Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
メルカリにおけるデータアナリティクス AI エージェント「Socrates」と ADK 活用事例
Search
na0
June 10, 2025
Technology
36k
29
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
メルカリにおけるデータアナリティクス AI エージェント「Socrates」と ADK 活用事例
NotebookLM:
https://notebooklm.google.com/notebook/98dd8491-4fbb-4614-9368-cd3427db716e
na0
June 10, 2025
More Decks by na0
See All by na0
データエージェントのためのナレッジカタログ
na0
4
3.7k
データ活用 3.0 with Socrates
na0
2
2.2k
AI 時代のデータ戦略
na0
8
6.3k
adk-samples に学ぶデータ分析 LLM エージェント開発
na0
3
1.8k
BigQuery でできること、人間がやるべきこと
na0
0
1.4k
データ分析エージェント Socrates の育て方
na0
10
6.9k
AI エージェントと考え直すデータ基盤
na0
26
13k
BigQuery リリースノート - 2023年上半期 #bq_sushi
na0
3
530
2023 年の BigQuery 権限管理
na0
5
3.4k
Other Decks in Technology
See All in Technology
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
2.8k
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.3k
AIペネトレーションテスト・ セキュリティ検証「AgenticSec」紹介資料
laysakura
2
8.1k
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
550
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.6k
AIで政治は変わるのか? — 中高生と考えたAI時代の民主主義(東海高校サタデープログラム)
eitarosuda
0
400
CSに"SLO"は要らない、経営層に"99.9%"は伝わらない - SREを全社に"翻訳"する3原則
cscengineer
PRO
0
3.6k
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
1.6k
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
180
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
400
デジタル・デザイン:次の50年を描く「進化する青写真」
y150saya
0
840
フルカイテン株式会社 エンジニア向け採用資料
fullkaiten
0
11k
Featured
See All Featured
HDC tutorial
michielstock
2
730
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
350
Designing for Timeless Needs
cassininazir
1
280
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Transcript
1 メルカリにおけるデータアナリティクス AI エージェント「Socrates」と ADK 活⽤事例 Naofumi Yamada (@na0fu3y) 2025-06-10
2 注意書き • この資料は意図的に⼤量の⽂字で構成されています ◦ Google NotebookLM を使って探索することを想定しています ▪ Mind
Map を使って構成を⾒ながら、資料と対話できます
3 Agent Engineer / Mercari BI Product Google Developer Expert
(Google Cloud) Naofumi Yamada @na0fu3y
あらゆる価値を循環させ、あらゆる人の可能性を広げる “Circulate all forms of value to unleash the
potential in all people” 4 グループミッション
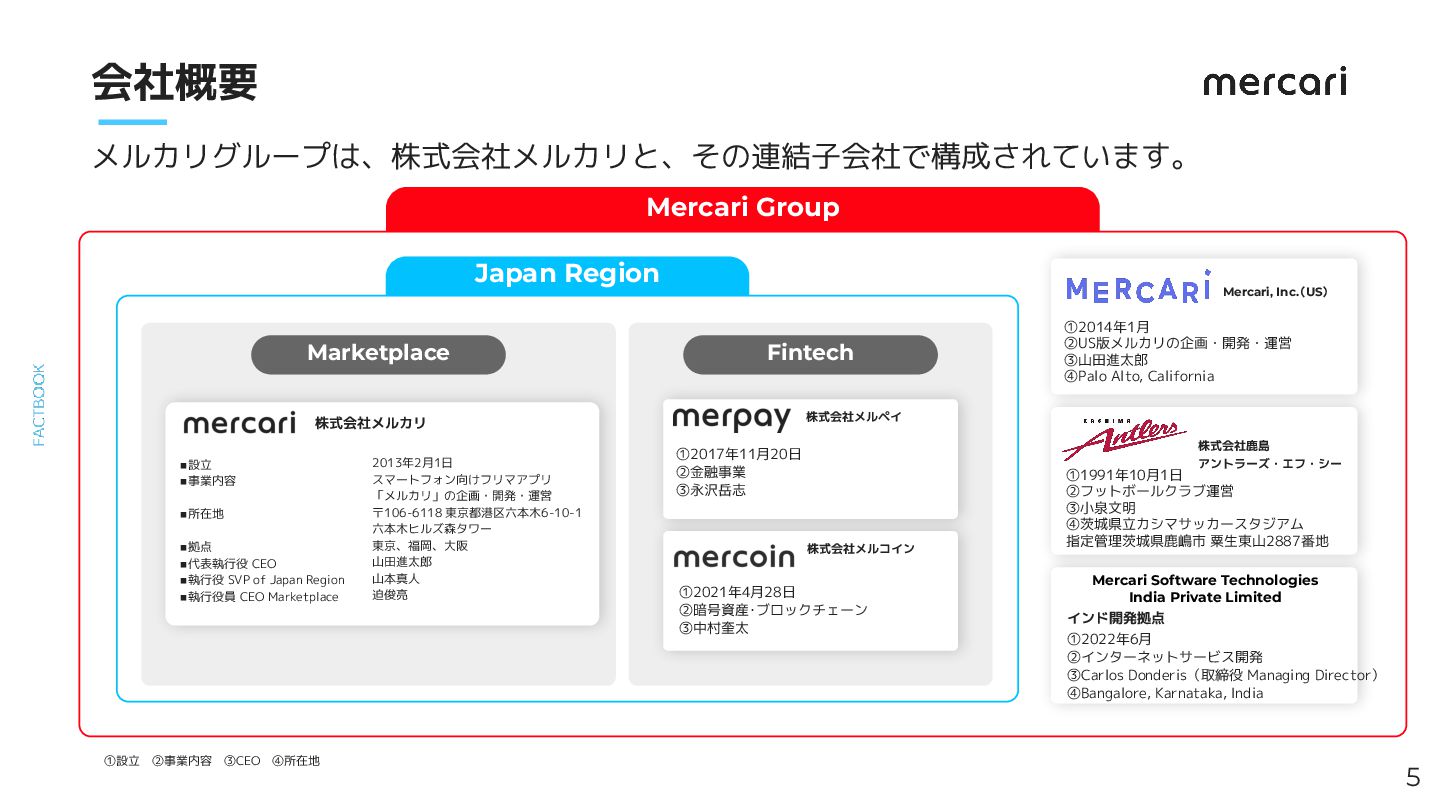
Japan Region Mercari Group Fintech 5 会社概要 メルカリグループは、株式会社メルカリと、その連結子会社で構成されています。 Marketplace
