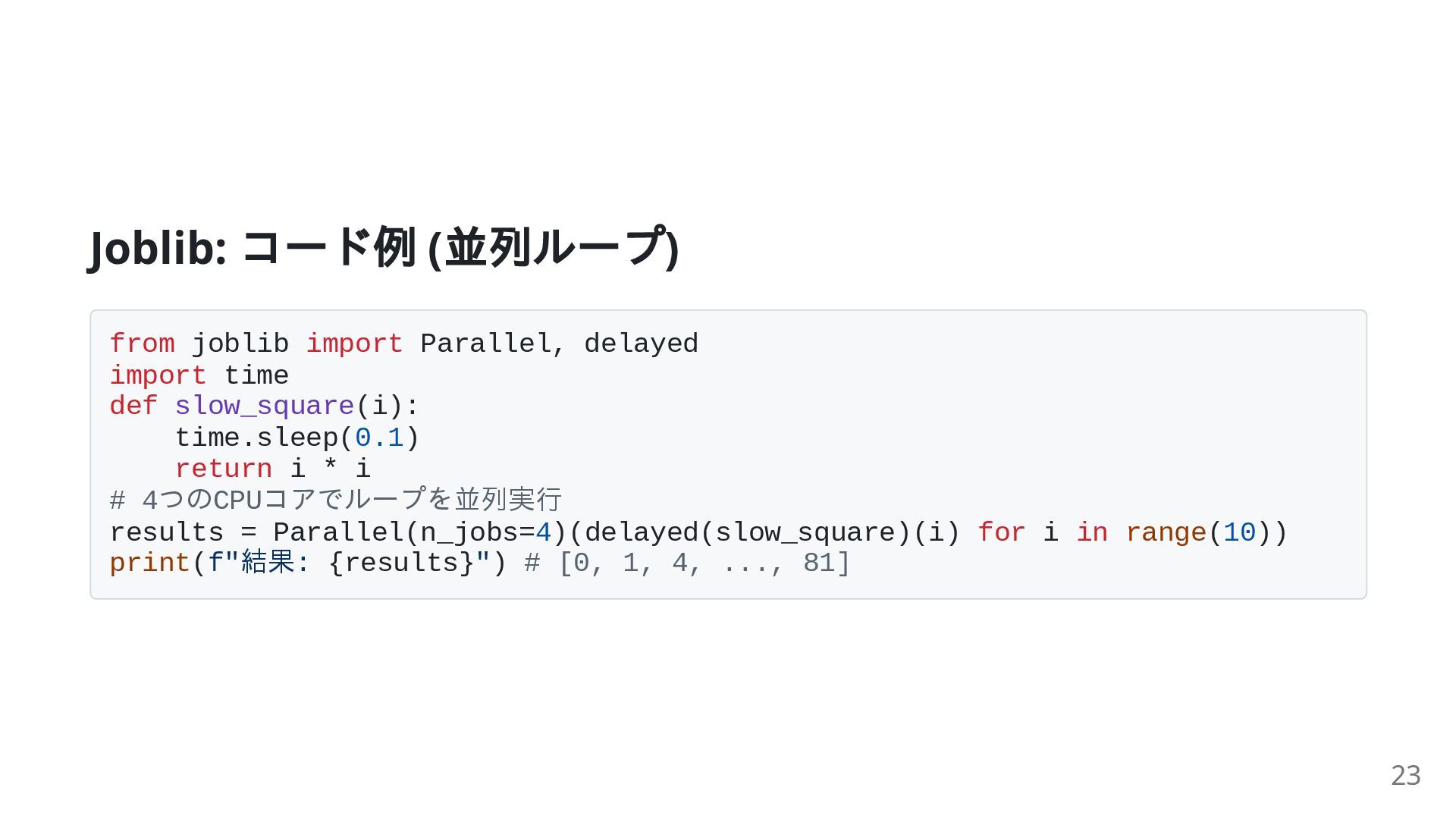
time def slow_square(i): time.sleep(0.1) return i * i # 4つのCPUコアでループを並列実行 results = Parallel(n_jobs=4)(delayed(slow_square)(i) for i in range(10)) print(f"結果: {results}") # [0, 1, 4, ..., 81] 23
as np x = np.arange(-3.0, 3.0, 0.1) y = np.arange(-2.0, 2.0, 0.1) X, Y = np.meshgrid(x, y) Z = np.exp(-X**2 - Y**2) # Matplotlibはこの呼び出しで内部的にcontourpyを使用 plt.contour(X, Y, Z) plt.show() 54
board.push_san("e5") print(board) # r n b q k b n r # p p p p . p p p # . . . . . . . . # . . . . p . . . # . . . . P . . . # . . . . . . . . # P P P P . P P P # R N B Q K B N R 81
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![tabulate: コード例 from tabulate import tabulate data = [["Alice", 28],](https://files.speakerdeck.com/presentations/21dee78400ce46c8890498e9371a81c0/slide_84.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}