本スライドは、MIXIの2025年度新卒向け技術研修で使用された資料です。
https://zenn.dev/mixi/articles/95e0d0477c1ed7
MIXI 2025新卒技術研修
『AI研修』
▼リポジトリ
https://github.com/mixigroup/2025BeginnerTrainingAI
▼動画
https://youtu.be/DzWxRv4cDf0
───────────────────────────────
※皆様へのお願い※ 資料・動画・リポジトリのご利用について
───────────────────────────────
公開している資料や動画は、是非、勉強会や社内の研修などにご自由にお使いいただければと思いますが、以下のような場でのご利用はご遠慮ください。
- 受講者から参加費や授業料など金銭を集めるような場での利用
(会場費や飲食費など勉強会の運営に必要な実費を集める場合は問題ありません)
- 出典を削除または改変しての利用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![©MIXI 36 [余談] LLMどうやって学習してるの? LLM(大規模言語モデル)とは? • Deep Learningの一種で、大量のテキストデータを用いて学習されたモデル 学習の仕組み •](https://files.speakerdeck.com/presentations/b7b000c1c83e4238ba1fed7ca211d834/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
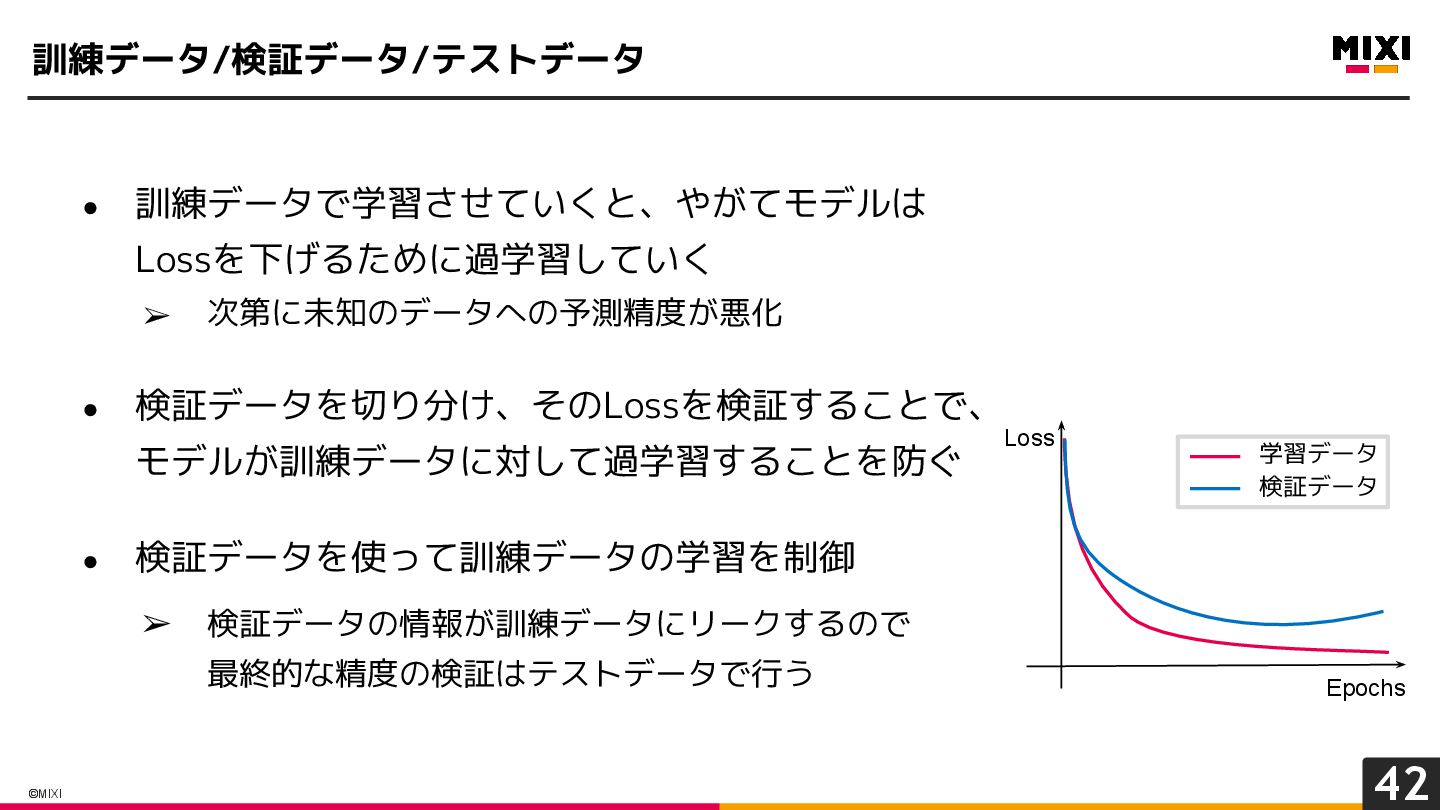{kind=link}
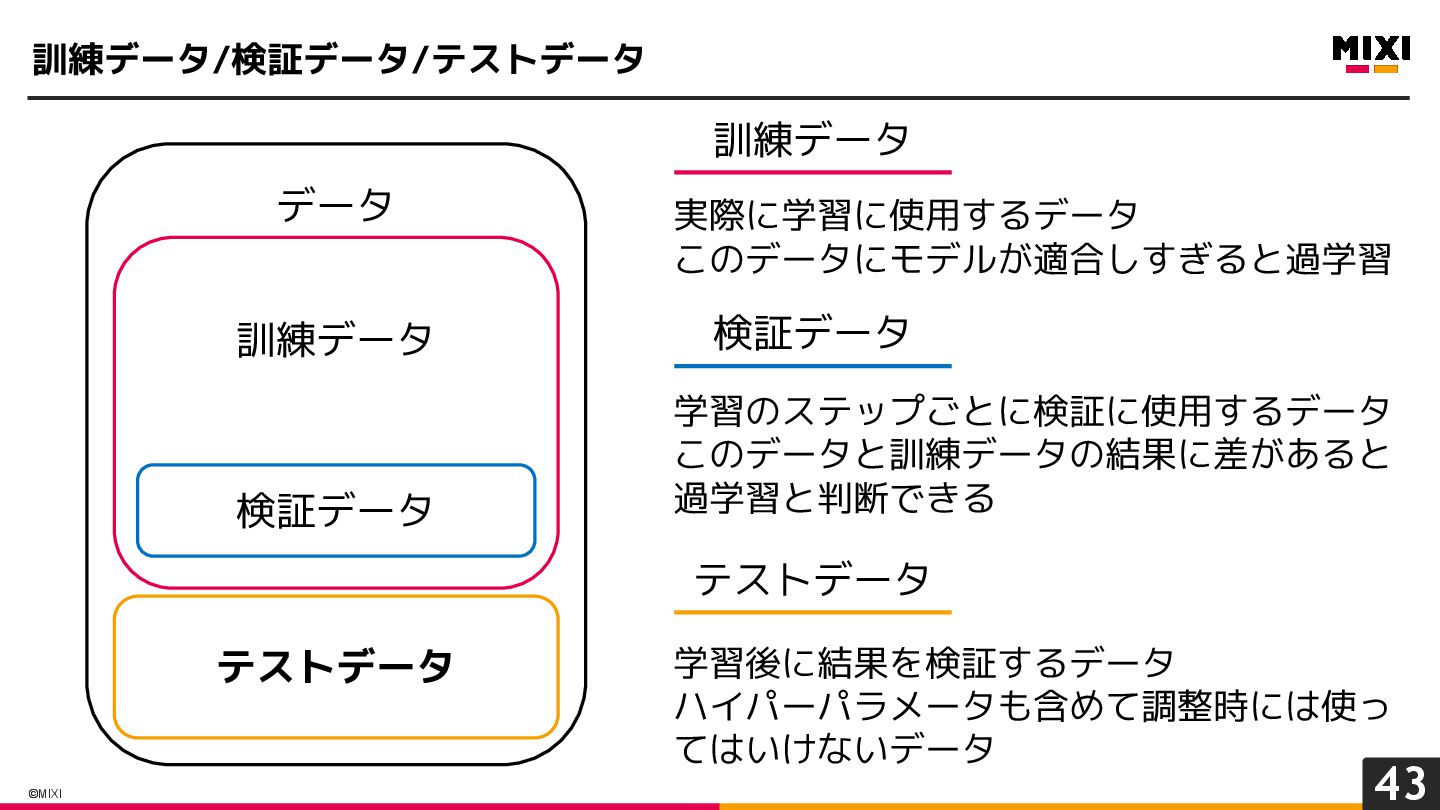{kind=link}
{kind=link}
{kind=link}
{kind=link}
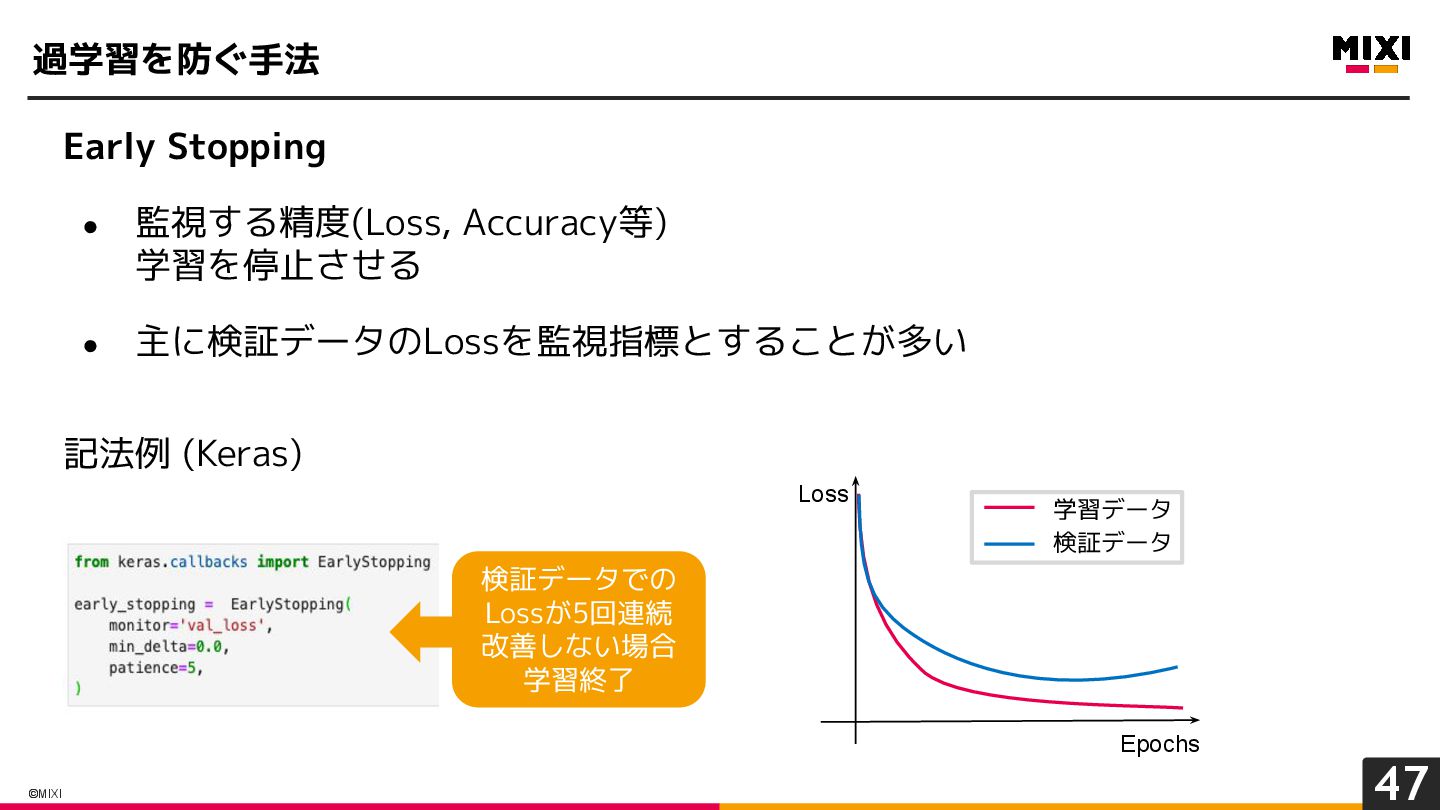{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