株式会社メルカリ ◼設立 ◼事業内容 ◼所在地 ◼拠点 ◼代表執行役 CEO ◼執行役 SVP of Japan Region ◼執行役員 CEO Marketplace 2013年2月1日 スマートフォン向けフリマアプリ 「メルカリ」の企画・開発・運営 〒106-6118 東京都港区六本木6-10-1 六本木ヒルズ森タワー 東京、福岡、大阪 山田進太郎 山本真人 迫俊亮 ①2017年11月20日 ②金融事業 ③永沢岳志 株式会社メルペイ ①2014年1月 ②US版メルカリの企画・開発・運営 ③山田進太郎 ④Palo Alto, California Mercari, Inc.(US) ①1991年10月1日 ②フットボールクラブ運営 ③小泉文明 ④茨城県立カシマサッカースタジアム 指定管理茨城県鹿嶋市 粟生東山2887番地 株式会社鹿島 アントラーズ・エフ・シー インド開発拠点 ①2022年6月 ②インターネットサービス開発 ③Carlos Donderis(取締役 Managing Director) ④Bangalore, Karnataka, India Mercari Software Technologies India Private Limited ①2021年4月28日 ②暗号資産・ブロックチェーン ③中村奎太 株式会社メルコイン ①設立 ②事業内容 ③CEO ④所在地
2013年2月1日 会社設立日 東京、福岡、大阪 Palo Alto、Bangalore オフィス 2,190名(連結) 従業員数 6
株式会社メルカリ 概要
7 エンタープライズ AI エージェント開発の実践知を共有 本⽇のゴール Google ADK の可能性を Socrates を例として実感
AI エージェントプロジェクト推進へのヒントと刺激を提供 02 03 01
8 アジェンダ 〜Socrates 開発と ADK 活⽤の物語〜 1. 【挑戦】メルカリのデータ活⽤課題と Socrates 誕⽣
2. 【Socrates 詳解】データアナリティクス AI エージェントの全貌 3. 【背景理解】なぜ AI エージェントなのか? なぜ⾃社開発なのか? 4. 【道具】Google ADK 登場と Socrates アーキテクチャ 5. 【学びの軌跡】技術選定とエコシステム構築の戦略 6. 【実践知】エンタープライズ AI エージェント運⽤のリアル 7. 【未来展望】ADK の進化への期待 8. 【まとめ】成功の鍵と教訓
9 1. 【挑戦】メルカリのデータ活⽤課題 と Socrates 誕⽣ メルカリが抱えていた課題と データアナリティクス AI エージェント「Socrates」開発の背景
10 メルカリが直⾯していたデータ活⽤の壁 (1/2) • 「データの宝庫」メルカリ: 膨⼤なお客様の⾏動、取引、商品データ。ま さにビジネス成⻑の源泉。 • しかし、活⽤への「壁」: ◦
SQL やデータ構造の専⾨知識の必要性: データの発⾒ / 権限申請 / 構 造理解が容易ではない。 ◦ データアナリストのボトルネック化: 分析依頼への対応に時間がかか り、意思決定の遅延や機会損失が発⽣。
11 メルカリが直⾯していたデータ活⽤の壁 (2/2) • 直⾯していた具体的な課題: ◦ データ分析の属⼈化‧サイロ化: 特定アナリストへの問い合わせ集 中、分析ノウハウ共有の困難さ。 ◦
定型業務の負荷: 定型的なデータ抽出‧可視化作業にアナリストの時 間が割かれる。 ◦ 探索的分析への時間不⾜: 要因深掘り、仮説検証、施策効果測定など の複雑な分析に⼗分な時間を割けない。 ◦ ビジネスサイドのデータアクセス障壁: SQL の習熟が必要で、⾮専⾨ 家にはハードルが⾼い。結果、データに基づいた迅速な意思決定が阻 害されることも。 • 「誰もが、もっと⼿軽に、データと対話できたら?」
12 Socrates 構想:AI による分析⽀援への期待 • Socrates 構想 ◦ 「優秀なデータアナリストと対話するかのように、誰もが⾃然⾔語で データと会話し、必要な情報を引き出し、洞察を得られる仕組み」
• AI による分析⽀援への期待と、従来の LLM 単体アプローチの限界認識 ◦ 単純な Text2SQL + ⼀問⼀答では、実務の複雑なプロセスに対応困難 ◦ 参考: 1⽇50万件貯まるクエリのログを活かして、SQLの⽣成に挑戦し ている話 - Speaker Deck
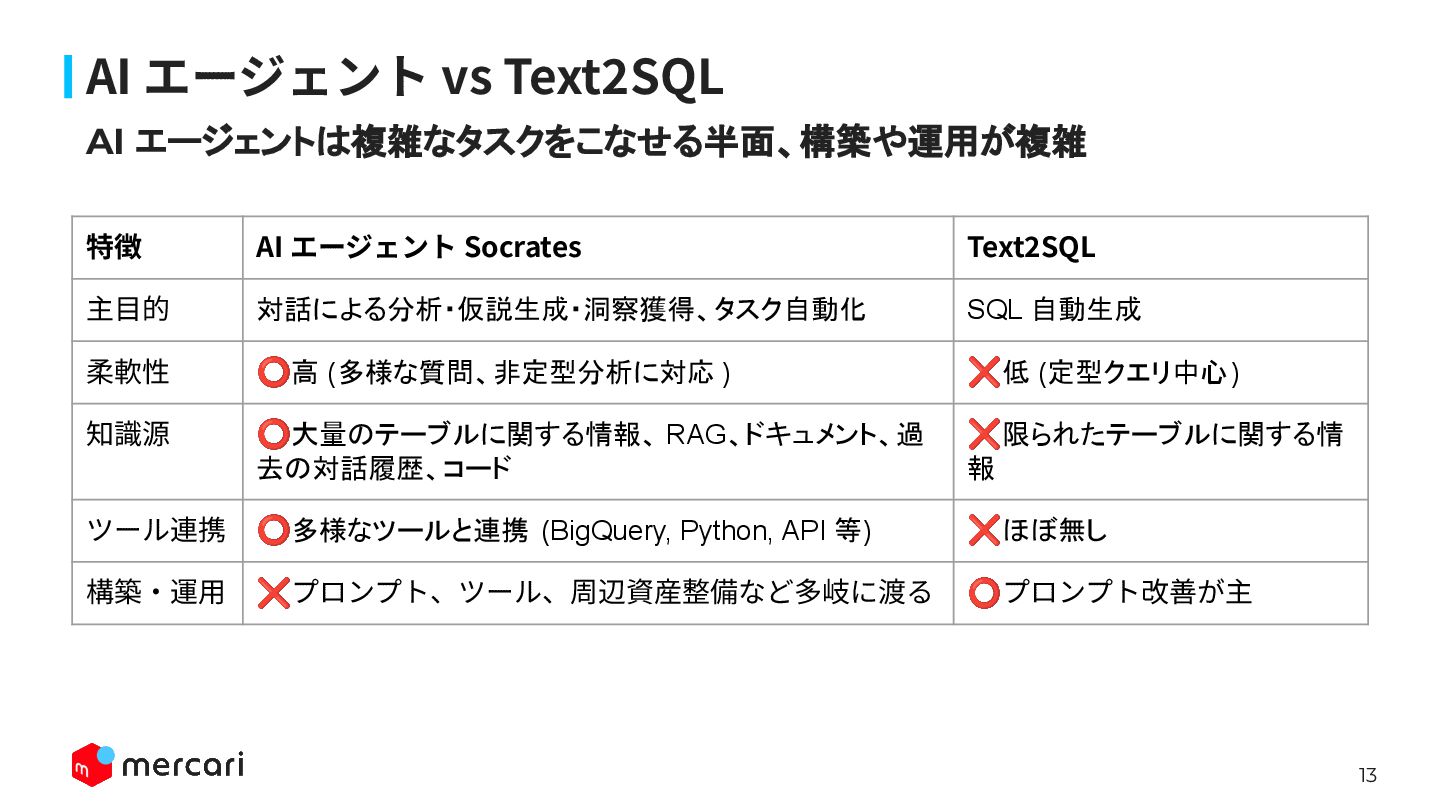
13 AI エージェント vs Text2SQL 特徴 AI エージェント Socrates Text2SQL
主⽬的 対話による分析・仮説生成・洞察獲得、タスク自動化 SQL 自動生成 柔軟性 ⭕高 (多様な質問、非定型分析に対応 ) ❌低 (定型クエリ中心) 知識源 ⭕大量のテーブルに関する情報、 RAG、ドキュメント、過 去の対話履歴、コード ❌限られたテーブルに関する情 報 ツール連携 ⭕多様なツールと連携 (BigQuery, Python, API 等) ❌ほぼ無し 構築‧運⽤ ❌プロンプト、ツール、周辺資産整備など多岐に渡る ⭕プロンプト改善が主 AI エージェントは複雑なタスクをこなせる半面、構築や運用が複雑
14 2. 【Socrates 詳解】データアナリ ティクス AI エージェントの全貌 Socrates が何を⽬指し、何ができるのか、その具体的な機能と動作イメージ
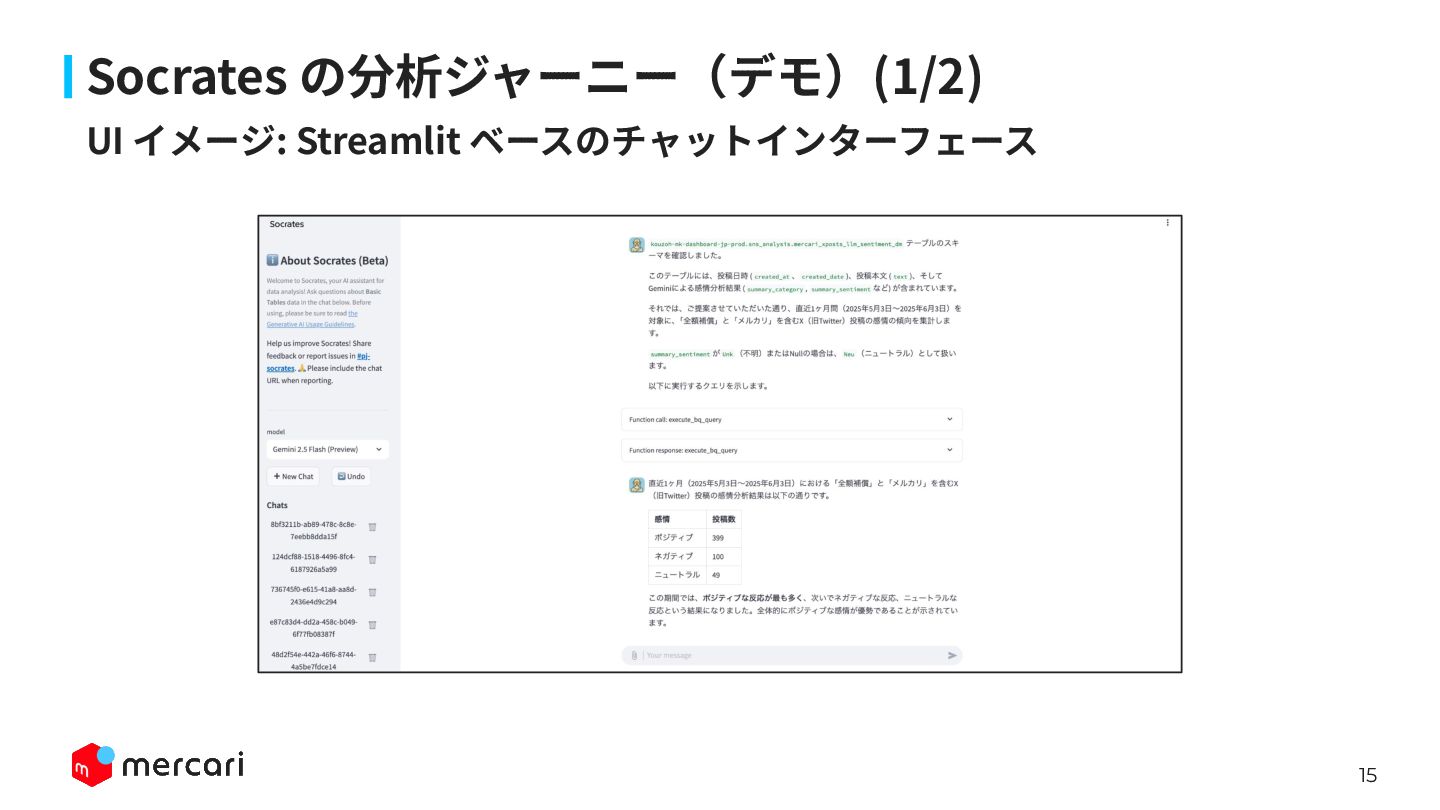
15 UI イメージ: Streamlit ベースのチャットインターフェース Socrates の分析ジャーニー(デモ)(1/2)
16 Socrates の分析ジャーニー(デモ)(2/2) • 具体的な対話例: ◦ 「先⽉の XX カテゴリの GMV
推移をグラフで教えて。理由も。」 ◦ 「GMVが急増した要因は?関連する可能性のある指標も教えて。」 ◦ 「メルカリの全額補償に関するプレスリリースの X(旧 Twitter)での 反応を教えて」
17 Socrates が実現する世界:⽬的と提供価値 • Socrates とは: データアナリストやビジネスユーザー(PdM、マーケター 等)向けの社内データアナリティクス AI エージェント。
