ライブラリへの習熟
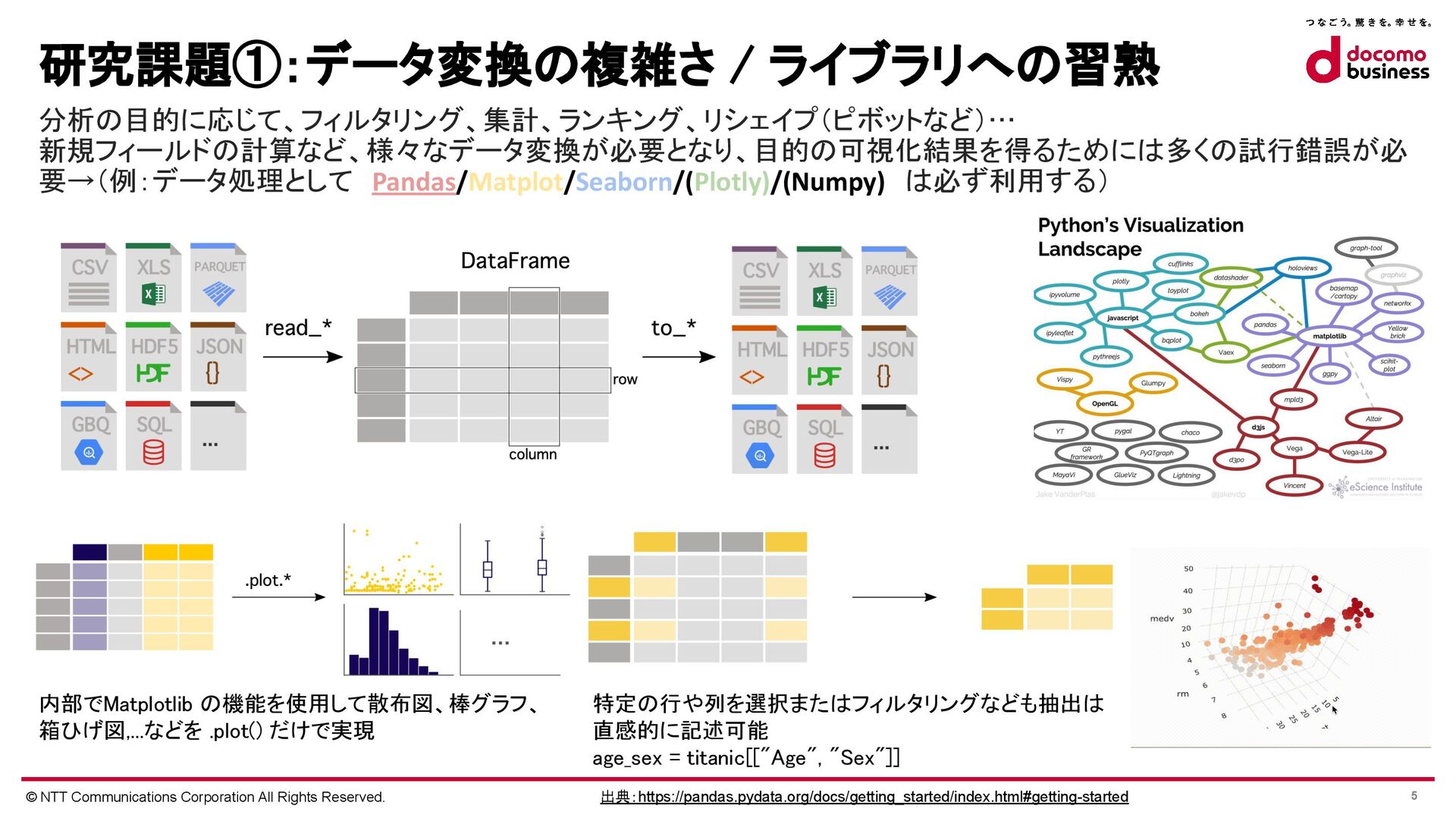
分析の目的に応じて、フィルタリング、集計、ランキング、リシェイプ(ピボットなど)…
新規フィールドの計算など、様々なデータ変換が必要となり、目的の可視化結果を得るためには多くの試行錯誤が必 要→(例:データ処理として