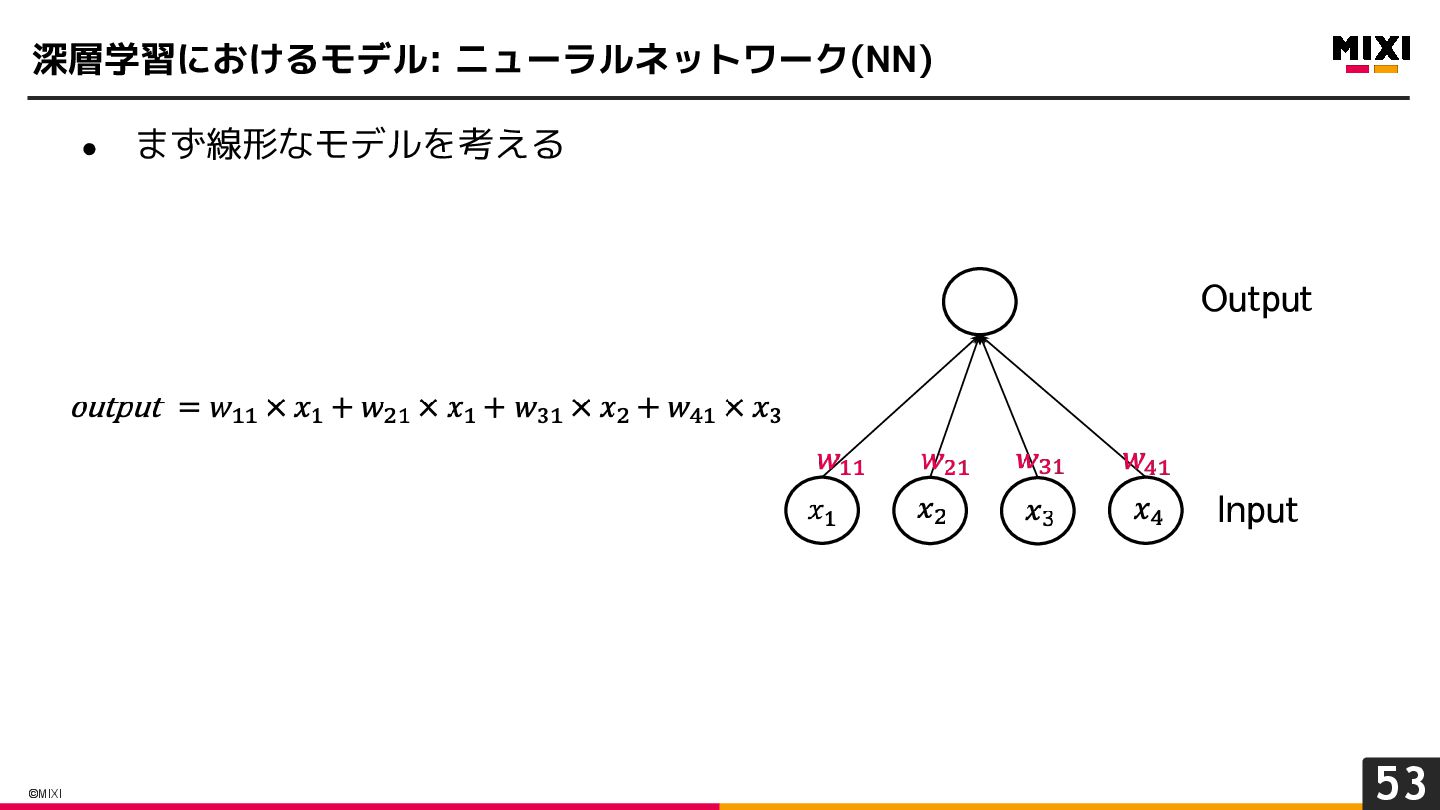{kind=link}
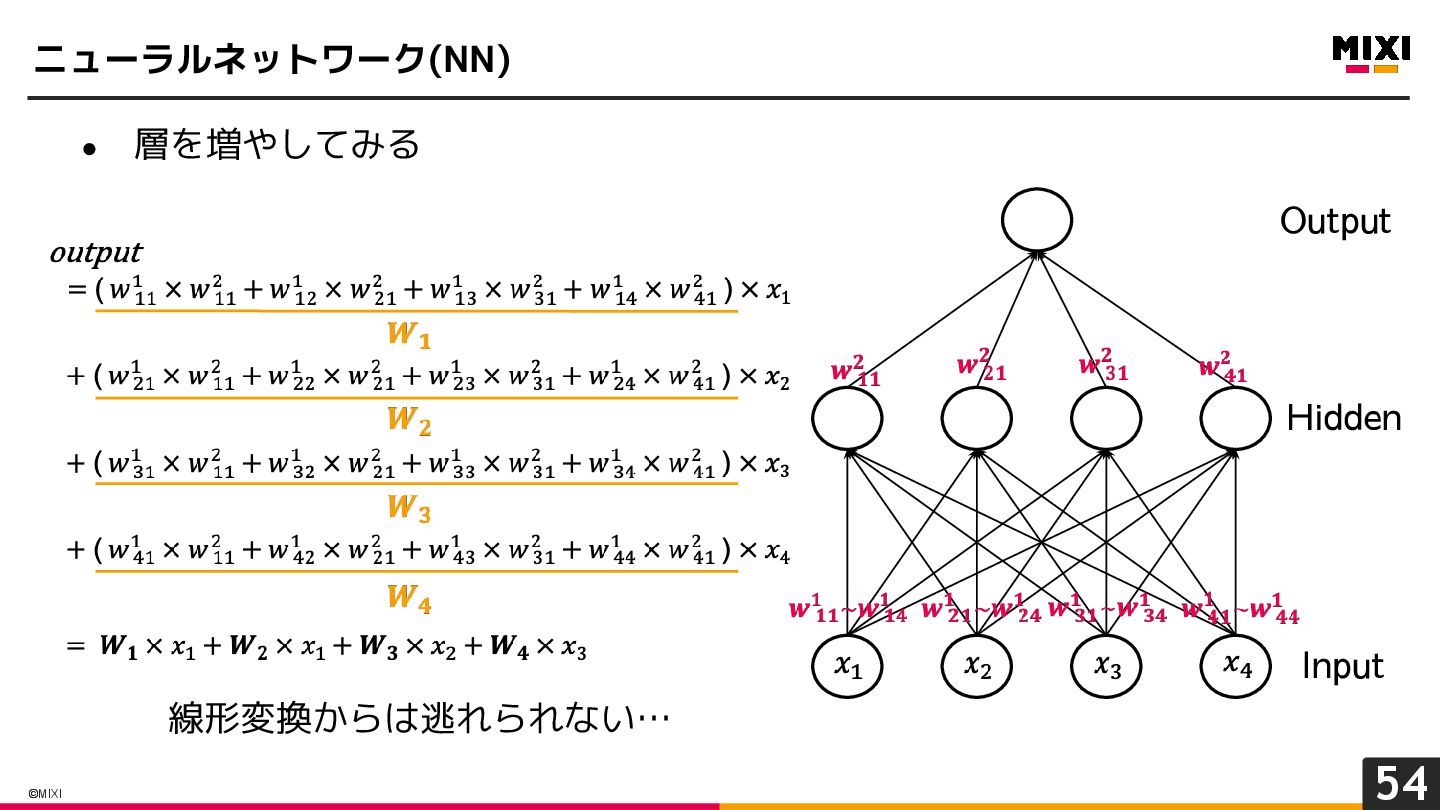{kind=link}
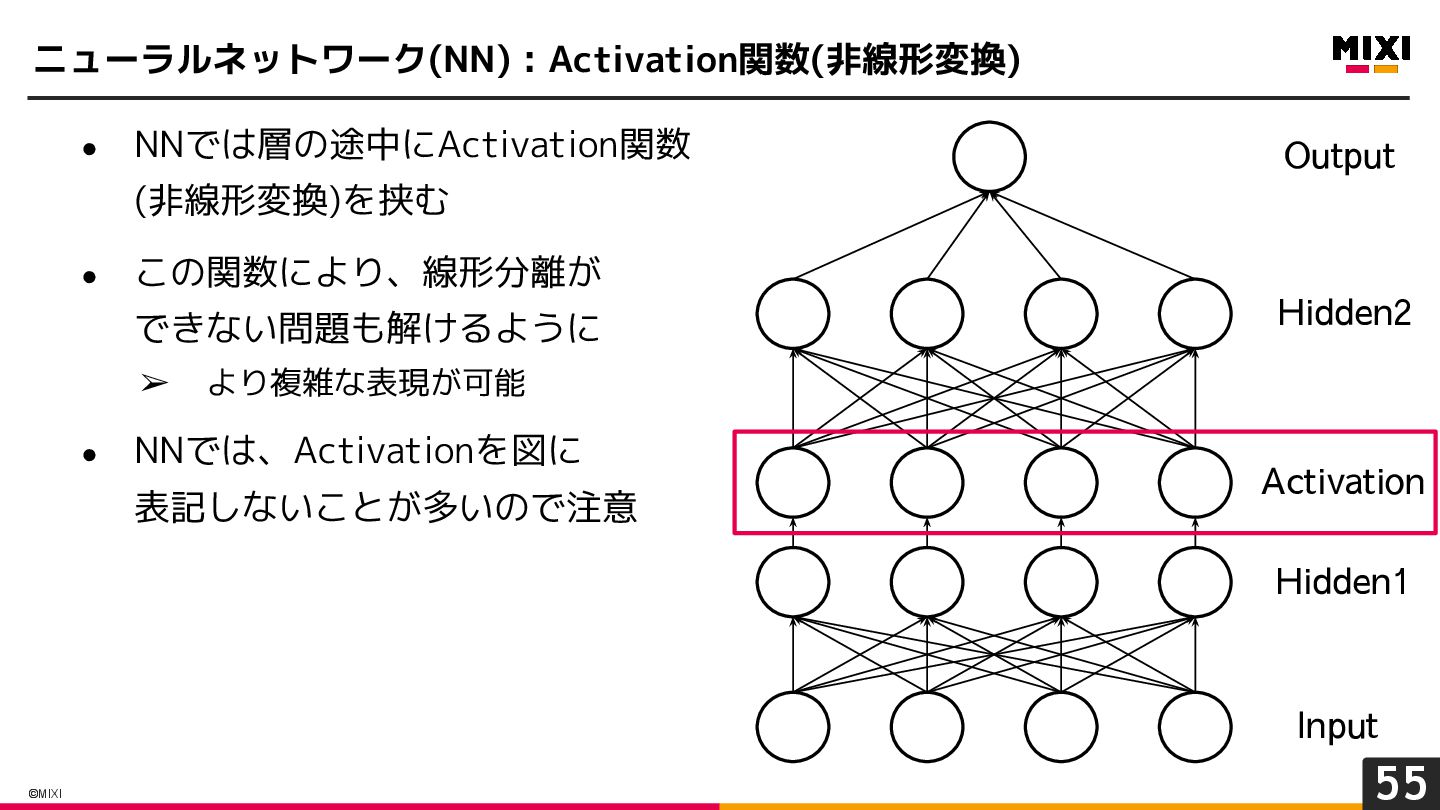{kind=link}
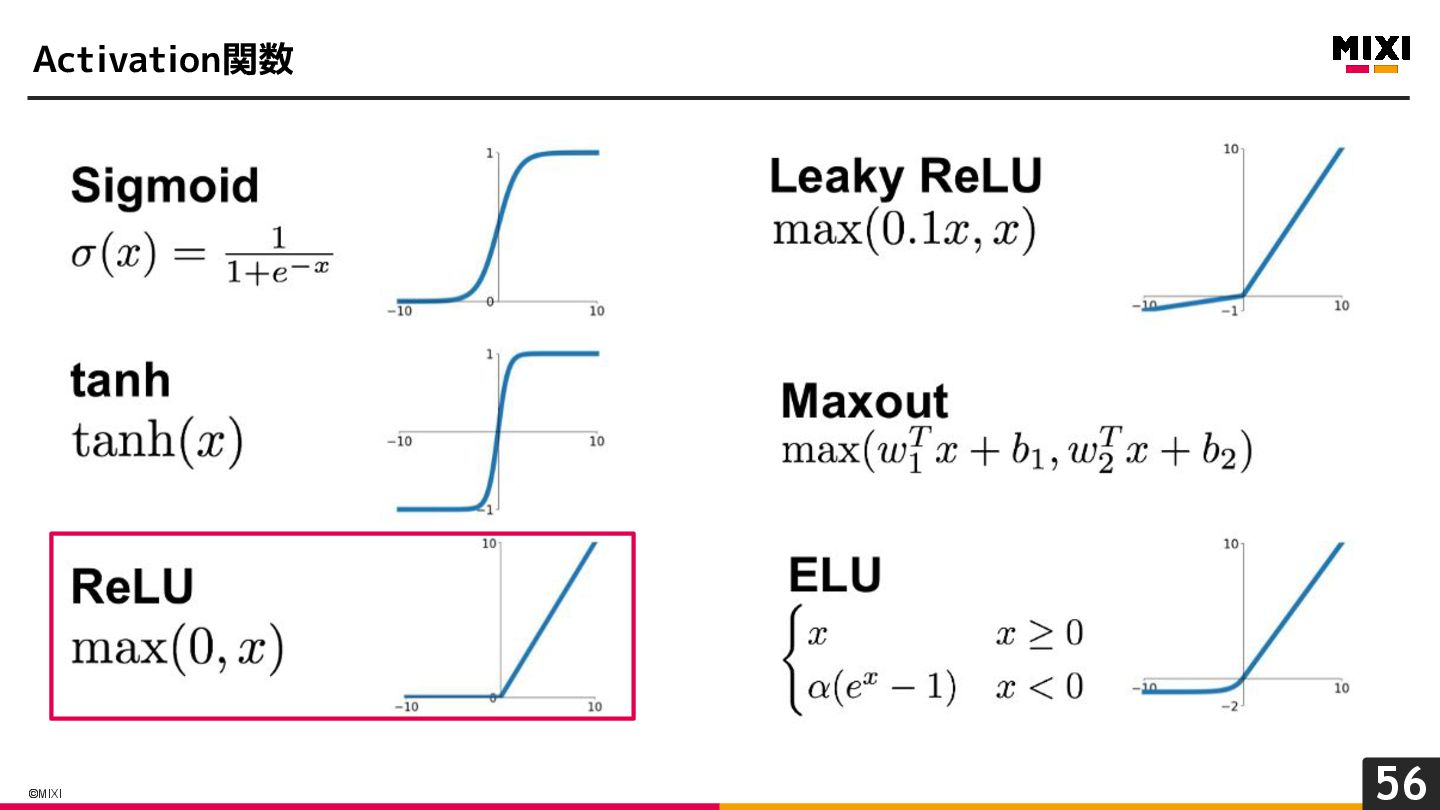{kind=link}
{kind=link}
{kind=link}
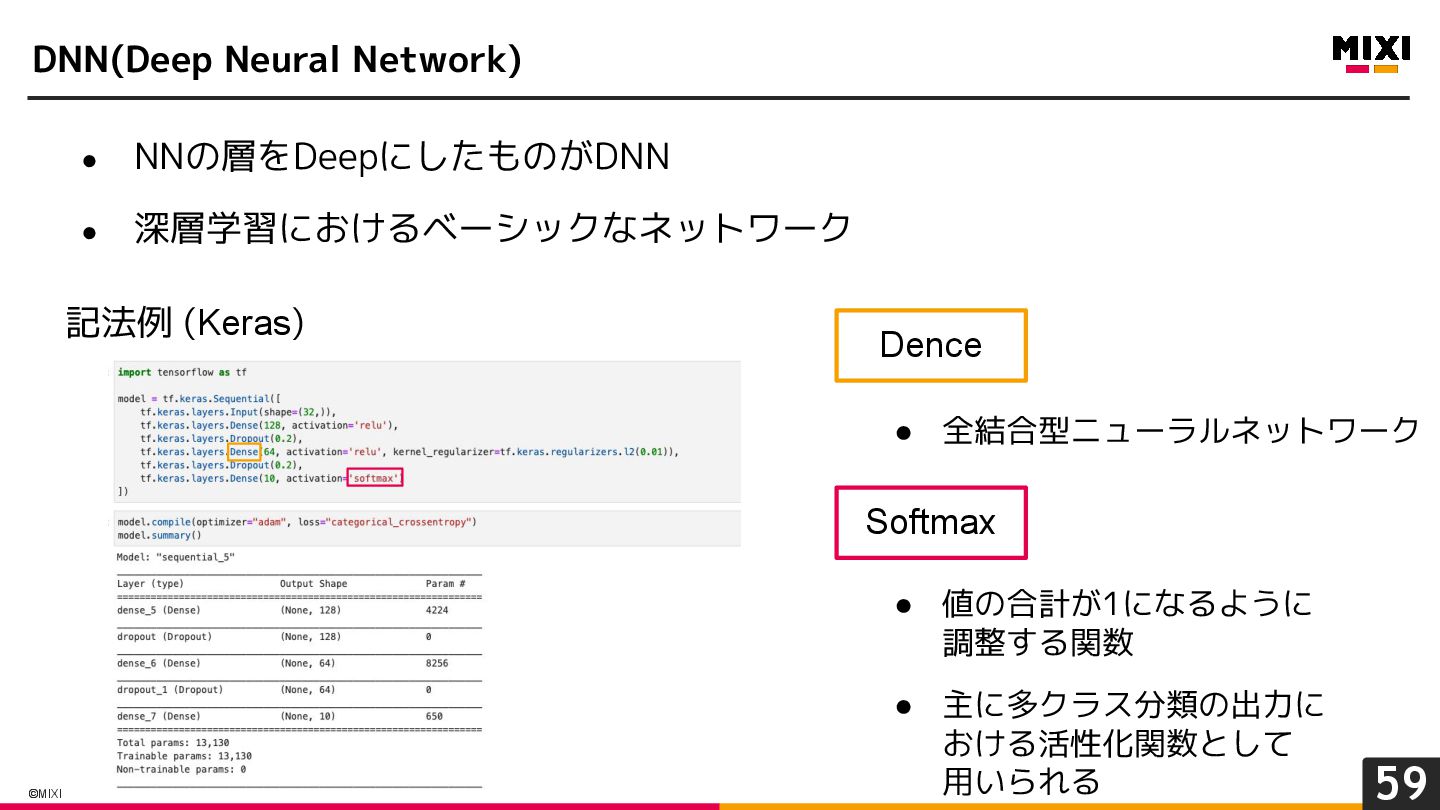{kind=link}
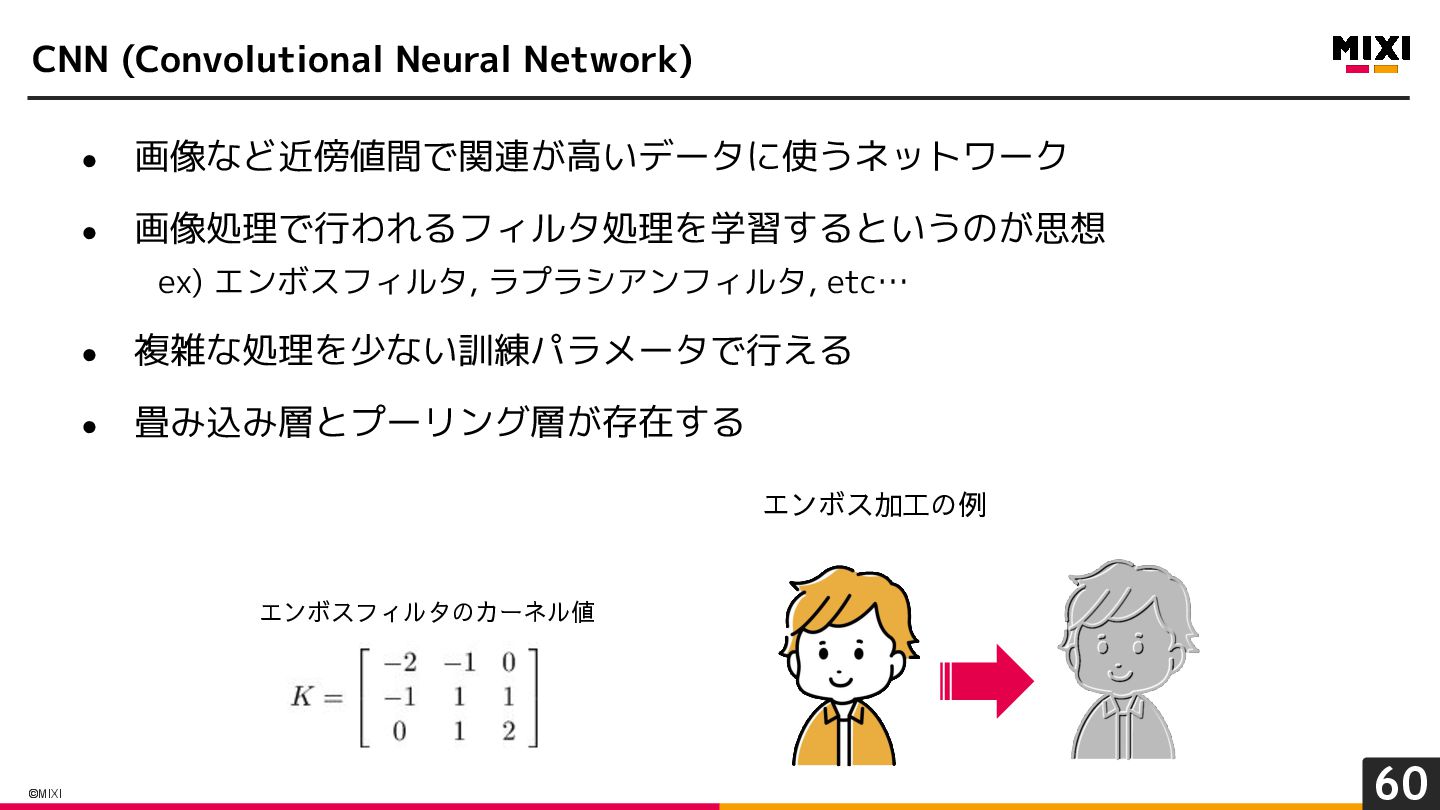{kind=link}
![©MIXI 61 CNN: 画像と行列 • 白黒画像は、2次元行列で表現できる ➢ SVGAサイズの場合、[800, 600]の行列に0〜255の数値が入る •](https://files.speakerdeck.com/presentations/b7b000c1c83e4238ba1fed7ca211d834/slide_60.jpg){kind=link}