• ⽬的 ◦ データ分析の⺠主化: 専⾨知識の有無によらず、誰もがデータにアク セスし、洞察を得られるように。 ◦ 意思決定の迅速化: 分析にかかる時間を⼤幅に短縮。 ◦ データドリブンな⽂化醸成: データに基づく議論と⾏動を促進。
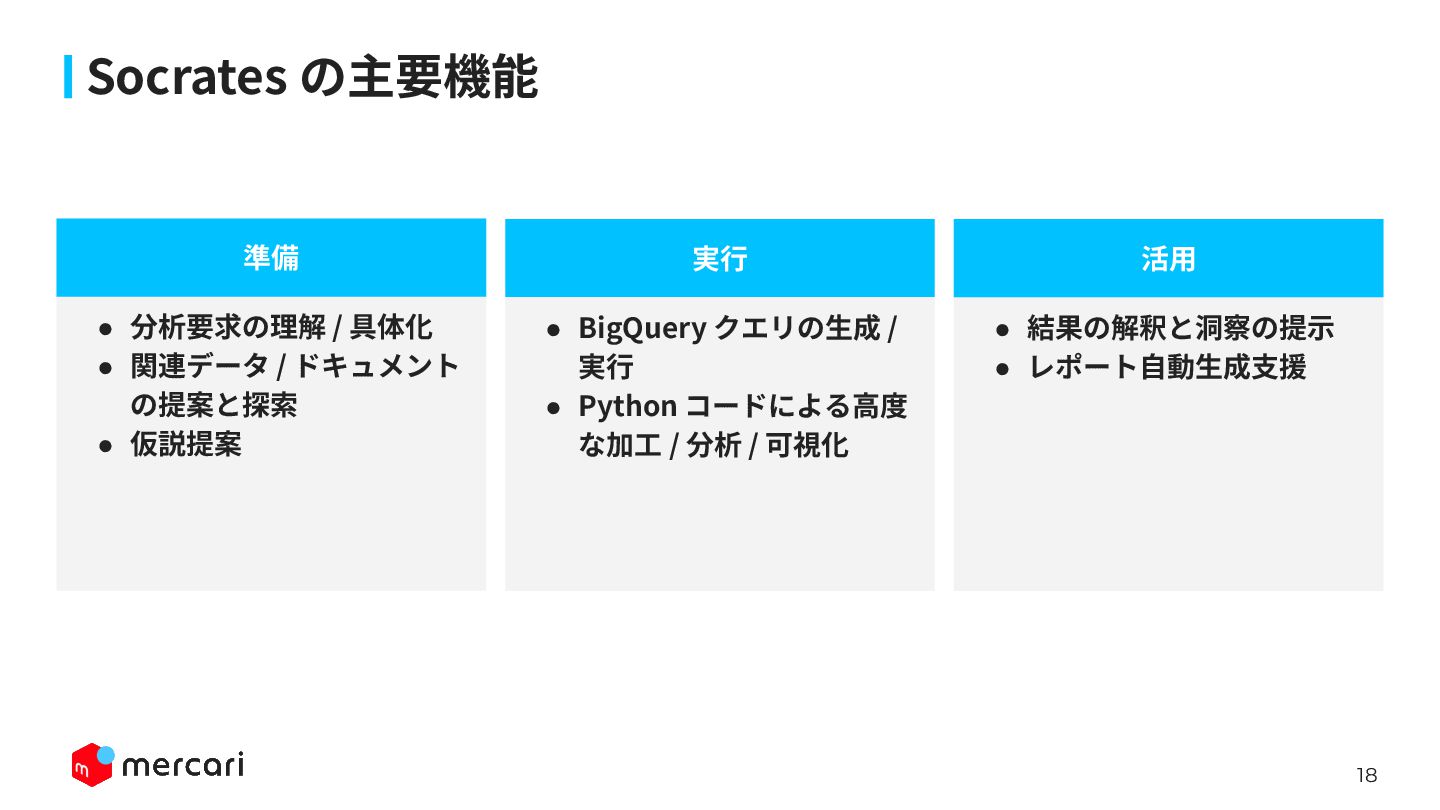
18 Socrates の主要機能 ⾒出し 実⾏ 準備 • 分析要求の理解 / 具体化
• 関連データ / ドキュメント の提案と探索 • 仮説提案 • BigQuery クエリの⽣成 / 実⾏ • Python コードによる⾼度 な加⼯ / 分析 / 可視化 • 結果の解釈と洞察の提⽰ • レポート⾃動⽣成⽀援 活⽤
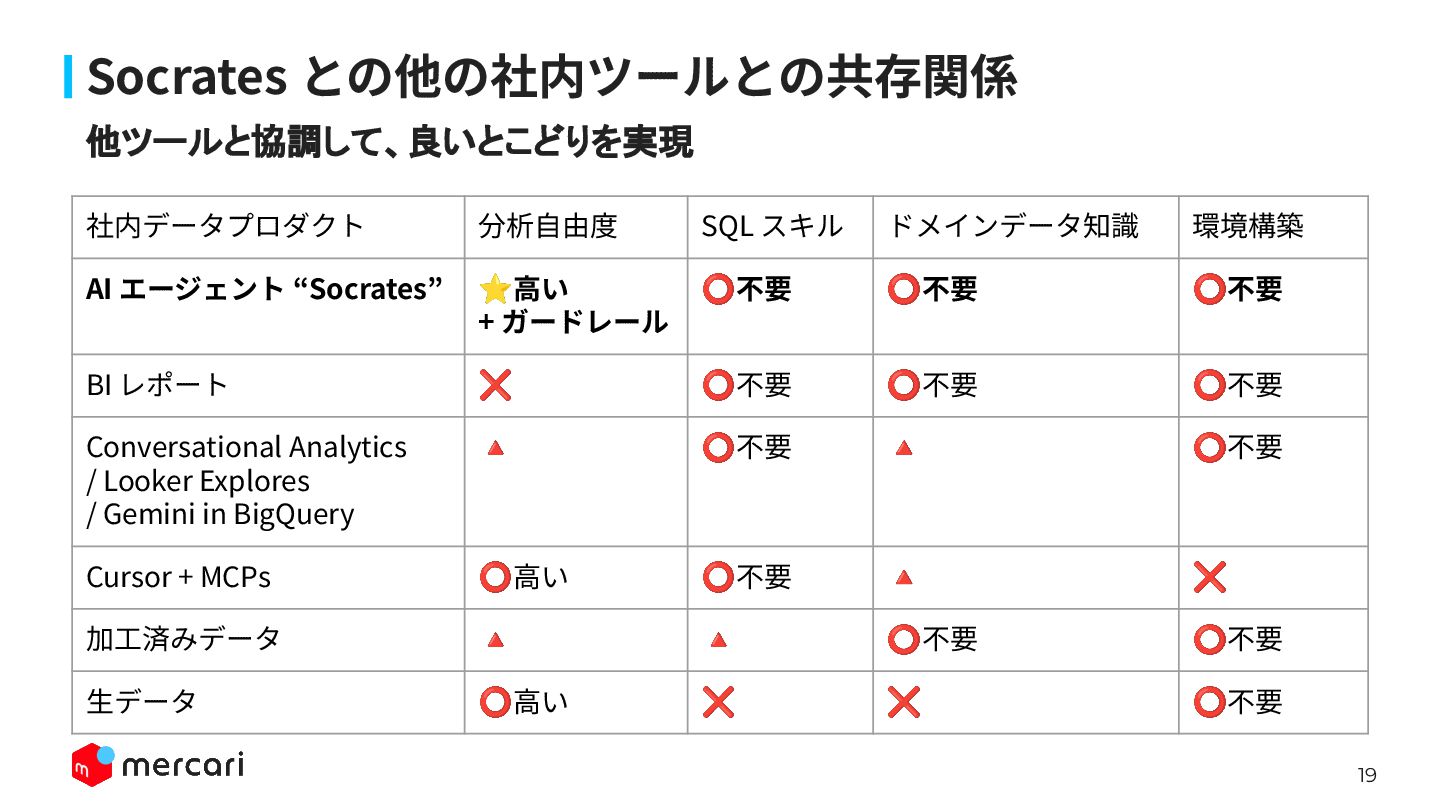
19 他ツールと協調して、良いとこどりを実現 Socrates との他の社内ツールとの共存関係 社内データプロダクト 分析⾃由度 SQL スキル ドメインデータ知識 環境構築
AI エージェント “Socrates” ⭐⾼い + ガードレール ⭕不要 ⭕不要 ⭕不要 BI レポート ❌ ⭕不要 ⭕不要 ⭕不要 Conversational Analytics / Looker Explores / Gemini in BigQuery 🔺 ⭕不要 🔺 ⭕不要 Cursor + MCPs ⭕⾼い ⭕不要 🔺 ❌ 加⼯済みデータ 🔺 🔺 ⭕不要 ⭕不要 ⽣データ ⭕⾼い ❌ ❌ ⭕不要
20 3. 【背景理解】なぜ AI エージェント なのか? なぜ⾃社開発なのか? Socrates のような AI
エージェントが登場した技術的背景と、メルカリの戦略 的判断
21 AI エージェントの定義 • AI エージェントとは:⾃ら「推論」し「⾏動」することで⽬標を達成する システム。近年ではさらに⾼度で多様な特徴を持つように進化。 • AI エージェントの主要な特徴:
◦ 推論 (Reasoning): 論理的に結論を導き、推論して、問題を解決する ◦ ⾏動 (Acting): 計画や⼊⼒に基づき、環境に⾏動を起こす ◦ 観察 (Observing): 環境を認識‧把握し、意思決定に活かす ◦ 計画 (Planning): ⽬標達成のための⼿順を⽴案し、⾏動⽅針を決める ◦ 協調 (Collaborating): ⼈間や他の AI と連携し、⽬標を達成する ◦ ⾃⼰改善 (Self-refining): 経験から学び、継続的に性能を向上させる What are AI agents? Definition, examples, and types | Google Cloud より要約
22 LLM の進化と限界、AI エージェントの必要性 • ⼤規模⾔語モデル(LLM)の⾶躍的進化 (例: Gemini 2.0 Pro)
◦ ⾃然⾔語理解‧⽣成が、実⽤的な速度、精度、コストで利⽤可能に。 ◦ ⾼度な質疑応答、⽂章要約、翻訳、多様なコンテンツ作成、コード⽣ 成⽀援など、ビジネス応⽤が急速に拡⼤。 • LLM 単体では実世界の複雑な問題解決には限界: ◦ 受動性: プロンプトへの応答のみで、⾃律的なタスク遂⾏は困難。 ◦ 知識の固定化: 社内 DB 等の最新情報へアクセスできない。 ◦ ⾏動の制約: 外部システム操作などは実⾏不可。 • ⇒ LLMの「思考」を、現実世界での具体的な「⾏動」に繋げ、より⾼度な タスクを⾃律的に実⾏させるAIエージェントへの期待が⾼まっている。
23 なぜ Socrates を⾃社開発したのか? (1/2) • タイミング (2025 年 3
⽉時点) ◦ データ活⽤AIプロジェクトの再燃と経営層の期待。 ◦ ⾼品質なデータマート (PJ 名: Basic Tables) の完成。 ◦ ⾼性能な LLM の登場。実⽤的な速度と精度。 ◦ LangGraph のような AI エージェント構築ライブラリ。 ▪ 2⽇で LangGraph ベースの初期デモが稼働。「AI エージェント によるデータ分析⽀援」の有効性を確信。 ◦ エンタープライズレベルで信頼でき、メルカリの複雑なデータ環境と 要求に応えられる汎⽤的なデータ分析 AI エージェントがなかった。
24 なぜ Socrates を⾃社開発したのか? (2/2) • 「周辺資産」への早期投資の意図 ◦ AI エージェントのコア技術は急速にコモディティ化する可能性。
◦ 真の競争優位性は、他社が模倣困難な「周辺資産」(構造化データ、 ⾮構造化ナレッジ、業務プロセス、評価基盤)にある。 ◦ Socrates を⾃社開発し運⽤することで、これらの周辺資産の価値を早 期に実証し、全社的な整備‧強化を加速させる「触媒」としての役割 を期待。 ◦ ⽬指すのは「AI Agent Ready」な組織と環境の確⽴
25 Socrates の初期検証:PoC スコープ (1/2) • PoC スコープ設定の戦略:「広範囲‧浅い」よりも「特定領域‧深い」 ◦ 理由:
▪ 最⼤価値の想起: 限定的でもエンドツーエンドで分析プロセスが ⾃動化される体験で、AI エージェントが将来提供しうる最⼤価値 を具体的にイメージさせる。 ▪ コア技術の実現性証明: 最も重要な「⾃然⾔語 → SQL → 分析結 果」のフローが、⾼品質データに対して機能することを⽰す。 ▪ 具体的フィードバックの獲得: 「動くもの」があることで、ユー ザーからの質の⾼いフィードバックを得やすい。 ▪ 品質保証期間の最⼩化: 最初は「寿命が短い」プロセスにフォー カスして、リリースサイクルを⾼速化。 Skip
