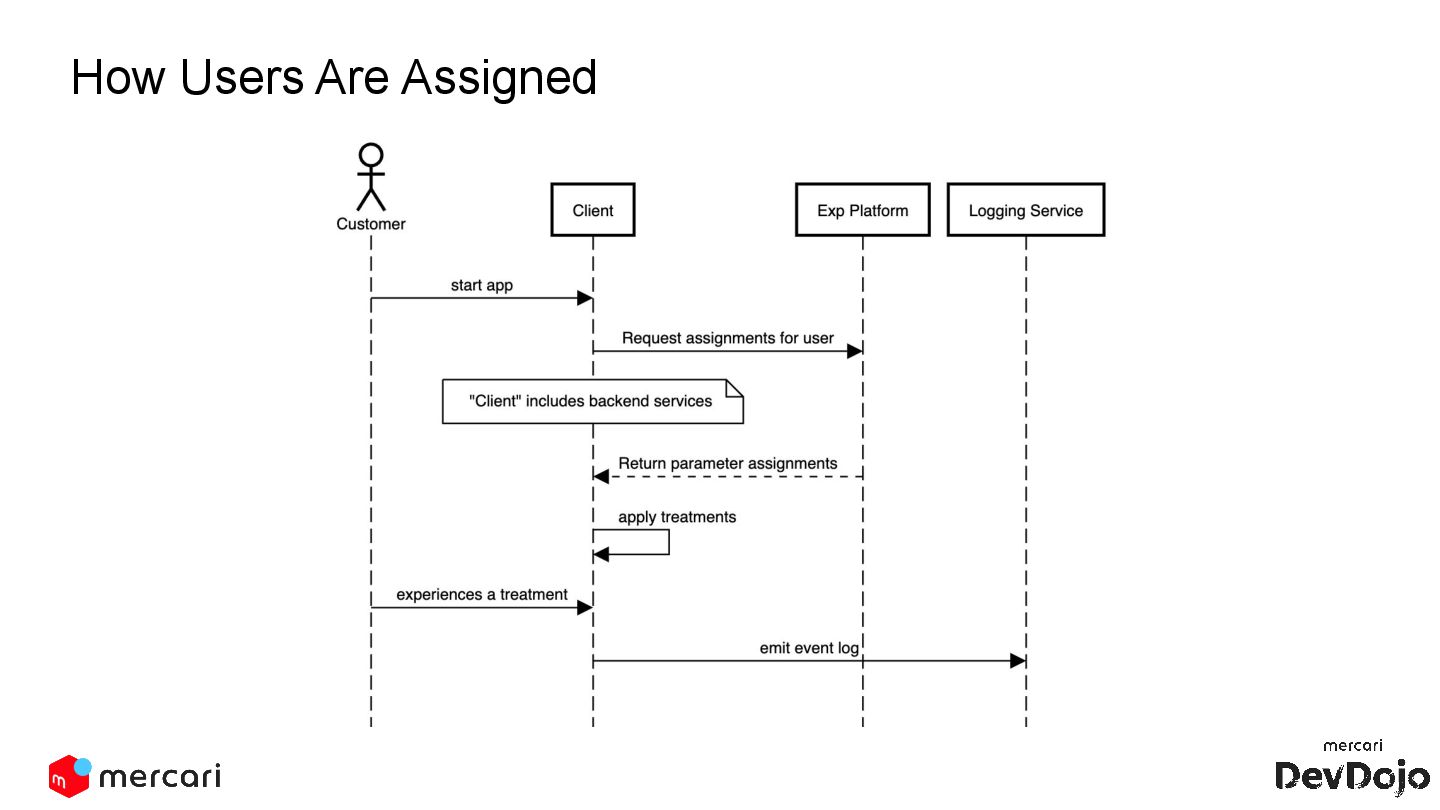
The session also delves into technical details of Mercari's experimentation platform, such as user assignment, population distribution, and event logging.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}