![©MIXI 62 CNN: フィルタを用いた畳み込み • CNNでは、画像の行列に対してフィルタをかけることで畳み込みを行う • フィルタの大きさは[縦, 横, カラーモード]で、縦と横はハイパーパラメータ](https://files.speakerdeck.com/presentations/b7b000c1c83e4238ba1fed7ca211d834/slide_61.jpg){kind=link}
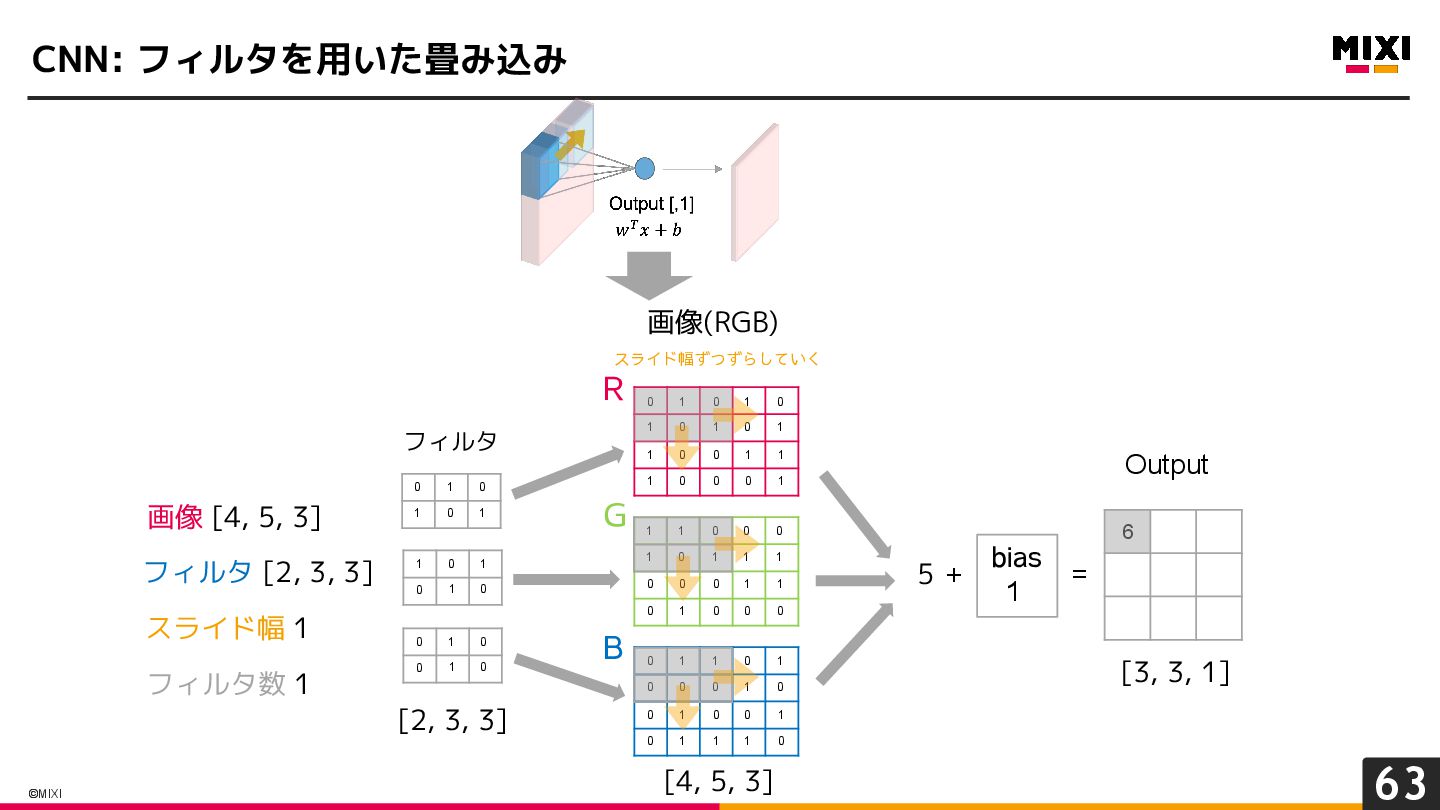{kind=link}
![©MIXI 64 CNN: プーリング • 畳み込み後に、行列を圧縮するために用いられる手法 • プーリング幅として[縦, 横, フィルタ数]の行列を指定](https://files.speakerdeck.com/presentations/b7b000c1c83e4238ba1fed7ca211d834/slide_63.jpg){kind=link}