26 Socrates の初期検証:PoC スコープ (2/2) • Socrates PoC の具体的スコープ: ◦
対象データソースの限定: ▪ ⾼品質データマート「Basic Tables」のみを対象 ◦ 対象分析プロセスの限定: ▪ ユーザーの分析ニーズ特定 ▪ 関連する Basic Tables からのテーブル選択 ▪ SQL クエリ⾃動⽣成と BigQuery での実⾏ ▪ 分析結果の表形式での描画 ◦ 対象外とした機能: ▪ 複雑な対話、グラフ描画、⾼度な統計分析、広範なデータソース への対応など。 • 成果と学び: 「優秀なアナリストと対話するようにデータ分析が進む」⼤ きな期待感と、データ整備の重要性を伝えた。 Skip
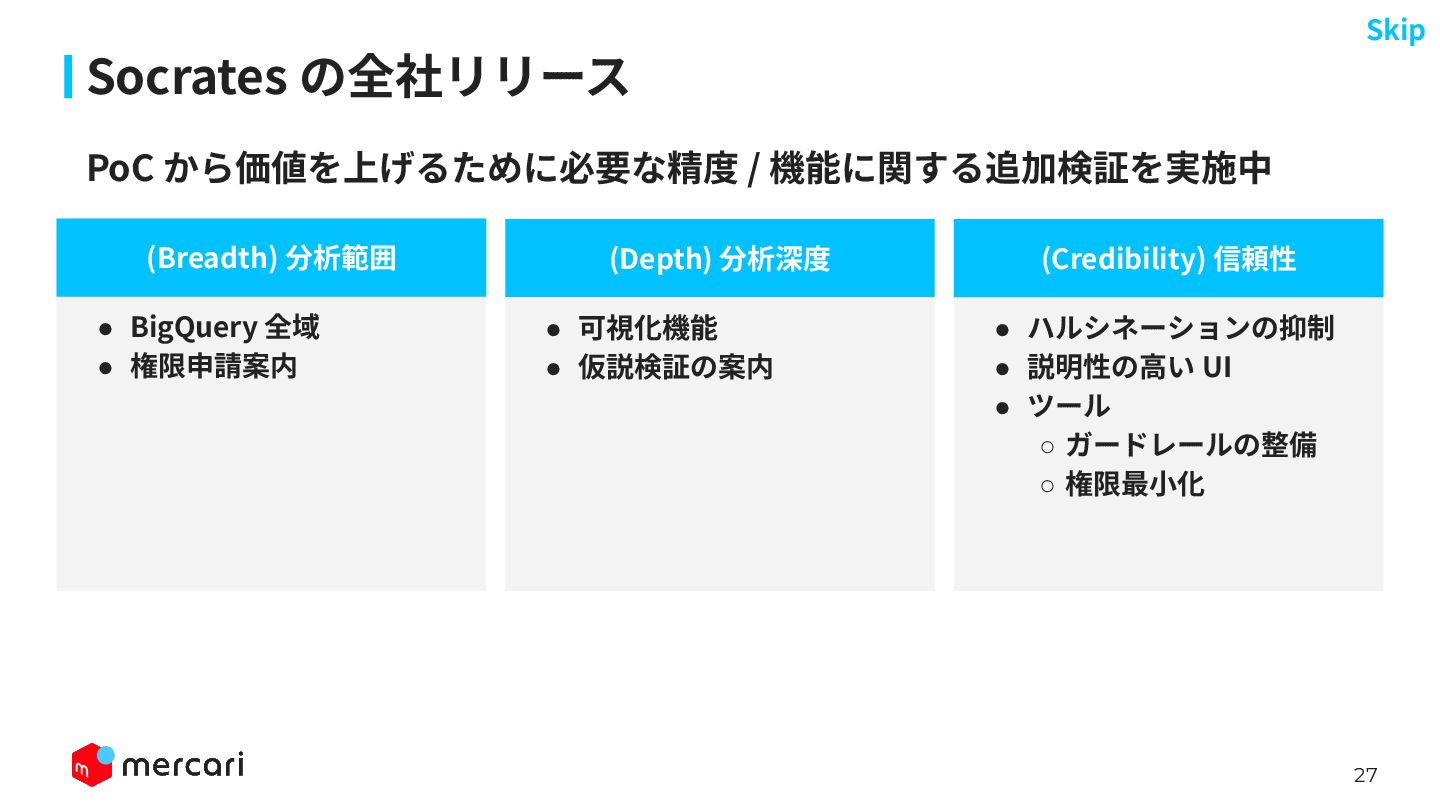
27 Socrates の全社リリース ⾒出し (Depth) 分析深度 (Breadth) 分析範囲 • BigQuery
全域 • 権限申請案内 • 可視化機能 • 仮説検証の案内 • ハルシネーションの抑制 • 説明性の⾼い UI • ツール ◦ ガードレールの整備 ◦ 権限最⼩化 (Credibility) 信頼性 PoC から価値を上げるために必要な精度 / 機能に関する追加検証を実施中 Skip
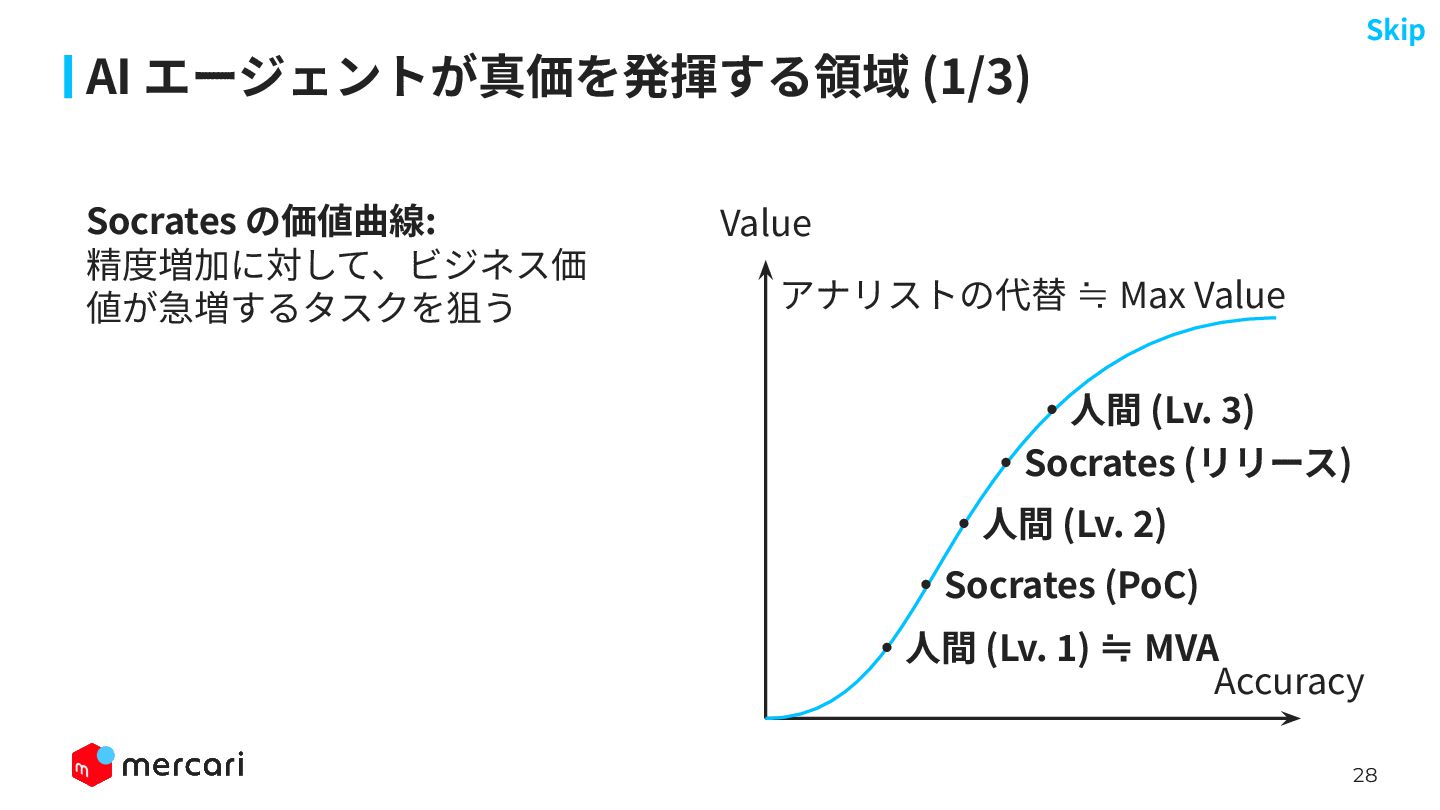
28 AI エージェントが真価を発揮する領域 (1/3) Socrates の価値曲線: 精度増加に対して、ビジネス価 値が急増するタスクを狙う アナリストの代替 ≒
Max Value ‧⼈間 (Lv. 1) ≒ MVA ‧⼈間 (Lv. 2) ‧Socrates (PoC) Value Accuracy Skip ‧Socrates (リリース) ‧⼈間 (Lv. 3)
29 AI エージェントが真価を発揮する領域 (2/3) • 「⾮決定論的」であることが強みになる&許容できる ◦ AI エージェントは同じ⼊⼒に対して、同じ出⼒や⾏動になるとは限ら ない。
• ⾮決定論性が「強み」となる領域 ◦ 探索や仮説⽣成: 答えが決まっていない問いに対し、様々な⾓度から 情報を収集し、多様な可能性を探る。 ◦ 柔軟な対応: 曖昧な指⽰や状況の変化に対して、⽂脈に応じた臨機応 変な判断や⾏動を⾏う。 ◦ 創造性やブレインストーミング: 新しいアイデアや洞察を⽣み出す。 Skip
30 AI エージェントが真価を発揮する領域 (3/3) • 「AI エージェントの提供できる価値」 ∝−1「成果物の寿命」? ◦ (得意)短命な成果物:作成された直後に価値が最⼤となり、時間経
過と共に急速に価値が低下するもの。 ▪ 例:⽇次分析レポート、リアルタイムな顧客問い合わせへの⼀次 回答、市場の瞬間的なトレンド把握 ◦ (苦⼿)⻑寿な成果物:⻑期間にわたり正確性や信頼性が求められる もの。 ▪ 例:会計監査報告書、製品の安全基準ドキュメント、学術論⽂* ▪ (*学術論⽂は書けることも指摘されているが、⾼度な実装が必要) • ⇒ データ分析は「寿命の短い成果物」として向いているタスクの⼀つ ◦ 検証レポートなどは、寿命が⻑いものに適⽤する場合は⼯夫が必要 Skip
31 4. 【道具】Google ADK 登場と Socrates アーキテクチャ AI エージェント開発を加速する ADK
と、Socrates におけるその活⽤⽅法
32 ADK の概要 • Agent Development Kit (ADK): AI エージェント開発を⽀援する
Python / Java フレームワーク • 主な特徴: ◦ Google エコシステムとの⾼い親和性: Google Workspace、Google Cloud 等とシームレスに連携。 ◦ マルチエージェントアーキテクチャ設計⽀援: 複数の専⾨エージェン トの協調を容易に実現。 ◦ 柔軟なオーケストレーション: LLM 駆動の動的処理と、ワークフロー ベースの静的処理を組み合わせ可能。 ◦ 豊富なツールエコシステムと拡張性: LangChain 等の外部ライブラリ との連携もサポート。 ◦ 双⽅向ストリーミング:リアルタイムな⾳声‧動画対話をサポート。
33 ADK のコア構成要素:エージェント開発の基盤 • エージェント (Agents): ◦ 特定のタスクを実⾏するために設計された基本的な「働き⼿」。 • ツール
(Tools): ◦ エージェントに外部 API との連携、情報検索、コード実⾏、他サービ ス呼び出しなどの機能を提供。
34 ADK のコア構成要素:インタラクションと状態の管理 • セッション管理 (Sessions): ◦ 単⼀の会話の⽂脈 (Sessions) を処理。
◦ 会話履歴 (Events) や、会話中のエージェントのワーキングメモリ (State) を含む。 • メモリ (Memory): ◦ 複数セッションにわたってユーザーに関する情報を記憶。 ◦ セッション内の短期的な State とは異なり、⻑期的な⽂脈を提供。 • イベント (Events): ◦ セッション中に発⽣する出来事 (ユーザーメッセージ、エージェント の返信、ツールの使⽤など) を表すコミュニケーションの基本単位。 ◦ 会話履歴を形成。 • アーティファクト管理 (Artifacts): ◦ セッションやユーザーに関連するファイルやバイナリデータ (画像、 PDF など) の保存、読み込み、管理。 Skip
35 ADK のコア構成要素:⾼度な機能と実⾏の仕組み • ランナー (Runner): ◦ 実⾏フローを管理するエンジン。 ◦ Event