Pandas/Matplot/Seaborn/(Plotly)/(Numpy) は必ず利用する)
内部でMatplotlib の機能を使用して散布図、棒グラフ、 箱ひげ図,...などを .plot() だけで実現
特定の行や列を選択またはフィルタリングなども抽出は 直感的に記述可能
age_sex = titanic[["Age", "Sex"]]
出典:https://pandas.pydata.org/docs/getting_started/index.html#getting-started
{kind=link}
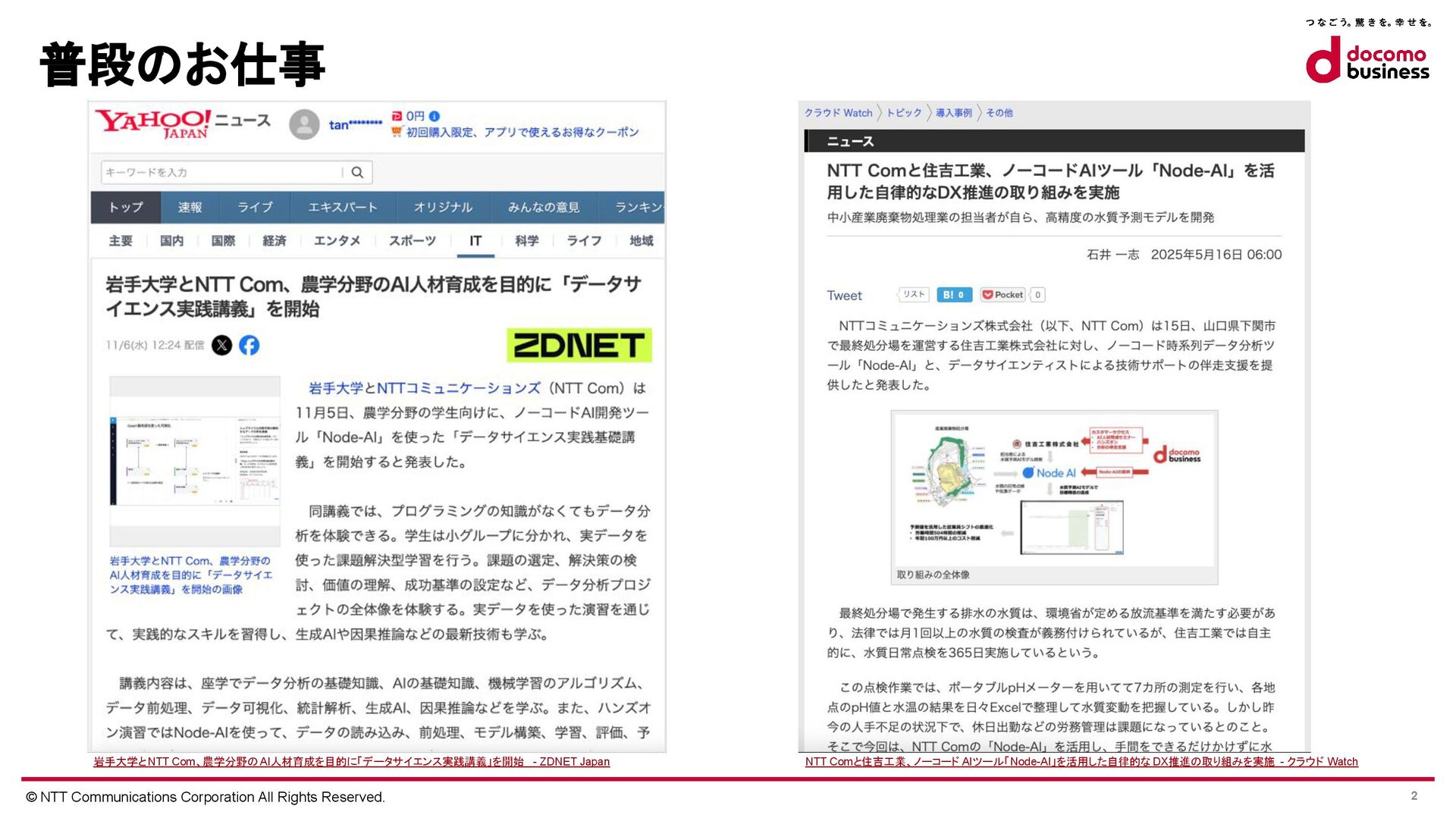{kind=link}
{kind=link}