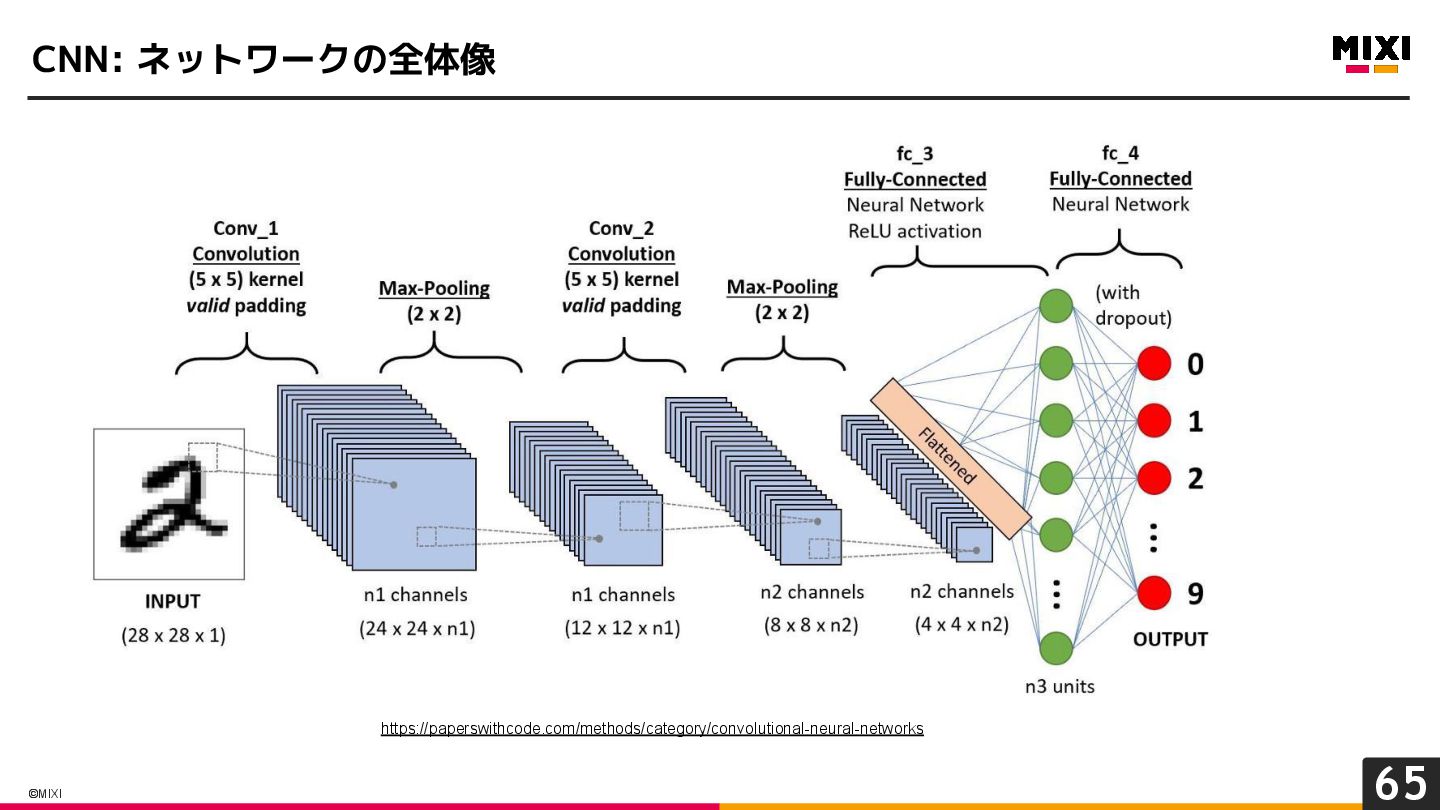{kind=link}
{kind=link}
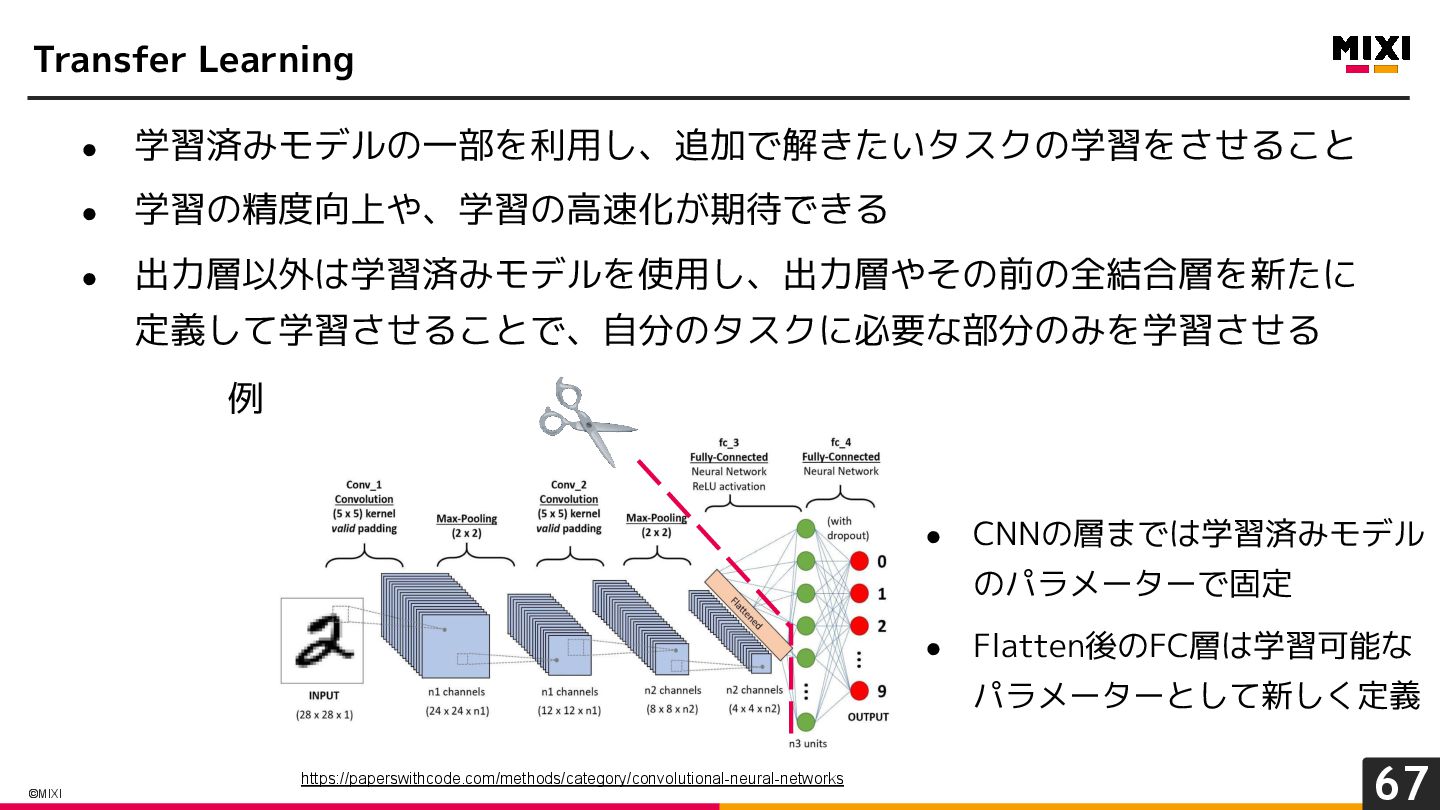{kind=link}
{kind=link}
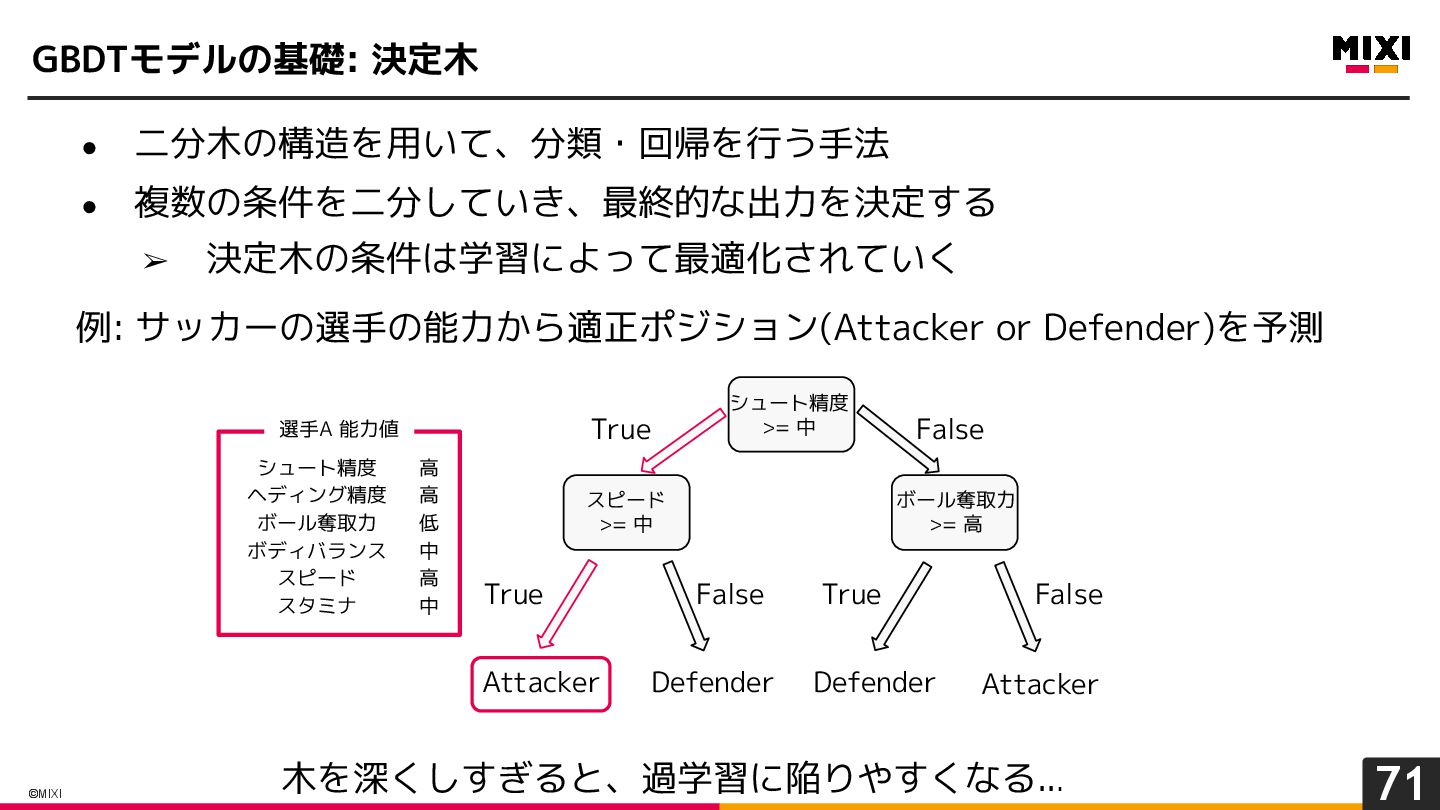
{kind=link}
{kind=link}
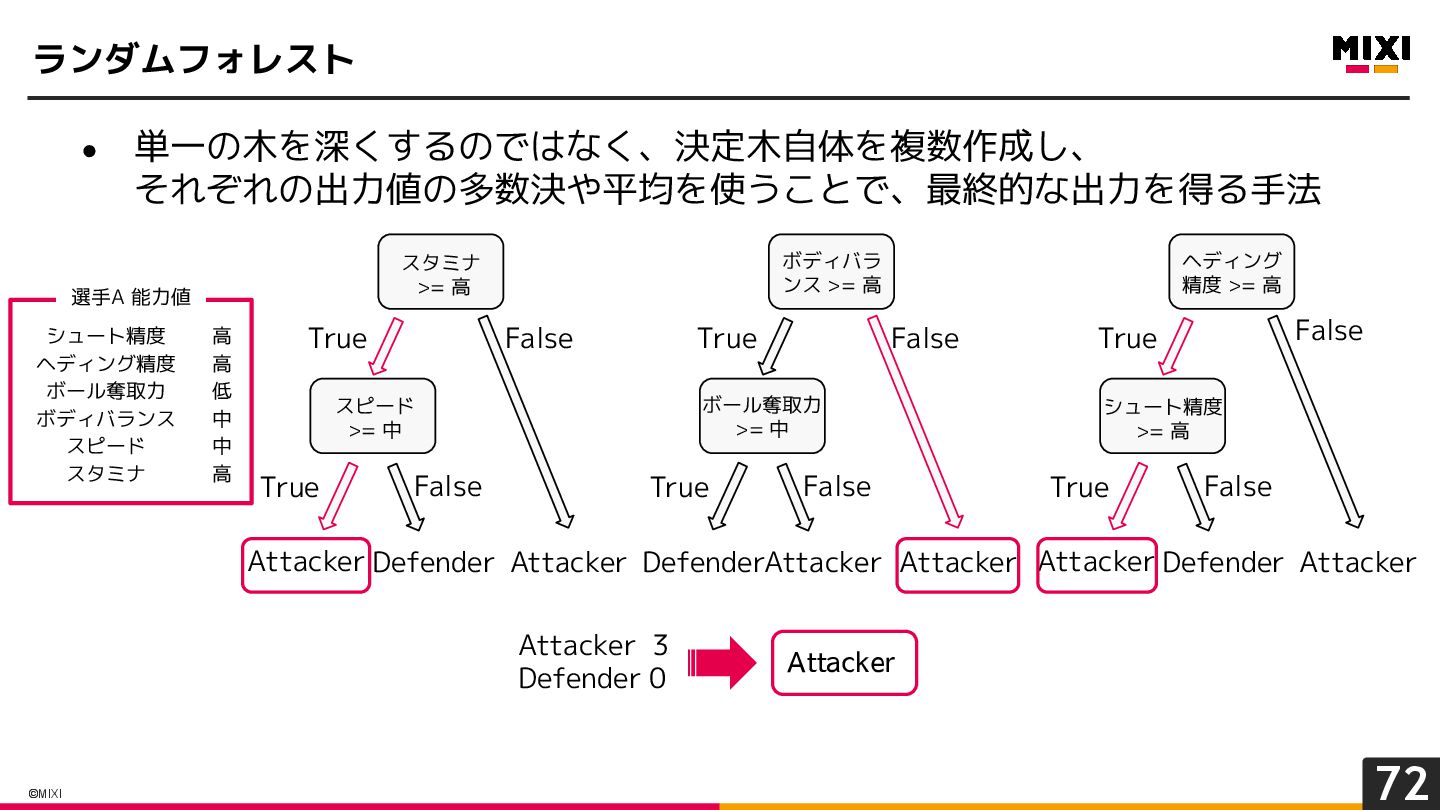
{kind=link}
{kind=link}
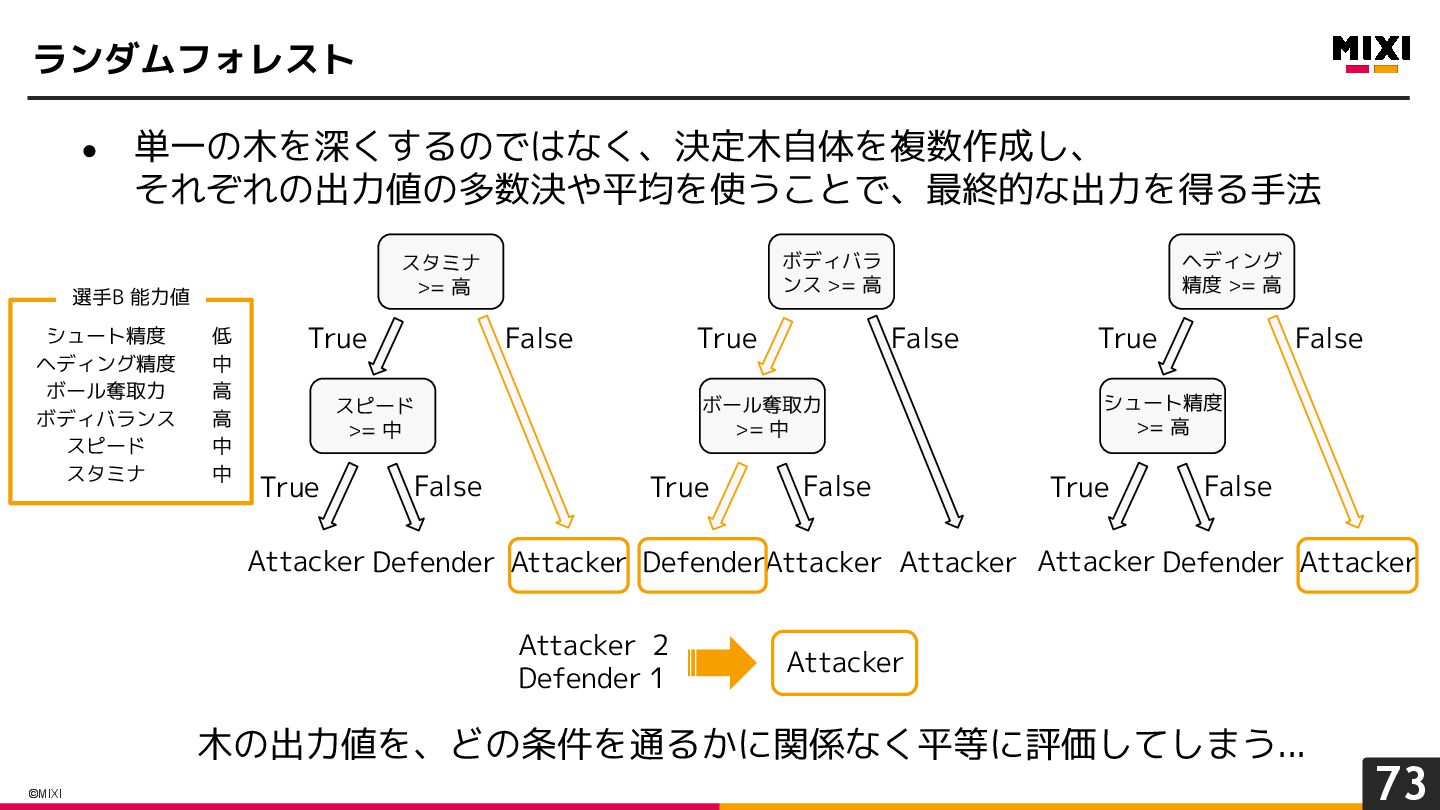{kind=link}
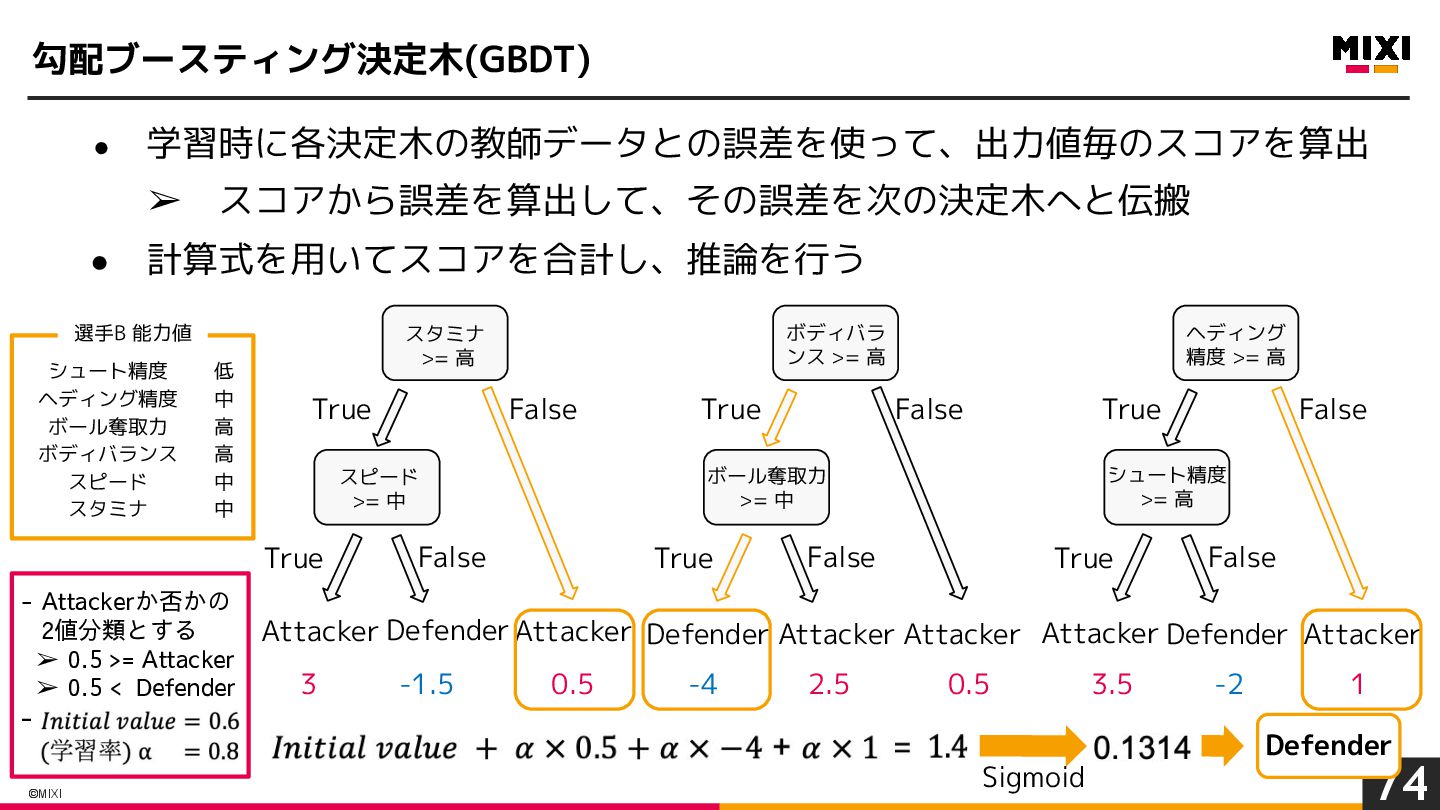{kind=link}
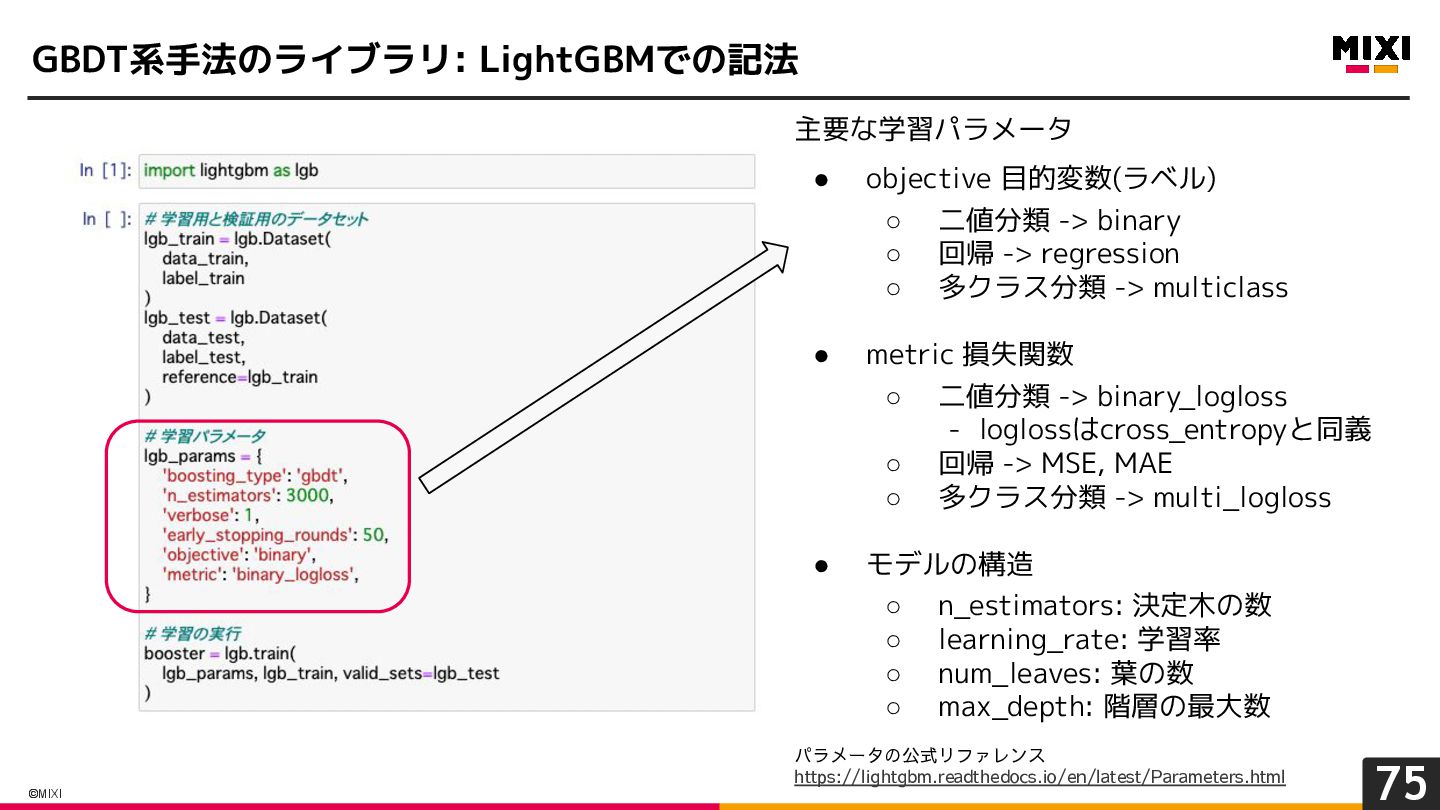{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