に基づいてエージェント間のインタラクションを調整し、バッ クエンドサービスと連携。 • コールバック (Callbacks): ◦ エージェントの処理プロセス内の特定のポイントで実⾏されるカスタ ムコード。 ◦ チェック、ロギング、動作の変更などが可能。 • コード実⾏ (Code Execution): ◦ エージェントがコードを実⾏する能⼒。 Skip
36 Socrates は、ADK を基盤としたマルチエージェントシステムとして設計。各エー ジェントが専門タスクを担当し、協調動作。 Socrates との他の社内ツールとの共存関係 ⼈ Socrates BigQuery
権限管理 エージェント 会話 Python エージェント ツール 使⽤ 依頼 応答 依頼 応答 応答
37 Socrates の ADK 活⽤ポイント • ADK の主要な柱と Socrates への具体的適⽤:
◦ モジュール性:⽬的特化型の複数のサブエージェントで構成。開発‧テ スト‧改修が容易。 ▪ 狙い: root エージェントの肥⼤化防⽌ / テスト可能性の維持、各 専⾨チームへのエージェント委任による組織全体のエージェント 運⽤促進 ◦ 豊富なツールエコシステム: 多数の実装済みツールと 3rd party ツール との互換レイヤー。
38 Socrates のワークフローを ADK で設計する • 主要な分析の進め⽅をステップごとに分類して、ADK で実装 ◦ LLM
Agents - 柔軟 / テキスト / ⾮決定論的なステップ ▪ (1.) ユーザー意図の明確化 ▪ (3.) 分析計画の⽴案とツール選択 ▪ (5.) SQL ⽣成 / 検証 / 反復実⾏ ▪ (7.) 結果の統合 / 解釈 / 報告 ◦ Tools - 厳格 / 決定論的なステップ ▪ (2.) 過去事例 / 関連知識の参照 ▪ (4.) データソース探索と理解 ▪ (6.) ⾼度な分析処理の実⾏
39 Socrates と ADK Agents / Tools 活⽤ Tools Agents
外部⼊出⼒、決定論的な データ処理 ⾮構造化データの処理、 思考、⾮決定論的なデー タ処理
40 Socrates と ADK Agents 連携:概要 • Socrates における ADK
Agents の重要性: 全体の計画とタスクの分割、⾮ 構造化データの処理を⾏う。 • Agents の種類: ◦ LLM Agent: ⼤規模⾔語モデル(LLM)を活⽤し、複雑な推論を⾏う。 ◦ Workflow Agents: 実⾏フローを制御する決定論的なエージェント。 ▪ Sequential Agent: 順次実⾏ ▪ Loop Agent: 反復実⾏ ▪ Parallel Agent: 並列実⾏ ◦ Custom Agents: 任意のロジックの実装。
41 Sequential Agent: LLM の成果物をレビューする Socrates と ADK Agents 実装例:Self-Reflection
(1/2) このクエリは全ユーザ数を示しており、 利用者の期待と違いそう アクティブユーザ数を調べるぞ SELECT COUNT(*) FROM users
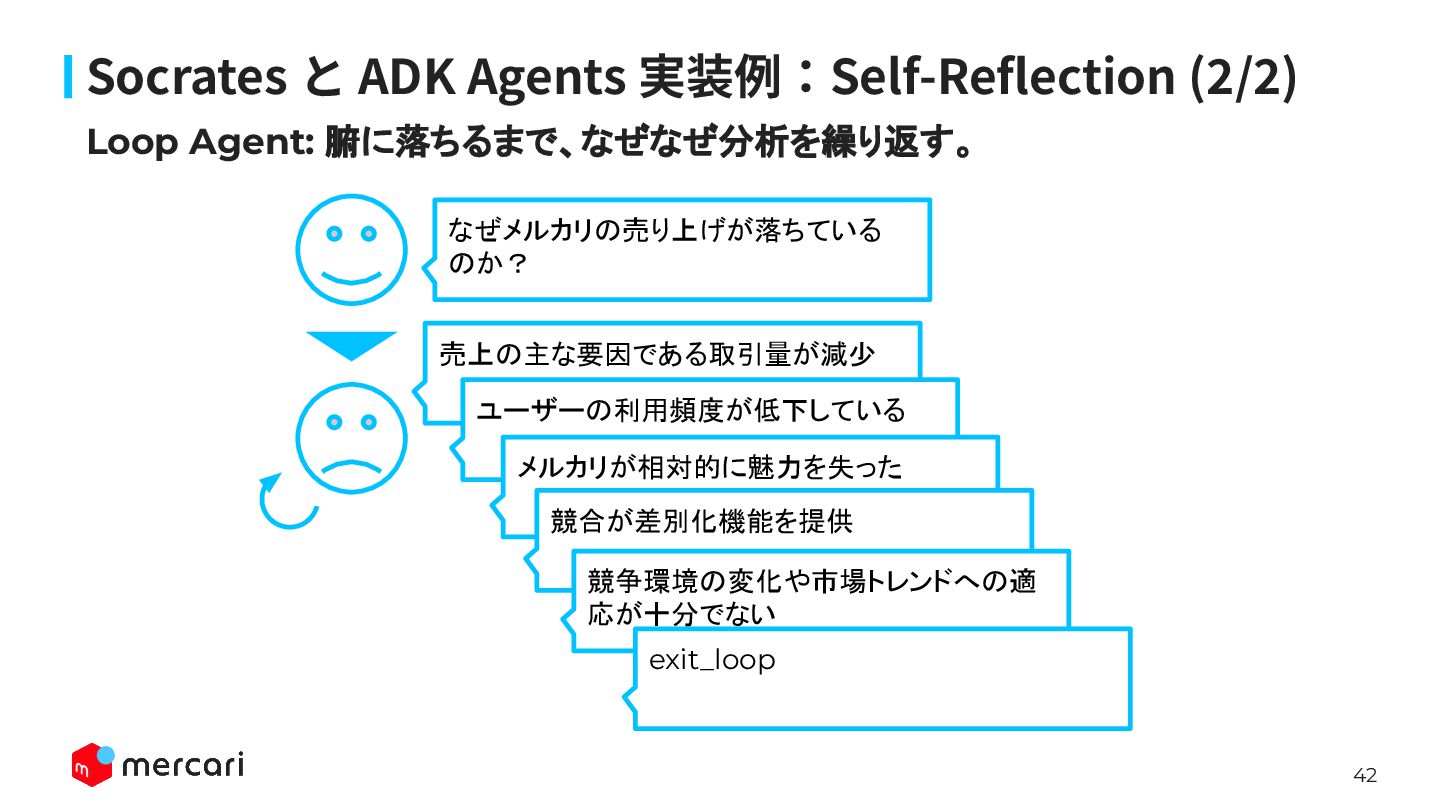
42 Loop Agent: 腑に落ちるまで、なぜなぜ分析を繰り返す。 Socrates と ADK Agents 実装例:Self-Reflection (2/2)
売上の主な要因である取引量が減少 なぜメルカリの売り上げが落ちている のか? ユーザーの利用頻度が低下している メルカリが相対的に魅力を失った 競合が差別化機能を提供 競争環境の変化や市場トレンドへの適 応が十分でない exit_loop
43 Parallel Agent: temperature の高い LLM Agents を用いたブレスト大会 Socrates と
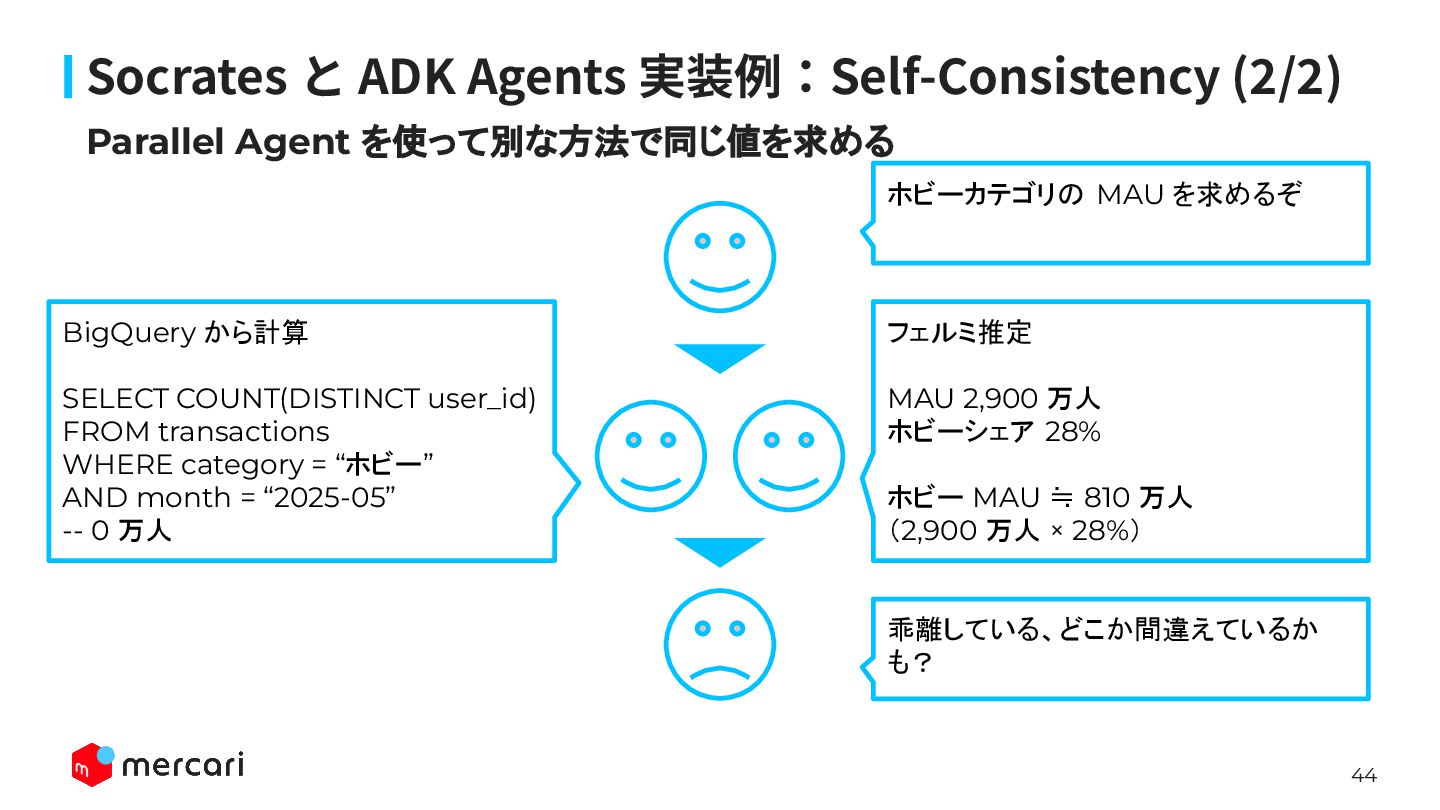
ADK Agents 実装例:Self-Consistency (1/2) 売上増加の原因を調べるぞ ホビーカテゴリじゃね? 服カテゴリの季節変動かも? 一昨日のリリースのおかげだよ 大型キャンペーンやってなかった? 大型キャンペーンが有力です。 順に検証してみましょう。
44 Parallel Agent を使って別な方法で同じ値を求める Socrates と ADK Agents 実装例:Self-Consistency (2/2)
フェルミ推定 MAU 2,900 万人 ホビーシェア 28% ホビー MAU ≒ 810 万人 (2,900 万人 × 28%) BigQuery から計算 SELECT COUNT(DISTINCT user_id) FROM transactions WHERE category = “ホビー” AND month = “2025-05” -- 0 万人 ホビーカテゴリの MAU を求めるぞ 乖離している、どこか間違えているか も?
45 ツールを LLM Agent で囲って、より柔軟にツールを使用する Socrates と ADK Agents 実装パータン:Agentic
Tools なぜメルカリの売り上げが落ちている のか調べて 売上テーブルは見つからなかったけ ど、transactions テーブルは見つかっ たよ。BigQuery の構文ドキュメントを 読んでクエリを書くね。 クエリ結果は ~。 BigQuery
46 Socrates と ADK Agents / Tools 活⽤ Tools Agents
外部⼊出⼒、決定論的な データ処理 ⾮構造化データの処理、 思考、⾮決定論的なデー タ処理