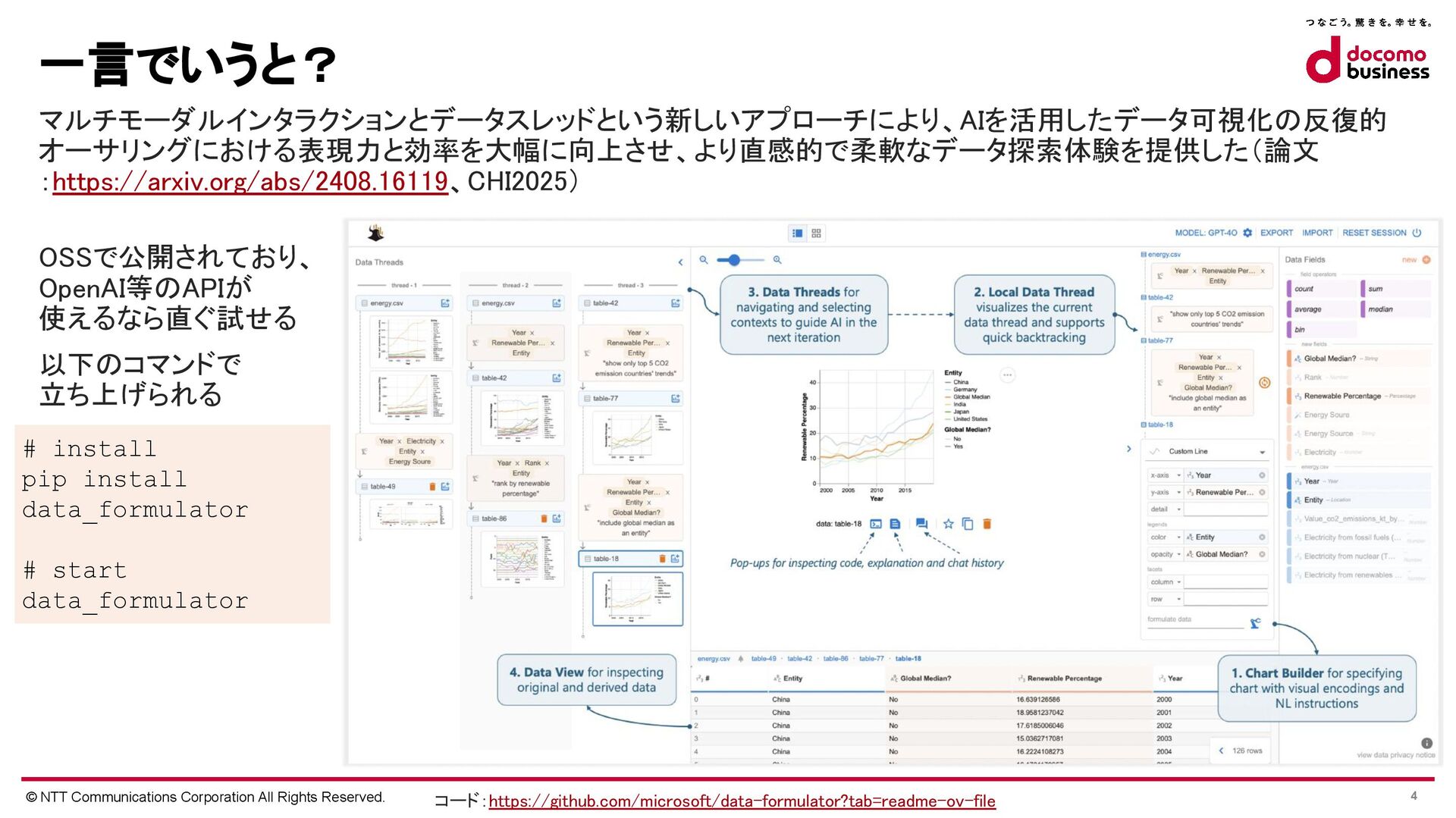{kind=link}
{kind=link}
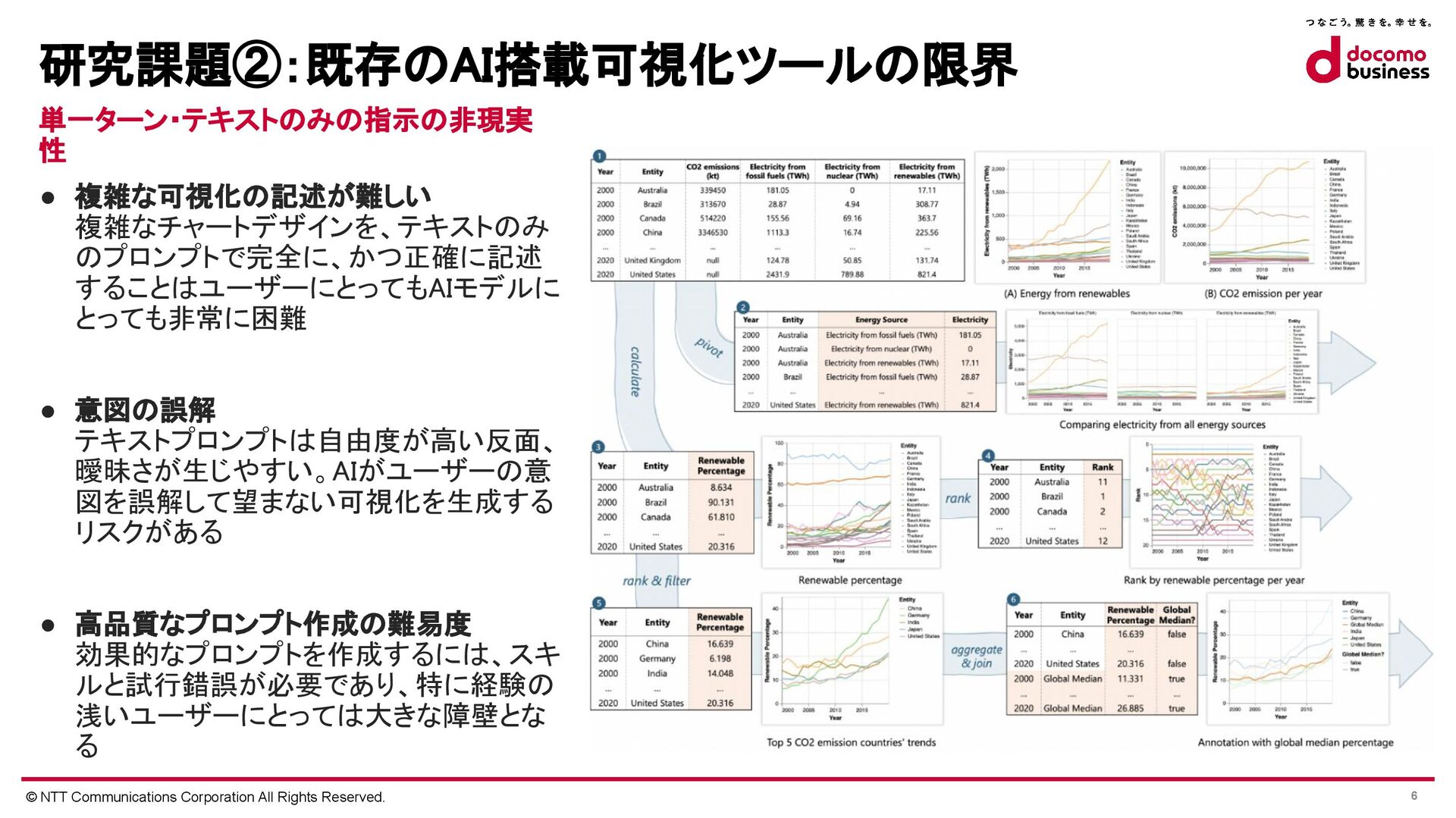{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}