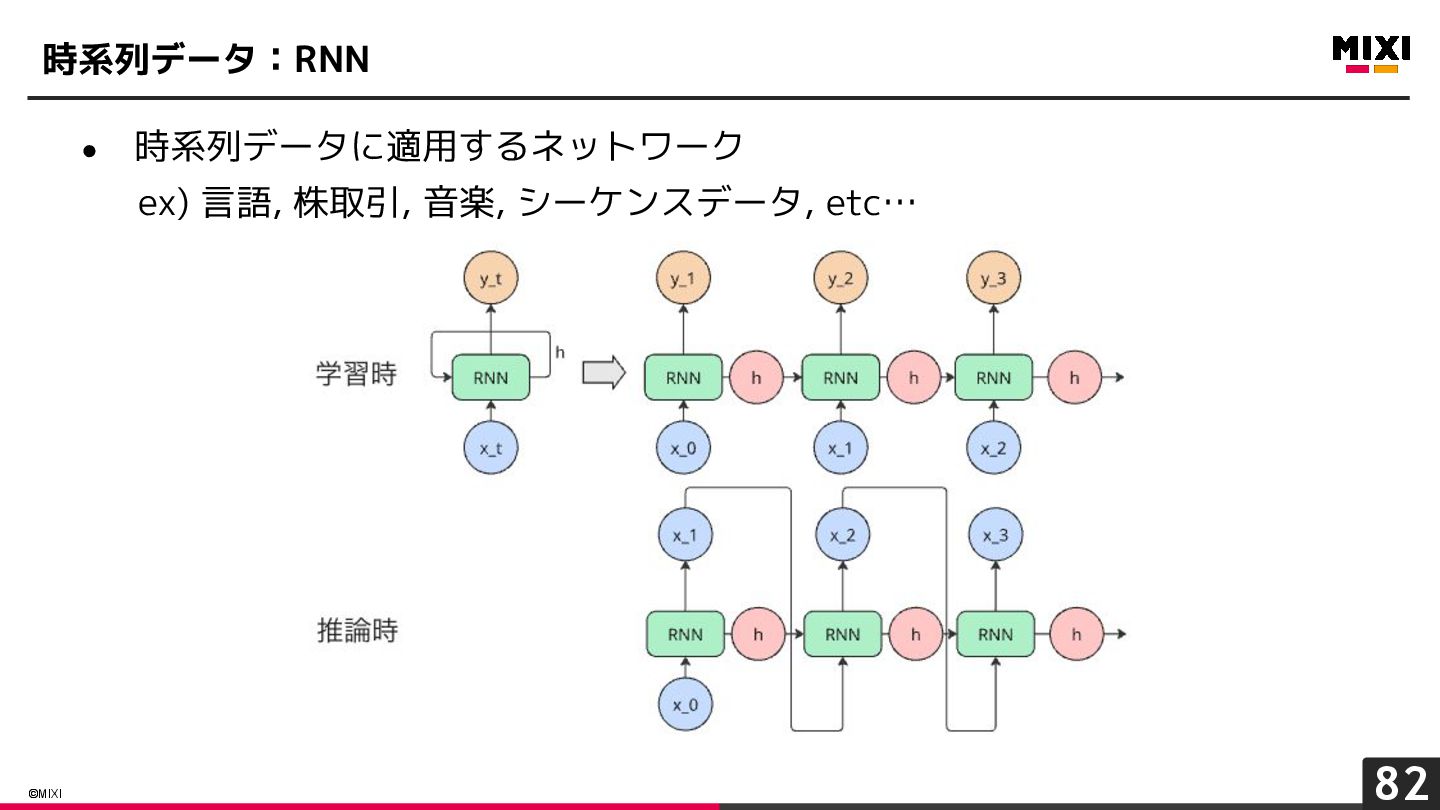{kind=link}
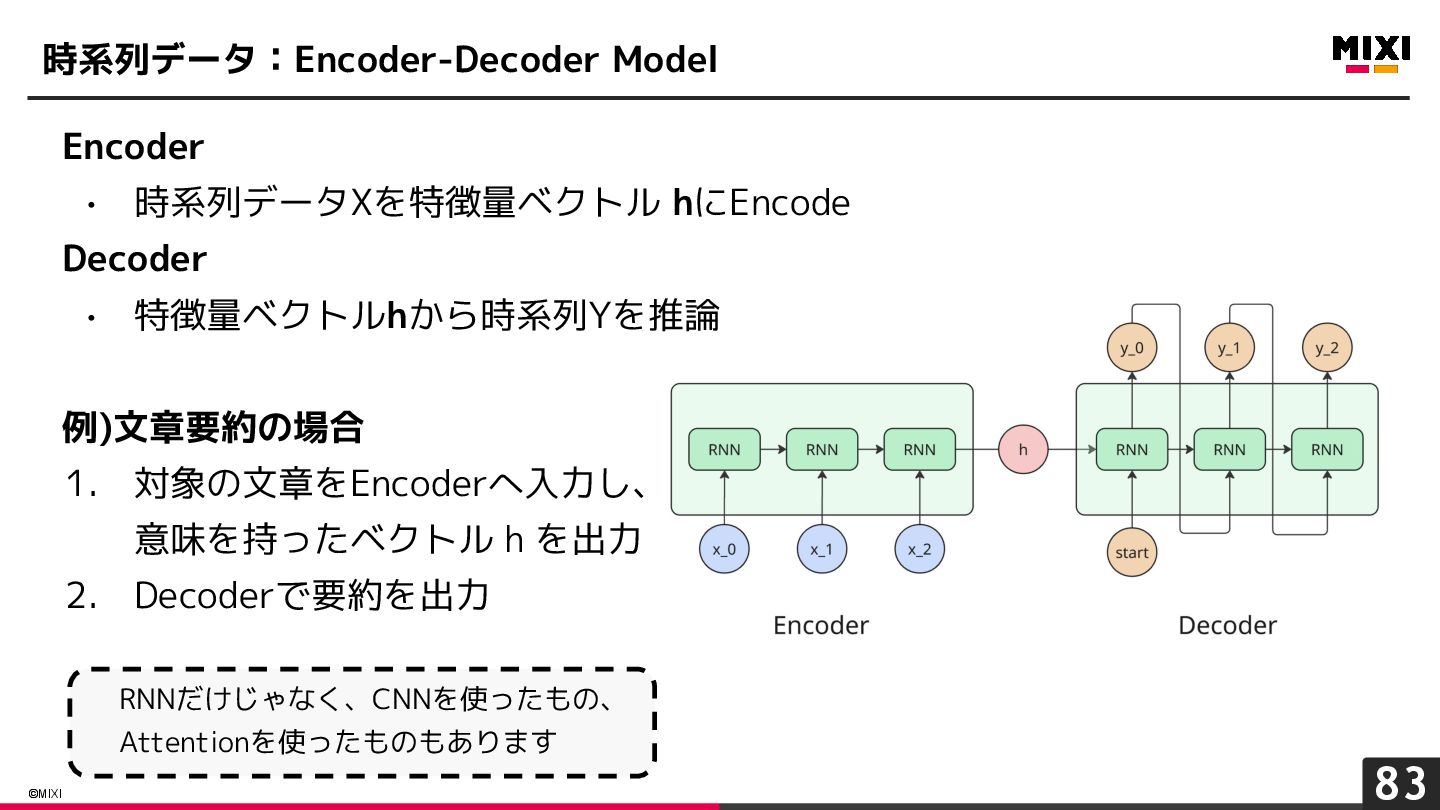{kind=link}
{kind=link}
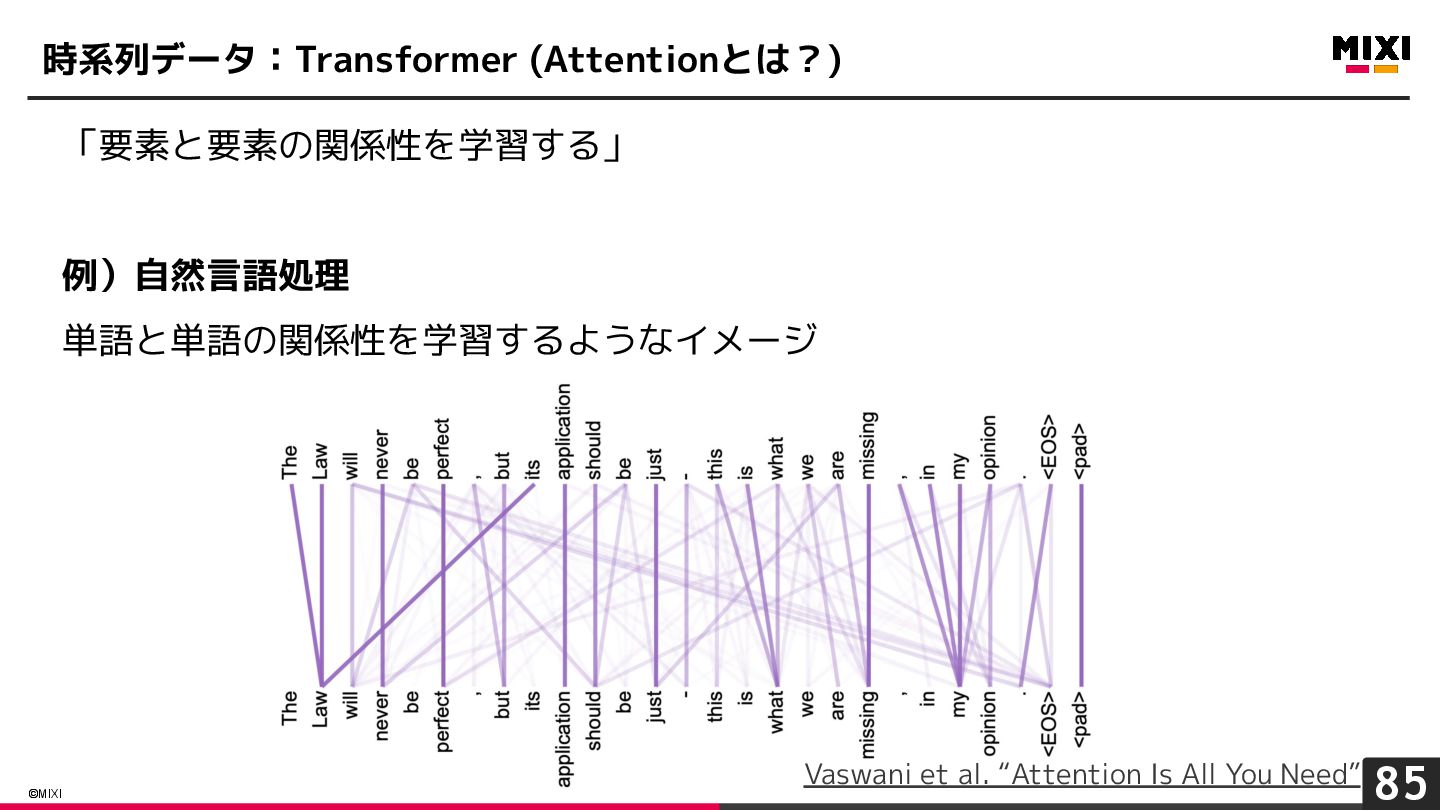{kind=link}
{kind=link}
{kind=link}
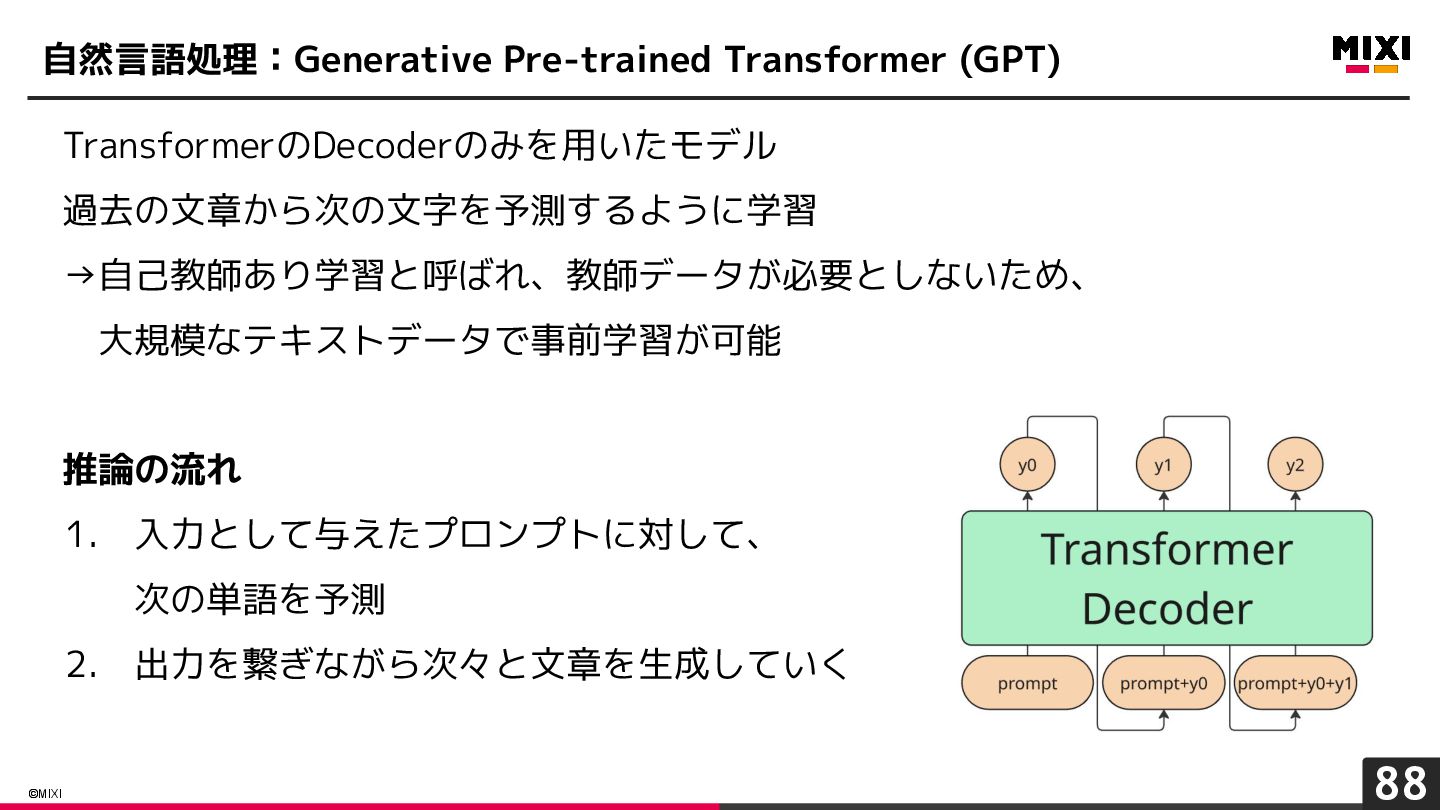{kind=link}
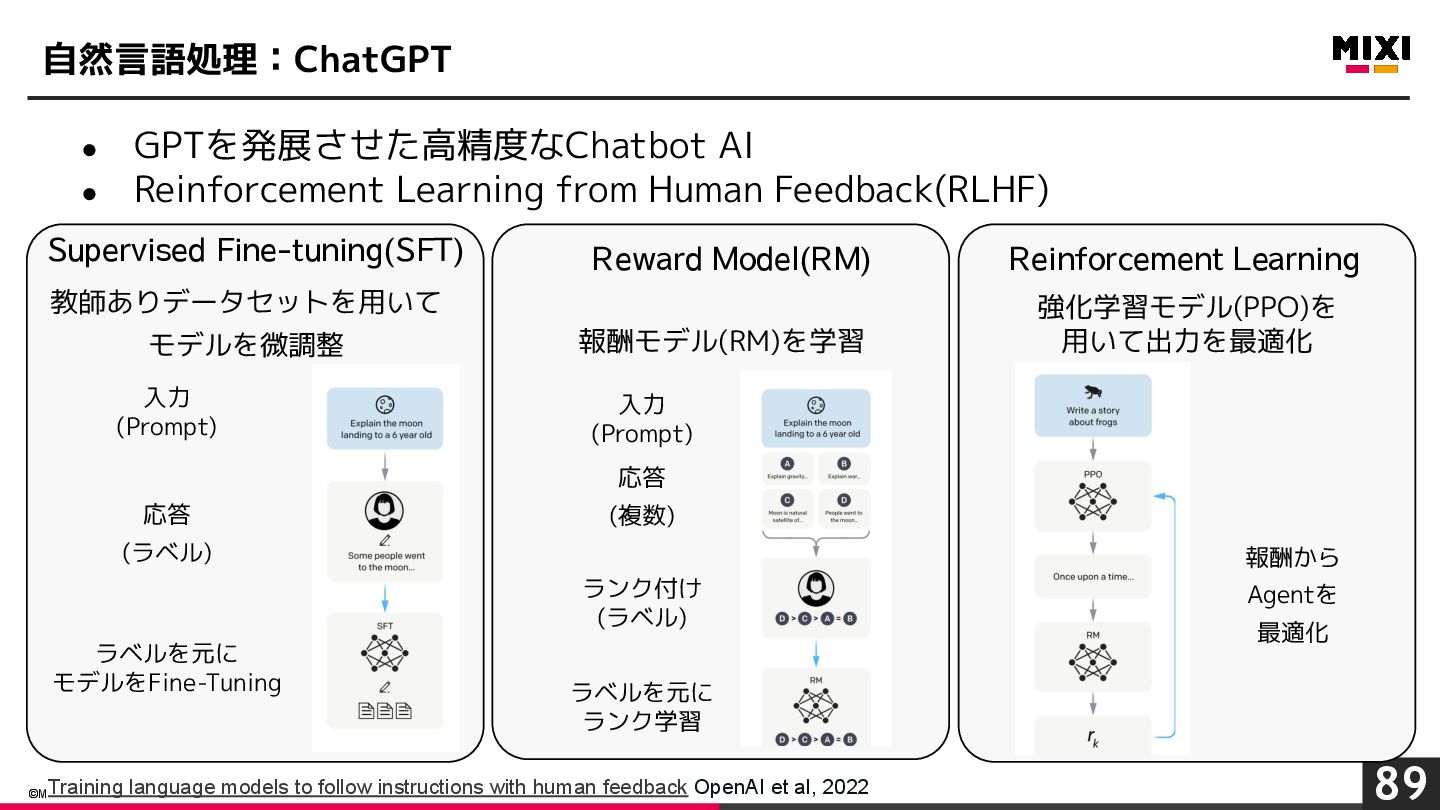{kind=link}
{kind=link}
![©MIXI 91 [余談] MIXIで使えるLLMサービス Chatサービス - Chat-M (MIXI) : MIXIの社内向け](https://files.speakerdeck.com/presentations/b7b000c1c83e4238ba1fed7ca211d834/slide_90.jpg){kind=link}