47 Socrates と ADK ツール連携:概要 • AI エージェントにおけるツールの重要性: LLM の知識の限界、計算能⼒の
限界、外部システム連携不可を補う。 • ツールの主な種類: ◦ 知識アクセス系ツール(Observing): LLM に外部知識を提供 ▪ Socrates: Vertex AI RAG Engine による社内ドキュメント検索、 BigQuery テーブル定義検索 ◦ 計算‧データ処理系ツール: 数値計算、データ加⼯、コード実⾏ ▪ Socrates: BigQuery 実⾏、Python コード実⾏ ◦ 外部連携‧API 呼び出し系ツール(Acting): 他システムとの連携 ▪ Socrates: Google ドライブ、他 API 連携
48 Socrates と ADK ツール連携:知識アクセス系ツール • BigQuery との対話(ADK BigQueryToolset): ◦
スキーマ参照 bigquery_tables_get を⾏い、テーブルのスキーマや説 明⽂を取得し、LLM のデータ理解を促進。 ◦ SQL 実⾏ bigquery_jobs_query。ADK の認証の仕組みを通じて、 ユーザー権限のセキュアなデータアクセス。 • Vertex AI RAG Engine による知識拡張(ADK VertexAiRagRetrieval): ◦ 社内ドキュメントや BigQuery テーブルを⾃然⾔語で検索 ▪ search_internal_documents(query) ▪ search_bigquery_tables_semantic(query) • メモリ保存‧検索(ADK VertexAiRagMemoryService): ◦ 過去の類似分析セッションの記録‧検索‧再利⽤ ▪ load_memory(query) ▪ add_session_to_memory(session)
49 Socrates と ADK ツール連携:計算‧データ処理系ツール • Python Code Executor (ADK
VertexAiCodeExecutor): ◦ SQLでは困難な⾼度なデータ処理、統計分析を実⾏。サンドボックス 化された安全な実⾏環境が鍵。 ◦ 現状、外部パッケージの動的インストールは制限あり。 ▪ matplotlib でグラフを書くと、⽇本語が⾖腐□になる。
50 Socrates と ADK ツール連携:外部連携系ツール他 • Google ドライブ系ツール (ADK DocsToolset,
SheetsToolset): ◦ よりリッチな⼊出⼒を⾏い、⼈間が介⼊しやすくサポートする。 ◦ チャットインタフェースの情報密度が低くなりやすいのを補う役割。 • 応答エージェントの変更(ADK transfer_to_agent) ◦ マルチエージェントシステムにおいて、より詳細な実装を持つエー ジェントに応答を委任する • Python ⾃作ツール(ADK FunctionTool / Agents as a tool) ◦ 既存の実装では不⾜する機能や、ガードレール付きの振る舞い、別な Agent へ⼀時的な⼿伝い依頼を実現する
51 Socrates と ADK ツール連携:なぜ⾃作ツールが必要か • AI エージェントにおけるツールの重要性: LLM の知識、計算能⼒、外部シ
ステム連携を補う。 • Socrates では多くのツールを⾃作。ADK の FunctionTool を活⽤。 ◦ 理由1: きめ細やかなガードレールの実装: ▪ Google Cloud の API を⾃作ツール内でラップ。 ▪ ツール実⾏前後のチェックに加え、実⾏中の監視や介⼊(例: BigQuery の過剰なコスト予測時の実⾏中断)など、より厳格な 安全対策を組み込むため。 ◦ 理由2: 品質改善サイクル: ▪ RAG の検索クエリごとのヒット率などきめ細やかなログを取得 し、RAG の品質改善サイクルを回せる。
52 AI エージェントのためのツール選定戦略:基本⽅針 (1/2) • ⽬的からツールを選ぶ ◦ エージェントに「何をさせたいか?」を明確にし、その⽬的達成に必 要な機能から逆算する。 ◦
Socrates 例:データアナリストの業務には、BigQuery アクセス、ス プレッドシート作成、ドキュメント検索が必要。 • LLM に⼿続きをさせる、知識を披露させない ◦ エージェントに必要な知識は、ツール、プロンプトで全て与える。 エージェントの知識を信⽤しない。 Skip
53 AI エージェントのためのツール選定戦略:基本⽅針 (2/2) • 実現可能性 / 既存資産を活⽤できないか考える ◦ 社内に利⽤可能なAPI、ライブラリ、データソースがないか確認。
◦ Socrates 例:Basic Tables、監査ログ • プロンプトで対応できないか考える ◦ 知識アクセス系のツールの場合は、プロンプトに知識を書いて、ツー ルとして実装しない⽅針も検討する。 • 信頼性と検証可能性を評価する ◦ ツールの安定性、エラーハンドリングの容易さ、品質確認のしやすさ を考慮。 • セキュリティとガバナンスを評価する ◦ 権限は必要⼗分か?機密情報の取り扱いは適切か? ◦ 場合によっては、ログやガードレールを含めて⾃作する Skip
54 5. 【学びの軌跡】エコシステム構築の 戦略 Socrates 開発を⽀える技術選択の背景と、AIエージェントを育む環境の重要 性
55 技術選定の道のり:LangGraph から ADK へ • LangGraph からの出発(2025 年 3