{kind=link}
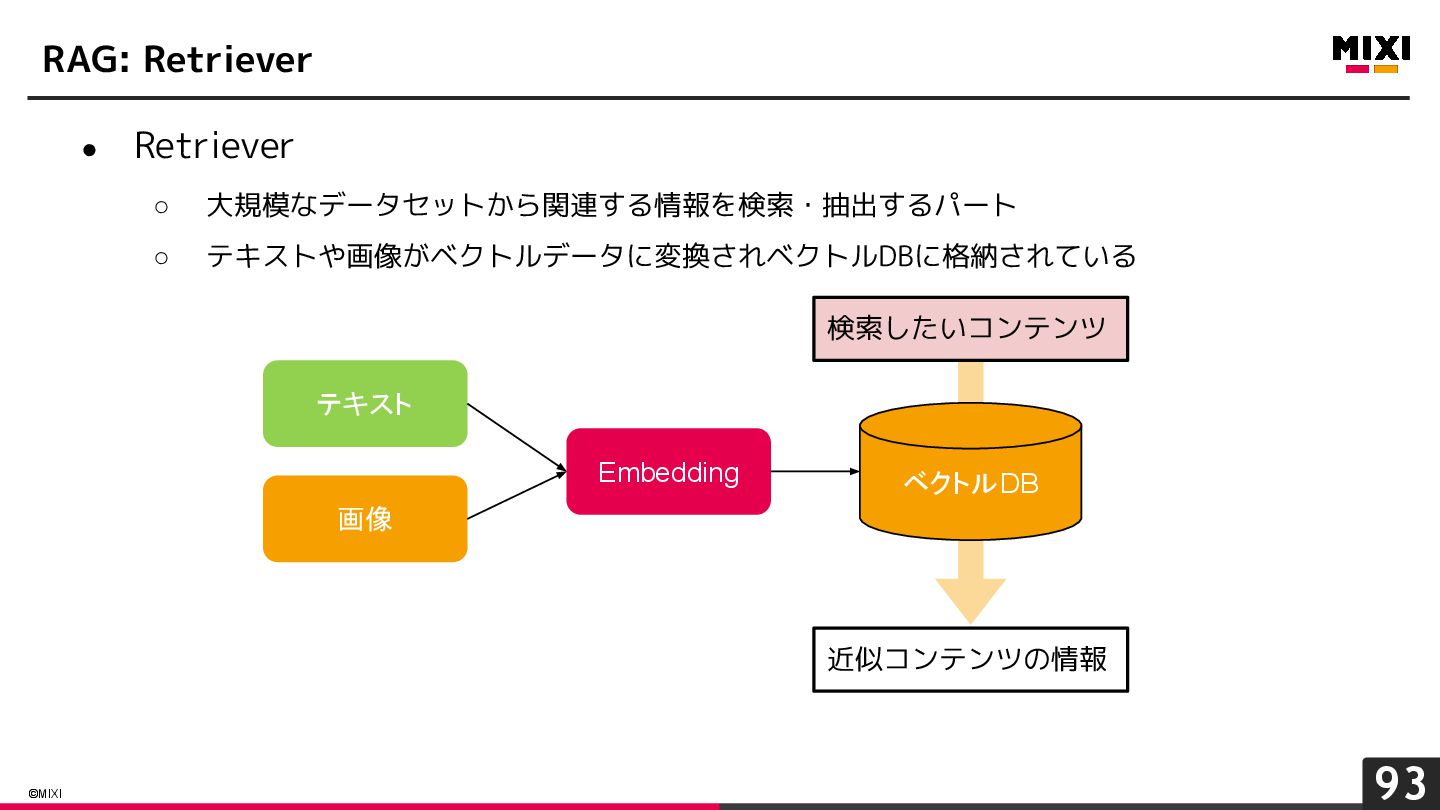{kind=link}
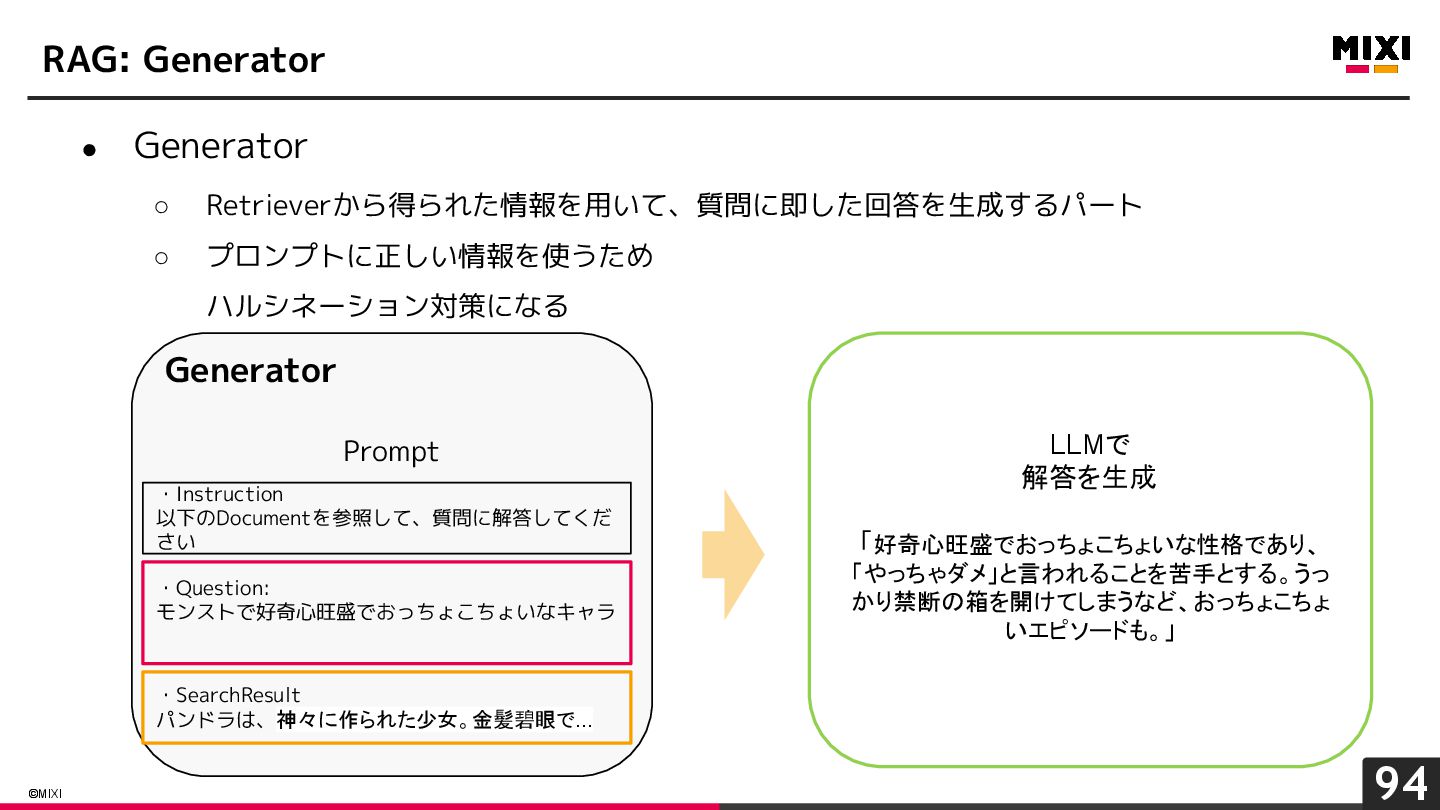{kind=link}
{kind=link}
{kind=link}
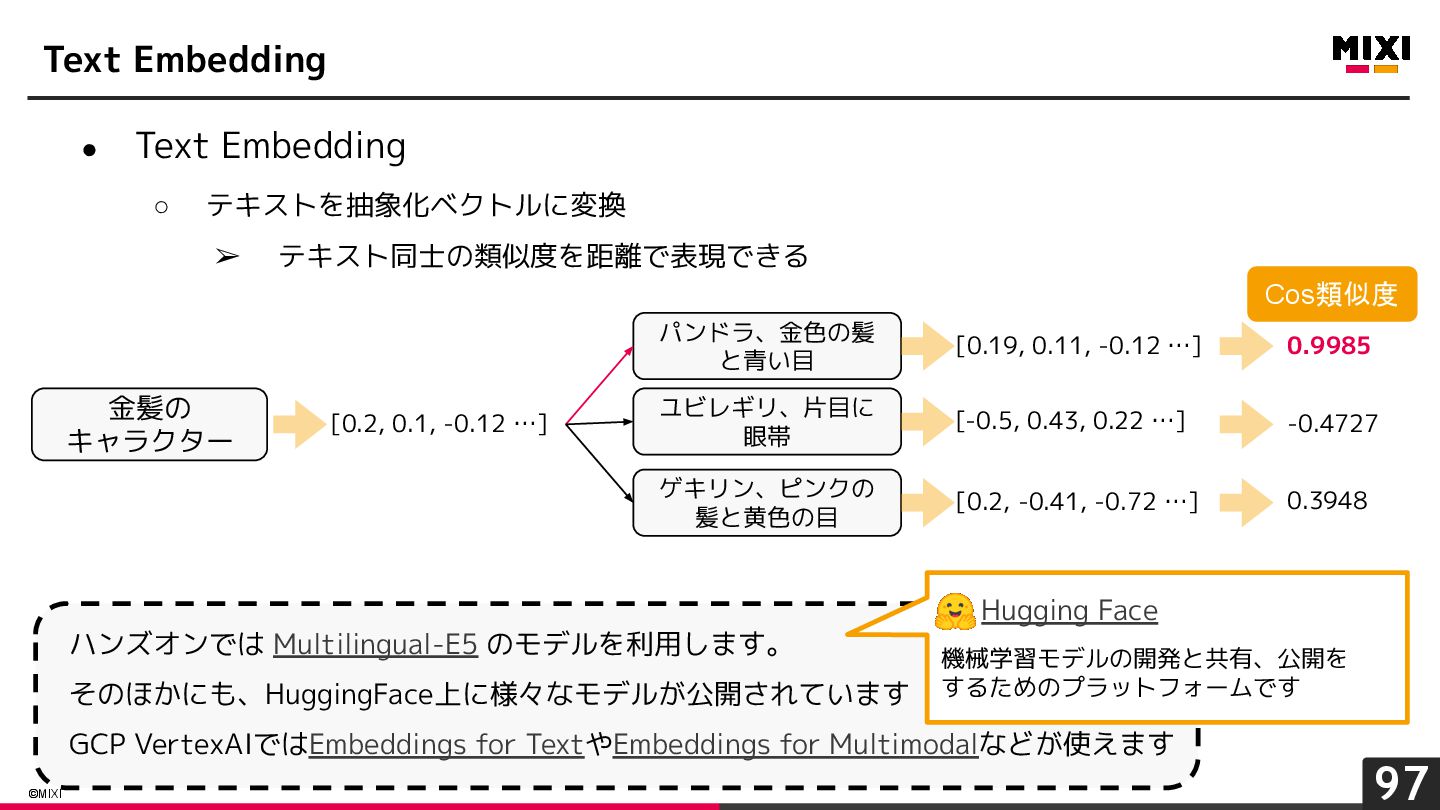{kind=link}
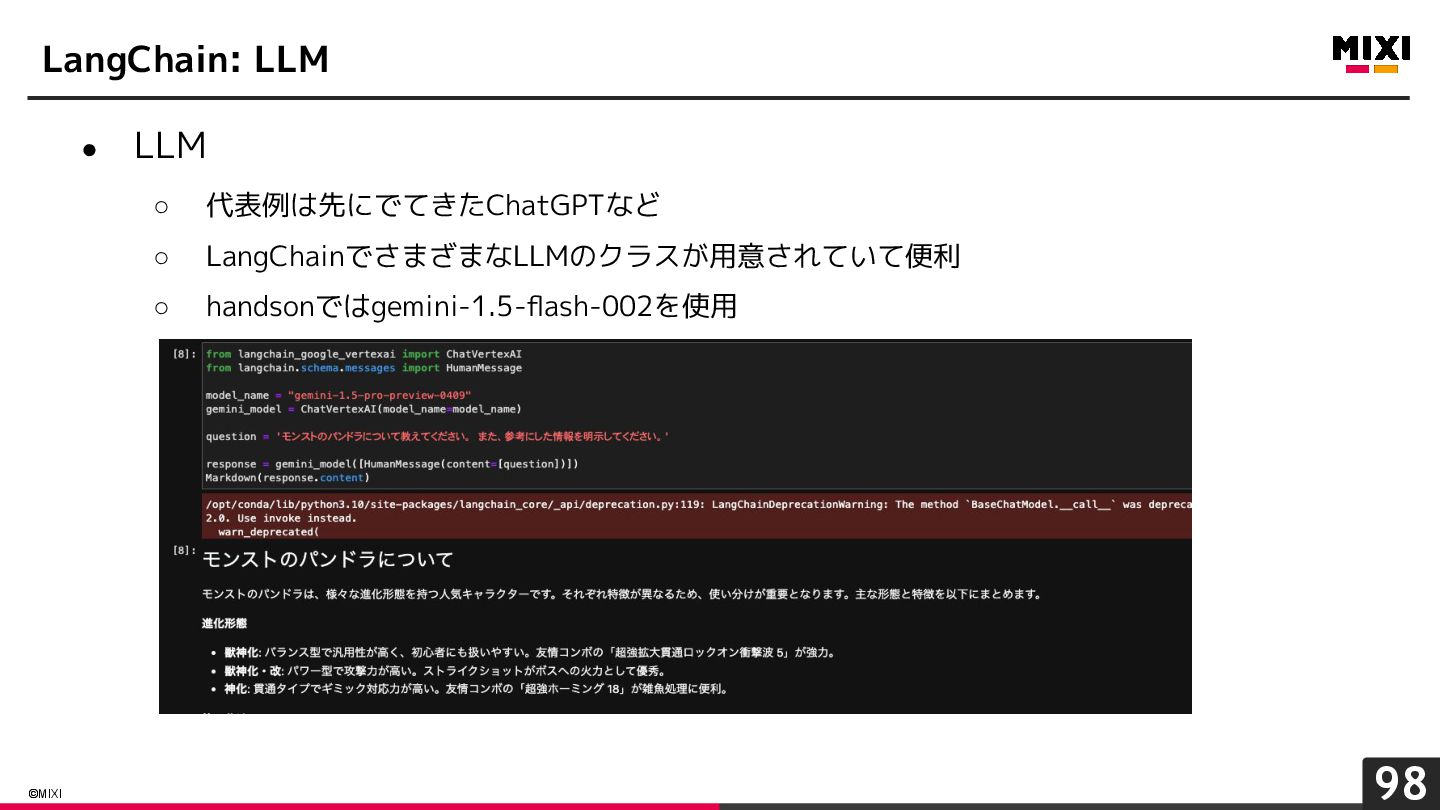{kind=link}
{kind=link}
{kind=link}
{kind=link}
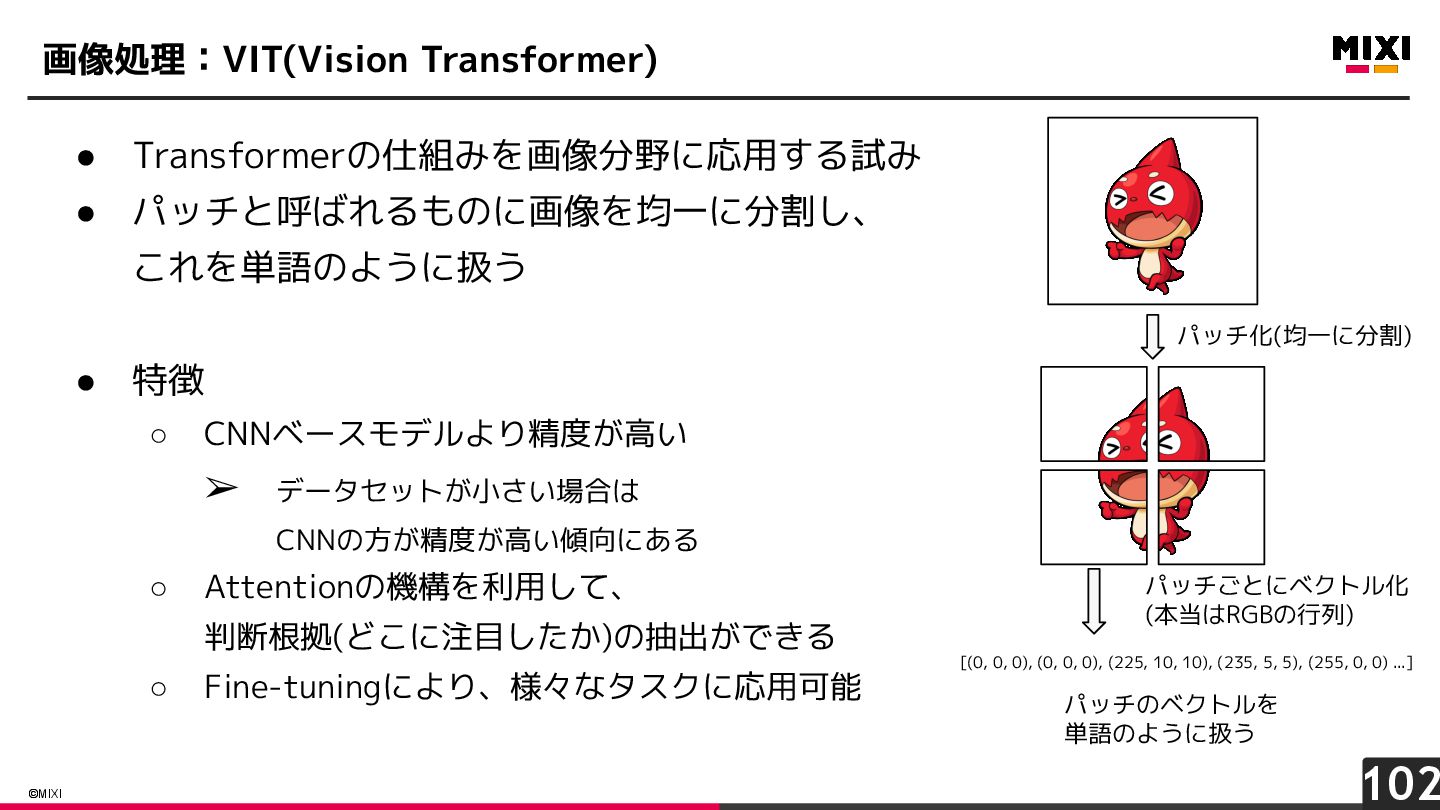{kind=link}
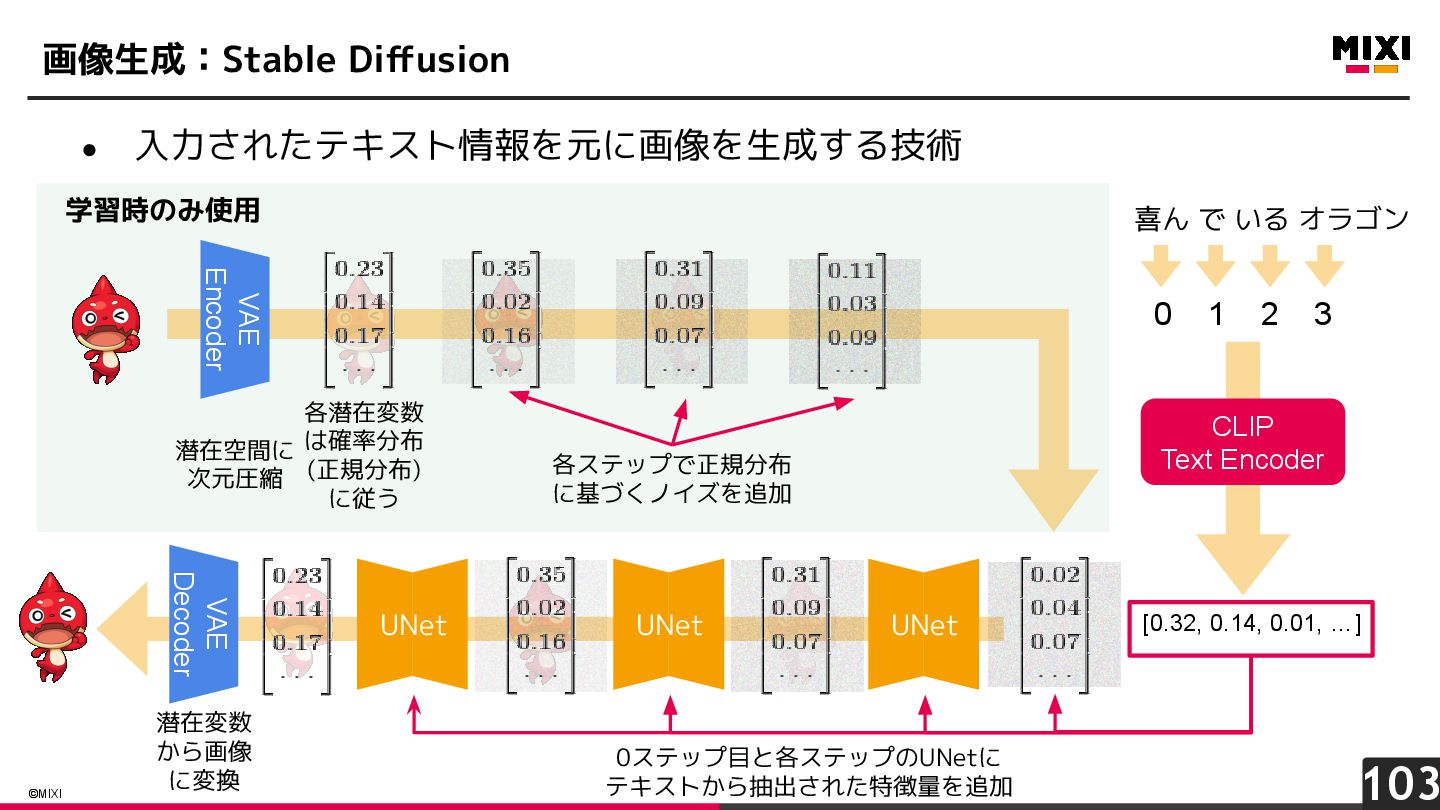{kind=link}
{kind=link}
{kind=link}
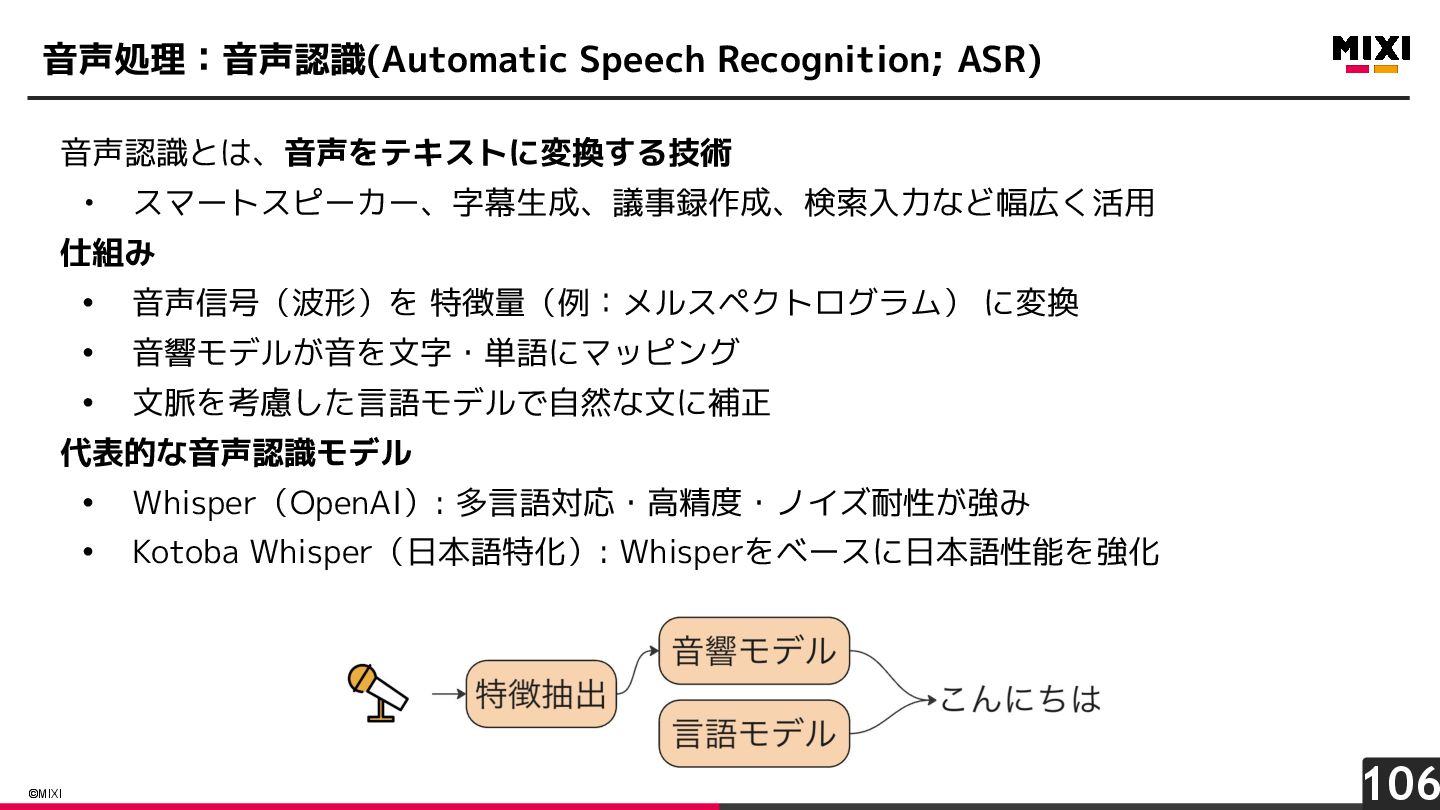{kind=link}
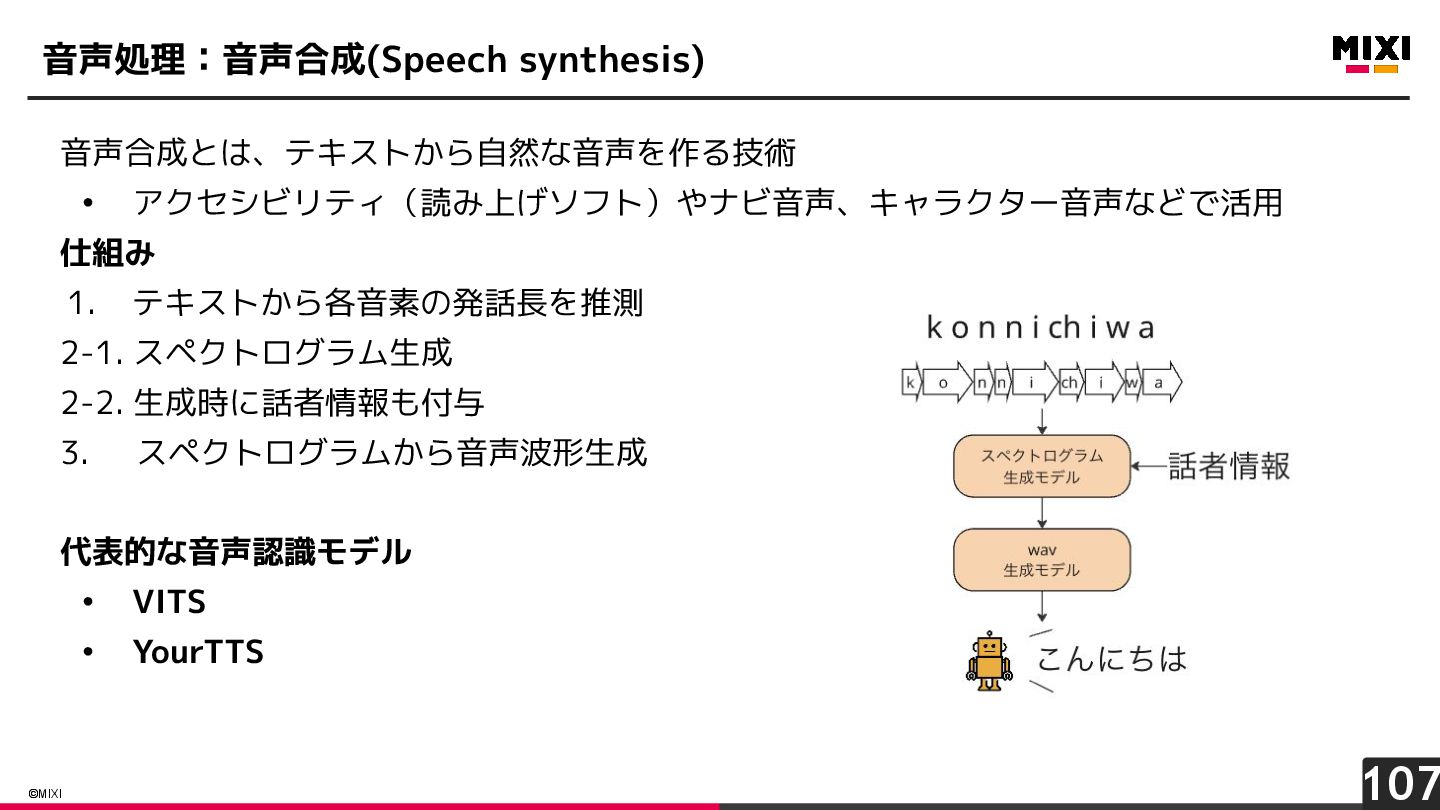{kind=link}
{kind=link}
{kind=link}
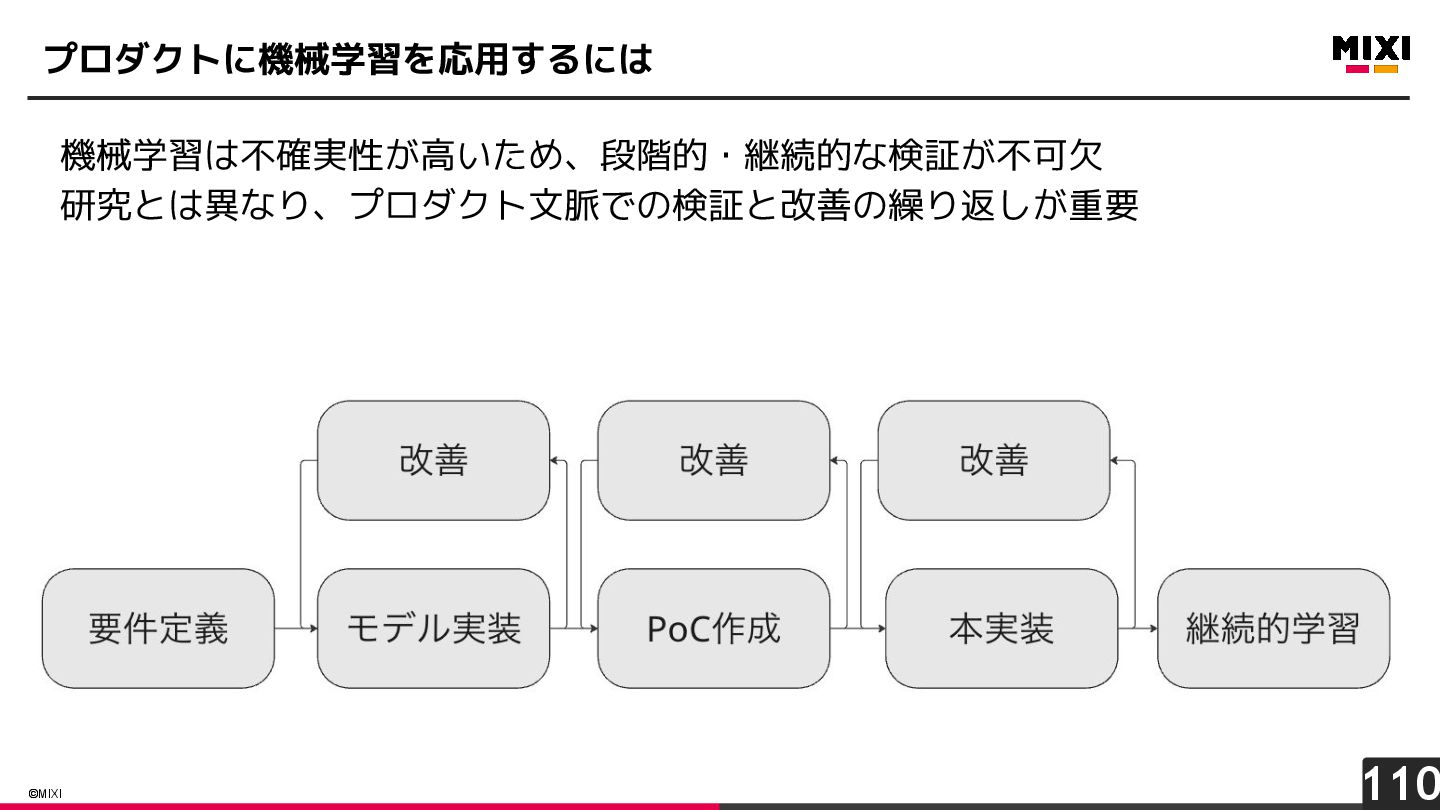{kind=link}
{kind=link}
{kind=link}
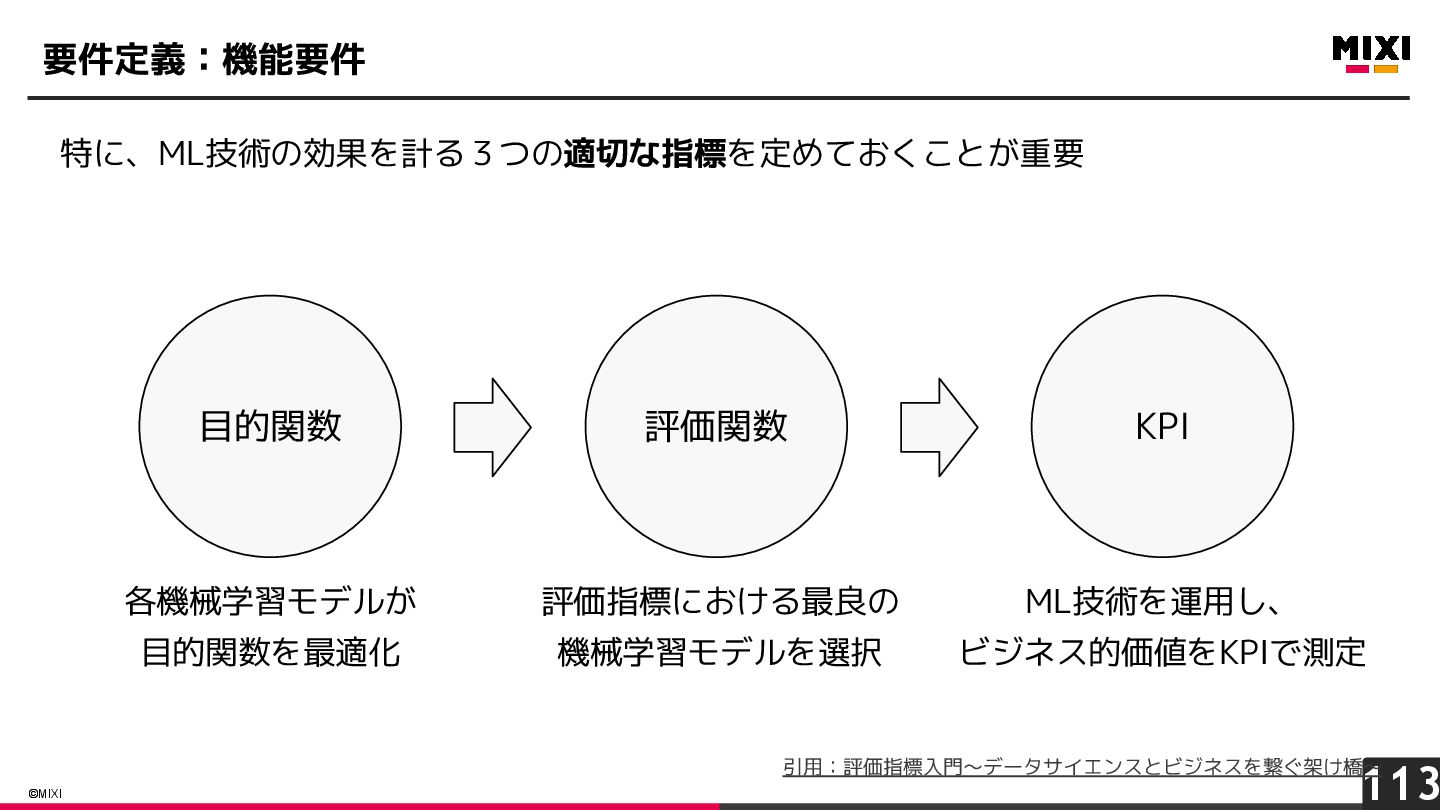{kind=link}
{kind=link}
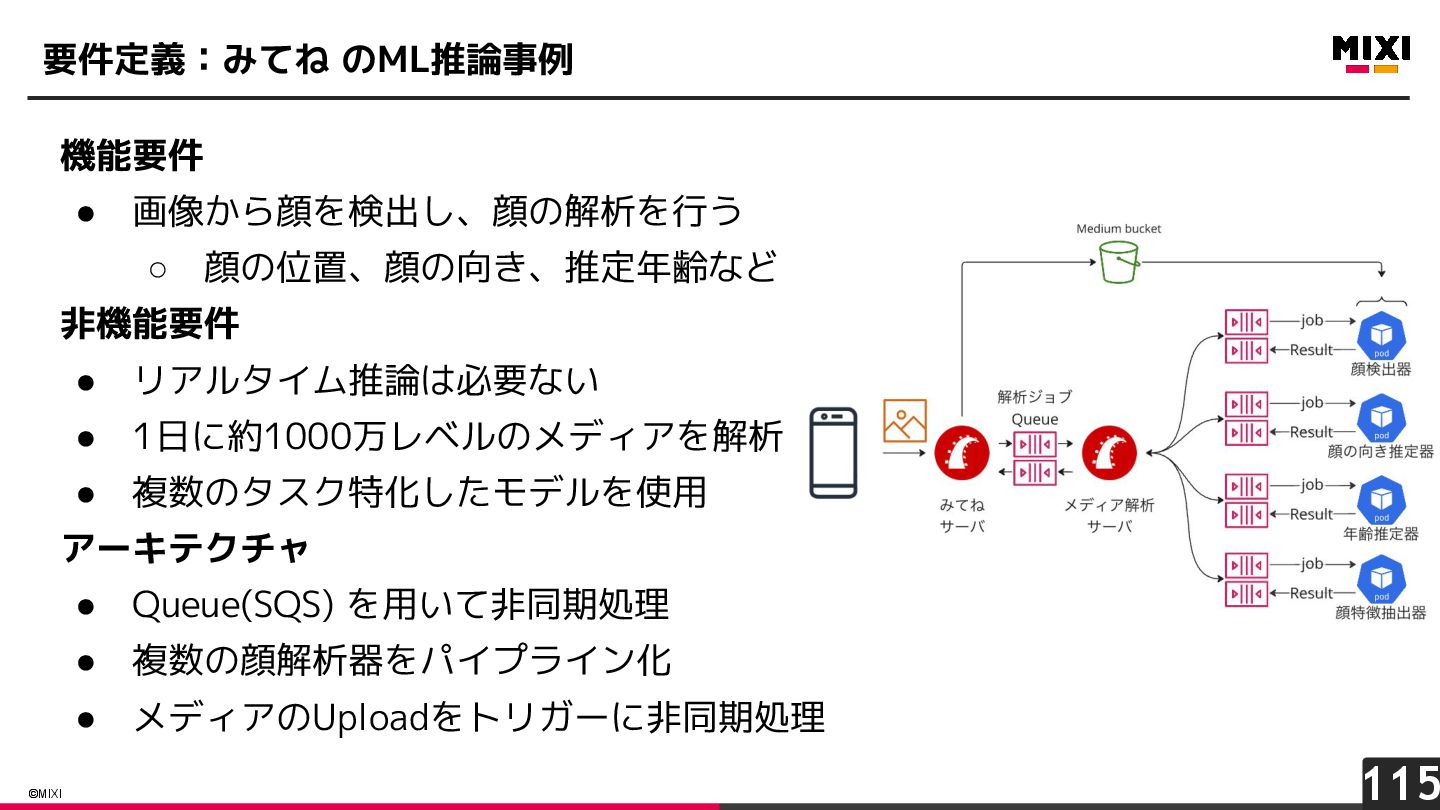{kind=link}
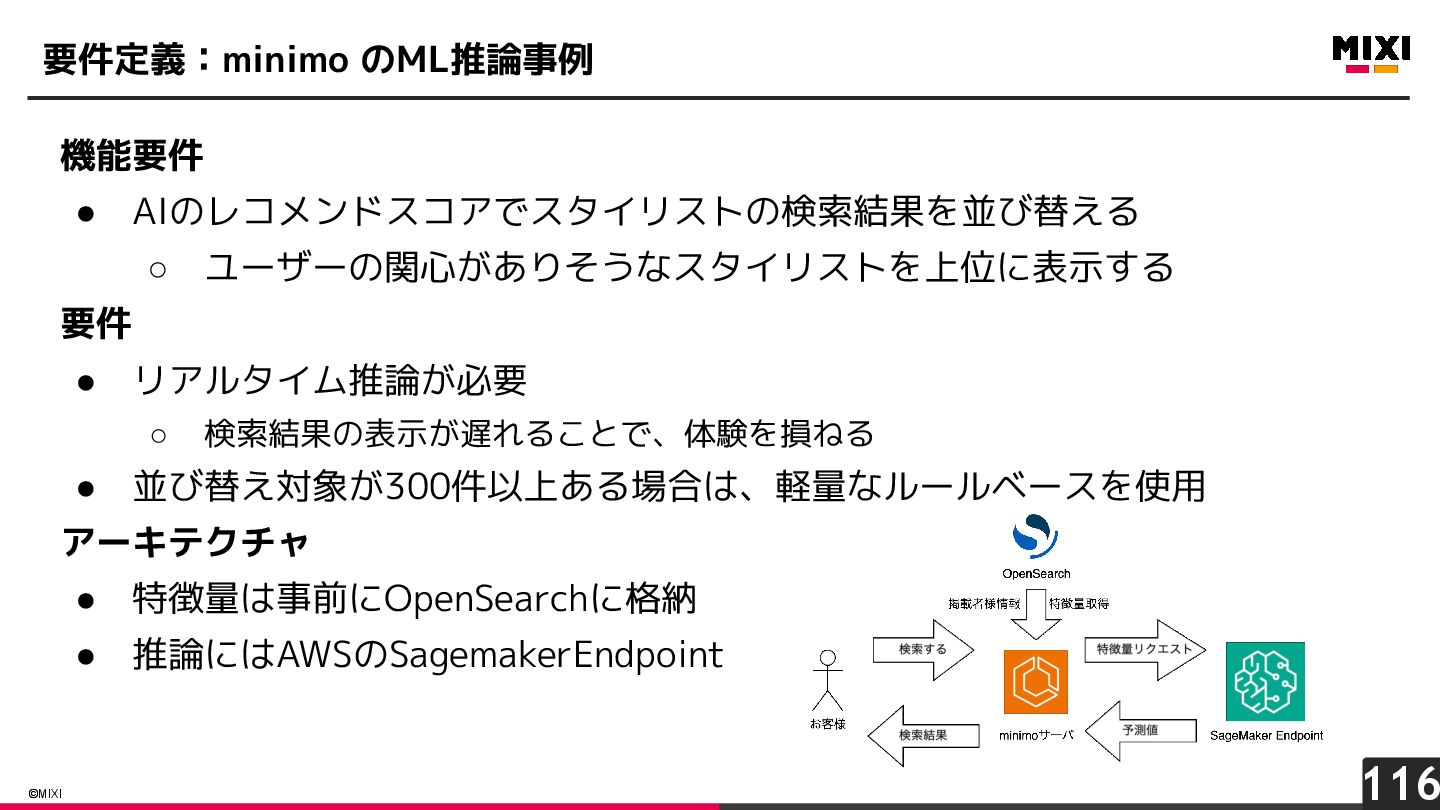{kind=link}
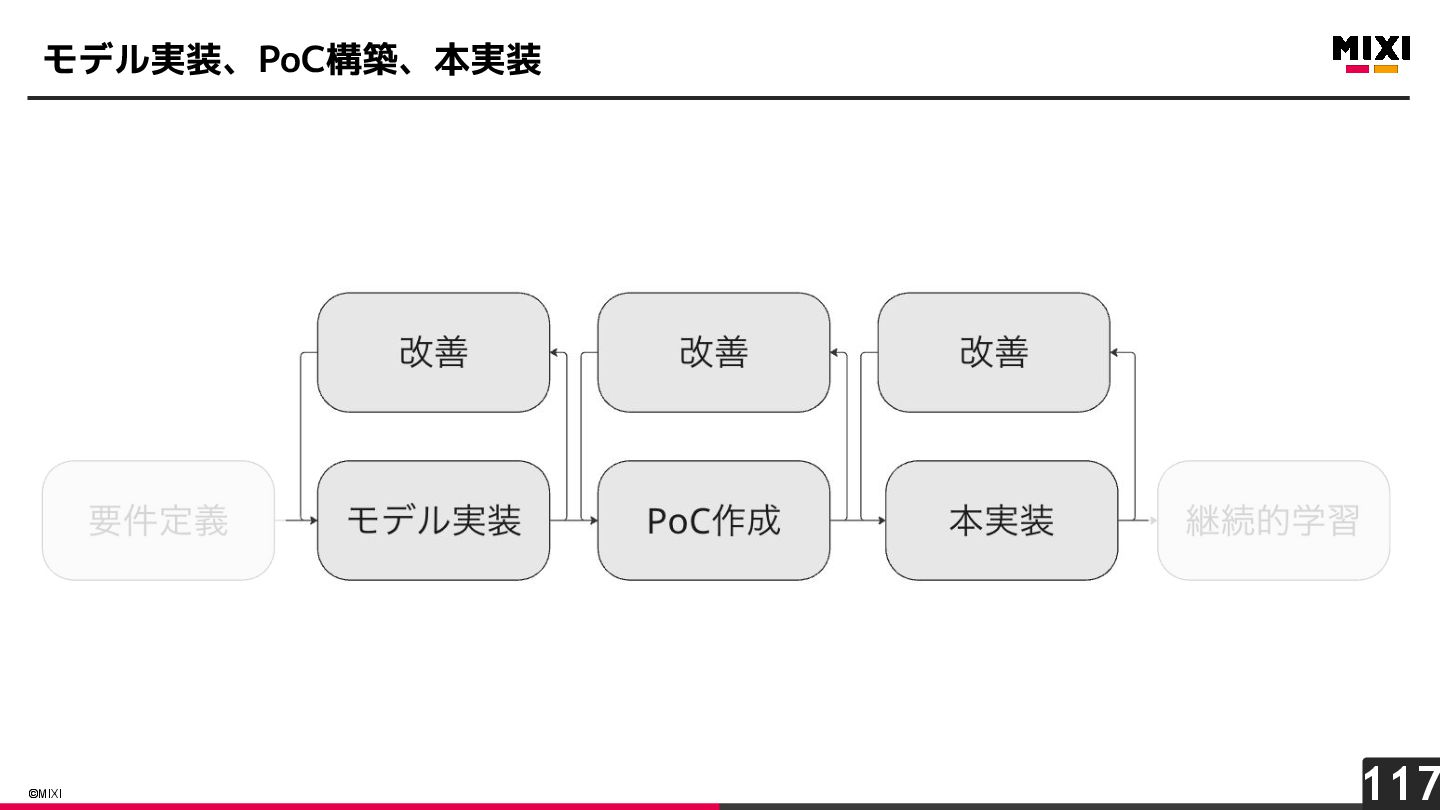{kind=link}
{kind=link}
{kind=link}
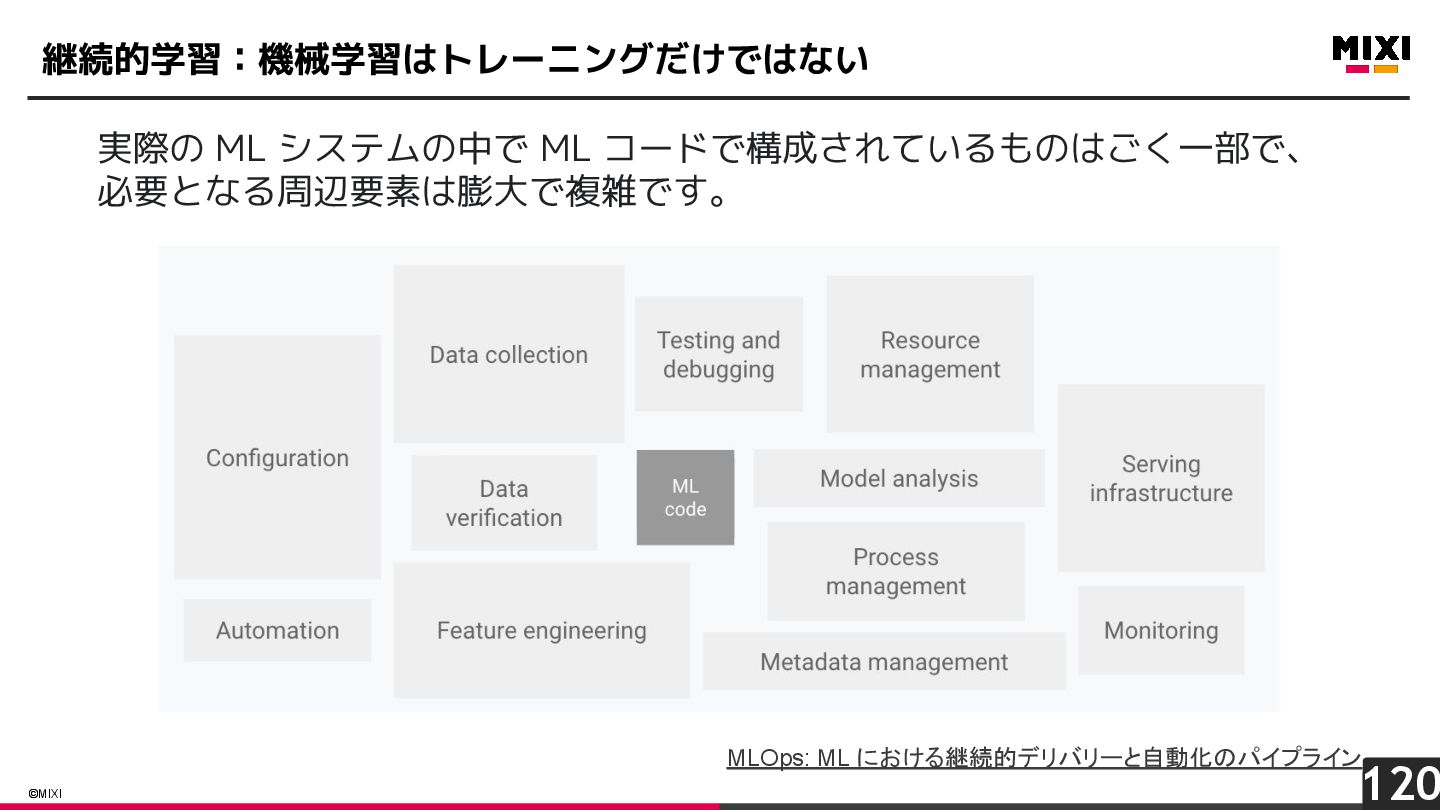{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}