⽉):「⾃律的に思考‧⾏動する エージェント」に着⽬し、プロトタイピングを実施。⾼品質データマート 「Basic Tables」が成功の鍵。2 ⽇でデモ版リリース。 • LangGraph から ADK への移⾏に期待したこと ◦ Google エコシステムとのネイティブ連携 ▪ Google Drive や BigQuery / Vertex AI Search などの強⼒なツール との連携 ▪ Vertex AI Agent Engine / Google Agentspace による運⽤監視へ の期待 ◦ LangGraph の若⼲の⼿間の解消 ▪ LangGraph Runnable#stream が、応答を配列とスカラ値、それ ぞれで返すことがあり、ハンドリングが煩雑
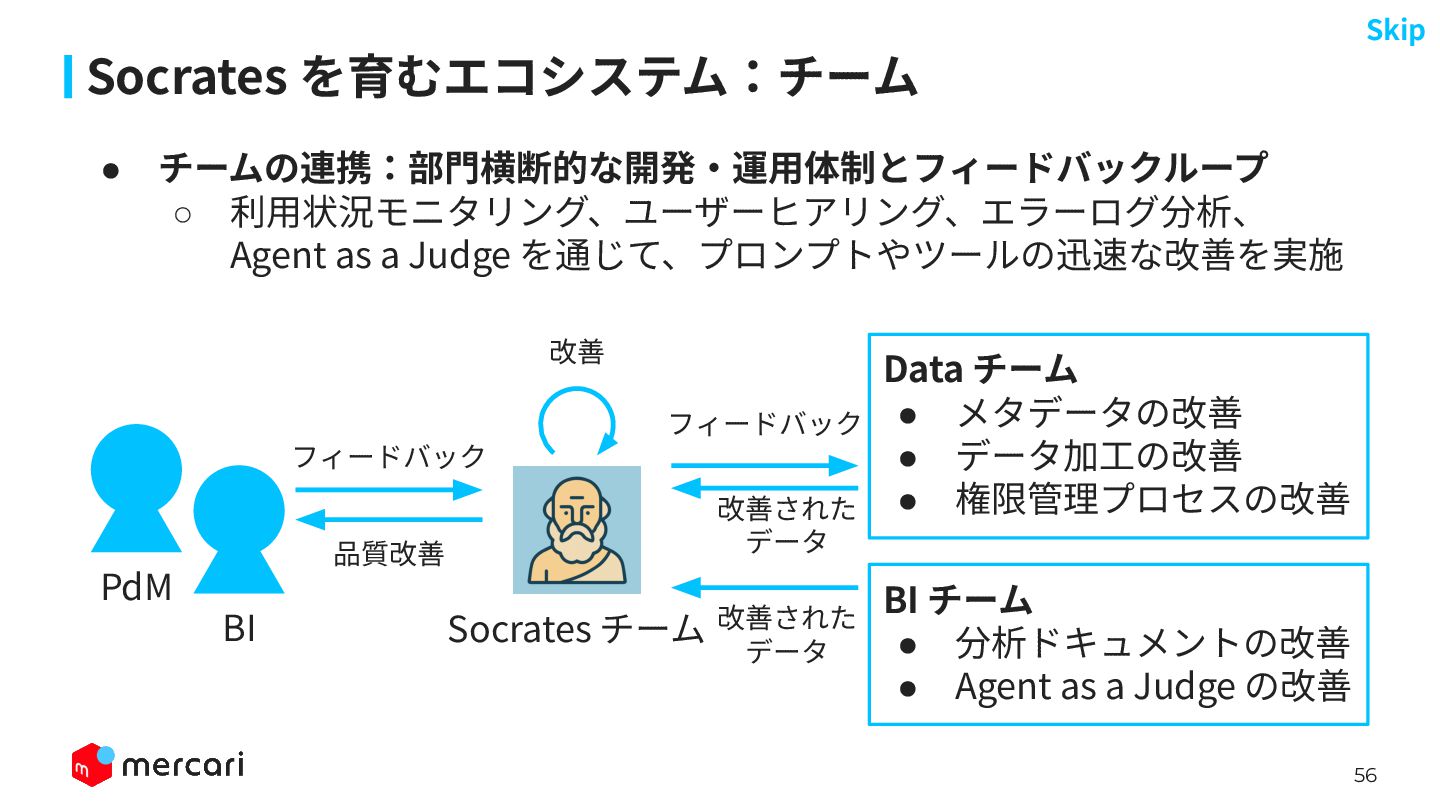
56 Socrates を育むエコシステム:チーム • チームの連携:部⾨横断的な開発‧運⽤体制とフィードバックループ ◦ 利⽤状況モニタリング、ユーザーヒアリング、エラーログ分析、 Agent as a
Judge を通じて、プロンプトやツールの迅速な改善を実施 Skip Socrates チーム BI PdM BI チーム • 分析ドキュメントの改善 • Agent as a Judge の改善 Data チーム • メタデータの改善 • データ加⼯の改善 • 権限管理プロセスの改善 フィードバック 改善 品質改善 フィードバック 改善された データ 改善された データ
57 Socrates を育むエコシステム:データ • データの⼒:整備されたデータ資産 ◦ ⾼品質データマート「Basic Tables」がSocratesの分析能⼒の源泉。 • カスタムデータカタログの構築と運⽤
◦ BigQuery 監査ログから、テーブル定義、⽣成⽅法、利⽤状況を収集 ‧解釈し、⽤途とテーブルの対応表を整備。 ◦ Vertex AI RAG Engine と連携し、⽤途からテーブル検索を可能に。 ◦ メリット: ▪ データカタログでヒットしないマイナーテーブルをカバー • 精度は semantic layer などでカバー ▪ 評価と改善サイクルの実現: 検索クエリや利⽤状況を分析し、カ タログの記述や構造を継続的に改善。 Skip
58 Socrates を育むエコシステム:ドキュメント • Machine Readable なドキュメントとナレッジベースの重要性 ◦ テーブル定義書、ビジネス⽤語集、分析⼿順書、過去の Q&A、施策カ
レンダーなどを RAG ⽤に整備。 ◦ 課題: ⼈間にとって書きやすく、かつ機械にとっても読みやすいド キュメントをどう増やすか。 ▪ 対策: ドキュメント作成のインセンティブ設計、ドキュメントテ ンプレート、LLM による記述⽀援。 ◦ 将来構想: Socrates が GitHub リポジトリを DeepWiki のような仕組 みを介して検索し、データ⽣成プロセスを理解する。 • 技術だけでなく、AI エージェントを業務に組み込み、共に成⻑していくた めの運⽤体制と組織⽂化の醸成が重要 Skip
59 6. 【実践知】エンタープライズ AI エージェント運⽤のリアル AI エージェントを本番環境で安定稼働させるための課題と、Socrates での具 体的な取り組み
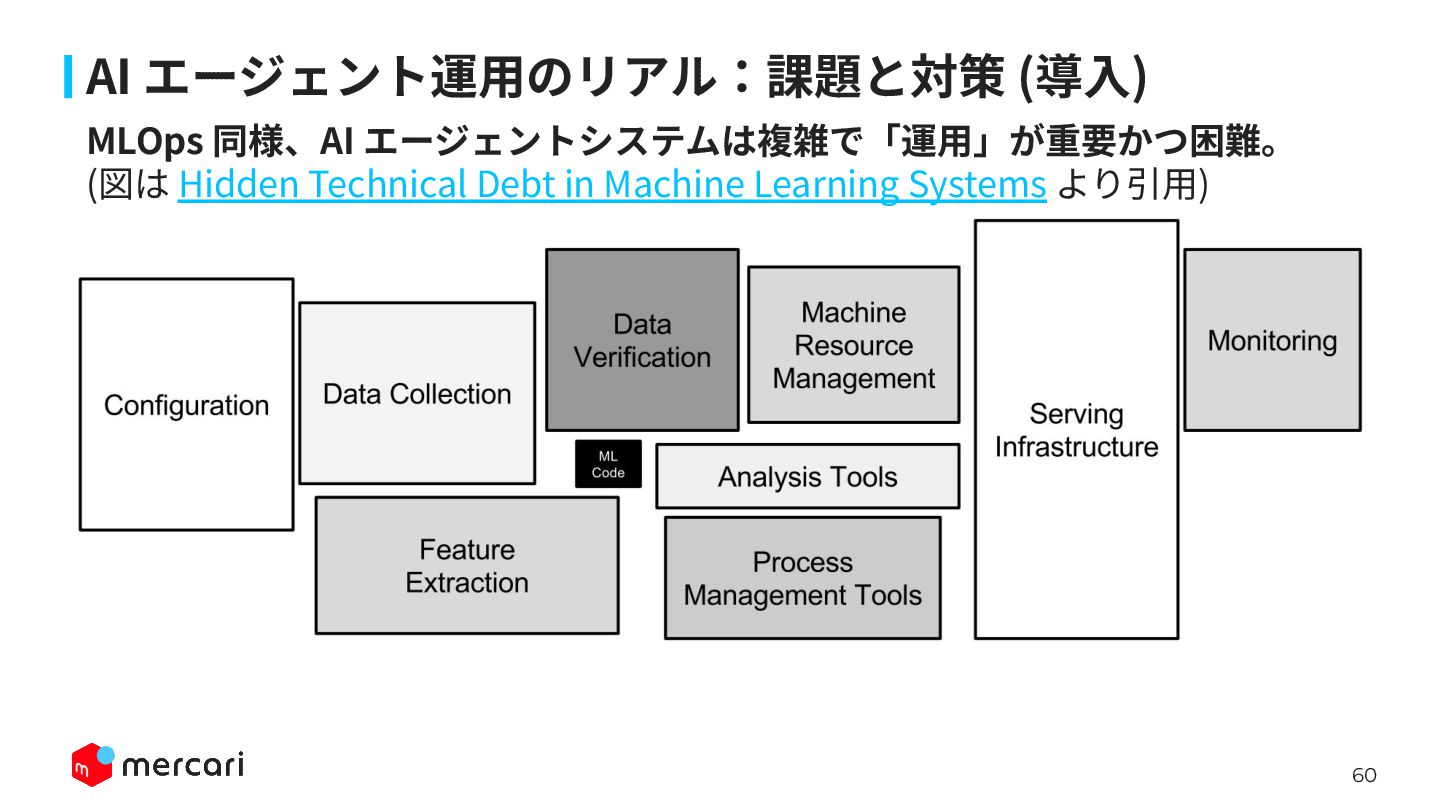
60 MLOps 同様、AI エージェントシステムは複雑で「運⽤」が重要かつ困難。 (図は Hidden Technical Debt in Machine
Learning Systems より引⽤) AI エージェント運⽤のリアル:課題と対策 (導⼊)
61 AI エージェント運⽤のリアル:課題と対策 (1/4) • LLM エージェント評価の難しさとアプローチ: ◦ 課題: ⾮決定論的で「正しさ」の定義が曖昧。評価すべき側⾯も多岐
(ツール連携、⻑期記憶、対話の流れ)に渡る。ロングセッションの テストは特に困難。 ◦ 評価: ▪ オフライン評価 (ADK Evaluation 活⽤): 事前定義された評価デー タセットでツール呼び出しや引数の妥当性確認。 ▪ オンライン評価 (Human-in-the-Loop): ユーザーからの直接 フィードバック。 ▪ Agent as a Judge: 別のエージェントが、Socrates の応答品質や セッション全体の妥当性を評価。特にロングセッションの E2E テ ストに効果を発揮。 ▪ ダッシュボード: 重要メトリクスをダッシュボードで可視化。
62 AI エージェント運⽤のリアル:課題と対策 (2/4) • LLM エージェント評価の難しさとアプローチ(続き): ◦ 改善: ▪
プロンプト更新: 各種評価をもとに、より⼈間のためになる⼿順 に近づくようにプロンプトを更新。 ▪ ツール更新: LLM が使いづらいと感じているツールは、ドキュメ ントやメタデータ、ユースケース例を追加したり、ツール⾃体を 分割する。 ◦ ⇒ 厳密な決定論的テストは困難。セッションレベルの達成度や品質を 多⾓的に検証し、継続的な評価と改善ループを回すことが重要。
63 AI エージェント運⽤のリアル:課題と対策 (3/4) • レイテンシ: ◦ 課題: ⾼速とは⾔えない。Gemini 2.5
Pro への問い合わせと同程度。 ⼀問⼀答ではないため、⼈間が idle になる時間が⻑くなりつつある。 ◦ 対策: ▪ ストリーミング応答、⾮同期処理による体感速度向上、ユーザー への進捗表⽰。 ▪ ⾼速なモデル(Gemini 2.0 Flash)と選択。
64 AI エージェント運⽤のリアル:課題と対策 (4/4) • コスト最適化: ◦ 課題: LLM API
コール数、トークン消費量などが想定以上に膨らむリ スク。 ◦ 対策: ADK の Gemini 呼び出し回数調整、ワークフロー最適化、 BigQuery コストガードレールの策定。 • セキュリティとガバナンス: ◦ 課題: プロンプトインジェクション、機密情報漏洩、意図しないエー ジェントの⾏動(データ破壊、誤ったデータの蓄積‧拡散)。 ◦ 対策:ツール実⾏スコープの最⼩化。ある程度の社内リスクは受け⼊れ つつ、⼊⼒サニタイズ‧出⼒フィルタリングなどのガードレールを実 装。
65 ADK の評価:実際に使ってみて良かった点 • 良かった点 (Socrates 開発における実感): ◦ 全体としてよくできている ◦
Google エコシステムとの強⼒なネイティブ連携: Vertex AI, BigQuery 等とのシームレスな統合が開発を加速。 ◦ サンプルコードの充実: adk-samples リポジトリが充実。 ◦ デバッグが簡単: コードが⼩さく、問題箇所の特定や修正が容易。 ◦ 単純な Evaluation が簡単: 単純なテストは ADK Evaluation で完結。 ◦ 画像 / ⾳声対応も簡単: ファイルを添付して、Agent に送るだけ。 ◦ Vertex AI Agent Engine への期待: マネージドな本番環境への移⾏パ スの安⼼感。スケーリングやインフラ管理の負担軽減を期待。
66 ADK の評価:苦労した点‧課題 • 苦労した点‧課題(解決済み) ◦ バグ: v0.1.0 から⼀部のエラーハンドリングが弱かった。v1.0.0 の今
は⼤部分が改善。 ◦ 互換切り: v.0.1.0 から⾒ると、DatabaseSessionService のデータス キーマ変更、async 関数化などの互換性がない変更があった。 • 苦労している点(未解決) ◦ Session Service 周りの課題: json.dumps できないオブジェクトが含 まれる Event が応答されると、Database や Agent Engine Sessions に保存できず、エラーになる。
67 ADK の評価:LangGraph の強み • 既存の応⽤的なオープンソースソフトウェアの参照: Deep Research など 丸ごとコピーして動かしたい時に便利。ADK
の実装はまだ少ない。 • 複雑なワークフローの実装: LangGraph は複雑なグラフ構造をワークフ ローとして定義できる。ADK は「順次」と「反復」の⼿続きのみ。
68 7. 【未来展望】ADK の進化への期待
69 ADK へのフィードバックと期待 • SessionService と MemoryService の機能拡充と外部連携強化: 多様な永 続化ストア対応(Cloud
Spanner, Firestore 等)、複雑なデータ型シリア ライズ標準化、Secret Manager 連携、⻑期記憶ソリューション。 • ツール呼び出しの堅牢性と柔軟なエラーハンドリング機構: リトライポリ シー、フォールバックの実装⽀援。ツール実⾏時の権限管理‧監査ログ標 準化。(+ Gemini の malformed_function_call 対策) • テスト‧評価フレームワークの充実 (ADK Evaluation のさらなる進化): エージェント振る舞い‧応答品質の体系的 / 効率的な評価フレームワー ク、マルチエージェント協調 / 全体タスク達成度評価⼿法。
70 エコシステムへの展望 • Google Agentspace / Vertex AI Agent Garden
への期待 ◦ エージェントシェアリング: 社内外の専⾨エージェントを共有 • Vertex AI Agent Engine への期待 ◦ 多様な Artifact Service のサポート ◦ MemoryService のサポート ◦ 利⽤者 Authorization のサポート ◦ SessionService への評価フレームワークの組み込み
71 8. 【まとめ】成功の鍵と教訓 本⽇の発表のまとめと、AIエージェント開発とADK活⽤に向けたメッセージ
72 ADK 活⽤の勘所と AI エージェント開発成功への教訓 • AI エージェントは LLM をコアとする複雑な「システム」
• AI エージェントは「作って終わり」ではなく、「育て続ける」もの ◦ 「構造化 / ⾮構造化データ」などの周辺資産も対象 ◦ 「組織」や「プロセス」の変⾰も伴う • AI エージェントのはじめ⽅ ◦ ユーザー提供価値の確認 ◦ スモールスタートと反復的改善 ◦ エージェントの能⼒拡張のためのツール設計 ◦ 運⽤の覚悟
73 2025-06-10 現在、AI エージェントを開発すべきか? 以下の条件を全て満たすなら Yes • PoC 時点の LLMs
の能⼒でも、⼗分に⾼い価値を提供できる • 代替⼿段が現実的でない(ソフトウェア化、⼈⼒化、省⼒化、廃⽌) • 保守し続ける覚悟がある • 時が来たら捨てる覚悟がある
74 参考資料‧リソース • Agent Development Kit • GitHub - google/adk-python
• GitHub - google/adk-samples • Speaker Deck - 1⽇50万件貯まるクエリのログを活かして、SQLの⽣成に 挑戦している話 • Hidden Technical Debt in Machine Learning Systems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}